Visual Interaction with Deep Learning Models through Collaborative Semantic Inference
Automation of tasks can have critical consequences when humans lose agency over decision processes. Deep learning models are particularly susceptible since current black-box approaches lack explainable reasoning. We argue that both the visual interface and model structure of deep learning systems need to take into account interaction design. We propose a framework of collaborative semantic inference (CSI) for the co-design of interactions and models to enable visual collaboration between humans and algorithms. The approach exposes the intermediate reasoning process of models which allows semantic interactions with the visual metaphors of a problem, which means that a user can both understand and control parts of the model reasoning process. We demonstrate the feasibility of CSI with a co-designed case study of a document summarization system.
💡 Research Summary
The paper addresses a critical gap in human‑AI interaction: while deep learning models achieve impressive performance, their internal reasoning is hidden, leaving users with little agency over automated decisions. To remedy this, the authors introduce a framework called Collaborative Semantic Inference (CSI), which tightly couples visual analytics, interaction design, and model architecture. CSI is built on three pillars: (1) exposing intermediate reasoning steps of a model as “hooks” – discrete latent variables that act as interpretable decision points; (2) visualizing these hooks in a metaphor that matches the user’s mental model of the task; and (3) allowing users to interact with the hooks both forward (changing inputs) and backward (modifying the desired output and observing how the model would have arrived at it).
The authors first situate CSI within a broader design space for machine‑learning visualizations. They categorize existing work into three integration levels: passive observation (static displays of model metrics or heatmaps), interactive observation (tools that let users probe model internals, such as embedding projectors or counter‑factual generators), and interactive collaboration (the most advanced level, where users can feed back into the model to shape its parameters or decisions). CSI occupies the interactive collaboration tier, requiring a tight coupling between the model and the interface that can only be achieved through co‑design.
Technically, the key contribution is the insertion of “hooks” into the neural architecture. These are discrete latent variables—e.g., topic assignments or sentence‑selection flags—that are explicitly modeled and can be queried or set by the user. Because they are part of the computational graph, changing a hook value triggers a backward pass that updates the model’s internal state and produces a new prediction in real time. This mechanism enables true “what‑if” analysis: users can see not only why a particular output was generated, but also what internal configuration would be required to obtain a different, user‑desired output.
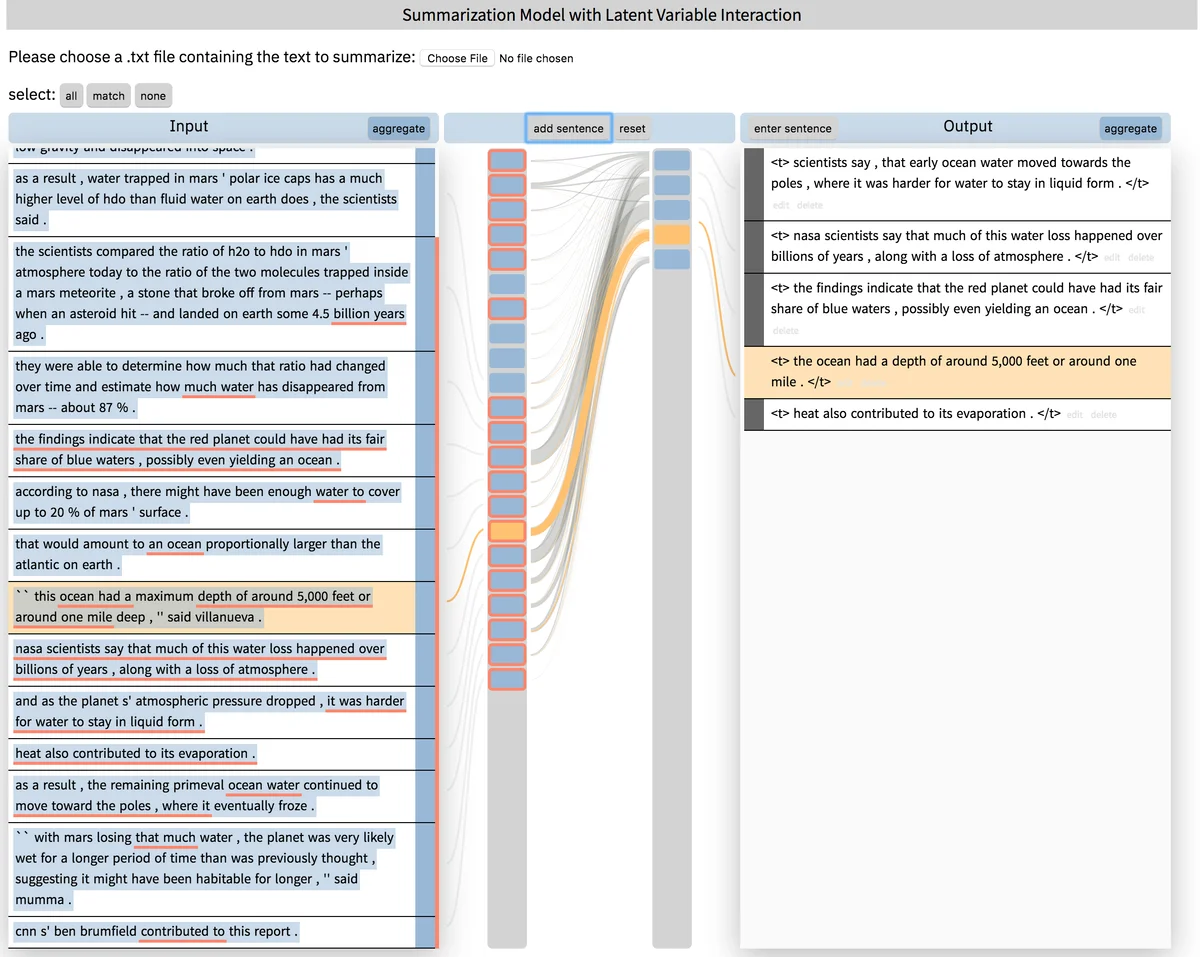
To demonstrate feasibility, the authors implement a document‑summarization system. The summarizer is augmented with two hooks: a latent topic distribution that guides content selection, and a binary selector for each source sentence indicating whether it should appear in the summary. The interface visualizes the summary as a hierarchical tree, highlights which sentences were chosen, and shows the associated topic weights. An end‑user can click a missing sentence to activate its selector hook, or adjust topic sliders to emphasize certain themes. The system instantly recomputes the summary, displaying the updated internal state (topic probabilities and sentence scores) alongside the new text. This concrete example illustrates how CSI can give domain experts (e.g., editors) direct control over a deep model without requiring them to understand the underlying neural math.
The paper also discusses challenges. Generalizing hooks to other modalities (images, audio, multimodal data) demands careful design of interpretable latent structures. Real‑time backward interaction can be computationally expensive, so efficient inference tricks or approximate updates are needed. Finally, the interface must balance transparency with cognitive load; too much detail can overwhelm users, while too little defeats the purpose of agency. The authors propose a role‑based approach—architects, trainers, and end‑users—each receiving tailored visualizations and interaction affordances.
In the discussion, the authors contrast CSI with prior explainability tools such as LIME, SHAP, or post‑hoc saliency maps, which only provide forward‑direction explanations. CSI’s bidirectional loop enables users not just to interpret but to actively shape model behavior, moving the relationship from “model as black‑box assistant” to “model as collaborative partner.” They argue that this shift is essential for high‑stakes domains (medicine, law, journalism) where human oversight and control are non‑negotiable.
Overall, the paper makes a compelling case that exposing and visualizing intermediate reasoning steps, combined with semantic interaction mechanisms, can restore human agency in deep‑learning‑driven workflows. By providing a concrete taxonomy, design principles, and a working prototype, the authors lay groundwork for future research on tightly integrated human‑AI collaborative systems across a wide range of applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment