A Survey on Food Computing
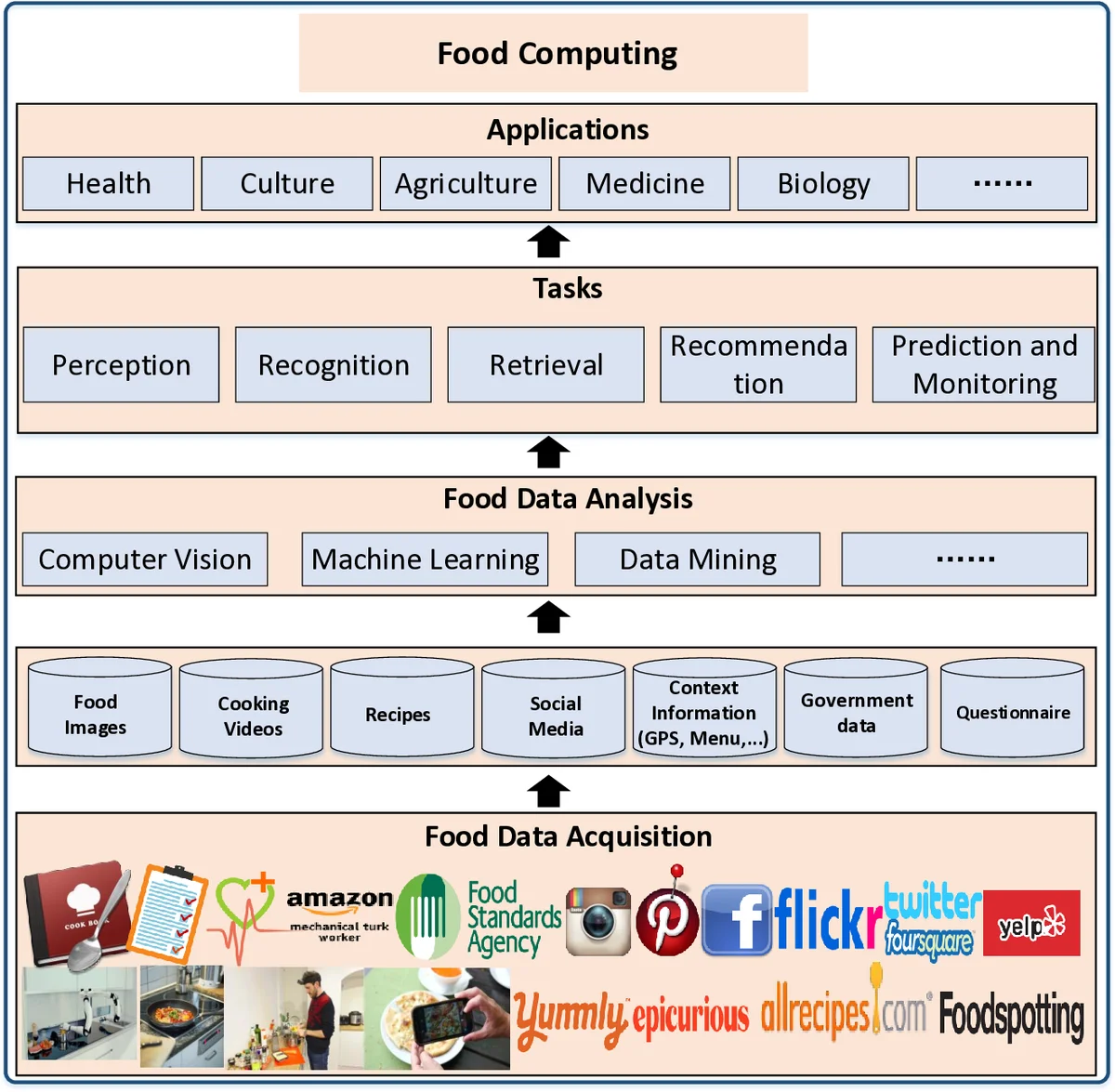
Food is very essential for human life and it is fundamental to the human experience. Food-related study may support multifarious applications and services, such as guiding the human behavior, improving the human health and understanding the culinary culture. With the rapid development of social networks, mobile networks, and Internet of Things (IoT), people commonly upload, share, and record food images, recipes, cooking videos, and food diaries, leading to large-scale food data. Large-scale food data offers rich knowledge about food and can help tackle many central issues of human society. Therefore, it is time to group several disparate issues related to food computing. Food computing acquires and analyzes heterogenous food data from disparate sources for perception, recognition, retrieval, recommendation, and monitoring of food. In food computing, computational approaches are applied to address food related issues in medicine, biology, gastronomy and agronomy. Both large-scale food data and recent breakthroughs in computer science are transforming the way we analyze food data. Therefore, vast amounts of work has been conducted in the food area, targeting different food-oriented tasks and applications. However, there are very few systematic reviews, which shape this area well and provide a comprehensive and in-depth summary of current efforts or detail open problems in this area. In this paper, we formalize food computing and present such a comprehensive overview of various emerging concepts, methods, and tasks. We summarize key challenges and future directions ahead for food computing. This is the first comprehensive survey that targets the study of computing technology for the food area and also offers a collection of research studies and technologies to benefit researchers and practitioners working in different food-related fields.
💡 Research Summary
The paper presents a comprehensive survey of “food computing,” a newly emerging interdisciplinary field that leverages large‑scale, heterogeneous food data to enable human‑centric services such as health management, behavior guidance, and cultural understanding. After motivating the need for such a field by highlighting the growing prevalence of obesity, diabetes, and other diet‑related health issues, the authors describe how the proliferation of social networks, mobile devices, and IoT sensors has generated massive collections of food images, recipes, videos, and diary entries.
Food computing is formally defined as the acquisition and analysis of diverse food data from disparate sources to support five core tasks: perception, recognition, retrieval, recommendation, and prediction/monitoring. The paper outlines a general framework in which data are gathered from five categories—official organizations and experts, recipe‑sharing platforms, social media, IoT devices, and crowdsourcing platforms—each providing distinct modalities (visual, textual, nutritional, contextual).
The survey then reviews the state‑of‑the‑art techniques for each task. Recognition focuses on deep‑learning models for image classification, multi‑label ingredient detection, and nutrient estimation. Retrieval covers both single‑modality (visual or textual) and cross‑modal (image‑to‑recipe) approaches, emphasizing embedding methods that align visual and textual representations. Recommendation systems are described as multi‑faceted, integrating personal preferences, health goals, and cultural factors to generate personalized meal plans or recipe suggestions. Prediction and monitoring exploit social media streams and sensor data to track public health trends, individual dietary habits, and disease risk. The authors stress the interdependence of these tasks—recognition outputs feed retrieval and recommendation pipelines, while predictive insights can refine recommendation strategies.
Key challenges identified include the high cost of accurate labeling, class imbalance, multimodal alignment difficulties, real‑time processing constraints, and privacy/ethical concerns. To address these, the authors propose future research directions: building large, high‑quality annotated datasets; developing unified multimodal and multitask learning frameworks; incorporating domain adaptation and explainable AI; establishing standardized benchmarks and baselines; and formulating policy, legal, and ethical guidelines for responsible food‑data use.
In conclusion, the survey positions food computing as a catalyst for innovation across health, culture, agriculture, and medicine, bridging computer science with traditional food sciences and offering a roadmap for researchers and practitioners to advance the field.
Comments & Academic Discussion
Loading comments...
Leave a Comment