A Study of Network Congestion in Two Supercomputing High-Speed Interconnects
Network congestion in high-speed interconnects is a major source of application run time performance variation. Recent years have witnessed a surge of interest from both academia and industry in the development of novel approaches for congestion control at the network level and in application placement, mapping, and scheduling at the system-level. However, these studies are based on proxy applications and benchmarks that are not representative of field-congestion characteristics of high-speed interconnects. To address this gap, we present (a) an end-to-end framework for monitoring and analysis to support long-term field-congestion characterization studies, and (b) an empirical study of network congestion in petascale systems across two different interconnect technologies: (i) Cray Gemini, which uses a 3-D torus topology, and (ii) Cray Aries, which uses the DragonFly topology.
💡 Research Summary
The paper addresses a critical gap in high‑performance computing (HPC) research: most prior work on network congestion relies on synthetic benchmarks or proxy applications that do not reflect the behavior of production workloads on real supercomputers. To bridge this gap, the authors develop an end‑to‑end monitoring and analysis framework and apply it to two petascale systems that employ different interconnect technologies: Cray Gemini (a 3‑D torus with static directional‑order routing) on the Blue Waters system, and Cray Aries (a DragonFly topology with adaptive routing) on the Edison system.
Data collection is performed with the Lightweight Distributed Metric Service (LDMS), which reads link‑level flow‑control counters from Cray’s gpcdr kernel module. Sampling intervals are one second on Edison and sixty seconds on Blue Waters, yielding a week‑long dataset of roughly 7.7 TB for Aries and 370 GB for Gemini. The Monet tool then processes these raw metrics, applying statistical aggregation and machine‑learning‑based anomaly detection to compute a congestion metric called Percent Time Stalled (PTS). PTS measures the fraction of time a link is unable to transmit because it lacks sufficient credits, making it a direct indicator of congestion in credit‑based networks.
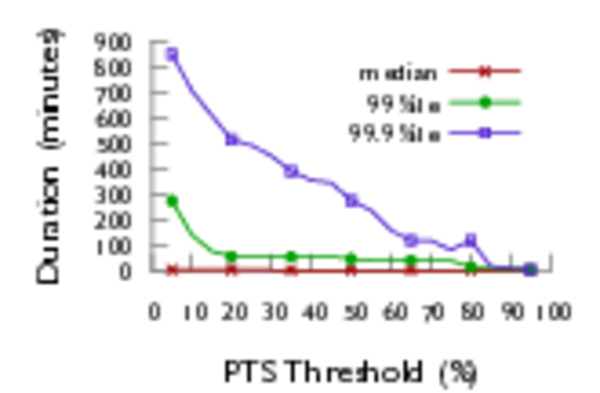
The analysis proceeds along three main axes. First, the impact of routing algorithms is quantified. By varying the PTS threshold (5 %–20 %) and measuring how long a link remains above that threshold, the authors find that Aries’ adaptive routing and low‑diameter DragonFly topology reduce the 99.9th‑percentile congested‑link duration by roughly two orders of magnitude compared with Gemini (≈1 minute vs. ≈400 minutes). This demonstrates that non‑minimal path selection can effectively offload hot spots that would otherwise persist in a static torus.
Second, the authors examine bandwidth heterogeneity. Gemini’s links are a mix of electrical (9.4 GB/s) and optical (15 GB/s) connections, while Aries combines electrical (1.75 GB/s) and optical (1.56 GB/s) links. In Gemini, X‑direction links (predominantly electrical) exhibit longer congestion episodes than Y or Z directions, indicating that uneven link capacities exacerbate contention. In Aries, optical “Blue” links experience shorter, less severe bursts than the electrical “Green” and “Black” links, suggesting that even modest bandwidth differences can shape congestion patterns.
Third, the study highlights the prevalence of long‑duration congestion events. Even at modest PTS thresholds (≤20 %), the 99.9th‑percentile duration exceeds one minute on both systems, providing a practical window for real‑time detection and mitigation. The authors argue that such detection can trigger actionable interventions—rank remapping, bully‑job isolation, or scheduler‑level rescheduling—using tools like TopoMesh that consume Monet’s diagnostic output.
Limitations are acknowledged: LDMS sampling is not perfectly synchronized across nodes, the choice of PTS threshold influences results, and a single week of data may not capture seasonal workload variations. Future work is proposed to extend the dataset across multiple weeks and systems, correlate congestion with specific MPI communication patterns, and explore closed‑loop adaptive routing that reacts to real‑time congestion signals.
In conclusion, the paper demonstrates that a scalable, production‑grade monitoring stack (LDMS + Monet) can reveal nuanced congestion behaviors on real supercomputers, that adaptive routing and topology design dramatically affect congestion severity, and that bandwidth uniformity remains a key design consideration. These findings provide concrete guidance for system administrators, application developers, and hardware architects aiming to reduce performance variability and improve scalability in next‑generation HPC platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment