A General Data Renewal Model for Prediction Algorithms in Industrial Data Analytics
In industrial data analytics, one of the fundamental problems is to utilize the temporal correlation of the industrial data to make timely predictions in the production process, such as fault prediction and yield prediction. However, the traditional …
Authors: Hongzhi Wang, Yijie Yang, Yang Song
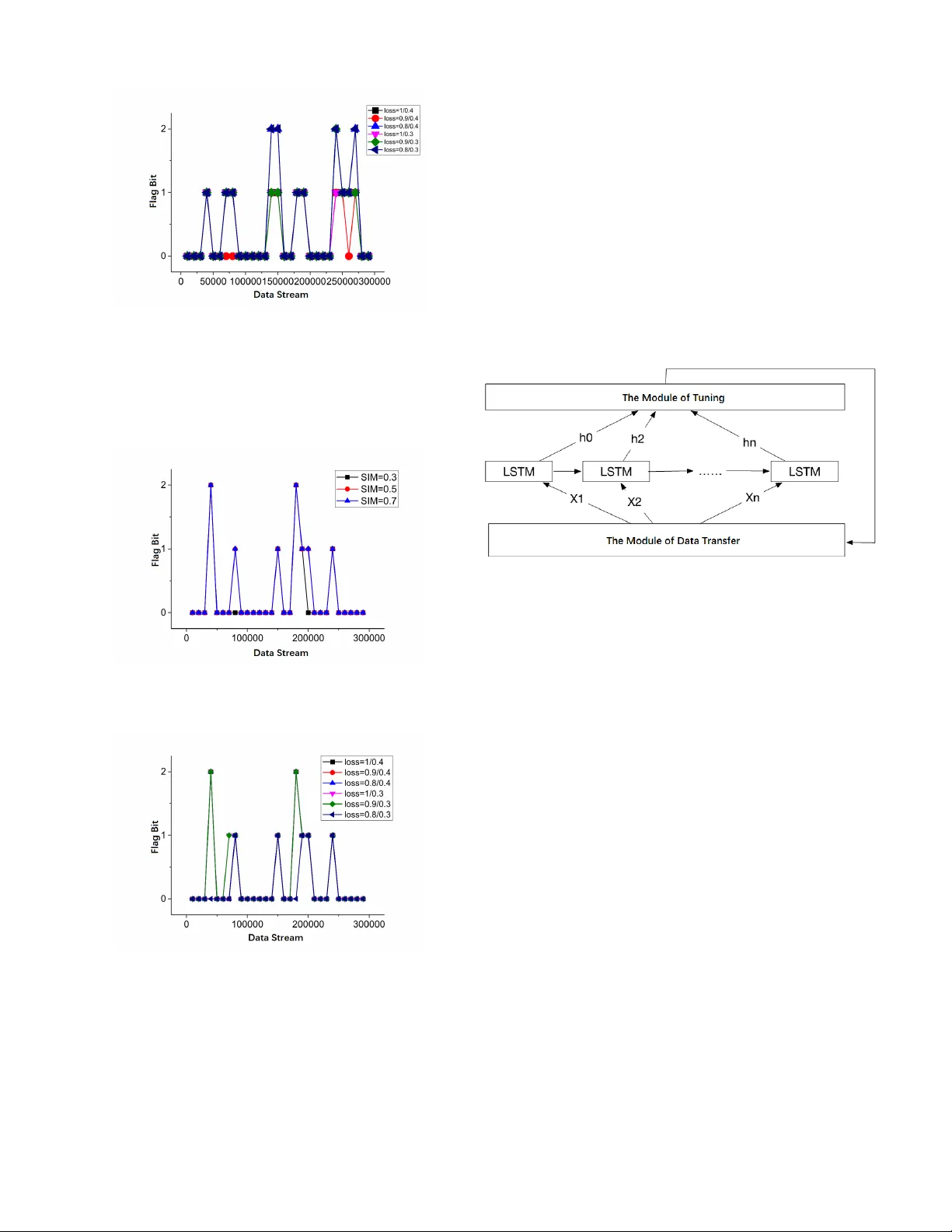
1 A General Data Rene wal Model for Prediction Algorithms in Industrial Data Analytics Hongzhi W ang, Member , IEEE, Y ijie Y ang, and Y ang Song Abstract —In industrial data analytics, one of the fundamental problems is to utilize the temporal correlation of the industrial data to make timely predictions in the pr oduction process, such as fault pr ediction and yield pr ediction. Howe ver , the traditional prediction models are fixed while the conditions of the machines change over time, thus making the errors of predictions increase with the lapse of time. In this paper , we propose a general data renewal model to deal with it. Combined with the similarity function and the loss function, it estimates the time of updating the existing prediction model, then updates it according to the evaluation function iteratively and adaptively . W e ha ve applied the data r enewal model to two prediction algorithms. The experiments demonstrate that the data r enewal model can effectively identify the changes of data, update and optimize the prediction model so as to impr ove the accuracy of prediction. Index T erms —Machine Learning, Data Mining, T ime-series, Data Str eams I . I N T RO D U C T I O N In the industrial processes, though strict regulations and stable operating conditions are required, ev en the most so- phisticated machines cannot av oid the runtime exception [1]. Due to a lar ge number of human interactions in the industrial manufacturing process, human errors may cause abnormalities in the overall process. According to statistics, the maintenance cost of various industrial enterprises accounts for about 15%- 70% of the total production cost [2]. Therefore, ho w to conduct malfunction analysis, yield dynamic prediction and make timely fault detection for industrial processes to ensure the ef fectiveness and ef ficiency of the production process hav e receiv ed much attention in both academia and industry . Because of the numerous sensors with high sampling fre- quency in industrial processes, the devices will accumulate large amounts of data in a short time interval. As time goes on, some parameters related to production prediction and fault detection are imperati ve to change synchronously due to the equipment aging, abrasion and so on. Howe ver , the currently known prediction algorithms in industry , mainly including artificial intelligence and data-dri ven Statistical methods[3] [4] , are all constrained by time, up to a point. In other words, these prediction models can only accurately reflect the state of the industrial equipment in a certain period, whereas the inaccuracy increases o ver time. Additionally , in the problems of malfunction diagnoses and predictions based on transfer learning[14][15], though there are v arious kinds of faults in industrial processes, the Hongzhi W ang, Y ijie Y ang and Y ang Song are with the Department of Computer Science and T echnology , Harbin Institute of T echnology , Harbin, Heilongjiang, 150000 China e-mail: wangzh@hit.edu.cn. similarities of them can be utilized to conduct the transfer learning of the malfunctions, so as to predict the faults efficieintly and effecti vely . W e will giv e an outline of a transfer-learning-based fault prediction algorithm in Section 3. Howe ver , in our experiments, we find that the transferability of two dif ferent types of equipment in the same technological process considerably decreased if the data used in the process are at dif ferent periods. It sho ws that the crucial precondition for the application of transfer learning to industrial time-series data is that the data of the tw o different types of industrial equipment in the same production process should also be in the same period. Therefore, the prediction model is required to recognize the changes of industrial data stream and update the parameters automatically with the lapse of time. This paper focuses on the automatic update and replacement of the model based on industrial time-series data, which are featured with periodicity and comple x correlation. T o address these problems, this paper proposes a general data rene wal model based on lifelong machine learning[16][17][18]. It can be applied to some prediction algorithms to impro ve their accuracy . The main idea of the model is to assess the freshness of the industrial time-series data according to the existing prediction model and the new data stream. Then it can decide whether to in valid the old model and retrain a ne w one according to the similarity function and the loss function. In our pre vious work, we attempted to establish a time- series forecasting model system which could solve the prob- lems of both discrete and continuous variable prediction. W e hav e proposed a time-series yield prediction algorithm and a transfer-learning-based fault prediction algorithm, which will be roughly described in Section 3. Ho we ver , their practical effects were limited due to the reasons mentioned abov e. Therefore, in our experiments, we will apply the data renew al model to them and testify its ef fecti veness by making a comparison between the learning models with and without a data renew al model. This paper makes follo wing contributions. • W e propose a general data renewal model combined with the similarity function and the loss function. It can be applied to some industrial prediction algorithms to find the regulations of renewing the prediction model based on industrial time-series, so as to update the prediction model opportunely and iterativ ely . • Through self-learning and automatic updating, the pre- diction algorithms applied with the data renewal model can be improved over time, thus reducing human in- terventions and perfecting the algorithm performance in industrial processes. 2 • W e ev aluate the proposed model on three datasets and two prediction algorithms in industry . The results demonstrate that the model can be updated ef fecti vely according to the industrial data stream, and the accurac y of the predictions can be increased by at least 33%, which is a significant improv ement. The rest of the paper is or ganized as follo ws. In Section 2, firstly , we define the problem and our target, then describe the model and approach in detail. And we apply our data renewal model to two prediction algorithms. The tuning process, brief introduction of the two prediction algorithms and the experi- mental results are presented in Section 3. Section 4 makes a summary of the paper; meanwhile, it explains the future work. I I . P R E D I C T I O N A L G O R I T H M S C O M B I N E D W I T H D A TA R E N E W A L M O D E L A. T ask Definition and Overview In a prediction algorithm, we build a renewal model based on the data, then continuously update the prediction model according to the data similarity and the loss function. In practical problems, the inputs are often time series. Giv en a sequence of data points measured in a fixed time interval, X t = [ x t 1 x t 2 · · · x tm ] ∈ R t × m , and the existing model M . The output is the updated prediction model M 0 . The problem is formalized as follo ws. Given the data of a piece of industrial equipment E acquired from time 0 to time t , for model M , there exists a function f ( · ) , such that M ( X t , f ( · )) = Y t (1) In the meantime, E keeps on running. Given the data of E from time t to time t + n ( n > 0) , X t + n = [ x 1 x 2 · · · x m ] ∈ R n × m , for model M 0 , there exists a function f 0 ( · ) , such that M 0 ( X t + n , f 0 ( · )) = Y t + n (2) If f ( · ) = f 0 ( · ) , the model does not need to update. If f ( · ) 6 = f 0 ( · ) , the model needs further analysis to determine whether it should be updated. If it is, then let M = M 0 . In practical industrial problems, X are time series. There- fore, we need to choose the model according to their features. Since the model often has a complicated mechanism and the correlation may be nonlinear , f is difficult to find an analytical solution. T o achiev e better performance, we often use neural network algorithms, such as BP Neural Network[24], Con vo- lutional Neural Network[25] and Recurrent Neural Network (LSTM)[26] In most cases, the loss function is enough to measure and determine whether a model needs to update. Ho wever , since the industrial data are often discrete, continuously collected and transferred by the sensors, the traditional mechanism model is ineffecti ve. As a result, the model should be based on data instead of mechanism. For accurate estimation, the similarity function and the loss function are combined to estimate the time of updating the existing model automatically , then the model is retrained on the calculated time iteratively . Fig. 1. The Components of the Data Rene wal Model B. Data Renewal Model The primary problem of the updating algorithm is to build a data rene wal model to predict when the model ought to be updated. As sho wn in Figure 1, the model achie ves this by two considerations. One is the similar of the original data and the new data. If they are similar enough, the model does not hav e to be updated or retrained. It is measure by the similarity computation, which will be described in Section II-B1. The other is the applicability of the existing model. If the model loses efficacy in ne w data stream, it should be updated or even retrained. It is measured by the loss function, which will be described in Section II-B2. 1) Similarity Computation: The data similarity computa- tion begins with analyzing the changed e xtent of the un- processed data in the pre vious moment with the data in the next moment. Chiefly , the data are classified into two types: the binary attribute data and the numeric data. They will be discussed in this section, respectiv ely . For the binary attrib ute data, the similarity is measured by the counting method. That is, for time series X t = [ x t 1 x t 2 · · · x tm ] ∈ R t × m and X t + n = [ x 1 x 2 · · · x m ] ∈ R n × m , assuming that X i t and X i t + n , the i -th dimension of X t and X t + n , are both binary attributes, the number of data pairs of them both belong to the first state is S 1 , while the number of data pairs are both the second state is S 2 , the total amount of data is n , then their similarity is shown as follo ws. sim ( X i t , X i t + n ) = S 1 + S 2 n (3) For a specific example, X i t = [1 0 0 0 1 0 1 1] , X i t + n = [0 0 0 1 1 1 1 1] , the 2nd and 3rd numbers of X i t and X i t + n are both 0, so S 1 = 2 , the 5th, 7th and 8th numbers of X i t and X i t + n are both 1, so S 2 = 3 , sim ( X i t , X i t + n ) = 2+3 8 = 0 . 625 . In the case of the numerical data, generally , there are two methods to measure the similarity de gree: similarity coef ficient and similarity measurement. Pearson Correlation Coefficient, 3 as sho wn in equation (4), can be used to a v oid the error of similarity measurement resulting from the severe dispersion of industrial data. It has a v alue between +1 and − 1 , where +1 is total positive linear correlation, 0 is no linear correlation, and − 1 is total negati ve linear correlation. ρ X,Y = cov ( X, Y ) σ X σ Y = E [( X − µx )( Y − µy )] σ X σ Y (4) For the data in the same set b ut dif ferent periods, they also hav e a certain de gree of similarity . In order to better measure the similarity between them, we take the absolute v alue and ignore the positi ve and negativ e correlation. In conclusion, for the purpose of achieving better performance, we adopt the similarity coef ficient method here and modify the Pearson Correlation. The new coef ficient formula is shown as follo w . sim ( X i t , X i t + n ) = ρ X i t ,X i t + n = | cov ( X i t , X i t + n ) σ X i t σ X i t + n | = | E [( X i t − µx i t )( X i t + n − µx i t + n ) σ X i t σ X i t + n | (5) W ith respect to different data vectors in the same data set, the similarity is gained by calculating the mean value of them and adjusted overall using the parameter δ , which is shown in (5). In most cases, δ i = 1 , if the data set does not contain attribute i , then δ i = 0 . sim ( X t , X t + n ) = 1 − P m i =1 δ i (1 − sim ( X i t , X i t + n ) P m i =1 δ i = P m i =1 δ i · sim ( X i t , X i t + n ) P m i =1 δ i (6) According to (3), (4) and (5), it can be concluded that the value of the similarity is in the range (0 , 1) . The higher the value is, the higher the degree of similarity should be between the two data sets. When the value of the similarity function is lower than a threshold z , the model needs to be updated. 2) Loss Function: The loss function aims to determine whether to update or abandon the old model and train a new one. In fact, the updating is to adjust the parameters in the existing model. Therefore, it is necessary to estimate the ef fect of the model, and generally it is measured by loss function. θ ∗ = ar gmin 1 N N X i =1 L ( y i , f ( x i ; θ i )) + λ Φ( θ ) (7) where L is the loss function, Φ( θ ) is the regularization term or the penalty term. As regards to specific problems, we use a more specific loss function for analysis. One of the typical problems is the updating of the industrial big data model, which mainly in volves tw o aspects, the model for continuous data such as yeild prediction, and the model for categorical attribute data such as fault prediction. According to the features of different models, we should define the corresponding loss function for estimation. For continuous data prediction, we use RMSE (Root Mean Square Error) to e valuate the loss, since it sho ws greater esti- mation results than quadratic loss function in our experiments. RM S E ( X , f ( · )) = v u u t 1 m m X i =1 ( f ( x i ) − y i ) 2 (8) For classification prediction problems, 0-1 loss function, Log loss function, Hinge loss, and perceptual loss function[27] [28] [29] are generally used to estimate the quality of the model. Here, we use the perceptual loss function: arg min w,b [ − n X i =1 y i ( w T x i + b )] (9) In the loss function, two questions should be taken into account, whether to update the existing model and whether to abolish the old one. The loss of the existing model is Lm , then the new data are collected and put into it for training, and the loss of the new model is Ln . Then the change rate of the loss is computed as follow . LC = | Ln − Lm Lm | (10) Fig. 2. The State-determining Schematic Diagram of the Loss Function Module In the formula, obviously , LC is greater than 0. The threshold v alues need to be set to determine when to update and discard the model (retrain a ne w one). So the they are set as follo ws: if LC > y , the original model will be discarded and a new model will be built through retraining. If y > LC > x , the model is updated: ne w data are added to the model for training, so the model parameters are changed. If LC < x , the original model state is retained with no update. The standards are shown in Figure 2. The thresholds will be adjusted according to the experiments. Algorithm 1 describes the procedure of the data renewal model. Line 1 analyzes the data similarity of period t 1 and period t 2 . Lines 2-11 decide whether to update the model according to the data similarity . Lines 3-9 calculate the v alue of loss function in the period t 1 and t 2 and output the flag bit according to the state-determination rules. Algorithm 1 update( data T 1 , data T 2 ) Input: The data set data T 1 in period t 1 ; The data set data T 2 in period t 2 Output: The updating flag of the model f lag 1: p ← sim ( data T 1 , data T 2 ) 2: if p < z then 3: l ← loss ( data T 1 , data T 2 ) ; 4: if l > y then 5: return 2; // Discard the model and retrain a new one 6: else if y > l and l > x then 7: return 1; // Add the new data and update the model 8: else 9: return 0; // Retain the model 10: else 11: return 0; // Retain the model 4 C. Algorithm Description The data rene wal model is based on the data similarity and the loss function. Furthermore, to control the updating frequency , the size of the ne w data should be controled. That is, the similarity will not be calculated until a certain amount of data has been accumulated. Only when the threshold of the data size is reached, will the loss function of the data be computed, and the corresponding processes of the model be performed. Algorithm 2 describes the procedure of updating according to Algorithm 1 and the algorithm flow discussed above. Lines 1-4 decide whether enough ne w data hav e been accumulated, and Lines 5-12 decide whether to update the model referring to the data renew al model in Algorithm 1. Algorithm 2 lifelong( data T 1 , data T 2 ) Input: The data set data T 1 in period t 1 ; The data set data T 2 in period t 2 ; The minimum (threshold) amount of data L ,the model M Output: The model M f 1: n ← shape ( data T 2 ) 2: if n < L then 3: return M ; 4: else 5: f lag ← update ( data T 1 , data T 2 ) ; 6: if f lag = 1 then 7: M f ← tr ain ( data T 1 , data T 2 ) ; 8: if f lag = 2 then 9: M f ← tr ain ( data T 2 ) ; 10: if f lag = 0 then 11: M f ← M ; 12: return M f ; The comple xity analysis of the algorithm is focused on the data renew al model. T ime Complexity Analysis Let the data size in the period t 1 and t 2 be N and M , respectively . The cost of similarity computation is O ( M N ) . The loss function add the data in period t 2 into the existing model and compares the ne w loss with the pre vious one. It only needs one round of calculation, so the time comple xity is O ( M ) . Therefore, the overall time complexity is O ( M N + M ) = O ( M N ) Space Complexity Analysis Let the needed space of the data in period t 1 and t 2 be N and M , respectiv ely . The similarity matrix costs O ( N M ) . O ( M ) is required to store the intermediate results calculated by the data in period t 2 to calculate its loss function. As a result, the overall spatial complexity is O ( N + 2 M + M N ) = O ( M N ) I I I . E X P E R I M E N T S A N D E V A L U A T I O N A. Experimental En vir onment and Datasets The e xperimental en vironment and datasets are shown in T able 1. Among them, the industrial boiler dataset and the generator dataset are generated by real-time production system in the Third Power Plant of Harbin. The boiler dataset includes more than 400,000 pieces of data, whose dimension are up to 70, and the main attributes in volv e time, flo w , pressure, and temperature. Moreover , the generator dataset includes more than 80,000 pieces of data, whose dimension are up to 38, and the major attributes include time, speed, power , pressure and temperature. In this section, the data rene wal model is respectiv ely applied to the time-series yield prediction algorithm and the transfer-learning-based f ault prediction algorithm to verify its effecti veness in model updating and optimization. T ABLE I T H E E X PE R I M EN TA L E N VI R ON M E NT A N D D AT A S ET S Machine Configuration 2.7GHz Intel Core i5 8GB 1867 MHz DDR3r Experimental En vironment Python 3.6.0; T ensorflow Datasets Industrial Boiler Dataset; Industrial Generator Dataset; Synthetic Industrial Generator Dataset Algorithms The T ime-series Y ield Prediction Al- gorithm; The Transfer -learning-based Fault Prediction Algorithm B. The Optimization of the Pr ediction Algorithm Based on Data Renewal Model The data rene wal model has two critical parameters, the similarity and the change rate of loss. Since the thresholds may have an impact on accuracy , we are imperativ e to test their impacts. W e first test the impact of the similarity . The goal of the similarity is to estimate the similar degree of the data at different time. The higher the value is, the more similar the data are. Therefore, the similarity threshold can neither be too low nor too high. Initially , it is set to 0.3, 0.5, and 0.7, while the loss rate threshold is set to 1/0.4. In order to observ e the changes with different thresholds more intuitively , we set the original number of tuples to 10,000. The model is assessed whether to be updated according to the flag bit for every 10,000 pieces of data added. Fig. 3. The Impact of the Similarity for Algorithm 1 As shown in Figure 3, when the similarity threshold is 0.3, the model updating frequency is low , while the model updates too often when the threshold is 0.7. T o ensure that the frequency is kept at an appropriate level, the similarity threshold is set to 0.5 in the next experiments . Then we test the impact of the change rate of loss. W e vary the rate of loss as 1/0.4, 0.9/0.4, 0.8/0.4, 1/0.3, 0.9/0.3, and 0.8/0.3. The results are sho wn in Figure 4. When the flag is 2, the model is discarded. When the flag is 1, the model is 5 Fig. 4. The Impact of the Change Rate for Algorithm 1 updated, and it is retained if the flag is 0. It is found that the discarding and updating of the model shows a more balanced frequency when the threshold is 0.9/0.3. Fig. 5. The Impact of the Similarity for Algorithm 2 Fig. 6. The Impact of the Change Rate for Algorithm 2 The similarity and the loss rate are tuned in a similar process for Algorithm 2. The experimental results are sho wn in Figures 5 and 6. W e ha ve observed that when the similarity is 0.5 and the loss rate is 0.9/0.3, the updating is more effecti ve. When the thresholds are moderate, the model can ex ecute the three actions, update, discard or retain the model in a proper and balanced frequency . From the experimental results described abo ve, after tuning the prediction algorithm based on the data renewal model, the threshold is fixed at the similarity of 0.5, and the loss rate is 0.9/0.3. The experimental results show that the algorithm does not need to be tuned frequently and the fixed parameters can also achiev e great experimental results. C. Results for the T ime-series Y ield Prediction Algorithm W e test the effecti veness of the proposed model renew al strategy on the time-series yield prediction algorithm. It’ s an LSTM algorithm based on multi-v ariable tuning. The algorithm improves the traditional LSTM algorithm and con- verts the time-series data into supervised learning sequences utilizing their periodicity , so as to improve the prediction accuracy . The LSTM algorithm based on multi-variable tuning Fig. 7. The Procedure of the T ime-series Yield Prediction Algorithm is di vided into three modules, a data transform module, an LSTM modeling module, and a tuning module. The data transform module con verts the time-series data into a super - vised learning sequence, and simultaneously searches for the variable sets which are most rele v ant and have the highest Y regression coefficient; the LSTM modeling module connects multiple LSTM perception to form an LSTM network; the tuning module adjusts the parameters according to the RMSE in each round, and returns the adjusted parameters to the data transform module for training iterati vely . Through continuous iteration, the approximate optimization solution of the algo- rithm is obtained. The algorithm process is shown in Figure 7. The following is the result of applying the data renewal model to the yield prediction algorithm based on time-series. After determining the optimal thresholds, we selected differ - ent update frequencies, 10,000, 50,000 and 100,000 pieces of data for each batch, to verify the effecti veness of the model. First, we set the data stream updating frequency to 10,000 pieces/batch. The experimental results are shown in Figure 8. The RMSE changes with the continuously updating of the data stream. During this process, the model’ s RMSE remains unchanged (the flag is 0) or decreases (the flag is 1 or 2). As time goes by and the data accumulate, the RMSE of the model constantly decreases with an irregular frequency . When the data updating frequency is 50,000 pieces/batch, the experimental results are sho wn in Figure 9. It is found that when the updating frequency of the data is reduced, the RMSE suffers dif ferent degrees of reduction, which indicates that dif ferent data update frequencies will af fect prediction accuracy . Nev ertheless, when the amount of data tend to be 6 Fig. 8. The Result at a Frequency of 10000 pieces/batch Fig. 9. The Result at a Frequency of 50000 pieces/batch consistent, ov erall, the RMSE can be reduced to a specific constant with less error . W e set the frequenc y for data updating to 100,000 pieces/batch. Let the original data be 100,000 pieces, and take the reduction degree of RMSE as its updating accuracy . As shown in T able 2, the algorithm can perform ef fective model updating in various frequencies. Moreover , the updating accuracy is up to 63.94%. T ABLE II E X PE R I M EN TA L P A R AM E T E RS O F T H E Y I E L D P R ED I C T IO N A LG O R I TH M No. Data V olume Similarity Loss Rate RMSE Accuracy 1 100000 0.34 0.592957366 30.17 - 2 100000 0.44 0.795650783 10.88 63.94% 3 100000 0.89 0.122410221 10.88 - D. Results for T ransfer-learning-based F ault Pr ediction Algo- rithm In the problems of malfunction diagnosis and predictions, though there are v arious kinds of faults, the similarities of them can be utilized to adopt the transfer learning of malfunctions, so as to predict the errors ef ficiently and ef fectiv ely . The transfer-learning-based fault prediction algorithm mainly con- sists of three modules, the time windo w module, the mapping network module, and the model transfer module. The time window module preprocesses the data and conducts similarity analysis based on the time window . The mapping network Fig. 10. The Schematic Diagram of the T ransfer Learning Based Fault Prediction Algorithm module mainly uses the step of the similar region of time- series data to transfer the data, and construct the mapping network with the con verted data. The model transfer module mainly utilizes the mapping network to transfer the trained model, which is prepared with the neural network method to construct a deep learning network. Figure 10 shows the structure of the algorithm. In the e xperiment, we suppose that there are two devices, device A with labeled data and device B with unlabeled data. The output is the fault detection model M of device B . The update of the algorithm is mainly composed of two parts. For device A , the update target is the fault prediction model. For device B , if the data change, it is the mapping network module that should be updated. Therefore, our e xperiments are also divided into tw o parts. For the prediction of de vice A , the original model is ev al- uated using the A UC (Area Under the Curv e) [30]. When the update frequency of the data is 10,000 or 50,000 pieces/batch, the prediction accuracy A UC is about 0.97. When the fre- quency is 100,000 pieces /batch, the prediction accuracy A UC is about 0.958, and the loss is less than 1%, so the model need not be updated after the initial modeling. For de vice B which gets new data, the updating process is more complicated. The mapping network module is updated first. Then the prediction model of device A through the map- ping network is trained. Finally , the prediction model of device B is analyzed. The experimental results are similar to that of the time-series yield prediction algorithm. W e set the update frequency to 10,000, 50,000 and 100,000 pieces/batch for the verification. During updating, the model’ s A UC remains unchanged (the flag is 0) or increases (the flag is 1 or 2). The experimental results with a frequency of 10,000 pieces/batch are shown in Figure 11. W ith the accumulation of data over time, the A UC of the model is continually increasing, which indicates better performance. When the data update frequenc y is 50,000 pieces/batch, the experimental results are shown in Figure 12. It is observed that the degree of updating varies with dif ferent updating frequencies. When the amount of data tends to be consistent, the values of A UC will get stable. W e set the frequency for data update to 100,000 pieces/batch, and take the A UC as its accurac y . W e observe that when the data similarity is low , there will be a more 7 Fig. 11. The Result at a Frequency of 10000 pieces/batch Fig. 12. The Result at a Frequency of 50000 pieces/batch considerable degree of updating, as the results sho wn in T able 3. It demonstrates that the data renewal model can effecti vely update the existing model with the data stream in different updating frequencies. T ABLE III E X PE R I M EN TA L R E SU LT S F O R T H E T R A NS F E R - L E A RN I N G - B A SE D F AULT P R ED I C T IO N A LG O R I TH M No. Data V olume Similarity Loss Rate A UC Accuracy 4 100000 0.33 0.874255365 0.68 - 5 100000 0.64 0.571217426 0.68 - 6 100000 0.23 0.427696411 0.91 33.82% I V . C O N C L U S I O N S A N D F U T U R E W O R K In this paper, we propose a general data renew al model to assess the industrial data stream and set the thresholds to update the prediction model adapti vely . It can by applied to some prediction algorithms to impro ve their performance. The effecti veness of the model and its significance to improving the accuracy of prediction are demonstrated by e xperiments on real-world industrial datasets and prediction algorithms. Howe ver , since it’ s a general model, the tuned parameters couldn’t be adaptiv e in any different kind of problems. So self-adaptiv e tuning may be taken into consideration in the future work. And we only apply the model to two industrial prediction algorithms in our work, the model can be examined by more algorithms. R E F E R E N C E S [1] K. McKee, G. Forbes, I. Mazhar , R. Entwistle, and I. Howard, “ A revie w of machinery diagnostics and prognostics implemented on a centrifugal pump, ” in Engineering Asset Management 2011 . Springer, 2014, pp. 593–614. [2] M. Bevilacqua and M. Braglia, “The analytic hierarchy process applied to maintenance strategy selection, ” Reliability Engineering & System Safety , v ol. 70, no. 1, pp. 71–83, 2000. [3] M. Pecht, “Prognostics and health management of electronics, ” Ency- clopedia of Structural Health Monitoring , 2009. [4] J. Sikorska, M. Hodkie wicz, and L. Ma, “Prognostic modelling options for remaining useful life estimation by industry , ” Mechanical Systems and Signal Pr ocessing , vol. 25, no. 5, pp. 1803–1836, 2011. [5] Z. Huang, Z. Xu, X. Ke, W . W ang, and Y . Sun, “Remaining useful life prediction for an adaptiv e ske w-wiener process model, ” Mechanical Systems and Signal Pr ocessing , vol. 87, pp. 294–306, 2017. [6] X. W ang, N. Balakrishnan, and B. Guo, “Residual life estimation based on a generalized wiener process with skew-normal random effects, ” Communications in Statistics-Simulation and Computation , vol. 45, no. 6, pp. 2158–2181, 2016. [7] X.-S. Si, W . W ang, C.-H. Hu, D.-H. Zhou, and M. G. Pecht, “Remain- ing useful life estimation based on a nonlinear diffusion degradation process, ” IEEE T ransactions on Reliability , vol. 61, no. 1, pp. 50–67, 2012. [8] G. Zhuang, Y . Li, and Z. Li, “F ault detection for a class of uncertain nonlinear markovian jump stochastic systems with mode-dependent time delays and sensor saturation, ” International Journal of Systems Science , vol. 47, no. 7, pp. 1514–1532, 2016. [9] J. W an, S. T ang, D. Li, S. W ang, C. Liu, H. Abbas, and A. V . V asilakos, “ A manufacturing big data solution for acti ve preventi ve maintenance, ” IEEE T ransactions on Industrial Informatics , v ol. 13, no. 4, pp. 2039– 2047, 2017. [10] R. M. Hasani, G. W ang, and R. Grosu, “ An automated auto-encoder correlation-based health-monitoring and prognostic method for machine bearings, ” arXiv preprint , 2017. [11] C. Zhang, W . Gao, S. Guo, Y . Li, and T . Y ang, “Opportunistic maintenance for wind turbines considering imperfect, reliability-based maintenance, ” Rene wable ener gy , vol. 103, pp. 606–612, 2017. [12] T . D. Batzel and D. C. Swanson, “Prognostic health management of aircraft power generators, ” IEEE T ransactions on Aerospace and Electr onic Systems , v ol. 45, no. 2, 2009. [13] J. P . Kharoufeh, S. M. Cox, and M. E. Oxley , “Reliability of manu- facturing equipment in complex environments, ” Annals of Operations Resear ch , vol. 209, no. 1, pp. 231–254, 2013. [14] M. Long, C. Y ue, J. W ang, and M. I. Jordan, “Learning transferable features with deep adaptation networks, ” 2015. [15] Z. Ran, H. T ao, L. W u, and G. Y ong, “T ransfer learning with neural networks for bearing fault diagnosis in changing working conditions, ” IEEE Access , vol. PP , no. 99, pp. 1–1, 2017. [16] Z. Chen and B. Liu, “Lifelong machine learning, ” Synthesis Lectures on Artificial Intelligence and Machine Learning , vol. 10, no. 3, pp. 1–145, 2016. [17] B. Liu, “Lifelong machine learning: a paradigm for continuous learning, ” F rontier s of Computer Science , vol. 11, no. 3, pp. 359–361, 2017. [18] D. L. Silver , Q. Y ang, and L. Li, “Lifelong machine learning systems: Beyond learning algorithms. ” in AAAI Spring Symposium: Lifelong Machine Learning , vol. 13, 2013, p. 05. [19] M.-F . Balcan, A. Blum, and S. V empala, “Ef ficient representations for lifelong learning and autoencoding, ” in Confer ence on Learning Theory , 2015, pp. 191–210. [20] N. R. V erstae vel, J. Boes, J. Nigon, D. d’Amico, and M.-P . Gleizes, “Lifelong machine learning with adaptive multi-agent systems, ” 2017. [21] D. L. Silver and R. E. Mercer, “The parallel transfer of task kno wledge using dynamic learning rates based on a measure of relatedness, ” in Learning to learn . Springer, 1996, pp. 213–233. [22] S. P . Singh, “T ransfer of learning by composing solutions of elemental sequential tasks, ” Machine Learning , vol. 8, no. 3-4, pp. 323–339, 1992. [23] D. L. Silver and R. E. Mercer, “The task rehearsal method of life- long learning: Overcoming impoverished data, ” in Confer ence of the Canadian Society for Computational Studies of Intelligence . Springer , 2002, pp. 90–101. [24] Q. Liu, Z. Feng, L. Min, and W . Shen, “ A fault prediction method based on modified genetic algorithm using bp neural netw ork algorithm, ” in IEEE International Conference on Systems , 2017. 8 [25] H. C. Shin, H. R. Roth, M. Gao, L. Lu, Z. Xu, I. Nogues, J. Y ao, D. Mollura, and R. M. Summers, “Deep con volutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning, ” IEEE T ransactions on Medical Imaging , vol. 35, no. 5, pp. 1285–1298, 2016. [26] X. Ma, Z. T ao, Y . W ang, H. Y u, and Y . W ang, “Long short-term memory neural network for traffic speed prediction using remote micro wave sensor data, ” T ransportation Researc h P art C , vol. 54, pp. 187–197, 2015. [27] L. Rosasco, E. D. V ito, A. Caponnetto, M. Piana, and A. V erri, “ Are loss functions all the same?” Neural Computation , vol. 16, no. 5, pp. 1063–1076, 2004. [28] Y . Shen, “Loss functions for binary classification and class probability estimation, ” Ph.D. dissertation, Uni versity of Pennsylvania, 2005. [29] H. Masnadi-Shirazi and N. V asconcelos, “On the design of loss functions for classification: theory , robustness to outliers, and savageboost, ” in Advances in neural information pr ocessing systems , 2009, pp. 1049– 1056. [30] T . F awcett, “ An introduction to roc analysis, ” P attern reco gnition letters , vol. 27, no. 8, pp. 861–874, 2006.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment