EXTD: Extremely Tiny Face Detector via Iterative Filter Reuse
In this paper, we propose a new multi-scale face detector having an extremely tiny number of parameters (EXTD),less than 0.1 million, as well as achieving comparable performance to deep heavy detectors. While existing multi-scale face detectors extra…
Authors: YoungJoon Yoo, Dongyoon Han, Sangdoo Yun
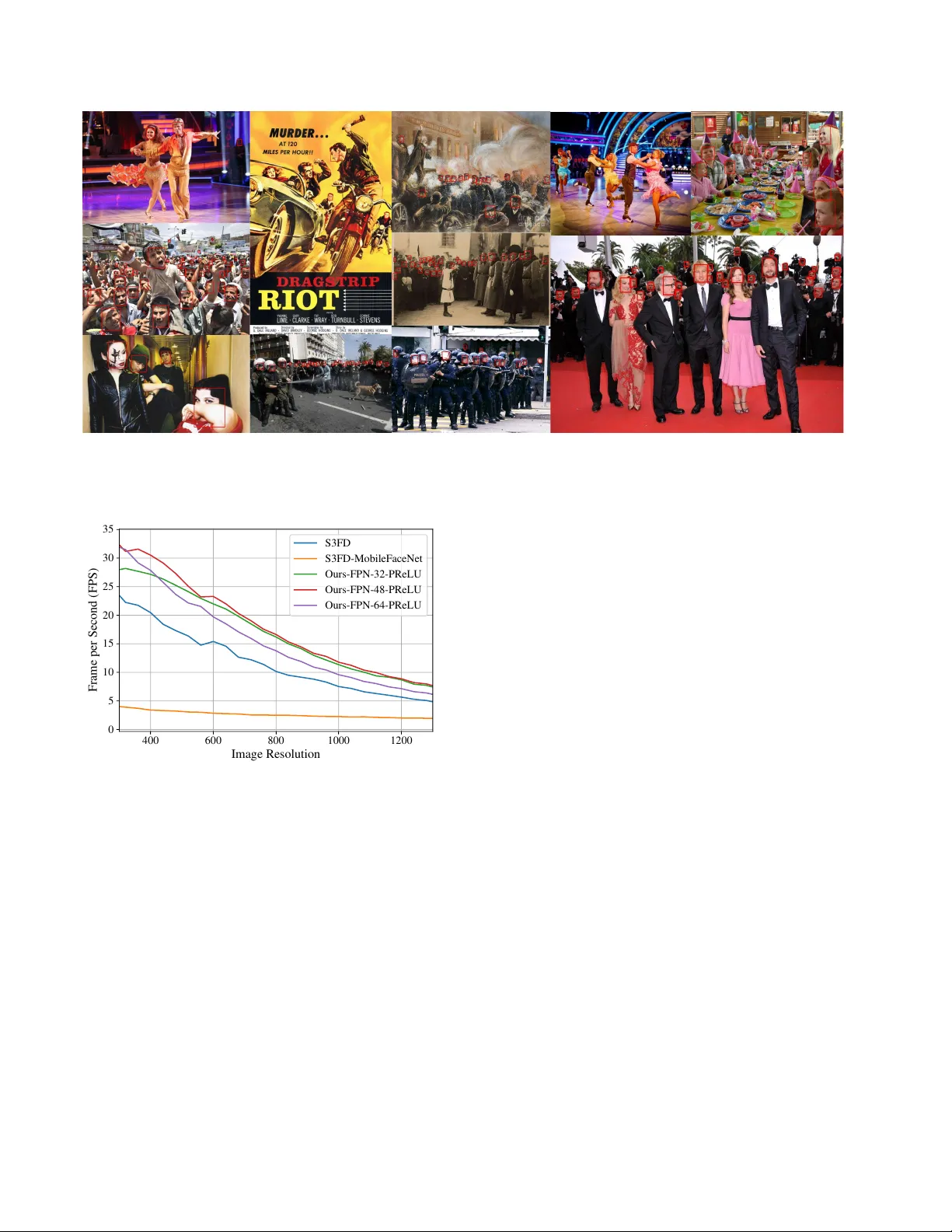
EXTD: Extr emely T iny F ace Detector via Iterativ e Filter Reuse Y oungJoon Y oo ∗ youngjoon.yoo@navercorp.com Dongyoon Han ∗ dongyoon.han@navercorp.com Sangdoo Y un ∗ sangdoo.yun@navercorp.com Abstract In this paper , we propose a ne w multi-scale face detec- tor having an extr emely tiny number of parameters (EXTD), less than 0 . 1 million, as well as achieving comparable per - formance to deep heavy detectors. While e xisting multi- scale face detectors e xtract featur e maps with differ ent scales fr om a single backbone network, our method gen- erates the feature maps by iteratively reusing a shared lightweight and shallow backbone network. This iterative sharing of the backbone network significantly r educes the number of parameters, and also pr ovides the abstract im- age semantics captur ed fr om the higher stage of the net- work layers to the lower-level featur e map. The pr oposed idea is employed by various model arc hitectures and eval- uated by e xtensive experiments. F r om the e xperiments fr om WIDER F ACE dataset, we show that the pr oposed face de- tector can handle faces with various scale and conditions, and ac hieved comparable performance to the mor e massive face detectors that few hundr eds and tens times heavier in model size and floating point operations. 1. Introduction Detecting faces in an image is considered to be one of the most practical tasks in computer vision applica- tions, and many studies [ 46 , 30 ] are proposed from the beginning of the computer vision research. After the ad- vent of deep neural networks, man y face detection algo- rithms [ 53 , 60 , 45 , 50 ] applying the deep network have re- ported significant performance impro vement to the con ven- tional face detectors. The state-of-the-art (SOT A) face detectors [ 60 , 45 , 50 ] for in-the-wild images employ the framew ork of the recent object detectors [ 7 , 38 , 36 , 37 , 28 , 4 , 26 ]. These meth- ods can even handle a various scale of faces with diffi- cult conditions such as distortion, rotation, and occlusion. Among them, the f ace detectors [ 60 , 32 , 54 , 44 , 3 , 58 ] using multiple feature-maps from dif ferent layer locations, which mainly stem from [ 28 , 26 , 27 ], are dominantly used since ∗ Clov a AI Research, N A VER Corp. W e follow the alphabetical order except the first author . (a) (b) Figure 1. Illustration of the mean av erage precision (mAP) regard- ing the parameter size (a) and Flops (b) ev aluated on WIDER F A CE dataset. Our method (star) shows comparable mAP to S3FD [ 60 ] with a significantly smaller model. Red stars denote the proposed models with various sizes. ‘S3FD+M’ denotes the S3FD variation using MobileFaceNet [ 2 ] as a backbone network instead of VGG-16 [ 42 ]. Best vie wed in wide and colored vision. these methods can handle the faces with various scale in a single forward path. While these methods achieved impressi ve detection per- formance, they commonly share two problems. One is their large number of parameters. Since the y use a large classi- fication network such as V GG-16 [ 42 ], ResNet [ 11 ]-50 or 101, and DenseNet-169 [ 14 ], the number of total parame- ters exceed 20 million, ov er 80 Mb supposing 32 -bit float- ing point for each parameter . Furthermroe, the amount of floating point operations (FLOPs) also exceeds 100 G, and these make it nearly impossible to use the face detectors in CPU or mobile en vironment, where the most face appli- cations run in. The second problem, from the architecture perspectiv e, is the limited capacity of the low-le vel feature map in capturing object semantics. The most single-shot de- tector (SSD) [ 28 ] variant object and face detectors struggle the problem because the low-le vel feature map passes shal- low con volutional layers. T o alle viate the problem, the v ari- ants of Feature pyramid network (FPN) architecture such as [ 28 , 26 , 41 , 43 ] are used but requires additional parameters and memories for re-expanding the feature map. In this paper , we propose a new multi-scale face detector with extremely tiny size (EXTD) resolving the two men- tioned problems. The main disco very is that we can share the network in generating each feature-map, as shown in Figure 2 . As in the figure, we design a backbone network such that reduces the size of the feature map by half, and 1 we can get the other feature maps with recurrently pass- ing the network. The sharing can significantly reduce the number of parameters, and this enables our model to use more layers to generate the low-le vel feature maps used for detecting small faces. Also, the proposed iterativ e architec- ture makes the netw ork to observe the features from various scale of faces and from v arious layer locations, and hence offer abundant semantic information to the network, with- out adding additional parameters. Our baseline framew ork follows FPN-like structures, but can also be applied to SSD-like architecture. For SSD based architecture, we adopt the setting from [ 60 ]. F or the FPN ar- chitectures, we refer an up-sampling strategy from [ 23 ]. The backbone network is designed to have less than 0 . 1 million parameters with employing in verted residual blocks pro- posed in MobileNet-V2 [ 40 ]. W e note that our model does not require an y e xtra layer commonly defined as in [ 28 , 25 ], and is trained from scratch. W e ev aluated the proposed de- tector and its v ariants on WIDER F A CE [ 53 ] dataset, the most widely used and similar to the in-the-wild situation. The main contributions of this work can be summarized as follows: (1) W e propose an iterative network sharing model for multi-stage face detection which can significantly reduce the parameter size, as well as provide abundant ob- ject semantic information to the lower stage feature maps. (2) W e design a lightweight backbone network for the pro- posed iterati ve feature map generation with 0 . 1 M number of parameters, which less than 400Kb, and achieved com- parable mAP to the heavy face detection methods. (3) W e employ the iterati ve network sharing idea to the widely used detection architectures, FPN and SSD, and show the effec- tiv eness of the proposed scheme. 2. Related W orks Face detectors: Face detection has been an important re- search topic since an initial stage of computer vision re- searches. V iola et al . [ 46 ] proposed a f ace detection method using Haar features and Adaboost with decent performance, and sev eral different approaches [ 22 , 31 , 51 , 30 ] followed. After deep learning has become dominant, man y f ace detec- tion methods applying the techniques have been published. In the early stages, v arious attempts were tried to employ the deep architecture to face detection, such as cascade ar- chitecture [ 53 , 57 ], and occlusion handling [ 52 ]. Recent face detectors has been designed based on the architecture of generic object detectors including Faster- RCNN [ 38 ], R-FCN [ 4 ], SSD [ 28 ], FPN [ 26 ], and Reti- naNet [ 27 ]. Face RCNN and its variants [ 47 , 15 , 56 ] apply Faster -RCNN, and [ 50 , 62 ] use R-FCN for detecting faces with meaningful performance improv ements. Also, to cope with the various scale of faces with single forward path, object detectors such as SSD, RetinaNet, and FPN are dominantly adopted since the y use features from multiple layer locations for detecting objects with various scale in a single forward path. S3FD [ 60 ] achieved promis- ing performance by applying SSD with introducing multi- ple strategies to handle the small size of faces. F AN [ 48 ] uses RetinaNet by applying anchor level attention to de- tect the occluded f aces. After S3FD, man y improved v er- sions [ 44 , 54 , 61 , 21 , 58 ] are introduced and achiev ed per- formance gain from the previous methods. FPN based face detection methods [ 3 , 59 , 45 ] achiev ed SOT A performance by enhancing the expression capacity of the lower -level fea- ture map used for detecting small faces. The mentioned SOT A methods commonly use classifica- tion network such as VGG-16 [ 42 ], ResNet-50 or 101 [ 11 ], and DenseNet-169 [ 14 ] as a backbone of the model. These classification networks have a lar ge number of parameters exceeding 20 million, and the model size is ov er 80 Mb supposing 32 -bit floating point for each parameter . Some cascade methods such as [ 55 ] report decent mAP with the smaller mount of model size, about 3 . 8 Mb. Ho wever , the size is still burdensome to the devices like mobile, because users generally want their applications not to exceed few ten’ s of Mb. Also, the face detector should mostly be much smaller than the total size of the application because a face detector is usually an end-lev el function of the application. Here, we propose a new scheme of iterativ ely sharing the backbone network, which can be applicable to both SSD and FPN based architectures. The method achieves compa- rable accuracy to the original models, and the o verall model size is extremely smaller as well. Lightweight generic object detectors: Recently , for de- tecting general objects in condition with a limited re- source such as mobile devices, various single-stage, and two-stage lightweight detectors were proposed. F or the single-stage detectors, MobileNet-SSD [ 13 ], MobileNetV2- SSDLite [ 40 ], Pelee [ 49 ] and T iny-DSOD [ 23 ] were pro- posed. For two-stage detectors, Light-Head R-CNN [ 24 ] and ThunderNet [ 35 ] were proposed. The mentioned meth- ods achiev ed meaningful accuracy and size trade-off, but we aim to de velop a detector which has a much smaller number of parameters with introducing a ne w paradigm, iterati ve use of the backbone network. Recurrent conv olutional network: The idea of recur- rently using con volutional layers has been applied to various computer vision applications. Sharesnet [ 1 ] and Iamnn [ 19 ] applied recurrent residual network into classification task. Guo et al . [ 9 ] reduce the parameters by sharing depth- wise con volutional filters in learning multiple visual domain data. The iterative sharing is also applied to dynamic rout- ing [ 16 ], fast inference of video [ 33 ], feature transfer [ 29 ], super-resolution [ 18 ], and recently in segmentation [ 20 ]. In this paper, we introduce a method applying the concept of iterativ e conv olutional layer sharing in the face detection task, which is the first to the best of our knowledge. Feature Extraction block, s = 2 Inverted Residual Block, s = 1 Inverted Residual Block, s = 1 Inverted Residual Block, s = 2 Upsample Block Upsample Block Upsample Block Upsample Block Upsample Block + + + + + 𝑓 : 160x160 𝑓 : 80x80 𝑓 : 40x40 𝑓 : 20x20 𝑓 : 10x10 𝑓 = 𝑔 : 5x5 𝑔 : 20x20 : Network Block : Feature map (FPN) : Feature map (SSD) 𝑔 : 10x10 𝑔 : 160x160 𝑔 : 40x40 𝑔 : 80x80 E(⋅) F(⋅) Figure 2. The ov erall framew ork of the proposed method. The structure recurrently generates the feature maps f i (SSD version), and we upsample the feature maps with skip connection to generate the feature maps g i (FPN v ersion). The classification and re gression heads can be attached to either f i and g i . 3. EXTD In this section, we introduce the main components of the proposed work including iterativ e feature map gener- ation, the architectures of the proposed face detection mod- els, backbone networks, and classification and regression head design. Also, implementation details for designing and training the models will be introduced. 3.1. Iterative F eature Map Generation Figure 2 sho ws the overall frame work of the proposed method with two v ariations, SSD-like, and FPN-like frame- works. In the proposed method, we get multiple feature maps with different resolutions by recurrently passing the backbone network. Let assume that F ( · ) and E ( · ) each de- notes the backbone network and the first Con v layer with stride two. Then, the iterati ve process is defined as follows: f i = F ( f i − 1 ) , i = 1 , ..., N , f 0 = E ( x ) . (1) Here, the set { f 1 , .., f N } denote the set of feature maps, and x is the image. In FPN version, we upsample each fea- ture map and connect the previous feature maps via skip- connection [ 11 , 39 ]. The upsampling step U i ( · ) is con- ducted with bilinear upsampling followed by an upsampling block composed of separable con volution and point-wise con volution, inspired by [ 23 ]. The resultant set of the fea- ture map G = { g 1 , ..., g N } is obtained as, g i +1 = U i ( g i )+ f N − i , i = 1 , ..., N − 1 , g 1 = f N . (2) For the SSD-like architecture, which is the first variant, we extract feature maps f i and connect the classification and regression head to the feature maps. In FPN-like archi- tecture, the feature maps g i from equation ( 2 ) are used. The classification and regression heads are designed by a 3x3 con volutional network and hence, both models are designed as a fully con volutional network. This enables the models to deal with various size of images. The detailed implementa- tion of the heads is introduced in below sections. For all the cases, we set the image x to hav e 640x640 resolution in training phase and use N = 6 number of fea- ture maps. Hence, we get 160x160, 80x80, 40x40, 20x20, 10x10 and 5x5 resolution feature maps. In each location of the feature map, prior anchor candidates for the face is de- fined, following the same setting as S3FD [ 60 ]. One notable property of this architecture is that this method pro vides more abundant semantic information in lower -lev el feature maps compared to the face detectors adopting SSD architecture. While the e xisting methods commonly report the problem that the lo wer-le vel feature maps only contain limited semantic information due to their limited length of depth, our iterati ve architecture repeatedly shows intermediate le vel features and the various scale of faces to the network. W e conjecture that the different fea- tures hav e similar semantics because the target objects in our case are faces, and the faces share homogeneous shapes (a) (b) (c) (d) (e) (f) Figure 3. Detailed configuration of the components. The terms s, p, g, c in , and c out denote the stride, padding, group, input channel width, and output channel width. Figures (a) and (b) each shows the initial and remaining inv erted residual blocks. In (c) and (d), upsampling block and the Feature extraction block are presented. Figures (e) and (f) each denotes the classification and regression head. For the acti vation function, PReLU or Leak y-ReLU are used for (a) and (b), and ReLU is used for the others. regardless of their scale dissimilar to general objects. In Section 4 , we show that the proposed method clearly en- hances the detection accuracy for small size faces, and this can be more improv ed by taking the FPN architecture. 3.2. Model Component Description In the proposed model, a lightweight backbone network reducing the feature map resolution by half is used. The net- work is composed of in verted residual blocks follo wed by one 3x3 con volutional (Con v) filter with stride 2, based on [ 40 , 2 ]. The in verted residual block is composed of a set of point-wise Conv , separable Conv , and point-wise Conv . In each block, the channel width is expanded in the first point-wsie Conv and then, squeezed by the last point-wise Con v filter . The default setting of the network depth is set to 6 or 8 , and the output channel width is set to 32 , 48 or 64 , which do not largely exceed overall 0 . 1 million param- eters. Different from MobileNet-V2 [ 40 ], PReLU [ 10 ] (or leaky-ReLU) is applied and sho wn to be more successful than ReLU in training the proposed recurrent architecture. This phenomenon will be further discussed in Section 4 . Other than the in verted residual block, the proposed ar- chitecture also includes feature extraction block, upsam- pling blocks, and classification and regression heads. The detailed description of the components is introduced in Fig- ure 3 . The figures in (a) and (b) each shows the in verted residual block architecture. Residual skip-connection is ap- plied when the input and output channel width are equiv- alent, and at the same time, the stride is set to one. The upsampling block in (c) consists of bilinear upsample layer followed by depth-wise and point-wise Con v blocks. Fea- ture extraction block (d) is defined by a 3x3 Conv network followed by batch normalization and the activation func- tion. The classification (e) and regression (f) heads are also defined by a 3x3 Conv netw ork. The implementation of the head is described in Section 3.3 . 3.3. Classification and Regression Head Design For detecting the faces using the generated feature maps, we use a classification head and a regression head for each feature map to classify whether each prior box contains a face, and to regress the prior box to the exact location. The classification and regression heads are both defined as sin- gle 3 x 3 Conv filters as sho wn in Figure 3 . The classifica- tion head C i has two-dimensional output channel c i except C 1 that having four-dimensional channels. For C 1 , we ap- ply Maxout [ 8 ] approach to select two of the four channels for alleviating the false positive rate of the small faces, as introduced in S3FD. The regression head R i is defined to hav e output feature r i to ha ve four -dimensionional channel, and each denotes width, height ratio, and center locations, adopting the dominantly used setting in RPN [ 38 ]. 3.4. T raining The proposed backbone network and the classification and regression head are jointly trained by a multitask loss function from RPN composed of a classification loss l c and a regression loss l r as, l ( { c j , r j } ) = λ N cls X j l c ( c j , c ∗ j ) + 1 N reg X j c ∗ j l r ( r j , r ∗ j ) (3) Here, j is the index of the anchor boxes, and the label c ∗ j ∈ { 0 , 1 } and r ∗ j is the ground truth of the anchor box. The label c ∗ j is set to 1 when Jaccard o verlap [ 6 ] between the anchor box and ground trurh box is higher than a threshold t . The denominator N cls denotes the total number of posi- tiv e and negati ve samples. The regression loss is computed only for the positive sample and hence, the number N reg is defined by N reg = P j c ∗ j . The parameter λ is defined to balance the two losses because N cls and N reg are different from each other . The vector r ∗ j denotes the ground truth box location and size for the face. The classification loss l c and the regression loss l r are defined as cross-entropy loss and smooth- ` 1 loss, respecti vely . The primary obstacle for the classification in the face de- tection task is a class imbalance problem between the face and the background, especially regarding the small faces. T o alleviate the problem, we also adopt the strategies including online hard ne gative mining and scale compensation anchor matching introduced in S3FD. Using the hard ne gative min- ing technique, we balance the ratio of positive and neg ati ve samples N neg /N pos to 3 and the balancing parameter λ is set to 4 . Also, from the scale compensation anchor match- ing strategy , we first pick the positiv e samples where the Jaccard overlap is o ver 0 . 35 , and then further pick the re- maining samples in sorted order from the samples that their Jaccard ov erlap is larger than 0 . 1 if the number of positive samples is insufficient. For Data augmentation, we follow the conv entional augmentation setting from S3FD. The augmentation in- cludes color distortions [ 12 ], random crop, horizontal flip, and vertical flip. The proposed method is implemented with PyT orch [ 34 ] and NA VER Smart Machine Learning (NSML) [ 17 ] system. Please refer Appendix A to see the detailed training and optimization settings for training the proposed network. Code will be av ailable at https:// github.com/clovaai . 4. Experiments In this section, we quantitativ ely and qualitatively an- alyze the proposed method with various ablations. For the quantitativ e analysis, we compare the detection perfor- mance of the proposed method and the SOT A f ace detection algorithms. Qualitati vely , we show that our method can suc- cessfully detect faces in v arious conditions. 4.1. Experimental Setting Datasets: we tested the proposed method and ablations of the method with WIDER F ACE [ 53 ] dataset, which is most recent and is similar to in-the-wild face detection sit- uation. The images in the dataset are divided into Easy , Medium, and Hard cases which are roughly categorized by different scales: large, medium, and small, of faces. The Hard case includes all the images of the dataset, and the Easy and Medium cases both are the subsets of the Hard case. The dataset has total 32,203 images with 393,703 la- beled faces and is split into training (40 % ), validation (20 % ) and testing (40 % ) set. W e trained the detectors with the training set and ev aluated them with validation and test sets. Comparison: Since our method follo wed the training and implementation details such as anchor design, data aug- mentation, and feature-map resolution design equiv alent to S3FD [ 60 ], which has become one of the baseline meth- ods in face detection field, we mostly ev aluated the perfor- mance by comparing the S3FD model and its SO T A vari- ations [ 44 , 21 ]. The other techniques based on the S3FD model such as Pyramid anchor [ 44 ], Feature enhancement module, Improv ed anchor matching, and Progressi ve an- chor loss [ 21 ] would be able to be adapted to the pro- posed model without re vising the proposed structure. Also, we used the MobileFaceNet [ 2 ], the face variant of the MobileNet-V2 [ 40 ], to the S3FD model instead of VGG-16 to see the effecti veness of the proposed method compared to the case of using the lightweight backbone network. V ariations: W e applied the proposed recurrent scheme mainly into the FPN-based structure. For the model, we de- signed three v ariations which have a different number of parameters, lighter one having 0 . 063 M parameters with 32 channels for each feature maps, intermediate one having 0 . 1 M parameters with 48 channels, and the heavier one with 64 channels and 0 . 16 M parameters when designed as FPN. See Appendix B for the detailed configuration of the back- bone networks for each case. Also, we tested dif ferent activ ation functions: ReLU, PReLU, and Leaky-ReLU for each model. The negativ e slope of the Leaky-ReLU is set to 0 . 25 , which is identical to the initial negati ve slope of the PReLU. In the following section, we will term each v ariation by a combination of abbreviations; EXTD-model-channel-activation . For exam- ple, the term EXTD-FPN-32-PReLU denotes the proposed model combined with FPN, with feature channel width 32 and with activ ation function PReLU. As an ablation, we also applied the proposed recurrent backbone into SSD-like structure as well. The ablation was trained and tested with the same conditions to the FPN- based version and abbreviated as SSD . Same as FPN case, for example, the term EXTD-SSD-32-PReLU denotes the proposed model combined with SSD, with feature channel width 32 and with acti vation function PReLU. 4.2. Perf ormance Analysis In T able 1 , we list the quantitative ev aluation results of face detection in WIDER F A CE dataset and the comparison to the SO T A f ace detectors. The table shows the mAP of the models on Easy , Medium, Hard cases for both validation and test sets of the dataset. Also, the table includes model information such as their backbone networks, number of pa- rameters, and total number of adder arithmetics (Madds). In Figure 4 , the precision recall curv e for the proposed and the other methods are presented. Figure 5 shows the examples of the face detection results from images with various con- ditions. In Figure 6 , we ev aluate the latency of the models in terms of the resolution of images, which measured via a machine with CPU i7 core and NVIDIA TIT AN-X. For a fair comparison, all the inference processes of the models are implemented by PyT orch 1.0. Comparison to the Existing Methods: The results in T able 1 shows that some variations of the proposed method achiev ed comparable performance to the baseline model S3FD. Among lighter models and intermediate models, EXTD-FPN-32-PReLU and EXTD-FPN-48-PReLU each got a mAP score 3 . 4% and 1 . 2% lower than S3FD in WIDER Face hard v alidation set. When compared to S3FD trained scratch, EXTD-FPN-64-PReLU achie ved ev en per- formances. For the heavier version, we found that our FPN variant achieved nearly the same accuracy , only 0 . 3% in WIDER F A CE hard v alidation set and 0 . 8% in test set to S3FD in spite of the huge model size and memory usage gaps. It is meaningful in that the proposed detectors: lighter , intermediate, and heavier versions, are about 343 , 220 , and Model Backbone # Params # Madds (G) Easy (mAP) WIDER F ACE Medium (mAP) Hard (mAP) PyramidBox [ 44 ]* VGG-16 57 M 129 0.961 / 0.956 0.950 / 0.946 0.887 / 0.887 DSFD [ 21 ]-ResNet101* ResNet101 399 M - 0.963 0.954 0.901 DSFD-ResNet152* ResNet152 459 M - 0.966 / 0.960 0.957 / 0.953 0.904 / 0.900 S3FD [ 60 ]* VGG-16 22 M 128 0.942 / 0.937 0.930 / 0.925 0.859 / 0.858 S3FD - Scratch VGG-16 22 M 128 0.931 0.920 0.846 S3FD + MobileFaceNet [ 2 ] MobileFaceNet 1.2 M 12.7 0.881 0.859 0.741 EXTD-FPN-32-PReLU - 0.063 M 4.52 0.896 0.885 0.825 EXTD-FPN-48-PReLU - 0.10 M 6.67 0.913 0.904 0.847 EXTD-FPN-64-PReLU - 0.16 M 11.2 0.921 / 0.912 0.911 / 0.903 0.856 / 0.850 T able 1. Quantitative comparison to recent state-of-the-art f ace detectors on WIDER F A CE dataset. ‘*’ denotes results reported in the original papers. For the proposed model with highest validation mAP , we list the mAPs from validation set and that from test set at the left-side and right-side of the slash in fifth to sev enth columns. The other cases, mAPs from the validation set are listed. 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.926 F aceness-WIDER - 0.714 T wo-stage CNN - 0.681 DSFD - 0.966 ISRN - 0.968 Multitask Cascade CNN - 0.849 VIM-FD - 0.965 SSH - 0.931 F ace R-CNN - 0.938 CMS-RCNN - 0.899 MSCNN - 0.917 Zhu et al. - 0.949 ScaleF ace - 0.868 F AN - 0.952 ETF - 0.921 SRN - 0.964 SFD - 0.938 F ace R-FCN - 0.947 DFS - 0.957 PyramidBox - 0.961 F ANet - 0.956 (a) V alidation Easy 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.910 F aceness-WIDER - 0.635 T wo-stage CNN - 0.619 DSFD - 0.957 ISRN - 0.959 Multitask Cascade CNN - 0.826 VIM-FD - 0.954 SSH - 0.921 F ace R-CNN - 0.922 CMS-RCNN - 0.875 MSCNN - 0.904 Zhu et al. - 0.934 ScaleF ace - 0.867 F AN - 0.940 ETF - 0.911 SRN - 0.953 SFD - 0.926 F ace R-FCN - 0.936 DFS - 0.948 PyramidBox - 0.950 F ANet - 0.948 (b) V alidation Medium 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.806 F aceness-WIDER - 0.346 T wo-stage CNN - 0.324 DSFD - 0.905 ISRN - 0.909 Multitask Cascade CNN - 0.598 VIM-FD - 0.904 SSH - 0.846 F ace R-CNN - 0.831 CMS-RCNN - 0.624 MSCNN - 0.803 Zhu et al. - 0.861 ScaleF ace - 0.773 F AN - 0.901 ETF - 0.856 SRN - 0.902 SFD - 0.859 F ace R-FCN - 0.875 DFS - 0.897 PyramidBox - 0.889 F ANet - 0.895 (c) V alidation Hard 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.924 T wo-stage CNN - 0.657 F aceness-WIDER - 0.716 ISRN - 0.964 Multitask Cascade CNN - 0.851 VIM-FD - 0.963 SSH - 0.927 F ace R-CNN - 0.932 CMS-RCNN - 0.903 MSCNN - 0.917 Zhu et al. - 0.950 ScaleF ace - 0.867 F AN - 0.947 SRN - 0.959 SFD - 0.935 EXTD - 0.912 F ace R-FCN - 0.943 DFS - 0.949 PyramidBox - 0.956 F ANet - 0.948 (d) T est Easy 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.911 T wo-stage CNN - 0.589 F aceness-WIDER - 0.605 ISRN - 0.954 Multitask Cascade CNN - 0.820 VIM-FD - 0.954 SSH - 0.916 F ace R-CNN - 0.917 CMS-RCNN - 0.874 MSCNN - 0.904 Zhu et al. - 0.936 ScaleF ace - 0.867 F AN - 0.936 SRN - 0.949 SFD - 0.922 EXTD - 0.903 F ace R-FCN - 0.931 DFS - 0.940 PyramidBox - 0.946 F ANet - 0.940 (e) T est Medium 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Recall 0 . 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 Precision HR - 0.820 T wo-stage CNN - 0.304 F aceness-WIDER - 0.316 ISRN - 0.903 Multitask Cascade CNN - 0.608 VIM-FD - 0.903 SSH - 0.844 F ace R-CNN - 0.827 CMS-RCNN - 0.643 MSCNN - 0.810 Zhu et al. - 0.865 ScaleF ace - 0.765 F AN - 0.886 SRN - 0.897 SFD - 0.858 EXTD - 0.850 F ace R-FCN - 0.877 DFS - 0.891 PyramidBox - 0.887 F ANet - 0.888 (f) T est Hard Figure 4. R OC curves on WIDER F ACE dataset. Best vie wed in wide vision. The curves from our method are illustrated by ‘black’. 138 times lighter in model size and are 28 . 3 , 19 . 2 , and 11 times lighter in Madds. When compared to SOT A face detectors such as Pyra- midBox [ 44 ] and DSFD [ 21 ], our best model EXTD-FPN- 64-PReLU achie ved lo wer results. The margin between PyramidBox and the proposed model on WIDER F A CE hard case was 3 . 4% . Considering that PyramidBox inher - its from S3FD and our model follows the equi valent train- ing and detection setting to S3FD, our model would have a possibility to further increase the detection performance by adding the schemes proposed in PyramidBox. The mAP gap to DSFD, which is tremendously heavier , is about 5 . 0% , but it would be safe to suggest that the proposed method offers more decent trade-off in that DSFD uses about 2860 times more parameters than the proposed method. This is also meaningful result in that our method did not use an y kind of pre-training of the backbone netw ork using the other dataset such as ImageNet [ 5 ]. Figure 4 sho ws the ROC curves of the proposed EXTD-FPN-64-PReLU and the other meth- ods. From the graphs, we can see that our method is in- cluded in the SO T A group of the detectors using heavy- weight pre-trained backbone networks. When it comes to our SSD-based v ariations, they got lower mAP results than FPN-based variants. Howe ver , when compared with the S3FD version trained with Mo- bileFaceNet backbone network, the proposed SSD variants Figure 5. Illustration of the face detection results. The illustration includes vulnerable cases such as scale, illumination, face print, occlusion, pose, color , and paintings. EXTD-FPN-64-PReLU version was used to detect the images. Best viewed in wide and colored vision. 400 600 800 1000 1200 Image Resolution 0 5 10 15 20 25 30 35 Frame per Second (FPS) S3FD S3FD-MobileF aceNet Ours-FPN-32-PReLU Ours-FPN-48-PReLU Ours-FPN-64-PReLU Figure 6. Ev aluation time gi ven image resolutions (a veraged 1000 trials each). The horizontal axis denotes the size of an image and the v ertical axis sho ws the frame per second (FPS). The model with the higher value means that it has f aster inference speed. achiev ed comparable or better detection performance. It is a meaningful result in that the proposed variations hav e smaller feature map width, S3FD-MobileFaceNet holds fea- ture map size of [64 , 128 , 128 , 128 , 128 , 128] , and use the smaller number of layer blocks; in verted residual blocks same as MobileFaceNet, repeatedly . This shows that the proposed itertati ve scheme ef ficiently reduces the number of parameters without loss of accuracy . Also, from the graph in Figure 6 , we showed that our EXTD achie ved faster inference speed to the S3FD, which is considered as real-time face detector , in a wide range of an input image resolution. This shows that the proposed face detector can safely alter S3FD without losing accuracy and with consuming much smaller capacity , as well as main- taining the inference speed. It is interesting to note that the inference was much slow when using MobileFaceNet in- stead of V GG-16. It would mainly be due to that Mobile- FaceNet version should pass more filters (48) than V GG-16 version (24), and the inference times of the filters including pooling, depth-wise, point-wise and ordinary conv olutional filters are not that different in Pytorch implementation. Detection performance regarding the Face Scale: One notable characteristic of the proposed method captured from the ev aluation is that our detector obtained better per- formance when dealing with a small size of faces. From the table, we can see that our method achiev ed higher per- formance in WIDER F A CE hard dataset than other cases. Since the Easy and Medium cases are subsets of the Hard dataset, this means that the proposed method is especially fitted to capture small sized faces. This tendency is com- monly observed for different variations, for the different model architecture, and for the dif ferent channel widths. This supports the proposition suggested in Section 3.1 that the proposed recurrent structure strengthens the feature map, especially for the lo wer-le vel feature maps, and hence enhance the detection performance of the small faces. 4.3. V ariation Analysis The ev aluation on the variations of the proposed EXTD is summarized in T able 2 . The table mainly consists of three blocks in rows. Each first, second, and third block lists the ev aluation results from the smaller version (32 channels), intermediate version (48 channel), and the heavier version (64 channel) with applying different acti vation functions. Model # Params # Madds (G) Easy (mAP) WIDER F ACE Medium (mAP) Hard (mAP) EXTD-SSD-32-ReLU 0.056 M 4.35 0.791 (-0.105) 0.770 (-0.115) 0.629 (-0.196) EXTD-SSD-32-LReLU 0.056 M 4.35 0.851 (-0.045) 0.836 (-0.049) 0.736 (-0.089) EXTD-SSD-32-PReLU 0.056 M 4.35 0.870 (-0.026) 0.855 (-0.030) 0.757 (-0.068) EXTD-FPN-32-ReLU 0.063 M 4.52 0.741 (-0.155) 0.735 (-0.150) 0.642 (-0.182) EXTD-FPN-32-LReLU 0.063 M 4.52 0.892 (-0.004) 0.884 (-0.001) 0.824 (-0.001) EXTD-FPN-32-PReLU 0.063 M 4.52 0.896 0.885 0.825 EXTD-SSD-48-ReLU 0.086 M 6.63 0.868 (-0.045) 0.852 (-0.052) 0.742 (-0.105) EXTD-SSD-48-LReLU 0.086 M 6.63 0.879 (-0.034) 0.860 (-0.044) 0.744 (-0.103) EXTD-SSD-48-PReLU 0.086 M 6.63 0.897 (-0.016) 0.879 (-0.025) 0.774 (-0.073) EXTD-FPN-48-ReLU 0.10 M 6.67 0.894 (-0.019) 0.885 (-0.019) 0.825 (-0.022) EXTD-FPN-48-LReLU 0.10 M 6.67 0.911 (-0.002) 0.901 (-0.003) 0.846 (-0.001) EXTD-FPN-48-PReLU 0.10 M 6.67 0.913 0.904 0.847 EXTD-SSD-64-ReLU 0.14 M 10.6 0.887 (-0.034) 0.867 (-0.044) 0.752 (-0.104) EXTD-SSD-64-LReLU 0.14 M 10.6 0.896 (-0.025) 0.878 (-0.033) 0.769 (-0.087) EXTD-SSD-64-PReLU 0.14 M 10.6 0.905 (-0.016) 0.888 (-0.023) 0.784 (-0.072) EXTD-FPN-64-ReLU 0.16 M 11.2 0.910 (-0.011) 0.900 (-0.011) 0.844 (-0.012) EXTD-FPN-64-LReLU 0.16 M 11.2 0.914 (-0.007) 0.906 (-0.005) 0.850 (-0.006) EXTD-FPN-64-PReLU 0.16 M 11.2 0.921 0.911 0.856 T able 2. V ariation study on WIDER F A CE validation dataset. The models with boldface denotes the representativ e models for each block. The value in the parentheses sho ws the margin between the best model in the block (written in boldface). Effect of the Model Architectur e: From the table, we can find two common observations among the proposed variations. First, for all the different channel width, FPN based architecture achieved better detection performance compared to SSD based architecture, especially for detect- ing small faces. The idea of expanding the number of lay- ers for reaching the largest sized feature-map, for detect- ing the smallest size of objects, is a common strategy for SSD v ariant methods. This approach assumes that typical SSD structure passes too small number of layers and hence, the resultant feature-map could not import much informa- tion useful for the detection task. In the face detection task, this assumption seems to be correct in that the FPN based models notably achiev ed superior detection performance on small faces compared to SSD based models for all the cases. Second, for both SSD based and FPN based model, chan- nel width was another key factor for performance enhance- ment. As the channel width increased by 32 to 64 , we can see that the detection accuracy significantly enhanced for all the cases; Easy , Medium, and Hard. Considering that we used a smaller number of layers for 48 and 64 channel cases than the case with 32 channel, this sho ws that hav- ing enough size of channel width is critical for embedding sufficient information to the feature map for detecting f aces. Effect of the Activation functions: From the ev alua- tion, we found that the choice of the activ ation function is another factor gov erning the detection performance of the proposed method. In all the cases including FPN based and SSD based structures, PReLU was the most effecti ve choice when it comes to mAP , but the g ap between Leaky-ReLU was not that significant for the FPN variants. When tested with SSD based architecture, PReLU outperformed Leaky- ReLU with larger mar gin than those using FPN structure. It is worth noting that ReLU occurred notable perfor- mance decreases especially when the channel width was small for both SSD and FPN cases. When the channel width was set to 32 , mAP for all the three cases were lower than 10% to 20% compared to those using other acti vation func- tions. The decreases were alleviated as the channel width in- creased. When the channel width was 48 , the gap was about 2 . 2% , and in the channel width 64 case, the mar gin was about 1 . 2% . From the results, we conjecture that the nature of ReLU that set all the negati ve values to zero occurs infor - mation loss in the proposed iterative process since it makes the feature map too sparse, and this information loss would be much critical when the channel width is small. 5. Conclusion In this paper , we proposed a new face detector which significantly reduces the model sizes as well as maintaining the detection accuracy . By re-using backbone network lay- ers recurrently , we reduced the vast amount of the network parameters and also obtained comparable performance to recent deep f ace detection methods using hea vy backbone networks. W e showed that our methods achie ved v ery close mAP to the baseline S3FD only with hundreds time smaller parameters and with using tens time smaller Madd without using pre-training. W e expect that our method can be fur - ther improved by applying recent techniques of the SOT A detectors which integrated to S3FD. Acknowledgement W e are grateful to Clova AI members with valuable discussions, and to Jung-W oo Ha for proofreading the manuscript. References [1] A. Boulch. Sharesnet: reducing residual network pa- rameter number by sharing weights. arXiv pr eprint arXiv:1702.08782 , 2017. 2 [2] S. Chen, Y . Liu, X. Gao, and Z. Han. Mobilefacenets: Ef fi- cient cnns for accurate real-time face verification on mobile devices. In Chinese Confer ence on Biometric Recognition , pages 428–438. Springer , 2018. 1 , 4 , 5 , 6 [3] C. Chi, S. Zhang, J. Xing, Z. Lei, S. Z. Li, and X. Zou. Selec- tiv e refinement network for high performance f ace detection. arXiv pr eprint arXiv:1809.02693 , 2018. 1 , 2 [4] J. Dai, Y . Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully con volutional networks. In Advances in neural information pr ocessing systems , pages 379–387, 2016. 1 , 2 [5] J. Deng, W . Dong, R. Socher , L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09 , 2009. 6 [6] D. Erhan, C. Szegedy , A. T oshev , and D. Anguelov . Scalable object detection using deep neural networks. In Pr oceed- ings of the IEEE conference on computer vision and pattern r ecognition , pages 2147–2154, 2014. 4 [7] R. Girshick. Fast r-cnn. In Pr oceedings of the IEEE inter- national conference on computer vision , pages 1440–1448, 2015. 1 [8] I. J. Goodfellow , D. W arde-Farley , M. Mirza, A. Courville, and Y . Bengio. Maxout networks. arXiv preprint arXiv:1302.4389 , 2013. 4 [9] Y . Guo, Y . Li, R. Feris, L. W ang, and T . Rosing. Depthwise con volution is all you need for learning multiple visual do- mains. arXiv preprint , 2019. 2 [10] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Pr oceedings of the IEEE international con- fer ence on computer vision , pages 1026–1034, 2015. 4 , 11 [11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learn- ing for image recognition. In Proceedings of the IEEE con- fer ence on computer vision and pattern recognition , pages 770–778, 2016. 1 , 2 , 3 [12] A. G. How ard. Some improvements on deep con volutional neural netw ork based image classification. arXiv pr eprint arXiv:1312.5402 , 2013. 5 [13] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W . W ang, T . W eyand, M. Andreetto, and H. Adam. Mobilenets: Effi- cient conv olutional neural networks for mobile vision appli- cations. arXiv preprint , 2017. 2 [14] G. Huang, Z. Liu, L. V an Der Maaten, and K. Q. W ein- berger . Densely connected con volutional networks. In Pr o- ceedings of the IEEE confer ence on computer vision and pat- tern r ecognition , pages 4700–4708, 2017. 1 , 2 [15] H. Jiang and E. Learned-Miller . Face detection with the faster r-cnn. In 2017 12th IEEE International Confer ence on A utomatic F ace & Gestur e Recognition (FG 2017) , pages 650–657. IEEE, 2017. 2 [16] I. Kemae v , D. Polyk ovskiy , and D. V etrov . Reset: Learn- ing recurrent dynamic routing in resnet-like neural netw orks. arXiv pr eprint arXiv:1811.04380 , 2018. 2 [17] H. Kim, M. Kim, D. Seo, J. Kim, H. Park, S. Park, H. Jo, K. Kim, Y . Y ang, Y . Kim, et al. Nsml: Meet the mlaas platform with a real-world case study . arXiv preprint arXiv:1810.09957 , 2018. 5 [18] J. Kim, J. Kw on Lee, and K. Mu Lee. Deeply-recursive con- volutional network for image super-resolution. In Pr oceed- ings of the IEEE conference on computer vision and pattern r ecognition , pages 1637–1645, 2016. 2 [19] S. Leroux, P . Molchanov , P . Simoens, B. Dhoedt, T . Breuel, and J. Kautz. Iamnn: Iterativ e and adaptive mobile neural network for efficient image classification. arXiv preprint arXiv:1804.10123 , 2018. 2 [20] H. Li, P . Xiong, H. Fan, and J. Sun. Dfanet: Deep fea- ture aggregation for real-time semantic segmentation. arXiv pr eprint arXiv:1904.02216 , 2019. 2 [21] J. Li, Y . W ang, C. W ang, Y . T ai, J. Qian, J. Y ang, C. W ang, J. Li, and F . Huang. Dsfd: dual shot face detector . arXiv pr eprint arXiv:1810.10220 , 2018. 2 , 5 , 6 [22] S. Z. Li, L. Zhu, Z. Zhang, A. Blak e, H. Zhang, and H. Shum. Statistical learning of multi-view face detection. In Eur opean Confer ence on Computer V ision , pages 67–81. Springer, 2002. 2 [23] Y . Li, J. Li, W . Lin, and J. Li. T iny-dsod: Lightweight ob- ject detection for resource-restricted usages. arXiv preprint arXiv:1807.11013 , 2018. 2 , 3 , 11 [24] Z. Li, C. Peng, G. Y u, X. Zhang, Y . Deng, and J. Sun. Light- head r-cnn: In defense of two-stage object detector . arXiv pr eprint arXiv:1711.07264 , 2017. 2 [25] T .-Y . Lin, P . Doll ´ ar , R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. arXiv pr eprint arXiv:1612.03144 , 2016. 2 [26] T .-Y . Lin, P . Doll ´ ar , R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , pages 2117–2125, 2017. 1 , 2 [27] T .-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Doll ´ ar . Focal loss for dense object detection. In Proceedings of the IEEE international confer ence on computer vision , pages 2980– 2988, 2017. 1 , 2 [28] W . Liu, D. Anguelov , D. Erhan, C. Szegedy , S. Reed, C.- Y . Fu, and A. C. Berg. Ssd: Single shot multibox detector . In European confer ence on computer vision , pages 21–37. Springer , 2016. 1 , 2 [29] Y . Liu. Efficient Recurrent Residual Networks Impr oved by F eature T ransfer . PhD thesis, Delft Univ ersity of T echnol- ogy , 2017. 2 [30] M. Mathias, R. Benenson, M. Pedersoli, and L. V an Gool. Face detection without bells and whistles. In Eur opean con- fer ence on computer vision , pages 720–735. Springer, 2014. 1 , 2 [31] T . Mita, T . Kanek o, and O. Hori. Joint haar -like features for face detection. In T enth IEEE International Conference on Computer V ision (ICCV’05) V olume 1 , volume 2, pages 1619–1626. IEEE, 2005. 2 [32] M. Najibi, P . Samangouei, R. Chellappa, and L. S. Da vis. Ssh: Single stage headless face detector . In Pr oceedings of the IEEE International Conference on Computer V ision , pages 4875–4884, 2017. 1 [33] B. Pan, W . Lin, X. Fang, C. Huang, B. Zhou, and C. Lu. Re- current residual module for fast inference in videos. In Pro- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 1536–1545, 2018. 2 [34] A. Paszk e, S. Gross, S. Chintala, G. Chanan, E. Y ang, Z. De- V ito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer . Auto- matic differentiation in p ytorch. 2017. 5 [35] Z. Qin, Z. Li, Z. Zhang, Y . Bao, G. Y u, Y . Peng, and J. Sun. Thundernet: T owards real-time generic object de- tection. arXiv preprint , 2019. 2 [36] J. Redmon and A. Farhadi. Y olo9000: better , faster , stronger . In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , pages 7263–7271, 2017. 1 [37] J. Redmon and A. Farhadi. Y olov3: An incremental improv e- ment. arXiv preprint , 2018. 1 [38] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: T o wards real-time object detection with region proposal networks. In Advances in neural information pr ocessing systems , pages 91–99, 2015. 1 , 2 , 4 [39] O. Ronneberger , P . Fischer, and T . Brox. U-net: Con volu- tional networks for biomedical image segmentation. In In- ternational Conference on Medical imag e computing and computer-assisted intervention , pages 234–241. Springer , 2015. 3 [40] M. Sandler, A. How ard, M. Zhu, A. Zhmoginov , and L.-C. Chen. Mobilenetv2: Inv erted residuals and linear bottle- necks. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 4510–4520, 2018. 2 , 4 , 5 , 11 [41] Z. Shen, Z. Liu, J. Li, Y .-G. Jiang, Y . Chen, and X. Xue. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Confer- ence on Computer V ision , pages 1919–1927, 2017. 1 [42] K. Simonyan and A. Zisserman. V ery deep con volutional networks for large-scale image recognition. arXiv pr eprint arXiv:1409.1556 , 2014. 1 , 2 [43] S. Sun, J. Pang, J. Shi, S. Y i, and W . Ouyang. Fishnet: A versatile backbone for image, region, and pixel lev el predic- tion. In Advances in Neur al Information Pr ocessing Systems , pages 754–764, 2018. 1 [44] X. T ang, D. K. Du, Z. He, and J. Liu. Pyramidbox: A conte xt- assisted single shot face detector . In Pr oceedings of the Eu- r opean Confer ence on Computer V ision (ECCV) , pages 797– 813, 2018. 1 , 2 , 5 , 6 [45] W . T ian, Z. W ang, H. Shen, W . Deng, B. Chen, and X. Zhang. Learning better features for face detection with feature fusion and segmentation supervision. arXiv preprint arXiv:1811.08557 , 2018. 1 , 2 [46] P . V iola, M. Jones, et al. Rapid object detection using a boosted cascade of simple features. 1 , 2 [47] H. W ang, Z. Li, X. Ji, and Y . W ang. F ace r-cnn. arXiv pr eprint arXiv:1706.01061 , 2017. 2 [48] J. W ang, Y . Y uan, and G. Y u. Face attention netw ork: an effecti ve face detector for the occluded faces. arXiv preprint arXiv:1711.07246 , 2017. 2 [49] R. J. W ang, X. Li, and C. X. Ling. Pelee: A real-time object detection system on mobile de vices. In Advances in Neural Information Pr ocessing Systems , pages 1963–1972, 2018. 2 [50] Y . W ang, X. Ji, Z. Zhou, H. W ang, and Z. Li. Detecting faces using region-based fully con volutional networks. arXiv pr eprint arXiv:1709.05256 , 2017. 1 , 2 [51] B. Y ang, J. Y an, Z. Lei, and S. Z. Li. Aggregate channel features for multi-vie w face detection. In IEEE international joint confer ence on biometrics , pages 1–8. IEEE, 2014. 2 [52] S. Y ang, P . Luo, C.-C. Loy , and X. T ang. From facial parts responses to face detection: A deep learning approach. In Pr oceedings of the IEEE International Confer ence on Com- puter V ision , pages 3676–3684, 2015. 2 [53] S. Y ang, P . Luo, C.-C. Lo y , and X. T ang. Wider f ace: A face detection benchmark. In Pr oceedings of the IEEE con- fer ence on computer vision and pattern recognition , pages 5525–5533, 2016. 1 , 2 , 5 [54] S. Y ang, Y . Xiong, C. C. Loy , and X. T ang. Face detection through scale-friendly deep conv olutional networks. arXiv pr eprint arXiv:1706.02863 , 2017. 1 , 2 [55] B. Y u and D. T ao. Anchor cascade for efficient face detec- tion. IEEE T ransactions on Image Processing , 28(5):2490– 2501, 2019. 2 [56] C. Zhang, X. Xu, and D. T u. Face detection using improved faster rcnn. arXiv pr eprint arXiv:1802.02142 , 2018. 2 [57] K. Zhang, Z. Zhang, Z. Li, and Y . Qiao. Joint face detection and alignment using multitask cascaded conv olutional net- works. IEEE Signal Processing Letters , 23(10):1499–1503, 2016. 2 [58] S. Zhang, L. W en, X. Bian, Z. Lei, and S. Z. Li. Single-shot refinement neural network for object detection. In Pr oceed- ings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 4203–4212, 2018. 1 , 2 [59] S. Zhang, R. Zhu, X. W ang, H. Shi, T . Fu, S. W ang, and T . Mei. Improved selectiv e refinement network for face de- tection. arXiv preprint , 2019. 2 [60] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. W ang, and S. Z. Li. S3fd: Single shot scale-in variant face detector . In Proceed- ings of the IEEE International Confer ence on Computer V i- sion , pages 192–201, 2017. 1 , 2 , 3 , 5 , 6 [61] C. Zhu, R. T ao, K. Luu, and M. Savvides. Seeing small faces from robust anchor’ s perspecti ve. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recogni- tion , pages 5127–5136, 2018. 2 [62] C. Zhu, Y . Zheng, K. Luu, and M. Savvides. Cms-rcnn: con- textual multi-scale region-based cnn for unconstrained face detection. arXiv preprint , 2016. 2 Figure 7. Backbone architectures for the recursiv e feature generation. Description 1 2 3 4 5 6 7 8 9 10 11 12 13 14 I-Residual type (a) (b) (b) (b) (b) (b) (b) (b) (b) (b) (b) (b) (b) (b) Output channel width 64 64 64 64 64 64 128 128 128 128 128 128 128 128 Hidden channel width 64 128 128 128 128 128 256 256 256 256 256 256 256 512 Stride 2 1 1 1 1 2 2 1 1 1 1 1 1 2 T able 3. Structure of MobileFaceNet backbone attached in S3FD. Three extra layers are attached to further reduce the feature map size. A ppendix A. Implementation detail For training the proposed architecture, a stochastic gradient descent optimizer (SGD) with learning rate 1 e − 3 , with 0 . 9 momentum, 0 . 0005 weight decay , and batch size 16 is used. The training is conducted from scratch, and the network weights were initialized with He-method [ 10 ]. The maximum iteration number is basically set to 240 K, and we drop the learning rate to 1 e − 4 and 1 e − 5 at 120 K and 180 K iterations. Also, we test the architecture with twice larger iterations 480 K as well. In this case, the learning rate is dropped at 240 K and 360 K iterations. Similar to the other networks using depth-wise separable networks [ 40 , 23 ], further performance improv ements were observed when training the network with lar ger iteration. A ppendix B. Detailed Ar chitecture Inf ormation Figure 7 shows the detailed structures of the backbone network for the v ariation having channel sizes 32 , 48 , and 64 . The layers in ‘blue’, ‘green’, and ‘red’ box es in the figure each denotes the version of the proposed detectors having channel width to 32, 48, and 64. Each model has parameter size 0 . 063 M, 0 . 10 M, and 0 . 16 M respectively , when designed as FPN structure. The term ‘I-Residual’ denotes the in verted residual block (a) and (b), where the configuration of the block is introduced in Figure 3 of the paper . The heavier versions which hav e 0 . 10 M, and 0 . 16 M model parameters are designed to hav e less number of parameters to reduce the parameter when compared to the lightest version. The results in the paper sho w that the width of the channels for each layer is more critical than the depth of the layers for the detection performance in the proposed model. A ppendix C. Implementation of S3FD with MobileF aceNet Backbone In the paper , we implemented the S3FD variation where the backbone network was set to MobileF aceNet instead of VGG- 16. The backbone netw ork consists of 14 in verted residual blocks follo wed by 3x3 con volutional filter which has output channel width 64 and stride two. The lowest-le vel in verted residual block is defined as in I-Residual (a), and the others are defined as I-Residual (b). The detailed setting of each blocks are described in T able 3 . W e added a classification and regression head at the bottom of layers 6, 7, and 14. After layer 14, three e xtra layers defined by 3x3 conv olutional filter with output channel width 128 are attached. This e xtra layer setting is equi v alent to original S3FD, and the resolutions of the feature maps are [64, 128, 128, 128, 128, 128] with total parameter number 1.2 million. The MobileFaceNet backbone itself is a reduced version of MobileNet-V2, and we only used the part of the MobileF aceNet layers. Ho wever , we can still see that the backbone network requires a lar ge number of parameters which makes challenging to be embedded in smaller de vices.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment