PCNNA: A Photonic Convolutional Neural Network Accelerator
Convolutional Neural Networks (CNN) have been the centerpiece of many applications including but not limited to computer vision, speech processing, and Natural Language Processing (NLP). However, the computationally expensive convolution operations i…
Authors: Armin Mehrabian, Yousra Al-Kabani, Volker J Sorger
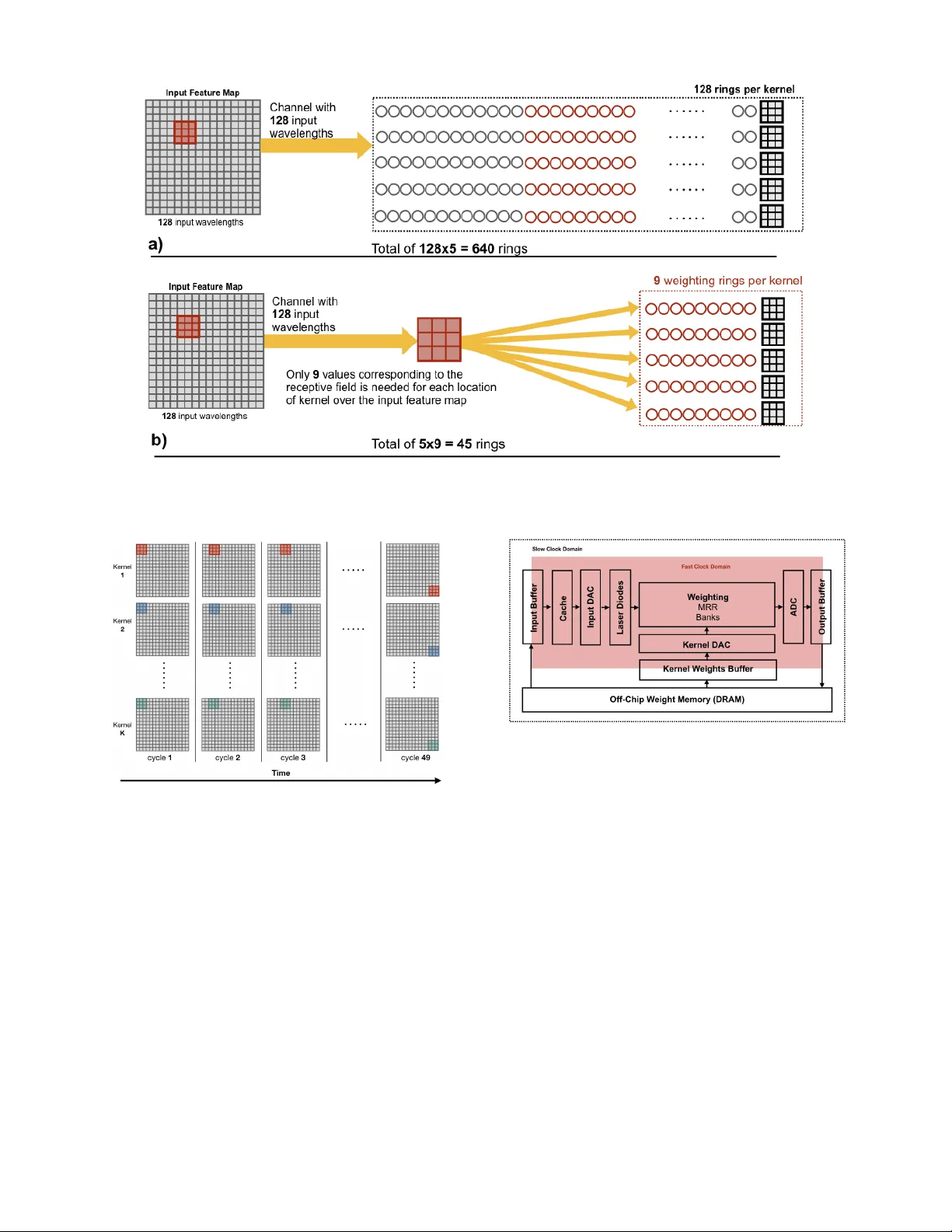
PCNN A: A Photonic Con volutional Neural Netw ork Accelerator Armin Mehrabian, Y ousra Al-Kabani, V olk er J Sorger , and T arek El-Ghaza wi Department of Electrical and Computer Engineering The George W ashington Uni versity , W ashington, DC, USA { armin,yousra,sorger ,tarek } @gwu.edu Abstract — Con volutional Neural Netw orks (CNN) ha ve been the centerpiece of many applications including but not limited to computer vision, speech processing, and Natural Language Processing (NLP). Howev er , the computationally expensi ve con volution operations impose many challenges to the perfor - mance and scalability of CNNs. In parallel, photonic systems, which are traditionally employed for data communication, have enjoyed recent popularity for data processing due to their high bandwidth, low power consumption, and reconfigurability . Here we propose a Photonic Conv olutional Neural Network Accelerator (PCNNA) as a proof of concept design to speedup the con volution operation for CNNs. Our design is based on the recently introduced silicon photonic micr oring weight banks, which use broadcast-and-weight protocol to perform Multiply And Accumulate (MA C) operation and move data through layers of a neural network. Here, we aim to exploit the synergy between the inher ent parallelism of photonics in the f orm of W avelength Division Multiplexing (WDM) and sparsity of connections between input feature maps and ker nels in CNNs. While our full system design offers up to more than 3 orders of magnitude speedup in execution time, its optical core potentially offer more than 5 order of magnitude speedup compared to state-of-the-art electronic counterparts. I . I N T R O D U C T I O N CNNs have been able to reach record-breaking perfor- mance in many tasks including but not limited to computer vision [1], speech recognition [2], and NLP [3]. Ho we ver , the success comes at the cost of high computational demands. Con volution operations account for roughly 90% of the total operations in a CNN [4]. While CNNs enjoy highly- parallel operations within a layer , data dependencies across layers challenge any attempt of inter-layer parallelization. The latter also poses scalability burdens in terms of power and throughput. Such challenges are even more magnified when electronics seem to be hitting fundamental power and speed limitations. Photonics is considered as a promising alternativ e to electronics both for communication and more recently for computation [5]. Photonic systems offer inherent parallelism potentials through their W av elength Division Multiplexing (WDM) capability . Low Light Matter Interaction (LMI) makes photonics a great choice for signal transmission to far distances with minute loss and ener gy . In addition, the linear nature of light can be e xploited to perform linear math- ematical operations such as multiplication and addition. This makes photonics an appealing choice for the implementation of CNNs due to their heavy reliance on MA C operation. c 2018 IEEE Previous work on CNN inference hardware has primarily focused on electronic implementations, either in the form of FPGA [6], [7] or ASIC designs [8], [9]. Despite some recent efforts to implement neural networks using optics [10], [11], to authors knowledge optical realization of CNNs has not been explored yet. In this paper we propose a photonic conv olution accelera- tor for CNNs inference-mode based on the recently proposed Micro-Ring-Resonator(MRR) banks and the broadcast-and- weight protocol [10]. W e summarize the main contributions of this work as: • A first proposed design for an optical CNN based on the recently proposed broadcast-and-weight protocol with MRR weight banks. • An optimization technique is proposed to reduce the number of microrings for the optical CNN realization. • An analytical frame work is introduced to identify the number of microrings for an y CNN layer and to estimate the ex ecution time. I I . C O N V O L U T I O NA L N E U R A L N E T W O R K S ( C N N S ) CNNs’ architecture enable them to receive inputs of higher dimensional shape and construct a hierarchy of feature repre- sentations. High-dimension inputs are inspected for presence of features (kernels) learned during a training process. This inspection process is carried out through a series of 4D con volution operations. Thus, the output of con v olution layer is a condensed set of values indicating the presence or absence of features in the input. For that, the outputs of layers in CNN is referred to as feature map. Unlike dense fully- connected layers a kernel in CNN only observes and operates on a narrow window of inputs referred to as recepti ve field. The size of this window equals the size of the kernel. Moreov er , the connections between the kernel values and the input feature map receptiv e field is one-to-one rather than all-to-all. In other words, in CNNs conv olutional layers enjoy sparsity of connections between input feature maps and kernels. This sparsity results in interesting characteristics including input feature map reuse. As the name suggests, a single feature map is reused as the conv olution input for many different kernels. In this paper we will exploit this property of CNNs as the conceptual foundation of our design. I I I . P H O TO N I C M I C RO R I N G R E S O N A T O R ( M R R ) B A N K S In [10] authors proposed a photonic ANN design based on the broadcast-and-weight protocol. Figure 1 shows the T ABLE I S U MM A RY O F C O N VO L UT I O N L A Y E R PA R AM E T E RS U S ED I N T H I S W O R K Parameter Description n Input feature map height and width m Kernel height and width p Padding size s Stride step size n c Input feature map number of channels N input Input feature map size N ouput Output feature map size N ker nel Size of kernel conceptual design of the broadcast-and-weight protocol. In this model MRR banks and photodiodes perform MA C operations while broadcast-and-weight protocol carry MA C results across layers. In broadcast-and-weight protocol each neuron output is multiplex ed onto a distinct light wav elength using Laser Diodes (LD). Multiple xed wa velengths are bun- dled together and placed on a wa ve guide to broadcast to the destination layer . At the destination layer , each neuron receiv es all the incoming wav elengths. Each wa velength is then multiplied in amplitude with its corresponding micror- ing. Multiplication is carried out by tuning rings in and out of resonance to a respectiv e laser wa velength. Later, a photodiode sums up all the incoming w av elengths into an aggregate photo-current. Fig. 1. Broadcast-and-weight protocol using MRR banks. Incoming bundled wav elengths propagate through the MRR banks. Each bank weights each wavelength by changing the tune of corresponding rings. A photodi- ode sums up all the wav elengths into a photo-current. The photo-current modulates a laser beam of wav elength λ m . All outgoing laser beams are multiplexed together to be broadcast to the next layer . I V . D E S I G N M E T H O D O L O G Y PCNN A takes advantage of MRR banks proposed in [10] to perform MA C operations. Howe ver , one major drawback of this scheme is that the number of microrings required to perform the multiplication part of MAC in each layer scales with N i × N i +1 , where N is the number of nodes in a layer and i is the layer number . This exponential increase in the number of microrings makes implementation of such networks challenging. For a kernel of size N ker nel , at each location of the kernel over the input feature map, only N ker nel values corresponding to the receptiv e field of input feature map take part in the con v olution. Therefore, using MRR banks, we only need to allocate N ker nel microrings for weighting and the rest of N input − N ker nel values can be ignored. W e will refer to these values as non-receptiv e field values for the rest of this paper . This ignoring of the non- receptiv e field values result in large savings in terms of both number of wa velengths that represent the input feature map and the number of microrings required in the following layer to demultiplex incoming wavelengths. Figure 2 conceptually shows the effect of filtering non-receptive field values in MRRs for con v olution operation (a) with no filtering of the non-receptiv e field values and (b) with non-recepti ve field values filtered. Current CNNs comprise of tens, if not hundreds, of layers with almost the same range of kernels per layer [1], [12], [13]. While filtering non-receptiv e field weight result in large savings in the number of microrings and respecti vely po wer consumption, implementing a full CNN using MRRs still requires large footprints and power consumptions. Therefore, in PCNNA we construct our design based on implementation of a single layer of CNN and virtually reusing it sequentially for dif ferent layers. In PCNN A conv olution layers are processed sequentially . Con volution result values of each layer are stored back to the off-chip DRAM. In addition, for each location of the kernels corresponding to a recepti ve field, partial con volutions are processed sequentially at the optical core of PCNNA. But, as multiple kernels share the same receptiv e field v alues, con volution computations for dif ferent kernels are performed in parallel. Figure 3 illustrates the parallel ex ecution of K kernels as they progress across the input feature map. At the high lev el PCNNA runs on two clock domains, a fast clock domain (5GHz), which runs the optical sub- systems and their immediate electronic circuitry , and a main slower clock domain to interface with the e xternal en vi- ronment. Figure 4 depicts the ov erall hardware architecture of our design. PCNN A consist of a weighting MRR bank repository , which its microrings tune to kernel weights. Kernel weights are initially stored in an of f-chip DRAM memory . Upon arriv al of a ne w layer request, kernel weights are loaded from the of f-chip DRAM into the K ernel W eights Buffer . Digital buf fered weights are then con verted into analog voltages, which control the tuning of the microrings in the MRR banks. Similarly , the input feature maps are initially stored in the off-chip DRAM. It should be noted that over the execution of one layer of a CNN the k ernel weights do not change. Howe ver , due to sequential progression of kernels ov er the input feature maps, the input values are regularly updated. For instance, in Figure 3 the v alues corresponding to kernels do not change until a new layer is loaded, but the input receptiv e field goes through 49 cycles. For each receptiv e field corresponding to a particular location of kernel a subset of input feature map v alues ( N ker nel ) are loaded into the Input Buffer . These b uffered values are then moved closer to the PCNNA core and stored in small but fast cache memory . Each v alue in the cache memory is then con verted to an analog signal using the input Digital to Analog Conv erters D ACs. Laser beams of different wa velengths generated by Laser Diodes (LD) modulate the Fig. 2. MRR bank for an input feature map of size 16 × 16 and 5 kernels of size 3 × 3 , a) without filtering the input feature map and b) with input feature map filtered to only pass through receptive field. It can be seen that taking advantage of narrow receptive field results in less number of total microrings. Fig. 3. Parallel execution of kernel as kernels sequentially progress over various locations of the input feature map. analog signal from the DA C. Laser beams fly through the MRR banks and their output photodiodes, which perform the multiplication and summation operations respecti vely . This process can be done quite fast (flight time of light) once all input values are loaded and conv erted to analog signals. Even the integrated photodiodes’ operating frequency at 0 bias voltage can be as high as tens of GHz if not hundreds [14]. Hence, the whole optical weighting and summation fits within a single clock c ycle of our fast clock domain. Lastly , computed con volution v alues are digitized back through the ADC and stored into the off-chip DRAM. The latter procedure repeats for ev ery location of kernels across the input feature map. For any consecutiv e location of kernels within a layer , only a fraction of input feature map values proportional to the size of the stride is required to be Fig. 4. Conceptual high-level hardware architecture PCNNA. The shaded areas, which include the core optical components run of a fast clock (5GHz). Buffers isolate the fast optical core from the outside slow clock en vironment. loaded into the cache. As a result, the bandwidth required for continuous loading of v arious receptive field values of input feature maps is minimized. V . E V A L U A T I O N S In this section we develop analytical models for the ev aluation of our design in term of the area consumed by microrings and the e xecution time. A. Micr oring Area For simplicity we assume that input feature maps are square-face volumes. As a result, the size of input feature maps and kernels are as follows, N input = n × n × n c (1) N ker nel = m × m × n c (2) where n and m are the size of input feature map and kernel in x and y direction, and n c is the number of channels. For a gi ven input feature map and a set of K kernels, the output feature map will ha ve the size, N output = ( ( n + 2 p − m ) s + 1) 2 × K (3) where p is the size of the padding , s is the size of the stride , and K is the number of kernels. Given the abov e input layer , without an y filtering of the non-receptiv e field v alues, the number of required microrings would be, N micror ings = N input × K × N ker nel (4) By filtering the non-receptiv e field values, the total number of rings will drop to: N micror ings = K × N ker nel (5) One important takeaw ay from equation 5 is that unlike equation 4 where the total number of rings scales with product of input size, number of kernels, and the kernel size, here the total number of rings scales linearly with the number of kernels K and its size N ker nel . For instance, the first con volutional layer of AlexNet with an input feature map of shape 224 × 224 × 3 and 96 kernels of shape 11 × 11 × 3 will require approximately 5 . 2 Billion microrings without filtering non-recepti ve field values. Howe ver , the same number once non-receptive field values are filtered would be 35 thousand. The latter translates into a saving of more than 150 k × in the number microrings. Similarly , the 4th layer of AlexNet , which accounts for the most number of kernel weights will require 3456 microrings. Considering a microring size of 25 µm × 25 µm [10], it takes an area of 2 . 2 mm 2 to fit all the microrings. Figure 2 compares the number of microring for dif ferent layers of AlexNet . Fig. 5. T otal number of microrings required in MRR banks for different con volutional layers of AlexNet for two cases, namely redundant microrings Filtered and Not-Filtered. B. Execution T ime Here we deriv e an analytical estimation of the ex ecution time for the PCNN A. As discussed in section IV The optical conv olution core of PCNN A is capable of computing con volutions of multiple kernels in parallel for a single receptiv e field within a single clock cycle. W e name this time windo w T mac i , which equals the time to complete all multiply-and-accumulate operations for a series of kernels ov er the receptive field location i th . The number of locations ( N locs ) kernels can have on the input feature maps is found by equation 3 di vided by its number of channels, N locs = N output K = ( ( n + 2 p − m ) s + 1) 2 (6) Therefore, without considering the electronic IO limita- tions, the computation time to perform a full con volution for for an input feature map and K kernels is, T conv = N locs × 1 f clock (7) It should be noted that T conv in equation 7 is independent of the number of kernels. This allows for increasing the number of kernels without sacrificing execution time. The only overhead associated with increased number of kernels in PCNN A is the allocation of more dedicated microrings per kernel. Howe ver , the number of microrings increase only linearly with the number of kernels. The total e xecution times based on a 5 GH z clock for each layer of Alexnet using PCNNA is listed in Figure 6. This result shows that the PCNNA core has the potential of speedups of up to 5 orders of magnitude in comparison to its cutting-edge electronic counterparts. But, a full system implementation performance of PCNNA is bound by the electronics, both at the front-end and the back-end. On the front-end, for Fig. 6. Comparison of execution time for conv olution layers of AlexNet . PCNN A(O) indicates the Optical core of PCNNA without electronic IO constraints. PCNN A(O+E) indicates full system comprising Optical and Electronic sub-systems. each iteration of kernels across the input feature map, the corresponding receptive field values are loaded from the off- chip DRAM into the buf fer . For each con volution layer, the first location of kernels on the input feature map require to load N ker nel = m × m × n c value into the buf fer . Howe ver , as the kernel moves across the input feature map, for subsequent locations of kernels, only a subset of N ker nel values equal to n c × s must be updated. The stride v alue s is usually 1 and in general smaller stride v alues are preferred over larger ones as they tend to retain more information from at the boundaries of kernels locations on inputs. Buffered inputs are cached in the SRAM memory [15], which has a 128 k b capacity that can store 8 thousand 16 bit values. The access time for the memory is 7 ns and it has a footprint of 0 . 443 mm 2 . Cached values need to be con verted to analog signals using Digital-to-Analog Con verters (DA C). In PCNN A D ACs operate at a rate of 6 GS a/s [16] while each takes up an area of 0 . 52 mm 2 . Our design comprises 1 kernel weight DA C and 10 input D A Cs. It is worth noting that for e very single set of kernel weights for a CNN layer , multiple input values need to be loaded corresponding to different locations of kernels over the input feature map. Here, analog input values from DA C modulate the laser beams with Mach Zehnder Modulators (MZM), which are usually faster than the 5 GH z clock. At the output, calculated con volutions are digitized with a 2 . 8 GS a/s Analog-to-Digital Con verter (ADC) [17] and stored into the of f-chip DRAM through the output buf fer . Considering all hardware specifications, the speed bottleneck of PCNNA is the DA C. For ev ery location of kernels over the input feature map a D A C needs to sequentially con vert digital inputs to analog v alues at each stride. This number for largest layer of AlexNet with a stride of 1 and 10 ( N DAC ) D ACs equals: N updated − inputs = n c × m × s N DAC = 384 × 3 × 1 10 ≈ 116 (8) W e calculated the execution time using this speed constraint. Figure 6 reports on the estimated execution time of con- volution layers of AlexNet on PCNNA in comparison with Eyeriss [18] and Y odaNN [19]. In Figure 6, PCNNA(O) indicates only the purely optical core execution times and PCNN A(O+E) represent the full system estimated execution times considering the electronic constraints. Even with elec- tronic IO speed restrictions the full PCNN A system still has the potential of saving up to more than 3 orders of magnitude in ex ecution time. V I . C O N C L U S I O N S In this paper we presented a proof of concept photonic ac- celerator for conv olutional neural netw orks. Our proposed ac- celerator is based the broadcast-and-weight protocol, which takes advantage of microring weight banks to perform mul- tiply and accumulate operations. In PCNNA, we exploited the sparsity of connections between input feature maps and kernels to reduce the number of microrings required to implement modern conv olutional neural networks. W e showed that the PCNN A optical core has the potential of achieving speedups of up to 5 orders of magnitude. Howe ver , electronic IO impose bandwidth limitations to efficiently transfer input data to the optical core. Y et, e ven when taking these electronic I/O limitations into account, we this optical accelerator sho ws a 3 orders of magnitude execution time improv ement ov er electronic engines. R E F E R E N C E S [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770–778. [2] A. Hannun, C. Case, J. Casper , B. Catanzaro, G. Diamos, E. Elsen, R. Prenger , S. Satheesh, S. Sengupta, A. Coates et al. , “Deep speech: Scaling up end-to-end speech recognition, ” arXiv preprint arXiv:1412.5567 , 2014. [3] D. Chen, A. Fisch, J. W eston, and A. Bordes, “Reading wikipedia to answer open-domain questions, ” arXiv preprint , 2017. [4] J. Cong and B. Xiao, “Minimizing computation in con volutional neural networks, ” in International confer ence on artificial neural networks . Springer , 2014, pp. 281–290. [5] D. A. Miller, “ Attojoule optoelectronics for lo w-energy information processing and communications, ” Journal of Lightwave T echnology , vol. 35, no. 3, pp. 346–396, 2017. [6] C. Zhang, P . Li, G. Sun, Y . Guan, B. Xiao, and J. Cong, “Optimizing fpga-based accelerator design for deep conv olutional neural networks, ” in Proceedings of the 2015 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2015, pp. 161–170. [7] N. Suda, V . Chandra, G. Dasika, A. Mohanty , Y . Ma, S. Vrud- hula, J.-s. Seo, and Y . Cao, “Throughput-optimized opencl-based fpga accelerator for large-scale con volutional neural networks, ” in Pr oceedings of the 2016 ACM/SIGD A International Symposium on F ield-Pr ogrammable Gate Arrays . A CM, 2016, pp. 16–25. [8] S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W . J. Dally , “Eie: ef ficient inference engine on compressed deep neural network, ” in Computer Architectur e (ISCA), 2016 ACM/IEEE 43r d Annual International Symposium on . IEEE, 2016, pp. 243–254. [9] A. Shafiee, A. Nag, N. Muralimanohar , R. Balasubramonian, J. P . Strachan, M. Hu, R. S. Williams, and V . Srikumar, “Isaac: A con- volutional neural network accelerator with in-situ analog arithmetic in crossbars, ” ACM SIGARCH Computer Ar chitectur e News , vol. 44, no. 3, pp. 14–26, 2016. [10] A. N. T ait, T . F . Lima, E. Zhou, A. X. W u, M. A. Nahmias, B. J. Shastri, and P . R. Prucnal, “Neuromorphic photonic networks using silicon photonic weight banks, ” Scientific Reports , vol. 7, no. 1, p. 7430, 2017. [11] Y . Shen, N. C. Harris, S. Skirlo, M. Prabhu, T . Baehr-Jones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englund et al. , “Deep learning with coherent nanophotonic circuits, ” Nature Photon- ics , vol. 11, no. 7, p. 441, 2017. [12] A. Krizhevsky , I. Sutskev er , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neur al information pr ocessing systems , 2012, pp. 1097–1105. [13] C. Sze gedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, A. Rabinovich et al. , “Going deeper with con volutions. ” Cvpr , 2015. [14] E. R. Fossum, D. B. Hondongwa et al. , “ A review of the pinned photodiode for ccd and cmos image sensors, ” IEEE J. Electr on Devices Soc , vol. 2, no. 3, pp. 33–43, 2014. [15] T . Fukuda, K. K ohara, T . Dozaka, Y . T akeyama, T . Midorika wa, K. Hashimoto, I. W akiyama, S. Miyano, and T . Hojo, “13.4 a 7ns- access-time 25 µ w/mhz 128kb sram for low-power fast wake-up mcu in 65nm cmos with 27fa/b retention current, ” in Solid-State Circuits Confer ence Digest of T echnical P apers (ISSCC), 2014 IEEE Interna- tional . IEEE, 2014, pp. 236–237. [16] C.-H. Lin, K. L. J. W ong, T .-Y . Kim, G. R. Xie, D. Major , G. Unruh, S. R. Dommaraju, H. Eberhart, and A. V enes, “ A 16b 6gs/s nyquist dac with imd¡-90dbc up to 1.9 ghz in 16nm cmos, ” in Solid-State Cir cuits Confer ence-(ISSCC), 2018 IEEE International . IEEE, 2018, pp. 360–362. [17] D. Stepanovic and B. Nikolic, “ A 2.8 gs/s 44.6 mw time-interleaved adc achieving 50.9 db sndr and 3 db effecti ve resolution bandwidth of 1.5 ghz in 65 nm cmos, ” IEEE Journal of Solid-State Circuits , vol. 48, no. 4, pp. 971–982, 2013. [18] Y .-H. Chen, T . Krishna, J. Emer , and V . Sze, “Eyeriss: An ener gy- efficient reconfigurable accelerator for deep con volutional neural net- works, ” 2016. [19] R. Andri, L. Cavigelli, D. Rossi, and L. Benini, “Y odann: An ultra- low power conv olutional neural network accelerator based on binary weights, ” in VLSI (ISVLSI), 2016 IEEE Computer Society Annual Symposium on . IEEE, 2016, pp. 236–241.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment