A Monaural Speech Enhancement Method for Robust Small-Footprint Keyword Spotting
Robustness against noise is critical for keyword spotting (KWS) in real-world environments. To improve the robustness, a speech enhancement front-end is involved. Instead of treating the speech enhancement as a separated preprocessing before the KWS …
Authors: Yue Gu, Zhihao Du, Hui Zhang
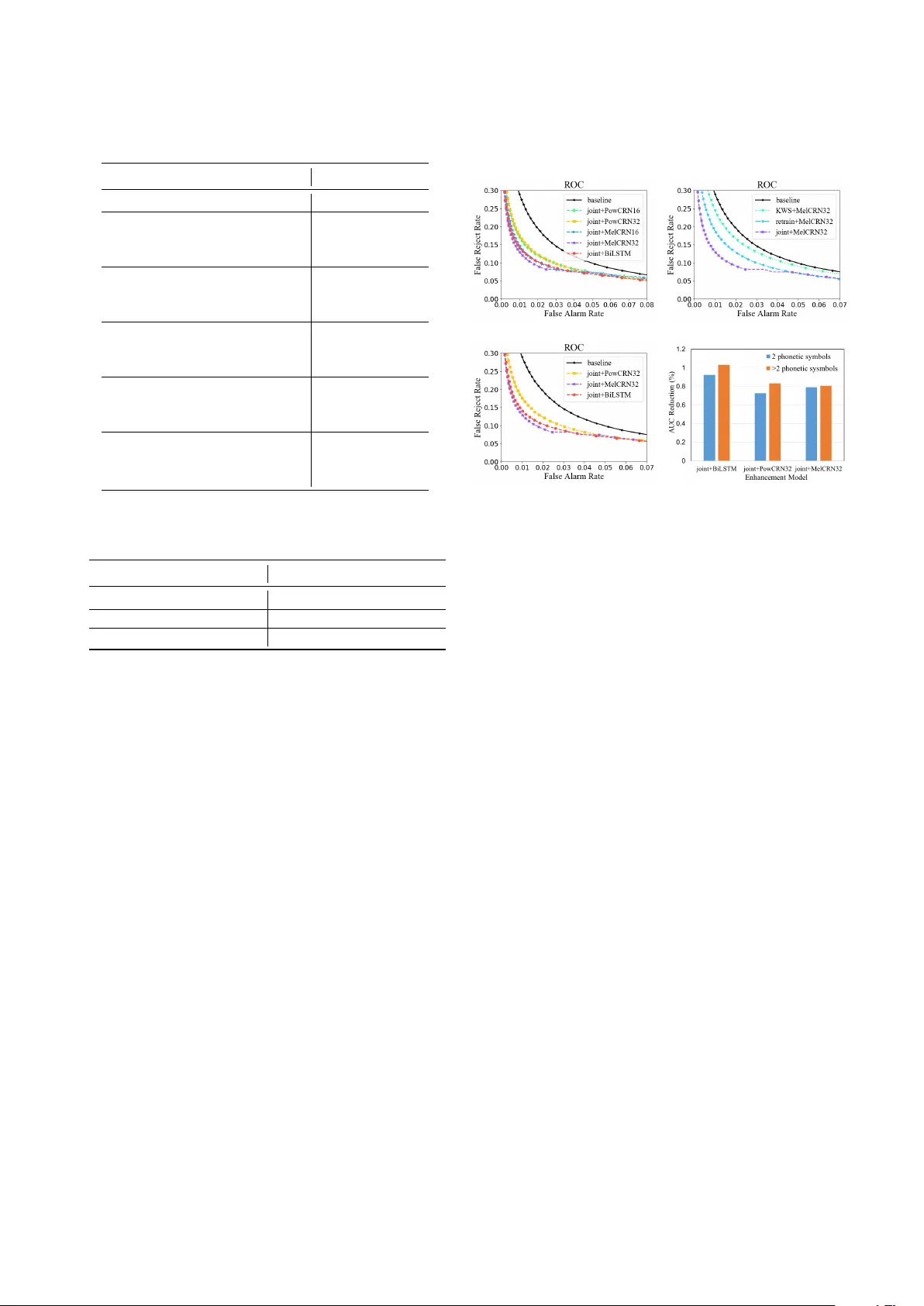
A Monaural Speech Enhancement Method f or Rob ust Small-F ootprint K eyword Spotting Y ue Gu 1 , Zhihao Du 2 , Hui Zhang 1 ∗ , Xueliang Zhang 1 1 Inner Mongolia K ey Laboratory of Mongolian Information Processing T echnology , Inner Mongolia Uni versity , Hohhot, China 2 School of Computer Science and T echnology , Harbin Institute of T echnology , Harbin, China 427gy@sina.com, 15b903064@hit.edu.cn, alzhu.san@163.com, cszxl@imu.edu.cn Abstract Robustness against noise is critical for keyword spotting (KWS) in real-world en vironments. T o improv e the robustness, a speech enhancement front-end is in volv ed. Instead of treating the speech enhancement as a separated preprocessing before the KWS system, in this study , a pre-trained speech enhancement front-end and a con volutional neural networks (CNNs) based KWS system are concatenated, where a feature transformation block is used to transform the output from the enhancement front-end into the KWS system’ s input. The whole model is trained jointly , thus the linguistic and other useful information from the KWS system can be back-propagated to the enhancement front-end to improve its performance. T o fit the small-footprint device, a nov el con volution recurrent network is proposed, which needs fewer parameters and computation and does not degrade performance. Furthermore, by changing the input features from the power spectrogram to Mel-spectrogram, less computation and better performance are obtained. our experimental results demonstrate that the proposed method significantly improves the KWS system with respect to noise robustness. Index T erms : Small footprint, speech enhancement, robust KWS 1. Introduction Ke yword spotting (KWS), also called ke yword detection (KWD) or spoken term detection (STD), is a crucial technique for human-computer interaction interface. For e xample, wake- up word detection on mobile devices is an typical scenario. It detects predefined wake-up words in a continuous audio stream. A good KWS system should have low false rejection rate and also lo w false alarm rate. Moreov er , KWS usually runs in “always-on” mode which requires low power consumption especially in small-footprint embedded systems. Currently , the KWS system performs well in a relatively quiet en vironment. For example, the latest research [1] achieved an accuracy of 95% on the Google’ s Speech Commands Dataset [2], with a small model. While, in noisy en vironments, KWS is still a challenge. In recent years, to increase the robustness against noise, a commonly and widely used method is multi-condition training [3–5] which train model with noisy utterances, directly . Ho wever , to achiev e a good performance, multi-condition training always need a large model, which is impossible to be deplo yed on devices with limited resources [6]. *Corresponding author . The first two authors contributed equally to this w ork. This research was supported in part by the China National Nature Science Foundation (No. 61876214, No. 61866030). Recently , with the rise of the deep learning, speech enhancement technique has made a significant progress [7]. In the automatic speech recognition (ASR) community , the front-end enhancement techniques have been introduced and hav e improv ed the rob ust ASR systems, where an enhancement front-end is employed to enhance the noisy speech before recognition. Then the recognizer can be trained on clean speech [8], or trained on enhanced speech [9]. After ASR, the front-end enhancement techniques hav e also been introduced in KWS. In [6], a text-dependent enhancement and KWS method has been developed and shown improvements on the noise robustness. Howe ver , its enhancement model is based on bidirectional long-short time memory ( BiLSTM) which needs too many parameters and computation, which does not fit the small-footprint device. In this paper , we propose a small-footprint enhancement method for the resource-limited KWS. Compared with the BiLSTM-based models, the proposed model achieves comparable or e ven better performance with much less parameters and computation. Considering speech enhancement and ke yword spotting are not two independent tasks, they can benefit each other . W e concatenate them to b uild a larger and deeper model, and then optimize them jointly to improve the noise robustness furtherly . Experimental results demonstrate the proposed joint- training method not only significantly outperforms the multi-conditional training method, b ut also outperforms the enhancement front-end methods, whether its KWS recognizer is trained on clean speech or on enhanced speech. W ith experiments, we find that for KWS task Mel-spectrogram is a better feature than the po wer spectrogram, which leads to better performance and lower computation complexity . W e also find with Mel-spectrogram the KWS system is less sensitiv e to the number of phonetic symbols in the keyw ords. 2. System description The overall frame work of our system is shown in Fig. 1. There are three components in the proposed system, i.e., speech enhancement model, feature transformation block and keyw ord spotting (KWS) model. The speech enhancement model is trained to predict the ideal ratio masks (IRMs) [10]. The enhanced spectrogram are obtained by point-wisely multiplying the noisy spectrogram with the predicted masks. Then the enhanced spectrogram are transformed to the Mel-frequency cepstral coefficients (MFCCs) by the feature transformation block. Given the MFCCs, the KWS model is trained to predict the posterior probability of k eywords. The details of these three components are giv en followingly . L o g S p e c t r o g r a m C o n v , BN , R e L U C o n v , BN , R e L U B i L S T M D e c onv , BN , L e a kyRe L U D e c o n v , BN , L e a k y R e L U FC E n h a n c e d F e a t u r e F e a t u r e T r a n s f o r m a t i o n K WS s y s t e m N o i s y S p e e c h S p e c t r o g r a m E s t i m a t e d M a s k S p e e c h E n h a n c e m e n t M o d e l Figure 1: Schematic diagram of the proposed system. Solid and dotted arr ows indicate the dir ections of forward pass and backwar d pass, respectively . See text for mor e details. 2.1. Speech enhancement model W e employ the masking-based speech enhancement method, which has successfully improved the human speech perceptive quality [11] and the noise rob ustness of ASR [12]. The loss function of masking-based method is defined as: L MSE = 1 T 1 F T X t =1 F X f =1 k M ( t, f ) − ˆ M ( t, f ) k 2 2 (1) where M ( t, f ) and ˆ M ( t, f ) are the ideal and predicted time- frequency (T -F) mask at time t and frequency f , respectiv ely . T and F are the total number of frames and frequency bins respectiv ely . The IRM M is defined as: M ( t, f ) = s | S ( t, f ) | 2 | S ( t, f ) | 2 + | N ( t, f ) | 2 (2) where S represents the spectrogram of the clean speech, N stands for the spectrogram of the noise signal. In test stage, the IRM is predicted from the noisy speech and the enhanced spectrogram can be obtained by: ˆ S = Y ⊗ ˆ M (3) where ˆ M is the mask predicted by the enhancement model. Y is the spectrogram of the noisy signal. ⊗ represents the element- wise matrix multiplication. The IRM can be defined in different T -F domains. Although the power spectrogram is a common choice in the speech enhancement community , there are better choice. In the proposed KWS system, the output of the enhancement model is feed into KWS model which requires the MFCC as input. While, the frequency bins in the power spectrograms are integrated to extract MFCCs by the Mel-filter bank. It means many information contained in the power spectrogram are filtered out. Therefore, it is not efficient and necessary to perform enhancement on the power spectrogram. In contrast, the Mel-spectrogram can be used to extract MFCCs, directly . So that we use the proposed enhancement model to predict IRM on the Mel-spectrogram. In this way , the spectrogram of noise N , clean speech S , and noisy speech Y , are all in the form of Mel-spectrogram. T o serve the small-footprint purpose, we design a novel con volution recurrent network (CRN) with the limiting parameters and computation. The architecture of CRN is shown as speech enhancement model in the lo wer part of the Fig. 1. There are two components in the CRN, i.e., the con volutional encoder-decoder and the RNN with LSTM cells followed by a linear projection layer . Skip connections are added to the corresponding layers between the encoder and decoder . Batch normalization [13] and rectified linear units (ReLUs) [14] are employed in the conv olutional layers and the leaky ReLUs (lReLUs) are used in the de-con volutional layers instead of ReLUs. Sigmoid nonlinearity is employed for the output layer . Note that there are two differences between the CRNs in [15] and ours. Firstly , with the limiting parameters and computation, the conv olution layers in our CRNs ha ve the strides on both time and frequency axises while the origin CRN only strides on the frequency axis. Secondly , we employ the lReLU at the decoding stage, which guarantees the nonzero gradients ev erywhere and benefits the optimizing processing of the encoding stage. 2.2. Featur e transformation block The input of KWS system is MFCC while the outputs of enhancement model are spectrograms. T o extract the MFCCs from the spectrograms, we design the feature transformation blocks (FTBs) which are shown in Fig. 2. T ransforming Mel-spectrogram to MFCC needs taking logarithm firstly then applying discrete cosine transformation (DCT). For comparison, an enhancement model trained to predict the IRM on the po wer spectrogram is also b uilt. For this model, we need transform the power spectrogram into MFCC. Similar to the Mel-spectrogram, to obtain MFCC from power spectrogram, the input should pass a Mel-filter bank, then take logarithm, at last apply a DCT . Note that both the Mel-filter bank filtering and the DCT can be implemented with the matrix multiplication which can be further represented as the linear layers in a neural network [16]. As a result, included the FTBs, the proposed systems can be trained with back-propagation algorithm. Figure 2: The feature transformation block for (a) Mel- spectr ogram and (b) power spectr ogram. E n h a n c e d M e l S p e c t r o g r a m D C T c o e f f i c i e n t L o g E n h a n c e d M F C C (a) Mel-spectrogram to MFCC E n h a n c e d P o w e r S p e c t r o g r a m M e l F i l t e r B a n k D C T c o e f f i c i e n t L o g E n h a n c e d M F C C (b) Power spectrogram to MFCC 2.3. Keyw ord spotting system W e employ the model cnn-trad-pool2 developed in [17] as our KWS system. This model div erges slightly from the model cnn-trad-fpool3 which is originally introduced in [15]. The size and stride of the first max-pooling layer are set to (2 , 2) and the hidden linear layers are dropped in cnn-trad-pool2 , which leads to better accuracy . 3. Experiments and results 3.1. Experimental settings W e evaluated the proposed models on Google’ s Speech Commands Dataset which contains 105,829 one-second long utterances and 6 background noise records (including pink noise, white noise, and daily en vironmental sounds such as doing the dishes, exercise bike, etc.) [2]. Follo wing Google’ s implementation, the task is to detect 10 ke ywords, unknown and silence. In our experiments, the baseline cnn-trad-pool2 follows the exactly the same procedure as the T ensorFlow reference. The dataset is split into the training, validation, and test set with the ratio of 8:1:1. Noisy utterances are obtained by mixing up with 6 noises at signal-to-noise ratios (SNRs) of {− 3 , 0 , 3 , 6 } . There are roughly 812k noisy examples for training and 97.6k each for validation and test. Another 25 keyw ords are employed to ev aluate the models, which are not in volv ed at the training phase. Finally , the test set contains 210k noisy utterances with keyw ords and non-keywords ratio of 1.3:1. T o ev aluate the generalization of the models, 100 Nonspeech Sounds 1 are employed, which are unseen at the training stage. The unmatched test set contains nearly 3.6M utterances. All the utterances are sampled to 16 kHz and the features are extracted with the window length of 30 ms and the shift length of 10 ms. The 480-point short-time Fourier transform is employed. The Mel-filter bank is calculated with the lo w frequency 20 Hz and high frequency 4 KHz. The 40-dimension DCT coefficients are used to e xtract MFCC. Accuracy is the main metric, which is simply measured as the fraction of classification decisions that correct. W e also plot receiv er operating characteristic (R OC) curv es, where the x and y axes show false alarm rate (F AR) and false reject rate (FRR), respectiv ely . Methods with less area under the curve (A UC) are better . Equal error rates (EERs) are also employed to shows the KWS performance with the enhancement models. All models are trained with the Adam optimizer [18] and the mini-batch size of 256 on the utterance-level. W e set the learning rate to 0.0001. The mean squared error (MSE) and cross entropy (CE) are the objectiv e functions of the enhancement model and KWS system, respecti vely . The best models are selected by the best accuracy on the v alidation set. W e ev aluate the proposed small-footprint CRNs on the po wer and Mel-spectrogram. For each spectrogram, we design two models with dif ferent model size. W e refer the full-size model trained on the power and Mel- spectrogram as PowCRN32 and MelCRN32 respectiv ely , and the narrow models are referred as PowCRN16 and MelCRN16 respectiv ely . The details of CRNs are shown in T ab . 1. As the comparison, a LSTM-based model is also ev aluated, which consists of two hidden layers with 384 bidirectional LSTM cells followed by a linear projection layer with 241 units. W e refer this enhancement model as BiLSTM [6]. The model size is given in T ab . 2. In T ab . 2, we list the parameter numbers 1 http://web .cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html and the computation complexity ev aluated by the number of multiply operation for each model. T able 1: The architectur es of small-footprint CRNs. T denotes the number of time frames in the spectr ogram. ( f , h ) is set to (16 , 32) and (32 , 64) for the narrow and full-size CRNs, r espectively . F or convolution and decon volution layers, the parameter indicates kernel size, stride and filter number . h stands for the number of bidir ectional LSTM cells. Layer Name Input Size Parameter Output Size PowCRN reshape 1 T × 241 - 1 × T × 241 con v 1 1 × T × 241 8 , 4 , f f × T / 4 × 60 con v 2 f × T / 4 × 60 8 , 4 , f f × T / 16 × 15 reshape 1 f × T / 16 × 15 - T / 16 × 15 f BiLSTM T / 16 × 15 f h T / 16 × h FC T / 16 × h 15 f T / 16 × 15 f reshape 2 T / 16 × 15 f - 2 f × T / 16 × 15 decon v 2 2 f × T / 16 × 15 8 , 4 , f 2 f × T / 4 × 60 decon v 1 2 f × T / 4 × 60 9 , 4 , f f × T × 241 con v out f × T × 241 3 , 1 , 1 1 × T × 241 reshape 3 1 × T × 241 - T × 241 MelCRN reshape 1 T × 40 - 1 × T × 40 con v 1 1 × T × 40 4 , 2 , f f × T / 2 × 20 con v 2 f × T / 2 × 20 4 , 2 , 2 f 2 f × T / 4 × 10 con v 3 2 f × T / 4 × 10 (3 , 4) , (1 , 2) , 4 f 4 f × T / 4 × 5 reshape 1 4 f × T / 4 × 5 - T / 4 × 20 f BiLSTM T / 4 × 20 f h T / 4 × h FC T / 4 × h 20 f T / 4 × 20 f reshape 2 T / 4 × 20 f - 8 f × T / 4 × 5 decon v 3 8 f × T / 4 × 5 (3 , 4) , (1 , 2) , 2 f 4 f × T / 4 × 10 decon v 2 4 f × T / 4 × 10 4 , 2 , f 2 f × T / 2 × 20 decon v 1 2 f × T / 2 × 20 4 , 2 , f f × T × 40 con v out f × T × 40 3 , 1 , 1 1 × T × 40 reshape 3 1 × T × 40 - T × 40 T able 2: The number of parameters and multiplies used for the KWS system and differ ent enhancement models. Model Name Parameters Multiplies cnn-trad-pool2 493.7K 95.87M BiLSTM 5661.0K 432.7M PowCRN32 724.0K 280.1M PowCRN16 182.3K 73.0M MelCRN32 881.3K 115.1M MelCRN16 221.5K 29.2M Beside the baseline cnn-trad-pool2 which uses the multi-conditional training technique, we apply three training strategys for all other enhancement front-end based models. Firstly , the enhancement model is pre-trained against the MSE loss as Equation (1). Then, the enhancement model is concatenated to the KWS model through the feature translation block. In these enhancement front-end based models, KWS model can be trained alone with the MFCC of noisy utterances, which we refer it as KWS+ { enhancement model } . KWS model also can be trained alone with the MFCC of enhanced spectrogram, which we refer it as retrain+ { enhancement model } . In fact, KWS model and the enhancement model can T able 3: The test accuracy , EER and AUR of each model under matched noise condition. Model T est accuracy(%) AUC (%) EER (%) cnn-trad-pool2 80.89 1.99 7.28 KWS+BiLSTM 87.64 1.30 6.66 retrain+BiLSTM 90.18 1.17 5.92 joint+BiLSTM 91.64 1.01 6.15 KWS+PowCRN32 86.42 1.52 6.67 retrain+PowCRN32 87.69 1.53 6.63 joint+PowCRN32 91.07 1.20 6.27 KWS+PowCRN16 86.20 1.61 6.73 retrain+PowCRN16 87.01 1.67 6.88 joint+PowCRN16 90.68 1.22 6.50 KWS+MelCRN32 87.59 1.59 6.97 retrain+MelCRN32 89.17 1.35 6.10 joint+MelCRN32 93.17 1.19 6.20 KWS+MelCRN16 86.87 1.64 7.00 retrain+MelCRN16 88.20 1.42 6.49 joint+MelCRN16 92.56 1.28 6.39 T able 4: The test accuracy of joint-trianing models under unmatched noise condition. Model Accuracy(%) Model Accuracy(%) cnn-trad-pool2 68.81 joint+BiLSTM 73.74 joint+PowCRN32 75.19 joint+PowCRN16 72.49 joint+MelCRN32 78.12 joint+MelCRN16 75.67 be trained together with the noisy spectrogram, which we refer it as joint+ { enhancement model } . 3.2. Results The experimental results are gi ven in T ab. 3 and Fig. 3. Model comparison: From T ab . 3 and Fig. 3 (a), we can see all of the comparison models outperform the baseline. The performance of the BiLSTM-based model is good, howev er its parameter number and computation is the hugest (seen in T ab . 2) which doesn’t serve the small-footprint purpose. The proposed CRNs have acceptable parameters and needs less computation, b ut have achiev ed comparable performance compared with BiLSTM-based model. The parameters and the required multiplies are further reduced in the narrow model (PowCRN16, MelCRN16), but it also obtained a comparable performance with the BiLSTM-based model. T raining strategy: From T ab. 3 and Fig. 3 (b), we can see all of the enhancement front-end based models outperform the multi-conditional trained baseline. Specifically , the retrained KWS model trained with enhanced spectrogram is better than the KWS model trained with noisy utterances, and the joint-trained KWS model is better than the retrained KWS model. It is because that the mismatch between the enhancement model and KWS model is descending in the order of model trained with clean utterances, retrained model and joint-trained model. Especially , for the small-footprint enhancement models (Po wCRNs and MelCRNs), the joint- training strategy significantly impro ves the performance. Figure 3: R OCs fr om the perspective of (a) dif fer ent enhancement models, (b) training strate gy , (c) feature domain. And (d) A UC reduction against phonetic symbol length. (a) Model (b) T raining Strategy (c) Feature Domain (d) A UC Reduction Mel vs power spectrogram: From T ab . 3 and Fig. 3 (c), we find the CRNs trained on the Mel-spectrogram have better performance and similar parameters compared with the models trained on the power spectrogram. Since the dimension of Mel-spectrograms is much less than the po wer spectrograms, the multiplies of the enhancement models can be significantly reduced. W e think the Mel-spectrogram is more suitable for the KWS system. Beacuse the input of KWS system is always silence, background noise or non-speech, false alarms on those must be minimized. W ith the limitation of low F AR ( < 2 . 0% ), we find MelCRN32 achieves the lowest FRR than the PowCRN32 and BiLSTM. This advantage is also retained by the narrow model. Sensibility on phonetic symbol length: Since the keyw ords hav e different phonetic symbols, we wonder whether enhancement models are sensitiv e to the number of phonetic symbols in the ke ywords. W e split the dataset into two sets, i.e., the keyw ords with 2 and more phonetic symbols. Fig. 3 (d) shows A UC reductions for keyw ords with different number of phonetic symbols, where the less reduction the better . From the figure, we can see that the Mel-spectrogram based method is less sensitive to the number of phonetic symbols in the keyw ords than the models on the power spectrogram. Noise generalization: T ab . 4 shows the results of joint- training models under the unmatched noise condition which contains 100 unseen noises. From the table, we can see the proposed full-size CRNs have better generalization to ne w noise conditions than the BiLSTM. And the CRNs on Mel spectrogram domain achiev es higher accuracy than that on power spectrogram domain. 4. CONCLUSIONS In this paper, we proposed a small-footprint speech enhancement technique for robust KWS, which integrates a front-end enhancement model and a back-end KWS model. The proposed CRNs achieve better performance under both matched and unmatched noise condition, and CRNs need less parameters and computation compared with the con ventional BiLSTM-based model. W e find Mel-spectrogram is better than power spectrogram because it can achiev e comparable performance with less computation and similar or smaller model size. Beside that the Mel-spectrogram based method is non-sensitiv e to the phonetic symbol length in the keyw ords. 5. References [1] R. T ang and J. Lin, “Deep residual learning for small-footprint keyw ord spotting, ” pp. 5484–5488, 2018. [2] P . W arden, “Speech commands: A dataset for limited-vocabulary speech recognition, ” arXiv preprint , 2018. [3] C. Shan, J. Zhang, Y . W ang, and L. Xie, “ Attention-based end-to-end models for small-footprint keyw ord spotting, ” Pr oc. Interspeech 2018 , pp. 2037–2041, 2018. [4] R. Prabhav alkar , R. Alvarez, C. Parada, P . Nakkiran, and T . N. Sainath, “ Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks, ” pp. 4704–4708, 2015. [5] T . Sainath and C. Parada, “Conv olutional neural networks for small-footprint ke yword spotting, ” in Pr oceedings of Interspeech , 2015. [6] M. Y u, X. Ji, Y . Gao, L. Chen, J. Chen, J. Zheng, D. Su, and D. Y u, “T ext-dependent speech enhancement for small-footprint robust keyword detection, ” Pr oc. Interspeech 2018 , pp. 2613– 2617, 2018. [7] D. W ang and J. Chen, “Supervised speech separation based on deep learning: An overvie w , ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 26, no. 10, pp. 1702– 1726, 2018. [8] J. Du, Q. W ang, T . Gao, Y . Xu, L.-R. Dai, and C.-H. Lee, “Robust speech recognition with speech enhanced deep neural networks, ” in F ifteenth Annual Conference of the International Speech Communication Association , 2014. [9] M. L. Seltzer, D. Y u, and Y . W ang, “ An in vestigation of deep neural networks for noise robust speech recognition, ” in 2013 IEEE international conference on acoustics, speech and signal pr ocessing . IEEE, 2013, pp. 7398–7402. [10] A. Narayanan and D. W ang, “Ideal ratio mask estimation using deep neural networks for robust speech recognition, ” in 2013 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing . IEEE, 2013, pp. 7092–7096. [11] Y . W ang, A. Narayanan, and D. W ang, “On training targets for supervised speech separation, ” IEEE/ACM Tr ansactions on Audio, Speech, and Language Pr ocessing , vol. 22, no. 12, pp. 1849–1858, 2014. [12] Z.-Q. W ang and D. W ang, “ A joint training frame work for robust automatic speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 24, no. 4, pp. 796– 806, 2016. [13] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal covariate shift, ” arXiv pr eprint arXiv:1502.03167 , 2015. [14] V . Nair and G. E. Hinton, “Rectified linear units impro ve restricted boltzmann machines, ” in ICML , 2010, pp. 807–814. [15] K. T an and D. W ang, “ A conv olutional recurrent neural network for real-time speech enhancement, ” in Proceedings of Interspeech , 2018, pp. 3229–3233. [16] T . N. Sainath, B. Kingsbury , A.-r . Mohamed, and B. Ramabhadran, “Learning filter banks within a deep neural network framework, ” in 2013 IEEE W orkshop on Automatic Speech Recognition and Understanding . IEEE, 2013, pp. 297–302. [17] R. T ang and J. Lin, “Honk: A pytorch reimplementation of con volutional neural networks for keyword spotting, ” arXiv pr eprint arXiv:1710.06554 , 2017. [18] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment