Data Augmentation for Drum Transcription with Convolutional Neural Networks
A recurrent issue in deep learning is the scarcity of data, in particular precisely annotated data. Few publicly available databases are correctly annotated and generating correct labels is very time consuming. The present article investigates into data augmentation strategies for Neural Networks training, particularly for tasks related to drum transcription. These tasks need very precise annotations. This article investigates state-of-the-art sound transformation algorithms for remixing noise and sinusoidal parts, remixing attacks, transposing with and without time compensation and compares them to basic regularization methods such as using dropout and additive Gaussian noise. And it shows how a drum transcription algorithm based on CNN benefits from the proposed data augmentation strategy.
💡 Research Summary
This paper presents a comprehensive investigation into data augmentation strategies to address the common challenge of limited annotated data in deep learning, specifically for the task of Automatic Drum Transcription (ADT). The core premise is that while Convolutional Neural Networks (CNNs) have shown strong performance in ADT, their generalization capability is often hindered by the scarcity and lack of diversity in precisely annotated training datasets. The study proposes and evaluates advanced, audio-domain-specific transformation techniques as a superior alternative to basic regularization methods.
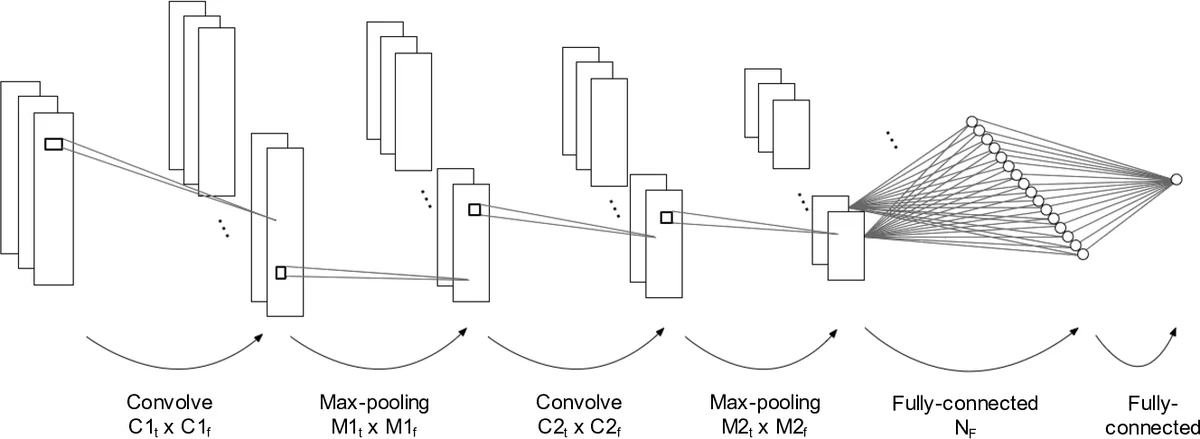
The research employs a Multi-Channel Mel Spectrogram (MCMS) as the input representation, which combines mel-spectrograms computed with three different window sizes (23ms, 46ms, 93ms) to capture multi-timescale features crucial for detecting percussive onsets. The model architecture is a CNN with two convolutional-pooling blocks followed by a fully-connected layer, trained separately for three primary drum instruments: bass drum (bd), snare drum (sd), and hi-hat (hh).
The methodological contribution centers on four high-quality audio transformations implemented using the AudioSculpt software: 1) Remixing Noise/Sinusoidal Parts: Separates and rebalances the harmonic and noisy components of a signal, altering its texture. 2) Remixing Attacks: Identifies and scales transient components, effectively modifying the sharpness or strength of drum attacks. 3) Transposition with Time Compensation: Changes the pitch while using a phase vocoder to preserve the original tempo and temporal envelope. 4) Transposition without Time Compensation: Changes the pitch by resampling, which also scales the timeline and thus alters the tempo. These can be combined with Spectral Envelope Transposition to further vary timbre.
The experiments use the MIREX 2018 drum transcription training dataset. A cross-validation framework is adopted, where models are trained on augmented versions of the data (created using each strategy with various parameter values) and evaluated on held-out original data. Performance is compared against two common regularization baselines: applying dropout and adding Gaussian noise to the input spectrograms.
The results yield several key findings. Overall, data augmentation consistently improves the F1-score over training on the original data alone. However, the effectiveness of different strategies varies significantly by instrument:
- For bass drum and snare drum, the proposed audio transformations (particularly remixing attacks and transposition without time compensation) provided the most substantial gains, outperforming both dropout and Gaussian noise.
- For hi-hat, the results were strikingly different. The best performance was achieved not by any of the complex audio transformations, but by the simple addition of Gaussian noise to the input spectrogram. This suggests that the spectral characteristics of hi-hats are so diverse that encouraging robustness through simple input noise is more beneficial than simulating specific acoustic variations.
The study also tested a combination of all four audio transformations, which yielded stable improvements but was not always the top performer for each instrument, indicating that task-specific augmentation strategies might be optimal.
In conclusion, the paper successfully demonstrates that advanced, perceptually-informed audio data augmentation is a powerful tool for improving CNN-based drum transcription systems. It moves beyond generic augmentation techniques by leveraging domain knowledge of sound structure. Crucially, it also highlights that there is no one-size-fits-all solution; the optimal augmentation strategy can depend heavily on the specific sub-task (i.e., the target instrument), advocating for a nuanced, instrument-aware approach to data augmentation in audio deep learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment