Visual Wake Words Dataset
The emergence of Internet of Things (IoT) applications requires intelligence on the edge. Microcontrollers provide a low-cost compute platform to deploy intelligent IoT applications using machine learning at scale, but have extremely limited on-chip …
Authors: Aakanksha Chowdhery, Pete Warden, Jonathon Shlens
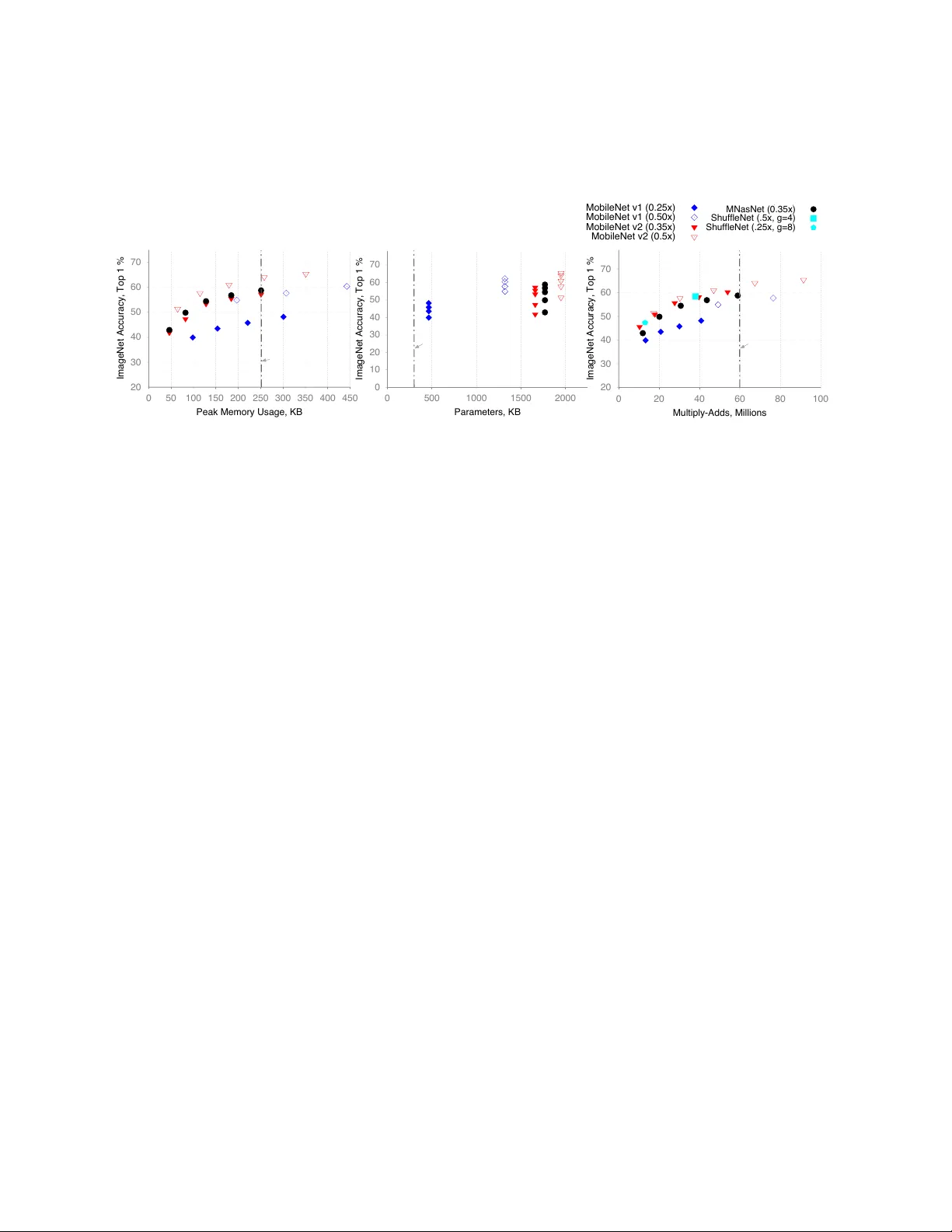
V isual W ake W ords Dataset Aakanksha Cho wdhery , Pete W arden, Jonathon Shlens, Andre w Ho ward, Rock y Rhodes Google Research { cho wdhery , pete warden, shlens, ho warda, rock y } @google.com Abstract The emergence of Internet of Things (IoT) applications requires intelligence on the edge. Microcontrollers pro- vide a lo w-cost compute platform to deploy intelligent IoT applications using machine learning at scale, b ut ha ve extremely limited on-chip memory and compute capabil- ity . T o deploy computer vision on such de vices, we need tiny vision models that fit within a few hundred kilobytes of memory footprint in terms of peak usage and model size on de vice storage. T o facilitate the dev elopment of microcontroller friendly models, we present a new dataset, V isual W ake W ords, that represents a common microcontroller vision use-case of identifying whether a person is present in the image or not, and provides a re- alistic benchmark for tiny vision models. Within a lim- ited memory footprint of 250 KB, several state-of-the-art mobile models achie ve accurac y of 85-90% on the V isual W ake W ords dataset. W e anticipate the proposed dataset will adv ance the research on tiny vision models that can push the pareto-optimal boundary in terms of accuracy versus memory usage for microcontroller applications. 1 Intr oduction Deep learning has increased the accurac y of computer vi- sion dramatically , enabling their widespread use. De vices at the edge hav e limited compute, memory , and po wer constraints; thereby requiring lo w-latency neural network architectures. Recent advances hav e enabled real-time in- ference for sev eral vision tasks on mobile platforms. First, CNN architectures, such as MobileNets [ 1 , 2 , 3 ], use op- erations such as depthwise separable con v olutions to op- timize the latency with minimal accuracy cost. Second, model compression techniques, such as quantization [ 4 ] and pruning [ 5 , 6 ] optimize the latenc y and size of the model further . W ith the emergence of Internet of Things (IoT), the ne xt frontier to deploy machine learning will be IoT sensors that use microcontrollers as limited compute platforms. Microcontrollers are widely used for lo w-cost compu- tation in IoT de vices ranging from industrial IoT to smart- home applications. Low-cost imaging sensors with mi- crocontrollers are economical to deploy in se veral vision applications, for example, to sense if humans (or pets) are present in the b uilding or to monitor cars in garage or traf- fic cameras. The limited computation may not be suffi- cient to get real-time insights of who or what is present. Howe v er , if the object of interest is present, it can then trigger an alert for human intervention or be streamed to a network server or cloud for further analysis. The two key challenges in deploying neural networks on microcontrollers are the low memory footprint and the limited battery life. In this paper , we focus on the low memory footprint. T ypical microcontrollers hav e ex- tremely limited on-chip memory (100–320 KB SRAM) and flash storage (256 KB–1 MB). The entire neural net- work model with its weight parameters and code has to fit within the small memory budget of flash storage. Fur - ther , the temporary memory buf fer required to store the input and output activ ations during computation must not exceed the SRAM. Thus, we need to design tin y vision models that achieve high accurac y on the typical micro- controller vision use-cases and fit within these constraints. W e set the following design constraints on the tiny vi- sion models for the microcontroller vision use-cases: the model size and the peak memory usage must fit within a 1 limited memory footprint of 250 KB each; and the neu- ral network computation must incur less than 60 million multiply-adds per inference at high accuracy . W e ob- serve that designing high-accuracy models under these constraints is challenging. A vailable image datasets are not representative of the typical microcontroller vision use-cases. For example, the MobileNet V2 model archi- tecture achieves only 58% accuracy at depth multiplier 0.5 with image resolution 160 on the ImageNet [ 7 ] dataset at 50 million multiply-adds and uses 1.95 million parame- ters. Ho wev er , ImageNet [ 7 ] requires classification to a thousand classes and this model could still be suitable for microcontroller vision use-case if it fit within the memory constraints. On the other hand, CIF AR10 [ 8 ] is a small dataset with a very limited image resolution of 32-by-32 that does not accurately represent the benchmark model size or accuracy on lar ger image resolutions. In this paper, we propose a ne w dataset, V isual W ake W ords, as a benchmark for the tiny vision models to deploy on microcontrollers and advance research in this area. W e select the use-case of classifying images to two classes, whether a person is present in the image or not, as the representative vision task in the proposed dataset because it is one of the popular microcontroller vision use-cases. This use-case is for a device to wake up when a person is present analogous to ho w audio wake words are used in speech recognition [ 9 ]. This dataset filters the labels of the publicly av ailable COCO dataset to pro- vide a dataset of 115k training and v alidation images with labels of person and not-person. W e observe that this dataset provides valuable insights for model design be- cause the accuracy on V isual W ake W ords dataset can’t be extrapolated directly from accuracy on the ImageNet dataset. Further , the availability of full-resolution images in the proposed dataset allows users to train vision models at different image resolutions and benchmark the pareto- optimal boundary in terms of accuracy vs memory usage of the model design in this regime. W e discuss the memory-latency tradeoffs in deploy- ing se veral state-of-the art mobile models, such as Mo- bileNet V1 [ 1 ], MobileNet V2 [ 2 ], MNasNet (without squeeze-and-excite) [ 10 ], Shuf fleNet [ 11 ] etc. in the tiny vision model regime. In particular , the peak memory usage increases when the conv olutional neural netw orks (CNNs) use residual blocks and inv erted residual blocks. When the SRAM is limited, we process only a single path MCU Platform Processor Frequency SRAM Flash FRDM-K64F [ 12 ] Cortex-M4 120 MHz 256 KB 1 MB STM32 F723 [ 13 ] Cortex-M7 216 MHz 256 KB 512 KB Nucleo F746ZG [ 14 ] Cortex-M7 216 MHz 320 KB 1 MB NXP i.MX1060 [ 15 ] Cortex-M7 600 MHz 1 MB External T able 1: Some of f-the-shelf microcontroller de velopment platforms with their SRAM and flash storage constraints. Note we list the microcontrollers with at least 250 KB SRAM, though other examples, such as, Cortex M0 only hav e 20–30 KB SRAM. each time; thus incurring additional latency when CNNs stage the computation of each path. Thus, the limited model size and peak memory usage of 250 KB determines the model parameters, such as selected image resolution, number of channels (depth multiplier for MobileNets), and the model depth. W e conclude with a set of candi- date models that achie ve 85–90% accuracy on the V isual W ake W ords dataset and define the pareto-optimal bound- ary in terms of accuracy vs memory usage. 2 Related W ork Model compr ession. Model architectures widely used and deployed on mobile devices include MobileNets [ 1 ], and MobileNetV2 [ 2 ]. The proposed architectures have been further optimized for latency using hardware-based profiling [ 16 ] and Neural architecture search [ 10 , 3 ]. ResNet-like model architectures [ 17 , 18 ] ha ve also been optimized for mobile and embedded de vices in ShuffleNet V2 [ 11 , 19 ] and SqueezeNet [ 20 ]. Recent literature has also proposed several compression approaches that in- clude quantization of weights and activ ations to leverage 8-bit arithmetic [ 4 , 21 ], and pruning the graph parameters that are less likely to af fect accuracy [ 5 , 6 , 16 ]. Models for micr ocontroller devices. In the regime of microcontrollers, machine learning model design has fo- cused on audio use cases such as keyw ord spotting. Re- cent papers benchmarking the speed-latency tradeof fs for the keyword-spotting use-case [ 9 ] on microcontrollers propose 20–64 KB model with 10-20 million operations per second [ 22 , 23 , 24 , 25 ]. Further speedups are poten- tially possible with the use of binary weights and acti v a- 2 tions, such as XnorNet [ 26 ], T rained T ernary Quantiza- tion [ 27 ] or with sparse architectures [ 28 ]. Under e xtreme memory constraints, recent work [ 29 ] has also proposed computing the con v olution weight matrices on the fly us- ing deterministic filter banks stored in the flash storage. 3 V ision on Microcontr ollers 3.1 V ision Use Cases Microcontrollers provide an economical way to deplo y vi- sion sensing at scale. V ideo camera feeds, ho we v er , do not contain objects of interest at most times. For example, in building automation scenarios, humans may be present in a small subset of image frames. Streaming the camera video feed to the cloud continuously is not economical or useful. On-device sensing is economical when the vi- sion models deployed on the microcontrollers are tiny and cost-effecti v e. Microcontrollers are best suited for vision tasks where they act as ‘V isual W akeW ords’ to other sen- sors or generate alerts, similar to the popular audio w ake- words, such as “Ok Google” or “Hey Google. ” W e dis- cuss some common use-cases for microcontroller vision models: Person/Not-P erson: A popular use-case is sensing whether a person is present in the image or not. Sens- ing person/not-person serv es a wide-v ariety of use-cases including smart homes, retail, and smart b uildings. The inference result could then feed in to the If-this-then-that logic of various IoT deployments enabling other IoT de- vices to start or trigger alerts. Generalizing from the person/not-person use case, low-cost vision sensors can be economically deployed to sense the presence of spe- cific objects of interest without high costs of inference, such as pets in a home, or cars in the garage. Object counting: In camera feeds, counting the num- ber of objects pro vides a lo w-cost w ay to trigger other sensors. F or example, in traf fic monitoring, the vision sensors could count the number of cars and trigger alerts in specific scenarios. Object localization: Lo w-cost vision sensors can also be used to localize the object of interest, such as, per- son, pet, car, or traffic signs and trigger useful alerts or reminders. 3.2 Micr ocontr oller Systems For the vision use cases in the pre vious section, we now discuss the key challenges in deploying deep neural net- works to enable real-time inference on microcontrollers because most microcontrollers are designed for embedded applications with low cost and do not have high through- put for compute-intensiv e workloads such as CNNs. On-chip memory f ootprint. A typical microcontroller system consists of a processor core, an on-chip SRAM block and an on-chip embedded flash. One major con- straint is the limited memory footprint in terms of on- chip memory and Flash storage. T able 1 lists the details of some off-the-shelf microcontroller de v elopment plat- forms with their SRAM and Flash storage. The program binary , usually pre-loaded into the non- volatile flash, is loaded into the SRAM at startup and the processor runs the program with the SRAM as the main data memory . The size of the SRAM limits the size of memory that the softw are can use. When the SRAM is extremely limited, we need to ensure that the peak mem- ory usage of the model computations is less than the total memory usage. Peak memory usage is the maximum amount of total memory , including to store CNN acti vation maps, at any point in time during inference. K eeping activ ations in fast on-chip memory is important for performing fast infer- ence, and large transient acti v ations require large amounts of e xpensi ve local memory or long wait times if acti v a- tions spill to slo wer of f-chip memories. W e assume that the weights will be read from the flash storage directly during the CNN inference, or else storing the temporary weights incurs additional memory usage. As a first-order approximation, we estimate the peak memory usage as follows. For each operation (e.g., mat- mul, con v olution, pooling), we sum the size of the input allocations and output allocation. If the neural network is a simple chain of operations with no branching, for e.g. in MobileNet V1, select the maximum of these numbers and skip the follo wing steps. For each parallel branch in the graph, for e.g. in MobileNet V2, we need to sum the acti- 3 vation storage of e very pair of operations between the two branches. For each pair of operations, shared inputs must be counted once (e.g., the input to a simple residual block will be used in both parallel chains of the block) and we select the maximum of these numbers. Model size. T o reduce the memory cost of storing the model on-device, the number of parameters in the model must be less than the flash memory storage. T o save suf- ficient space for code of the compiler frame work, we as- sume that 250 KB is needed to store the model in flash. Thus, the CNN model must be less than 250 K parame- ters assuming 8-bit representations for weights. Perf ormance. W e benchmark the performance of CNNs in terms of accuracy and multiply-adds per infer - ence. T o enable at least one or more inferences per second on a microcontroller processor running at 100-200 MHz (see T able 1 ), we limit the multiply-add operations on the microcontroller to be less than 60 million multiply- adds per inference. A CNN model with only 10 mil- lion multiply-adds per inference can increase the infer- ence throughput by 5-10x. The actual performance cost needs to be measured in terms of latenc y per inference because it includes the cost of memory accesses and the latenc y cost of con v olutional kernels. Multiply-adds pro vide a first-order approxima- tion of the inference cost agnostic to the underlying plat- form architecture and kernel implementation specifics. T o ensure a long battery life for the IoT devices, we must also consider the energy ef ficiency of the microcon- troller so that it can last without char ging for long time periods. Energy efficiency depends on the computational cost of the CNN and the duty c ycle of processing; both of which continue to be an activ e area of research. Based on the microcontroller system constraints in this section, we set the following design constraints on the tin y vision models for the microcontroller vision: the model size and the peak memory usage must fit within a limited memory footprint of 250 KB each; and the CNN compu- tation must incur less than 60 million multiply-adds per inference at high accuracy . 4 V ision Datasets f or Micr ocon- tr ollers Currently vision models are benchmarked on the CI- F AR10 [ 8 ] or ImageNet [ 7 ] datasets both of which are restricted in terms of benchmarking the model accurac y and the memory costs for the common lo w-complexity microcontroller use-case. W e present a ne w dataset, V i- sual W ake W ords, that represents a common microcon- troller vision use-case of identifying whether a person is present in the image or not, The proposed dataset is de- riv ed from the publicly av ailable COCO dataset, and pro- vides a realistic benchmark for tiny vision models. 4.1 Existing Datasets ImageNet [ 7 ] is the most widely used dataset for vision benchmarks. It constitutes tens of millions of annotated images with labels that classify the images in to 1000 classes providing a generic benchmark for se v eral state- of-the-art models. There are several challenges in using this dataset to benchmark the microcontroller vision use- cases. First, ImageNet dataset does not address a v ery popular use-case of person/not-person classification be- cause it does not hav e instances of person class. Second, the typical vision use-cases for microcontroller do not re- quire a large number of classes. The parameters of the last few layers of CNN in the classification model can domi- nate the model size. For a binary classification task, the model size can be compressed substantially by reducing the memory footprint of last few layers. CIF AR10 dataset [ 8 ] has been actively used to bench- mark some recent microcontroller vision models. For e x- ample, recent work [ 25 ] benchmarks a 5-layer con v olu- tional neural network (CNN) for CIF AR-10 dataset on an of f-the-shelf Arm Cortex-M7 platform classifying 10.1 images per second with an accuracy of 79.9%. Ho we ver , CIF AR10 dataset is a small dataset that consists of 60000 32x32 color images in 10 classes. Limited image resolu- tion limits its use to benchmark model accurac y for lar ger image resolutions. Further the model size and memory usage scales with the square of the image resolution and thus, the accuracy benchmarks on this dataset are not rep- resentativ e of the peak memory usage or the model size if the model will be used for larger image resolutions. 4 4.2 V isual W ake W ords Dataset W e define a ne w dataset to fit a popular use-case for mi- crocontrollers discussed in Section 3.1 . W e focus on the binary classification use-case where the images are la- beled with two labels: object-of-interest is present or not present. The most interesting use-case enables the mi- crocontrollers to classify whether there is a person in the image or not. Hence, we call this the V isual W ake W ords dataset because it enables a device to w ake up when a hu- man is present analogous to how audio wake words are used in speech recognition [ 9 ]. W e deri ve the ne w dataset by re-labeling the images av ailable in the publicly av ailable COCO dataset with labels corresponding to whether the object-of-interest is present or not. This provides a powerful way to bench- mark this common vision use-case for microcontrollers with a simple tweak to the COCO dataset. COCO dataset [ 30 ] is widely used to benchmark object detection and segmentation tasks. COCO dataset comprises natural images of complex e veryday scenes that contain multiple objects and it has 91 objects types with more than a mil- lion labeled instances in 115k images in the training and validation set. The process of creating new labels for V isual W ake W ords dataset from COCO dataset is as follows. Each image is assigned a label 1 or 0. The label 1 is assigned as long as it has at least one bounding box corresponding to the object of interest (e.g. person) with the box area greater than 0.5% of the image area. In the person/not- person use-case, the label 1 corresponds to the ‘person’ being present in the image and the label 0 corresponds to the image not containing any objects from person class. T o generate the new annotations and the files in T ensorFlo w records format corresponding to this dataset, use the script build visualwakewords data.py av ailable in open-source in ‘tensorflow/models/research/slim/datasets’ [ 31 ]. The command to generate the V isual W ake W ords dataset from ‘tensorflow/models/research/slim’ di- rectory using the script as follows: p y t h o n d a t a s e t s / b u i l d v i s u a l w a k e w o r d s d a t a . p y \ − − t r a i n i m a g e d i r = ” $ { T RAIN IM AGE DIR } ” \ − − v a l i m a g e d i r = ” $ { VAL IMAGE DIR } ” \ − − t e s t i m a g e d i r = ” $ { T EST I MAGE D IR } ” \ − − t r a i n a n n o t a t i o n s f i l e = ” $ { T RA IN A NNO TA TI ON S } ” \ − − v a l a n n o t a t i o n s f i l e = ” $ { V A L AN NO T A T I O NS } ” \ − − o u t p u t d i r = ” $ { OUTPUT DIR } ” \ (a) ‘Person’ (b) ‘Not-person’ Figure 1: Sample images labeled to ‘person’ and ‘not- person’ categories from COCO training dataset. − − s m a l l o b j e c t a r e a t h r e s h o l d = 0 . 0 0 5 Figure 1 illustrates an example of sample images la- beled to ‘person’ and ‘not-person’ categories from the COCO training dataset. The command can be modified to classify the presence of another object of interest instead of the ‘person’ class by adding an additional flag specifying the ne w label from the COCO category . The def ault is set to the ‘person‘ category . − − f o r e g r o u n d c l a s s o f i n t e r e s t = ‘ p e r s o n ’ W e use the above script on the training and v alidation image set of COCO2014 dataset [ 30 ]. W e use a total of 115k images of the training and v alidation dataset to gen- erate ne w annotations. W e assign ‘person’ label when the image contains at least one bounding box from per- son class with the bounding box area greater than 0 . 5 % of the image area. W e observe that the reassigned labels are roughly balanced between the two classes: 47% of the images in the training dataset of 115k images are labeled to the ‘person’ cate gory , and similarly , 47% of the images in the validation dataset are labeled to the ‘person’ cate- gory . For e v aluation, we use the mini v al [ 32 , 33 ] on the COCO2014 dataset [ 30 ] comprising a total of 8k images. 5 Experiments W e ev aluate the tiny vision models on the ImageNet dataset and the proposed V isual W ake W ords Dataset for the person/not-person classification task. W e present ex- perimental results to demonstrate the effecti v eness of the proposed dataset to benchmark the microcontroller vision 5 20 30 40 50 60 70 0 20 40 60 80 100 ImageNet Accuracy, Top 1 % Multiply-Adds, Millions 60 million MAdds/ inference 20 30 40 50 60 70 0 50 100 150 200 250 300 350 400 450 ImageNet Accuracy, Top 1 % Peak Memory Usage, KB 250 KB constraint 0 10 20 30 40 50 60 70 0 500 1000 1500 2000 ImageNet Accuracy, Top 1 % Parameters, KB 250 KB constraint MobileNet v1 (0.25x) MobileNet v1 (0.50x) MobileNet v2 (0.35x) MobileNet v2 (0.5x) MNasNet (0.35x) MobileNet v2 (0.5x) MNasNet (0.35x) ShuffleNet (.5x, g=4) ShuffleNet (.25x, g=8) Figure 2: On ImageNet dataset, we compare the top-1 accurac y versus the memory footprint, model size and multiply- adds per inference. Figure (a) shows the top-1 accurac y vs estimated peak memory usage (in KB), (b) the top-1 accuracy vs number of parameters (in KB), and figure (c) sho ws the top-1 accuracy vs multiply-adds (in millions). Each point corresponds to different image resolution in { 96, 128, 160, 192, 224 } . use-cases. W e benchmark the following models: Mo- bileNet V1 [ 1 ], MobileNet V2 [ 2 ], MNasNet (without squeeze-and-excite) [ 10 ], and Shuf flenet [ 11 ]. W e com- pare accuracy versus measures of resource usage such as the peak memory usage, model size (number of parame- ters) and inference multiply adds. Our design goal is tiny vision models that use less than 250 KB in SRAM, the model size fits within 250 KB of av ailable flash storage, and the inference cost is less than 60 million multiply- adds per inference. 5.1 T raining setup MobileNet and MNasNet models are trained in T ensor- Flow using asynchronous training on GPU using the stan- dard RMSPropOptimizer with both decay and momentum set to 0.9. W e use 16 GPU asynchronous workers, and a batch size of 96. W e use an initial learning rate of 0.045, and learning rate decay rate of 0.98 per epoch. All the con v olutional layers use batch normalization with av erage decay of 0.99. Using the floating-point checkpoints, we then train models with 8-bit representation of weights and activ ations by using quantization-aw are training [ 34 , 4 ] with a learning rate of 10 − 5 and learning rate decay of 0.9 per epoch. Since we only classify two classes in V i- sual W ake W ords dataset, we shrink the last con v olutional layer in MobileNet V2 and MNasNet models. In the V isual W ake W ords dataset, we ev aluate the ac- curacy on the miniv al image ids [ 32 , 33 ] of COCO2014 dataset [ 30 ] comprising a total of 8k images, and for training, we use the remaining images out of 115k im- ages in training/validation dataset (not including the 8k COCO2014 miniv al images). 5.2 Accuracy W e compare and contrast the accurac y of these models on ImageNet dataset vs the V isual W ake W ords Dataset. Figure 2 illustrates the top-1 accuracy of MobileNet [ 1 ], MNasNet (without squeeze-and-excite) [ 10 ], and Shuf- fleNet [ 19 ] models on ImageNet dataset (that classifies the images to 1000 classes) with respect to peak mem- ory usage, model size, and multiply-adds. W e measure the model size in terms of number of parameters in kilo- bytes assuming 8-bit representation of weights. W e vary the depth multiplier of the models and for each depth multiplier , we illustrate the model accuracy at multiple image resolutions in { 96, 128, 160, 192, 224 } . W ith fixed inference cost of 50 million multiply-adds, the ac- curacy improves in the order of MobileNet V1, Mo- bileNet V2, Shuf fleNet, and MNasNet (without squeeze- and-excite). Note that the top-1 accuracy increases with increased depth multiplier and image resolution. For a fixed model size, we can reduce the peak memory usage 6 75 80 85 90 95 100 0 50 100 150 200 250 300 Visual WakeWords Accuracy, % Peak Memory Usage, KB 75 80 85 90 95 100 0 100 200 300 400 500 Visual WakeWords Accuracy, % Parameters, KB 75 80 85 90 95 100 0 10 20 30 40 50 60 Visual WakeWords Accuracy, % Multiply-Adds, Millions 250 KB constraint 250 KB constraint 60 million MAdds/ inference MobileNet v1 (0.25x) MobileNet v2 (0.35x) MNasNet (0.35x) Figure 3: On V isual W ake W ords dataset, we compare the accuracy versus the memory footprint, model size and multiply-adds per inference. Figure (a) shows the accuracy vs estimated peak memory usage (in KB), (b) the ac- curacy vs number of parameters (in KB), and figure (c) sho ws the accuracy vs multiply-adds (in millions). Each point corresponds to different image resolution in { 96, 128, 160, 192, 224 } . Note that the red and black points are ov erlapping. and the multiply-adds by reducing the image resolution. For example, increasing the image resolution from 96 to 224 increases the top-1 accuracy of MobileNet V1 with depth multiplier 0.25 from 39.9% to 48%, and of MNas- Net from 42.91% to 58.79%. Howe v er , there is a trade- off in terms of the peak memory usage, number of pa- rameters, and multiply-adds. For example, in the regime of models with less than 60 million multiply-adds, Mo- bileNet V1 model with depth multiplier 0.5 on image res- olution 128 achie ves higher top-1 accuracy of 54.9% com- pared to the same model with depth multiplier 0.25 on im- age resolution 224. Howe ver , it is not feasible to fit this model in 250KB because the model trained on ImageNet dataset has much higher model size and peak memory us- age. Figure 3 illustrates the accuracy of correct classification on the two classes person/not-person on the V isual W ake W ords dataset. Note that the top-1 accuracy of MobileNet V1, MobileNet V2 and MNasNet (without squeeze-and- excite) is less than 60% on the ImageNet dataset, how- ev er , the accuracy is greater than 85% for the three models on the V isual W ake W ords dataset. Further , we note that all models fit within the peak memory usage of 250 KB. Howe v er , MobileNet V2 and MNasNet models require special memory management to fit the model within these constraints that we discuss in detail in the ne xt section. In terms of model size (number of parameters) in KB, Mo- bileNet V1 with depth multiplier 0.25 is 208 KB while the MobileNet V2 and MNasNet models with depth mul- tiplier 0.35 require 290 KB and 400 KB respecti v ely . This suggests that model size can be compressed further by reducing the depth multiplier and additional techniques such as pruning to provide smaller model sizes. 5.3 Memory-latency trade-offs Peak Memory Usage. W e use on-chip SRAM to store the input/output acti v ation maps of each layer assuming that we reuse the temporary buf fer space for storing the input and the output b uf fer space. T o benchmark the peak memory usage, we assume 8-bit representation for acti v a- tions. W e find that the peak memory usage is often dom- inated by the input and output activ ation maps of the first few layers in MobileNet and MNasNet architectures. T o limit the peak memory usage, the output channels in first con v olutional layer are limited to eight channels when we use depth multiplier 0.35 for MobileNet V2 and MNasNet model architectures. Figure 4 illustrates this for two different models: Mo- bileNet V1 and MobileNet V2. Note that in MobileNet V1 architecture, we re-use the b uf fer A to store the inputs to con v 1x1 layer . In MobileNet V2 architecture, we hav e parallel paths between the inputs and the outputs of dif- ferent layers, but the projection and expansion layers do 7 Depthwise Conv 3x3, stride=s, Relu6 Conv 1x1, Relu6 Buffer A Buffer B Buffer A Depthwise Conv 3x3, stride=s, Relu6 Conv 1x1, Relu6 Buffer A Buffer C Buffer D Conv 1x1, Relu6 Buffer B Figure 4: T emporary b uf fer management for MobileNet V1 (left) and MobileNet V2 (right). not need to be materialized completely using tricks sug- gested in [ 2 ]. W e assume that the expansion/depthwise- con v olution/projection matrices are split into six parallel paths and each path is materialized only during its compu- tation. As a result, we need additional temporary buffers B and C to store the intermediate values so that they can be added to the output afterward. Peak memory usage for each of the neural-network lay- ers must fit within the SRAM. W e observe in Figure 3 that for a gi ven model architecture with a fix ed depth multi- plier , scaling the input image resolution reduces the peak memory usage. In the first few layers, the acti vation map size is directly proportional to the square of image reso- lution that will be a limiting factor in selecting the archi- tecture and its number of channels. In the last few layers, the larger number of channels could dominate the mem- ory required. Further note that the con volution kernel may require additional b uffer space to store the temporary out- puts when using GEMM kernels that affects the memory consumption of the last few layers. Further optimization requires efficient conv olution kernels that are computed in-place or in a tiled implementation, further reducing the memory usage of specific layers. Model size. The model must fit in the flash memory typically within a fe w hundred kilobytes (up to 1 MB). T echniques to reduce the model size include using a lo wer depth multiplier in the MobileNet type architectures, and compression techniques, such as quantization or pruning. T ypically models with a higher depth multiplier achie v e higher accuracy but require a lar ger model size. Reducing the input image resolution will only reduce the peak mem- ory usage or latency but not the model size. Consider the scenario with image resolution of 224, MobileNet V2 ar- chitecture with depth multiplier 0.35 requires 290KB and with depth multiplier 0.5 requires 569KB to store weights of the layers that extract features in 8-bit. Latency . Model performance depends on the computa- tional cost of the conv olution kernels. MobileNet archi- tectures’ latency is dominated by pointwise and separa- ble depthwise con volution kernels, that can be made faster using fix ed-point arithmetric with 8-bit representation of models or using GEMM kernels. In some cases, we may choose to trade-of f memory for latency , for example, we can compute depthwise separable con v olutions in-place using for loops to sav e memory footprint, but then we can no longer use the memory rearrangement techniques to speed up the kernels. Alternate implementations of con v olution kernels using lower -precision weights could speed up the con v olution kernels. W e profile the latency of deploying the con volutional layers of the MobileNet V1 model with depth multi- plier (0.25x) on the microcontroller development board STM32 F746 [ 13 ]. W e use ARM CMSIS5-NN kernels to program the depthwise and pointwise con volutions in Mo- bileNet V1 architecture. The ov erall latenc y per inference is approx 1.3 sec enabling approximately 0.75 frames/sec. This frame rate suf fices in application requirements when the person count doesn’t change frequently . 6 Conclusions and Futur e W ork In this paper , we introduced the challenges in deploying neural netw orks on microcontrollers that can enable intel- ligence on the edge at scale in se veral emerging IoT ap- plications. Limited on-chip memory will be a major con- straint in deploying CNN models on microcontrollers. W e believ e that such model deployments will require tiny vi- sion models fitting both the model size and the peak mem- ory usage within 250 KB at less than 60 million multiply- adds per inference. Existing datasets are not represen- tativ e of the pareto-optimal boundary of model accuracy vs peak memory usage for such tin y vision models. T o 8 advance research in this area, we present a ne w dataset, ‘V isual W ake W ords’, that classifies images for the pres- ence of a person or not that is a popular microcontroller vision use-case. Our initial benchmarks on the state-of- the-art models with 8-bit weights and acti vations on this dataset achiev e up to 90% for classification task, and the same MobileNet models can also form the basis of per- son counting and localization tasks. W e believ e that the V isual W ake W ords Dataset will provide researchers with a platform to fundamentally rethink the design of tiny vi- sion models that fit on microcontrollers. Refer ences [1] A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W . W ang, T . W eyand, M. Andreetto, and H. Adam. MobileNets: Ef ficient Con volutional Neural Net- works for Mobile V ision Applications, April 2017. [2] Mark Sandler , Andrew Howard, Menglong Zhu, Andrey Zhmoginov , and Liang-Chieh Chen. Mo- bilenetv2: In verted residuals and linear bottlenecks. In Pr oceedings of the IEEE Confer ence on Com- puter V ision and P attern Recognition , pages 4510– 4520, 2018. [3] Andrew Howard, Mark Sandler , Grace Chu, Liang- Chieh Chen, Bo Chen, Mingxing T an, W eijun W ang, Y ukun Zhu, Ruoming Pang, V ijay V asude- van, Quoc V . Le, and Hartwig Adam. Searching for mobilenetv3. arXiv pr eprint arXiv:1905.02244 , 2019. [4] B. Jacob, S. Kligys, B. Chen, M. Zhu, M. T ang, A. Howard, H. Adam, and D. Kalenichenko. Quanti- zation and T raining of Neural Netw orks for Ef ficient Integer -Arithmetic-Only Inference. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 2704–2713, 2018. [5] Michael Zhu and Suyog Gupta. T o prune, or not to prune: exploring the efficac y of pruning for model compression. arXiv preprint , 2017. [6] Forrest N. Iandola, Matthew W . Moske wicz, Khalid Ashraf, Song Han, William J. Dally , and Kurt Keutzer . Squeezenet: Alexnet-le vel accuracy with 50x fe wer parameters and < 1mb model size. CoRR , abs/1602.07360, 2016. [7] Olga Russakovsk y , Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy , Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Im- ageNet Large Scale V isual Recognition Challenge. International Journal of Computer V ision (IJCV) , 115(3):211–252, 2015. [8] Alex Krizhe vsky and Geoffre y Hinton. Learning multiple layers of features from tiny images. T ech- nical report, Citeseer , 2009. [9] Pete W arden. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv pr eprint arXiv:1804.03209 , 2018. [10] Mingxing T an, Bo Chen, Ruoming Pang, V ijay V a- sudev an, and Quoc V Le. Mnasnet: Platform-aw are neural architecture search for mobile. arXiv pr eprint arXiv:1807.11626 , 2018. [11] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely ef ficient con- volutional neural netw ork for mobile de vices. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 6848–6856, 2018. [12] NXP MCUs. https://www .nxp.com/support/dev eloper- resources/ev aluation-and-de v elopment- boards/freedom-dev elopment-boards/mcu- boards/freedom-dev elopment-platform-for -kinetis- k64-k63-and-k24-mcus. [13] STM32F7 Series of MCUs. https://www .st.com/en/microcontrollers- microprocessors/stm32f7-series.html. [14] STM32 Nucleo boards. https://www .st.com/en/ev aluation-tools/stm32- nucleo-boards.html. 9 [15] NXP i.MX R T Series: Crossover Processor . https://www .nxp.com/products/processors-and- microcontrollers/arm-based-processors-and- mcus/i.mx-applications-processors/i.mx-rt-series. [16] T ien-Ju Y ang, Andre w How ard, Bo Chen, Xiao Zhang, Alec Go, Mark Sandler , V i vienne Sze, and Hartwig Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In Pr o- ceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 285–300, 2018. [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual net- works. In Eur opean confer ence on computer vision , pages 630–645. Springer , 2016. [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recogni- tion. In Pr oceedings of the IEEE conference on com- puter vision and pattern r ecognition , pages 770– 778, 2016. [19] Ningning Ma, Xiangyu Zhang, Hai-T ao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for ef fi- cient cnn architecture design. In Pr oceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 116–131, 2018. [20] Forrest N Iandola, Song Han, Matthe w W Moske wicz, Khalid Ashraf, William J Dally , and Kurt Keutzer . Squeezenet: Alexnet-le vel accuracy with 50x fewer parameters and¡ 0.5 mb model size. arXiv pr eprint arXiv:1602.07360 , 2016. [21] Raghuraman Krishnamoorthi. Quantizing deep con v olutional networks for efficient inference: A whitepaper . arXiv pr eprint arXiv:1806.08342 , 2018. [22] Liangzhen Lai, Naveen Suda, and V ikas Chandra. Cmsis-nn: Ef ficient neural network kernels for arm cortex-m cpus. arXiv pr eprint arXiv:1801.06601 , 2018. [23] Liangzhen Lai and Na v een Suda. Rethinking ma- chine learning dev elopment and deployment for edge devices. arXiv pr eprint arXiv:1806.07846 , 2018. [24] Liangzhen Lai, Naveen Suda, and V ikas Chandra. Not all ops are created equal! arXiv pr eprint arXiv:1801.04326 , 2018. [25] Y undong Zhang, Naveen Suda, Liangzhen Lai, and V ikas Chandra. Hello edge: Ke yword spotting on microcontrollers. arXiv pr eprint arXiv:1711.07128 , 2017. [26] Mohammad Rastegari, V icente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary con v olutional neural net- works. In European Confer ence on Computer V i- sion , pages 525–542. Springer , 2016. [27] Chenzhuo Zhu, Song Han, Huizi Mao, and W illiam J Dally . Trained ternary quantization. arXiv pr eprint arXiv:1612.01064 , 2016. [28] Igor Fedorov , Ryan P Adams, Matthe w Mattina, and Paul N Whatmough. Sparse: Sparse architecture search for cnns on resource-constrained microcon- trollers. arXiv pr eprint arXiv:1905.12107 , 2019. [29] V incent W -S Tseng, Soura v Bhattacharya, Javier Fern ´ andez Marqu ´ es, Milad Alizadeh, Catherine T ong, and Nicholas D Lane. Deter- ministic binary filters for con volutional neural networks. In Pr oceedings of the 27th International Joint Confer ence on Artificial Intelligence , pages 2739–2747. AAAI Press, 2018. [30] Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Dev a Ramanan, Piotr Doll ´ ar , and C Lawrence Zitnick. Microsoft coco: Common objects in conte xt. In Eur opean confer - ence on computer vision , pages 740–755. Springer, 2014. [31] V isual W ake W ords Dataset. https://github .com/tensorflo w/models/blob/master/ research/slim/datasets/build visualwake words data.py . [32] COCO 2014 miniv al. https://github .com/tensorflo w/models/blob/master/ research/object detection/data/mscoco mini v al ids.txt. 10 [33] Jonathan Huang, V i v ek Rathod, Chen Sun, Meng- long Zhu, Anoop K orattikara, Alireza Fathi, Ian Fis- cher , Zbigniew W ojna, Y ang Song, Sergio Guadar- rama, and Ke vin Murphy . Speed/accuracy trade-of fs for modern conv olutional object detectors. In IEEE Confer ence on Computer V ision and P attern Recog- nition , 2017. [34] T ensorflow quantization library . https://www .tensorflow .org/api docs/python/ tf/contrib/quantize. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment