Self-Attention Networks for Connectionist Temporal Classification in Speech Recognition
The success of self-attention in NLP has led to recent applications in end-to-end encoder-decoder architectures for speech recognition. Separately, connectionist temporal classification (CTC) has matured as an alignment-free, non-autoregressive appro…
Authors: Julian Salazar, Katrin Kirchhoff, Zhiheng Huang
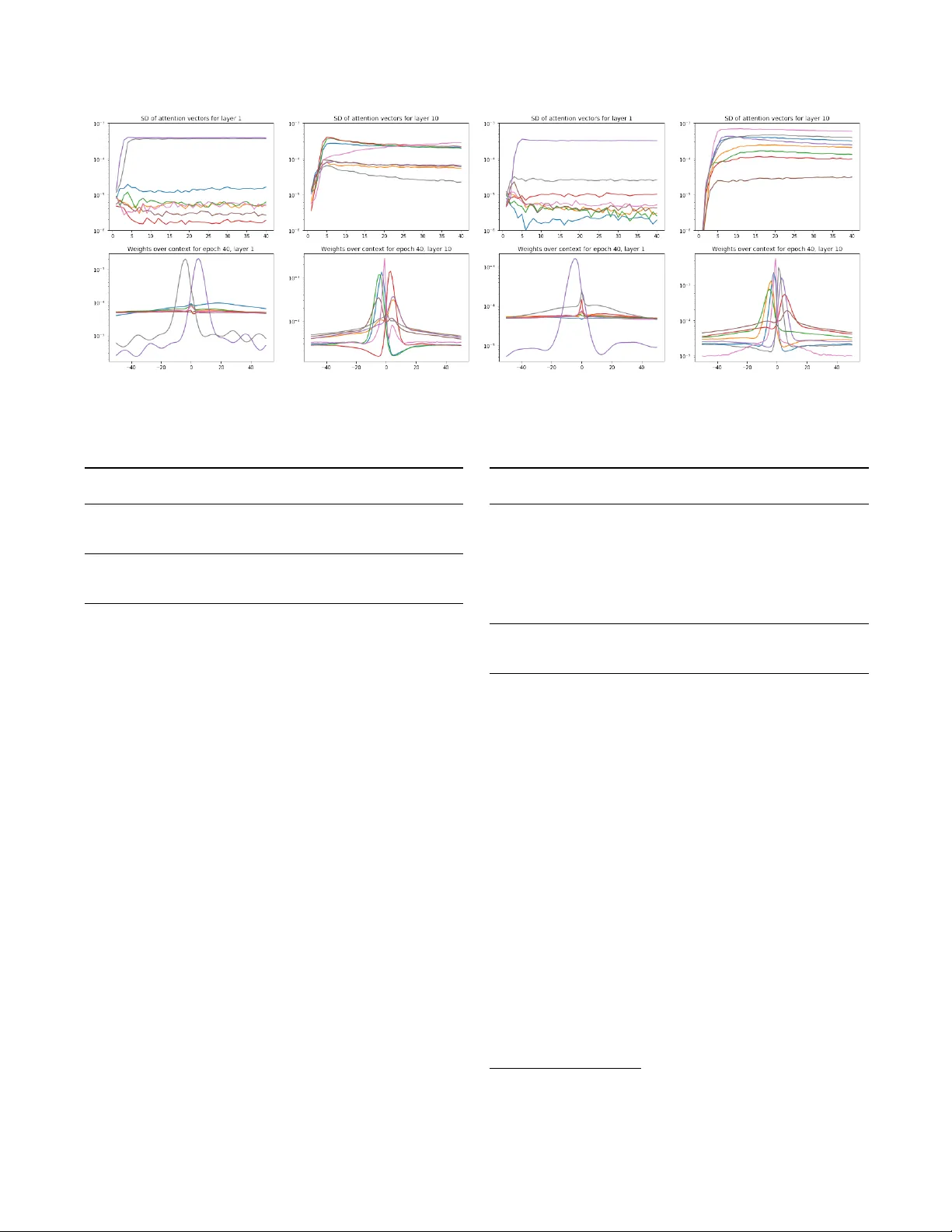
SELF-A TTENTION NETWORKS FOR CONNECTIONIST TEMPORAL CLASSIFICA TION IN SPEECH RECOGNITION J ulian Salazar ? Katrin Kir chhof f ? † Zhiheng Huang ? ? Amazon AI † Uni versity of W ashington { julsal,katrinki,zhiheng } @amazon.com ABSTRA CT The success of self-attention in NLP has led to recent applications in end-to-end encoder-decoder architectures for speech recognition. Separately , connectionist temporal classification (CTC) has ma- tured as an alignment-free, non-autore gressiv e approach to sequence transduction, either by itself or in v arious multitask and decoding framew orks. W e propose SAN-CTC , a deep, fully self-attentional network for CTC, and sho w it is tractable and competitiv e for end-to- end speech recognition. SAN-CTC trains quickly and outperforms existing CTC models and most encoder-decoder models, with char - acter error rates (CERs) of 4.7% in 1 day on WSJ e val92 and 2.8% in 1 week on LibriSpeech test-clean , with a fixed architecture and one GPU. Similar improv ements hold for WERs after LM decoding. W e motiv ate the architecture for speech, ev aluate position and down- sampling approaches, and explore how label alphabets (character , phoneme, subword) af fect attention heads and performance. Index T erms — speech recognition, connectionist temporal classification, self-attention, multi-head attention, end-to-end 1. INTR ODUCTION Connectionist temporal classification (CTC) [1] has matured as a scalable, end-to-end approach to monotonic sequence transduction tasks like handwriting recognition [2], action labeling [3], and au- tomatic speech recognition (ASR) [1, 4–11], sidestepping the label alignment procedure required by traditional hidden Markov model plus neural network (HMM-NN) approaches [12]. Howe ver , the most successful end-to-end approach to gener al sequence transduc- tion has been the encoder-decoder [13] with attention [14]. Though first used in machine translation, its generality makes it useful to ASR as well [15–20]. Howe ver , the lack of enforced monotonicity makes encoder-decoder ASR models difficult to train, often neces- sitating thousands of hours of data [18], careful learning rate sched- ules [19], pretraining [20], or auxiliary CTC losses [17, 20, 21] to approach state-of-the-art results. The decoders are also typically au- toregressi ve at prediction time [13, 22], restricting inference speed. Both approaches hav e con ventionally used recurrent layers to model temporal dependencies. As this hinders parallelization, Copyright 2019 IEEE. Published in the IEEE 2019 International Conference on Acous- tics, Speech, and Signal Processing (ICASSP 2019), scheduled for 12-17 May , 2019, in Brighton, United Kingdom. Personal use of this material is permitted. Howev er, permission to reprint/republ ish this material for advertising or promotional purposes or for creating new collectiv e works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works, must be obtained from the IEEE. Contact: Manager, Cop yrights and Permissions / IEEE Service Center / 445 Hoes Lane / P .O. Box 1331 / Piscataway , NJ 08855-1331, USA. T elephone: + Intl. 908-562-3966. later works proposed partially- or purely-conv olutional CTC mod- els [8–11] and con volution-hea vy encoder-decoder models [16] for ASR. Howe ver , con volutional models must be significantly deeper to retrieve the same temporal recepti ve field [23]. Recently , the mechanism of self-attention [22, 24] was proposed, which uses the whole sequence at once to model feature interactions that are arbitrarily distant in time. Its use in both encoder -decoder and feed- forward contexts has led to faster training and state-of-the-art results in translation (via the T ransformer [22]), sentiment analysis [25], and other tasks. These successes have moti vated preliminary work in self-attention for ASR. Time-restricted self-attention was used as a drop-in replacement for individual layers in the state-of-the- art lattice-free MMI model [26], an HMM-NN system. Hybrid self-attention/LSTM encoders were studied in the context of listen- attend-spell (LAS) [27], and the T ransformer was directly adapted to speech in [19, 28, 29]; both are encoder-decoder systems. In this work, we propose and ev aluate fully self-attentional net- works for CTC ( SAN-CTC ). W e are moti vated by practicality: self- attention could be used as a drop-in replacement in existing CTC- like systems, where only attention has been evaluated in the past [30, 31]; unlike encoder-decoder systems, SAN-CTC is able to pre- dict tokens in parallel at inference time; an analysis of SAN-CTC is useful for future state-of-the-art ASR systems, which may equip self-attentiv e encoders with auxiliary CTC losses [17, 20]. Unlike past works, we do not require con volutional frontends [19] or in- terleav ed recurrences [27] to train self-attention for ASR. In Sec- tion 2, we motiv ate the model and relev ant design choices (position, downsampling) for ASR. In Section 3, we v alidate SAN-CTC on the W all Street Journal and LibriSpeech datasets by outperforming ex- isting CTC models and most encoder-decoder models in character error rates (CERs), with fe wer parameters or less training time. Fi- nally , we train our models with dif ferent label alphabets (character , phoneme, subword), use WFST decoding to gi ve word error rates (WERs), and examine the learned attention heads for insights. 2. MODEL ARCHITECTURES FOR CTC AND ASR Consider an input sequence of T feature vectors, viewed as a matrix X ∈ R T × d fr . Let L denote the (finite) label alphabet, and denote the output sequence as y = ( y 1 , . . . , y U ) ∈ L U . In ASR, X is the sequence of acoustic frames, L is the set of graphemes/phonemes/wordpieces, and y is the corresponding ground-truth transcription ov er L . For CTC, one assumes U ≤ T and defines an intermediate al- phabet L 0 = L ∪ {−} , where ‘ − ’ is called the blank symbol . A path is a T -length sequence of intermediate labels π = ( π 1 , . . . , π T ) ∈ L 0 T . Paths are related to output sequences by a many-to-one map- ping that collapses repeated labels then remov es blank symbols: B : L 0 T → L ≤ T , e.g., ( a, b, − , − , b, b, − , a ) 7→ ( a, b, b, a ) . (1) In this way , paths are analogous to framewise alignments in the HMM-NN framework. CTC models the distribution of sequences by marginalizing o ver all paths corresponding to an output: P ( y | X ) = P π ∈B − 1 ( y ) P ( π | X ) . (2) Finally , CTC models each P ( π | X ) non-autoregressiv ely , as a se- quence of conditionally-independent outputs: P ( π | X ) = Q T t =1 P ( π t , t | X ) . (3) This model assumption means each P ( π t , t | X ) could be computed in parallel, after which one can do prediction via beam search, or training with gradient descent using the objectiv e L CTC ( X , y ) = − log P ( y | X ) ; the order-monotonicity of B ensures L CTC can be efficiently e v aluated with dynamic programming [1, 4]. 2.1. Recurrent and con volutional models In practice, one models P ( π , t | X ) with a neural network. As inspired by HMMs, the model simplification of conditional indepen- dence can be tempered by multiple layers of (recurrent) bidirectional long short-term memory units (BLSTMs) [1–4]. Howev er , these are computationally expensi ve (T able 1), leading to simplifications like gated recurrent units (GR Us) [8, 32]; furthermore, the success of the ReLU ( x ) = max(0 , x ) nonlinearity in pre venting v anishing gradi- ents enabled the use of vanilla bidirectional recurrent deep neural networks (BRDNNs) [5, 6, 33] to further reduce operations per layer . Con volutions over time and/or frequency were first used as ini- tial layers to recurrent neural models, beginning with HMM-NNs [34] and later with CTC, where they are vie wed as promoting in- variance to temporal and