An individualized super Gaussian single microphone Speech Enhancement for hearing aid users with smartphone as an assistive device
In this letter, we derive a new super Gaussian Joint Maximum a Posteriori based single microphone speech enhancement gain function. The developed Speech Enhancement method is implemented on a smartphone, and this arrangement functions as an assistive…
Authors: Ch, an K A Reddy, Nikhil Shankar
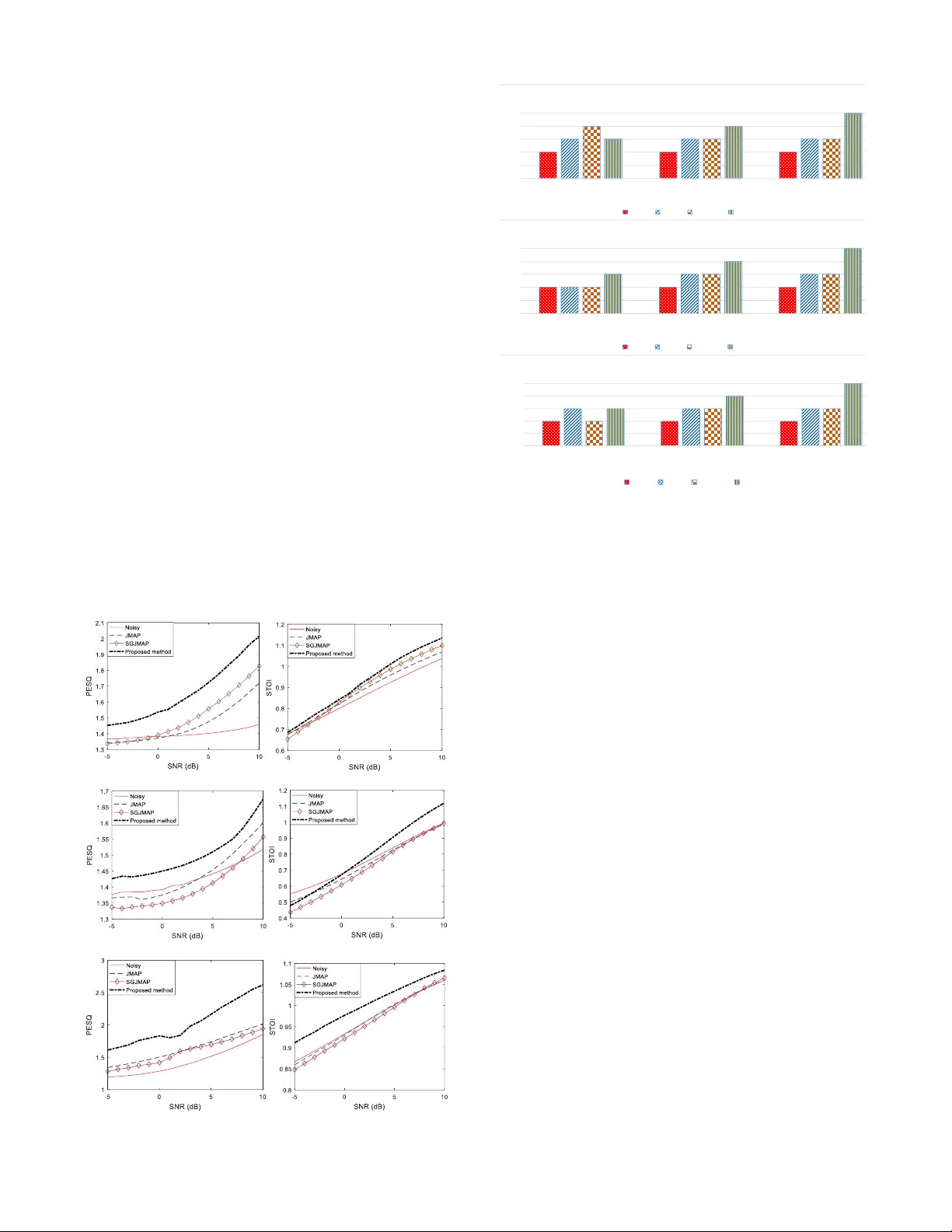
IEEE SIGNAL PROCESSIN G LETT ERS 1 Abstract — In this letter, w e deriv e a new sup er Gaussian Joint Maximum a Po steriori (SGJMAP) based single m ic rophone speech enhancement gain f unction. The developed S peech Enhance me nt method is implemented on a smartphone, and this arrangement functions as an assistive device to hearing aids. We introduce a “ tradeoff ” parameter in th e derived gain fu nction that allows the smartphone user to custo m ize their liste ning preference, by co ntrolling the amount of n oise suppression and speech distortion in real-time based on t heir le vel of hearing comfort perceived in noisy r eal w orld aco ustic env ironment. Objective quality and intelligibility m easures show the effectiveness o f the proposed method in comparison to benchm ark techniques considered in t his paper. Subjective results reflect the usefulness of the developed Speech Enhancement a pplication in real-w orld noisy conditions at signal to noise ratio levels of -5 dB, 0 dB and 5 dB. Index Terms — Super Gaussian, Speech Enh ancement, Hearing Aid, Smartphone, customizable. I. I NTRODUCTI ON cross the w orld, 360 milli on people suffer from hearing los s. Statistics reported by National Institute on Deafn ess and other Co mmunication Di sorders (NIDCD) show that in United States, 15% o f American adul ts (37million) aged 18 and o ver report some kind of hearing lo ss . Researchers in academia and industry ar e de veloping viable solutions for hearing impaired in the form of Hearing Aids (H A) and Cochlear Implants (CI). Speech Enhance ment (SE) is a key co m ponent in the HA pipeline. Existing H A devices do not ca rry the co mputational power to handle complex b ut indispensable si gnal processing algorithms [1-3]. Recently, HA m a nufacturers are u sing an external microphone in the form of a pen or a necklace to capture speech with higher S ignal to Noise Ratio (SNR) and wirelessly tr ansmit to HA [4]. The prob lem with these existing auxiliary devices is that they are too expensive a nd are not portable. One strong contending auxiliary device is our perso nal smartphone t hat has t he capabilit y to capture the noisy spee ch data using its microphone, perfor m complex computations a n d wirelessly tran smit the data to the HA d evice. Recen tly, extensively used smartpho nes such a s Apple iP hone and other Android smartp hones, are coming up with new H A features such as Live L isten by Apple [5], and many 3 rd party HA applications to e nhance the o verall quality and in telligibility of the speech per ceived by hearing impaired . Most o f these HA The National I nsti tute of the De afness an d Other Comm unication D isorders (NIDCD) of the National I nst itutes of H ealth ( NIH) und er award n umber applications on the smartphon e use single micro phone, to avoid audio Input/output latencies. The most chal lenging task in a single microphone SE is to suppress the backgrou nd noise without distorting the clean speech. Traditional methods like Spectral Subtraction [6 ] introduce musical noise due to ha lf -wave rec tification prob lem [7 ], which is p rominent at lower SNRs. This prob lem is solved by estimating t he clean speech magnitude spectru m by minimizing a statis tical error cr iterion, proposed b y Ephra im and Malah [8, 9] . In [10], a computationally efficient alterna tive is proposed for SE methods in [8, 9 ]. In this new method, speech is estimated b y applying th e jo int maximum a posteri or i (JMAP) estimation rule. In [1 3], super -Gaussian e xtension of the J MAP (SGJ MAP) is p roposed which is shown to outperform algorithms proposed in [8 - 10 ]. Super-Gaussi an statistical model of the cle an speech and noi se spect ral components (esp ecially Babb le) attains a lo wer mean sq uared error com pared to Gaus sian model. The challenge w ith existing single microphone SE techniq ues for HA ap plications is that the amount o f noise suppression cannot be controlled in real -time. Therefore, the am ount of speech distortion cannot be restrained below toler able level. Recent develop ments include SE based on deep neural networks (DNN) [11, 12], which requires rigorous training d ata. Although these methods yield supreme noise suppression, the p reservation of Spectro -temporal characteristics of spee ch, the quality and natural attribu tes remains a s a prime challe nge. Hence, these methods are n ot suitable for HA ap plications, where the hearing impaired prefers to hear speech that sounds natural , like a normal hearing. In this work, we introduce a parameter called ‘ tradeoff’ factor in the optimization of SGJMAP cost fun ction to estimate the clean speech magnitude spectr um. T he prop osed gain is a function o f tradeoff parameter that is designed to vary in real time allo wing the smartphone user to control t he a mount of noise suppr ession and s peech distortion. T he developed method is computatio nally inexpensive, and requires no training. Varying the tradeoff parameter has influence over performance of SE in reverberant and changing noi se conditions. Ob jective and subj ective evaluations of the pr oposed method are carried out to assess the effecti veness of the method against t he benchmark tec hniques co nsidered , and discuss t he overall usability of the developed algorithm . 1R01DC015430-01 supporte d this work. The content is solely the responsibility of the authors a nd does not ne cessarily represent the official view s of the NIH . Chandan K A Redd y, Nikhil Shankar, Gautam S B hat, Ram Charan, Stud ent Members, IEEE, Issa Panahi, Senio r Member, IEEE An individualized super Gaussian single microphone Speech Enhancement for hearing aid users with smartphone as an assistive device A IEEE SIGNAL PROCESSIN G LETT ERS 2 II. SGJMAP BASED SPEECH EN HANCEMENT In th e SGJMAP [13] method, a super Gaussian speec h m o del is used by co nsidering non-Gaussiani ty prop erty in spectr al domain noise r eduction frame work [14 , 15 ] and by kno wing that speech spectral co efficients ha ve a super-Gau ssian distribution. Spectral amplitude estimator using super Gaussian speech model allo ws the prob ability den sity function (PDF) o f the speec h spectral a m plitude to be approxi m ated by the function of two para meters and . These two para meters can be ad justed to fit the underlying PDF to the real distribut ion of the speec h magnitude. Considering the additive mixt ure model for noisy speech , w ith clean speech and noise , (1) The noisy Discrete Fourier Transfor m (DFT) coefficient of for frame is given by, (2) where an d are the clea n s peech and noise DFT co efficients respectively. In polar coordinates, (2) can be written as, (3) where , , are magnitude spectrums of noisy speech, clean speech a nd noise respectivel y. , , are the p hase spec trums o f noisy speech, clean spee ch and noise respectively. The goal of any SE technique is to estimate clean speech m a gn itude spectrum and its phase spectrum . We dro p in further discussion for brevity. The J MAP estimator of the magnitude and p hase j ointly maximize the pro bability of m agnitude and phase sp ectrum conditioned on the observed c omplex coefficient given b y, (4) ( 5) Assuming uniform distrib ution for phase, the joint P DF (6) The super-Gaussia n PDF [14 ] o f the am plitude spectr al coefficient with variance is given by, (7) Assuming t he Gaussian distribution for noise and super - Gaussian distributio n (7) for speech, (4 ) is given by [13 ], , (8 ) where is the a priori SN R and is the a posteriori SN R. is est imated usin g a voice activity detector (VAD) [16 ]. is t he esti mated instantaneous clean spee ch power spectral density. In [1 3], and is shown to give better r esults. The optimal phase spec trum is the noisy phase itself III. P ROPOSED REAL - TI ME CUSTOMIZA BLE SE GAIN Figure 1 shows the block diagram of t he pr oposed method. In (8), the gain of SGJMAP is a function of fo ur parameters . T he accuracy of depends on the VAD and the SE gain function of the previous frames. Th e values o f and can b e set empirically to achie ve good noise reduction without distorting the speech, as disc ussed in [1 6]. However, the opti m al values of these parameters in real world rapidly fluct uate with cha nging acoustical a nd enviro nmental conditions, o wing to the fact that the gain i s designed b y assuming su per-Gau ssian PDF for speech only in id eal acoustic conditions. In the presenc e of reverberation and noise (especially babble), the real PDF of speech received at the microphone c hanges. T herefore, having fixed and is not feasible to give rob ust noise reduction in d yn amic conditions . In o rder to compensate for these inaccuracie s in the model, we introduce a “ trade - o ff” p arameter into the cost function optimization for o ptimal clea n spee ch magnitude estimation. Taking nat ural logarit hm of (4), and d iff erentiating w ith r espect to gives, ( 9) Setting (9) to zero and substituting simplifies to ( 10) On si mplifying (10), the following quadratic eq uation is obtained, (11) Solving the above quadratic equation and writing in term s of and yields ( 12) The speech magnitude spectrum estimate is (13) Fig. 1. Block di agram of the propose d SE method IEEE SIGNAL PROCESSIN G LETT ERS 3 where (14) We k now f rom the literature that the phase is perce ptually unimportant [17 ]. Hence, w e consider th e nois y phase for reconstruction. T he final clean speech spectrum estimate i s (15) The time do main sequence is ob tained by taking Inver se Fast Fourier Transfor m (IFFT ) of . At very low values o f and , the gai n bec omes less dependent o n , which minimizes speech distortion while compromising on noise suppression. This m akes the al gorithm robust to inaccuracies in the estimatio n of . In most of the stati stical model based SE algorithms, t he accurac y of c lean speech magnitude spec trum directly depends on how accuratel y is estimated. Ho w ever, inaccurate results in distortion of speech a nd introduces musical noise in the background. The prop osed m ethod circumvents this prob lem b y allo wing t he user to select lo wer . At higher values of , the overall g ain decreases y ielding good noise suppression, but ends up attenuating s peech as well. Although, higher values of is not useful when there is speech of interest, but it is use ful in conditions when the user is exposed to loud noisy environment with no speech of in terest. At , the proposed method reduces to SGJMAP. Setti ng app ropriate intermediate values for yields noise s uppression with considerable speech d istortion. IV. R EAL - TIME I MPLEMENTATION ON SMARTPH ONE TO FUNCTIO N AS AN ASSI STIVE DEVICE TO HA In this work, iPhone 7 running iOS 10.3 op erating s ystem is considered as an assistive dev ice to HA. T hough smartpho nes come with 2 or 3 mics, manufacturers onl y allo w default microphone (Fig ure 2) on iPhone 7 to capture the audio d ata, process the signal and wirelessly transmit t he enhanced signal to the HA de vice. The develo ped code ca n also run faultlessly in other iOS ver sions. Xco de [18 ] is used for coding and debugging of the SE algorithm. T he d ata is ac quired at a sampling rate o f 48 kHz. C ore Audio [16], an open source library from Apple w as used to carry out input/o utput handling. After i nput callback, the short data is converted to float and a frame size of 25 6 is used for the i nput buffer. Figure 2 sho ws a snapshot of the con figuration screen of the algorithm implemented on iPhone 7. When the switch butto n present is in ‘OFF’ m ode , the ap plication m erely plays back the aud io through t he smartp hone witho ut pro cessing it . Switching ‘ON’ the button enables SE module to pro cess the inco ming a udio stream by app lying t he p roposed noise suppression algorithm , on th e magnitude spectrum of nois y speec h. The enhanced signal is then played back t hrough the HA device. Initially when the switch is turned on, the algorithm uses co uple of seco nds (1 -2 sec) to estimate t he noise po wer. Therefore, we assume that there is n o speech activity at least for 2 s econds when the switch is turned on. Once the noise suppression is on, we h ave provided other parameters, which can be varied in real -tim e. In (14), the gain function depends on 5 different parameters among which and needs to be empirically deter mined. It is known t hat the optimal values of these parameters depend on the noisy signal and acoustic characteristic s [13]. A typical HA user do not have co ntrol over the noisy environment they are exposed to, and the co nditions change co ntinuously with time. Hence, it is no nviable to fix th e values of and irrespective of changing conditions. In our smartphone application, the user can control all three parameters and adjust to their comfort le vel of hearing. T hrough o ur experiments, w e deter mined that the amount of noise suppression and speech d istortion can b e largely controlled by varying , than var ying and . T he range o f and are from 0.5 to 3 and 0.0 1 to 1 respectively. The range of is fro m 0.1 to 5. At close to 0.5 yields speech with mi nimal di stortion, but the noise suppr ession is no t protruding. As we increase the value o f , the amount of noise suppression also increases. H owever, at higher values the perceptibility of speec h distortion becomes prominent. Therefore, it is critical to choose optimal to strike a balance in achievin g satisfactor y noise suppression with to lerable speech distortion. The p rocessing time for a frame o f 10 ms (480 samples) is 1.4 m s. T he computationally efficienc y of the proposed alg orithm allows t he smartphone app to consume very less power. T hrough our experi ments we found that a ful l y charged smartphone can run the application seamlessl y for 6.3 hours on iPhone 7 with 1960 mAh battery. We use Starkey live listen [20] to stream th e data from iPhone to the HA. The audio streaming is encoded for Bluetooth Low Energy consu mption. V. E XPERIMENTAL R ESULTS A. Objective Evalu ation: There are no algorithms that are developed to our kno wledge that pro vide si milar functionalit y o f ac hieving t he balance between noise suppression and speech distortion in real time without any pre or po st filtering. We therefore fix the values of few par ameters and evaluate the p erformance of the pro posed method by comparin g with JMAP [10] and SGJ MAP [13] method, as our two-benc hmark single micro phone SE techniques t hat have s hown promising r esults. Also, the developed method is a n i mproved exten sion of these t wo methods. The experimental evaluation s are performed for 3 different noise types: machinery, multitalker babble and traffic noise. The reported results are the average o ver 20 sentences Fig. 2. Snapsho t of the deve loped smartphone application IEEE SIGNAL PROCESSIN G LETT ERS 4 from HINT datab ase. For ob jective evaluation, all the files are sampled at 16 kHz and 20 ms frames with 50% overlap are considered. As objective evaluation criteria, we choose the perceptual evaluation of speech quality (PESQ) [21 ] f or speech quality measurement and sho rt time obje ctive intelligibility (STOI) [22] to measure speech intelligibility. PESQ r anges between 0.5 and 4 .5 , with 4 .5 being h igh p erceptual quali ty. Higher the scor e o f ST OI better is t he speech intelligibilit y. Figure 3 shows the plo ts o f PESQ and ST OI vers us SN R f or the 3 noise types. The best values o f and were empirically determined over large dataset as they largel y control t he statistical pr operties of the no isy signal. He nce, the y are no ise dependent. T he value of was set to 2.5, 2 and 1 .75 and w as set to 1 , 0.9 and 0.75 for multi tal ker babble, machinery a nd traffic n oise types respectively . The w as adjusted empiricall y to sim ultaneously give the best valu es f or both PESQ and STOI and for eac h noise type. PESQ values sho w statist ically significant improve ments o ver J MAP a nd SGJM AP SE methods for all th ree noise types considered. The STOI is close to that o f noisy speech for machinery and babble, but significantly improves for traf fic noise. Supporting files for these results can be fo und at ww w.utdalla s.edu/ssprl/hearin g- aid-projec t . Objective measures reemphasize the fact that the proposed meth od ar chives co nsiderable noise suppression without distorting speec h. B. Subjective test setu p and results: Although objec tive measures give usef ul evaluation res ults during the develop ment phase of our method, the y give very little infor mation ab out the u sability of our application b y the end user. We performed Mean Opinion Score (MOS) tests [2 3] on 15 expert nor mal hearing s ubjects who were presented with noisy speech and enhanced spee ch using the prop osed, J MAP and SGJM AP meth ods a t SN R levels o f -5 d B, 0 dB and 5 dB. The key contrib ution of this paper is in providing the user the ability to customize th e parameters for their listening preference. Before starti ng the actual tests, the subjec ts wer e instructed to set and for each noise type as per their preference. One key o bservation was, the preferred values of and varied across subj ects. This supp orts our claim that the d eveloped applicatio n is user custo mizable. T herefore, for each aud io file t he s ubjects w e re instructed to scor e in the range 1 to 5 with 5 bei ng e xcellent speech qualit y a nd 1 b eing b ad speech quality. The d etailed description of scoring procedure is in [23] . Subjective test results in Figure 4 illustrate the effectiveness of the p roposed method in reducing the background musical noise, simultaneously preserving the quality and intelli gibility o f the speech . We also conducted a field test o f our application in real w orld nois y co nditions, which change dynamical ly. Varying the and in r eal -time provides tremendous flexibilit y for the end user to control the perceived speech. VI. C ONCLUSION We develo ped a super Gaussian b ased single microphone SE technique by introducing a tra deoff factor in the cost functio n. The resu lting gai n allo ws us to strik e a balance between a m ount of noise suppression and speech distortion. T he proposed algorithm was implemented o n a smartpho ne device, which works as an assistive device for HA. Varying the tradeo ff enables the smartphone user to control the amoun t o f noi se suppression an d speech distortion. T he o bjective and subjective results exempli fy the usability of the met hod in real w orld noisy conditions. (a) Machinery noise (b) Multi talker Babble noise (c) Traffic noise Fig.3. Objective e valuation of spe ech quality and intel ligibility Fig. 4. Subject ive test results 0 1 2 3 4 5 -5 0 5 MOS SNR (dB) Machinery N oise Nois y JMAP SGJM AP Pr oposed Met hod 0 1 2 3 4 5 -5 0 5 MOS SNR (dB) Multi talk er Babble N oise Nois y JMAP SGJM AP Propos ed Method 0 1 2 3 4 5 -5 0 5 MO S SNR ( dB) T raffic N oise Noisy J MA P SGJMAP Propos ed Method IEEE SIGNAL PROCESSIN G LETT ERS 5 R EFERENCES [1] Y-T. Kuo, T-J. Lin, W-H Chang, Y-T Li, C -W Liu and S-T Young, “Complex ity -effective audito ry compensation for di gital hearing aids,” IEEE Int. Symp o n Circuits ad Systems (ISCAS) , May 2008. [2] T. J. Klasen, T. V Bogaer t den, M. Moonen, J. Wouters, “Binaur al Noise Reduction algorithms for hearing aids that preserve interaural time delay cues,” IEEE Trans. Signal Process , v ol. 55 , pp. 1579-1585, A pril 2007. [3] C. K . A . Reddy, Y. Hao, I. Panahi, “Tw o microphones spectral -coherence based speech enhance ment for hearing aids us ing smartphone as an assistive d evice,” IEEE Int. Conf. on Eng. In Medicne and B iology soc., Oct 2016. [4] B. E dwards, “T he future of Hearing Aid technol ogy,” Journal Li st, Trends Amplif , v.11(1): 31-45, Mar 2007. [5] https://support.apple .com/en-us/HT20399 0 [6] S. Boll, “Suppression of ac oustic noise in speech u sing spectral subtraction,” IEEE Trans. Acoustic, Speech a nd Signal Process , vol. 27, pp. 113-120, Apr 1979. [7] M. Berouti, M. Schwartz, and J. Makhoul , “Enhanceme nt of speech corrupted by ac o ustic noise,” Proc of IEEE Conf. on Acousti c SpeechSignal Pro cessing , pp. 208-211, Was hington D.C, 1979. [8] Y. Ephraim and D.Malah, “Speech en hancement using a minimum mean - square error shor t- time spe ctral amplitude e stimator,” IEEE Tr a ns. Acoustics, Speech, and Signal Processing , vol. 32, no. 6, pp. 1109 – 1121, 1984. [9] Y. Ephraim and D.Malah, “Speech en hancement using a minimum mean - square error log- spectral amplitude estimator,” IEEE Trans. Acoustics, Speech, and Sig nal Processing , vo l. 33, no. 2, pp. 443 – 445, 1985 . [10] P. J. Wolfe and S. J. Godsill , “Efficient alternatives to the Ephraim and Malah suppression rule for audio signal enhancement ,” EURASIP Journal on Applie d Signal Processi ng , vol. 2003, no. 10, pp. 1043 – 1051, 2003, special iss ue: Digital A udio for Multimed ia Communicatio ns T. [11] Y. Xu, J. Du, L- R. Dai, C - H. Lee , “An experime ntal study on sp ee ch enhancement based on deep neural n et works,” IEEE Signal Proc. Letters , pp. 65-68, Nov 2 013. [12] F . Weninger, J. R. Hershey, J. L. Roux,B. Schuller, “Discriminative ly trained recurrent neural networks for single- channel speech separatio n,” IEEE Global Conf . on Signal an d Inf Processing , Dec 2 014. [13] L otter, P. Vary , “Speech Enhancement by MAP Spectral Am plitude Estimation using a super- gaussian spee ch model,” EURASIP Journa l on Applied Sig. Pro cess , pp. 1110-1126, 2005. [14] R. Martin, “S peech enhanceme nt using MMSE short time spectral estimation with gamma distributed speech priors,” in Pr o c. IEEE Int. Conf. Acoustics, Speech, Signal Processing (ICASSP ’02) , vol. 1, pp. 253 – 256, Orlando, F la, USA , May 2002. [15] R. Martin and C. Breithaupt, “Speech enhanceme nt in the DFT domain using Laplacian speech priors,” in Proc. International Worksho p on Acoustic Echo and Noi se Control (IWAENC’03) , pp. 87 – 90, Kyoto , Japan, Septem ber 2003. [16] J. Sohn, N. S. Kim, and W. Sung, “A statistical model -based voice activity detection,” IEEE S ignal Processi ng Letters ., vol . 6, no. 1, pp. 1 – 3, 19 99. [17] P. Vary, “Noise suppression by spectral m agnitude estimation — mechanisms and theoretical lim its,” Signal Processing , vol. 8, no. 4, pp. 387 – 400, 1985. [18] https://developer .apple.com/xcode/ [19] https://developer .apple.com/library /content/docume ntation/MusicA u dio/ Conceptual/Core AudioOve rview/WhatisCore Audio/WhatisCore Audio.h tml [20] http://www.starkey .com/blog/2014/04/7-halo-f eatures-that-wil l-enhanse- every-listening-ex perience [21] A. W. Rix, J. G. Beerends, M. P Hol lier, A. P. Hekstra, “Perceptual evaluation of speech q uality (PESQ) – a new method for spee ch quality assessment of telephone netw orks and codecs,” IEEE Int. C onf. Acoust., Speech, Signal Pr ocessing (ICA SSP) , 2, pp. 749-752., May 2001. [22] C. H Taal, R. C . Hendricks, R. Heusdens, R. Jensen, “An algorithm for intelligibility prediction of time- fre quency we ighted noisy speech,” IEEE trans. Audio, Sp eech, Lang. Process . 19(7), pp. 2125-21 36., Feb 2011. [23] ITU- T R ec. P.830, “Subjective p erf ormance assessment of telephone - band and w ideband digital co decs,” 1996.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment