Discriminative Learning for Monaural Speech Separation Using Deep Embedding Features
Deep clustering (DC) and utterance-level permutation invariant training (uPIT) have been demonstrated promising for speaker-independent speech separation. DC is usually formulated as two-step processes: embedding learning and embedding clustering, wh…
Authors: Cunhang Fan, Bin Liu, Jianhua Tao
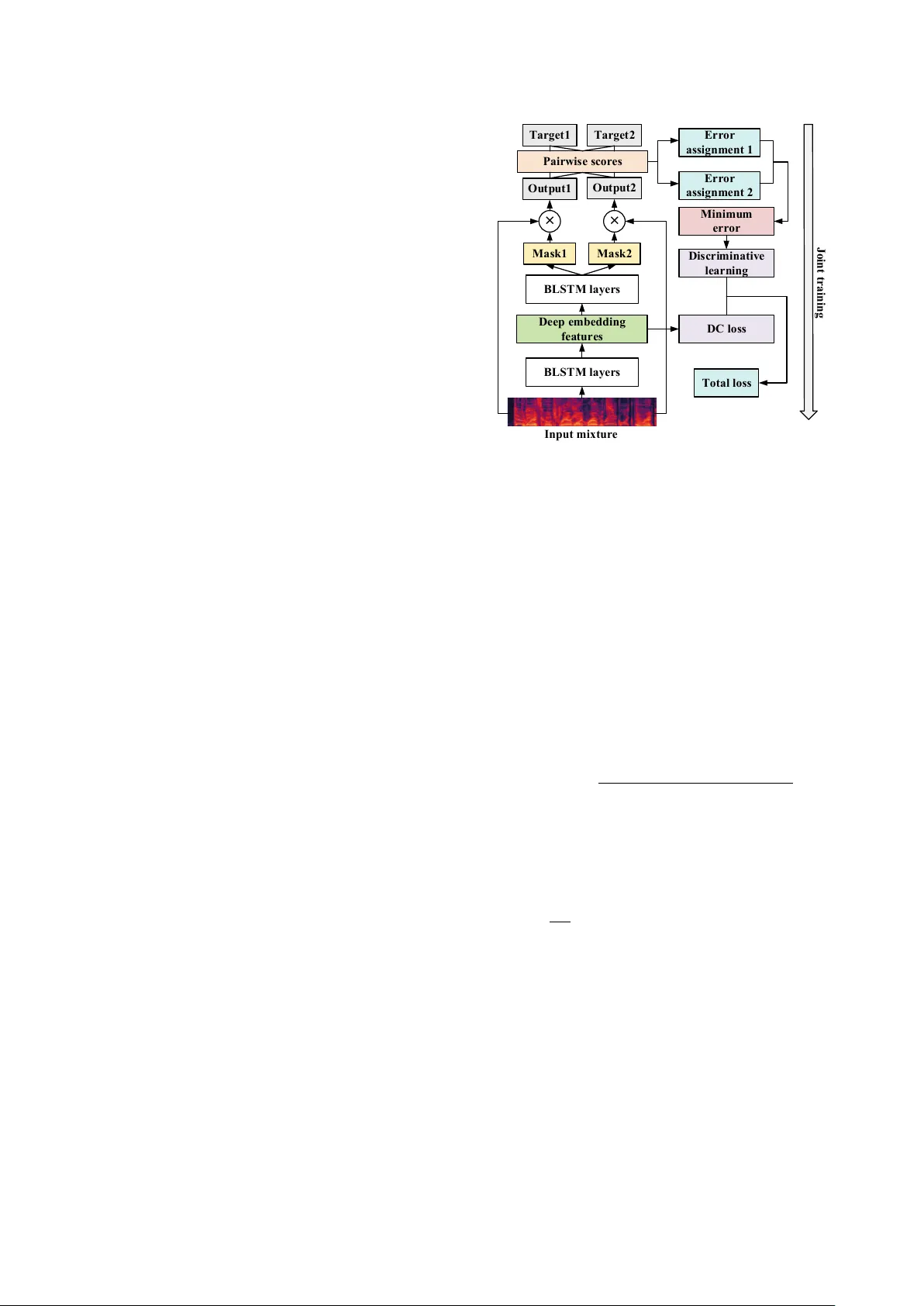
Discriminativ e Learning f or Monaural Speech Separation Using Deep Embedding F eatures Cunhang F an 1 , 3 , Bin Liu 1 , Jianhua T ao 1 , 2 , 3 , Jiangyan Y i 1 , Zhengqi W en 1 1 NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing, China 2 CAS Center for Excellence in Brain Science and Intelligence T echnology , Beijing, China 3 School of Artificial Intelligence, Uni versity of Chinese Academy of Sciences, Beijing, China { cunhang.fan, liubin, jhtao, jiangyan.yi, zqwen } nlpr.ia.ac.cn Abstract Deep clustering (DC) and utterance-lev el permutation in v ariant training (uPIT) have been demonstrated promising for speaker- independent speech separation. DC is usually formulated as two-step processes: embedding learning and embedding clus- tering, which results in comple x separation pipelines and a huge obstacle in directly optimizing the actual separation objectives. As for uPIT , it only minimizes the chosen permutation with the lowest mean square error , doesn’t discriminate it with other per - mutations. In this paper , we propose a discriminati ve learning method for speaker -independent speech separation using deep embedding features. Firstly , a DC network is trained to ex- tract deep embedding features, which contain each source’ s in- formation and hav e an advantage in discriminating each target speakers. Then these features are used as the input for uPIT to directly separate the different sources. Finally , uPIT and DC are jointly trained, which directly optimizes the actual separa- tion objectiv es. Moreover , in order to maximize the distance of each permutation, the discriminative learning is applied to fine tuning the whole model. Our experiments are conducted on WSJ0-2mix dataset. Experimental results show that the pro- posed models achiev e better performances than DC and uPIT for speaker -independent speech separation. Index T erms : deep clustering, uPIT , speech separation, dis- criminativ e learning, deep embedding features 1. Introduction Monaural speech separation aims to estimate target sources from mixed signals in a single-channel. It is a very challeng- ing task, which is known as the cocktail party problem [1]. In order to solve the cocktail party problem, many works hav e been done o ver the decades. T raditional speech sepa- ration methods include computational auditory scene analy- sis (CASA) [2], non-negati ve matrix factorization (NMF) [3] and minimum mean square error (MMSE) [4]. Howe ver , these methods hav e led to very limited success in speaker- independent speech separation [5]. Recently , supervised methods using deep neural networks hav e significantly improv ed the performance of speech separa- tion [6, 7, 8, 9, 10, 11]. Deep clustering (DC) [12] is a deep learning based method for speech separation and achiev es im- pressiv e results. It trains a bidirectional long-short term mem- ory (BLSTM) network to map the mixed spectrogram into an embedding space. At testing stage, the embedding vector of each time-frequenc y (TF) bin is clustered by K-means to obtain binary masks. Howe ver , the objecti ve function of DC is defined in the embedding space, which can’t be trained end-to-end. T o ov ercome this limitation, the deep attractor network (DANet) [13] method is proposed. D ANet creates attractor points in a high-dimensional embedding space of the acoustic signals. Then the similarities between the embedded points and each attractor are used to directly estimate a soft separation mask at the training stage. Unfortunately , it enables end-to-end train- ing while still requiring K-means at the testing stage. In other words, it applies hard masks at testing stage. The permutation inv ariant training (PIT) [14] and utterance- lev el PIT (uPIT) [15] are proposed to solve the label ambi- guity or permutation problem of speech separation. The PIT method solves this problem by minimizing the permutation with the lo west mean square error (MSE) at frame le vel. Howe ver , it does not solve the speaker tracing problem. T o solve this problem, uPIT is proposed. With uPIT , the permutation cor- responding to the minimum utterance-lev el separation error is used for all frames in the utterance. Therefore, uPIT doesn’t need speaker tracing step during inference. Howev er, uPIT and PIT only use the mixed amplitude spectrum as input features, which can’t discriminate each speaker very well. In addition, uPIT doesn’t increase the distance between the chosen permu- tation and others. This may lead to increasing the possibility of remixing the separated sources. In [16], a Chimera network [17] is applied to speech separation, which uses a multi-task learning architecture to combine the DC and uPIT . Howe ver , it simply emplo ys the DC and uPIT as tw o outputs rather than fusion with each other . In this paper , in order to address the problems of DC and uPIT , we propose a discriminative learning method for speaker- independent speech separation with deep embedding features. uPIT is incorporated into DC-based speech separation frame- work. Firstly , a DC network is trained to extract deep embed- ding features. Clusters in the embedding space can represent the inferred spectral masking patterns of individual source. There- fore, these deep embedding features contain the information of each source, which is conduciv e to speech separation. Then in- stead of using K-means clustering to estimate hard masks, we make full use of the uPIT network to directly learn each source’ s soft mask from the embedding features. And then uPIT and DC are jointly trained, which directly optimizes the actual separa- tion objecti ves. Finally , in order to decrease the possibility of remixing the separated sources, moti vated by our previous work [10], we apply the discriminativ e learning to fine tuning the sep- arated model. The rest of this paper is organized as follows. Section 2 presents the single channel speech separation based on masks. The proposed method is stated in section 3. Section 4 shows detailed experiments and results. Section 5 draws conclusions. 2. Single Channel Speech Separation The object of single channel speech separation is to separate target sources from a mix ed signal. y ( t ) = S X s =1 x s ( t ) (1) where y ( t ) is the mixed speech, S is the number of source sig- nals and x s ( t ) , s = 1 , ..., S are tar get sources. The correspond- ing short-time Fourier transformation (STFT) of those signals are Y ( t, f ) and X s ( t, f ) . Our aim is to estimate each source signal x s ( t ) from y ( t ) or Y ( t, f ) . It is well-kno wn that mask based speech separation can obtain a better result [18]. According to the commonly used masking method, the estimated magnitude | e X s ( t, f ) | of each source can be estimated by | e X s ( t, f ) | = | Y ( t, f ) | M s ( t, f ) (2) where indicates element-wise multiplication and M s ( t, f ) is the mask of source s . It is v ery difficult to estimate phase di- rectly for speech separation and speech enhancement. There- fore, the estimated magnitude | e X s ( t, f ) | and the phase of mixed signals are utilized to reconstruct each source signal by in verse STFT (ISTFT). 3. The Proposed Speech Separation System In this section, we present our proposed discriminati ve learning method for speaker -independent speech separation with deep embedding features, which is shown in Figure 1. From DC net- work [12] we can know that clusters in the deep embedding space can represent the inferred spectral masking patterns of individual sources. Therefore, these embedding v ectors are dis- criminativ e features for speech separation. Moti vated by this, we use this deep embedding v ectors as the input of separation system. Then a uPIT network is used to learn the soft mask of each source instead of K-means clustering. Moreov er, in oder to maximize the distance of each speaker , the discriminativ e learn- ing is applied to fine tuni ng the whole model. Finally , uPIT and DC are jointly optimized. 3.1. Deep embedding features As shown in Figure 1, we firstly train a BLSTM network as the extractor to acquire deep embedding features. The input of BLSTM is the mixed amplitude spectrum | Y ( t, f ) | and the output is the D-dimensional deep embedding features V . V = f θ ( | Y ( t, f ) | ) ∈ R T F × D (3) where TF is the number of T -F bins and f θ ( ∗ ) is a mapping function based on the BLSTM network. The loss function of embedding features’ network is defined as follow: J DC = || V V T − B B T || 2 F = || V V T || 2 F − 2 || V T B || 2 F + || B B T || 2 F (4) where B ∈ R T F × C is the source membership function for each T -F bin, i.e., B tf ,c = 1 , if source c has the highest energy at time t and frequency f compared to the other sources. Otherwise, B tf ,c = 0 . C is the number of source. || ∗ || 2 F is the squared Frobenius norm. J DC is the DC loss in Figure 1. M a s k 1 I n p u t m i x tu r e BLS T M l a y e r s BLS T M l a y e r s M a s k 2 × × O u t p u t1 O u t p u t2 Ta r g e t 1 Ta r g e t 2 P a i r w i s e s c o r e s Er r o r a s s i g n m e n t 1 Er r o r a s s i g n m e n t 2 M i n i m u m e r r o r D C l o s s To ta l l o s s D e e p e m b e d d i n g fe a tu r e s D i s c r i m i n a ti v e l e a r n i n g J o i n t tr a i n i n g 迅捷 PDF 编辑器 Figure 1: Schematic diagram of our pr oposed DL-DEF speech separation system. DC loss is the loss of deep clustering. 3.2. Speech separation model based on deep embedding features Different from deep clustering [12] utilizing the K-means clus- tering to acquire hard masks, we use the embedding vectors as the input of uPIT to directly learn each source’ s soft masks. Therefore, the DC and uPIT can be trained end-to-end. When these features are extracted, they are reshaped as V 0 ∈ R T × F D . Then these embedding features V 0 are sent to the separated sys- tem. In this way , we can learn a soft mask of each source from these features, which is better than the hard mask estimated by K-means clustering. In order to mak e full use of phase information, we use the ideal phase sensitiv e mask (IPSM) [19] in this w ork. The IPSM is defined as M s ( t, f ) = | X s ( t, f ) | cos ( θ y ( t, f ) − θ s ( t, f )) | Y ( t, f ) | (5) where θ y ( t, f ) and θ s ( t, f ) are the phase of mixed speech and target source. During the separation stage, the uPIT is used to estimate each source. W e apply the MSE between estimated magnitude and true magnitude as the training criterion. J φ p ( s ) = 1 T F S X s =1 ||| Y | f M s − | X φ p ( s ) | cos ( θ y − θ s ) || 2 F (6) where f M s is the estimated mask. φ p ( s ) , p ∈ [1 , P ] is an assign- ment of target source s, P = S ! ( ! denotes the factorial symbol) is the number of permutations. In order to solve the label ambiguity problem, the minimum cost among all permutations (P) is chosen as the optimal assign- ment. φ ∗ = ar g min φ ∈ P J φ p ( s ) (7) 3.3. Discriminative learning For uPIT , the tar get of minimizing Eq.7 is to mak e the predic- tions and targets more similar . In this paper, we explore dis- criminativ e objectiv e function that not only increase the simi- larity between the prediction and its target, but also decrease the similarity between the prediction and the interference sources. The discriminati ve learning maximizes the dissimilarity be- tween the chosen permutation φ ∗ and the other permutations by adding a regularization at the cost function. The cost function of the proposed model is defined as J DL = φ ∗ − X φ 6 = φ ∗ ,φ ∈ P αφ (8) where φ is a permutation from P but not φ ∗ , α ≥ 0 is the regularization parameter of φ . When α = 0 , there is no dis- criminativ e learning, which is same as the loss of uPIT . For two-talker speech separation, we assume that φ 1 is the permutation with the lowest MSE. Therefore, the cost function becomes as follow: J DL = φ 1 − αφ 2 = 1 T F X ( ||| Y | f M 1 − | X 1 ||| 2 F − α ||| Y | f M 1 − | X 2 ||| 2 F + ||| Y | f M 2 − | X 2 ||| 2 F − α ||| Y | f M 2 − | X 1 ||| 2 F ) (9) From Eq.9 we can know that the discriminative learning enlarges the distance of the target source with the interference sources. It means that it maximizes the differences between the target speak ers with the others. Therefore, the proposed model with discriminati ve learn- ing minimizes the distance between the outputs of model and their corresponding reference signals. Simultaneously , it maxi- mizes the dissimilarity between the target source and the inter- ference. So the discriminativ e learning decreases the possibility of remixing the separated sources. 3.4. Joint training loss function The deep clustering objectiv e can reduce within-source variance in the internal representation [17]. Therefore, in order to effec- tiv ely extract embedding features, we make full use of a joint training framew ork for the proposed system. More specifically , the deep clustering objectiv e is added at the loss function. J = λJ DC + (1 − λ ) J DL = λJ DC + (1 − λ )( φ ∗ − X φ 6 = φ ∗ ,φ ∈ P αφ ) (10) where J is the joint training loss function of the proposed sys- tem. λ ∈ [0 , 1] controls the weight of two objectiv es. Note that when λ = 1 , the proposed method is same as deep clustering [12]. In order to get the better deep embedding features, we only train the DC network firstly . The loss function is Eq.4. Then these deep embedding features are used to train the separated model based on uPIT . The loss function is with no discrimina- tiv e learning: J 0 = λJ DC + (1 − λ ) φ ∗ (11) Finally , we apply the discriminati ve learning to fine tuning the whole model by the joint training loss function J in Eq.10. 4. Experiments and Results 4.1. Dataset Our e xperiments are conducted on the WSJ0-2mix dataset [12], which is deriv ed from WSJ corpus [20]. The WSJ0-2mix dataset consists three sets: training set (20,000 utterances about 30 hours), validation set (5,000 utterances about 10 hours) and test set (3,000 utterances about 5 hours). Specifically , training and v alidation set are generated by randomly selecting utter- ances from WSJ0 training set ( si tr s ) with signal-to-noise ratios (SNRs) between 0dB and 5dB. Similar as generating training and validation set, the test set is created by mixing the utterances from the WSJ0 dev elopment set ( si dt 05 ) and ev aluation set ( si et 05 ). W e use the validation set to e valuate the source separation performance in closed conditions (CC). Moreov er , because the speakers in the test set are dif ferent from those in the training set and v alidation set, the test set is considered as open condition (OC) ev aluation. 4.2. Experimental setup The sampling rate of all generated data is 8 kHz before process- ing to reduce computational and memory costs. The 129-dim normalized spectral magnitudes of the mixed speech are used as the input features, which are computed using a short-time Fourier transform (STFT) with 32 ms length hamming window and 16 ms window shift. The magnitudes of two targets are generated in the same way . Our models are implemented using T ensorflo w deep learning framew ork [21]. In this work, the deep embedding netw ork has two BLSTM layers with 896 units. The embedding dimension D is set to 40. A tanh activ ation function is followed by the embedding layer . As for the separated network, it has only one BLSTM layer with 896 units. Therefore, there are three BLSTM layers in this work, which keeps the network configuration the same as baseline in [15]. A Rectified Liner Uint (ReLU) acti vation function is followed by the uPIT network, which is the mask estimation layer . The re gularization parameter α of discrimina- tiv e learning is set to 0.1. All models contain random dropouts with a dropout rate 0.5. Each minibatch contains 16 randomly selected utterances. The minimum number of epoch is 30. The learning rate is ini- tialized as 0.0005 and scaled down by 0.7 when the training objectiv e function value increased on the development set. The early stopping criterion is that the relati ve loss improvement is lower than 0.01. Our models are optimized with the Adam al- gorithm [22]. 4.3. Baseline model and evaluation metrics W e re-implement uPIT with our e xperimental setup as our base- line. It has three BLSTM layers with 896 units. The others are same as our experimental setup. In this work, in order to quantitativ ely ev aluate speech separation results, the models are ev aluated on the signal-to-distortion ratio (SDR), signal-to- interference ratio (SIR) and signal-to-artifact ratio (SAR) which are the BBS-ev al [23] score, and the perceptual evaluation of speech quality (PESQ) [24] measure. 4.4. Experimental results T able 1 shows the results of SDR, SIR, SAR and PESQ be- tween the proposed method and uPIT -BLSTM on the WSJ0- 2mix database. DEF denotes the deep embedding features. 4.4.1. Evaluation of deep embedding featur es From T able 1, we can find that our proposed uPIT+DEF meth- ods outperform baseline uPIT in all objecti ve measures no mat- ter optimal assignment (Opt. assign.) or default assignment T able 1: The r esults of SDR, SIR, SAR and PESQ for differ ent separation methods on closed (CC) and open (OC) condition. λ is the weight of joint training in Eq.10 and 11. DEF denotes the deep embedding featur es. uPIT is the baseline method, uPIT+DEF and uPIT+DEF+DL ar e our proposed methods. uPIT+DEF means with no discriminative learning. Method λ Optimal (Opt.) Assign. Default (Def.) Assign. SDR(dB) SIR(dB) SAR(dB) PESQ SDR(dB) SIR(dB) SAR(dB) PESQ CC OC CC OC CC OC CC OC CC OC CC OC CC OC CC OC uPIT(baseline) - 11.3 11.2 18.8 18.8 12.3 12.3 2.68 2.67 10.3 10.1 17.7 17.5 11.5 11.3 2.60 2.58 uPIT+DEF 0.01 11.7 11.6 19.4 19.5 12.7 12.6 2.85 2.84 10.8 10.7 18.4 18.4 12.0 11.8 2.77 2.75 uPIT+DEF 0.05 11.7 11.7 19.5 19.6 12.7 12.6 2.84 2.84 10.8 10.8 18.4 18.8 11.9 11.9 2.76 2.75 uPIT+DEF 0.1 11.7 11.7 19.5 19.5 12.7 12.6 2.84 2.84 10.8 10.7 18.5 18.4 12.0 11.9 2.76 2.74 uPIT+DEF+DL 0.05 11.9 11.9 19.9 20.0 12.8 12.7 2.83 2.83 11.0 10.8 18.8 18.8 12.0 11.9 2.74 2.73 (Def. assign.). These indicate that the deep embedding features are more easily separated than the mix ed amplitude spectral fea- tures. Because deep embedding features contain the potential masks of individual sources and they can effectiv ely discrimi- nate different target speakers. Therefore, they are conducive to speech separation. Moreov er , in order to acquire better deep embedding fea- tures, we propose a novel joint training framew ork to in- struct the training of deep embedding network. Three differ - ent weights λ (0.01, 0.05 and 0.1) are applied. From T able 1, we can know that the performance of these three λ for speech separation are similar . The reason is that we firstly train a DC network with 30 epochs, which can obtain a pretty good repre- sentation for deep embedding features. Therefore, these three λ get similar performance. 4.4.2. Evaluation of discriminative learning Since the discriminativ e learning separates the target speaker with others, it provides a constraint to ensure that the output frames of the same speaker do not remix to the interferences. Therefore, we use discriminative learning to fine tuning the whole model based on λ = 0 . 05 . From T able 1, we can know that when the discriminative learning is applied, our proposed method uPIT+DEF+DL achiev es better performances than the proposed uPIT+DEF ov erall objectiv e scores, except for the PESQ measure. This shows the ef fectiveness of the discrimi- nativ e learning. Meanwhile, compared with the uPIT baseline system, the proposed uPIT+DEF+DL gets a better performance in all cases. For example, as for the optimal assignment on open condition, the proposed method achieves 6.3%, 6.4% and 3.3% relativ e improvements in SDR, SIR and SAR over the uPIT baseline system. These results reveal the effecti veness of our proposed method. 4.4.3. Comparisons with other separation methods In order to better compare the performance of our proposed method (uPIT+DEF+DL) and other separation methods, T a- ble 2 presents the results of SDR (dB) in the other competi- tiv e approaches on the same WSJ0-2mix dataset. Note that, for [9, 12, 25, 15, 26, 13] methods are use SDR improvements results. Therefore, we manually add 0.2 dB to their final re- sults although the SDR result of the mixture is only about 0.15 dB. Compared with other speech separation methods, our pro- posed method improves the performance significantly to 11.9 dB and 10.8 dB with no phase enhancement for Opt Assign and Def Assign. Moreover , from T able 2, we can kno w that our proposed method outperforms other methods, such as DC+, T able 2: The results of SDR (dB) in the other different separa- tion methods on the WSJ0-2mix dataset on CC and OC with no phase enhancement. Method Opt Assign Def Assign CC OC CC OC DC[12] - - 6.1 6.0 DC+[26] - - - 9.6 D ANet[13] - - - 9.8 uPIT -BLSTM [15] 11.1 11.0 9.6 9.6 cuPIT -Grid LSTM-RD[9] 11.4 11.4 10.4 10.3 SDC-ML T -Grid LSTM [25] 11.6 11.6 10.8 10.7 uPIT+DEF+DL(our proposed) 11.9 11.9 11.0 10.8 D ANet, SDC-ML T -Grid LSTM. Compared with DC+ [26], our proposed method achie ves 12.5% relati ve improvement on open condition. These results confirm that using discriminativ e learn- ing and deep embedding features can improve the performance of speaker -independent speech separation. 5. Conclusions In this paper , we propose a speaker-independent speech sepa- ration method with discriminati ve learning based on deep em- bedding features. W e firstly train an DC network to e xtract deep embedding features. Then these features are used as the input of uPIT system to directly separate the different speaker sources. Moreov er , uPIT and DC are jointly optimized. Finally , the dis- criminativ e learning is applied to fine tuning the whole model. Results sho w that the proposed method outperforms uPIT base- line, with a relative improvement of 6.3%, 6.4% and 3.3% rel- ativ e improvements in SDR, SIR and SAR, respectively . In the future, we will explore phase enhancement based on the pro- posed method. 6. Acknowledgements This work is supported by the National Key Research & De- velopment Plan of China (No.2017YFB1002802), the NSFC (No.61425017, No.61831022, No.61771472, No.61603390), the Strategic Priority Research Program of Chinese Academy of Sciences (No.XDC02050100), and Inria-CAS Joint Research Project (No.173211KYSB20170061). Authors also thank Shuai Nie for his helpful comments on this work. 7. References [1] J. A. O’Sulliv an, A. J. Power , N. Mesgarani, S. Rajaram, J. J. Foxe, B. G. Shinncunningham, M. Slaney , S. A. Shamma, and E. C. Lalor , “ Attentional selection in a cocktail party en vironment can be decoded from single-trial ee g, ” Cerebral Cortex , vol. 25, no. 7, p. 1697, 2015. [2] D. W ang and G. J. Brown, Computational auditory scene analy- sis: Principles, algorithms, and applications . Wile y-IEEE press, 2006. [3] M. N. Schmidt and R. K. Olsson, “Single-channel speech sepa- ration using sparse non-negati ve matrix factorization, ” in INTER- SPEECH 2006 - Icslp, Ninth International Confer ence on Spoken Language Processing, Pittsbur gh, P a, Usa, September , 2006. [4] Y . Ephraim and D. Malah, “Speech enhancement using a mini- mum mean-square error log-spectral amplitude estimator, ” IEEE transactions on acoustics, speech, and signal pr ocessing , vol. 33, no. 2, pp. 443–445, 1985. [5] M. Cooke, J. R. Hershey , and S. J. Rennie, “Monaural speech separation and recognition challenge, ” Computer Speech & Lan- guage , v ol. 24, no. 1, pp. 1–15, 2010. [6] H. Erdogan and T . Y oshioka, “In vestigations on data aug- mentation and loss functions for deep learning based speech- background separation, ” Proc. Interspeech 2018 , pp. 3499–3503, 2018. [7] J. W ang, J. Chen, D. Su, L. Chen, M. Y u, Y . Qian, and D. Y u, “Deep extractor network for target speaker recovery from single channel speech mixtures, ” Proc. Interspeech 2018 , pp. 307–311, 2018. [8] Y . Luo and N. Mesgarani, “T asnet: time-domain audio separation network for real-time, single-channel speech separation, ” in Pr oc. ICASSP . IEEE, 2018, pp. 696–700. [9] C. Xu, W . Rao, X. Xiao, E. S. Chng, and H. Li, “Single channel speech separation with constrained utterance le vel permutation in- variant training using grid lstm, ” in 2018 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 6–10. [10] C. Fan, B. Liu, J. T ao, Z. W en, J. Y i, and Y . Bai, “Utterance- lev el permutation in variant training with discriminativ e learning for single channel speech separation, ” in Proc. ISCSLP . IEEE, 2018. [11] K. W ang, F . Song, and X. Lei, “ A pitch-aw are approach to single- channel speech separation, ” in 2019 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2019. [12] J. R. Hershey , Z. Chen, J. L. Roux, and S. W atanabe, “Deep clus- tering: Discriminative embeddings for segmentation and separa- tion, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing , 2016, pp. 31–35. [13] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation, ” in 2017 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2017, pp. 246–250. [14] D. Y u, M. Kolbk, Z. H. T an, and J. Jensen, “Permutation inv ari- ant training of deep models for speaker-independent multi-talker speech separation, ” in IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing , 2017, pp. 241–245. [15] M. Kolbæk, D. Y u, Z. T an, J. Jensen, M. Kolbaek, D. Y u, Z. T an, and J. Jensen, “Multitalker speech separation with utterance-lev el permutation in variant training of deep recurrent neural networks, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr o- cessing (T ASLP) , vol. 25, no. 10, pp. 1901–1913, 2017. [16] Z.-Q. W ang, J. Le Roux, and J. R. Hershe y , “ Alternative objecti ve functions for deep clustering, ” in 2018 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 686–690. [17] Y . Luo, Z. Chen, J. R. Hershe y , J. Le Roux, and N. Mesgarani, “Deep clustering and conventional networks for music separa- tion: Stronger together, ” in 2017 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2017, pp. 61–65. [18] Y . W ang, A. Narayanan, and D. L. W ang, “On training targets for supervised speech separation, ” IEEE/ACM T rans Audio Speech Lang Pr ocess , vol. 22, no. 12, pp. 1849–1858, 2014. [19] H. Erdogan, J. R. Hershey , S. W atanabe, and J. L. Roux, “Phase- sensitiv e and recognition-boosted speech separation using deep recurrent neural networks, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , 2015, pp. 708–712. [20] J. Garofalo, D. Graff, D. Paul, and D. Pallett, “Csr-i (wsj0) com- plete, ” Linguistic Data Consortium, Philadelphia , 2007. [21] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, and M. Devin, “T ensorflow: Large-scale machine learning on heterogeneous distributed sys- tems, ” 2016. [22] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” Computer Science , 2014. [23] E. V incent, R. Gribon val, and C. F ´ evotte, “Performance measure- ment in blind audio source separation, ” IEEE transactions on au- dio, speec h, and language processing , vol. 14, no. 4, pp. 1462– 1469, 2006. [24] A. W . Rix, M. P . Hollier , A. P . Hekstra, and J. G. Beerends, “Per- ceptual evaluat ion of speech quality (pesq) the new itu standard for end-to-end speech quality assessment part i–time-delay com- pensation, ” Journal of the Audio Engineering Society , vol. 50, no. 10, pp. 755–764, 2002. [25] C. Xu, W . Rao, E. S. Chng, and H. Li, “ A shifted delta coef ficient objectiv e for monaural speech separation using multi-task learn- ing, ” in Pr oceedings of Interspeech , 2018, pp. 3479–3483. [26] Y . Isik, J. L. Roux, Z. Chen, S. W atanabe, and J. R. Hershey , “Single-channel multi-speaker separation using deep clustering, ” arXiv pr eprint arXiv:1607.02173 , 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment