Low-light Image Enhancement Algorithm Based on Retinex and Generative Adversarial Network
Low-light image enhancement is generally regarded as a challenging task in image processing, especially for the complex visual tasks at night or weakly illuminated. In order to reduce the blurs or noises on the low-light images, a large number of pap…
Authors: Yangming Shi, Xiaopo Wu, Ming Zhu
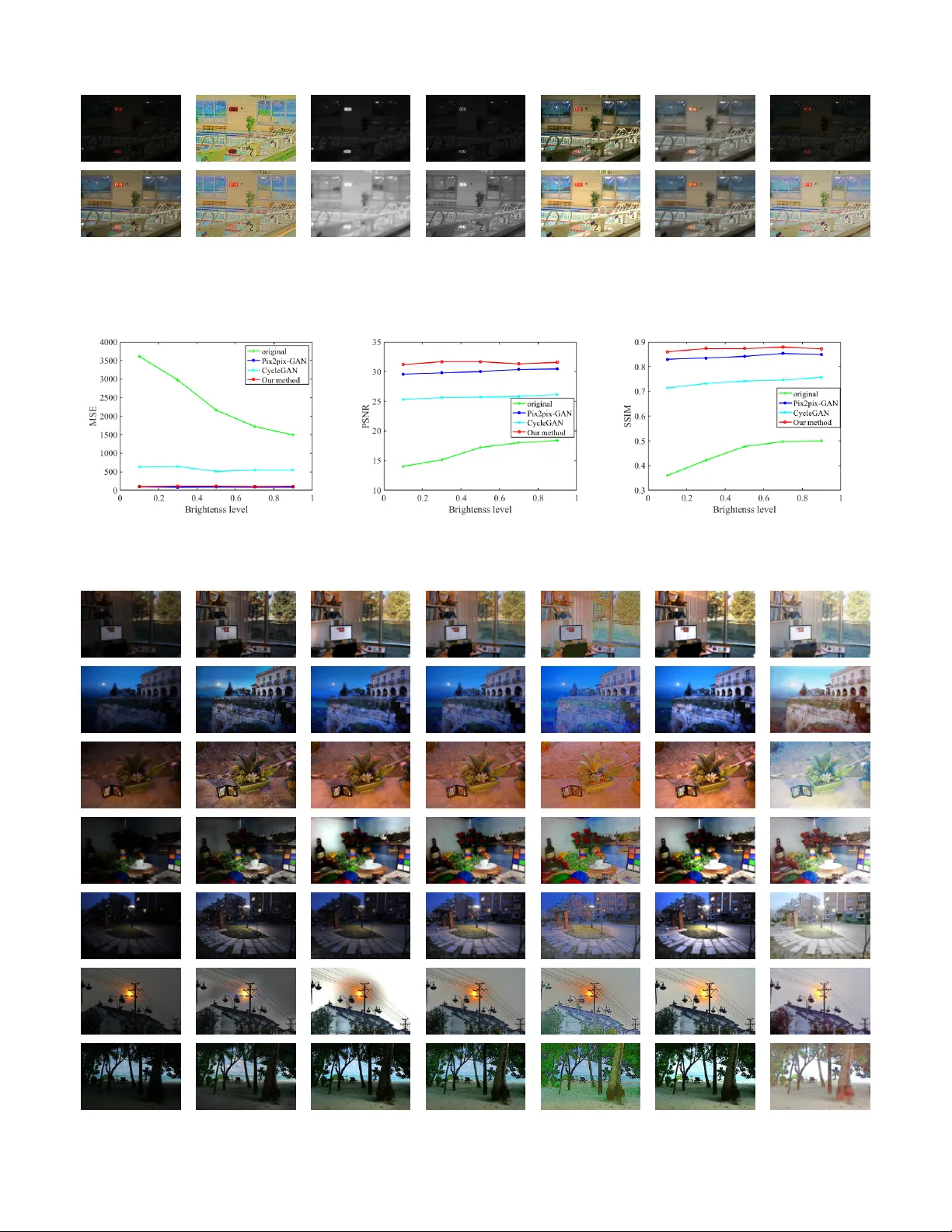
1 Lo w-light Image Enhancement Algorithm Based on Retine x and Generati ve Adv ersarial Network Shi Y angming, Student Member , IEEE, W u Xiaopo, Member , IEEE, and Zhu Ming, Member , IEEE Abstract —Low-light image enhancement is generally regarded as a challenging task in image processing, especially f or the complex visual tasks at night or weakly illuminated. In order to reduce the blurs or noises on the low-light images, a large number of papers hav e contributed to applying differ ent technologies. Regretfully , most of them had serv ed little purposes in coping with the extremely poor illumination parts of images or test in practice. In this work, the authors propose a novel approach for processing low-light images based on the Retinex theory and generative adv ersarial network (GAN), which is composed of the decomposition part f or splitting the image into illumination image and r eflected image, and the enhancement part for generating high-quality image. Such a discriminative network is expected to make the generated image clearer . Couples of experiments have been implemented under the circumstance of different lighting strength on the basis of Con verted See-In-the-Dark (CSID) datasets, and the satisfactory results hav e been achieved with exceeding expectation that much encourages the authors. In a word, the pr oposed GAN-based network and employed Retinex theory in this work have pro ven to be effective in dealing with the low-light image enhancement problems, which will benefit the image processing with no doubt. Index T erms —GAN, lo w-light enhancement, image processing, Retinex I . I N T RO D U C T I O N For the past sev eral years, deep con volution neural net- works (DCNNs) have found their extensi ve applications in image processing such as image classification [1]–[5], object detection [6]–[12], image segmentation [6], [13]–[16] and object tracking [17]–[22], and so forth. And thanks to the dev elopment of DCNNs, it has sparked remarkable activity in specific image analysis. While, in spite of tremendous progress brought by DCNNs, one unified theory and general solution of low light image processing had eluded the most researchers, especially for the cases of poor illumination condition and camera shaking in the real world. There is still a substantial number of scientific papers contributing to the examinations on low-light enhancement task [23]–[31] in the latest years. Interesting though those works were, these approaches can achiev e good results under certain conditions but still ha ve some limitations. The greatest challenge is that there was no suitable dataset for training and testing. Those researchers usually experimented on artificial low-light datasets needing Manuscript receiv ed June ***, 2019; This work was supported by the Anhui Provincial Natural Science Foundation under Grant 1908085QF254. Shi Y angming and Zhu ming are with the Automation Department of Univ ersity of Science and T echnology of China, Hefei, Anhui, China, 230026. E-mail: ymshi@mail.ustc.edu.cn, mzhu@ustc.edu.cn W u Xiaopo is with the Department of Electronic Engineering and Informa- tion Science of Univ ersity of Science and T echnology of China, Hefei, Anhui, China, 230026. E-mail: wuxiaopo@ustc.edu.cn darken-process and denoise-process on the original images, which resulted in an embarrassment that images from real en vironment cant be processed effecti vely . When dealing with the image of relativ ely poor lightness and be with ambient noise, these approaches can’t get satisfactory results. Fig. 1 shows part of the results by some of those methods. According to the images generated by the LIME [25] method, one could find that the lower brightness images can’t be restored well in detail, such as the top right-hand corner distant dark trees. The results by the LightenNet [27] method show that the method is not stable enough, the generated images are overe xposed and blurred in high illumination le vel and full of noise for the case of low-light illumination. (a) Input (b) LIME (c) Input (d) LightenNet Fig. 1. Experimental results by LIME and LightenNet. The input images of first line are with brightness lev els of 0.1, and the second line are with brightness lev els of 1. T o avoid the aforementioned dilemma, the authors propose a novel method based on cross-domain algorithms. It is assumed that images from low-light en vironment belong to dark domain in a same distribution while long exposure or normal images belong to another domain which satisfy another distribution. W e can use cross-domain approach to solve this low-light enhancement problem. It is the generativ e adversary networks (GANs) [32] that make the cross-domain image-to- image be so attracti ve and considerable numbers of approaches based on GANs are generally employed to deal with domain- transferring issues. Y ears of research in computer vision, image processing, computational photograph y , and graphics hav e produced powerful translation systems. These approaches can be divided into two categories, one is the supervised algorithm [33] and the other is the unsupervised one [34]– [36]. In the former method, paired inputs are needed to obtain higher performance. While, in the latter method, paired inputs are not necessary and one could readily collect plenty of the unsupervised datasets. By comparison, we prefer to adopt the supervised algorithm not only for the brought higher performance, but also due to the fact that the unsupervised 2 algorithm f ail to get precise results in detail when dealing with complex tasks. The supervised algorithm we suggest is actually utilizing a hybrid architecture based on generativ e adversarial network and Retinex theory [37]. In order to employ effecti vely the Retinex theory in generativ e adversary networks, the authors had tried three different strategies for applying the Retinex to CNNs and dev eloping the regularization loss to avoid the local optimal solution. Fortunately , the experimental results indeed help to v erify the a vailable algorithm. Meanwhile, to maximize the performance of the model, the LO w- L ight (LOL) dataset produced by W ei et al. [30] and the C onv erted S ee- I n-the- D ark (CSID) dataset (originating from the raw image of See- In-the-Dark) were introduced to implement the e xperiment. The satisfactory results demonstrate that Retinex-GAN could bring about considerable improvement as expected. In this papers remaining, Section II describes the related work of GAN and image enhancement to this research in retrospect. And in Section III, the proposed network and the dataset production approach are presented detailedly , followed by the experimental results and discussions in Section IV . I I . B A C K G RO U N D A N D P R E V I O U S W O R K A. Low-light Enhancement and Image Denoising The past decades hav e witnessed the rapid de velopment of low-light image enhancement from unpopular domain to hot topics, owing to the booming techniques of deep learning. There exist lots of approaches proposed to im- prov e the quality of lo w-light images. T o sum up, those approaches could be generally divided into three categories, namely the pre-processing, the post-processing, and using both of them. The pre-processing methods are mainly to use algorithms or physical setup, such as flash photogra- phy techniques. Other well-known methods include histogram equalization (HE) [37], Contrast-Limiting Adaptiv e Histogram Equalization (CLAHE) [38], Unsharp Masking (UM) [39], Multiscale Retinex (MSR) [26], Msr-net: Low-light image enhancement using deep conv olutional network (Msr -net) [31], a weighted variational model for simultaneous reflectance and illumination estimation (A WVM) [24], lo w-light image enhancement (LIME) [25], the low-light net (LLNET) [28], LightenNet [27] and etc. . HE is a popular algorithm for image enhancement which adjusts the intensity of image for better quality . CLAHE is a method de veloped based on adaptiv e histogram equaliza- tion (AHE) which transforms the intensity of the pixel into the display range proportional to the pixel intensitys rank in the local intensity histogram, and will reduce the ef fect of edge shadowing. UM is a method that used for sharpening image quality by blurring and then adding some differences to the original image. BM3D is an algorithm for noise removal by utilizing W iener filter as a collaborative form used to filter dimensional patches block by clustering similar blocks from 2D to 3D array of data and afterward denoising the gathered fixes mutually . Then, the denoised patches are connected back to the first pictures by a voting instrument which expels noise from the considered area. Besides, many deep-learning based algorithms are proposed to deal with those issues and found themselves with ov er- whelming advantages. Lore et al. proposed LLNet [28] to learn underlying signal features in low-light images by using deep AutoEncoders. Fu et al. [24] proposed a weighted mini- mization algorithm for estimating reflectance and illumination from an image. Guo et al. [25] dev eloped a structure-aware smoothing model to improv e the illumination consistency of images. Lore et al. [28] proposed a deep AutoEncoder approach to learn features from lo w-light images and then enhance those images. Li et al. [27] proposed the LightenNet which learns a mapping between weakly illuminated image and the corresponding illumination map to obtain the enhanced image. Meanwhile, W ei et al. [30] proposed a deep Retinex decomposition method which can learn to decompose the observed image into reflectance and illumination in a data- driv en way without decomposing further the image of ground truth. The authors tried to improve the algorithm to make the process of image-brightening and de-noising more effecti vely . B. Gener ative Adversarial Networks (GAN) Recently , generative adversarial nets (GAN) [32] hav e been attracting most of the attentions in image-to-image translation. The original GAN includes two networks which are built to play a one-sum games. The generative network is trained for generating realistic synthetic samples from a noise distribu- tion to cheat the discriminativ e network. The discriminativ e network aims to distinguish true and generated fake samples. In addition to random sample from a noise distrib ution, various form data can also be used as input to the generator . Image-to-image translation algorithms transfer an input image from one domain to corresponding image in another domain. Isola et al. [33] first proposed supervised GAN which used U-net as the generativ e network and make good results in domain transfer . Zhu et al. [36] provided an unsupervised algorithm which mapped images from one domain to another domain and then mapped to the original domain, and finally used cycle-consistent loss to reduce the difference. Simultane- ously , Y i et al. [35], Liu et al. [34] and Kim et al. [40] had put emphasis on the domain transfer with unsupervised manners. What the authors trying to examine was inspired by those image-to-image translation approaches. W e assume that im- ages from dark environments with noise which were meeting a distribution and coming from one specific domain, and the high-quality images were from another domain. The recovery step is an image-to-image translation process. T o the best of our kno wledge, applying generativ e adversary networks to the low-light image enhancement and image denoising still remains an opening area, the authors are the first to propose such a novel technique to cope with the low light image processing and to obtain the results with exceeding expectations. I I I . P RO P O S E D A P P RO AC H A. Network Structur e Our approach benefits from the Retinex theory by E.H.Land [37]. It is well kno wn in Retinex theory 3 Fig. 2. Retinex-GAN: x is lo w-light image and y is the corresponding ground truth image. The generative network is composed of two parallel Unets to split x and y into reflected image when data training commences, which is also termed as the decomposition process. The following enhancement process in the generativ e network is responsible for generating the reflected images for x by the yellow Unet and then a new image is formed by combining the reflected part and illumination part. At last, the discriminative network, actually a normal con volutional neural network, is to distinguish x and y . When testing, only the area encircled by red line rectangular works. Fig. 3. Illustration of Retinex theory . The image observed can be decomposed into the brightness matrix produced by the light source and the reflectivity matrix of the object. that the color of an object is determined by its ability to reflect long-wa ve ( red ), medium-wave ( green ) and short- wa ve ( blue ) light rather than the absolute value of the reflected light intensity . The color of an object is not affected by the illumination heterogeneity and has consistency , that is, Retinex theory is based on the color consistency (color constancy). As shown in Fig. 3, the image S is obtained by reflecting the incident light L from the surface of the object. The reflectivity R is determined by the object itself. Its assumed in Retinex theory that the original image S consist of the product of the illumination image I and the reflected image R , which can be expressed as the following form: S ( i, j ) = R ( i, j ) I ( i, j ) (1) where ( i, j ) represent the pixel location. W e apply the Retinex theory to our neural network. As shown in Fig. 2, the network is composed of one generativ e network and one discriminativ e network. The generativ e net- work ( G ) which looks like a letter W includes decomposition part and enhancement part. The decomposition part aims to split the original image into illumination image I x and re- flected image R x while the enhancement part tries to enhance the brightness of the image. Finally , the reflected image R x and new illumination image I x 0 do dot product operation and output a ne w normal image. Meanwhile, the discriminative network ( D ) make the generated image look more realistic which have ability on distinguishing noised image from real high-quality images. Let x ∈ X be low-light image, y ∈ Y be high-quality image. The whole network aims to recover images in domain Y from corresponding images in domain X . W e simply call it Retinex-GAN for a con venience. B. Re gularization Loss W e assume that RGB channels of images are exposed to the same level of light, thus we use the Unet to split the image S into reflected image R with three channels and illumination image I with one channel. It has proved that the assumption fails to maximize the network performance while illumination image I and reflected image R can’t reconstruct the original image S ef fectiv ely [37]. Then we try the second strategy . W e assume that the illumination image is also three channels. On the basis of this assumption, there is a serious problem that the network quickly falls into a local optimal solution. Let’ s giv e a brief analysis of this problem from a mathematical point of view . Given two matrix S 1 , S 2 , if we want optimize min | R 1 − R 2 | to satisfy the following equation for all points i, j : S 1 ( i, j ) = R 1 ( i, j ) I 1 ( i, j ) S 2 ( i, j ) = R 2 ( i, j ) I 2 ( i, j ) (2) Obviously , the best two solutions are as below: R 1 ( i, j ) = 1 R 2 ( i, j ) = 1 I 1 ( i, j ) = S 1 ( i, j ) I 2 ( i, j ) = S 2 ( i, j ) (3) 4 and R 1 ( i, j ) = − 1 R 2 ( i, j ) = − 1 I 1 ( i, j ) = − S 1 ( i, j ) I 2 ( i, j ) = − S 2 ( i, j ) (4) According to the abov e inference, after many iterations, the value of reflected image will become all 1 or -1 and the illumination image will be same as original or the reversed image. This means that the decomposition part does useless work. T o solve this problem, we propose a regularization loss L reg which can prev ent the RGB v alues of generated illumination image from approaching 1 or -1 to av oid that the network falls into a local optimal solution. L reg = 1 mn m − 1 X i =0 n − 1 X j =0 1 C − f ( R ( i, j )) C ≥ 1 (5) If R ( i, j ) approaching to C ≈ 1 or C ≈ − 1 , L reg becomes large which makes R ( i, j ) far away from 1 or-1. The regular - ization loss is quite useful during training and testing. C. Multitask Loss Formally , during training, we define a multi-task loss as L = λ rec L rec + λ dec L dec + λ com L com + λ cGAN L cGAN (6) where λ rec , λ dec , λ com and λ cGAN (short for condition GAN) are respectively the loss weightings for each loss term. W e take part of the loss of Pix2pix-GAN which includes the L cGAN loss and the L 1 loss while the L 1 loss is replaced by smooth L 1 loss. The original cGAN loss can be described as: L cGAN ( G, D ) = E x,y [log D ( x, y )] + E x [log(1 − D ( x, G ( x )))] (7) The smooth L 1 loss is defined as: L L 1 ( x, y ) = smooth L 1 ( x, y ) (8) in which smooth L 1 ( x ) = 0 . 5 x 2 if x < 1 x − 0 . 5 other wise, (9) The reconstruction loss L rec ensures that the image divide into illumination part and reflected part then can be restored which is defined as: L rec = L rec x + L rec y + L reg (10) where L rec x = L L 1 ( x, R x · I x ) (11) L rec y = L L 1 ( y , R y · I y ) (12) The decomposition loss is defined as: L dec = L L 1 ( I x , I y ) (13) The decomposition loss makes the image in different bright- ness is decomposed to the same illumination images. And finally the enhancement loss optimize the L 1 distance of composite image and target image which can be described as: L enh = L L 1 ( y , x ) = L L 1 ( y , R x · I x 0 ) (14) where R 0 is the enhanced reflected image. In order to obtain the image details, we use the better SSIM- MS loss L ssim − ms which are proposed by Zhao et al. [41]. The SSIM-MS loss is a multi-scale version of SSIM loss which comes from the S tructural SIM ilarity index (SSIM). Means and standard deviations are computed with a Gaussian filter with standard deviation σ G , G σ G . SSIM for pixel p is defined as: S S I M ( i, j ) = (2 µ i µ j + c 1 )(2 σ ij + c 2 ) ( µ 2 i + µ 2 j + c 1 )( σ 2 i + σ 2 j + c 2 ) (15) where µ i , µ j is the a verage of i, j , σ 2 i , σ 2 j is the v ariance of i, j , σ ij is the conv ariance of i and j , c 1 = ( k 1 L ) 2 , c 2 = k 2 L 2 are two variables to stabilize the division with weak denominator, L is the dynamic range of the pixel-v alues, k 1 = 0 . 01 and k 2 = 0 . 03 by default. The loss function for SSIM can be then written as: L ssim ( p ) = 1 mn m − 1 X i =0 n − 1 X j =0 (1 − S S I M ( i, j )) = l ( p ) cs ( p ) (16) while SSIM Loss are influenced by the parameters σ G , Zhao et al. use the M S S S I M rather than fine-tuning the σ G , Giv en a dyadic pyramid of M levels, M S S S I M is defined as: M S S S I M ( p ) = l α M ( p ) M Y j =1 cs β j j ( p ) (17) The multiscale SSIM loss for patch p is defined as: L ssim ms = 1 − M S S S I M ( ˜ p ) (18) W e combine the L enh with L ssim ms and take the strategies in [41]. L com = α L enh + (1 − α ) L ssim ms (19) where α is set to 0.84. I V . E X P E R I M E N TA L R E S U LT S A N D D I S C U S S I O N S In order to verify the framework mentioned above, large numbers of CSID dataset [42] and the LOL dataset [30] were chosen for the experiment. All the models are implemented with the T ensorflow framework on 1080T i GPUs. Training details and structure models from Pix2pix-GAN will help to build our Retinex-GAN. The resolution of the images for all the experiments is set to 384 x 256. The generativ e network is composed of two similar Unets [43] from generated network of Pix2pix-GAN [33] and all Unets adopt skip-connection strate- gies. The discriminator network is a 46 × 46 PatchGAN that is used to distinguish a 46 × 46 image patch whether it is real or fake. W e use Adam optimizer with the proposed optimization settings in [44] with [ β 1 , β 2 , ] = [0 . 5 , 0 . 999 , 10 − 8 ] . The batch size is set to 16. The initial learning rate is 0.0002 for all the trained network, which would be decreased manually when the training loss con verges. For the loss weighting in our final loss function, we empirically find that the combination [ λ rec , λ dec , λ com , λ cGAN ] = [1 , 1 , 10 , 1] results in a stable training. 5 A. Con verted See In the Dark Dataset The original SID [42] dataset is composed of 5094 ra w short-exposure images, each with a corresponding long- exposure reference images and that multiple short-exposure images can correspond to the same long-exposure images. These images will be trained as the dataset for our exper- iments. Actually , we con vert both short-e xposure and long- exposure images from raw format to PNG format. The long- exposure raw images can generate high-quality PNG images by default con verting free of further processing. But short- exposure raw images will show all black after conv erting for the lack of adequate. So we carry out some manual processing by adjusting parameter in the rawp y python package. The brightness le vels are di vided into 5 le vels from 0.1 to 0.9 with the interval of 0.2 and the brightness value equal to 1.0 is referred as the top le vel. And the lev el 1 usually looks like the same as the long-exposure ground truth images with noise. In order to acquire the qualified input, we simply resize all con verted images to 384 × 256 resolution for training and testing. On the premise of the above operation, we select 1550 pairs of images for training and 217 pairs of images for testing by removing the images with a lot of noise. Some examples of the dataset are shown in Fig. 4. Fig. 4. Examples in the CSID datasets: from left to right, the brightness lev els are: 1(0.1), 3(0.5), 5(0.9), and the ground truth. Qualitative Analysis. W e compare our Retinex-GAN with fiv e low-light enhancement methods including A WVM [24], and CLAHE [38], and the state-of-the-art LIME [25], and LightenNet [27] on five different brightness lev el. As shown in Fig. 5, our method works best visually and the stable results are most similar to ground truth. The results sho w that the LightenNet method has no effect on our dataset, and even reduces the brightness of the input image. Although other methods, such as the LIME, A WVM and CLAHE, can enhance images to a certain extent owing to the fact that their experiment datasets are synthesized by reducing the v alue of V channel in clear illuminated images, their framework doesn’t take into account the effects of noise. When testing on the real image datasets with noise by image sensors, the resulting image contains a lot of noise. Another point worth noting is that other methods will get different results when dealing with different lighting images. For instance, the CLAHE method try to get dim results when processing extremely poor light images. Quantitative Analysis. Due to the ground truth of e very image is known, we can ev aluate the quality of the generated image numerically . W e ev aluate our method with three indications. The M ean S quare E rror (MSE) of generated image A and ground truth image B is defined by equation: M S E = 1 mn m − 1 X i =0 n − 1 X j =0 [ I A ( i, j ) − I B ( i, j )] 2 (20) where I A ( i, j ) and I B ( i, j ) are separately the pixel values of A and B in position (i,j). Then, the P eak S ignal to N oise R atio (PSNR) is defined by equation: P S N R = 10 lg max( I ) 2 M S E (21) The S tructure SIM ilarity index (SSIM) is a method for pre- dicting quality of digital images. SSIM is used for measuring the similarity between two images which is defined by (15). Because other low-light methods don’t train on the CSID dataset or rely on the learning-based techniques, we only compare our method with GAN-based methods including Pix2pix-GAN [33] and CycleGAN [36] on 5 situations which the brightness lev els are from 0.1 to 0.9 with the interval of 0.2. In Fig. 7, thanks to the supervised learning, the result of our method is v ery close to ground truth as the supervised Pix2pix- GAN method while the unsupervised CycleGAN method try to approach the ground truth. The MSE value of our method is slightly higher than the Pix2pix-GAN method, b ut our method is much better than the Pix2pix-GAN and CycleGAN methods in terms of the value of the signal-to-noise ratio (PSNR) and the value of the image similarity (SSIM). Simultaneously , the experimental results also prove to some extent the effecti veness of GAN in image enhancement. B. LOL Dataset In this section, we mainly ev aluate the performance of our method on the LOw-Light (LOL) dataset. The LoL paired dataset of fered by W ei et al. [30] contains 500 low and normal- light image pairs. Similar to the CSID dataset, the images of LOL are synthesized on the real scenes. The difference of two datasets is that the ground truth images of LOL are normal- light images while images in CSID are all captured on weak illumination. Comparison of decomposition results. In Fig. 6, we compare the decomposition results by our method, the LIME method and the Retinex-Net method. It is worth noting that since the illumination image by our method is three-channel, the R and I results of decompression are the opposite of LIME and Retine x-Net. In f act, based on the analysis of Retinex theory , the results generated by our method are more in line with expectations because the amount of light recei ved by each channel should be different. Aside from the influence of these factors, we can also find that the generated illumination images by us are more clearer than the reflected images by LIME and Retine x-Net. The estimated R images by LIME are different between low light and normal illumination while Retinex-Net try to reduce the differences of them but get a lot of noise when dealing with low-light image. By comparing 6 (a) Input (b) CLAHE [38] (c) LightenNet [27] (d) A WVM [24] (e) LIME [25] (f) Ours (g) Ground truth Fig. 5. V isual effects comparison of e xperimental results on the CSID dataset. From top to bottom, the brightness lev els are 0.1, 0.5 and 0.9. with other methods, the Retinex-GAN seems to achiev e better performance on decomposition when processing the same image. Comparison in the Real Scene. According to above analysis, we hold that the illumination image enhanced by Retinex- GAN can be considered as a good enhancement result instead of the final synthesized result image. Therefore, we can also use the enhanced illumination image as the result of generation in practice. Then we ev aluate the algorithm on the real scene while the ev aluation dataset comes from public dataset. W e compare Retinex-GAN with LIME, LightenNet, CLAHE, Retinex-Net and A WVM. The model of Retinex- GAN is trained on LOL dataset. In Fig. 8, it displays some of the experimental results and it is evident that the pictures tested were extremely dark. From the perspectiv e of image brightness, the image generated by our method is much brighter than those ones by other methods. There are two main reasons. One is the data distribution. The brightness of low- light images in LOL dataset are generally lo w , and the ground truth images are very bright. This leads to the fact that the brightness of the generated image will increase the same level in the brightness level of the tested image when processing actual image. Another reason is that, as we mentioned earlier , we take the brightness of the intermediate enhancement as the final result while the enhanced illumination image is a little brighter than the final composite image inherently . Although the increase in brightness leads to the weakening of color , the results we produced are visually acceptable, and more comfortable than those generated by other methods in some ways. C. Ablation Study on CSID The scientific contribution of our work could come in three aspects. Firstly , so far we’ re the first to combine the Retinex theory with GAN for the research of low-light image enhance- ment as we know . Secondly , we propose to add a re gularization loss function for the decomposition loss adapted to Retinex theory . Moreover , some of the latest tricks were employed to make the network stable. In order to sho w the influence of each of these contributions, we conduct the following experiments. First, we build three basic networks which implement three different strategies on chapter III-B without GAN, SSIM-loss and smooth-L1 loss. Then we add new components one by one and observe the changes in ev aluation values on the basis of the third strategy . W e did ablation experiments on CSID with a brightness lev el of 0.5. In T ab . I, S1, S2 and S3 represents the first, second and third strate gy respecti vely . As can be seen from the table, since the decomposition solution space of S2 contains the decomposition solution space of S1, the values of PSNR and SSIM have increased while the v alues of MSE have also declined by 6.2. Then, in Fig. 9, the more meaningful reflected and illumination images generated by S3 fully proves that the network with regularization loss function are more consistent with Retinex theory than S1 and S2. Simultaneously , adding GAN loss, SSIM loss and using Smooth-L1 loss instead of normal L1 loss also improves network performance. 7 (a) Input (b) R by Retinex-Net (c) I by Retinex-Net (d) R by LIME (e) I by LIME (f) R by ours (g) I by ours Fig. 6. Decomposition results by LIME, Retinex-Net, and our method on the LOL dataset. The first column is low-light image, the second column is normal-light image. (a) MSE (b) PSNR (c) SSIM Fig. 7. Comparison of numerical indicators on the CSID dataset. (a) Input (b) CLAHE (c) LightenNet (d) A WVM (e) RetinexNet (f) LIME (g) Ours Fig. 8. V isual effects comparison on real scene dataset. 8 T ABLE I PSNR MSE SSIM S1 30.54 111.27 0.853 S2 30.76 105.07 0.859 S3 30.89 103.03 0.864 S3 + Smooth-L1 + SSIM 30.87 103.41 0.872 S3 + Smooth-L1 + SSIM + GAN 31.31 99.12 0.879 (a) (b) S1 S2 S3 (c) (d) (e) (f) Fig. 9. Decomposition results by S1, S2 and S3 in the CSID datasets: (a) Input images. (b) Ground truth. (c) Reflected image of (a). (d) Illumination image of (a). (e) Reflected image of (b) (f) Illumination image of (b). From top to bottom: results by S1, S2 and S3. D. Discussion Strong though the proposed hybrid Retinex-GAN is, there remains still much w ork to be done to dev elop our ideas. Firstly , maybe we will be likely faced with the shortage of paired inputs including low and high images which are not so easy to acquire in the real environment. A small scale of datasets is unable to maximize the performance of such a deep network. As such, combining the Retinex theory with unsupervised learning algorithm will be considered in future work. Secondly , the established complex GANs with Retinex theory in this work operated at the speed of 91 frames per second when dealing with image of 384 × 256 resolution on GTX1080TI but only got 11 FPS at the resolution of 1280 × 720 , so that the processing efficienc y will not suffice to cope with the real-time video processing in reality . So, the optimization of the networks will be worth studying in the next step. Furthermore, even the most advanced algorithm will become useless when dealing with the extremely weak light images and the ambient noise is too high enough. Hence, more preparation in the image pre-processing stage should be guaranteed to prevent the inv alid dataset. Here the authors present some of the failed examples in Fig.10. Since the input image (a) contaminated by much noise, the decomposition images (b) and (c) by our techniques were consequently full of noise. Although the model is possible to restore images (h) similar to the ground truth (e), theres still much missing details such as words on the book cover . In brief, the authors had a great confidence that such a no vel w ork will be of considerable value in image processing application. (a) (b) (c) (d) (e) (f) (g) (h) Fig. 10. F ailed examples in the CSID datasets: (a) Input images with a lot of noise. (b) Reflected image of (a). (c) Illumination image of (a). (d) Enhanced illumination image of (a). (e) Ground truth. (f) Reflected image of (e). (g) Illumination image of (e). (h) Enhanced image of (a). V . C O N C L U S I O N By combining generativ e adversarial network with Retinex theory , low-light image enhancement issue was settled down effecti vely . T o improv e the quality of output images, the authors had tried to introduce Structural Similarity loss to av oid the side effect of blur and to provide a global optimiza- tion possibility . The con vincing tests and satisfactory results hav e encouraged the authors to carry on the further study to in vestigate the application of Retinex-GAN to the scenario of higher resolution video streams and images. W e believe in that such a hybrid architecture of GAN and Retinex Theory will undoubtedly benefit the image processing. A C K N O W L E D G M E N T The authors will be grateful to the referees and the Ed- itor for their valuable time and contributions. This work is supported partly by the Anhui Provincial Natural Science Foundation under Grant 1908085QF254 and the Fundamental Research Funds for the Central Universities under Grant WK2100060023. Furthermore, we wish to acknowledge the faculty of Ke y Laboratory of Network Communication System and Control who made this research possible. W e mostly appreciated their helpful suggestions. R E F E R E N C E S [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pp. 770–778, 2016. [2] G. Huang, Z. Liu, L. van der Maaten, and K. Q. W einber ger , “Densely connected conv olutional networks, ” in The IEEE Conference on Com- puter V ision and P attern Recognition (CVPR) , July 2017. [3] A. Krizhe vsky , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural infor- mation pr ocessing systems , pp. 1097–1105, 2012. 9 [4] K. Simonyan and A. Zisserman, “V ery deep convolutional networks for large-scale image recognition, ” arXiv pr eprint arXiv:1409.1556 , 2014. [5] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with conv olutions, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pp. 1–9, 2015. [6] K. He, G. Gkioxari, P . Doll ´ ar , and R. Girshick, “Mask r-cnn, ” in Pr oceedings of the IEEE international conference on computer vision , pp. 2961–2969, 2017. [7] T .-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Doll ´ ar , “Focal loss for dense object detection, ” in Proceedings of the IEEE international confer ence on computer vision , pp. 2980–2988, 2017. [8] W . Liu, D. Anguelov , D. Erhan, C. Szegedy , S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector, ” in Eur opean confer ence on computer vision , pp. 21–37. Springer , 2016. [9] J. Redmon and A. Farhadi, “Y olo v3: An incremental improvement, ” arXiv pr eprint arXiv:1804.02767 , 2018. [10] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: T ow ards real-time object detection with re gion proposal networks, ” in Advances in neural information pr ocessing systems , pp. 91–99, 2015. [11] Q. Zhao, T . Sheng, Y . W ang, Z. T ang, Y . Chen, L. Cai, and H. Ling, “M2det: A single-shot object detector based on multi-le vel feature pyramid network, ” arXiv pr eprint arXiv:1811.04533 , 2018. [12] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sade ghian, I. Reid, and S. Sav arese, “Generalized intersection over union: A metric and a loss for bounding box regression, ” arXiv pr eprint arXiv:1902.09630 , 2019. [13] V . Iglo vikov , S. Seferbekov , A. Buslaev , and A. Shvets, “T ernausnetv2: Fully conv olutional network for instance segmentation, ” in The IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) W ork- shops , June 2018. [14] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy , and A. L. Y uille, “Deeplab: Semantic image segmentation with deep conv olutional nets, atrous conv olution, and fully connected crfs, ” IEEE transactions on pattern analysis and machine intelligence , vol. 40, no. 4, pp. 834–848, 2017. [15] H. Zhao, J. Shi, X. Qi, X. W ang, and J. Jia, “Pyramid scene parsing network, ” in Proceedings of the IEEE conference on computer vision and pattern r ecognition , pp. 2881–2890, 2017. [16] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. T orralba, “Scene parsing through ade20k dataset, ” in Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2017. [17] L. Bertinetto, J. V almadre, J. F . Henriques, A. V edaldi, and P . H. T orr, “Fully-con volutional siamese networks for object tracking, ” in Eur opean confer ence on computer vision , pp. 850–865. Springer , 2016. [18] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy , and A. L. Y uille, “Deeplab: Semantic image segmentation with deep conv olutional nets, atrous conv olution, and fully connected crfs, ” IEEE transactions on pattern analysis and machine intelligence , vol. 40, no. 4, pp. 834–848, 2018. [19] A. He, C. Luo, X. T ian, and W . Zeng, “ A twofold siamese network for real-time object tracking, ” in Proceedings of the IEEE Conference on Computer V ision and P attern Recognition , pp. 4834–4843, 2018. [20] M. Li, J. Liu, W . Y ang, X. Sun, and Z. Guo, “Structure-revealing lo w- light image enhancement via rob ust retinex model, ” IEEE T ransactions on Image Pr ocessing , vol. 27, no. 6, pp. 2828–2841, 2018. [21] W . Luo, P . Sun, F . Zhong, W . Liu, and Y . W ang, “End-to-end activ e object tracking via reinforcement learning, ” arXiv pr eprint arXiv:1705.10561 , 2017. [22] E. Ristani and C. T omasi, “Features for multi-target multi-camera tracking and re-identification, ” in Proceedings of the IEEE Conference on Computer V ision and P attern Recognition , pp. 6036–6046, 2018. [23] X. Fu, D. Zeng, Y . Huang, Y . Liao, X. Ding, and J. Paisley , “ A fusion-based enhancing method for weakly illuminated images, ” Signal Pr ocessing , vol. 129, pp. 82–96, 2016. [24] X. Fu, D. Zeng, Y . Huang, X.-P . Zhang, and X. Ding, “ A weighted vari- ational model for simultaneous reflectance and illumination estimation, ” in Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pp. 2782–2790, 2016. [25] X. Guo, Y . Li, and H. Ling, “Lime: Low-light image enhancement via illumination map estimation. ” IEEE Tr ans. Image Processing , vol. 26, no. 2, pp. 982–993, 2017. [26] D. J. Jobson, Z.-u. Rahman, and G. A. W oodell, “ A multiscale retinex for bridging the gap between color images and the human observation of scenes, ” IEEE T ransactions on Image pr ocessing , vol. 6, no. 7, pp. 965–976, 1997. [27] C. Li, J. Guo, F . Porikli, and Y . Pang, “Lightennet: a convolutional neural network for weakly illuminated image enhancement, ” P attern Recognition Letters , v ol. 104, pp. 15–22, 2018. [28] K. G. Lore, A. Akintayo, and S. Sarkar, “Llnet: A deep autoencoder approach to natural low-light image enhancement, ” P attern Recognition , vol. 61, pp. 650–662, 2017. [29] Q. W ang, X. Fu, X.-P . Zhang, and X. Ding, “ A fusion-based method for single backlit image enhancement, ” in 2016 IEEE International Confer ence on Image Pr ocessing (ICIP) , pp. 4077–4081. IEEE, 2016. [30] C. W ei, W . W ang, W . Y ang, and J. Liu, “Deep retinex decomposition for low-light enhancement, ” arXiv pr eprint arXiv:1808.04560 , 2018. [31] L. Shen, Z. Y ue, F . Feng, Q. Chen, S. Liu, and J. Ma, “Msr-net: Low-light image enhancement using deep con volutional network, ” arXiv pr eprint arXiv:1711.02488 , 2017. [32] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farley , S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets, ” in Advances in neural information pr ocessing systems , pp. 2672–2680, 2014. [33] P . Isola, J.-Y . Zhu, T . Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks, ” in Proceedings of the IEEE confer ence on computer vision and pattern reco gnition , pp. 1125–1134, 2017. [34] M.-Y . Liu, T . Breuel, and J. Kautz, “Unsupervised image-to-image translation networks, ” in Advances in Neural Information Processing Systems , pp. 700–708, 2017. [35] Z. Y i, H. Zhang, P . T an, and M. Gong, “Dualgan: Unsupervised dual learning for image-to-image translation, ” in Proceedings of the IEEE international confer ence on computer vision , pp. 2849–2857, 2017. [36] J.-Y . Zhu, T . Park, P . Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks, ” in Pr oceedings of the IEEE international conference on computer vision , pp. 2223– 2232, 2017. [37] E. H. Land and J. J. McCann, “Lightness and retinex theory , ” Josa , vol. 61, no. 1, pp. 1–11, 1971. [38] A. M. Reza, “Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement, ” Journal of VLSI signal processing systems for signal, ima ge and video technology , vol. 38, no. 1, pp. 35–44, 2004. [39] C. Solomon and T . Breckon, Fundamentals of Digital Image Pr ocessing: A practical appr oach with examples in Matlab . John W iley & Sons, 2011. [40] T . Kim, M. Cha, H. Kim, J. K. Lee, and J. Kim, “Learning to discover cross-domain relations with generati ve adv ersarial networks, ” in Pr oceedings of the 34th International Confer ence on Machine Learning- V olume 70 , pp. 1857–1865. JMLR. org, 2017. [41] H. Zhao, O. Gallo, I. Frosio, and J. Kautz, “Loss functions for image restoration with neural networks, ” IEEE T ransactions on Computational Imaging , vol. 3, no. 1, pp. 47–57, 2017. [42] C. Chen, Q. Chen, J. Xu, and V . Koltun, “Learning to see in the dark, ” in Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pp. 3291–3300, 2018. [43] O. Ronneber ger , P . Fischer, and T . Brox, “U-net: Con volutional networks for biomedical image segmentation, ” in International Conference on Medical image computing and computer-assisted intervention , pp. 234– 241. Springer , 2015. [44] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment