Learning Discriminative features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
💡 Research Summary
The paper presents a novel multitask learning framework for speech emotion recognition (SER) that combines a convolutional neural network (CNN) with two complementary regularization strategies: center loss and an auxiliary reconstruction task. The authors argue that conventional SER systems often rely on automatic speech recognition (ASR) to convert speech to text before applying natural language processing, which discards valuable paralinguistic cues. By directly feeding low‑level acoustic representations—spectrograms and Mel‑frequency cepstral coefficients (MFCCs)—into a 2‑D CNN, the model preserves emotion‑related information that is otherwise lost in transcription.
The core technical contribution is the joint supervision of three loss components: (1) the standard softmax cross‑entropy loss for classifying four emotions (neutral, happiness, sadness, anger); (2) center loss, originally introduced for face recognition, which learns a feature centroid for each class and penalizes the Euclidean distance between sample embeddings and their respective centroids, thereby encouraging intra‑class compactness while maintaining inter‑class separation; and (3) a reconstruction loss (mean‑squared error) that forces the network to reconstruct its input features through a decoder branch, effectively acting as an auto‑encoder‑style auxiliary task. The combined loss is L = L_S + λ₁·L_C + λ₂·L_A, where λ₁ and λ₂ are hyper‑parameters tuned empirically (λ₁ = 4 gave the best results).
Architecturally, the network consists of four parallel 2‑D convolutional paths, each with 200 filters but distinct kernel sizes (4×6, 6×8, 8×10, 10×12). This multi‑scale design captures a variety of temporal‑frequency patterns in the speech signal. After convolution, each path undergoes max‑pooling that halves both dimensions, yielding a 200×4 feature map per path. The pooled features are flattened, concatenated, and fed into two independent fully‑connected (FC) layers. The lower FC layer connects to the softmax and center‑loss heads, while the upper FC layer feeds a deeper decoder composed of additional FC layers and a sigmoid output that matches the dimensionality of the original input feature (spectrogram or MFCC). ReLU activations are used throughout, dropout rates between 25 % and 75 % are explored, and Adadelta is employed as the optimizer.
For data preprocessing, the authors use the IEMOCAP corpus, selecting only improvised utterances to avoid textual bias. Utterances are truncated or zero‑padded to 6 seconds (the 75th percentile length). Spectrograms are generated with a 2048‑sample FFT window, 512‑sample hop, and then mapped to the mel scale; MFCCs are extracted with 40 coefficients per frame. Both representations are normalized and fed as 2‑D tensors to the CNN.
Experiments follow a 5‑fold cross‑validation protocol: in each fold, four sessions are used for training, one session is split into a validation speaker and a test speaker. The authors evaluate both overall accuracy (weighted by sample count) and class‑average accuracy (mean of per‑class accuracies) to address the pronounced class imbalance (neutral ≈ 49 % of data, others 12‑27 %).
Results (Table 1) show that adding center loss to the softmax‑only baseline improves overall accuracy from 71.2 % to 73.6 % (spectrogram) and from 70.5 % to 73.4 % (MFCC). Incorporating the reconstruction auxiliary task further raises performance, with the full S + A + C configuration achieving 74.3 % overall accuracy and 67.2 % class‑average accuracy on spectrogram inputs—an improvement of 3.1 % and 5.3 % respectively over the prior state‑of‑the‑art (Yenigalla et al., 2018). Parameter count is reduced to 0.26 M, a 62 % reduction compared with the 0.69 M parameters of Satt et al. (2017), highlighting the efficiency of the parallel‑CNN design.
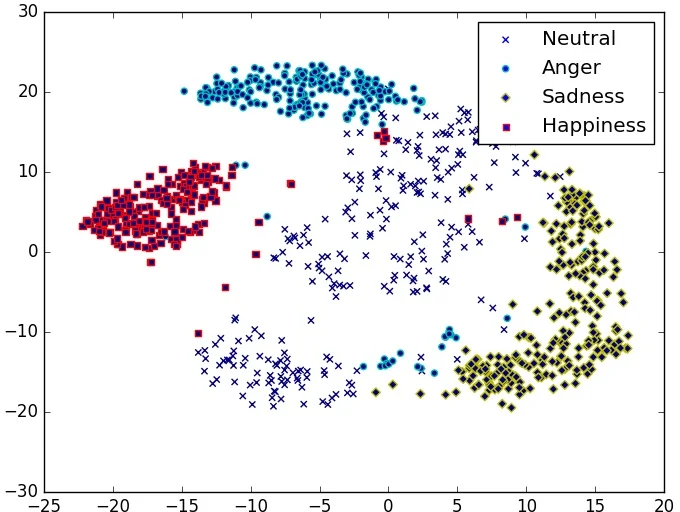
Qualitative analysis using t‑SNE visualizations of the final hidden layer confirms that center‑loss‑trained models produce tighter, more separable clusters for each emotion, whereas softmax‑only models exhibit scattered embeddings with noticeable overlap, especially for non‑happiness classes.
The authors discuss limitations: experiments are confined to a single English corpus, and no latency or real‑time inference analysis is provided. Future work could extend validation to multilingual datasets, explore model compression for on‑device deployment, and integrate the learned embeddings into downstream affective dialogue systems.
In summary, the paper demonstrates that (i) center loss effectively enforces intra‑class compactness in SER, (ii) an auto‑encoder‑style reconstruction task serves as a powerful regularizer that mitigates overfitting on limited, imbalanced data, and (iii) a multi‑scale parallel CNN architecture can achieve state‑of‑the‑art performance with substantially fewer parameters. This combination offers a practical and scalable solution for emotion‑aware speech interfaces.
Comments & Academic Discussion
Loading comments...
Leave a Comment