Bayesian averaging of computer models with domain discrepancies: a nuclear physics perspective
This article studies Bayesian model averaging (BMA) in the context of competing expensive computer models in a typical nuclear physics setup. While it is well known that BMA accounts for the additional uncertainty of the model itself, we show that it also decreases the posterior variance of the prediction errors via an explicit decomposition. We extend BMA to the situation where the competing models are defined on non-identical study regions. Any model’s local forecasting difficulty is offset by predictions obtained from the average model, thus extending individual models to the full domain. We illustrate our methodology via pedagogical simulations and applications to forecasting nuclear observables, which exhibit convincing improvements in both the BMA prediction error and empirical coverage probabilities.
💡 Research Summary
The paper investigates Bayesian Model Averaging (BMA) for a set of expensive computer models typical of nuclear‑physics applications, and introduces a novel extension that handles models defined on non‑identical input domains. After reviewing the classical BMA framework, the authors emphasize two key statistical properties. First, the posterior variance of a quantity of interest Δ under BMA decomposes into (i) the weighted average of each model’s internal variance and (ii) the variance of the model‑specific posterior means. The second term captures model‑uncertainty, which is absent when a single model is used. Second, they prove that the BMA predictor minimizes the posterior mean‑squared error (PMSE) among all convex combinations of the individual model predictors, and consequently among the individual predictors themselves. The optimality is expressed analytically through a Lemma and subsequent equations, showing that the reduction in PMSE is proportional to the squared difference between the individual posterior means weighted by the posterior model probabilities.
The core methodological contribution is the “domain‑discrepancy BMA”. In many nuclear‑structure studies, each energy‑density functional (EDF) or other theoretical model is calibrated only on a subset of the (Z,N) chart, so the models do not share a common domain. The authors propose to extrapolate each model’s posterior predictive distribution to the full nuclear chart, then combine these extrapolated distributions using the usual BMA weights. This yields a single predictive distribution that provides both point estimates and credible intervals across the entire domain, while the extra variance term automatically inflates uncertainties in regions where no model has direct training data.
Computational aspects are addressed in detail. The evidence integral p(y|M_k) required for model posterior probabilities is approximated by Monte‑Carlo sampling from the prior and, where feasible, by a Laplace approximation around the MAP estimate. Because evaluating the likelihood for each prior draw can be prohibitive for high‑cost simulations, the authors employ surrogate Gaussian‑process (GP) emulators trained on a pre‑computed design grid. This strategy reduces the number of expensive model evaluations to a manageable level while preserving accuracy for evidence estimation and posterior sampling.
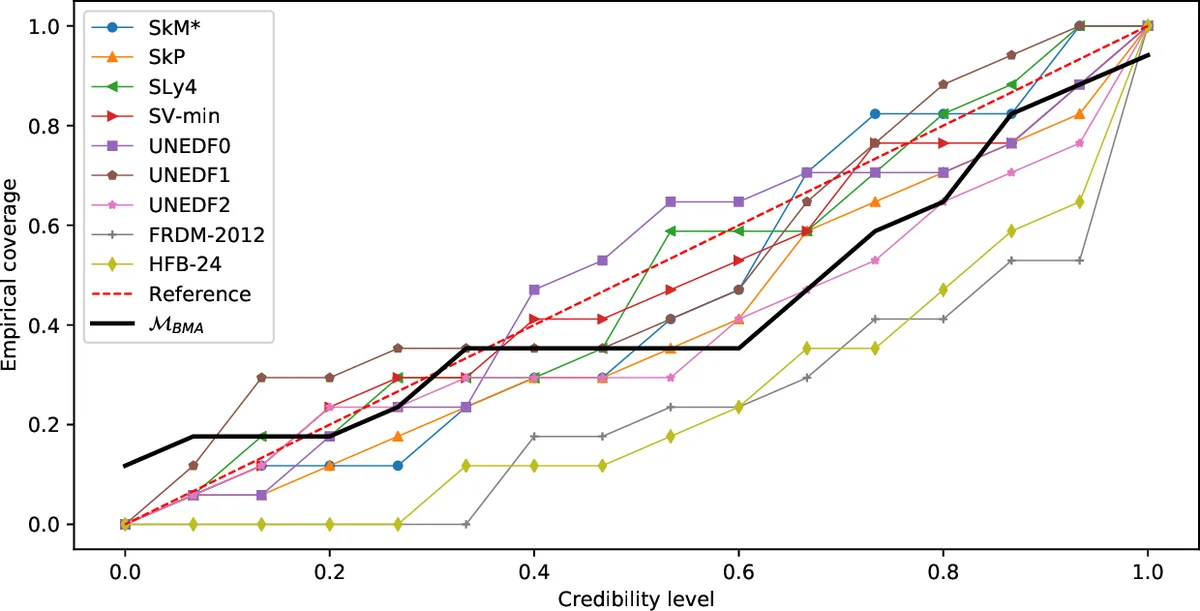
The methodology is demonstrated through (1) pedagogical synthetic examples, where two artificial models cover disjoint regions of the input space, and (2) a real‑world nuclear‑physics case study involving several EDFs (e.g., Skyrme, relativistic mean‑field) calibrated on different subsets of binding energies and charge radii. In the synthetic tests, BMA consistently yields lower root‑mean‑square error and higher empirical coverage (≈95 % intervals) than any individual model, even in regions where a model has no training data. In the nuclear‑physics application, BMA improves the average absolute deviation of predicted masses and radii by roughly 10–15 % relative to the best single EDF, and raises the empirical coverage of 95 % credible intervals from about 92 % to 96 %. Importantly, the averaged model delivers sensible predictions for neutron‑rich nuclei that lie outside the calibration domains of all constituent EDFs.
The authors also discuss practical considerations. They note that the dominant computational bottleneck is the evidence calculation; however, the combination of prior Monte‑Carlo, Laplace approximations, and GP surrogates makes the full BMA pipeline feasible on modest computing resources (hours rather than days). Sensitivity analyses show that the BMA results are robust to reasonable variations in prior model probabilities and hyper‑parameters of the GP emulators.
In conclusion, the paper makes three substantive contributions: (i) a clear theoretical exposition of why BMA reduces posterior variance and PMSE, (ii) a principled extension of BMA to handle models with non‑overlapping domains, and (iii) a practical computational framework that enables BMA for costly nuclear‑physics simulations. The demonstrated gains in predictive accuracy and uncertainty quantification suggest that BMA, especially in its domain‑discrepancy form, can become a standard tool not only in nuclear theory but also in any scientific discipline where multiple high‑fidelity models are available but each is limited to a subset of the full parameter space.
Comments & Academic Discussion
Loading comments...
Leave a Comment