AI for Earth: Rainforest Conservation by Acoustic Surveillance
Saving rainforests is a key to halting adverse climate changes. In this paper, we introduce an innovative solution built on acoustic surveillance and machine learning technologies to help rainforest conservation. In particular, We propose new convolu…
Authors: Yuan Liu, Zhongwei Cheng, Jie Liu
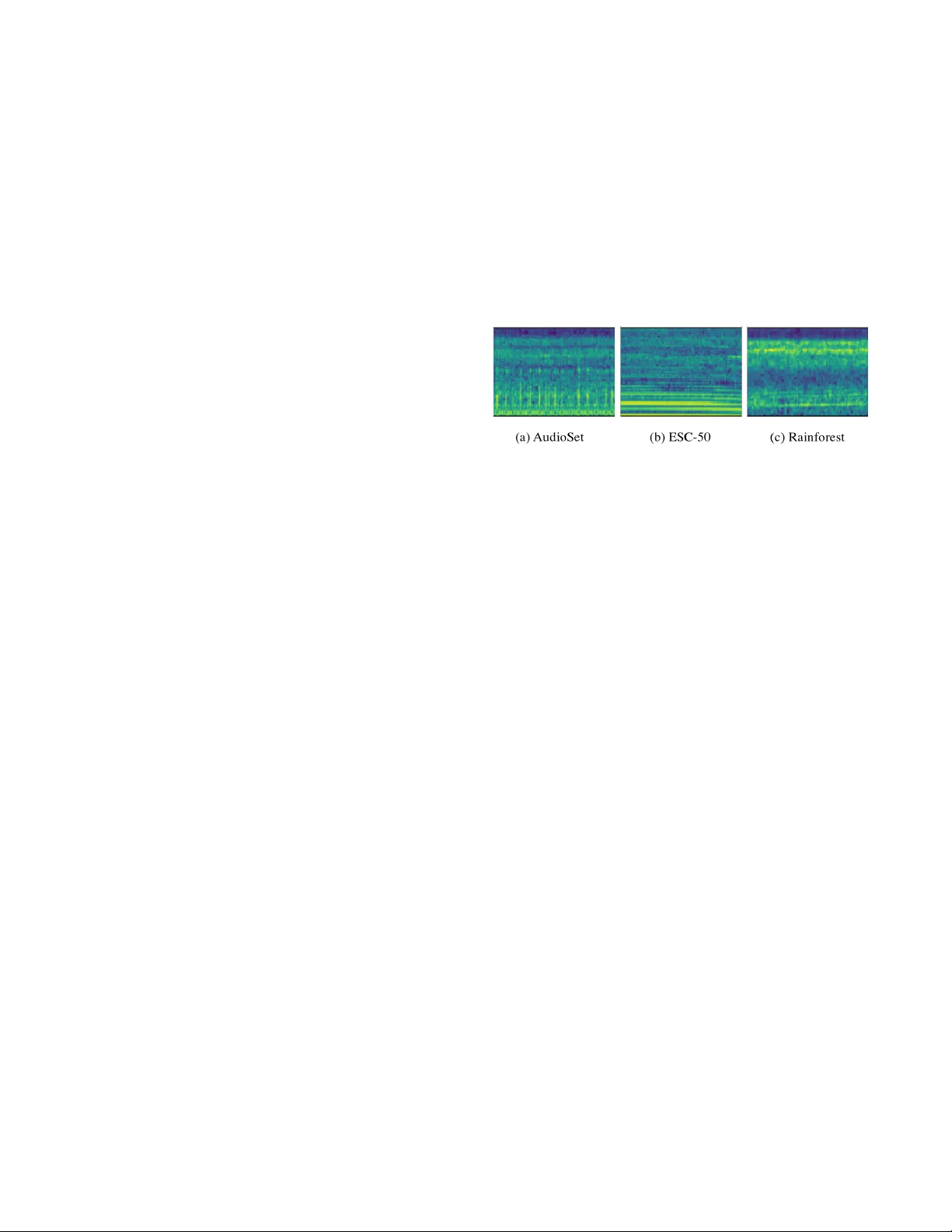
AI for Earth: Rainforest Conservation by Acoustic Surveillance Y uan Liu Huawei Cloud liuyuan45@huawei.com Zhongwei Cheng Futurewei zhongwei.cheng@futurew ei.com Jie Liu Huawei Cloud roger .liujie@huaw ei.com Bourhan Y assin Rainforest Connection bourhan@rfcx.org Zhe Nan Futurewei zhe.nan@futurew ei.com Jiebo Luo Futurewei jiebo.luo@futurewei.com ABSTRA CT Saving rainfor ests is a key to halting adverse climate changes. In this paper , we introduce an innovative solution built on acoustic surveillance and machine learning te chnologies to help rainforest conservation. In particular , W e propose new convolutional neural network (CNN) models for environmental sound classi cation and achieved promising preliminary results on two datasets, including a public audio dataset and our real rainforest sound dataset. The proposed audio classi cation models can b e easily extended in an automated machine learning paradigm and integrated in cloud- based ser vices for real world deployment. KEY W ORDS audio classi cation, acoustic surveillance, neural networks 1 IN TRODUCTION Rainforests are the Earth’s oldest living e cosystems, which o ver half of all biotic species are indigenous to. Deforestation contributes to nearly 1/5 of all global carbon emission. Therefore, protecting reforests is a key to ghting against climate changes and preserving bio-diversity . Tr emendous e orts have be en made to help save rain- forests with modern technologies. With the increasing successful applications of machine learning and arti cial intelligence in vari- ous industries and society in general, such advanced technologies are also attracting the attention of people who are dedicated to protecting our planet. W e focus on the task of rainforest conservation and attempt to bring AI into the picture to signi cantly improv e the e ciency and e ectiveness of the protection on the ground. Despite the recent successes of such technologies in many domains, applying them to real-world conservation projects remains challenging. Deploying AI-powered systems in rural areas faces a wide variety of critical restrictions, such as ver y limited p ower supply , p oor connectivity , and harsh conditions. W e need to utilize a practical yet e ective modality to sense the environment and provide informative data to support decision making. Compared with image data which is limited by eld of view and area covered with dense understor y such as the rainforest, audio data can be a good t in the sense of ease and robustness of data acquisition, low data volume and high information density . Several early attempts [ 9 ] of acoustic surveillance for rainforests have reported the promising value of audio information. Adapting audio recognition techniques in rainforest conser va- tion tasks such as detecting illegal deforestation, animal p oaching, as well as bio-acoustic monitoring are nontrivial, although urban Figure 1: Log-Mel spe ctrograms of chainsaw sounds from various sources. sound classi cation mo dels have outperforme d humans. The main challenges come from the notable domain gap between the sounds of urban and natural environments, and the shortage of extremely expertise-dependent lab eled data. Fig.1 illustrates the Log-Mel spec- trums of chainsaw sounds sampled from di erent sources. It shows the signi cant characteristic di erences in the same kind of sounds in di erent scenarios caused by the variations in the background sounds and distances from the sensing devices. W e introduce our preliminary work on improving audio analysis towards rainforest conser vation. In addition, we brie y outline our vision on building cloud AI powered conser vation systems to bridge the domain experts and AI specialists while making it easy to enable te chnology utilization for good. 2 AUDIO RECOGNI TION Convolutional neural network (CNN) based models [ 2 , 5 , 8 ] have been propose d for sound event detection (SED). While they have achieved very promising results on public datasets for research, we cannot directly employ these existing models or labele d resources since there is signi cant domain gap b etween them and our targeted rainforest tasks. Computational e ciency is also a concern. T o address the above concerns, we propose two new modi ed CNN models to better balance mo del capacity and capability , and also to improve model performance using transfer learning tech- niques to leverage large-scale weakly labeled audio datasets. 2.1 A ugmented VGGish model The V GGish model [ 2 ] broadly used in audio recognition is mod- i ed from V GG16 with layer pruning to reduce the number of parameters. However , it still holds 72.1M parameters and its model (in)e ciency restricts its application on resource-limited devices like Io T devices. Moreover , V GGish only supports single size d input features. In order to accommodate various input sizes to achieve Liu and Cheng et al. exibility in transfer learning and better performance, we propose an augmented VGGish network. The Aug- VGGish mo del includes only 4.7M parameters and is able to achieve b etter recognition performance. The modi cations we made are as follows: 1. Batch Normalization[ 3 ] is introduced following each convo- lutional layer . Batch Normalization allows much higher learning rates and is less sensitive to initialization. 2. A global po oling layer replaces a attened layer . Adding the global pooling layer not only helps lter the features but also makes the network adapt to di erent sizes of input spectrograms. 3. The 4096-unit FC layers are reduced to 256-unit FC layers. 4. The nal 128-unit dense layer is removed. 2.2 Fully convolutional network The Aug- VGGish model produces go od p erformance in our experi- ments, while global p ooling still tends to lose potential informative signals. Given that fully convolutional networks (FCNs) [ 4 ] have shown leading performance in vision tasks, we propose to employ FCN in audio recognition. Our proposed FCN- VGGish mo del con- tains 8 convolutional layers with 18.7M parameters in total. The FCN- V GGish network has the advantages of Aug- V GGish mo dels in addition to the enhanced capability brought by more convolutions. 3 PRELIMINARY RESULTS W e conduct preliminary experiments to validate our proposed mod- els. W e test our models on audio classi cation tasks against two datasets, one of which is a public b enchmark audio dataset and the other is real-world audio samples collected in rainforests. Our models are rst traine d on weakly lab eled A udioSet [ 1 ], and then transferred to the target tasks with parameter ne-tuning. Per- formance results of di erence models are reported with an identical training setup unless stated other wise. 3.1 Results on the ESC-50 dataset ESC-50 [ 6 ] is a balanced public dataset that contains 2000 audio recordings of 50 classes, 40 clips per class and 5 se conds per clip. Re- sults based on 5-fold cross-validation are listed in Table1 to evaluate the mo del performance. T aking human capability of 81.3% accuracy on this task as a reference, the current state-of-the-art [ 7 ] listed on the dataset webpage is 86.5%. Our proposed mo dels obtain clearly better performance with 87.5% accuracy for A ug- VGGish and 90.1% accuracy for FCN- VGGish. Comparing to the vanilla V GGish mo del, our modi e d new models achieve at least 6.2% improvement, which validates the e e ctiveness of our mo di cations. T able 1: Audio classi � cation performance on ESC-50 Model Mean Accuracy F1 score Human Accuracy [6] 81.3% N/A FBEs+ConvRBM-BANK[7] 86.5% N/A V GGish[2] 81.3% 0.806 A ug- VGGish 87.5% 0.870 FCN- V GGish 90.1% 0.898 3.2 Results on real-world sounds in rainforests The rainforest environmental audio data was collected on-site and annotated by our NGO partner Rainforest Connection. Note that used Huawei smartphones are deployed as the sensors due to their long battery life and robustness in the harshly hot and wet condi- tions of the rainforest. This dataset currently includes 22000 audio recordings with annotations of chainsaw or not per one second clip, and is very unbalance d between the 2 classes. The target chainsaw sounds are notably di erent from those in ESC-50 as shown in Fig.1. W e test the V GGish model and our proposed variations on this dataset with the same transfer learning strategy . The performance comparison of classifying chainsaw sounds in rainforests is shown by the precision-recall cur ves in Fig2. Note that there are no extreme samples like insect buzzing in the current data collection, therefore the overall performance seems satisfactor y . W e can se e that Aug- V GGish outperforms vanilla VGGish and FCN- VGGish is the best. Figure 2: Chainsaw sound classi � cation in rainforests. 4 F U T URE WORK W e will explore transfer learning and few-shot learning techniques to improve audio recognition in natural environments, including further rainforest conser vation tasks such as spider monkey habitat modeling and monitoring. With our NGO partner , we are making cloud-based AI solutions for rainforest conser vation a reality . REFERENCES [1] Jort F Gemmeke, Daniel P W Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R Channing Mo ore, Manoj Plakal, and Marvin Ritter . 2017. A udio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE International Conference on Acoustics, Spe ech and Signal Processing (ICASSP) . IEEE, 776–780. [2] Shawn Hershey , Sourish Chaudhuri, Daniel PW Ellis, Jort F Gemmeke, Aren Jansen, R Channing Moore, Manoj P lakal, Devin Platt, Rif A Saurous, Bryan Seybold, et al . 2017. CNN architectures for large-scale audio classi cation. In 2017 ieee international conference on acoustics, sp eech and signal processing (icassp) . IEEE, 131–135. [3] Sergey Io e and Christian Szege dy . 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015). [4] Jonathan Long, Evan Shelhamer , and Trev or Darrell. 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition . 3431–3440. [5] Karol J Piczak. 2015. Environmental sound classi cation with convolutional neural networks. In 2015 IEEE 25th International W orkshop on Machine Learning for Signal Processing (MLSP) . IEEE, 1–6. [6] Karol J Piczak. 2015. ESC: Dataset for environmental sound classi cation. In Proceedings of the 23rd ACM international conference on Multimedia . ACM, 1015– 1018. [7] Hardik B Sailor , Dharmesh M Agrawal, and Hemant A Patil. 2017. Unsuper- vised Filterbank Learning Using Convolutional Restricted Boltzmann Machine for Environmental Sound Classi cation.. In IN TERSPEECH . 3107–3111. [8] Naoya T akahashi, Michael Gygli, Beat P ster , and Luc V an Gool. 2016. Deep convolutional neural networks and data augmentation for acoustic event dete ction. arXiv preprint arXiv:1604.07160 (2016). [9] Marina Y uso and Amirul Sadikin Md Afendi. 2018. Acoustic Sur veillance Intru- sion Detection with Linear Predictive Coding and Random Forest. In International Conference on Soft Computing in Data Science . Springer , 72–84.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment