End-to-end losses based on speaker basis vectors and all-speaker hard negative mining for speaker verification
In recent years, speaker verification has primarily performed using deep neural networks that are trained to output embeddings from input features such as spectrograms or Mel-filterbank energies. Studies that design various loss functions, including …
Authors: Hee-Soo Heo, Jee-weon Jung, IL-Ho Yang
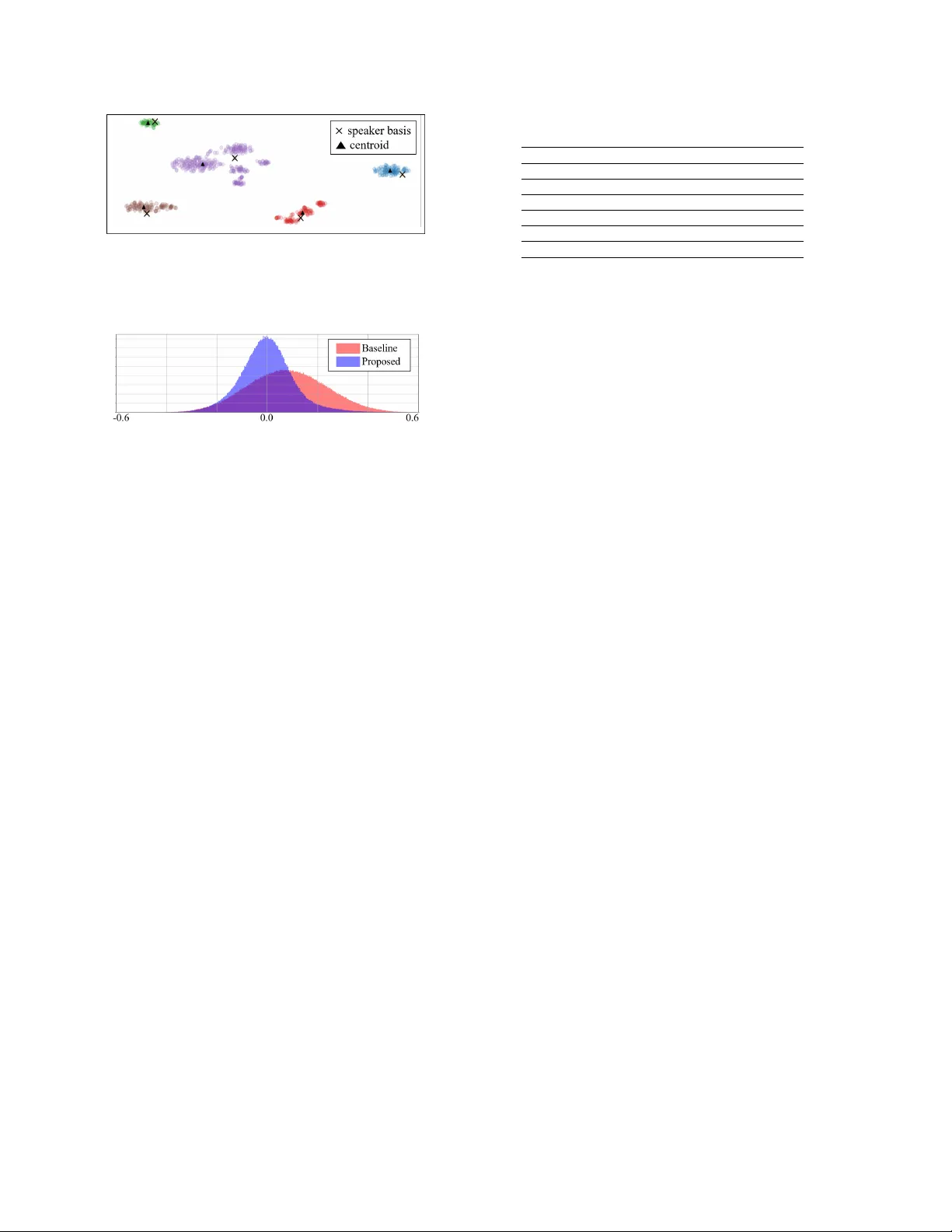
End-to-end losses based on speaker basis v ectors and all-speaker hard negati ve mining f or speak er verification Hee-Soo Heo, J ee-weon J ung , IL-Ho Y ang, Sung-Hyun Y oon, Hye-jin Shim, and Ha-Jin Y u † School of Computer Science, Uni versity of Seoul, South K orea zhasgone@naver.com, jeewon.leo.jung@gmail.com, heisco@hanmail.net, ysh901108@naver.com shimhz6.6@gmail.com, hjyu@uos.ac.kr Abstract In recent years, speaker verification has primarily performed us- ing deep neural networks that are trained to output embeddings from input features such as spectrograms or Mel-filterbank en- ergies. Studies that design various loss functions, including metric learning hav e been widely explored. In this study , we propose two end-to-end loss functions for speaker verification using the concept of speaker bases, which are trainable parame- ters. One loss function is designed to further increase the inter- speaker variation, and the other is designed to conduct the iden- tical concept with hard negati ve mining. Each speaker basis is designed to represent the corresponding speaker in the process of training deep neural networks. In contrast to the con ven- tional loss functions that can consider only a limited number of speakers included in a mini-batch, the proposed loss functions can consider all the speak ers in the training set regardless of the mini-batch composition. In particular, the proposed loss func- tions enable hard negati ve mining and calculations of between- speaker variations with consideration of all speakers. Through experiments on VoxCeleb1 and VoxCeleb2 datasets, we confirmed that the proposed loss functions could supplement con ventional softmax and center loss functions. Index T erms : Speaker verification, end-to-end loss, metric learning, speaker embedding 1. Intr oduction In recent years, se veral studies ha ve reported superior results us- ing deep neural netw orks (DNNs) for extracting speaker embed- dings compared to conv entional state-of-the-art i-vector-based [1] speaker verification systems [2–8]. Therefore, sev eral re- cent studies hav e mainly focused on designing loss functions to train DNNs to make them suitable for speaker verification. W an et al. proposed a generalized end-to-end (GE2E) loss func- tion based on centroids, which are the a verage embeddings for each speaker , to train DNNs with higher generalization perfor- mance [5]. Li et al. applied a loss function based on angular softmax, which was proposed for face recognition [9], to create an angular mar gin between speak ers in an embedding space [4]. The conv entional studies on loss functions mentioned abov e do not address the follo wing two problems. The first problem is that con ventional loss functions only consider a lim- ited number of speakers according to mini-batch composition. In the process of repeatedly training DNNs with mini-batches of a small size, the parameters of a network could be biased to † Corresponding author This work was supported by the T echnology Innovation Program (10076583, Development of free-running speech recognition technolo- gies for embedded robot system) funded By the Ministry of T rade, In- dustry & Energy(MO TIE, Korea) only the speakers included in one mini-batch. The second prob- lem is that excessi ve ov erhead occurs in performing hard neg- ativ e mining, which is important in metric-learning-based loss functions [10]. Hard negati ve mining is known to have a signif- icant impact on the performance of metric learning. Howe ver , it is usually performed at regular intervals because of practical issues. Ideally , hard negati ve mining should be conducted for each mini-batch. This is because hard negati ve samples will change as weight parameters are updated e very mini-batch. Al- though GE2E has partially solved these problems, there is a lim- itation that only few speakers can be considered by hard neg a- tiv e mining in GE2E. In this paper , we propose loss functions based on speaker bases to handle these problems. The speaker bases refer to the column vectors of the weight matrix of the output layer . This definition stems from the fact that since the column vectors rep- resent speakers in embedding space (output of the last hidden layer), each column vector can be considered as a basis for that speaker . This concept can be considered rather a general ap- proach because it can be applied to any DNN-based speaker embedding extraction system that comprises a fully-connected code layer . W e expect that it would be possible to train all speakers simultaneously and perform hard negati ve mining in ev ery mini-batch using the loss function based on the speaker bases. 2. Related works In this section, we introduce v arious e xisting loss functions that can be used to train speaker verification systems. These loss functions are already successfully applied to speaker verifica- tion and the face recognition field. 2.1. Softmax-based loss function The softmax-based loss function is widely used to train DNNs for identification purposes. Generally , when the softmax-based loss function is exploited for speaker verification, the output of the last hidden layer is used as the embedding of each utterance after training DNNs. The softmax loss function is calculated as: L S = − M X i =1 log exp ( W T y i e i + b y i ) Σ N j =1 exp ( W T j e i + b j ) , (1) where e i and y i denote the embedding (output of the last hidden layer) of the i 0 th utterance and the corresponding speaker label, respectiv ely , M is the number of utterances, N is the number of speakers in the training set, W = [ W 1 , W 2 , ..., W N ] and b = [ b 1 , b 2 , ..., b N ] are the weight matrix and the bias vector of the output layer , respectiv ely , and exp ( · ) is the exponential function. 2.2. Center loss function The center loss function was proposed to reduce within-class variations to supplement the softmax-based loss function [11]. T o reduce within-class variations, loss is calculated based on the mean squared error between the embeddings of each utterance and the center embedding of the corresponding speaker . This loss function was successfully applied in the field of face recog- nition, and high performance improv ement was reported. The center loss function, defined in equation (2), is used in conjunc- tion with the con ventional softmax-based loss function in most cases. L C = λ 2 M X i =1 || e i − c y i || 2 2 , (2) where c i is the center embedding of the i 0 th speaker and λ is the weight factor of the center loss function. The center embedding of each speaker in the center loss function is not trained based on gradient descent, like other parameters of DNNs. Rather , it is trained by moving the center embedding by a scalar α based on the delta center value calculated using the following formula: ∆ c k = Σ M i =1 δ ( y i = k ) · ( c k − e i ) 1 + Σ M i =1 δ ( y i = k ) , (3) where δ ( condition ) = 1 if the condition is satisfied; other- wise, δ ( condition ) = 0 . 2.3. Additive mar gin loss function The additive margin softmax (AMsoftmax) loss function was proposed to replace the inner product operation of the softmax- based loss function with the cosine similarity operation [9] and widen the margin between each class in an embedding space [12]. The AMsoftmax loss function is calculated based on the cosine similarity , cos ( · , · ) , so that the embedding between each speaker has an additional mar gin of m , as follows: L AM S = − M X i =1 log exp ( s · ( cos ( W y i , e i ) − m )) exp ( s · ( cos ( W y i , e i ) − m )) + R i , (4) R i = Σ N j =1 ,j 6 = y i exp ( s · cos ( W y j , e i )) , (5) where s is a scaling f actor for stabilizing the training process of cosine similarity-based loss. This loss function is an improved version of the angular softmax function [9] and has been suc- cessfully applied to speaker recognition systems [4, 13, 14]. 2.4. Generalized end-to-end loss function The GE2E loss function, a recent one of the advanced versions of triplet loss, was proposed to reduce the distance between the embeddings of each utterance and the centroid embeddings of the corresponding speaker while increasing the distance from the centroid embeddings of other speakers [15]. The most sig- nificant characteristic of the GE2E loss function is that it does not calculate the distance between samples but calculates the distance between centroids by a veraging the embeddings from the same speaker . W an, Li et al. assumed that higher gen- eralization performance could be achieved through a distance comparison with centroid embeddings [15]. F or this purpose, the distance between the embedding of the i 0 th utterance of the j 0 th speaker and the centroid of the k 0 th speaker , S j i,k , is cal- culated as follows: S j i,k = w score · cos ( e j i , ˆ c k ) + b score , (6) where w score and b score are the trainable parameters for scal- ing and shifting scores. It is important to note that the centroid ˆ c k , in equation (6), is dif ferent from the center embedding, c k , in equation (2). Centroid embedding is calculated utilizing the embeddings of each speaker as follo ws: ˆ c k = 1 M k M k X i =1 e ki , (7) where M k is the number of utterances of the k 0 th speaker . The GE2E loss function is calculated based on S j i,k , as follows: L G = X j,i 1 − σ ( S j i,j ) + max 1
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment