Continuous-Time Markov Decision Processes with Controlled Observations
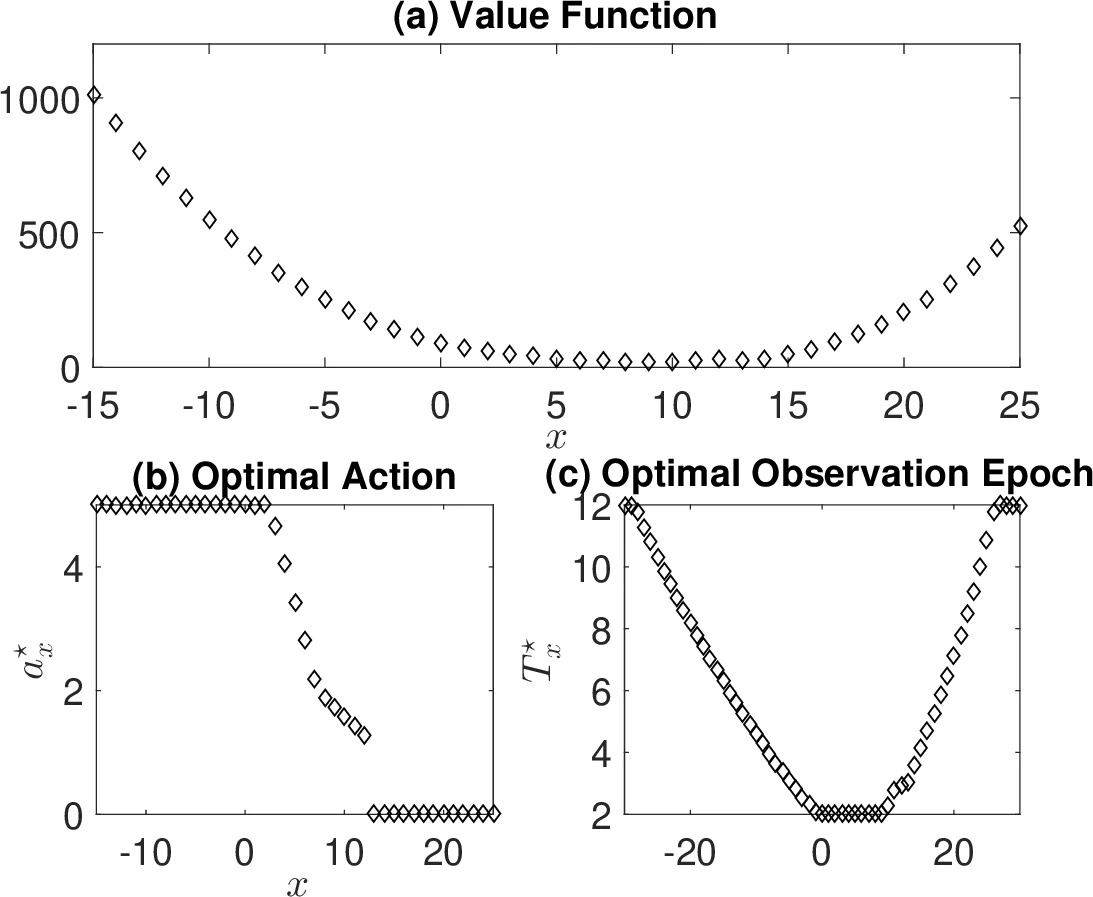
In this paper, we study a continuous-time discounted jump Markov decision process with both controlled actions and observations. The observation is only available for a discrete set of time instances. At each time of observation, one has to select an optimal timing for the next observation and a control trajectory for the time interval between two observation points. We provide a theoretical framework that the decision maker can utilize to find the optimal observation epochs and the optimal actions jointly. Two cases are investigated. One is gated queueing systems in which we explicitly characterize the optimal action and the optimal observation where the optimal observation is shown to be independent of the state. Another is the inventory control problem with Poisson arrival process in which we obtain numerically the optimal action and observation. The results show that it is optimal to observe more frequently at a region of states where the optimal action adapts constantly.
💡 Research Summary
This paper investigates a continuous‑time discounted jump Markov decision process (MDP) in which both the control actions and the observation epochs are decision variables. Unlike classical MDPs that assume continuous state observation, the authors consider a setting where the system state can be observed only at a discrete set of time points, and each observation incurs a cost. At each observation instant the decision maker must choose (i) the length of time until the next observation and (ii) a control trajectory to be applied during the inter‑observation interval. The central contribution is a unified theoretical framework that simultaneously optimizes observation scheduling and control actions.
The authors first formalize the underlying stochastic dynamics as a controlled Markov jump process (MJP). The transition rates λₓ are fixed for each state x, while the transition probabilities q(x′|x,a) may be influenced by a control function a(·) defined over the interval until the next observation. An observation interval Tₓ is also a controllable variable, bounded below by a minimum dwell time T_min. A stationary Markov policy is defined as a collection of pairs (aₓ(·), Tₓ) for every state x. The instantaneous reward r(X(t),A(t)) is integrated over each observation interval, discounted by a factor β, and an additional observation cost g(T) is added. By aggregating the reward over each interval, the authors define a “consolidated utility” (\bar r(x,a(·),T)). This aggregation transforms the original continuous‑time problem into a discrete‑time discounted MDP with state Zₖ = (X( (\bar T_k) ), (\tilde T_k)) and action Aₖ = (aₖ(·), Tₖ). The overall objective becomes
\
Comments & Academic Discussion
Loading comments...
Leave a Comment