Large-Scale Speaker Diarization of Radio Broadcast Archives
This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Du…
Authors: Emre Y{i}lmaz, Adem Derinel, Zhou Kun
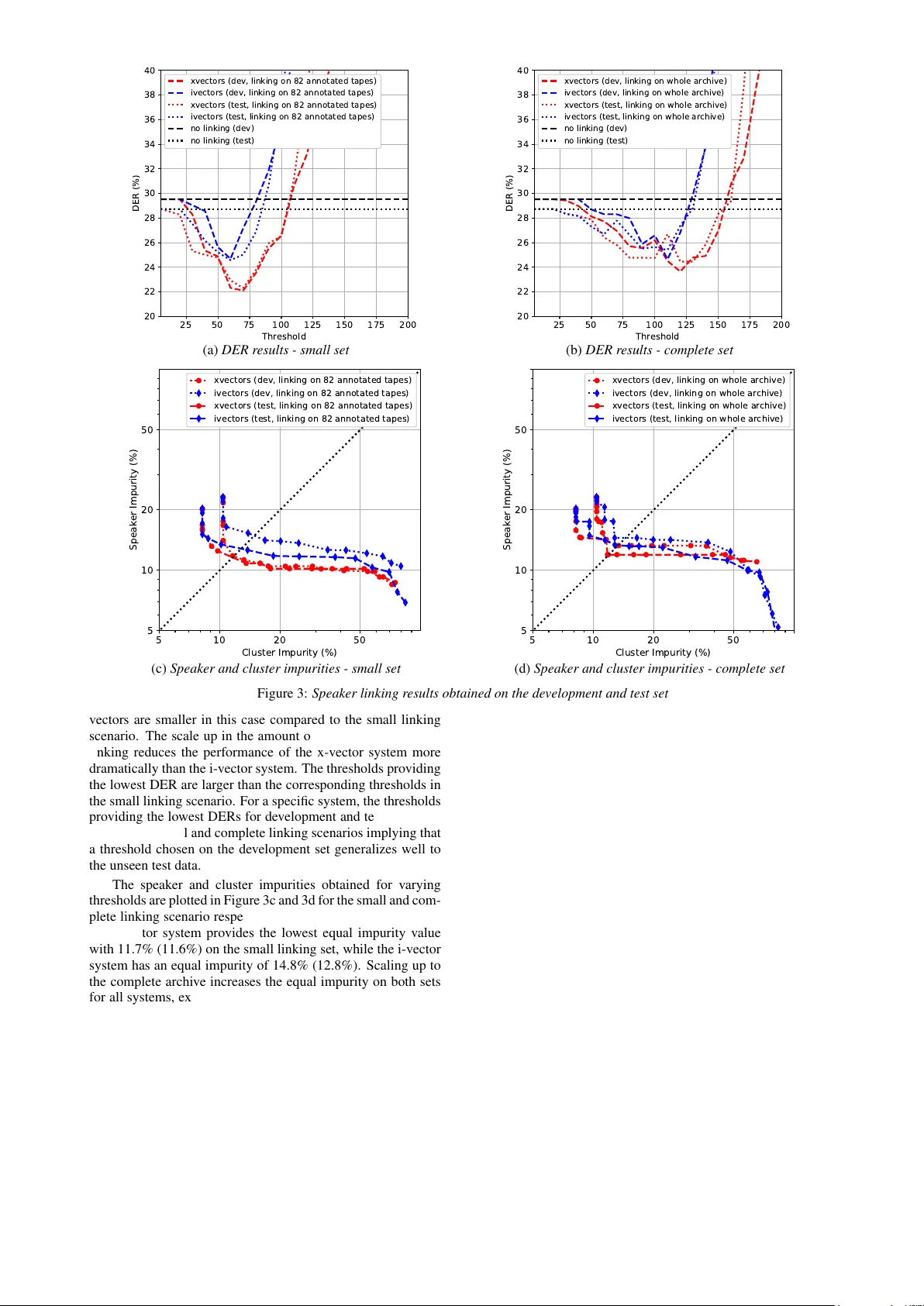
Large-Scale Speak er Diarization of Radio Br oadcast Archi ves Emr e Yılmaz 1 , Adem Derinel 1 , Zhou K un 1 , Henk van den Heuvel 2 , Niko Brummer 3 , Haizhou Li 1 , David A. van Leeuwen 4 1 Dept. of Electrical and Computer Engineering, National Uni versity of Sing apore, Singapore 2 CLS/CLST , Radboud Uni versity , Nijme gen, Netherlands 3 Cyberupt BV , South Africa 4 ICIS, Radboud Uni versity , Nijme gen, Netherlands emre@nus.edu.sg Abstract This paper describes our initial efforts to build a lar ge-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archiv e from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian- Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme in v olves two stages: (1) tape- lev el speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of se v- eral frequently appearing speakers from the previously collected F AME! speech corpus, we further perform speaker identifica- tion by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and ev aluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is ev aluated on a small subset of the archive which is manually annotated with speaker informa- tion. The speaker linking performance reported on this subset (53 hours) and the whole archiv e (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data. Index T erms : Speaker diarization, speaker linking, speaker and cluster impurities, longitudinal broadcast data, x-vectors 1. Introduction Speaker diarization (SD) in the conv entional sense has been achiev ed by clustering segments with similar speaker charac- teristics to reveal the number of speakers inv olved in a con- versation and label who speaks when. V arious top-do wn and bottom-up approaches ha v e been proposed in which the diariza- tion starts with small and large number of clusters respectiv ely and iterati vely conv erges to an optimum number of clusters [1]. Large-scale SD techniques are employed on considerably larger amount data to perform SD in a computationally tractable manner . T o deal with the computational restrictions of con- ventional SD techniques due to the major increase in speech data, multiple pre vious work proposed to perform SD in mul- tiple stages [2–6]. The idea is to first perform standard SD on smaller units such as the tapes in a broadcast archive or record- ings in a meeting archiv e and then link the speakers appearing in multiple times using a metric to assign a similarity score to all pseudo-speaker pairs which are hypothesized in the first stage. One common way of achieving the linking is to apply agglomer- ativ e clustering-based speaker clustering with different linking strategies such as single, W ard and complete-linkage [6, 7]. In these previous works, the speaker clusters modeled as multiv ari- ate Gaussian mixture models (GMM) are mer ged until a certain stopping criterion is met. More recently , SD techniques employing speaker clustering using probabilistic linear discriminant analysis (PLD A) for cal- culating similarity scores between clusters have been proposed [8–11]. In this setting, speech segments are represented in the form of i-vectors [12] and x-vectors [13, 14]. As mentioned in multiple earlier work, e.g. [9], this SD frame work pro vides bet- ter SD performance compared to the con ventional GMM-based approaches using Bayesian information criterion [15] to assign cluster similarity . In the F AME! Project, we have dev eloped a spoken docu- ment retriev al system for the radio broadcast archives of Om- rop Frysl ˆ an (Frisian Broadcast), the regional public broadcaster of the pro vince Frysl ˆ an in the Netherlands. This system re- lies on automatically generated transcriptions hypothesized by a code-switching automatic speech recognition system [16] and speaker labels generated by a modern speaker recognition sys- tem dev eloped using the resources [17] with the ultimate goal of making these archiv es searchable. In this paper , we focus on the de velopment of an e xperi- mental setup for speaker linking research on very large speech corpora and describe our initial efforts to build a large-scale SD system which would perform SD and linking in two stages. For this purpose, we created a ne w SD corpus, dubbed as the F AME! SD corpus, with 6494 digitized tapes from the radio broadcast archive that contains more than 3000 hours of Frisian- Dutch speech. The e valuation of the SD performance is done on the 82 subsegments that appear as a part of longer tapes. These subsegments were manually annotated with speaker informa- tion during the initial data collection described in [18]. As a technical contribution, we introduce a new speaker linking approach that uses x-vectors with PLDA for assigning similarity scores to pseudo-speaker pairs. The tape-le vel SD performed in the first stage uses an off-the-shelf SD toolkit en- suring a reasonably accurate initial speak er clustering which are later used for the linking performed in the second stage. The speaker linking results provided by the proposed system on 82 partly annotated tapes and the whole archi ve are presented in terms of diarization error rate and speaker and cluster impuri- ties. The longitudinal, multilingual and div ersely accented na- ture of this speech archi ve introduces new challenges to modern large-scale SD systems which is yet to be explored in the future. 2. F AME! speak er diarization corpus The Frisian-Dutch speech data has been collected in the scope of the F AME! (Frisian Audio Mining Enterprise) Project with 0 1 0 0 0 2 0 0 0 3 0 0 0 4 0 0 0 5 0 0 0 6 0 0 0 Du r a t i o n ( se c ) 0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 0 1 2 0 0 1 4 0 0 C o u n t Figure 1: Duration distribution of the tapes in the r adio ar chive the aim of building a spoken document retriev al system 1 for the disclosure of the archi ves of Omrop Frysl ˆ an (Frisian Broadcast) cov ering a large time span from 1950s to present and a wide va- riety of topics. Omrop Frysl ˆ an is the regional public broadcaster of the province Frysl ˆ an. It has a radio station and a TV chan- nel both broadcasting in Frisian and is the main data provider of this project with a radio broadcast archi ve containing more than 3000 hours of recordings. The longitudinal and bilingual nature of the material enables to perform research on v arious research topics including speaker tracking and diarization over a large time period. A small subset of the radio broadcast recordings has been manually annotated by two nativ e Frisian and Dutch speak- ers. The annotation protocol designed for this code-switching Frisian data includes the orthographic transcription containing the uttered words, speak er details such as the gender , dialect, name (if known) and spoken language information. T o get more precise information about the speaker details, all available meta- information of the radio broadcasts is also used during the an- notation. Further details of this corpus are gi ven in [18]. In the last years, we hav e created two publicly av ailable speech corpora for CS ASR [19] and speaker recognition [17] research using the manually annotated and ra w data extracted from these archiv es. After having the complete archive digitized last year , we ha ve created a third speech corpus that is designed for lar ge- scale SD research. Unlike previous corpora, this component will not be included in the open Frisian resources due to intel- lectual property rights. The F AME! SD corpus contains 6494 tapes whose dura- tions are distributed as shown in Figure 1. The mean duration is 1737 seconds (28 minutes, 57 seconds) which is marked in white on the histogram. All a vailable tapes that are provided by the broadcast after the digitization have been included except a few corrupted ones containing silence only . The evaluation of the speaker linking performance has been done on 82 partly an- notated tapes. Each of these tapes has a 5-minute subsegment which has been annotated during the initial manual annotation effort [18]. The exact positions of each annotated subsegment (start and end times) in the corresponding tape are manually determined and recorded in a text file which is included in the corpus. The total duration of these 82 tapes is 53 hours and the total duration of the annotated subsegments is 7 hours 20 min- utes. There are 215 speakers in the annotated subse gments, 154 with known and 61 with unknown speaker name. According to 1 A vailable online at https://zoek en.fame.frl/ the ground truth transcriptions, there are 22 annotated speakers appearing in more than one tape and 10 annotated speakers ap- pearing in five or more tapes. The annotated subsegments are equally divided into a de velopment and test set, each contain- ing 41 subsegments with approximately 3 hours 40 minutes of speech. 3. Large-scale speaker diarization This section describes the details of the large-scale SD system applied to the radio archiv e described in Section 2. As con ven- tional approaches to SD cannot be employed in our setting due to intractable computational burden, we opt for a two-stage di- arization scheme, which is illustrated in Figure 2 and detailed in the upcoming subsections. 3.1. First stage: T ape-level diarization The initial pseudo-speaker labels are obtained using the pub- licly av ailable LIUM toolkit [20]. Focusing on the speaker link- ing component in the second stage, the goal in the first stage is to obtain a pseudo-speaker labeling of reasonable quality . The clustering parameters hav e been chosen to fav or a mild overes- timation of the actual number of speakers in the first stage to prev ent irreversible mer ging of speakers on tape le vel. The incorporated SD system uses Gaussian models per- forms acoustic segmentation and clustering based on a Bayesian information criterion (BIC) [15] follo wed by a GMM-based speaker clustering by maximizing cross likelihood ratio (CLR) [21] measure to obtain optimal speaker clusters. Further details of the LIUM toolkit can be found in [20]. 3.2. Second stage: Speaker linking and identification Linking and identifying pseudo-speakers is a straightforward step towards improving the quality of the automatically gen- erated speaker labels. The goal is to assign identical labels to the speakers appearing in multiple tapes, e.g. presenters and celebrities. F or this purpose, we extract the se gments labeled with the same pseudo-speakers based on the tape-level diariza- tion output. These segments that belong to the same speakers are merged to create a single recording for each pseudo-speaker . The same procedure is applied to the speaker segments with known identities. The merged segments that are shorter than a threshold duration are remov ed to ensure some amount of pres- ence of the pseudo-speakers on tape le vel. For all remaining pseudo-speakers and known speakers, we extract i-vectors and x-vectors using the e xtractors trained us- ing the implementations a vailable in the Kaldi toolkit [22]. The performance of these systems is found to be comparable with a similar system trained on the automatically labeled Frisian- Dutch data described in [17]. A similarity matrix for all possible speaker pairs are calculated using a PLD A model [23] to find the cross-tape speaker similarities. Based on these speaker similar- ity scores, speaker linking is performed by applying complete- linkage clustering as described in [7]. V arying le vels of speaker linking can be performed by manipulating the clustering thresh- old results in different levels of speaker and cluster impurities. All speaker labels in the same cluster are mapped to a new pseudo-speaker label or , if a kno wn speaker exists in the cluster, identified as the known speak er . 4. Experimental setup 4.1. Speech Corpora The GMM-UBM model and the i-vector extractor is trained us- ing the follo wing corpora: Switchboard Phase 1-2-3, Switch- board Cellular 1-2, SRE2004-SRE2010 and Mixer 6. The x- Radio Archive (~3000 hours of audio recorded in 6500 tapes) T ape-level Speaker Diarization System i-vector extractor PLDA x-vector extractor PLDA T apes Similarity Matrix Similarity Matrix Agglomerative Hierarchical Clustering Agglomerative Hierarchical Clustering Speaker Linking ... Final Speaker Labels Final Speaker Labels Segments with known speakers Figure 2: Block dia gram of the lar ge-scale speaker diarization and identification systems vector extractor training has been done using the same cor - pora and some additional recordings that are noisy and rev er- berant v ersions of a randomly selected subset of the clean utter - ances. The PLD A training for the i-vector and x-vector system has been done on a subset of the augmented data that contains recordings from previous SRE corpora only . The preparation of the F AME! SD corpus on which the speaker linking results are reported is detailed in Section 2. 4.2. Implementation details W e used the LIUM toolkit (v er . 8.4.1) for the tape-le vel SD in the first stage. This system provides a time a veraged tape- lev el diarization error rate of 19.6% on all 82 tapes. There are 338 pseudo-speakers in total, while the actual speaker number is 215. The merged pseudospeaker recordings shorter than 10 seconds are not included in the speaker linking stage. The total number of pseudo-speak ers identified after the tape lev el SD for the annotated 82 and all tapes are 811 and 45 288 respectively . Segments from 187 kno wn speakers are also included during the speaker linking in both linking scenarios. These segments are extracted from the remaining 122 manually annotated seg- ments in the F AME! speech corpus which are excluded from the dev elopment and test set. The i-vector extractor is trained according to standard Kaldi (v5.4) recipe ( sre16/v1 ) dev eloped for the NIST SRE 2016 e val- uation. The incorporated GMM-UBM baseline is detailed in [24]. The acoustic features are 20 MFCCs with a frame shift of 10 ms and a frame length of 25 ms with deltas and delta- deltas. Mean normalization is applied ov er a 3 second win- dow . F or the GMM-UBM, a full-cov ariance matrix is trained initially by applying 4 EM iterations followed by another 4 it- erations with a full-cov ariance matrix. The i-vector extractor is obtained after 5 EM iteration on the training data and it gener- ates 600-dimensional i-vectors. Finally , the i-vector mean sub- traction and length normalization is applied before calculating the PLD A scores. The x-vector extractor used in these experiments [14] is trained according to the standard Kaldi recipe ( sr e16/v2 ). A time-delay neural network (TDNN) [25] is trained using the same acoustic features as in the i-vector system. The TDNN model includes five frame-lev el hidden layers with rectified lin- ear unit acti vation and batch normalization [26]. The specific time-delay information of these frame-lev el layers are gi ven in [14]. A statistics pooling layer follo ws the output of the last frame-le vel layer which computes the mean and standard deviation of the frames of input segments. The final two hid- den layers are 512-dimensional pooling layers, also operat- ing at se gment level, prior to the softmax layer which targets speaker labels for each audio se gment. The softmax and the second pooling layer are removed during x-v ector extraction and 512-dimensional x-vectors are e xtracted at the output of the first pooling layer . The PLD A estimation has been per- formed using the clean and augmented SRE data after applying 10 expectation-maximization iterations for both systems. The SciPy [27] implementation of agglomerative clustering with complete-linkage has been used for performing the speaker clustering. By varying the threshold, various clustering le vels hav e been created and the linking performance for all thresholds has been reported. In the final stage, a common speak er label is assign to the pseudo-speakers and known speakers that belong to the same cluster . 4.3. Speaker linking experiments W e compare the speaker linking performance of i-vectors and x- vectors in the pipeline shown in Figure 2 on (1) 82 tapes which contains the annotated subse gments (small set) and (2) all 6494 tapes (complete set). The former scenario contains 53 hours speech data while the latter has approximately 3000 hours of speech data. W e ev aluate the speaker linking performance using two metrics: (1) diarization error rate (DER) calculated by con- catenating the 41 annotated segments in the de velopment and test set and (2) speaker and cluster impurities [3] obtained on the dev elopment and test data. The former metric measures the speaker confusions between dif ferent clusters, the latter mea- sures the amount of different speak ers in each cluster . 5. Results and Discussion The DER results obtained on each set are presented in Figure 3a and 3b for the small and complete linking scenario respec- tiv ely . The DER value without performing any speaker link- ing is 29.5% (28.7%) on the dev elopment (test) set as shown in black dashed (dotted) line. By varying the clustering threshold, we in vestigate where each system reaches the lowest DER for linking on the small and complete set. For the linking on small set, the i-vector system has a lo west DER of 24.7% (24.6%), while the x-vector system gi ves a DER of 22.1% (22.3%). Both results are much lower than the DER value without linking in- dicating that the described pipelines improve the quality of the speaker labels by linking the speakers appearing in multiple tapes. Moreover , the x-vector system outperforms the i-vector system with a lar ge margin on both sets. The best results are achiev ed at a clustering threshold of 60 for the i-vector system and 70 for the x-vector system on both sets. The lowest DER values increase for both systems when linking is done on the complete archive. The DER values for the i-vector and x-v ector systems are 24.7% (25.4%) and 23.7% (24.5%) respecti vely . All results are worse than the previous re- sults reported when the linking is done on the small set. Scaling up from 82 to 6494 tapes increases the complexity of the link- ing task considerably resulting in some linking accuracy loss in general. The improv ements given by the x-vectors o ver i- 2 5 5 0 7 5 1 0 0 1 2 5 1 5 0 1 7 5 2 0 0 T h r e sh o l d 2 0 2 2 2 4 2 6 2 8 3 0 3 2 3 4 3 6 3 8 4 0 DE R ( % ) x v e c t o r s ( d e v , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) i v e c t o r s ( d e v , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) x v e c t o r s ( t e st , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) i v e c t o r s ( t e st , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) n o l i n k i n g ( d e v ) n o l i n k i n g ( t e st ) (a) DER r esults - small set 2 5 5 0 7 5 1 0 0 1 2 5 1 5 0 1 7 5 2 0 0 T h r e sh o l d 2 0 2 2 2 4 2 6 2 8 3 0 3 2 3 4 3 6 3 8 4 0 DE R ( % ) x v e c t o r s ( d e v , l i n k i n g o n w h o l e a r c h i v e ) i v e c t o r s ( d e v , l i n k i n g o n w h o l e a r c h i v e ) x v e c t o r s ( t e st , l i n k i n g o n w h o l e a r c h i v e ) i v e c t o r s ( t e st , l i n k i n g o n w h o l e a r c h i v e ) n o l i n k i n g ( d e v ) n o l i n k i n g ( t e st ) (b) DER r esults - complete set 5 1 0 2 0 5 0 C l u st e r I m p u r i t y ( % ) 5 1 0 2 0 5 0 S p e a k e r I m p u r i t y ( % ) x v e c t o r s ( d e v , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) i v e c t o r s ( d e v , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) x v e c t o r s ( t e st , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) i v e c t o r s ( t e st , l i n k i n g o n 8 2 a n n o t a t e d t a p e s) (c) Speaker and cluster impurities - small set 5 1 0 2 0 5 0 C l u st e r I m p u r i t y ( % ) 5 1 0 2 0 5 0 S p e a k e r I m p u r i t y ( % ) x v e c t o r s ( d e v , l i n k i n g o n w h o l e a r c h i v e ) i v e c t o r s ( d e v , l i n k i n g o n w h o l e a r c h i v e ) x v e c t o r s ( t e st , l i n k i n g o n w h o l e a r c h i v e ) i v e c t o r s ( t e st , l i n k i n g o n w h o l e a r c h i v e ) (d) Speaker and cluster impurities - complete set Figure 3: Speaker linking r esults obtained on the development and test set vectors are smaller in this case compared to the small linking scenario. The scale up in the amount of tapes included during linking reduces the performance of the x-vector system more dramatically than the i-v ector system. The thresholds providing the lowest DER are larger than the corresponding thresholds in the small linking scenario. For a specific system, the thresholds providing the lowest DERs for dev elopment and test sets coin- cide in both small and complete linking scenarios implying that a threshold chosen on the development set generalizes well to the unseen test data. The speaker and cluster impurities obtained for varying thresholds are plotted in Figure 3c and 3d for the small and com- plete linking scenario respectiv ely . Similar to the DER results, the x-vector system provides the lowest equal impurity value with 11.7% (11.6%) on the small linking set, while the i-vector system has an equal impurity of 14.8% (12.8%). Scaling up to the complete archive increases the equal impurity on both sets for all systems, except the i-vector system which giv es compa- rable results on the dev elopment set. The x-vector system per- forms better on both sets compared to the i-vector system with smaller improv ements than the ones reported on the small link- ing scenario as also observed in the DER results. In general, it can be concluded from both the DER and impurity results that using x-vectors for speaker linking provides better results than the i-vector system which is consistent with earlier literature on other speaker-related applications. On the other hand, the per- formance losses reported due to the scaling up in the amount of linked tapes are consistently lar ger for the x-vector system. 6. Conclusion In this paper, we present a new corpus consisting of 6500 tapes from a bilingual radio archiv e designed for large-scale speaker diarization research and in vestigate the speaker linking perfor- mance of a ne w x-vector -based linking system by performing speaker clustering using a similarity matrix with PLD A scores. The clustering is achiev ed by performing agglomerativ e cluster- ing with complete-linkage and performed using speak er models from all pseudo-speakers labeled by a generic SD system and a small set of known speakers. Based on the disco vered clus- ters, we perform speak er linking and identification by detecting similarities between the pseudo-speakers appearing in different tapes and identify them if they belong to the same cluster as a known speaker . W e compare the speaker linking performance of i-vector and x-vector variants of the described pipeline on the new SD corpus in terms of a verage diarization error rates and speaker and cluster impurities. Future work includes exploring the recently proposed meta-embeddings [28] for speaker clus- tering using the introduced experimental setup. 7. Acknowledgements This research is supported by National Research Foundation through the AI Singapore Programme, the AI Speech Lab: Au- tomatic Speech Recognition for Public Service Project AISG- 100E-2018-006 and the NWO Project 314-99-119. 8. References [1] X. Anguera, S. Bozonnet, N. Evans, C. Fredouille, G. Fried- land, and O. V inyals, “Speaker diarization: A re view of recent research, ” IEEE T ransactions on A udio, Speech, and Language Pr ocessing , vol. 20, no. 2, pp. 356–370, Feb 2012. [2] S. Meignier , D. Moraru, C. Fredouille, J.-F . Bonastre, and L. Be- sacier , “Step-by-step and integrated approaches in broadcast news speaker diarization, ” Computer Speech & Language , vol. 20, no. 2, pp. 303 – 330, 2006. [3] D. A. V an Leeuwen, “Speaker linking in large data sets, ” in Proc. Odyssey , 2010, pp. 202–208. [4] M. Huijbregts and D. A. van Leeuwen, “Large-scale speaker di- arization for long recordings and small collections, ” IEEE T rans- actions on Audio, Speech, and Language Processing , vol. 20, no. 2, pp. 404–413, Feb 2012. [5] M. Ferras and H. Bourlard, “Speaker diarization and linking of large corpora, ” in Proc. IEEE SL T , Dec 2012, pp. 280–285. [6] M. Ferras, S. Madikeri, and H. Bourlard, “Speaker diarization and linking of meeting data, ” IEEE/ACM T ransactions on Au- dio, Speech, and Language Pr ocessing , vol. 24, no. 11, pp. 1935– 1945, Nov 2016. [7] H. Ghaemmaghami, D. Dean, S. Sridharan, and D. A. V an Leeuwen, “ A study of speaker clustering for speaker attribu- tion in large telephone conv ersation datasets, ” Computer Speech & Language , v ol. 40, no. Supplement C, pp. 23 – 45, 2016. [8] J. Prazak and J. Silo vsky, “Speaker diarization using PLD A-based speaker clustering, ” in Proceedings of the 6th IEEE International Confer ence on Intelligent Data Acquisition and Advanced Com- puting Systems , vol. 1, Sep. 2011, pp. 347–350. [9] G. Sell and D. Garcia-Romero, “Speaker diarization with PLD A i-vector scoring and unsupervised calibration, ” in Pr oc. IEEE Spo- ken Language T echnolo gy W orkshop SLT , 2014, pp. 413–417. [10] A. W . Zewoudie, J. Luque, and J. Hernando, “Short- and long-term speech features for hybrid hmm-i-vector based speaker diarization system, ” in Odyssey 2016 , 2016, pp. 400–406. [Online]. A vailable: http://dx.doi.org/10.21437/Odyssey .2016- 58 [11] D. Garcia-Romero, D. Snyder, G. Sell, D. Pov ey, and A. McCree, “Speaker diarization using deep neural network embeddings, ” in 2017 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , March 2017, pp. 4930–4934. [12] N. Dehak, P . J. Kenn y , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech, and Language Processing , vol. 19, no. 4, pp. 788–798, May 2011. [13] D. Snyder, D. Garcia-Romero, D. Povey , and S. Khudan- pur , “Deep neural network embeddings for text-independent speaker verification, ” in Pr oc. INTERSPEECH , 2017, pp. 999–1003. [Online]. A vailable: http://dx.doi.org/10.21437/ Interspeech.2017- 620 [14] D. Snyder , D. Garcia-Romero, G. Sell, D. Pove y, and S. Khudan- pur , “X-vectors: Robust dnn embeddings for speaker recognition, ” in in Pr oc. ICASSP , April 2018, pp. 5329–5333. [15] S. S. Chen and P . S. Gopalakrishnan, “Speaker , environment and channel change detection and clustering via the bayesian infor - mation criterion, ” in D ARP A Broadcast News T ranscription and Understanding W orkshop , 1998, pp. 127–132. [16] E. Yılmaz, H. V an den Heuvel, and D. A. V an Leeuwen, “ Acous- tic and textual data augmentation for improved ASR of code- switching speech, ” in Pr oc. INTERSPEECH , Sept. 2018, pp. 1933–1937. [17] E. Yılmaz, J. Dijkstra, H. V an de V elde, F . Kampstra, J. Al- gra, H. V an den Heuvel, and D. A. V an Leeuwen, “Longitudi- nal speaker clustering and verification corpus with code-switching Frisian-Dutch speech, ” in Pr oc. INTERSPEECH , 2017, pp. 37– 41. [18] E. Yılmaz, M. Andringa, S. Kingma, F . V an der Kuip, H. V an de V elde, F . Kampstra, J. Algra, H. V an den Heuvel, and D. A. V an Leeuwen, “ A longitudinal bilingual Frisian-Dutch radio broadcast database designed for code-switching research, ” in Pr oc. LREC , 2016, pp. 4666–4669. [19] E. Yılmaz, H. V an den Heuvel, and D. A. V an Leeuwen, “Inv esti- gating bilingual deep neural networks for automatic speech recog- nition of code-switching Frisian speech, ” Pr ocedia Computer Sci- ence , pp. 159–166, May 2016. [20] S. Meignier and T . Merlin, “Lium spkdiarization: an open source toolkit for diarization, ” in Pr oc. CMU SPUD W orkshop , 2010. [21] D. A. Reynolds, E. Singer, B. A. Carlson, G. C. O’Leary , J. McLaughlin, and M. A. Zissman, “Blind clustering of speech utterances based on speaker and language characteristics, ” in Pr oc. ICSLP , 1998. [22] D. Povey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz, J. Silo vsky , G. Stemmer, and K. V esely , “The Kaldi speech recog- nition toolkit, ” in Pr oc. ASRU , Dec. 2011. [23] S. J. D. Prince and J. H. Elder, “Probabilistic linear discriminant analysis for inferences about identity , ” in IEEE 11th International Confer ence on Computer V ision, ICCV , 2007, pp. 1–8. [24] D. Snyder , D. G. Romero, and D. Pov ey , “T ime delay deep neural network-based uni versal background models for speaker recogni- tion, ” in Pr oc. ASRU , 2015, pp. 92–97. [25] A. W aibel, T . Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks, ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 37, no. 3, pp. 328–339, Mar 1989. [26] S. Iof fe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal covariate shift, ” in Proc. ICML , 2015, pp. 448–456. [27] E. Jones, T . Oliphant, P . Peterson et al. , “SciPy: Open source scientific tools for Python, ” 2001–. [28] N. Brummer , A. Silnova, L. Burget, and T . Stafylakis, “Gaussian meta-embeddings for efficient scoring of a heavy-tailed PLD A model, ” CoRR , vol. abs/1802.09777, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment