Stochastic quasi-Newton with line-search regularization
In this paper we present a novel quasi-Newton algorithm for use in stochastic optimisation. Quasi-Newton methods have had an enormous impact on deterministic optimisation problems because they afford rapid convergence and computationally attractive a…
Authors: Adrian Wills, Thomas Sch"on
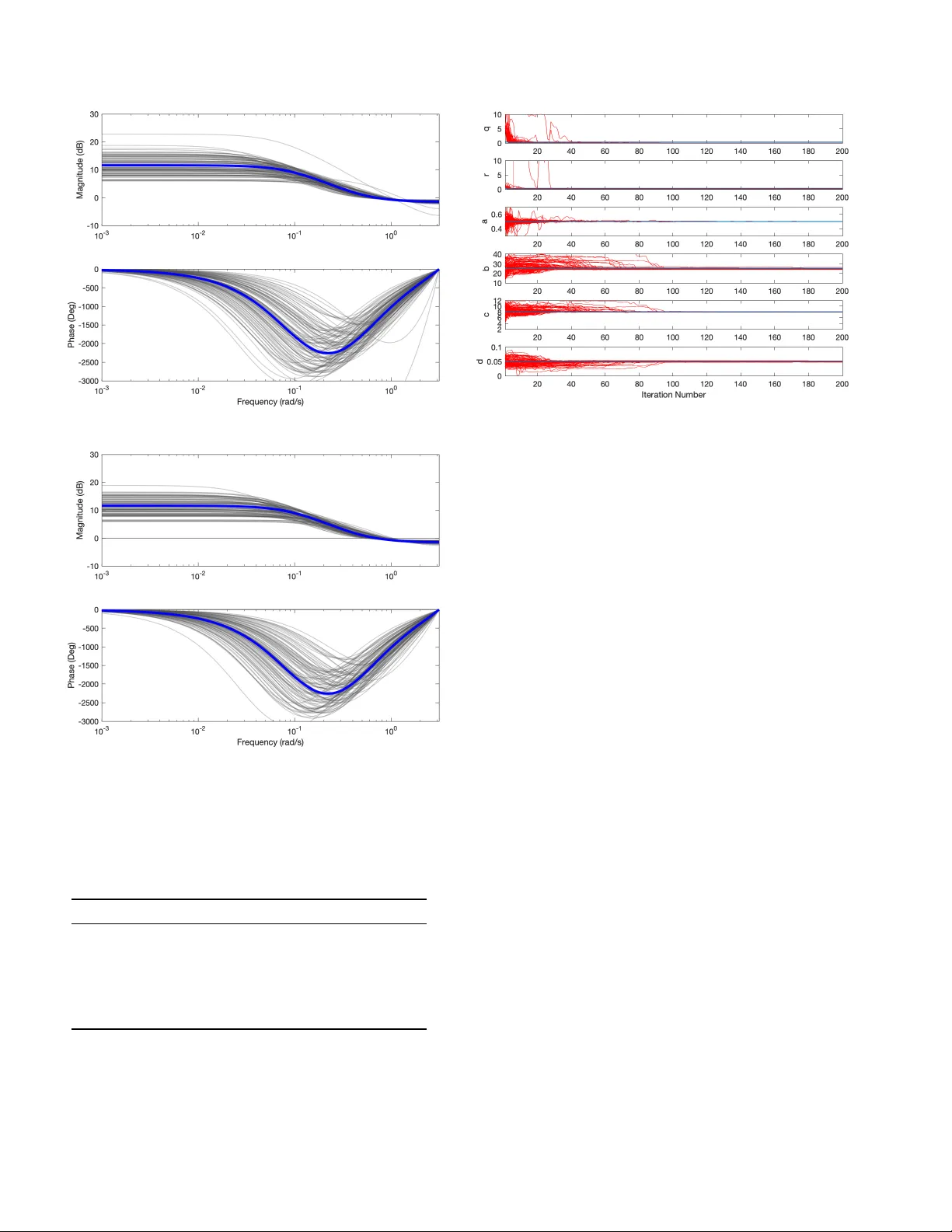
Sto c hastic quasi-Newton with line-searc h regularization Adrian Wills a , Thomas B. Sc h¨ on b a University of Newc astle, Scho ol of Engine ering, Cal laghan, NSW 2308, Austr alia. b Uppsala University, Dep artment of Information T e chnolo gy, 751 05 Uppsala, Swe den. Abstract In this pap er w e presen t a no v el quasi-Newton algorithm for use in stochastic optimisation. Quasi-Newton methods hav e had an enormous impact on deterministic optimisation problems because they afford rapid conv ergence and computationally attractiv e algorithms. In essence, this is achiev ed by learning the second-order (Hessian) information based on observing first- order gradien ts. W e extend these ideas to the stochastic setting b y employing a highly flexible model for the Hessian and infer its v alue based on observing noisy gradien ts. In addition, we propose a sto chastic coun terpart to standard line-search pro cedures and demonstrate the utility of this com bination on maxim um lik eliho o d identification for general nonlinear state space mo dels. Key wor ds: Nonlinear System Iden tification, Stochastic Optimisation, Stochastic Gradien t, Sto chastic Quasi-Newton, Sequen tial Mon te Carlo, P article Filter, and Gaussian Process. 1 In tro duction W e are in terested in the non-conv ex sto c hastic optimi- sation problem min x f ( x ) , (1) where w e only hav e access to noisy ev aluations of the cost function f ( x ) and its first-order deriv ativ es. The problem has a long history and an imp ortant landmark dev elopmen t was the so-called sto chastic appr oximation idea deriv ed b y Robbins and Monro almost 70 y ears ago [42]. The central idea of sto c hastic approximation is to form a Marko v-Chain for x via x k +1 = x k + α k p k (2) that conv erges (under fairly mild conditions) to a lo cal minim um of (1) for careful c hoices of the se ar ch-dir e ction p k and step-length α k > 0 (see e.g. [7]). In recent years the relev ance of this problem has mas- siv ely increased mainly due to the fact that it arises in ? This paper was not presented at an y IF AC meeting. Cor- resp onding author: A. Wills. Email addr esses: Adrian.Wills@newcastle.edu.au (Adrian Wills), thomas.schon@it.uu.se (Thomas B. Sc h¨ on). at least the follo wing tw o imp ortant situations. First, when the cost function and its gradients are intractabl e, but where w e can still make use of n umerical metho ds to compute noisy estimates (preferably unbiased) of these ob jects. Second, when the cost function inheren tly de- p ends on a v ery large amoun t of data and it becomes impractical to ev aluate it or the asso ciated gradient us- ing the entire dataset. It is then standard to use only a smaller fraction of the data, whic h is commonly referred to as minibatching. This situation arises in large-scale application of supervised machine learning and in par- ticular in deep learning. The application that motiv ated us to develop the solu- tion presen ted in this work is that of maximum likelihoo d iden tification of nonlinear state space mo dels. This is a sp ecific instance of the first situation men tioned ab ov e. The cost function—the likelihoo d—is intractable, but w e ha v e n umerical metho ds—sequen tial Mon te Carlo (SMC) [18,25,49]—that pro vide unbiased estimates of the likelihoo d [11,39]. F or tw o relativ ely recent ov erviews of the use of SMC—a.k.a. particle filters—in nonlinear system identification, see [43,22]. Our main c ontribution is a new sto c hastic optimisation algorithm which features mechanisms facilitating the use of second-order information (Hessian) in calculating the searc h-direction p k , and a stochastic line searc h to com- pute the step-length α k . The represen tation used for the Hessian is pro vided by the Gaussian process [41] and we Preprin t submitted to Automatica 4 Septem b er 2019 dev elop a metho d for its online up dating as the optimi- sation algorithm progresses. W e also deriv e a sto chas- tic line-search pro cedure that employs a version of the Armijo condition [2,53,54]. It is p erhaps surprising that little work has b een done when it comes to developing sto c hastic line-search metho ds [5]. W e stress that while the dev elopmen ts mentioned ab ov e are generally appli- cable, the application that motiv ated us to undertake this work is the nonlinear system identification problem, whic h provides an imp ortant spin-off contribution. 2 Related w ork Due to its imp ortance, the sto c hastic optimisation prob- lem is rather w ell studied by now. The first stochas- tic optimisation algorithm was introduced in [42]. It mak es use of first-order information only , motiv ating the name sto chastic gradient (SG), which is the contempo- rary term [7] for these algorithms, originally referred to as sto chastic approximation. Interestingly most SG al- gorithms are not descen t methods since the sto chastic nature of the up date can easily pro duce a new iterate corresp onding to an increase in the cost function. In- stead, they are Marko v chain metho ds in that their up- date rule defines a Marko v chain. Since the landmark pap er [42], many extensions and mo difications hav e b een developed within the statistics and automatic con trol communities. While the contri- butions are to o many to enumerate here, some notable w orks include conv ergence results [23,29,30], online pa- rameter estimation and system identification in [27,28], adaptiv e con trol strategies [17], and general b o oks in the area [4,48,31]. It is imp ortant to note that a primary mo- tiv ation for the current pap er is the closely related area of system identification for nonlinear dynamic systems. This existing researc h is ha ving an enormous impact in the related area of machine learning at presen t and w e b eliev e the reason is simple: it is used to solve almost all sup ervised machine learning problems, including all deep learning problems [7]. This is evidenced by all av ail- able to olb oxes in the area offering SG algorithms and v arian ts of them. Due to this, SG metho ds are still re- ceiving enormous research attention. The primary fo cus of curren t research activity is directed to w ards pro ducing algorithms with improv ed conv er- gence rates. Two imp ortant asp ects that impact conv er- gence rate are: • Poor problem scaling can lead to slow con v ergence [7]; • Classical step-length formulas are conserv ative [3,37]. Regarding the first p oint, a well-kno wn drawbac k of first-order metho ds is that the choice of co ordinate sys- tem can greatly impact the rate of con vergence, which is highlighted in the concluding commen ts of a recent review pap er on the topic [7]. Incorportating second- order information (Hessian) can alleviate the sensitiv- it y to coordinate choice, whic h is one of the motiv ations for the Newton’s metho d and it’s lo cally quadratic con- v ergence rate. A t the same time, in man y pratical sit- uations, computing the Hessian is impractical, which is certainly the case in man y system iden tification prob- lems and almost all deep learning problems. Address- ing this problem are the infamous suite of quasi-Newton metho ds such as the BFGS metho d [10,13,16,47], Broy- den’s metho d [8] and the DFP formula [15,9]. In essence, these algorithms learn the Hessian (or its in verse) ma- trix based on first-order information, resulting in fast con v ergence and computationally attractiv e algorithms. F or the stochastic setting of the curren t pap er, these classical quasi-Newton metho ds are not applicable [7]. T ow ards addressing this, ov er the past decade we hav e witnessed increasing capabilities of so-called sto chastic quasi-Newton metho ds , the category to which our cur- ren t dev elopments b elong. The w ork by [45] developed mo difications of BFGS and its limited memory v ersion. There has also b een a series of pap ers appro ximating the inv erse Hessian with a diagonal matrix, see e.g. [6] and [12]. The idea of exploiting regularisation together with BFGS w as successfully in tro duced by [36]. Some of these approaches rely on the assumption that main- taining common random num b ers b etw een tw o gradi- en t ev aluations will result in lo cally deterministic be- ha viour. While this assumption ma y b e satisfied for cer- tain classes of functions, it is not v alid of nonlinear sys- tem iden tification situation when SMC based calculation of the cost and gradient are employ ed [22]. In the current pap er, w e take a differen t approach and dev elop a new quasi-Newton algorithm that deals with the stochastic problem directly . The dev elopment stems from stating the in tegral form of the so-called quasi- Newton equation, where an exact relation b etw een gra- dien t differences and the Hessian are provided. This pro- vides a natural p oin t for treating the sto chastic gradi- en ts and w e then prop ose the use of a flexible mo del structure for the unknown Hessian matrix based on for- m ulating the problem as a Gaussian Pro cess regression problem. This results in a fully probabilistic mo del for the Hessian, where the mean function is used as a surro- gate Hessian matrix in a new quasi-Newton algorithm. Regarding the second p oint, the step-length sc hedule is also addressed in the curren t pap er b y suggesting a sto c hastic line-search pro cedure mo delled after the back- trac king line-search with Armijo conditions [2,53,54]. It is interesting—and perhaps somewhat surprising—to note that it is only v ery recen tly that stochastic line searc h algorithms ha v e started to b ecome a v ailable. One nice example is the approac h proposed b y [34] whic h uses the framework of Gaussian pro cesses and Bay esian optimisation. The step length is chosen that b est satis- fies a probabilistic measure com bining reduction in the 2 cost function with satisfaction of the Armijo condition. Conceptually more similar to our pro cedure is the line searc h prop osed by [5], which is tailored for problems that are using sampled mini-batc hes, as is common prac- tice within deep learning. The final line-search algorithm prop osed in the curren t pap er b egins with a more classi- cal backtrac king style pro cedure and conv erges tow ards a deterministic schedule that satisfies the t ypical con- v ergence requirements for SG metho ds. While w e started this dev elopment in our earlier confer- ence pap er [52], that pap er missed several key ingredi- en ts that w e pro vide in this paper. In particular w e ha ve no w developed a correct and prop erly working mecha- nism for represen ting and up dating the lo cal Hessian us- ing a GP . F urthermore, we hav e introduced a completely new and improv ed line search algorithm. 3 Sto c hastic quasi-Newton method Quasi-Newton methods hav e found enormous success within the field of optimisation [38]. The primary reasons are that they capture the cost function curv ature infor- mation and that they are computationally inexp ensiv e, requiring only gradient calculations. The c urv ature in- formation leads to b etter scaling of the negative gradient direction and consequently to faster conv ergence [38]. In pursuit of similar adv antages for the sto chastic op- timisation problem, many authors hav e considered how to develop quasi-Newton algorithms when the gradient v ector is sto chastic (see e.g. the concluding remarks in [7]). While the p otential b enefits of incorp orating cur- v ature information are widely recognised, it remains a rapidly evolving area. In order to describ e our quasi-Newton approach in Sec- tion 4, here we provide some background material with a sligh tly non-standard introduction to the quasi-Newton metho d (Section 3.1). This leads to the so-called quasi- Newton inte gr al from which the more classic se c ant e qua- tion can b e obtained. The secan t equation is essen tial to all standard quasi-Newton methods such as BF GS, DFP and SR1 metho ds, and is obtained by introducing a rather strong approximation. W e refrain from making this approximation and in Section 3.2 we show that we can formulate a sto chastic version of the quasi-Newton in tegral. 3.1 A non-standar d quasi-Newton intr o duction The idea underlying the Newton and quasi-Newton metho ds is to le arn a lo c al quadr atic surr o gate mo del q ( x k , δ ) of the cost function f ( x ) around the curren t iterate x k q ( x k , δ ) , f ( x k ) + δ T ∇ f ( x k ) + 1 2 δ T ∇ 2 f ( x k ) δ, (3) where δ = x − x k . Note that (3) is a second-order T a ylor expansion of f ( x ), i.e. f ( x ) ≈ q ( x k , δ ) in a close vicinity around the current iterate x k . Quasi-Newton methods are used in situations where the curv ature information inherent in the Hessian is imp or- tan t at the same time as it is to o exp ensive or imp ossi- ble to compute the Hessian. The idea is to introduce a represen tation for the Hessian and compute an estimate of the Hessian using zero- and first-order information (function v alues and their gradients). More sp ecifically the existing quasi-Newton methods are designed to rep- resen t the cost function according to the following mo del f q ( x k + δ ) = f ( x k ) + δ T ∇ f ( x k ) + 1 2 δ T H k δ, (4) for some matrix H k represen ting the Hessian. In order to see how to up date the Hessian approximation as the algorithm pro ceeds let us assume that x k and x k +1 are kno wn. The line segmen t r k ( τ ) connecting these t wo iterates can b e expressed as r k ( τ ) = x k + τ ( x k +1 − x k ) , τ ∈ [0 , 1] . (5) The fundamental theorem of calculus states that Z 1 0 ∂ ∂ τ ∇ f ( r k ( τ ))d τ = ∇ f ( r k (1)) − ∇ f ( r k (0)) = ∇ f ( x k +1 ) − ∇ f ( x k ) (6) and the chain rule allows us to express the integrand as ∂ ∂ τ ∇ f ( r k ( τ )) = ∇ 2 f ( r k ( τ )) ∂ r k ( τ ) ∂ τ = ∇ 2 f ( r k ( τ ))( x k +1 − x k ) . (7) By inserting (7) into (6) we conclude that Z 1 0 ∇ 2 f ( r k ( τ ))( x k +1 − x k )d τ = ∇ f ( x k +1 ) − ∇ f ( x k ) . (8) W e introduce the following notation s k , x k +1 − x k , (9) for the differences b et w een t w o adjacen t iterates. The in tegral (8) can be written in a more con venien t form according to ∇ f ( x k +1 ) − ∇ f ( x k ) = Z 1 0 ∇ 2 f ( r k ( τ ))d τ s k , (10) whic h we will refer to as the quasi-Newton inte gr al . The in terpretation of the ab ov e developmen t is that the dif- ference betw een tw o consecutive gradients constitute a 3 line inte gr al observation of the Hessian . The challenge is that the Hessian is unknown and there is no functional form av ailable for it. The approac h taken b y existing quasi-Newton algo- rithms is to assume that the Hessian can be described b y a zero-order T a ylor expansion, ∇ 2 f ( r k ( τ )) ≈ H k +1 , τ ∈ [0 , 1] , (11) implying that the integral equation in (10) is appro xi- mated according to ∇ f ( x k +1 ) − ∇ f ( x k ) = H k +1 s k . (12) This equation is known as the se c ant c ondition or the quasi-Newton e quation [14,38]. It constrains the p ossible c hoices for the Hessian approximation H k +1 since in ad- dition to b eing symmetric, it should at least satisfy the secan t condition (12). This is still not enough to uniquely determine the Hessian and we are forced to include ad- ditional assumptions to find the Hessian appro ximation. Dep ending on whic h assumptions are made we reco ver the standard quasi-Newton algorithms. See [20] for ad- ditional details. Our approach is fundamentally different in that we will allo w the Hessian to evolv e according to a general non- linear function whic h is represented using a Gaussian pro cess. 3.2 Sto chastic quasi-Newton formulation The situation we are interested in corresp onds to the case where we hav e access to noisy ev aluations of the cost function and its gradients. In particular, assume that the computed gradient g k can b e mo delled as g k = ∇ f ( x k ) + v k (13) and where we make the simplifying assumption that v k is indep endent and identically distributed according to v k ∼ N (0 , R ) , R 0 . (14) Therefore, via (9)–(10) ∇ f ( x k +1 ) − ∇ f ( x k ) = Z 1 0 ∇ 2 f ( r k ( τ ))d τ s k = g k +1 − g k + v k +1 − v k , (15) so that if we define y k = g k +1 − g k (16) then w e obtain a sto chastic quasi-Newton inte gr al ac- cording to y k = Z 1 0 ∇ 2 f ( r k ( τ ))d τ s k + w k , (17) where w k = v k − v k +1 . Based on (17) the Hessian can no w b e estimated via the gradien ts that we hav e av ail- able. T o enable this we first need a suitable represen- tation for the Hessian. How ever, before w e mak e that c hoice in the subsequent section, let us rewrite the inte- gral slightly to clearly exploit the fact that the Hessian is by construction a symmetric matrix. Note that since ∇ 2 f ( r k ( τ )) s k is a column v ector w e can straigh tforw ardly apply the vectorisation op erator inside the integral in (17) without changing the result, ∇ 2 f ( r k ( τ )) s k = v ec ∇ 2 f ( r k ( τ )) s k = ( s T k ⊗ I ) v ec ∇ 2 f ( r k ( τ )) = ( s T k ⊗ I ) v ec ∇ 2 f ( r k ( τ )) , (18) where ⊗ denotes the Kroneck er pro duct and v ec ( · ) is the vectorisation op erator that when applied to an n × m matrix A produce a column vector by stac king each column A i ∈ R n for i = 1 , . . . , m via v ec ( A ) , A 1 . . . A m ∈ R nm × 1 (19) The whole p oint of this exercise is that w e ha ve now iso- lated the Hessian in a vectorised form vec ∇ 2 f ( r k ( τ )) inside the resulting integral y k = ( s T k ⊗ I ) Z 1 0 v ec ∇ 2 f ( r k ( τ )) d τ + w k . (20) The so-called half-vectorisation op erator 1 v ec h ( · ) [33] is no w a useful b o okkeeping to ol to encode the fact that the Hessian is symmetric. It will effectiv ely extract the unique elemen ts of the full Hessian and conv eniently store them in a vector for us according to h ( r k ( τ )) = vec h ∇ 2 f ( r k ( τ )) . (21) W e can then retrieve the full Hessian using the so-called duplic ation matrix D , which is a matrix such that v ec h ∇ 2 f ( r k ( τ )) = D h ( r k ( τ )) . (22) 1 F or a symmetric n × n matrix A , the vector v ec ( A ) contains redundan t information. More sp ecifically , we do not need to k eep the n ( n − 1) / 2 entries abov e the main diagonal. The half- v ectorisation vec h ( A ) of a symmetric matrix A is obtained b y v ectorising only the lo w er triangular part of A . 4 More details and some useful results on the duplication matrix, the asso ciated elimination matrix L (vec h ( A ) = L v ec ( A )) and their use are provided b y [33]. Finally , inserting (22) into (39) results in y k = ( s T k ⊗ I ) D | {z } = ¯ D k Z 1 0 h ( r k ( τ ))d τ + w k = ¯ D k Z 1 0 h ( r k ( τ ))d τ + w k . (23) W e hav e no w arrived at an integral pro viding us with information ab out the unique elemen ts of the Hessian ∇ 2 f ( x ) via the noisy gradient observ ations in y k . 4 Lo cal Hessian represen tation and learning If the cost function f ( x ) is truly quadratic, then the Hes- sian ∇ 2 f ( x ) is constant. On the other hand, in the more in teresting case when f ( x ) is not quadratic, the Hessian ∇ 2 f ( x ) can change rapidly and in a nonlinear wa y as a function of x . T ogether with the fact that our measure- men ts of the cost function and it gradients are noisy this motiv ates the need for a Hessian represen tation that can accommo date nonlinear functions in a sto chastic setting. There are of course many candidates for this, but the one w e settle for in this w ork is the Gaussian pr o c ess . It is a natural candidate since it provides a non-parametric and probabilistic mo del of nonlinear functions [41]. Besides these t wo reasons w e w ould also lik e to men tion the fact that all existing quasi-Newton algorithms can in fact be in terpreted as maximum a p osteriori estimates where a v ery specific Gaussian prior was used for the unknown v ariables. This was relatively recently discov ered b y [20]. As a fourth and final motiv ation, the GP is also v ery sim- ple to work with since it only inv olves manipulations of m ultiv ariate Gaussian distributions. An in triguing con- sequence of representing the Hessian using a GP is that it op ens up for new algorithms compared to the previ- ously a v ailable quasi-Newton algorithms. This w as in- deed also mentioned as an av enue for future work in [20], see also [21]. How ever, apart from our very preliminary w ork in [52] this is—to the b est of our knowledge—the first assembly of a working algorithm of this kind. Motiv ated by the ab ov e we will assume a GP prior for the unique elements of the Hessian according to h ∼ G P ( µ, κ ) , (24) where µ denotes the mean v alue function and κ de- notes the cov ariance function. With this in place we no w need to solv e a slightly non-standard GP regres- sion problem in order to incorp orate the gradient in- formation in to a p osterior distribution of the Hessian p ( h ( x ) | y k − p , . . . , y k ), where { y i } k i = k − p denotes the noisy gradien t-difference measuremen ts that are a v ailable. The non-standard nature of this regression problem is due to the integral that is present in (23). How ever, the GP is closed under linear op erators [41], and it is p ossi- ble to make use of the line integral formulation in (23). This will b e exploited to derive closed-form expression for the Hessian p osterior making use of the most recen t p + 1 observ ations av ailable in the gradients and iterates. Since w e will make frequent use of the most recen t p + 1 indecies, it is conevient to define an index set ` k as ` k , { k − p, k − p + 1 , . . . , k } . (25) Using this notation, we in tro duce b old face notation for the stac ked gradient differences and iterate differences according to y ` k , y T k − p y T k − p +1 · · · y T k T , (26a) s ` k , s T k − p s T k − p +1 · · · s T k T . (26b) The join t distribution of the unknown h ( x ) and the kno wn y ` k is given by h ( x ) y ` k ! ∼ N µ ( x ) m ` k ! , κ ( x, x ) K x,` k K ` k ,x K ` k ,` k !! . (27) where the mean vector m ` k is given by m ` k , m T k − p , . . . m T k T (28) and m i = E [ y i ] = ¯ D i Z 1 0 E [ h ( r i ( τ ))] d τ = ¯ D i Z 1 0 µ ( r i ( τ ))d τ . (29) The cov ariance matrix K ` k ,` k is given by K ` k ,` k , K k − p,k − p K k − p,k − p +1 , · · · K k − p,k K k − p +1 ,k − p K k − p +1 ,k − p +1 , · · · K k − p +1 ,k . . . . . . . . . K k,k − p K k,k − p +1 , · · · K k,k (30) 5 with each matrix element K i,j giv en by K i,j = E h ( y i − E [ y i ]) ( y j − E [ y j ]) T i = E " ¯ D i Z 1 0 ( h ( r i ( τ )) − µ ( r i ( τ ))) d τ + w i × ¯ D j Z 1 0 ( h ( r j ( t )) − µ ( r j ( t ))) d t + w j T # = ¯ D i Z 1 0 Z 1 0 κ ( r i ( τ ) , r j ( t ))d τ d t ¯ D T j + Rδ i,j , (31) where δ i,j reflects the cov ariance structure of (see (17)) E w i w T j = E ( v i − v i +1 )( v j − v j +1 ) T , (32) so that δ i,j = 2 if i = j, − 1 if | i − j | = 1 , 0 otherwise . (33) The terms in the cross-cov ariance K x,` k are given b y (and analogously for K ` k ,x ) K x,` k , K x,k − p K x,k − p +1 , · · · K x,k , (34) with each matrix element K x,j giv en by K x,j = E h ( h ( x ) − µ ( x )) ( y j − E [ y j ]) T i = E " ( h ( x ) − µ ( x )) × ¯ D j Z 1 0 ( h ( r j ( t )) − µ ( r j ( t ))) d t + e j T # = Z 1 0 κ ( x, r j ( t ))d t ¯ D T j . (35) The p osterior distribution can now be computed by ap- plying the standard result of conditioned Gaussian dis- tributions to the join t Gaussian distribution (27) result- ing in h ( x ) | y ` k ∼ N ( φ ` k ( x ) , Σ ` k ( x )) , (36a) where φ ` k ( x ) = µ ( x ) − K x,` k K − 1 ` k ,` k ( y ` k − m ` k ) , (36b) Σ ` k ( x ) = κ ( x, x ) − K x,` k K − 1 ` k ,` k K ` k ,x . (36c) T o actually b e able to work with this, the integrals in (31) and (35) hav e to b e computed. These in tegrals do of course dep end on our particular choice of k ernel. W e mak e use of a m ultiv ariate v ersion of the so-called squared exp onential kernel κ ( x, x 0 ) = M exp − 1 2 ( x − x 0 ) T V ( x − x 0 ) , (37) where the positive definite symmetric matrix M 0 de- scrib es the co v ariance effect on eac h element of h ( · ) and the p ositive definite symmetric matrix V 0 acts as an in verse length scale. The resulting in tegrals in (31) and (35) are non-trivial, but they can b e efficien tly com- puted using standard n umerical tools, see [19] for all the details. When a differen t kernel is used, the alternativ es are to either solve the corresponding integrals or to em- plo y the simplifying assumption we develop in the sub- sequen t section. W e conclude this section by illustrating the ab ov e GP approac h on a simple one dimensional example. Consider the function f ( x ) = 4( x − 6) 2 + e 1 . 2 x − 5 + 10 − 10 sin(1 . 2 x ) . (38) W e obtain N = 12 noise corrupted observ ations of the gradien t where g k = ∇ f ( x k ) + v k and v k ∼ N (0 , 100). The iterates x k ∈ [ − 5 , 7]. W e employ the squared- exp onen tial kernel (37) with M = 1000 and V = 0 . 2 for the cov ariance κ ( x, x 0 ) and select the mean function as µ ( x ) = 100. The resulting Hessian approximation in terms of the GP conditioned on y 1: N and s 1: N is shown in Figure 1 for a range of x v alues. Note that in the region x ∈ [ − 15 , − 5], w e ha v e not learned v ery m uch so the GP conv erges to the prior. Whereas, for the re- gion where w e observ e the gradien t, the resulting GP appro ximation supp orts the exact Hessian. Fig. 1. GP Hessian approximation for the function (38). Exact Hessian (solid black line), GP based Hessian mean (dashed blue) and co v ariance (shaded blue). 6 4.1 A simplifying appr oximation The ab ov e developmen t can b e simplified by inv oking the standard quasi-Newton appro ximation (12), effectiv ely remo ving the integrals. Indeed, if the Hessian can be mo delled as a constan t matrix b etw een x k and x k +1 , then the measurements can b e simplified to y k = Z 1 0 ∇ 2 f ( r k ( τ ))d τ s k + w k ≈ ∇ 2 f ( x k ) Z 1 0 d τ s k + w k = ∇ 2 f ( x k ) s k + w k . (39) W e can replace the unknown Hessian ∇ 2 f ( x k ) with the same GP as used ab ov e, so that the measurement equa- tion now b ecomes y k = ( s T k ⊗ I ) h ( x k ) + w k . (40) Therefore, in order to compute the posterior distribu- tion of h ( x k ) given the most recent p + 1 observ ations, w e follow an analogous path to the abov e discussion and emplo y (36), but where the required terms are now in- stead given by m i = E [ y i ] = ¯ D i µ ( x i ) , (41) and K i,j = E ( y i − m i )( y j − m j ) T = ¯ D i κ ( x i , x j ) ¯ D T j + Rδ i,j , (42) where δ i,j is defined in (33), and K x,j = E h ( h ( x ) − µ ( x )) ( y j − m j ) T i = κ ( x, x j ) ¯ D T j . (43) 4.2 Computing the se ar ch dir e ction In the deterministic optimisation setting, conv ergence to lo cal minima often requires that the search direction p k is a so-called des cen t direction that satisfies (see e.g. [38]) p T k ∇ f ( x k ) < 0 . (44) This essentially means that p k is sufficiently aligned with the negative gradient direction −∇ f ( x k ), which then affords lo cal progress along the direction p k . When the search direction is determined by a scaling matrix p k = − B k ∇ f ( x k ) , (45) then the descent condition can b e guaranteed if B k 0 since −∇ f T ( x k ) B k ∇ f ( x k ) < 0 for all ∇ f ( x k ) 6 = 0. This is sufficien t, but not necessary . If B k is c hosen as the in- v erse Hessian then there is no guaran tee that B k 0 unless the problem is strongly conv ex. In the more gen- eral non-conv ex setting then the Hessian can b e indefi- nite, particularly in early iterations, and this should b e carefully dealt with. In terestingly , standard BFGS and DFP quasi-Newton metho ds com bat this b y maintain- ing p ositive definite matrices B k as the algorithm pro- gresses (see e.g. [38]). In the sto chastic setting of this pap er, we cannot guar- an tee a descent direction since we do not hav e access to the gradien t ∇ f ( x k ), but only a noisy v ersion g k . In the curren t section, we propose a mechanism to ensure that the search direction is a descent direction in exp ectation. That is, we will compute a search direction p k = − B k g k (46) based on the GP quasi-Newton approximatation from Section 4 and show that E p T k ∇ f ( x k ) | x k , s ` k − 2 , y ` k − 2 < 0 . (47) In particular, let the matrix B k b e defined as B k = ( H k + λ k I ) − 1 , (48a) where H k comes from the mean v alue of the GP quasi- Newton approximation based on { s ` k − 2 , y ` k − 2 } . More sp ecifically , using φ ` k − 2 ( x ) from (36b), H k is defined as (note that if k < 2, then { s ` k − 2 , y ` k − 2 } is empty and φ ` k − 2 ( x ) = µ ( x )) H k = D φ ` k − 2 ( x k ) , (48b) where D is the duplication matrix defined in (22), and λ k is selected as λ k = − min { 0 , η k } , (48c) where η k is the minimum eigenv alue of H k and > 0 is a user-defined tolerance. With this c hoice for the scaling matrix B k , we hav e the following Lemma. Lemma 1 L et the matrix B k b e given by (48) and the se ar ch dir e ction p k b e given by (46) , then E p T k ∇ f ( x k ) | x k , s ` k − 2 , y ` k − 2 < 0 . (49) Pro of 1 Sinc e we ar e c onditioning on { x k , s ` k − 2 , y ` k − 2 } , then H k is deterministic. F urthermor e, sinc e H k is sym- metric by c onstruction and λ k > 0 is chosen such that 7 H k + λ k I 0 , then B k 0 is also deterministic. Then, E p T k ∇ f ( x k ) = E − ( ∇ f ( x k ) + v k ) T B k ∇ f ( x k ) , = − E [ − v k ] T B k ∇ f ( x k ) − ∇ f T ( x k ) B k ∇ f ( x k ) , < 0 . 5 Sto c hastic line searc h It is t ypical within the sto chastic optimisation setting to ensure stability of the Marko v-chain x k +1 = x k + α k p k (50) b y requiring that the step-length α k satisfies ∞ X k =1 α k = ∞ , ∞ X k =1 α 2 k < ∞ , (51) with a standard choice b eing α k = α 0 /k with α 0 > 0. In addition to this, the searc h direction p k m ust also satisfy certain conditions, that are t ypically met when p k = − g k for example (see [7] for an excellent review of these conditions and asso ciated conv ergence pro ofs). While these choices are often sufficien t, they are also kno wn to b e conserv ative [3,37]. The initial step-length α 0 is often forced to b e small in order to pro vide sta- bilit y , since the optimal choice depends on certain Lips- c hitz constants [7], that are typically not easy to obtain for man y practical problems. One wa y to combat this sensitivit y is to scale the gradien t b y the in v erse Hes- sian, but this alone is not sufficient to ensure stability . Another approach is to use adaptiv e scaling methods that ha v e found enormous impact in the machine learn- ing literature (see [24] and [32] for example). A further mec hanism, used in deterministic optimisation, is to se- lect α k suc h that the new cost f ( x k + α k p k ) sufficiently decreases, which is often called a line-search pro cedure. In this section we will discuss a line-search pro cedure for stochastic optimisation. In early iterations it mimics a deterministic line-search using the noisy cost function to regulate the step-length. As the iteration k increases, w e con verge to taking steps that mimic α k = α 0 /k , whic h then affords standard conv ergence results [7]. In this sense, the line-search pro cedure can b e interpreted as a mec hanism to find α 0 suc h that steps α k = α 0 /k are likely to pro duce a stable Marko v-chain. T ow ards this end, in the deterministic setting, the ques- tion of how far to mov e in the searc h direction p k can be form ulated as the following scalar minimisation problem min α f ( x k + αp k ) , α > 0 . (52) One commonly used approach is to aim for a sub-optimal solution to (52) that guarantees a sufficien t decrease in the cost. F or example, the p opular Armijo condition [2] requires a step-length α k suc h that f ( x k + αp k ) ≤ f ( x k ) + cα k g T k p k , (53) where the user-defined constan t c ∈ (0 , 1). The abov e condition is also kno wn as the first W olfe condition [53, ? ]. In the sto chastic setting, w e unfortunately do not hav e access to either f ( x ) or ∇ f ( x ) but only noisy versions of them. This presents the following difficulties in emplo y- ing an Armijo type condition: • W e may accept a step-length α k in the case where the observ ed cost has sufficien tly decreased, even though the true cost may in fact hav e increased; • W e may reject a suitable α k when the observed cost in- creased, even though the true cost may hav e decreased sufficien tly . Consider the case when the measurements of the func- tion and its gradient are given by b f ( x k ) = f ( x k ) + e k , g k = ∇ f ( x k ) + v k , (54) where e k and v k denote indep endent noise on the func- tion and gradient ev aluations, resp ectively . F urthermore w e assume that E [ e k ] = b, Cov [ e k ] = σ 2 f , E [ v k ]= 0 , Cov [ v k ] = R. (55) Since b f and g k are random v ariables, we explore the idea of requiring (53) to b e fulfilled in exp ectation when the exact quan tities are replaced with their stochastic coun terparts, that is E h b f ( x k + αp k ) − b f ( x k ) − cα k g T k p k | x k , s ` k − 2 , b y ` k − 2 i ≤ 0 , (56) This is certainly one wa y in which we can reason ab out the Armijo condition in the stochastic setting w e are in- terested in. Although satisfaction of (56) do es not leav e an y guaran tees when considering a single measuremen t, it still serves as an important prop erty that could b e exploited to provide robustness for the entire optimisa- tion pro cedure. T o motiv ate our prop osed algorithm we hence start by establishing the following results. Theorem 1 (Sto chastic Armijo Condition) Assume that A1: f ( · ) is twic e c ontinuously differ entiable on an op en set X ⊆ R n x ; 8 A2: the gr adient is unbiase d, E [ g k ] = ∇ f ( x k ) ; A3: the exp e cte d c ost ob eys E h b f ( x k ) i = f ( x k ) + b ; A4: a desc ent dir e ction is exp e cte d, E p T k ∇ f ( x k ) < 0 . Then (for α smal l) E h b f ( x k + αp k ) − b f ( x k ) − cα k g T k p k | x k , s ` k − 2 , b y ` k − 2 i ≤ 0 , (57) wher e 0 < c < ¯ c = ∇ f T ( x k ) B k ∇ f ( x k ) ∇ f T ( x k ) B k ∇ f ( x k ) + T r { B k R } . (58) Pro of 2 Se e App endix A. Note that as the gradient noise v ariance R v anishes, we reco v er the classical result that ¯ c < 1 (see e.g. [38]). Relying up on this result, we prop ose a line search with psuedo-co de given in Algorithm 1. An input to this algo- rithm is the search direction p k , whic h can b e computed using any preferred metho d. The step length is initially set to b e the minimum of the natural step length 1 and the iteration dependent v alue ξ /k . In this w a y the initial step length is kept at 1 until k > ξ , a p oint after which it is decreased at the rate 1 /k . Then w e chec k whether the new point x k + αp k satisfies the sto chastic Armijo condition. If this is not the case, w e decrease α k with the scale factor ρ . This is rep eated un til the condition is met, unless w e hit an upp er b ound max { 0 , τ − k } on the num b er of bac ktrac king iterations, where τ > k is a p ositive integer. With this restriction the decrease of the step length is limited, and when k ≥ τ w e use a prescribed form ula for step length no matter if the sto chastic Armijo condition is satisfied or not. It should b e noted that for finite ξ > 0 and finite τ > 0, the follo wing algorithm will even tually take steps according to α k = ξ k and thus mimic the step-length prop erties required for con v ergence in standard sto chastic optimi- sation algorithms (see [7]). Algorithm 1 Sto chastic backtracking line search Require: Iteration index k , spatial point x k , searc h di- rection p k , scale factor ρ ∈ (0 , 1), reduction limit ξ ≥ 1, backtrac king limit τ > 0. 1: Set the initial step length α k = min { 1 , ξ /k } 2: Set i = 1 3: while b f ( x k + α p k ) > b f ( x k ) + cα k g T k p k and i ≤ max { 0 , τ − k } do 4: Reduce the step length α k ← ρα k 5: Set i ← i + 1 6: end while 6 Resulting algorithm In this brief section, we summarise the main algorithm emplo y ed in the simulations to follow. Algorithm 2 Sto chastic quasi-Newton Require: Search direction : a mean and cov ariance function µ and κ , resp ectively , for the prior GP ac- cording to (24). A cov ariance R 0 for the gradient noise v k and a memory length p > 0. Step-length : parameters according to Algorithm 1. A maximum n um b er of iterations k max > 0 and set k = 0 and and x 0 ∈ X . 1: while k < k max do 2: Obtain the gradient estimate g k . 3: if k > 0 then 4: Compute y k − 1 and s k − 1 . 5: end if 6: Compute the searc h direction p k = − B k g k , where B k is determined by (48a). 7: Calculate α k using Algorithm 1 and p k . 8: Compute x k +1 = x k + α k p k . 9: Up date k ← k + 1. 10: end while 7 Application to nonlinear system identification The metho d developed ab ov e is indeed generally appli- cable to a broad class of sto chastic and non-conv ex op- timization problems. By wa y of illustration we will con- sider its application to the problem of maximum likeli- ho o d identification of nonlinear state space mo dels x t = f ( x t − 1 , θ ) + w t , (59a) y t = g ( x t , θ ) + e t , (59b) where x t denotes the state, y t denotes the measure- men ts and θ denotes the unknown (static) parameters. The t wo nonlinear functions f ( · ) and g ( · ) denotes the nonlinear functions describing the dynamics and the measuremen ts, resp ectively . F urthermore, the pro cess noise is Gaussian distributed with zero mean and co- v ariance Q , w t ∼ N (0 , Q ) and the measuremen t noise is given b y e t ∼ N (0 , R ). Finally , the initial state is distributed according to x 0 ∼ p ( x 0 | θ ). The problem w e are interested in is to estimate the unknown param- eters θ by making use of the av ailable measuremen ts y 1: N = { y 1 , y 2 , . . . , y N } to maximize the lik eliho o d function p ( y 1: N | θ ) b θ = arg max θ p ( y 1: N | θ ) . (60) 9 The likelihoo d function can via rep eated use of condi- tional probabilities b e rewritten as p ( y 1: N | θ ) = N Y t =1 p ( y t | y 1: t − 1 , θ ) , (61) with the conv ention that y 1:0 = ∅ . The one step ahead predictors are av ailable via marginalization p ( y t | y 1: t − 1 , θ ) = Z p ( y t , x t | y 1: t − 1 , θ )d x t = Z p ( y t | x t , θ ) p ( x t | y 1: t − 1 , θ )d x t . (62) One in tuitiv e in terpretation of the abov e in tegral is that it corresp onds to av eraging o ver all possible v alues for the state x t . The c hallenge is of course ho w to actually compute this integral. By making use of particle filter [18,25,49] to approximate the likelihoo d we are guaran- teed to obtain an unbiased estimate [11,35]. Likelihoo d gradien ts can also b e calculated using particle meth- o ds [40], which we employ in the simulations b elow. The particle filter—which is one member of the family of sequen tial Mon te Carlo (SMC) methods—has a fairly ric h history when it comes to solving nonlinear system iden tification problems. F or introductory o verviews we refer to [43,22]. 7.1 Numeric al example – sc alar line ar SSM The first example to b e considered is the following simple linear time series x t +1 = ax t + v t , y t = cx t + e t , " v t e t # ∼ N " 0 0 # , " q 0 0 r #! (63a) with the true parameters given b y θ ? = [ a ? , c ? , q ? , r ? ] = [0 . 9 , 1 . 0 , 0 . 1 , 0 . 5] . Here we wish to estimate all four pa- rameters a, c, q and r based on observ ations y 1: N . The reason for including this example is that this problem is generally considered to b e solved. Indeed, using any standard quasi-Newton line-searc h algorithm in combi- nation with a Kalman filter to ev aluate the log-likelihoo d cost and gradient vector will pro vide the necessary com- p onen ts to estimate θ . This is not a sto chastic optimisation problem, but it is included so that our new GP based quasi-Newton Al- gorithm (henceforth referred to as QN-GP) can b e pro- filed in a situation where standard algorithms also apply . Therefore, in order to compare these metho ds, we gen- erated 100 data sets y 1: N with N = 100 observ ations in eac h. The standard quasi-Newton line-search algorithm w as run as usual with no mo dification. Ho wev er, when running the new QNGP algorithm (and only in this case) an extra noise term was added to eac h and ev ery log- lik eliho o d and gradient ev aluation. In particular, for the QNGP case we generated noisy log-likelihoo ds and gra- dien ts via (where the noise realisation w as changed for ev ery ev aluation) b ` ( θ ) , ` ( θ ) + η , η ∼ N (0 , 1) , (64a) d ∇ θ ` ( θ ) , ∇ θ ` ( θ ) + η g , η g ∼ N (0 , I ) . (64b) Figure 2 shows the Bode resp onse for each Mon te Carlo run and for each Algorithm. The v ast ma jority of esti- mates are grouped around the true Bode resp onse, with one or tw o estimates b eing trapped in lo cal minima that results in a p o or estimate. Interestingly , this is true for b oth the standard quasi-Newton algorithm and the new QNGP algorithm. Both algorithms w ere initialised with the same parameter v alue θ 0 , which itself was obtained b y generating a random stable system. 7.2 Numeric al example – nonline ar toy pr oblem A commonly emplo yed nonlinear b enchmark problem in v olves the following system x t +1 = ax t + b x t 1 + x 2 t + c cos(1 . 2 t ) + v t , (65a) y t = dx 2 t + e t , (65b) " v t e t # ∼ N " 0 0 # , " q 0 0 r #! (65c) where the true parameters are θ ? = [ a ? , b ? , c ? , d ? , q ? , r ? ] = [0 . 5 , 25 , 8 , 0 . 05 , 0 , 0 . 1] . Here we rep eat the simulation exp erimen t from [44], where a Monte Carlo study was p erformed using 100 differen t data realisations Y N of length N = 100. F or each of these cases, an estimate b θ was computed using 1000 iterations of Algorithm 2. The algorithm w as initialised with the i ’th elemen t of θ 0 c hosen via θ 0 ( i ) ∼ U 1 2 θ ? ( i ) , 3 2 θ ? ( i ) . In all cases M = 50 particles were used. Figure 3 shows the parameter iterates (for a, b, c, d ). This sho ws all Mon te Carlo runs (note that non w ere trapp ed in a lo cal minima). By wa y of comparison, the metho d presen ted in this paper is compared with the EM ap- proac h from [44] and the results are pro vided in T able 1, where the v alues are the sample mean of the parame- ter estimate across the Mon te Carlo trials plus/min us the sample standard deviation. F or the EM approach, 8/100 sim ulations w ere trapped in minima that w ere far from the global minimum and these results ha v e b een remo v ed from the calculations in T able 1. 7.3 Numeric al example – interfer ometry In terferometry was recen tly made famous due to its use in Nob el a ward winning detection of gra vitational w av es 10 (a) Standard quasi-Newton algorithm with no noise on func- tion v alues or gradients. (b) Quasi-Newton Gaussian pro cess algorithm. Fig. 2. Bo de plots of estimated mean (light grey) and true (blue) systems for 100 Monte Carlo runs. T able 1 T rue and estimate d p ar ameter values for QNGP and PSEM algorithms; me an value and standar d deviations ar e shown for the estimates base d on 100 Monte Carlo runs. θ θ ? QNGP PSEM a 0 . 5 0 . 50 ± 0 . 0011 0 . 50 ± 0 . 0019 b 25 . 0 25 . 0 ± 0 . 25 25 . 0 ± 0 . 99 c 8 . 0 8 . 0 ± 0 . 03 7 . 99 ± 0 . 13 d 0 . 05 0 . 05 ± 0 . 0006 0 . 05 ± 0 . 0026 q 0 1 . 5 × 10 − 6 ± 1 . 1 × 10 − 5 7 . 78 × 10 − 5 ± 7 . 6 × 10 − 5 r 0 . 1 0 . 095 ± 0 . 015 0 . 106 ± 0 . 015 in 2015 [1]. Tw o 4km interferometers form the Laser In terferometer Gra vitational-W av e Observ atory , called LIGO for short. The measured intensit y of eac h laser b eam at time t , denoted here as y t, 1 and y t, 2 , can b e plot- Fig. 3. Parameter iterations for nonlinear b enchmark prob- lem. T rue v alue (solid blue line), parameter evolution (think red line p er simulation). ted against one another to reveal an elliptical shap e as illustrated in Figure 4. This shape is essential to detect- ing reflector p erturbations, but is typically not known. The aim is to estimate this ellipse based on observed data. W e can parametrize this relationship as y t, 1 = α 0 + α 1 cos( κp t ) + e t, 1 , (66a) y t, 2 = β 0 + β 1 sin( κp t + γ ) + e t, 2 , (66b) where e t, 1 ∼ N (0 , σ 2 ) , e t, 2 ∼ N (0 , σ 2 ) and p t denotes the p osition of the laser reflector, which is not directly measured. A suitable model for the dynamics is pro vided b y a simple discrete-time kinematic relationship p t +1 v t +1 ! = 1 ∆ 0 1 ! p t v t ! + w t , (67) where ∆ > 0 is the sample interv al and w t is an un- kno wn action on the system. The unknown parameters are collected as θ = α 0 α 1 β 0 β 1 γ σ T and the re- sulting maximum likelihoo d system identification prob- lem can b e expressed as (60). This problem construc- tion is known as a blind Wiener problem [51]. W e gener- ated N = 1000 samples of the outputs using the ab ov e mo del with true parameter v alues indicated in T able 2. T o calculate the lik eliho od and its gradient, we employ ed a particle filter with M = 50 particles. A Monte-Carlo sim ulation with 100 runs was performed and the results are pro vided in T able 2. Figure 4 also pro vides the mea- sured outputs for one simulation and plots the ellipse as the algorithm progresses. The final ellipse is indicated in solid black while the true ellipse is shown in red. Based on these results, it appears that Algorithm 2 app ears to b e p erforming quite well . 11 Fig. 4. Parameter iterations for nonlinear interferometry problem. T rue ellipse (solid red), data p oints (crosses), in ter- mediate ellipse estimates (light grey), final ellipse estimate (solid black). T able 2 T rue and estimate d p ar ameter values for QNGP algorithm on the interfer ometry pr oblem; me an value and standar d devia- tions ar e shown for the estimates b ased on 100 Monte Carlo runs. θ θ ? QNGP Estimate α 0 0 − 0 . 0035 ± 0 . 0026 α 1 1 0 . 992 ± 0 . 0034 β 0 0 − 0 . 0001 ± 0 . 0027 β 0 1 1 . 01 ± 0 . 0042 γ 0 . 4 0 . 42 ± 0 . 01 σ 0 . 18 0 . 14 ± 0 . 0052 7.4 MIMO Hammerstein-Wiener system As a further example, w e turn attention to the multiple- input/m ultiple-output (MIMO) Hammerstein-Wiener system from [51] (Section 6.2 in that pap er). The sys- tem has t wo inputs, tw o outputs and 4’th order linear dynamics with saturation and deadzone static nonlin- earities on the input and output channels. F ull details of this system and the asso ciated parametrization can b e obtained from [51] and are not rep eated here due to page limitations. F or the purposes of estimation, N = 2000 samples of the inputs and outputs w ere sim ulated. In this case, t wo differen t algorithms are compared: (1) The SMC based Exp ectation-Maximisation metho d developed in [51], called the PSEM (parti- cle smo other EM) approach; (2) The quasi-Newton GP based solution presented in the current pap er, denoted as QNGP . F or QNGP metho d, M = 100 particles were used, and for QNGP M = 2500 particles were used (note that the computational complexit y of the former metho d scales as O ( M 2 ), while the second SMC approac h scales as O ( M ), making the tw o comparable). The algorithms w ere terminated after 1000 iterations. The results of 100 Mon te Carlo runs for all algorithms are sho wn in Fig- ures 5a–7. F or eac h run, differen t noise realisations w ere used according to the distributions sp ecified abov e. In eac h plot, the solid blue line indicates the true resp onse, while the red lines indicate the mean (think dashed) and one standard deviation from mean (thin dashed). This example shows that the prop osed Algorithm 2 com- pares well to state-of-the-art methods suc h as PSEM. A p otential b enefit of the QNGP approac h is that only forw ard filtering is required, whereas PSEM requires a SMC-based smo other, which can b e challenging in general[26,22]. -2 -1 0 1 2 QNGP Method -1.5 -1 -0.5 0 0.5 1 1.5 -2 -1 0 1 2 PSEM Method -1.5 -1 -0.5 0 0.5 1 1.5 Input nonlinearity 1 - Saturation (a) Input nonlinearity-1. -2 -1 0 1 2 QNGP Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 -2 -1 0 1 2 PSEM Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 Input nonlinearity 2 - Deadzone (b) Input nonlinearity-2. -2 -1 0 1 2 QNGP Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 -2 -1 0 1 2 PSEM Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 Output nonlinearity 1 - Deadzone (c) Output nonlinearity-1. -2 -1 0 1 2 QNGP Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 -2 -1 0 1 2 PSEM Method -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 Output nonlinearity 2 - Saturation (d) Output nonlinearity-2. 8 Conclusion and future w ork In this pap er we ha v e presen ted a new quasi-Newton algorithm for sto chastic optimisation problems. The approac h uses a tailored Gaussian pro cess to mo del the unkno wn Hessian, which is then learned from gradient information as the algorithm progresses. T o regulate the iterates, we dev elop ed a sto chastic line-search proce- dure that satisfies an Armijo condition (in exp ectation) for early iterations, and conv erges to a deterministic step-length schedule as the iterations grow. The former pro vides a mechanism to handle p o orly scaled prob- lems while the Hessian is learned, and the latter mimics conditions required for conv ergence in the sto chastic setting. The resulting combination is demonstrated on sev eral challenging nonlinear system identification problems, with promising results. The metho d can 12 10 -2 10 -1 10 0 G 11 -50 0 50 10 -2 10 -1 10 0 G 12 -60 -40 -20 0 20 40 60 10 -2 10 -1 10 0 G 21 -40 -20 0 20 40 10 -2 10 -1 10 0 G 22 -50 0 50 QNGP Fig. 6. Bo de magnitude resp onse using the QNGP metho d for the example studied in Section 7.4. 10 -2 10 -1 10 0 G 11 -50 0 50 10 -2 10 -1 10 0 G 12 -60 -40 -20 0 20 40 60 10 -2 10 -1 10 0 G 21 -40 -20 0 20 40 10 -2 10 -1 10 0 G 22 -50 0 50 PSEM Fig. 7. Bo de magnitude resp onse using the PSEM metho d for the example studied in Section 7.4. b e straightforw ardly extended to handle the situation where—p ossibly noisy—Hessian matrices are also ob- serv ed. The GP construction assumes that the gradient is cor- rupted b y additive Gaussian noise, and this is poten- tially not suitable for certain problem classes, particu- larly where the noise distribution has heavy tails. This allo ws for an extension to other pro cesses such as the studen t-t pro cess [46]. A further extension is for the case of large-scale problems, whic h frequently occur within the Mac hine Learning field. Some initial w ork in this di- rection can b e found in [50]. Ac knowledgemen ts This researc h is financially supp orted by the Swedish Re- searc h Council via the pro jects NewLEADS - New Dir e c- tions in L e arning Dynamic al Systems (contract n um b er: 621-2016-06079) and L e arning flexible mo dels for non- line ar dynamics (contract num b er: 2017-03807), and the Sw edish F oundation for Strategic Research (SSF) via the pro ject ASSEMBLE (contract n um b er: RIT15-0012). References [1] Benjamin P Abbott, Ric hard Abb ott, TD Abb ott, MR Ab ernathy , F austo Acernese, Kendall Ackley , Carl Adams, Thomas Adams, Paolo Addesso, RX Adhik ari, et al. Observ ation of gravitational wa ves from a binary black hole merger. Physic al r eview letters , 116(6):061102, 2016. [2] L. Armijo. Minimization of functions ha ving Lipschitz contin uous first partial deriv atives. Pacific Journal of Mathematics , 16(1):1–3, 1966. [3] H. Asi and J. C. Duchi. Stochastic (approximate) proximal point metho ds: conv ergence, optimality , and adaptivity . SIAM Journal on Optimization , T o app ear, 2019. [4] Dimitri P Bertsek as and John N Tsitsikli s. Neur o-dynamic pr o gramming , volume 5. Athena Scien tific Belmon t, MA, 1996. [5] R. Bollapragada, D. Mudigere, J. No cedal, H.-J. M. Shi, and P . T. P . T ang. A progressive batching L-BFGS method for machine learning. In Pro c e e dings of the 35th International Confer enc e on Machine Le arning (ICML) , Stockholm, Sweden, 2018. [6] A. Bordes, L. Bottou, and P . Gallinari. SGD-QN: Careful quasi-Newton sto chastic gradien t descent. Journal of Machine Le arning R esear ch (JMLR) , 10:1737–1754, 2009. [7] L. Bottou, F. E. Curtis, and J. No cedal. Optimization methods for large-scale machine learning. SIAM R eview , 60(2):223–311, 2018. [8] C. G. Broyden. A class of metho ds for solving nonlinear simultaneous equations. Mathematics of Computation , 19(92):577–593, 1965. [9] C. G. Broyden. Quasi-Newton metho ds and their application to function minimization. Mathematics of Computation , 21:368–381, 1967. [10] C. G. Broyden. The conv ergence of a class of double- rank minimization algorithms. Journal of the Institute of Mathematics and Its Applications , 6(1):76–90, 1970. [11] P . Del Moral. F eynman-Kac formulae: Genealo gic al and Inter acting P article Systems with Applic ations . Springer, New Y ork, USA, 2004. [12] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine L e arning R esear ch (JMLR) , 12:2121– 2159, 2011. [13] R. Fletcher. A new approach to v ariable metric algorithms. The computer journal , 13(3):317–322, 1970. [14] R. Fletcher. Pr actic al metho ds of optimization . John Wiley & Sons, Chichester, UK, second edition, 1987. [15] R. Fletc her and M. J. D. Po well. A rapidly conv ergent descent method for minimization. The c omputer journal , 6(2):163– 168, 1963. 13 [16] D. Goldfarb. A family of v ariable metric up dates derived by v ariational means. Mathematics of Computation , 24(109):23– 26, 1970. [17] Graham C Go o dwin, Peter J Ramadge, and Peter E Caines. Discrete time sto chastic adaptive control. SIAM Journal on Contr ol and Optimization , 19(6):829–853, 1981. [18] N. J. Gordon, D. J. Salmond, and A. F. M. Smith. Nov el approach to nonlinear/non-Gaussian Bayesian state estimation. In IEE Pr o c e e dings on R adar and Signal Pr o cessing , volume 140, pages 107–113, 1993. [19] J. N. Hendriks, C. Jidling, A. Wills, and T. B. Sch¨ on. Ev aluating the squared-exp onential cov ariance function in Gaussian pro cesses with integral observ ations. T echnical report, arXiv:1812.07319, 2018. [20] P . Hennig. Probabilistic interpretation of linear solvers. SIAM Journal on Optimization , 25(1):234–260, 2015. [21] P . Hennig and M. Kiefel. Quasi-Newton methods: a new direction. Journal of Machine L e arning R ese ar ch (JMLR) , 14:843–865, 2013. [22] N. Kantas, A. Doucet, S. S. Singh, J. M. Maciejowski, and N. Chopin. On particle metho ds for parameter estimation in state-space mo dels. Statistical Scienc e , 30(3):328–351, 2015. [23] Jack Kiefer and Jacob W olfowitz. Sto chastic estimation of the maxim um of a regression function. The A nnals of Mathematic al Statistics , 23(3):462–466, 1952. [24] D. P . Kingma and J. Ba. Adam: a method for stochastic optimization. In Pr o c e e dings of the 3rd international c onfer ence on learning r epresentations (ICLR) , San Diego, CA, USA, 2015. [25] G. Kitagaw a. A Monte Carlo filtering and smo othing method for non-Gaussian nonlinear state space mo dels. In Pr o ce e dings of the 2nd US-Jap an joint Seminar on Statistical Time Series Analysis , pages 110–131, 1993. [26] F. Lindsten and T. B. Sch¨ on. Backw ard simulation metho ds for Monte Carlo statistical inference. F oundations and Trends in Machine Learning , 6(1):1–143, 2013. [27] L. Ljung. Asymptotic behavior of the extended Kalman filter as a parameter estimator for linear systems. IEEE T r ansactions on Automatic Contr ol , AC–24(1):36–50, F ebruary 1979. [28] L. Ljung and T. S¨ oderstr¨ om. Theory and Pr actic e of R e cursive Identific ation . The MIT Press series in Signal Processing, Optimization, and Con trol. The MIT Press, Cambridge, Massach usetts, 1983. [29] Lennart Ljung. Analysis of recursive sto chastic algorithms. IEEE transactions on automatic c ontrol , 22(4):551–575, 1977. [30] Lennart Ljung. Strong con vergence of a stochastic approximation algorithm. The Annals of Statistics , pages 680–696, 1978. [31] Lennart Ljung, Georg Pflug, and Harro W alk. Sto chastic appr oximation and optimization of r andom systems , volume 17. Birkh¨ auser, 2012. [32] Liangchen Luo, Y uanhao Xiong, and Y an Liu. Adaptiv e gradient metho ds with dynamic b ound of learning rate. In International Confer enc e on Le arning R epr esentations (ICLR) , New Orleans, LA, USA, 2019. [33] J. R. Magn us and H. Neudeck er. The elimination matrix: some lemmas and applications. SIAM Journal on Algebr aic Discr ete Metho ds , 1(4):422–449, 1980. [34] M. Mahsereci and P . Hennig. Probabilistic line searc hes for sto chastic optimization. Journal of Machine L e arning R ese arch (JMLR) , 18(119):1–59, 2017. [35] S. Malik and M. K. Pitt. Particle filters for con tinuous likelihood ev aluation and maximisation. Journal of Ec onometrics , 165(2):190–209, 2011. [36] A. Mokhtari and A. Rib eiro. RES: regularized stochastic BFGS algorithm. IEEE T r ansactions on Signal Pr oc essing , 62(23):6089–6104, 2014. [37] E. Moulines and F. Bach. Non-asymptotic analysis of stochastic appro ximation algorithms for machine learning. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , Granada, Spain, 2011. [38] J. No cedal and S. J. W right. Numerical Optimization . Springer Series in Op erations Research. Springer, New Y ork, USA, second edition, 2006. [39] M. K. Pitt, R. dos Santos Silv a, R. Giordani, and R. Kohn. On some properties of Marko v chain Monte Carlo simulation metho ds based on the particle filter. Journal of Ec onometrics , 171(2):134–151, 2012. [40] G. Po yiadjis, A. Doucet, and S.S. Singh. Particle approximations of the score and observ ed information matrix in state space mo dels with application to parameter estimation. Biometrika , 98(1):65–80, 2011. [41] C. E. Rasmussen and C. K. I. Williams. Gaussian pro c esses for machine learning . MIT Press, 2006. [42] H. Robbins and S. Monro. A sto chastic approximation method. Annals of Mathematic al Statistics , 22(3):400–407, 1951. [43] T. B. Sc h¨ on, F. Lindsten, J. Dahlin, J. W ˚ agberg, A. C. Naesseth, A. Svensson, and L. Dai. Sequential Monte Carlo methods for system identification. In Pr o c e e dings of the 17th IF AC Symp osium on System Identification (SYSID) , Beijing, China, Octob er 2015. [44] T. B. Sch¨ on, A. Wills, and B. Ninness. System identification of nonlinear state-space mo dels. Automatic a , 47(1):39–49, January 2011. [45] N. N. Schraudolph, J. Y u, and S. G¨ unter. A stochastic quasi-Newton metho d for online conv ex optimization. In Pr o ce e dings of the 11th international c onfer ence on Artificial Intel ligenc e and Statistics (AIST A TS) , 2007. [46] A. Shah, A. G. Wilson, and Z. Ghahramani. Student-t processs as alternatives to Gaussian pro cesses. In Pr o c ee dings of the 17th international c onfer ence on artificial intel ligence and statistics (AIST A TS) , Reykjavik, Ic eland, May 2014. [47] D. F. Shanno. Conditioning of quasi-Newton metho ds for function minimization. Mathematics of Computation , 24(111):647–656, 1970. [48] James C Spall. Intr o duction to stochastic se ar ch and optimization: estimation, simulation, and c ontr ol , v olume 65. John Wiley & Sons, 2005. [49] L. Stewart and P . McCarty . The use of Bay esian b elief netw orks to fuse contin uous and discrete information for target recognition and discrete information for target recognition, tracking, and situation assessmen t. In Pr o ce e dings of SPIE Signal Pro c essing, Sensor F usion and T ar get Re c o gnition , volume 1699, pages 177–185, 1992. [50] A. Wills and T. B. Sch¨ on. Sto chastic quasi-Newton with adaptive step lengths for large-scale problems. arXiv:1802.04310, 2018. [51] A. Wills, T. B. Sch¨ on, L. Ljung, and B. Ninness. Iden tification of Hammerstein-Wiener mo dels. Automatic a , 49(1):70–81, 2013. [52] A. G. Wills and T. B. Sch¨ on. On the construction of probabilistic Newton-type algorithms. In Pr o c ee dings of the 14 56th IEEE Conferenc e on De cision and Control (CDC) , Melbourne, Australia, December 2017. [53] P . W olfe. Conv ergence conditions for ascent metho ds. SIAM R eview , 11(2):226–235, 1969. [54] P . W olfe. Conv ergence conditions for ascent metho ds I I: some corrections. SIAM R eview , 13(2):185–188, 1971. A The stochastic Armijo condition All exp ectation b elow are conditioned on the v ariables { x k , s ` k − 2 , b y ` k − 2 } . This conditioning is dropp ed from the notation in order to improv e readabilit y . The required exp ectation is E h b f ( x k + α k p k ) − b f ( x k ) − cα k g T k p k i ≤ 0 , (A.1) and recall that b f ( x k ) = f ( x k ) + e k , (A.2a) g k = ∇ f ( x k ) + v k , (A.2b) p k = − B k g k (A.2c) = − B k ( ∇ f ( x k ) + v k ) . (A.2d) Assume that x k ∈ X and x k + α k p k ∈ X . Since f is assumed t wice con tinuously differentiable on X , then emplo ying T a ylor’s theorem results in f ( x k + α k p k ) = f ( x k ) + α k p T k ∇ f ( x k ) + α 2 k 2 p T k ∇ 2 f ( ¯ x k ) p k (A.3) for some ¯ x k ∈ X . Hence, using (1) and (A.3) then (A.1) b ecomes E h f ( x k ) − f ( x k ) + e k +1 − e k − α k ( ∇ f ( x k ) + v k ) T B k ∇ f ( x k ) + cα k ( ∇ f ( x k ) + v k ) T B k ( ∇ f ( x k ) + v k ) + α 2 k 2 p T k ∇ 2 f ( ¯ x k ) p k i ≤ 0 whic h reduces to α k (1 − c ) ∇ f T ( x k ) B k ∇ f ( x k ) − c T r { B k R } ≤ − E h α 2 k 2 p T k ∇ 2 f ( ¯ x k ) p k i . Let γ = ∇ f T ( x k ) B k ∇ f ( x k ) and β = T r { B k R } , then division on b oth sides by α k > 0 results in γ − c ( γ + β ) ≤ − α k κ, (A.4) where κ = E[1 / 2 p T k ∇ 2 f ( ¯ x k ) p k ]. Since b oth B k 0 and R 0 then γ > 0, and β > 0. Therefore, for α k > 0 small enough, then (A.4) is satisfied for 0 < c < ¯ c = γ γ + β . 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment