On Energy Compaction of 2D Saab Image Transforms
The block Discrete Cosine Transform (DCT) is commonly used in image and video compression due to its good energy compaction property. The Saab transform was recently proposed as an effective signal transform for image understanding. In this work, we …
Authors: Na Li, Yongfei Zhang, Yun Zhang
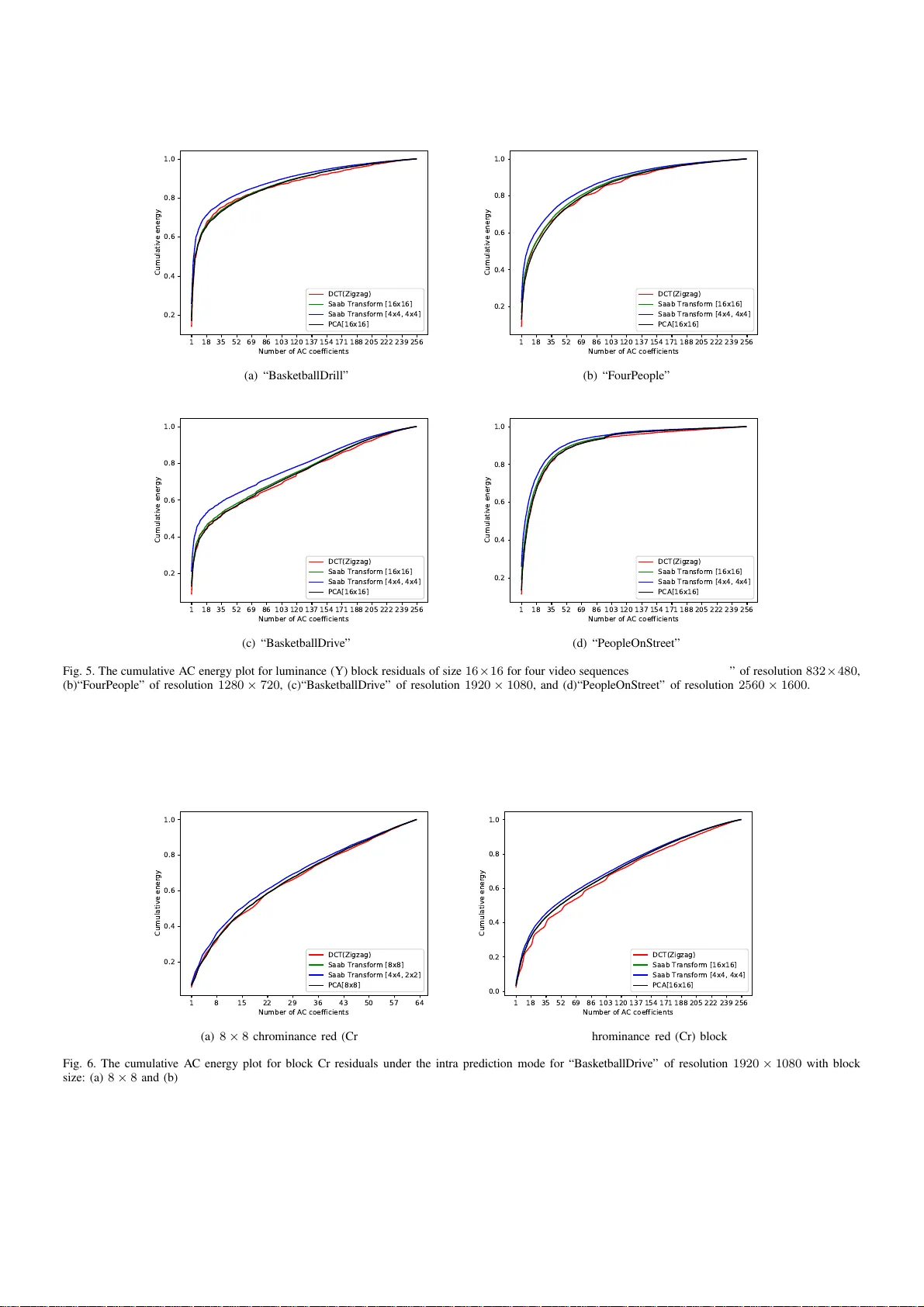
On Ener gy Compaction of 2D S aab Image T ransforms Na Li ∗ , Y ongfei Zhang † , Y un Zhang ∗ , C.-C. Jay K uo ‡ ∗ Shenzhen Institutes of Advanced T echn ology , Chinese Academy of Sciences, Shenzhen , China † School o f Computer Science and Engineerin g, Beihang Uni versity , Beijing , Ch in a ‡ University of Southern Califor nia, Los An geles, California, USA Abstract —The block Discrete Cosine T ransform ( D CT ) is commonly used in image and video compression due to it s good energy compaction p roperty . Th e S aab transform was recently proposed as an effective signal transform f or image understandin g. In this wo rk, we study the energy compaction property of the Saab transf orm i n the context of intra-codin g of the High Efficiency Video Coding (HEVC) st an d ard. W e compare the energy compaction property of th e Saab transform, the DCT , and the Karhunen-Loeve transfo rm (KL T) by applying them to dif f erent sizes of intra-predicted residual blocks in HEVC. The b asis functions of th e S aab transform ar e visuali zed . Extensive experimental results are giv en to demonstrate the energy compaction capability of the S aab transform. I . I N T R O D U C T I O N T wo-dimensiona l (2D) image transforms map 2D sig n als defined on a regular grid from the spatial domain to th e spec- tral doma in . Since they can comp act th e energy distribution in the spatial-d omain to a fewer n umber of frequen cy-domain coefficients, 2D im a ge transfo rms are wid ely used in image or v ideo cod ing standar d s. T ra ditionally , 2D imag e transfor ms adopt separable transform kernels. T hat is, the 2 D tran sform kernel is formed by the tensor produc t of hor izontal and ver- tical one-dim e nsional (1D) transform kernels. The transforms are first conduc ted along one dimension (say , th e h orizontal dimension) and then followed in the second dimen sion (say , the vertical d imension). It is w e ll kn own that the Karhun en-Loeve tra n sform (KL T) is the optimal transfor m in the sense tha t it provides the best energy co mpaction property . T o der iv e the 1D KL T , we first comp ute the covariance matr ix of image pixels in on e horizon tal or vertical segment of N pixels (say , N = 4 , 8 , 16 , 32 , etc. ) . Next, we find the eigenvectors of the covariance matrix, which are the KL T basis fun ctions. Th e KL T is also known as the pr incipal comp onent analysis (PCA). Th e KL T is a data-depen dent (or data-driven) tran sform, wh ich has higher computatio nal co mplexity than data-indepen dent tran sforms. The discrete co sine transform (DCT) [6] is a data-indepen d ent transform , which can be easily implemented by hardware for acceleration. Besides, the DCT provides a good ap prox im ation to data-depen dent KL T for image data. The 2D sepa r able DCT is widely used in today’ s image and vid e o cod ing stand ards. W e co mpare the en ergy c o mpaction prop erty of the Saab transform s with the DCT and the KL T in the context of intra- coding of the High Efficiency V ideo Cod ing (HEVC) standard [8] in this work. Our research objective is to enhan ce the DCT perfor mance by exploring th ree new directions. 1) Da ta - indepen dent versus data-d epende n t transforms Generally speaking, data-d ependen t tran sforms such as the PCA h ave better energy comp action pro p erty tha n data-indep endent tr ansforms such as the DCT . Howev er, data-dep e ndent transfo rms received little atten tion in the p ast due to their h igher co mputation al co mplexity . Howe ver , it is a recent trend in moder n video coding standards to trade highe r computatio nal complexity for a higher coding gain. Th u s, it is worthwhile to revisit data-dep e ndent transform s. 2) Sep arable versus nonsep arable transfo rms [ 7], [ 9] Most existing hig her d imensional transforms are derived as the tensor prod uct of sev e r al 1D transfo rms. Howe ver , this may n ot be the optimal choice . I t is actually e a sy to derive high dimension al tran sforms directly . Let u s use the 2D case as an example. F o r an image b lock of size N × N , we can c o ncatenate N pixels in N rows into on e long vector of leng th N 2 and compu te the covariance matr ix for such random vectors acco rdingly . The eigenvectors of the covariance matrix defin e a set of 2D n onseparab le tra n sform kern els. W e would like to check wh ether a 2D non separable transform is better than its co rrespond ing 1D sepa r able transfo rm in energy compactio n . 3) On e-stage versus mu lti-stage transfo rms By factor izing N into the product of two integers, i.e. , N = N 1 × N 2 , we ca n cond uct two-stage PCA. The first stage PCA is applied to a segment of N 1 pixels. There are N 2 segments in total. W e obtain N 1 transform coefficients for each segment. In th e secon d stage, we condu c t the PCA on a d ata array of dimen sio n N 1 × N 2 , where N 1 and N 2 indicate the n umber s of f requency and spatial componen ts. The o utput is still of d imension N = N 1 × N 2 . On e example of multi-stage PCA is the Saab transform pr oposed b y Kuo et al. in [1]. The main feature o f the Saab transfo rm is to add a sufficiently large constant to all ou tput elem ents fro m the p r evious transform stage so that all inpu t elemen ts to the next stage PCA are non-n egati ve. This is needed to a void the sign conf usion problem. There is little compa r ison study between one - stage and multi-stage PCA in the literature [2]. Here, we would like to see whether the Saab transfor m ( i.e. , multi-stage PCA) h as a b etter energy co mpaction p r operty than one-stage PCA. W e cond uct extensive experim ental results to dem onstrate that the Saab transform outperfo rms both the DCT and the PCA in term s of energy comp action efficiency . This makes it an attractiv e candidate in fu tu re ima g e/video co ding stand ards. The rest of this paper is organized as f o llows. Backgrou nd is r eviewed in Sec. II. W e examine the ene rgy co m paction proper ty of the DCT , the PCA and the Saab transform on different sizes of intr a-predicted residual blocks in HEVC in Sec. III. T h e basis fun ctions of the Saab transfor m are visualized in Sec. IV. Con c lu ding remarks are given in Sec. V. I I . B A C K G RO U N D R E V I E W T ran sform energy com p action means th e capability of a transform to red istribute signa l energy into a smaller number of transform coeffi c ien ts. Among state-of - the-art separable tr ans- forms, the DCT is the mo st widely used in the com p ression field, includin g the JPEG im age coding stan dard a nd MPEG- 1, MPEG-2, H.264/A VC an d HEVC video coding standards. For examp le, in the latest HEVC coding standard, th e DCT is applied to bo th intra an d inter block residuals of size N × N , where N = 4 , 8 , 1 6 an d 32 . It is followed by qu antization and entropy co ding. Th e kerne l fu nctions o f th e 2 D DCT are in form of f ( m, n ) = 2 N N − 1 P p =0 N − 1 P q =0 Λ( p )Λ( q )cos( (2 p +1) πm 2 N ) cos( (2 q +1) π n 2 N ) , (1) where m, n = 0 , · · · , N − 1 and Λ( ξ ) = √ 2 − 1 if ξ = 0 and 1 , otherwise. T o consider de p endency of row an d colu mn elements of a picture [7], on e ca n arrange pixel samples in an image blo ck of size N × N in lexicographic ord er; nam ely , x = [ x 00 , x 01 , ... , x 0 ,N − 1 , x 10 , x 11 , ..., x 1 ,N − 1 , ... , x N − 1 , 0 , ... , x N − 1 , N − 1 ] T . (2) Similarly , we ca n exp r ess a transf o rm kernel as a = [ a 00 , a 01 , ... , a 0 ,N − 1 , a 10 , a 11 , ..., a 1 ,N − 1 , ... , a N − 1 , 0 , ... , a N − 1 , N − 1 ] T . (3) One can con duct the PCA on rando m vectors as defined by Eq. (2) and choose the p rincipal components as the kernels in Eq. (3). Pixels in im a ges h av e a decaying correlation proper ty . The correlation betwe e n local pixels is stronger and the c orrelation becomes weaker as their distance becomes larger . T o exploit this proper ty , K uo et a l. [1] cond ucted a subspace affine transform in a local w in dow to get a local spectral vector . The input space is first decom p osed into th e DC (d irect c u rrent) subspace an d the AC (alternate c u rrent) sub sp ace in the Saab transform . The A C subspa c e is for med by elemen ts x AC = x − ( a T 0 x + b 0 ) 1 , (4) where 1 = c / || c || , and c = (1 , 1 , · · · , 1 , 1) is the constant unit vector , in each stage of th e Saab transform . The block Saab transfor m is given by [ 1] y k = N 2 − 1 P n =0 a k,n x n + b k = a T k x + b k k = 0 , 1 , ..., N 2 − 1 , (5) where a 0 is the DC filter and a k , k = 1 , ..., N 2 − 1 are the A C filters. The PCA is ado pted to compute the A C filters in the A C su b space. The bias term b k , k = 0 , 1 , ..., N 2 − 1 is selected to be a suf ficien tly large positive n umber to ensur e that x AC is non -negative when it serves as the input to the Saab transfor m in the next stage. W e would like to emph asize the main d ifferences between the KL T and the Saab transfo rm below . • T he KL T does not de c ompose signals into DC and A C c o mpone nts. It removes the ensemble mean and then compute the eigen-vector s of th e covariance matrix of mean-rem oved signals. The Saab transfo rm h as one default DC filter . Then, we co nduct the PCA on DC- removed signals. • T he in p ut to the KL T can be positive and negative values while the input to any stage in the Saab transfo rm should always be non- negativ e. The Saab tran sform propo sed b y Kuo et al. [1] is a da ta- driven (PCA-based ) , mu lti-stage, and nonsepar able tra n sform. It meets all three criteria stated in Sec. I. T he Saab tran sform is motiv ated by the analysis of n onlinear acti vation of con - volutional neu ral n etworks (CNNs) in [3], [4] as well as the subspace app roximation interpretation of convolutional filters in [ 5]. W e will focus on the energy comp a c tion prope rty of the 2 D Saab image transform in this preliminary study and show that it offers better e nergy com paction capability than the DCT and the KL T . Th us, it is an attractiv e im age transfo rm candidate for image and video compression. T o make ou r stud y as close to the real world cod ing en v ironmen t as po ssible, we study the energy comp a ction capability of se vera l transforms applied to block residuals obtained b y intra p rediction in the HEVC test mod el version 16.9 under th e all intra configuratio n in the next section. W e co nsider no n-overlapping blocks with the following settings. • b lock size 4 × 4 For th e one-stage transfor m, we map 16 p ixels in o ne block to one direct current (DC) coefficient and 15 alternating current (A C) co efficients. For the two-stage transform , we fir st m ap o ne sub block o f size 2 × 2 to one DC and 3 AC c o efficients. After wards, we map a spatial-spectral cu boid, wh ich h as a spatial dime n sion of 2 × 2 and a spectral dimension of 4 , to a spectral vector of dim ension 16 . Again, it has on e DC an d 1 5 A C coefficients. • b lock size 8 × 8 For th e one-stage transfor m, we map 64 p ixels in o ne block to one DC coefficient and 63 A C coe fficients. For the two-stage transform, we con sider two cases. For the first case, we first m ap one subblock of size 2 × 2 to one DC and 3 A C co efficients. After that, we map a spatial-spectral cub o id, which has a spatial dimension of 4 × 4 a nd a spectr a l dimension of 4 , to a spectral vector of d im ension 64. F o r the second case, we first map on e subblock of size 4 × 4 to one DC and 15 A C coefficients. Afterwards, we map a spatial-spectra l cuboid, which h as a spatial dimension of 2 × 2 and a spectral dimen sio n of 16 , to a spectr al vector of dimension 64. In both of the cases, it has one DC an d 63 AC coefficients. • b lock size 16 × 16 For the on e-stage transform , we map 256 p ixels in one block to one DC coefficient an d 25 5 A C coefficients. For the two-stage transform, we first map one subblo ck of size 4 × 4 to one DC and 15 A C co efficients. Af terwards, we map a spatial-spectral cuboid, which has a spatial dimension of 4 × 4 and a spectral dimension of 16 , to a spectral vector of dime nsion 256, which contains one DC and 255 A C coefficients. I I I . E N E R G Y C O M PAC T I O N C O M PA R I S O N O F I M AG E T R A N S F O R M S W e com p are the energy compac tio n pr operties of the DCT , the KL T and th e one-stage and two-stage Saab transf o rms in this section. First, we describe th e energy compa c tion measure and elabor ate on how to collect blo ck residuals from the HE V C encoder and obtain the Saab transform kernels accordin g ly in Sec. III-A. Th en, we comp are the energy compactio n proper ty of different tran sforms applied to intra- predicted block residu als of various sizes and resolu tions in HEVC in Sec. III-B. A. Ener gy Comp action Mea sur e and Sa mple Number S elec- tion The Saab transform kernels ar e compute d from the covari- ance matr ix, which will conver g e statistically as the numb e r of samples increases. W e need to d e termine the numbe r of samples requ ired by the cov arian ce matrix computation . A covariance matrix is said to co n verge if the Frobeniu s-norm difference of two cov ar iance matrices sampled by M and M ′ samples ( M ≈ M ′ ) beco mes suf ficiently sma ll, e.g. , less than ǫ = 1 . 5 × 10 − 4 . An examp le of th e relationship between the covariance matrix difference compu tation and the number of samples is shown in Fig. 1 , whe r e the y-axis is the Frob enius-no r m difference of two covariance matrices expressed in the natural log scale an d the x-ax is indica tes the sample number s. This plot is o btained u sing th e 8 × 8 luminan ce (Y) residual blocks for sequence “BasketballDriv e” of frame resolution 832 × 4 80 , encoded b y HM version 16.9 un d er all intra configuration with f our quan tization param eter (QP) values ( i.e. , 22, 27, 32 and 37). T o comp u te the Saab tran sform kernels (or the KL T eigenv ec to rs), we see fr om the figur e that it is sufficient to use around 60K block s for the covariance matrix to conv erge as Frob enius-nor m d ifference of two covariance m a trices is to be less than ǫ = 1 . 5 × 10 − 4 . W e ad opt the same pr ocess 5 . 0 1 5 . 0 2 5 . 0 3 5 . 0 4 5 . 0 5 5 . 0 6 5 . 0 7 5 . 0 8 5 . 0 9 5 . 0 Nu m b e r o f 8 x 8 b l o c ks ( K ) − 1 0 −9 −8 −7 −6 −5 −4 −3 l o g ( F r o b e n i u ( - n o r m o f c o v a ri a n c e m a tr i x d i ffe r e n c e ) S a a b T r a n sfo r m [ 8 x 8 ] S a a b T r a n sfo r m [ 2 x 2 , 4 x 4 ] S a a b T r a n sfo r m [ 4 x 4 , 2 x 2 ] PC A [ 8 x 8 ] Fig. 1. Determinat ion of the sample number required for Saab transform kernel computat ion for the luminance (Y) bloc k of size 8 × 8 . in der i v ing Saab tran sform kernels and KL T eigenv ecto rs for block sizes with different resolution s. By ene rgy compaction , we refer to th e cap ability of a transform to redistribute the signal energy into a small num ber of tran sform coefficients. For a block o f d imension N × N , we obtain N 2 transform coe fficients. For th e DCT and the Saab transform , th e first one is th e DC coefficient w h ile the remaining on es are the AC coefficients. Althoug h th e KL T does not d ecompose signals into the DC and AC sub spaces, there is an equ i valent concept; namely , its ensemble mean compon ent. The KL T subtracts the ensemble mean fro m all signals and th e n compute the princ ipal vectors on the mean- removed sig n al subspace. It is not practical to compute th e ensemble mean in image and vide o coding so that we use the spatial mean to estimate the ensemb le mean under the ergodic assumption. By following the ab ove cond ition, we show the av er aged DC energy ( k = 0 ), the A C energy ( 1 < = k < = 15 ) and the total ene rgy ( 0 < = k < = 1 5 ) for 100 lumin a nce (Y) block residuals of size 4 × 4 in T ab le I, where the comp onent k = 0 in th e KL T is the energy of the ensemble mean vector . T ABLE I A V E R A G E D D C A N D AC E N E R G Y VAL U E S F O R L U M I N A N C E ( Y ) R E S I D U A L B L O C K S O F S I Z E 4 × 4 U N D E R D I FF E R E N T T R A N S F O R M S . Energy Index (k) DCT KL T Saab Tra nsform [4 × 4] [2 × 2, 2 × 2] DC 0 122.35 150.29 122.35 49.53 A C 1 ∼ 15 155.56 127.02 155.19 228 . 20 T otal 0 ∼ 15 277.90 277.31 277.54 277 . 73 Although there are small variations in th e total en ergy values, the difference becomes smaller as the sample size becomes larger . T heoretically , the total energy befor e and after all o rthono rmal transform s sho uld be the same. Sin ce the DCT and the o ne-stage Saab transform comp u te the DC c ompon ents of block s in th e same ma n ner, they have the same averaged DC values. Th e KL T h as the hig h est en ergy for k = 0 . Howev e r , their d ifferences become smaller as the numb er of residual block samples in creases as shown in Fig. 2. A sy mptotically , they all conver g e to zero since we e xpect the residual blo c ks should be av er a g ed ou t in th e lo n g run. 0 2 5 0 5 0 0 7 5 0 1 0 0 0 1 2 5 0 1 5 0 0 1 7 5 0 2 0 0 0 Nu mb e r o f b l o c k r e i d u a l − 3 0 0 − 2 0 0 − 1 0 0 0 1 0 0 Av e r a g e d e n e r g y o f c o e ffi c i e n t c 0 DC T S a a b T r a n fo r m [ 4 x 4 ] S a a b T r a n fo r m [ 2 x 2 , 2 x 2 ] PC A Fig. 2. Compari son of a veraged energy of the coef ficient inde xed k = 0 of DCT , KL T , the one-stage and the two-stage Saab transforms as a function of the number of residual blocks. Interestingly , the two-stage Saab transfor m has th e lowest DC energy among the four in T ab le I. At the second -stage Saab transform , its DC com putation in volves the sum of a cuboid of four spatial dimensions and f our spectral d imensions. Only the lowest spectra l dimen sion of the four spatial locations contribute significant energy values. Thus, after a verag ing, its DC value drops. Since the DC compo n ent h as no discrimin ant power in imag e classification , the m ulti-stage Saab transform is p r eferred for pattern reco gnition and computer vision appli- cations. In the context of im age and v ideo coding , DC and A C compon ents are encoded separ ately . W e expect the DC coding cost is the lowest for the two-stage Saab transform. When the n u mber of block sam ples in crease, the ensemble mean of the KL T will conver g e to the DC value. As a result, the KL T , the DCT an d the one-stage Saab transform will have the same value for k = 0 . The A C energy co m paction is the only determin ing factor for the total energy co mpaction . In contrast, the DC co mponen t o f the two-stage Saab transfo rm is significantly smaller . The larger range of AC energy is good for recognition. Ho w ever , it is still not clear wheth er this helps or hurts the overall RD gain. It d emands furthe r study . If w e show both DC an d AC in one p lot, we cann ot see the excellen t A C en ergy com paction o f the two-stage Saab tr ansform clearly since it is masked by its low DC value. For th is reason , we focus on the energy compa ction prope r ty of a transform of its AC coefficients only ( i.e. , K = 1 , · · · , N 2 − 1 fo r N 2 coefficients) below . Mathematically , we have E N × N K = K P k =1 c 2 k N 2 − 1 P k =1 c 2 k × 100 % , (6) where c k is the coefficient of the k th AC compone n t o f the transform . B. Ener gy Compa ction P erforman ce Co mparison W e compare the A C energy c o mpaction per forman ce of the DCT , the KL T , on e-stage and two-stage Saab tran sforms. W e will discu ss th e lumin a nce (Y) block re siduals first and , then, the chrom inance red (Cr) block residuals. Luminance Blocks of Size 4 × 4 . W e first examine residuals for blo c ks of size 4 × 4 . They are obtained via intra pred iction coded with QP = 2 2 and predicted as the planar mod e. The cumulative A C energy is plotted as a function of first K AC coefficients in Fig. 3 (a). The curves in dicate the mean v a lu es of four different transfo r ms. W e see that the DCT , the KL T and the one-stage Saab transform have similar AC energy compactio n property while the two-stage Saab tran sform out- perfor ms all of them by a significant margin. The advantage of two-stage Saab transform o n the cu m ulative A C energy is demonstra te d via sequences “FourPeople”, “BasketballDriv e” and “PeopleOnStreet” of resolution s 1280 × 720 , 19 20 × 1080 and 2560 × 1600 in Figs. 3 ( b)-(d) . Luminance Blocks of Size 8 × 8 . W e examine lumin ance (Y) block residuals of size 8 × 8 fo r f our v ideo sequence s with the intra pred icted planar mode; namely , “BasketballDrill”, “FourPeople”, “BasketballDriv e” and “Peo p leOnStreet”. T he A C cumulative en ergy plots in Fig s. 4(a)-(d). W e have two observations. First, th e two-stage Saab transf o rms have better A C energy com paction pr operty than the DCT , the KL T an d the on e-stage Saab transform. T wo ca ses of the two-stage Saab transform a r e c ompared : 1) 2 × 2 spatial blocks followed b y 4 × 4 spatial b locks an d 2) 4 × 4 spatial blocks followed by 2 × 2 spatial block s. Case (2) is slightly better than case (1). Luminance Blocks of Size 16 × 16 . W e plo t the AC energy compactio n of lu minance (Y) b lock resid u als o f size 16 × 16 with the intra p redicted planar mode f or four video sequences of different resolution s in Figs. 5(a)-(d). T h e tw o -stage Saab transform with 4 × 4 spatial blo cks followed by 4 × 4 spatial blocks has the best A C en ergy compaction prop erty am ong all benchm a rking cases. Chrominance Blocks of Sizes 8 × 8 and 1 6 × 16 . The A C energy co mpaction p roperties for residuals of intra predicted chromin ance red (Cr) blocks for seq uence “BasketballDri ve” are co mpared in Figs. 6(a)( b). The differences between dif- ferent tran sfo rms are smaller for chromin ance red (Cr) b lock residuals. I V . V I S U A L I Z A T I O N O F T R A N S F O R M B A S I S F U N C T I O N S W e can gain add itional insights into image tran sforms by visualizing th eir basis fun ctions (or transform kernels). T o obtain the on e-stage or the two-stage Saab transform basis function s, we set o ne and only one A C spectral compo nent in the last stage to unity while setting oth er A C spectral compon ents to zero. Afterwards, we perfo rm the in verse on e- stage o r two-stage Saab transform from th e spectr al do main back to the spatial domain. Finally , we normalize the gray lev el of each pixel to the range between 0 and 255 using a linear scaling operation followed by a shifting operation . Luminance Blocks o f Size 4 × 4 . W e compare the basis function s of the DCT , the on e-stage Saab transfor m and the 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [4 x 4 ] S a a b T r a n sfo r m [2 x 2 , 2 x 2 ] PC A [4 x 4 ] (a) “Basket ballDrill” 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 Nu m b e r o f AC c o e ffi c i e n t s 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 C u m u l a ti v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [ 4 x 4 ] S a a b T r a n sfo r m [ 2 x 2 ,2 x 2 ] PC A[4 x 4 ] (b) “FourPe ople” 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u mu l a t i v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [4 x 4 ] S a a b T r a n sfo r m [2 x 2 , 2 x 2 ] PC A [4 x 4 ] (c) “Basket ballDri ve” 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 Nu m b e r o f AC c o e ffi c i e n t s 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 C u mu l a t i v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [ 4 x 4 ] S a a b T r a n sfo r m [ 2 x 2 ,2 x 2 ] PC A[4 x 4 ] (d) “PeopleOnStre et” Fig. 3. The cumulati ve AC energy plot for luminance (Y) block residuals of size 4 × 4 for four video sequences: (a)“Bask etballDri ve” of resolution 832 × 480 , (b)“Fou rPeople” of resolution 1280 × 720 , (c)“Basket ballDri ve” of resolution 1920 × 1080 , and (d)“PeopleOnStre et” of resoluti on 2560 × 1600 . two-stage Saab transform w ith the planar m ode in Fig. 7. Since the DCT is a separable transform, we show the transform basis func tions in form of a 2D array in Fig. 7(a), where the upper left co r ner is the DC compone n t while the other 15 are A C compone n ts. W e see that separability of transfor m kernels imposes se vere constraints on th e kernel form. Since the Saab transform is a non sep arable o ne, their transform kernels for DC is followed by AC kernels, wh ere A C kernels are ordered from the largest to the smallest energy perc e ntages, in two rows ( i.e. , from le f t to r ight a n d then from to p to bottom). The basis function of the one-stage Saab tr ansform are sho wn in Fig. 7 (b). The first A C basis is in b owl fo r m, the secon d and the third A C basis fu n ctions are tilted plan es of 135 an d 45 degrees, respectively , the fourth one is in saddle form an d the fifth one is in well form . These patterns are more likely to happen . The remaining basis functions are less frequently seen. Finally , we sho w the basis fu nction o f the two-stage Saab transfor m Fig . 7(c). T he first AC of th e two-stage Saab transform is in bowl form but rotated by 45 degree. The most interesting observation is the last thr ee A C componen ts. The two-stage Saab transf o rm can includ e them in the basis function set. This is th e major difference be tween the one- stage and the two-stage Saab tran sforms. Luminance Blocks of Size 8 × 8 . W e show the basis functions of th e on e -stage Saab transform for lum in ance residu al blocks of size 8 × 8 with the intra horizo ntal mode and the intra planar mo de in Figs. 8 (a) and (b), re sp ectiv ely . When a block is p redicted to be in the ho rizontal mod e , it tends to h av e textures alo ng the h orizontal direction . Th us, th e first 8 A C basis f u nctions in Fig. 8(a) all have h orizontal p a tter ns so a s to express the sig nal better . T h is is no t possible for DCT basis function s. When a b lock is pred icted to b e in the planar mod e, the basis func tio ns can be in bowl shap e, tilted planes, saddle shape, etc. . Luminance Blocks of Size 1 6 × 16 . W e show the basis function s of the two-stage Saab transform fo r luminance ( Y ) block residuals of size 1 6 × 16 with the intra horizontal mode and th e intra planar mode in Figs. 9 (a) an d (b), resp ectiv ely . W e h av e observations similar to 8 × 8 blo cks with th e intr a horizon tal mode and the intra planar mode as stud ied above. V . C O N C L U S I O N A N D F U T U R E W O R K The energy compaction pr o perty of the multi-stage non- separable data-driven Saab transform was studied on dif f e rent block r esidual sizes for in tr a p r ediction in HM version 16 .9 in this work. It was demon strated b y extensive experimental 1 8 1 5 2 2 2 9 3 6 4 3 5 0 5 7 6 4 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [8 x 8 ] S a a b T r a n sfo r m [2 x 2 , 4 x 4 ] S a a b T r a n sfo r m [4 x 4 , 2 x 2 ] PC A[ 8 x 8 ] (a) “Basket ballDrill” 1 8 1 5 2 2 2 9 3 6 4 3 5 0 5 7 6 4 Nu m b e r o f AC c o e ffi c i e n t s 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [8 x 8 ] S a a b T r a n sfo r m [2 x 2 , 4 x 4 ] S a a b T r a n sfo r m [4 x 4 , 2 x 2 ] PC A[8 x 8 ] (b) “FourPe ople” 1 8 1 5 2 2 2 9 3 6 4 3 5 0 5 7 6 4 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u mu l a t i v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [8 x 8 ] S a a b T r a n sfo r m [2 x 2 , 4 x 4 ] S a a b T r a n sfo r m [4 x 4 , 2 x 2 ] PC A[ 8 x 8 ] (c) “Basket ballDri ve” 1 8 1 5 2 2 2 9 3 6 4 3 5 0 5 7 6 4 Nu m b e r o f AC c o e ffi c i e n t s 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u mu l a t i v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [8 x 8 ] S a a b T r a n sfo r m [2 x 2 , 4 x 4 ] S a a b T r a n sfo r m [4 x 4 , 2 x 2 ] PC A[8 x 8 ] (d) “PeopleOnStre et” Fig. 4. The cumul ativ e AC ener gy plot for luminance (Y) bloc k residuals of size 8 × 8 for video sequenc es: (a)“Baske tball Drill” of resolu tion 832 × 480 , (b)“Fou rPeople” of resolution 1280 × 720 , (c)“Basket ballDri ve” of resolution 1920 × 1080 , and (d)“PeopleOnStre et” of resoluti on 2560 × 1600 . results that th e Saa b transfo rm h as be tter e n ergy compa ction capability than the widely u sed DCT and PCA. Th us, we can draw the conclusion that th e Saab transform o ffers a highly competitive solu tion to the residua l transform f or fu tu re im- age/video codin g standards. Furthermore, th e basis function s of th e Saab and DCT wer e visualize d an d compared . This helps explain the advantages of the Saa b tr a nsform over the DCT and the PCA. It is desired to extend o ur study to block residuals of inter prediction . Besides, we plan to in corpor ate th e qu antization and the entropy codin g modu les and provide a complete picture of the r ate-distortion gain of the Saab tran sform over the D CT in the HEVC video cod in g standar d in th e n ear futu re. A C K N O W L E D G M E N T This work was supported in part by Shenz hen In- ternational Collaborative Research Project under Grant GJHZ20170 3141 55404913 an d Guang d ong In te r national Sci- ence and T ech nology Collaborative Research Project und er Grant 2018A0 5050 6 063. This work was also sup ported in par t by the Nationa l Natural Science Foundation of China (No . 61772 054) and the NSFC Ke y Project (No . 61632 001). R E F E R E N C E S [1] C.-C. J. Kuo, M. Zhang, S. Li, J. Duan, and Y . Chen, “Interpretabl e con volut ional neural networks via fee dforward design, ” in Jou r nal of V isual Communic ation and Image Repre s entati on, pp.346-359, 2019. [2] Y . Su, R. Lin, and C.-C. J. Kuo, “Tree-stru ctured multi-stage princ ipal component analysis (TMPCA): Theory and applicat ions, ” Expert Sys- tems with Applicat ions 118 (2019 ): 355-364. [3] C.-C. J. Kuo, “Unde rstanding con volution al neura l networks with a mathemati cal model , ” in J ournal of V isual Communi cation and Image Repr esentation, v ol.41, pp.406-413, 2016. [4] C.-C. J. Kuo, “The CNN as a guided m ultil ayer RECOS transform [lectu re notes], ” in IEEE Signal Proc essing Ma gazine, vol.34, no.3, pp.81-89, 2017. [5] C.-C. J. Kuo, Y . Chen, “On data-dr ive n Saak transform, ” in Journal of V isual Communicatio n and Image Represen tation, vol.50, pp.237-246, 2018. [6] N. Ahmed, T . Natarajan and K.R. RA O, “Discre te Cosine Transfor m , ” IEEE T ransacti on on computers, January 1974. [7] T . Raj Natarajan and N. Ahmed, “Performa nce Evalu ation for Tran s form Coding Using a Nonsepara ble Cov ariance Model, ” in IEEE T ransacti ons on Communicati ons, vol. 26, no. 2, pp. 310-312, February 1978. [8] G. J. Sulli v an, J. Ohm, W .-J. Han, T . W iegand, “Ove rview of the high ef ficiency video codin g (HEVC) standa rd, ” in IEEE T ransaction s on Circuit s and Systems for V ideo T ec hnology , 22, pp.1649C1668, December 2012. [9] J. A. D. Aston, D. Pigoli and S. T av akoli, “T ests for separability in nonparame tric cov ariance operators of random surfa ces, ” in The Annals of Statisti cs, vol.45, no.4, pp.1431-1461, 2017. 1 1 8 3 5 5 2 6 9 8 6 1 0 3 1 2 0 1 3 7 1 5 4 1 7 1 1 8 8 2 0 5 2 2 2 2 3 9 2 5 6 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a t i v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [1 6 x 1 6 ] S a a b T r a n sfo r m [4 x 4 , 4 x 4 ] PC A[ 1 6 x 1 6 ] (a) “Basket ballDrill” 1 1 8 3 5 5 2 6 9 8 6 1 0 3 1 2 0 1 3 7 1 5 4 1 7 1 1 8 8 2 0 5 2 2 2 2 3 9 2 5 6 Nu m b e r o f AC c o e ffi c i e n t s 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a t i v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [1 6 x 1 6 ] S a a b T r a n sfo r m [4 x 4 , 4 x 4 ] PC A[1 6 x 1 6 ] (b) “FourPe ople” 1 1 8 3 5 5 2 6 9 8 6 1 0 3 1 2 0 1 3 7 1 5 4 1 7 1 1 8 8 2 0 5 2 2 2 2 3 9 2 5 6 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [1 6 x 1 6 ] S a a b T r a n sfo r m [4 x 4 , 4 x 4 ] PC A[ 1 6 x 1 6 ] (c) “Basket ballDri ve” 1 1 8 3 5 5 2 6 9 8 6 1 0 3 1 2 0 1 3 7 1 5 4 1 7 1 1 8 8 2 0 5 2 2 2 2 3 9 2 5 6 Nu m b e r o f AC c o e ffi c i e n t s 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T ( Zi g za g ) S a a b T r a n sfo r m [1 6 x 1 6 ] S a a b T r a n sfo r m [4 x 4 , 4 x 4 ] PC A[1 6 x 1 6 ] (d) “PeopleOnStre et” Fig. 5. The cumulati ve A C ener gy plot for luminance (Y) block residual s of size 16 × 16 for four video sequences: (a)“Basket ballDrill” of resolution 832 × 480 , (b)“Fou rPeople” of resolution 1280 × 720 , (c)“Basket ballDri ve” of resolution 1920 × 1080 , and (d)“PeopleOnStre et” of resoluti on 2560 × 1600 . 1 8 1 5 2 2 2 9 3 6 4 3 5 0 5 7 6 4 Nu m b e r o f A C c o e ffi c i e n ts 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T (Zi g za g ) S a a b T r a n sfo r m [8 x 8 ] S a a b T r a n sfo r m [4 x 4 , 2 x 2 ] PC A[ 8 x 8 ] (a) 8 × 8 chrominance red (Cr) block 1 1 8 3 5 5 2 6 9 8 6 1 0 3 1 2 0 1 3 7 1 5 4 1 7 1 1 8 8 2 0 5 2 2 2 2 3 9 2 5 6 Nu m b e r o f AC c o e ffi c i e n t s 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 C u m u l a ti v e e n e r g y DC T ( Zi g z a g ) S a a b T r a n sfo r m [ 1 6 x 1 6 ] S a a b T r a n sfo r m [ 4 x 4 , 4 x 4 ] PC A[1 6 x 1 6 ] (b) 16 × 16 chrominance red (Cr) bloc k Fig. 6. The cumulati ve AC ener gy plot for block Cr residuals unde r the intra predictio n mode for “Baske tballDri ve” of resolu tion 1920 × 1080 with block size: (a) 8 × 8 and (b) 16 × 16 . (a) DCT (b) one-stage Saab transform (c) two-stage Saab transform Fig. 7. V isualizat ion of transform basis functions for 4 × 4 blocks: (a) the DCT , (b) the one-stage Saab tra nsform, and (c) the two-st age Saab transfo rm . (a) intra horizontal (b) intra planar Fig. 8. Vi sualization of basis functions of the one-sta ge Saab transform for 8 × 8 residual blocks wit h (a) the intra horizo ntal mode and (b) the intra planar mode. (a) intra horizontal (b) intra planar Fig. 9. V isualiz ation of the top 80 basis function s of the two -stage Saab transfo rm for 16 × 16 luminance residual blocks with (a) the intra horizont al and (b) the intra planar modes.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment