A unified decision making framework for supply and demand management in microgrid networks
This paper considers two important problems -- on the supply-side and demand-side respectively and studies both in a unified framework. On the supply side, we study the problem of energy sharing among microgrids with the goal of maximizing profit obt…
Authors: Diddigi Raghuram Bharadwaj, Sai Koti Reddy D, a
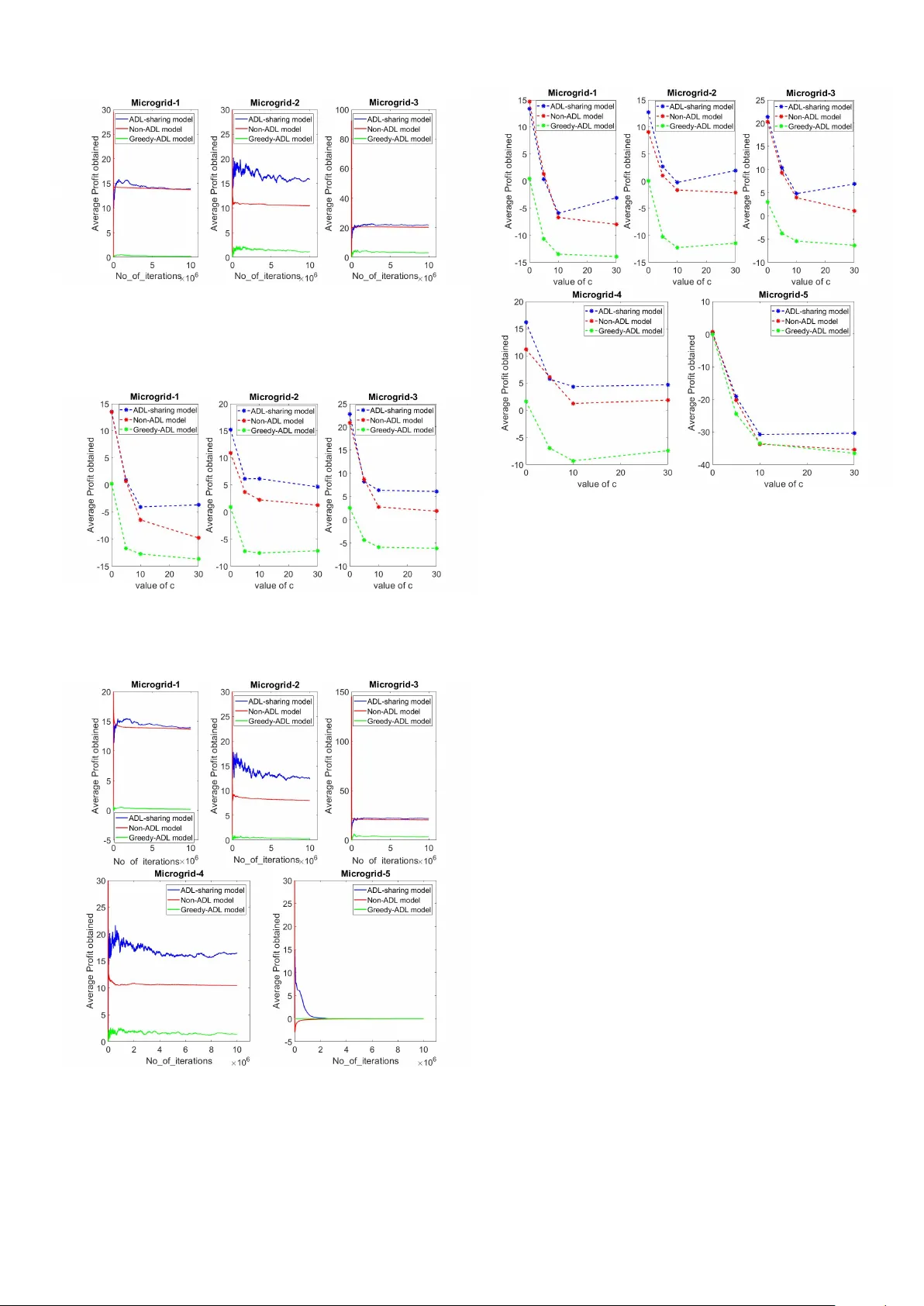
A unified decision making frame work for supply and demand management in microgrid networks D. Raghuram Bharadwaj † Department of CSA, Indian Institute of Science, Bangalore, India Email: raghub@iisc.ac.in D. Sai K oti Reddy † , Krishnasuri Narayanam IBM Research - India Email: saikotireddy@in.ibm.com Email: knaraya3@in.ibm.com Shalabh Bhatnagar Department of CSA and RBCCPS Indian Institute of Science, Bangalore, India Email: shalabh@iisc.ac.in ©2018 IEEE. Personal use is permitted, but republication/redistrib ution requires IEEE permission. This paper is accepted at IEEE SmartGridComm 2018 DOI: 10.1109/SmartGridComm.2018.8587514 Abstract —This paper considers two important pr oblems - on the supply-side and demand-side respectively and studies both in a unified framework. On the supply side, we study the problem of energy sharing among microgrids with the goal of maximizing profit obtained from selling power while at the same time not deviating much from the customer demand. On the other hand, under shortage of power , this problem becomes one of deciding the amount of power to be bought with dynamically varying prices. On the demand side, we consider the problem of optimally scheduling the time-adjustable demand - i.e., of loads with flexible time windows in which they can be scheduled. While pr evious works hav e treated these two problems in isolation, we combine these problems together and pr ovide a unified Markov decision process (MDP) framework f or these problems. W e then apply the Q-learning algorithm, a popular model-free reinf orcement learning technique, to obtain the optimal policy . Through simulations, we show that the policy obtained by solving our MDP model provides more profit to the microgrids. I . I N T RO D U C T I O N A microgrid is a networked group of distrib uted energy sources with the goal of generating, con verting and storing energy . While the main po wer stations are highly connected, microgrids with local power generation, storage and con version capabilities, act locally or share power with a fe w neighboring microgrid nodes [1]. This scenario is being en visaged as an important alternative to the con ventional scheme with lar ge power stations transmitting energy over long distances. In order to tak e full advantage of the modularity and flex- ibility of microgrid technologies, smart control mechanisms are required to manage and coordinate these distributed energy systems so as to minimize the costs of energy production, con- version and storage, without jeopardizing the central smart grid stability . Augmenting microgrid with smart controls ho wev er in volves addressing many problems. In this paper, we address two problems. (i) Supply-side management (SSM) problem: energy sharing among microgrids under stochastic supply and demand along with optimal battery scheduling of each microgrid and (ii) Demand-side management (DSM) problem: efficiently scheduling the time adjustable demand from smart appliances in a smart home environment along with non-adjustable demand. Our goal here is to maximize profit earned by microgrids from selling e xcess ener gy while maintaining a low gap between demand and supply . W e address these learning and scheduling † Both of these authors are joint first authors, in this paper problems by modeling them in the framew ork of Markov decision process (MDP) [2]. A simple example which explains the specific problem that we are trying to solve on the supply side using our proposed framew ork is the following. Consider three microgrids MG-1, MG-2, and MG-3 with their respective forecasted demand and supply profiles ov er two time intervals as in T able I. Here, supply denotes the power a vailable to the microgrid from its renew able energy sources (though, accurate prediction of the supply from renew able energy sources is a challenge). Let us assume for this example, that the microgrids do not buy power from the central main grid to which they are connected. Let the price of the power (per unit) in time interval 2 be higher than the price in time interval 1 (this information is not known to the microgrids a priori). Belo w are three possible po wer sharing scenarios, between these microgrids. T ABLE I: Sample forecasted demand & supply profiles Microgrid # Interval 1 Interval 2 demand supply demand supply MG-1 1 2 1 0 MG-2 1 0 1 1 MG-3 1 2 1 1 Scenario 1: Po wer sharing is not allowed between microgrids. Then there is power deficiency in microgrid MG-2 during the time interval 1 and in the microgrid MG-1 during the time interval 2. Scenario 2: Po wer sharing is allo wed between microgrids, MG-2 buys power from MG-1 in interval 1, MG-3 stores it’ s excess power in the battery in interval 1, and MG-1 buys power from MG-3 in interval 2. Scenario 3: Po wer sharing is allo wed between microgrids, MG-2 buys po wer from MG-3 in interval 1, and MG-1 stores it’ s excess po wer in the battery in interval 1 for consumption in interval 2. Scenario 2 addresses the power deficiency issue in Scenario 1. Ho we ver a more intelligent way of handling the power deficiency for MG-1 is possible in Scenario 3. In the Scenario 2, the profit obtained by MG-1 (which is negati ve as it sells the power when the price is low and buys it when the price is high) is less than the profit obtained by it in the Scenario 3 (which is zero). Our objecti ve, therefore in this framework, is to obtain an optimal power buying and selling policy for microgrids, so as to maximize the ov erall profits , in the presence of rene wable energy supply sources and dynamically varying power prices. An assumption we mak e in this w ork is that, in an y microgrid, when supply meets the demand in a giv en interval, it is to be understood that the demand represents the actual power consumption by the consumers, plus the electric power trans- mission and distribution losses. W e howe ver do not explicitly try to minimize the power transmission and distribution losses. Our framework inherently tries to minimize these power losses, by drawing po wer preferably from nearby peer microgrids as opposed to far -away microgrids. A. Supply-side management (SSM) pr oblem Cooperativ e energy exchange among microgrids is a popular technique in SSM for efficient energy distribution. Local energy sharing/exchange between microgrids has the following advan- tages: (a) it can significantly reduce po wer wastage that would otherwise result over long-distance transmission lines, and (b) it helps satisfy demand and reduce reliance on the main/central grid. Figure 1 shows a cooperati ve energy exchange model with multiple microgrids (on the distribution side of the network) that can cater to their individual local loads. Each microgrid controls its local sub-network through its controller (labeled C 1 , C 2 etc.) that mainly has access to its local state information. Distribution Network Main Grid M 1 M 2 M 3 Loads C 1 C 2 C 3 Microgrids Fig. 1: Cooperativ e Energy Exchange Model In classical power grids, system lev el optimization is done based on a centralized objectiv e function, where as a microgrid network has heterogeneous nature right from the manner in which electricity is generated such as from wind turbines, solar farms and diesel generators to energy storage devices such as batteries and capacitors. Because of this heterogeneity and the fact that energy can be shared between microgrids depending on requirements, one needs to consider distrib uted techniques to control and optimize a smart grid system with a distribution network catering to multiple microgrids. Related work : The literature considering the ener gy ex- change among the microgrids is vast. A surve y on game theo- retic approaches for microgrids is considered in [3]. This survey examines both cooperativ e energy sharing models as well as non-cooperativ e game models for distrib uted control of micro- grids assuming that the system model is known. Energy sharing among the microgirds is studied in [4] with the objectiv e of minimizing the energy bills for the microgrids. This work is later extended in [5] to consider the price-based demand response. [6], [7], [8] and [9] consider multi-agent systems for energy trading and control of microgrids under v arious objectives and formulations. Howe ver , most of the existing literature assumes that the underlying distributions for both supply and demand are known. But this doesn’t hold good especially in the context of microgrids with renew able energy sources as there is significant randomness in the amount of energy generated. Since models for energy dynamics are very unreliable [10] due to randomness at various stages, one needs to use model-free and data-dri ven algorithms to address these problems. Because of their model- free nature, Reinforcement Learning (RL) [11] approaches that are primarily data-driven control techniques play a significant role in solving these problems. The first step in this direction is to formulate the problem in the Markov Decision Process (MDP) framework. In section II, we provide the details of our proposed model for the energy trading problem among the microgrids in order to maximize profits, adhering to the a verage- cost MDP framew ork [12]. B. Demand-side management (DSM) pr oblem Load shifting is a popular technique used in demand-side management (DSM) [13]. It in volv es moving the consumption of load to different times within an hour , a day , or a week. It does not result in reduction in the net quantity of energy consumed, b ut simply in volves changing the time when the energy is consumed. Load shifting facilitates the customer in reducing the energy consumption cost and at the same time it helps the smart grid in managing the peak load. W ith increased use of smart appliances and smart home en vi- ronments, the concept of load shifting is becoming increasingly popular for the smart grid as the demand from smart appliances is time adjustable in general. One or more of these smart appliances collectively achiev e some activity in the smart home en vironment, called ADL (activity of daily li ving). It is possible to monitor and identify the ADLs in smart home en vironments [14]. W ith the help of smart home technology , it is possible to find the amount of load each ADL puts on the grid, and also the allowed time window during which the ADL would perform the activity (e.g., scheduling a washing machine for an hour to clean the clothes anytime between 3PM to 6PM). The demand from ADLs need not be met during a fixed time period, instead it could be met during any time period within a flexible time window . W ith the help of the advanced metering infrastructure (AMI) that provides a two-way communication between the utility and customers, it is possible to make a decision on when to schedule the ADL demand at the smart grid and con vey the same to the customer’ s smart meter . There is regular demand that needs to be met at fixed time periods, apart from the ADL related demand associated with any customer . This regular demand of a smart home will be called non-ADL demand in the rest of the paper . Similarly , the demand from ADL of the smart home will be called ADL demand. There is prior work around scheduling the ADL-demand us- ing the load shifting technique for handling peak load scenarios [15]. Howe ver , the authors make the unrealistic assumption of precisely kno wing the supply profile while doing such a scheduling of the ADL-demand. In this paper , we propose scheduling of ADL-demand using the load shifting technique with uncertainty in the supply profile generated (e.g., renew able energy sources like solar or wind being the primary sources of power generation). Our main contributions: (i) T o the best of our knowledge, we are the first to integrate both the demand-side and supply-side management problems of a network of microgrids in a unified Marko v decision process framew ork. W e apply Reinforcement Learning (RL) algorithms which do not require knowledge of the underlying system model to address these problems. Our algorithms are easy to implement. (ii) W e perform for the first time, optimal scheduling of ADL demand when both demand and power generation are stochastic in nature. Even though this is the most natural scenario, it had not been studied previously . The rest of the paper is org anized as follows. In section II, we discuss in detail about the problem formulation using the MDP framew ork. W e present in section III the Q-learning algorithm. In section IV, we present simulation experiments along with other algorithms for comparison. Finally , in section V, we provide the concluding remarks. I I . P R O BL E M F O R M U L A T I O N A N D T H E M D P M O D E L W e consider N microgrids denoted by 1 , . . . , N which are inter-connected through the central electric grid distribution network. Each microgrid comprises of the distributed small scale rene wable po wer generation sources that are equipped with energy storage devices. W e divide a day into t time units during which the decisions about power allocation are made. At every time instant t of a day , the i th microgrid controller C i has access to the following information: (a) T otal renewable energy ( r i t ) generated from it’ s energy sources. (b) Price per unit energy ( p t ) decided by the main grid at time t . (c) Accumulated non-ADL demand ( d i t ) from each load. (d) Set of all ADL jobs ( J i t ). J i t has the form { γ i 1 , . . . , γ i n } , where the j th ADL job γ i j = ( a i j , f i j ) . Here, a i j represents the number of units of energy required to finish the job, and f i j represents the number of future time instants remaining (after the current time instant t ) by when the controller C i can schedule the job γ i j without incurring a penalty . (e) Let B i represent the maximum battery capacity of the microgrid i and b i t the amount of power av ailable in the battery at time t . Here 0 ≤ b i t ≤ B i for any time instant t . From the abov e av ailable information, microgrid controller C i at ev ery time step t has to decide on the following choices: (a) Amount of energy it needs to buy (sell) from (to) the main grid. (b) Amount of energy it needs to buy (sell) from (to) the neighboring microgrids. (c) Amount of energy it needs to store (retrieve) into (from) its storage device. (d) The subset of ADL jobs it needs to schedule. Both the demand and ener gy generated at each microgrid are uncertain due to the random nature of loads ( d i t and J i t ) and the amount of rene wable energy generation ( r i t ) in time slot t . Therefore, this problem falls in the realm of Markov Decision Based on the state s t , RL agent takes actions u t and v t . Buys | v t | units to meet the ADL-demand Unscheduled ADL jobs are passed on to the next time period t + 1 If u t ≥ 0 Sells the power to the neighboring microgrids Buys | u t | units to meet the non-ADL demand. End If nd t − u t ≥ 0 Stores the remaining power in the battery End yes no yes no Fig. 2: Actions of an RL agent at each time instant t Process (MDP). In the ne xt subsection we provide the details of our MDP model. A. MDP frame work MDP is a general framework for modeling problems of dynamic optimal decision making under uncertainty . An MDP is a tuple < S , U , R , P > , where S is the set of all states, U is the set of feasible actions, R : S × U × S → R is the single- stage rew ard function and P is the state transition probability matrix. In RL, an agent interacts with the en vironment by observing state s t ∈ S and picking an action u t ∈ U . The ne w state s t +1 is obtained from the state transition probability P ( s t +1 | s t , u t ) and yields a rew ard g t = R ( s t , u t , s t +1 ) . The goal of the RL agent is to learn the optimal sequence { u t } of actions so as to maximize its av erage expected return (see Section II-B). W e begin by specifying the states, actions and single-stage rew ards, for our MDP model. 1) State space: The state s i t at time instant t for the microgrid i is the following tuple: s i t = ( t, nd i t , p t , J i t ) , (1) where the net demand nd i t = r i t + b i t − d i t . If nd i t > 0 , then there is excess of power after meeting the non-ADL demand and if nd i t < 0 , there is a deficit in power ev en to meet the non-ADL demand. The state also includes time t since optimal action can depend on it. For example, a microgrid operating on solar renew able generation can sell excess power during the morning as the solar power will be av ailable e ven during afternoon. But it may not be a good choice to aggressiv ely sell it in the evening as there will be no solar power generation during the night. 2) Action space: Let P i t be the power set of J i t , which consists of all possible combinations of the ADL jobs that can be scheduled at time instant t at microgrid i . W e define another set A i t , that denotes the total aggregated ADL demand for each element in P i t . For example, the j th element A i t ( j ) = P n k =1 ,γ i k ∈ P i t ( j ) a i k , where P i t ( j ) is the j th element in P i t and n is the total number of elements in P i t ( j ) . At each time instant t , the microgrid controller needs to make two decisions u i t and v i t . • When u i t is negati ve, | u i t | represents the amount of power drawn from the peer microgrids/maingrid to meet the non- ADL demand along with optionally storing in the battery (if the power is bought, it is first used to meet the non-ADL demand). • When u i t is positi ve, | u i t | represents the amount of power sold to the peer microgrids/maingrid from the battery storage and energy generated from renewable sources. • The second action v i t pertains to the scheduling decision of ADL jobs taken by microgrid controller C i . v i t is always non-positiv e, and | v i t | represents the power needed to meet the ADL demand in time interv al t at microgrid i . Formally , if the j th element of the set P i t is selected at time t , | v i t | is equal to A i t ( j ) . The feasible region for the action u i t is as follows: − min ( M , B i − nd i t + max 1 ≤ j ≤ 2 n A i t ( j )) ≤ u i t + v i t ≤ max (0 , nd i t ) , (2) where M denotes the maximum amount of power a microgrid can buy to meet the demand. This constraint is to maintain the stability of the main grid. The abov e bounds indicate that the microgrid can sell the surplus; or can buy energy to meet the non-ADL demand, ADL demand and to fill its battery . Note that there is flexibility for microgrids to buy (sell) this power from (to) the neighboring microgrids. If it needs to buy (sell) more power , only then it buys (sells) it from (to) the main grid. In this way , we allow for cooperation among the microgrids. Further this makes sure that the demand at the main grid is controlled at all the times. Let b J i t +1 be the new set of ADL jobs received by the microgrid i in the time interval t + 1 . Depending on the action v i t , not all the ADL jobs might have got scheduled in the time interval t . The ADL jobs which are not scheduled in the time interv al t but are eligible to be scheduled be yond time interval t are considered in the time interval t + 1 along with the new jobs b J i t +1 . Thus, we hav e J i t +1 = b J i t +1 ∪ e J i t , where e J i t = { ( a i j , f i j − 1) | ( a i j , f i j ) ∈ J i t and f i j > 0 } and J i t = J i t − P i t . The battery information is updated as follows: b i t +1 = max (0 , nd i t − u i t ) , (3) which denotes the power av ailable after meeting the non-ADL demand. Figure 2 illustrates the actions of a microgrid at ev ery time instant t . 3) Single-stage r ewar d function: W e want to maximize the profit of each microgrid obtained by selling power while re- ducing the demand and supply deficit. Our single-stage reward function has components for both the reward obtained by selling power and penalty for unmet demand. The single-stage reward function for the microgrid i at time t is as follows: g i ( s i t , u i t , v i t ) = p t ∗ ( u i t + v i t ) + c ∗ min (0 , nd i t − u i t ) − c ∗ n X k =1 I { f i k =0 } a i k . (4) The first term in (4) represents the loss/gain incurred for buying/selling power while the second and third terms represent the penalty incurred for not meeting the non-ADL and the ADL demands respectiv ely . Here, c ( ≥ 0) is the penalty per unit of unmet demand and I { f i k =0 } is the indicator random variable which equals one if f i k = 0 and is zero otherwise. Here c acts as a threshold between the profit of the microgrid and the penalty for not satisfying the demand. For example, when c = 0 , each microgrid takes decision to maximize its profit without satisfying any customer demand. On the other hand, if the value of c is very high, microgrids need to satisfy customer demand at every time instant as they incur huge penalty otherwise. Next, we provide the long-run average cost objectiv e function. B. A verag e cost setting The objecti ve is to maximize the expected a verage profit obtained by all the microgrids. The long-run av erage profit objectiv e function J i ( π ) of the microgrid i for a giv en policy π is giv en as follows: J i ( π ) := lim sup n →∞ 1 n E n X t =0 g i ( s t , u t , v t ) π ! , (5) where E ( . ) denotes the expected v alue. Here we view a policy π as the map π : S → A which assigns for any state s , a certain feasible action a . The goal of our RL agent i is to find π ∗ i = arg max π ∈ Π J i ( π ) , where Π is the set of all feasible policies. I I I . A L G O R I T H M In this work, we do not assume any model of the system (i.e., probability transition model of the demand, supply as well as renew able energy generation). W e apply Reinforcement Learning algorithms that do not assume any model of the en vironment to provide optimal solution. W e assume that we hav e access to a simulator that provides the state samples (i.e., Non-ADL and ADL demand, price) at ev ery time instant to the algorithm. This can be achiev ed, for instance, through smart meters deployed in households. W e employ the A verage-Cost Q-Learning algorithm, a popular RL method for solving the av erage cost problem in section II-B. W e apply the Relative V alue Iteration (R VI) based Q-Learning algorithm for each agent i , proposed in [12]. The algorithm is described below . Let Q i t ( s i t , u i t ) represent the Q-value estimate corresponding to state s i t and action u i t for the agent i in the t th iteration. The initial Q-values associated with all states and actions are set to zero i.e., Q i 0 ( s i , u i ) = 0 ∀ ( s, u ) and ∀ i . Subsequently , the Q-values are updated as follo ws (using similar notations as in [12]): Q i t +1 ( s i t , u i t ) = Q i t ( s i t , u i t ) + α ( t, s i , u i )( g i ( s i t , u i t , s i t +1 )+ max u Q i t ( s i t +1 , u ) − f ( Q i t ) − Q i t ( s i t , u i t )) , (6) where α ( . ) is the learning rate, g i ( s i t , u i t , s i t +1 ) is the rew ard obtained by taking an action u i t in state s i t and transitioning to the state s i t +1 and f ( Q i t ) is a Lipschitz continuous function satisfying suitable conditions specified in [12]. This term is subtracted from (6) to maintain stability of the update equation. It is shown in [12] that f ( Q i t ) con verges to the optimal average cost as t → ∞ . One such function f ( . ) that satisfies the conditions is max u Q i t ( s 0 , u ) , where s 0 is an arbitrarily chosen, fixed state. Therefore the final update equation for the Q-values for each agent i is as follows: Q i t +1 ( s i t , u i t ) = Q i t +1 ( s i t , u i t ) + α ( t, s i , u i )( g i ( s i t , u i t , s i t +1 )+ max u Q i t ( s i t +1 , u ) − max u Q i t ( s 0 , u ) − Q i t ( s i t , u i t )) , (7) At each iteration of this algorithm, the agent i selects an action u i t for the current state s i t using the − greedy polic y . That is, a random action is selected with probability and the action that maximizes the current Q-estimate is selected with probability 1 − . The simulator takes the current ( s i t , u i t ) pair and generates the current stage reward and the next state. In [12], it is shown that under an appropriate learning rate, the algorithm conv erges to the optimal Q-v alues which implicitly giv e the optimal policy . Each microgrid runs a version of this algorithm independently until conv ergence. The optimal policy of microgrid i is obtained as follows: π ∗ i ( s ) = arg max u Q i ∗ ( s, u ) (8) that is, the optimal action in state s is obtained by taking the maximum ov er all actions of the Q-values in state s . I V . S I M U L A T I O N E X P E R I M E N T S W e implement our model on networks with three and fi ve microgrids, respecti vely . In the three microgrid setup, tw o of the microgrids have solar renewable energy as the power supply source while the third operates on wind energy . In the fi ve microgrid network, two of the microgrids use solar renewable energy as the po wer supply source, two of them use wind renew able energy as the power supply source and one does not hav e any access to renewable energy . T o simulate the renewable generation, we use the RAPsim software [16]. RAPsim is an open source simulator for analyzing the power flow in micro- grids. It has a provision for simulating the renewable generation, which is the main feature that we use in our experiments. A. Implementation W e solve the MDP model described in section II and refer to it as the ADL-sharing model . For comparison purposes, we also solve the following MDP models. 1 1 The implementations of all the three MDP models are available at https://github .com/raghudiddigi/SmartGrid • Greedy-ADL model : In this model, microgrids exhibit greedy beha vior . They share power only after filling their respectiv e batteries fully . The actions u i t and v i t at each time instant t are bounded as follo ws: − min ( M ,B i − nd i t + max 1 ≤ j ≤ 2 n A i t ( j )) ≤ u i t + v i t ≤ max (0 , nd i t − B i ) . (9) Thus, if nd i t < 0 , decision is taken on the amount of power to b uy in order to satisfy the demand and to fill the battery . If nd i t > 0 , then the generated excess power by the microgrid i in time interval t is first used to fill the battery fully and if more power is left, it will be sold to the other microgrids/main grid. • Non-ADL model : In this model, ADL demand is treated as normal demand. Penalty is levied immediately if the demand is not met in the current time slot. B. Simulation setup W e used the RAPsim simulator to generate per hour re- new able energy data for each of the microgrids. W e used this data to fit a Poisson distribution for energy generation at each microgrid. W e limit the maximum renewable energy av ailable at each time instant to 8 units. The number of decision time intervals in a day is taken to be 4. For each time period, non-ADL demand ( d i t ) at each of the microgrids can be one of the following three values: 2, 4 or 6 units. The price ( p i t ) per unit energy value (in USD) is considered to be one of 5, 10 or 15. The transition probability matrix for non-ADL demand and the price values are generated randomly . For our experiments, the maximum size of the battery ( B i ) is set to 8 units and the maximum po wer that a microgrid can obtain from the main grid ( M ) is limited to 14 units. At each microgrid, we consider 3 ADL jobs, { γ i 1 = (1 , 2) , γ i 2 = (1 , 3) , γ i 3 = (2 , 4) } at the start of the day , where ADL job γ i j = ( a, b ) requires a units of demand within b ( > 0) time slots. In the N on − AD L model, the ADL demand is added to the demand at t = 1 each day . W e ran all our simulations for each of the follo wing c (penalty in USD per unit of unmet demand) values : 0, 5, 10 and 30, respectiv ely . C. Results The algorithms are trained for 10 7 cycles. W e used the av erage profit obtained by each microgrid as a performance metric to ev aluate the models. Figures 3 and 5 plot the average profit obtained for each microgrid in the two settings of three and fi ve microgrid networks, respecti vely , versus the number of iterations, when c = 0 in each case. W e can see that the algorithms show con vergence as the number of iterations increase. Figures 4 and 6 on the other hand plot the av erage profit obtained for each microgrid versus c (i.e., penalty per each unit of unmet demand) for all the three models. W e run the trained models for 1000 runs to obtain the av erage profit in each case. Fig. 3: Con ver gence of algorithms for the three models when c = 0 for the three microgrid network as a function of number of iterations. Fig. 4: Performance Comparisons of the three models on each microgrid in the three microgrid network as a function of c . Fig. 5: Con ver gence of algorithms for the three models when c = 0 for the fiv e microgrid network as a function of number of iterations. Fig. 6: Performance Comparisons of the three models on each microgrid in the fiv e microgrid network as a function of c . D. Discussion From our experiments we make the following observations: • When c = 0 , the microgrid controllers need not b uy power to satisfy the excess demand as they do not incur penalty for not meeting the demand. In the AD L − shar ing and N on − AD L models, we observe that all the controllers fill the battery when the price is low while they sell power when the price is high. Hence, the profit obtained is very high compared to the Greedy − AD L model where the power is bought to first fill the battery . • As the value of c increases, we expect that the profit earned by the microgrid would decrease. This is because the penalty for not meeting the demand would increase. From Figure 6, we observe that profit for c = 30 is slightly higher than when compared with the case of c = 10 for AD L − S har ing model. This is due to the high v ariance in the solar generation during the testing phase. When the value of c is set to 30, the demand at all times will be met without any penalty . • W e observe that the profit gap between the AD L − sharing method and the N on − AD L method increases as the value of c increases. This shows that the profit of the microgrids increases due to the flexibility a vailable to the controllers in scheduling the demand by following the ADL − shar ing model. • The sharing among the microgrids happens as follows: A microgrid operating on solar renewable energy source in the second time period shares the excess power with the other microgrids, as it generates more po wer as the day progresses. At the same time, a microgrid operating on wind renewable energy source buys power to store in its battery , if it expects more demand than the po wer it generates in future time periods. From the abov e discussion we conclude that our proposed AD L − shar ing model provides more profits by exhibiting the following intelligent behavior: (a) Schedules few of the ADL jobs at the beginning, few at the end and few in the middle of their allowed ex ecution time window to exploit flexible nature of the ADL demand. (b) Microgrids do not sell all of their surplus ener gy to the other microgrids if there is more demand than supply in the future (particularly , solar microgrids sell excess energy during the midday but not at the end of the day). V . C O N C L U S I O N Providing a unified solution frame work for modeling both demand-side management problem (scheduling ADL jobs) and supply-side management problem (enabling cooperative energy exchange among the microgrids) is a challenging task, particu- larly when both demand and supply are considered stochastic. W e have studied these two problems, for the first time, in a unified framew ork by using MDPs. Also, for the first time in the literature, we proposed the method of scheduling ADL demand at the microgrid lev el as a load shifting technique. RL algorithms provide an optimal solution methodology for solving MDP when the underlying model is not known. W e apply the Q- learning algorithm to maximize the profit earned by microgrids by selling excess energy while maintaining a low gap between demand and supply . Based on the simulation experiments, we show that the policy obtained by our MDP model (ADL-sharing model) consistently outperforms the policies obtained by other models. As future work, we would like to consider the pricing mechanism for microgrids. In the current model, the transaction of power is carried out at the price decided by the main grid. The pricing mechanism allows microgrids to bid for the selling price as well as b uying price. One can use RL agents to bid for adaptiv e prices in such a way that microgrids maximize their profits. Another important future work is to use RL algorithms with function approximation to scale the proposed algorithms. The challenge here is to select the appropriate features to obtain an optimal policy . R E F E R E N C E S [1] H. Farhangi, “The path of the smart grid, ” IEEE power and ener gy magazine , vol. 8, no. 1, 2010. [2] M. L. Puterman, Markov decision processes: discrete stochastic dynamic pr ogramming . John W iley & Sons, 2014. [3] W . Saad, Z. Han, H. V . Poor , and T . Basar, “Game-theoretic methods for the smart grid: An overvie w of microgrid systems, demand-side management, and smart grid communications, ” IEEE Signal Processing Magazine , vol. 29, no. 5, pp. 86–105, 2012. [4] T . Liu, X. T an, B. Sun, Y . Wu, X. Guan, and D. H. Tsang, “Energy man- agement of cooperative microgrids with p2p energy sharing in distribution networks, ” in Smart Grid Communications (SmartGridComm), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 410–415. [5] N. Liu, X. Y u, C. W ang, C. Li, L. Ma, and J. Lei, “Energy-sharing model with price-based demand response for microgrids of peer-to-peer prosumers, ” IEEE T ransactions on P ower Systems , vol. 32, no. 5, pp. 3569–3583, 2017. [6] M. Mao, P . Jin, N. D. Hatziargyriou, and L. Chang, “Multiagent-based hybrid energy management system for microgrids, ” IEEE Tr ansactions on Sustainable Ener gy , vol. 5, no. 3, pp. 938–946, 2014. [7] M. H. Cintuglu, H. Martin, and O. A. Mohammed, “Real-time implementa- tion of multiagent-based game theory rev erse auction model for microgrid market operation, ” IEEE Tr ansactions on Smart Grid , vol. 6, no. 2, pp. 1064–1072, 2015. [8] C. Dou, D. Y ue, X. Li, and Y . Xue, “Mas-based management and control strategies for integrated hybrid energy system, ” IEEE T ransactions on Industrial Informatics , vol. 12, no. 4, pp. 1332–1349, 2016. [9] T . Logenthiran, R. T . Naayagi, W . L. W oo, V .-T . Phan, and K. Abidi, “Intelligent control system for microgrids using multiagent system, ” IEEE Journal of Emer ging and Selected T opics in P ower Electronics , vol. 3, no. 4, pp. 1036–1045, 2015. [10] R. Zamora and A. K. Sri vasta va, “Controls for microgrids with storage: Revie w , challenges, and research needs, ” Renewable and Sustainable Ener gy Revie ws , vol. 14, no. 7, pp. 2009–2018, 2010. [11] R. S. Sutton and A. G. Barto, Reinforcement learning: An intr oduction . MIT press Cambridge, 1998, vol. 1, no. 1. [12] J. Abounadi, D. Bertsekas, and V . S. Borkar , “Learning algorithms for markov decision processes with average cost, ” SIAM J ournal on Control and Optimization , vol. 40, no. 3, pp. 681–698, 2001. [13] B. Davito, H. T ai, and R. Uhlaner, “The smart grid and the promise of demand-side management, ” McKinsey , 2010. [14] G. Baryannis, P . W oznowski, and G. Antoniou, “Rule-based real-time ADL recognition in a smart home environment, ” in Rule T echnologies. Research, T ools, and Applications - 10th International Symposium, RuleML 2016, Stony Br ook, NY , USA, July 6-9, 2016. Proceedings , ser . Lecture Notes in Computer Science, vol. 9718. Springer , 2016, pp. 325–340. [15] C. O.Adika and L. W ang, “Smart charging and appliance scheduling ap- proaches to demand side management, ” International Journal of Electrical P ower & Energy Systems , vol. 57, pp. 232–240, 2014. [16] M. Pochacker , T . Khatib, and W . Elmenreich, “The microgrid simula- tion tool rapsim: description and case study , ” in Innovative Smart Grid T echnologies-Asia (ISGT Asia), 2014 IEEE . IEEE, 2014, pp. 278–283.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment