Point Cloud Super Resolution with Adversarial Residual Graph Networks
Point cloud super-resolution is a fundamental problem for 3D reconstruction and 3D data understanding. It takes a low-resolution (LR) point cloud as input and generates a high-resolution (HR) point cloud with rich details. In this paper, we present a data-driven method for point cloud super-resolution based on graph networks and adversarial losses. The key idea of the proposed network is to exploit the local similarity of point cloud and the analogy between LR input and HR output. For the former, we design a deep network with graph convolution. For the latter, we propose to add residual connections into graph convolution and introduce a skip connection between input and output. The proposed network is trained with a novel loss function, which combines Chamfer Distance (CD) and graph adversarial loss. Such a loss function captures the characteristics of HR point cloud automatically without manual design. We conduct a series of experiments to evaluate our method and validate the superiority over other methods. Results show that the proposed method achieves the state-of-the-art performance and have a good generalization ability to unseen data.
💡 Research Summary
Point cloud super‑resolution aims to reconstruct a dense, high‑resolution (HR) point set from a sparse, low‑resolution (LR) input, a task critical for downstream 3D applications such as reconstruction, printing, and animation. Existing approaches fall into two categories. Traditional optimization‑based methods (e.g., MLS, Voronoi‑based upsampling) rely on strong geometric priors about surface smoothness and often blur sharp edges. Data‑driven methods, exemplified by PU‑Net, use PointNet++ to extract multi‑scale features and then expand the point set via multi‑branch convolutions. While PU‑Net outperforms many classic techniques, it suffers from two major drawbacks: (1) it directly regresses point coordinates without explicitly exploiting the similarity between LR and HR clouds, making training difficult; (2) it employs a handcrafted loss that encodes human priors (e.g., uniform distribution) and fails to capture higher‑order properties such as continuity and surface texture.
The paper introduces Adversarial Residual Graph Convolutional Network (AR‑GCN), a novel architecture that addresses both issues. The generator is built on graph convolutional networks (GCNs) where each point is a node and its k‑nearest neighbors (k=8) define edges. A residual graph convolution block consists of 12 layers with skip connections, enabling the network to learn the residual (difference) between LR and HR coordinates rather than the absolute positions. This residual formulation mirrors successful strategies in 2‑D image super‑resolution and accelerates convergence. An unpooling block predicts a residual offset δx for each point, reshapes it to produce two new points, and adds it to the original coordinates, effectively upsampling by a factor of two at each stage. A lightweight “feature net” extracts local descriptors from the k‑nearest neighbor set using point‑wise convolutions and max‑pooling, feeding these descriptors into the graph convolutions.
Training loss combines a Chamfer Distance (CD) term and a graph‑based adversarial term. CD (∑{p∈y} min{q∈ŷ}‖p−q‖²) ensures point‑wise proximity to ground truth, while the adversarial component follows the LS‑GAN formulation: L_G = ‖1−D(ŷ)‖²₂, where D is a discriminator also implemented as a GCN. The discriminator operates as a “graph patch GAN”: it repeatedly downsamples the input via farthest point sampling, aggregates local features with max‑pooling, and outputs 64 patch‑level scores rather than a single global flag. This design forces every local region of the generated cloud to resemble the distribution of real HR clouds, mitigating the blurriness typical of global discriminators. The overall objective is L = λ·L_CD + L_G, with λ balancing the two terms (set to 1 in experiments).
The architecture is applied iteratively, performing 2× upsampling at each step, which empirically yields higher fidelity than a single large‑scale upsampling. The model contains roughly 0.785 M parameters, comparable to PU‑Net (0.777 M), indicating that the performance gains are not due to a massive increase in capacity.
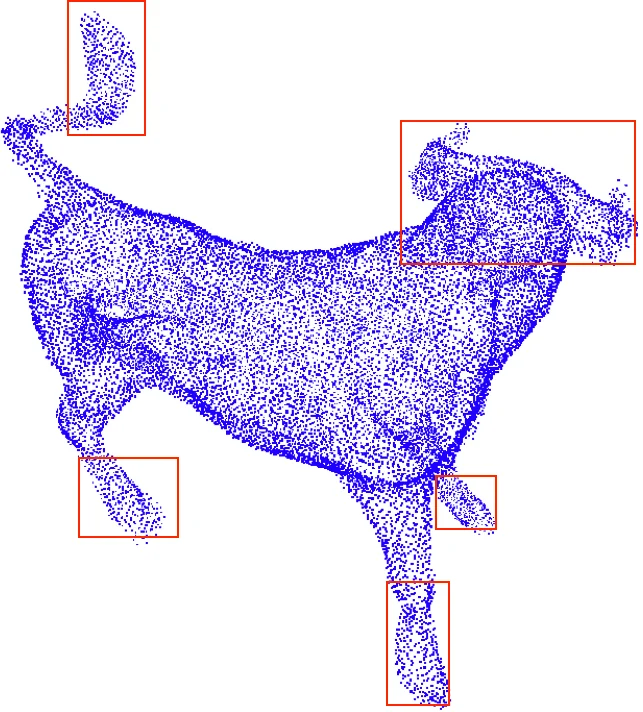
Experiments are conducted on two benchmarks. The first is the PU‑Net training/testing split of the Visionair dataset (40 models for training, 20 for testing). Each ground‑truth patch contains 4,096 points; LR inputs are randomly sampled to 1,024 points. The second is the unseen SHREC15 dataset (50 categories, 24 models each), used without any fine‑tuning to assess generalization. Quantitative metrics include Chamfer Distance, Earth Mover’s Distance (EMD), F‑score, and Normalized Uniformity Coefficient (NUC) evaluated at multiple p‑values. AR‑GCN consistently outperforms baselines: CD drops from 0.0118 (PU‑Net) to 0.0084 on the seen set and from 0.0103 to 0.0054 on SHREC15; NUC improves from 70.28 % to 93.07 %, indicating superior uniformity and reduced noise. Visual comparisons show sharper edges and fewer spurious points compared to PU‑Net.
Ablation studies confirm the contribution of each component: removing residual connections or the adversarial loss degrades performance, while using only CD leads to duplicated points due to the symmetric term being omitted. Additional experiments demonstrate the utility of AR‑GCN in (i) iterative upsampling to 4× and 8× resolutions, (ii) enhancing downstream 3D reconstruction pipelines, and (iii) serving as a pre‑processor for point‑cloud classification, where it improves classification accuracy.
In summary, the paper presents a compelling integration of graph‑based residual learning and adversarial training for point cloud super‑resolution. By directly modeling the LR‑HR relationship through residual graph convolutions and by learning a data‑driven loss that captures high‑order geometric properties, AR‑GCN achieves state‑of‑the‑art results on both seen and unseen datasets while maintaining a modest model size. Future directions include scaling to higher upsampling ratios, exploring dynamic edge weighting, incorporating multimodal cues (e.g., RGB images), and optimizing for real‑time deployment in practical 3D acquisition systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment