A Layered Aggregate Engine for Analytics Workloads
This paper introduces LMFAO (Layered Multiple Functional Aggregate Optimization), an in-memory optimization and execution engine for batches of aggregates over the input database. The primary motivation for this work stems from the observation that for a variety of analytics over databases, their data-intensive tasks can be decomposed into group-by aggregates over the join of the input database relations. We exemplify the versatility and competitiveness of LMFAO for a handful of widely used analytics: learning ridge linear regression, classification trees, regression trees, and the structure of Bayesian networks using Chow-Liu trees; and data cubes used for exploration in data warehousing. LMFAO consists of several layers of logical and code optimizations that systematically exploit sharing of computation, parallelism, and code specialization. We conducted two types of performance benchmarks. In experiments with four datasets, LMFAO outperforms by several orders of magnitude on one hand, a commercial database system and MonetDB for computing batches of aggregates, and on the other hand, TensorFlow, Scikit, R, and AC/DC for learning a variety of models over databases.
💡 Research Summary
The paper presents LMFAO (Layered Multiple Functional Aggregate Optimization), an in‑memory engine designed to evaluate very large batches of group‑by aggregates over the natural join of relational tables. The authors observe that many modern analytics—ridge regression, decision and regression trees, Chow‑Liu Bayesian network structure learning, and data‑cube construction—can be expressed as collections of aggregates that share the same join. Existing database systems excel at single‑query optimization but struggle with batches that number in the hundreds or thousands, leading to redundant computation, excessive I/O, and memory pressure.
LMFAO tackles this problem through a seven‑layer architecture. First, the Join‑Tree Layer builds a single optimal join tree for the whole batch, using state‑of‑the‑art hypertree decomposition when the query graph is cyclic. The novel Find‑Roots Layer then selects, for each aggregate, a possibly different root in the same join tree, allowing many aggregates to share intermediate views and reducing the total number of views by a factor of 2–5 in practice.
In the Aggregate‑Pushdown Layer, each aggregate is decomposed into directional views—one per edge of the join tree—so that partial aggregation is performed as early as possible, “pushing” the computation past joins. The Merge‑Views Layer consolidates these directional views by (i) eliminating duplicate views, (ii) merging views that share the same group‑by attributes and body but have different aggregate functions, and (iii) merging views that share group‑by attributes but have different bodies. This step dramatically shrinks the view set; for example, 814 aggregates over five tables in the Retailer dataset generate 3,256 raw views, which are merged down to just 34 views that collectively compute 1,468 aggregates.
The Group‑Views Layer clusters views that emanate from the same node but are independent, enabling a single scan of the underlying relation to feed all views in the group. The scan is organized as a trie (factorized representation), which can visit up to three times fewer tuples than a conventional row‑wise scan. The Multi‑Output Optimization Layer then creates an execution plan for each view group that performs one pass over the relation, using hash lookups into incoming views to retrieve the needed partial aggregates. This sharing of scans is especially beneficial for snow‑flake schemas with large fact tables.
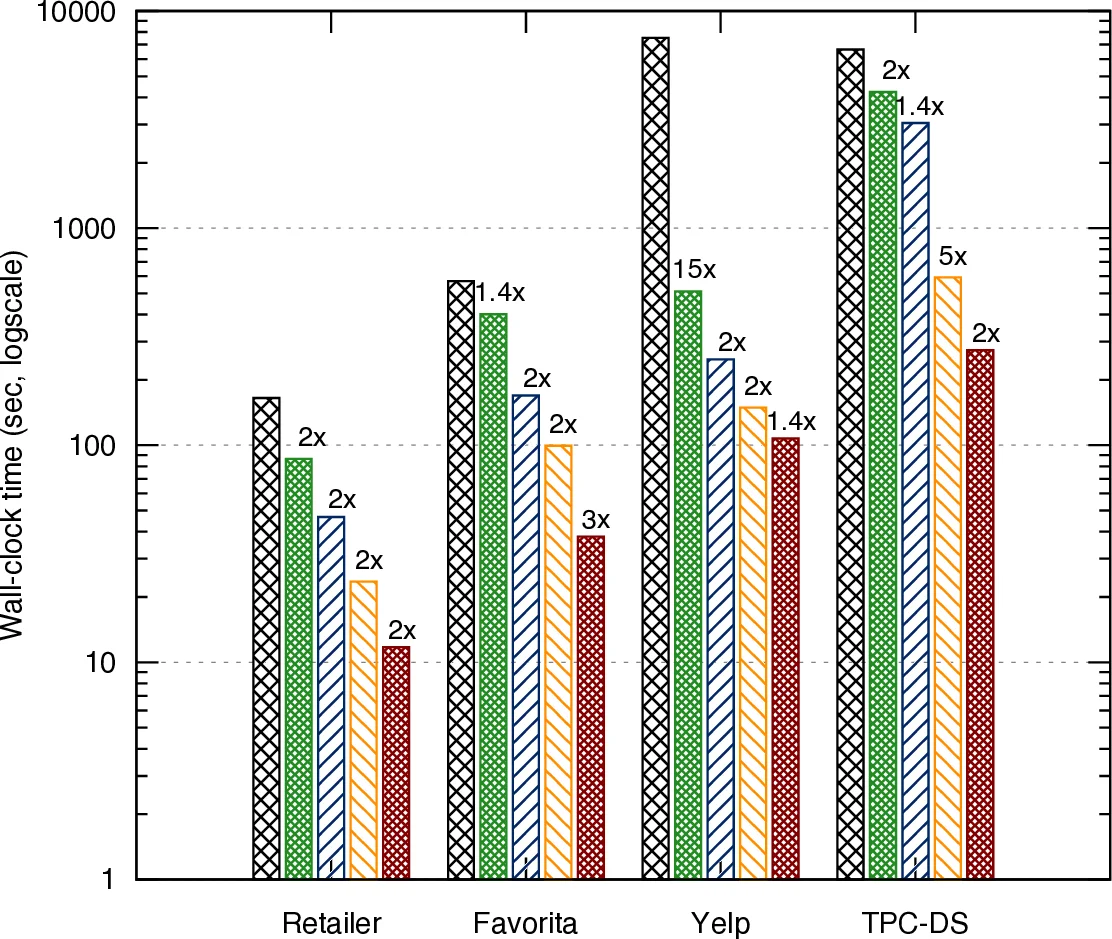
Parallelism is introduced in the Parallelization Layer: a dependency graph of view groups is built, independent groups are assigned to separate threads, and the largest input relations are partitioned. On a 4‑vCPU AWS instance, this yields an additional 1.4–3× speedup. Finally, the Compilation Layer automatically generates C++ code specialized to the specific join tree, schema, and set of aggregates. The generated code applies low‑level optimizations such as function inlining, contiguous storage of aggregate arrays, reuse of arithmetic operations, loop fusion, and vector‑like processing of aggregates. For aggregates that change between iterations (dynamic UDAFs), the engine emits separate compilation units that can be re‑linked at runtime, avoiding the overhead of repeated inlining.
The authors evaluate LMFAO on four real‑world datasets covering retail, e‑commerce, and other domains. They compare against PostgreSQL, MonetDB, a commercial DBMS for pure aggregate batch execution, and against TensorFlow, Scikit‑learn, R, and AC/DC for end‑to‑end model training. LMFAO outperforms the databases by 10⁰–10³× and the ML frameworks by 10⁰–10²×, largely because it eliminates the costly materialization of training data and computes all required statistics directly from the base relations. In ridge regression, LMFAO either computes the gradient vector on the fly or pre‑computes the full covariance matrix, both via aggregated queries, and achieves orders‑of‑magnitude speedups over conventional pipelines that first extract a flat feature table.
In summary, the paper’s contributions are: (1) a principled, layered approach to batch aggregate processing that introduces novel concepts such as multi‑root join‑tree traversals, directional view synthesis, and multi‑output execution plans; (2) a demonstration of the approach’s versatility across a spectrum of analytics tasks; and (3) an extensive experimental validation showing that LMFAO can dramatically surpass both mature database systems and modern machine‑learning libraries on realistic workloads. The work bridges the gap between database query processing and statistical learning, suggesting a new direction for tightly integrated analytics engines.
Comments & Academic Discussion
Loading comments...
Leave a Comment