spectral translation in ASR [8], or image translation in handwriting recognition [35]; the y also serve as a form of dimensionality reduction (Section 2.4). Howev er , these networks were still bottlenecked by the sequentiality of operations at the re- current layers, leading [8] to propose row con volutions for unidirec- tional RNNs, which had finite lookaheads to enable online process- ing while having some future conte xt. This led to con volution-only CTC models for long-range tem- poral dependencies [9–11]. Howe ver , these models ha ve to be very deep (e.g., 17-19 con volutional layers on LibriSpeech [23]) to cov er the same context (T able 1). While in theory , a relatively local con- text could suf fices for ASR, this is complicated by alphabets L which violate the conditional independence assumption of CTC (e.g., En- glish characters [36]). W ide contexts also enable incorporation of noise/speaker contexts, as [27] suggest regarding the broad-context attention heads in the first layer of their self-attentional LAS model. 2.2. Motivating the self-attention layer W e now replace recurrent and conv olutional layers for CTC with self-attention [24]. Our proposed framework (Figure 1a) is built around self-attention layers , as used in the Transformer encoder [22], previous explorations of self-attention in ASR [19, 27], and defined in Section 2.3. The other stages are downsampling , which reduces input length T via methods like those in Section 2.4; embedding , which learns a d h -dim. embedding that also describes token posi- tion (Section 2.5); and projection , where each final representation is mapped framewise to logits o ver the intermediate alphabet L 0 . input X downsampling embedding × n layers selfattentionlayer positionwiseproj. alphabetdists. ∏ position encoding (a) SAN-CTC framew ork hiddenstates H multiheadattention layernorm positionwiseFFN layernorm SelfAttL yr( H ) (b) Self-attention layer Fig. 1 : Self-attention and CTC A layer’ s structure (Figure 1b) is composed of two sublayers . The first implements self-attention , where the success of attention in CTC and encoder-decoder models [14, 31] is parallelized by using each position’ s representation to attend to all others, giving a con- textualized representation for that position. Hence, the full receptive field is immediately av ailable at the cost of O ( T 2 ) inner products (T able 1), enabling richer representations in fewer layers. Model Operations per layer Sequential op- erations Maximum path length Recurrent O ( T d 2 ) O ( T ) O ( T ) Con volutional O ( k T d 2 ) O (1) O ( T /k ) Con volutional (strided/dilated/pooled) O ( k T d 2 ) O (1) O (log k ( T )) Self-attention O ( T 2 d ) O (1) O ( T ) Self-attention (restricted) O ( k T d ) O (1) O ( T /k ) T able 1 : Operation complexity of each layer type, based on [22]. T is input length, d is no. of hidden units, and k is filter/context width. W e also see inspiration from conv olutional blocks: residual con- nections, layer normalization, and tied dense layers with ReLU for representation learning. In particular, multi-head attention is akin to having a number of infinitely-wide filters whose weights adapt to the content (allowing fewer “filters” to suffice). One can also assign in- terpretations; for example, [27] ar gue their LAS self-attention heads are dif ferentiated phoneme detectors. Further inductive biases like filter widths and causality could be expressed through time-restricted self-attention [26] and dir ected self-attention [25], respectiv ely . 2.3. Formulation Let H ∈ R T × d h denote a sublayer’ s input. The first sublayer per- forms multi-head, scaled dot-product , self-attention [22]. For each head i of n hds , we learn linear maps W ( i ) Q , W ( i ) K ∈ R d h × d k , W ( i ) V ∈ R d h × d h /n hds . Left multiplication by H give the queries Q ( i ) , keys K ( i ) , and values V ( i ) of the i -th head, which combine to giv e HdAtt ( i ) = σ Q ( i ) K ( i ) > / √ d h V ( i ) , (4) where σ is row-wise softmax. Heads are concatenated along the d h /n hds axis to gi ve MltHdAtt = [ HdAtt (1) , . . . , HdAtt ( n hds ) ] . The second sublayer is a position-wise feed-forward network [22] FFN ( H ) = ReLU ( H W 1 + b 1 ) W 2 + b 2 where parameters W 1 ∈ R d h × d ff , b 1 ∈ R d ff , W 2 ∈ R d ff × d h , b 2 ∈ R d h are learned, with the biases b 1 , b 2 broadcasted over all T positions. This sub- layer aggregates the multiple heads at time t into the attention layer’ s final output at t . All together , the layer is given by: MidL yr ( H ) = LN ( MltHdAtt ( H ) + H ) , (5) SelfAttL yr ( H ) = LN ( FFN ( MidL yr ( H )) + MidL yr ( H )) . (6) 2.4. Downsampling In speech, the input length T of frames can be many times larger than the output length U , in contrast to the roughly word-to-word setting of machine translation. This is especially prohibitive for self-attention in terms of memory: recall that an attention matrix of dimension Q ( i ) K ( i ) > ∈ R T × T is created, giving the T 2 fac- tor in T able 1. A con volutional frontend is a typical downsam- pling strategy [8, 19]; ho wev er, we leave integrating other layer types into SAN-CTC as future work. Instead, we consider three fixed ap- proaches, from least- to most-preserving of the input data: subsam- pling , which only takes ev ery k -th frame; pooling , which aggre gates ev ery k consecuti ve frames via a statistic (av erage, maximum); re- shaping , where one concatenates k consecutiv e frames into one [27]. Note that CTC will still require U ≤ T /k , ho wev er . 2.5. Position Self-attention is inherently content-based [22], and so one often en- codes position into the post-embedding vectors. W e use standard trigonometric embeddings, where for 0 ≤ i ≤ d emb / 2 , we define PE ( t, 2 i ) = sin t 10000 2 i/d emb , PE ( t, 2 i + 1) = cos t 10000 2 i/d emb . for position t . W e consider three approaches: content-only [21], which forgoes position encodings; additive [19], which takes d emb = d h and adds the encoding to the embedding; and con- catenative , where one takes d emb = 40 and concatenates it to the embedding. The latter was found necessary for self-attentional LAS [27], as additive encodings did not gi ve con vergence. Howev er , the monotonicity of CTC is a further positional inductive bias, which may enable the success of content-only and additiv e encodings. 3. EXPERIMENTS W e take ( n layers , d h , n heads , d ff ) = (10, 512, 8, 2048), giving ∼ 30M parameters. This is on par with models on WSJ (10-30M) [4, 5,9] and an order of magnitude below models on LibriSpeech (100-250M) [8, 23]. W e use MXNet [37] for modeling and Kaldi/EESEN [7, 38] for data preparation and decoding. Our self-attention code is based on GluonNLP’ s implementation. At train time, utterances are sorted by length: we e xclude those longer than 1800 frames ( 1% of each training set). W e take a windo w of 25ms, a hop of 10ms, and con- catenate cepstral mean-variance normalized features with temporal first- and second-order dif ferences. 1 W e downsample by a factor of k = 3 (this also gav e an ideal T /k ≈ d h for our data; see T able 1). W e perform Nestero v-accelerated gradient descent on batches of 20 utterances. As self-attention architectures can be unstable in early training, we clip gradients to a global norm of 1 and use the standard linear warmup period before inv erse square decay associated with these architectures [19, 22]. Let n denote the global step number of the batch (across epochs); the learning rate is giv en by LR ( n ) = λ √ d h min n n 1 . 5 warmup , 1 √ n , (7) 1 Rescaling so that these differences also ha ve v ar . ≈ 1 helped WSJ training. Model dev93 eval92 CER WER CER WER CTC (BRDNN) [5] — — 10.0 — CTC (BLSTM) [4] — — 9.2 — CTC (BLSTM) [17] 11.5 — 9.0 — Enc-Dec (4-1) [17] 12.0 — 8.2 — Enc-Dec+CTC (4-1) [17] 11.3 — 7.4 — Enc-Dec (4-1) [39] — — 6.4 9.3 CTC/ASG (Gated CNN) [40] 6.9 9.5 4.9 6.6 Enc-Dec (2,1,3-1) [41] — — 3.6 — CTC (SAN), reshape, additiv e 7.1 9.3 5.1 6.1 + label smoothing, λ = 0.1 6.4 8.9 4.7 5.9 T able 2 : End-to-end, MLE-based, open-vocab . models trained on WSJ. Only WERs incorporating the extended 3-gram LM or a 4- gram LM (Gated CNN) are listed. Model dev93 eval92 PER WER PER WER CTC (BRDNN) [7] — — — 7.87 CTC (BLSTM) [11] — 9.12 — 5.48 CTC (ResCNN) [11] — 9.99 — 5.35 Ensemble of 3 (voting) [11] — 7.65 — 4.29 CTC (SAN), reshape, additiv e 7.12 8.09 5.07 4.84 + label smoothing, λ = 0.1 6.86 8.16 4.73 5.23 T able 3 : CTC phoneme models with WFST decoding on WSJ. where we take λ = 400 and n warmup as a hyperparameter . Howe ver , such a decay led to early stagnation in v alidation accuracy , so we later di vide the learning rate by 10 and run at the decayed rate for 20 epochs. W e do this twice, then take the epoch with the best validation score. Xavier initialization gav e v alidation accuracies of zero for the first few epochs, suggesting room for improvement. Like previous works on self-attention, we apply label smoothing (see T ables 2, 3, 5; we also tried model averaging to no gain). T o compute word error rates (WERs), we use the dataset’ s provided language model (LM) as incorporated by WFST decoding [7] to bridge the gap between CTC and encoder-decoder frameworks, allowing comparison with known benchmarks and informing systems that incorporate expert knowledge in this w ay (e.g., via a pronunciation lexicon). 3.1. W all Street Journal (WSJ) W e train both character - and phoneme-label systems on the 80-hour WSJ training set to validate our architectural choices. Similar to [17, 19], we use 40-dim. mel-scale filter banks and hence 120-dim. features. W e warmup for 8000 steps, use a dropout of 0.2, and switch schedules at epoch 40. For the WSJ dataset, we compare with similar MLE-trained, end-to-end, open-vocabulary systems in T able 2. W e get an eval92 CER of 4.7%, outdoing all previous CTC-like results except 4.6% with a trainable frontend [40]. W e use the provided extended 3-gram LM to retrieve WERs. F or phoneme training, our labels come from the CMU pronunciation lexicon (T able 3). These models train in one day (T esla V100), comparable to the Speech T ransformer [19]; howe ver , SAN-CTC gi ves further benefits at in- ference time as token predictions are generated in parallel. W e also ev aluate design choices in T able 4. Here, we con- sider the effects of downsampling and position encoding on accu- racy for our fixed training regime. W e see that unlik e self-attentional LAS [27], SAN-CTC works respectably e ven with no position en- Fig. 2 : A verage attention weights over WSJ’ s test set. The left half is a character model; the right half is a phoneme model. Each curve corresponds to a head, at layers 1 and 10, of representati ve SAN-CTC models (reshape + additive embedding). The first ro w charts standard deviation o ver time; the second ro w charts the attention magnitudes relative to position, where 0 represents attending to the same position. Downsampling Position embedding dev93 CER WER reshape content-only 7.62 9.57 reshape additiv e 7.10 9.27 reshape concatenativ e 7.10 9.97 pooling (maximum) additiv e 7.15 10.72 pooling (av erage) additiv e 6.82 9.41 subsample additive none none T able 4 : SAN-CTC character model on WSJ with modifications. coding; in fact, the contribution of position is relatively minor (com- pare with [21], where location in an encoder-decoder system im- prov ed CER by 3% absolute). Lossy do wnsampling appears to pre- serve performance in CER while degrading WER (as information about frame transitions is lost). W e believ e these observ ations align with the monotonicity and independence assumptions of CTC. Inspired by [27], we plot the standard de viation of attention weights for each head as training progresses; see Figure 2 for details. In the first layers, we similarly observ e a differentiation of v ariances, along with wide-context heads; in later layers, unlike [27] we still see mild dif ferentiation of variances. Inspired by [26], we further plot the attention weights relati ve to the current time position (here, per head). Character labels gave forward- and backw ard-attending heads (incidentally , a veraging these would retrieve the bimodal distrib ution in [26]) at all layers. This suggests a gradual expansion of context ov er depth, as is often engineered in conv olutional CTC. This also suggests possibly using fewer heads, directed self-attention [25], and restricted conte xts for f aster training (T able 1). Phoneme labels ga ve a sharp backward-attending head and more diffuse heads. W e be- liev e this to be a symptom of English characters being more context- dependent than phonemes (for example, emitting ‘tt’ requires look- ing ahead, as ‘–’ must occur between two runs of ‘t’ tokens). 3.2. LibriSpeech W e gi ve the first large-scale demons tration of a fully self-attentional ASR model using the LibriSpeech ASR corpus [42], an English corpus produced from audio books gi ving 960 hours of training Model T ok. test-clean test-other CER WER CER WER CTC/ASG (W av2Letter) [9] chr . 6.9 7.2 — — CTC (DS1-like) [33, 43] chr . — 6.5 — — Enc-Dec (4-4) [44] chr . 6.5 — 18.1 — Enc-Dec (6-1) [45] chr . 4.5 — 11.6 — CTC (DS2-like) [8, 32] chr . — 5.7 — 15.2 Enc-Dec+CTC (6-1, pretr .) [20] 10k — 4.8 — 15.3 CTC/ASG (Gated CNN) [23] chr . — 4.8 — 14.5 Enc-Dec (2,6-1) [41] 10k 2.9 — 8.4 — CTC (SAN), reshape, additiv e chr . 3.2 5.2 9.9 13.9 + label smoothing, λ = 0.05 chr . 3.5 5.4 11.3 14.5 CTC (SAN), reshape, concat. chr. 2.8 4.8 9.2 13.1 T able 5 : End-to-end, MLE-based, open-vocab . models trained on LibriSpeech. Only WERs incorporating the 4-gram LM are listed. data. W e use 13-dim. mel-freq. cepstral coeffs. and hence 39-dim. features. W e double the warmup period, use a dropout of 0.1, and switch schedules at epoch 30. Using character labels, we at- tained a test-clean CER of 2.8%, outdoing all pre vious end-to-end results except OCD training [41]. W e use the pro vided 4-gram LM via WFST to compare WERs with state-of-the-art, end-to-end, open-vocab ulary systems in T able 5. At this scale, ev en minor label smoothing w as detrimental. W e run 70 epochs in slightly ov er a week (T esla V100) then choose the epoch with the best validation score for testing. For comparison, the best CTC-like architecture [23] took 4-8 weeks on 4 GPUs for its results. 2 The Enc-Dec+CTC model is comparable, taking almost a week on an older GPU (GTX 1080 T i) to do its ∼ 12.5 full passes ov er the data. 3 Finally , we trained the same model with BPE subwords as CTC targets, to get more context-independent units [36]. W e did 300 merge operations (10k was unstable) and attained a CER of 7.4%. This g ave a WER of 8.7% with no LM (compare with T able 5’ s LM- based entries), and 5.2% with a subword WFST of the LM. W e still 2 https://github.com/facebookresearch/wav2letter/issues/11 3 https://github.com/rwth- i6/returnn- experiments/ tree/master/2018- asr- attention/librispeech/ full- setup- attention observed attention heads in both directions in the first layer , suggest- ing our subwords were still more context-dependent than phonemes. 4. CONCLUSION W e introduced SAN-CTC, a novel framework which integrates a fully self-attentional network with a connectionist temporal classi- fication loss. W e addressed the challenges of adapting self-attention to CTC and to speech recognition, showing that SAN-CTC is com- petitiv e with or outperforms existing end-to-end models on WSJ and LibriSpeech. Future avenues of work include multitasking SAN- CTC with other decoders or objectiv es, and streamlining network structure via directed or restricted attention. 5. REFERENCES [1] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhuber , “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, ” in Pr oc. Int. Conf. Mac h. Learning (ICML) . ACM, 2006, pp. 369–376. [2] A. Graves and J. Schmidhuber , “Offline handwriting recog- nition with multidimensional recurrent neural networks, ” in Pr oc. Adv . Neur al Inform. Pr ocess. Syst. (NIPS) , 2009, pp. 545–552. [3] D.-A. Huang, L. Fei-Fei, and J.C. Niebles, “Connectionist tem- poral modeling for weakly supervised action labeling, ” in Proc. Eur . Conf. Comput. V ision (ECCV) , 2016, pp. 137–153. [4] A. Grav es and N. Jaitly , “T ow ards end-to-end speech recogni- tion with recurrent neural networks, ” in Pr oc. Int. Conf. Mac h. Learning (ICML) . A CM, 2014, pp. 1764–1772. [5] A.Y . Hannun, A.L. Maas, D. Jurafsky , and A.Y . Ng, “First- pass large vocabulary continuous speech recognition using bi- directional recurrent DNNs, ” CoRR , vol. abs/1408.2873, 2014. [6] A.L. Maas, Z. Xie, D. Jurafsky , and A.Y . Ng, “Lexicon-free con versational speech recognition with neural networks, ” in Pr oc. Conf. North Amer . Ch. Assoc. Comput. Linguistics Hu- man Lang. T echnol. (NAA CL-HLT) , 2015, pp. 345–354. [7] Y . Miao, M. Gowayyed, and F . Metze, “EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding, ” in Pr oc. IEEE Autom. Speech Recognition Under- standing W orkshop (ASR U) . IEEE, 2015, pp. 167–174. [8] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Bat- tenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen, et al., “Deep Speech 2: End-to-end speech recognition in English and Mandarin, ” in Pr oc. Int. Conf. Mach. Learning (ICML) . A CM, 2016, pp. 173–182. [9] R. Collobert, C. Puhrsch, and G. Synnaeve, “W av2Letter: an end-to-end ConvNet-based speech recognition system, ” CoRR , vol. abs/1609.03193, 2016. [10] Y . Zhang, M. Pezeshki, P . Brakel, S. Zhang, C. Laurent, Y . Bengio, and A. C. Courville, “T o wards end-to-end speech recognition with deep con volutional neural networks, ” in Pr oc. Ann. Conf. Int. Speech Communication Assoc. (INTER- SPEECH) , 2016, pp. 410–414. [11] Y . W ang, X. Deng, S. Pu, and Z. Huang, “Residual con volu- tional CTC networks for automatic speech recognition, ” CoRR , vol. abs/1702.07793, 2017. [12] A.J. Robinson, “ An application of recurrent nets to phone prob- ability estimation, ” IEEE T rans. Neural Netw . , vol. 5, no. 2, pp. 298–305, 1994. [13] I. Sutskev er, O. V inyals, and Q.V . Le, “Sequence to sequence learning with neural networks, ” in Pr oc. Adv . Neural Inform. Pr ocess. Syst. (NIPS) , 2014, pp. 3104–3112. [14] D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine trans- lation by jointly learning to align and translate, ” CoRR , vol. abs/1409.0473, 2014. [15] W . Chan, N. Jaitly , Q.V . Le, and O. V inyals, “Listen, attend and spell: A neural network for large vocabulary con versational speech recognition, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2016, pp. 4960–4964. [16] Y . Zhang, W . Chan, and N. Jaitly , “V ery deep con volutional networks for end-to-end speech recognition, ” in Proc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2017, pp. 4845–4849. [17] S. Kim, T . Hori, and S. W atanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learn- ing, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2017, pp. 4835–4839. [18] C.-C. Chiu, T .N. Sainath, Y . Wu, R. Prabhav alkar, P . Nguyen, Z. Chen, A. Kannan, R.J. W eiss, K. Rao, K. Gonina, et al., “State-of-the-art speech recognition with sequence-to- sequence models, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2018, pp. 4774–4778. [19] L. Dong, S. Xu, and B. Xu, “Speech-transformer: a no- recurrence sequence-to-sequence model for speech recogni- tion, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr o- cess. (ICASSP) . IEEE, 2018. [20] A. Zeyer , K. Irie, R. Schl ¨ uter , and H. Ney , “Improv ed train- ing of end-to-end attention models for speech recognition, ” in Pr oc. Ann. Conf. Int. Speech Communication Assoc. (INTER- SPEECH) , 2018. [21] T . Hori, S. W atanabe, Y . Zhang, and W . Chan, “ Advances in joint CTC-attention based end-to-end speech recognition with a deep CNN encoder and RNN-LM, ” in Pr oc. Ann. Conf . Int. Speech Communication Assoc. (INTERSPEECH) , 2017. [22] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A.N. Gomez, Ł. Kaiser, and I. Polosukhin, “ Attention is all you need, ” in Pr oc. Adv . Neural Inform. Pr ocess. Syst. (NIPS) , 2017, pp. 6000–6010. [23] V . Liptchinsky , G. Synnaeve, and R. Collobert, “Letter - based speech recognition with gated Con vNets, ” CoRR , vol. abs/1712.09444, 2017. [24] J. Cheng, L. Dong, and M. Lapata, “Long short-term memory- networks for machine reading, ” in Pr oc. Conf. Empirical Meth- ods Natural Lang . Pr ocess. (EMNLP) , 2016, pp. 551–561. [25] T . Shen, T . Zhou, G. Long, J. Jiang, S. Pan, and C. Zhang, “DiSAN: Directional self-attention netw ork for RNN/CNN- free language understanding, ” in Proc. AAAI Conf. Artificial Intell. (AAAI) , 2018. [26] D. Povey , H. Hadian, P . Ghahremani, K. Li, and S. Khudanpur , “ A time-restricted self-attention layer for ASR, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2018. [27] M. Sperber , J. Niehues, G. Neubig, S. St ¨ uker , and A. W aibel, “Self-attentional acoustic models, ” in Proc. Ann. Conf. Int. Speech Communication Assoc. (INTERSPEECH) , 2018. [28] S. Zhou, L. Dong, S. Xu, and B. Xu, “Syllable-based sequence- to-sequence speech recognition with the T ransformer in Man- darin Chinese, ” in Pr oc. Ann. Conf. Int. Speech Communica- tion Assoc. (INTERSPEECH) , 2018. [29] S. Zhou, S. Xu, and B. Xu, “Multilingual end-to-end speech recognition with a single Transformer on low-resource lan- guages, ” CoRR , vol. abs/1806.05059, 2018. [30] Rohit Prabhavalkar , Kanishka Rao, T ara N. Sainath, Bo Li, Leif Johnson, and Navdeep Jaitly , “ A comparison of sequence- to-sequence models for speech recognition, ” in Pr oc. Ann. Conf. Int. Speech Communication Assoc. (INTERSPEECH) . 2017, pp. 939–943, ISCA. [31] Amit Das, Jinyu Li, Rui Zhao, and Y ifan Gong, “ Advanc- ing connectionist temporal classification with attention model- ing, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . 2018, pp. 4769–4773, IEEE. [32] Y . Zhou, C. Xiong, and R. Socher , “Improving end-to-end speech recognition with policy learning, ” in Proc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) , 2018, pp. 5819–5823. [33] A.Y . Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates, et al., “Deep Speech: Scaling up end-to-end speech recog- nition, ” CoRR , vol. abs/1412.5567, 2014. [34] T .N. Sainath, O. V inyals, A. Senior, and H. Sak, “Conv olu- tional, long short-term memory , fully connected deep neural networks, ” in Proc. IEEE Int. Conf. Acoustics Speech Signal Pr ocess. (ICASSP) . IEEE, 2015, pp. 4580–4584. [35] Z. Xie, Z. Sun, L. Jin, Z. Feng, and S. Zhang, “Fully conv o- lutional recurrent network for handwritten Chinese text recog- nition, ” in Proc. Int. Conf. P attern Recognition (ICPR) . IEEE, 2016, pp. 4011–4016. [36] T . Zenkel, R. Sanabria, F . Metze, and A. W aibel, “Subword and crossword units for CTC acoustic models, ” in Proc. Ann. Conf . Int. Speech Communication Assoc. (INTERSPEECH) , 2018, pp. 396–400. [37] T . Chen, M. Li, Y . Li, M. Lin, N. W ang, M. W ang, T . Xiao, B. Xu, C. Zhang, and Z. Zhang, “MXNet: A flexible and ef- ficient machine learning library for heterogeneous distributed systems, ” CoRR , vol. abs/1512.01274, 2015. [38] Daniel Pove y , Arnab Ghoshal, Gilles Boulianne, Lukas Bur- get, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding . IEEE Signal Process- ing Society , 2011, number EPFL-CONF-192584. [39] D. Bahdanau, J. Chorowski, D. Serdyuk, P . Brak el, and Y . Ben- gio, “End-to-end attention-based large vocabulary speech recognition, ” in Pr oc. IEEE Int. Conf. Acoustics Speec h Signal Pr ocess. (ICASSP) , 2016, pp. 4945–4949. [40] N. Zeghidour , N. Usunier , G. Synnae ve, R. Collobert, and E. Dupoux, “End-to-end speech recognition from the raw wa veform, ” in Proc. Ann. Conf. Int. Speech Communication Assoc. (INTERSPEECH) , 2018, pp. 781–785. [41] S. Sabour, W . Chan, and M. Norouzi, “Optimal completion distillation for sequence learning, ” CoRR , vol. abs/1810.01398, 2018. [42] V . Panayotov , G. Chen, D. Pov ey , and S. Khudanpur, “Lib- riSpeech: an ASR corpus based on public domain audio books, ” in Pr oc. IEEE Int. Conf. Acoustics Speech Signal Pr o- cess. (ICASSP) . IEEE, 2015, pp. 5206–5210. [43] Mozilla Foundation, “ A journey to < 10% word er- ror rate, ” https://hacks.mozilla.or g/2017/11/a-journey-to-10- wor d-err or-rate/ , 2017. [44] D. Liang, Z. Huang, and Z.C. Lipton, “Learning noise- in variant representations for robust speech recognition, ” in Pr oc. IEEE Spoken Language T ec hnol. W orkshop (SL T) . IEEE, 2018. [45] A. Sriram, H. Jun, S. Satheesh, and A. Coates, “Cold Fusion: T raining seq2seq models together with language models, ” in Pr oc. Ann. Conf. Int. Speech Communication Assoc. (INTER- SPEECH) , 2018, pp. 387–391.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment