Design space exploration of Ferroelectric FET based Processing-in-Memory DNN Accelerator
In this letter, we quantify the impact of device limitations on the classification accuracy of an artificial neural network, where the synaptic weights are implemented in a Ferroelectric FET (FeFET) based in-memory processing architecture. We explore a design-space consisting of the resolution of the analog-to-digital converter, number of bits per FeFET cell, and the neural network depth. We show how the system architecture, training models and overparametrization can address some of the device limitations.
💡 Research Summary
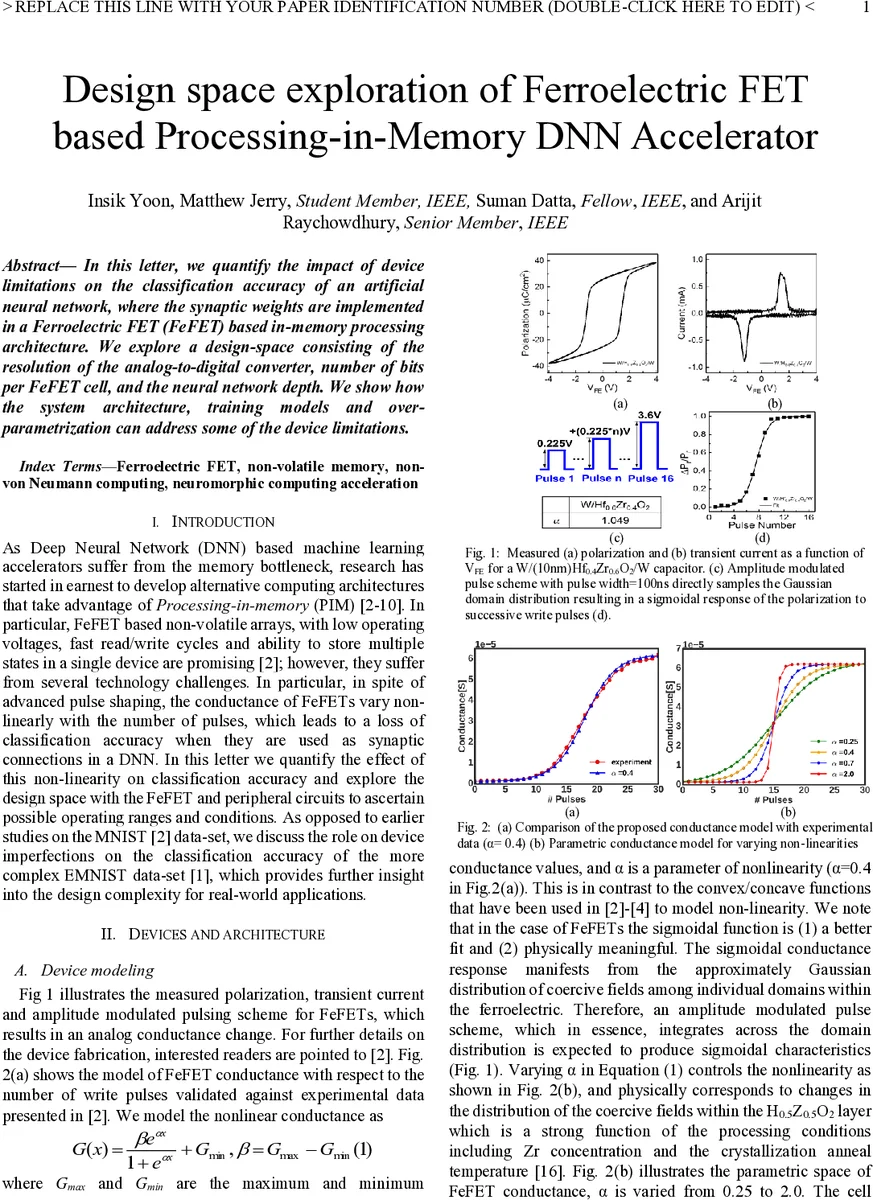
The paper investigates the impact of device non‑idealities of ferroelectric field‑effect transistors (FeFETs) on the classification accuracy of deep neural networks (DNNs) when the weights are stored in a processing‑in‑memory (PIM) architecture. The authors model the FeFET conductance as a sigmoidal function of the number of programming pulses, G(n)=G_min + (G_max‑G_min)/(1+e^{‑α(n‑β)}), where the parameter α controls the degree of non‑linearity (α=0.4 matches measured data). This model reflects the Gaussian distribution of coercive fields across ferroelectric domains and the effect of amplitude‑modulated pulses.
A differential FeFET cell is proposed, allowing both positive and negative weights to be stored in a single array without a dedicated negative‑weight sub‑array. During write, two access transistors receive programming pulses; during read, differential currents from the two FeFETs are summed and converted to digital values by an on‑chip ADC. The architecture enables matrix‑vector multiplication in O(1) time by activating all word lines simultaneously and summing the source‑line currents.
Three simulation scenarios are explored on the EMNIST Balanced dataset using TensorFlow augmented with device, circuit, and architectural models: (1) a floating‑point (FP) baseline where training and inference run on a GPU; (2) a hardware‑aware inference (HAI) case where training is performed on a GPU but inference runs on the FeFET PIM; (3) a hardware‑aware training and inference (HATI) case where both phases are executed on the FeFET PIM. In HAI and HATI, weights are scaled to the range
Comments & Academic Discussion
Loading comments...
Leave a Comment