eSLAM: An Energy-Efficient Accelerator for Real-Time ORB-SLAM on FPGA Platform
Simultaneous Localization and Mapping (SLAM) is a critical task for autonomous navigation. However, due to the computational complexity of SLAM algorithms, it is very difficult to achieve real-time implementation on low-power platforms.We propose an …
Authors: Runze Liu, Jianlei Yang, Yiran Chen
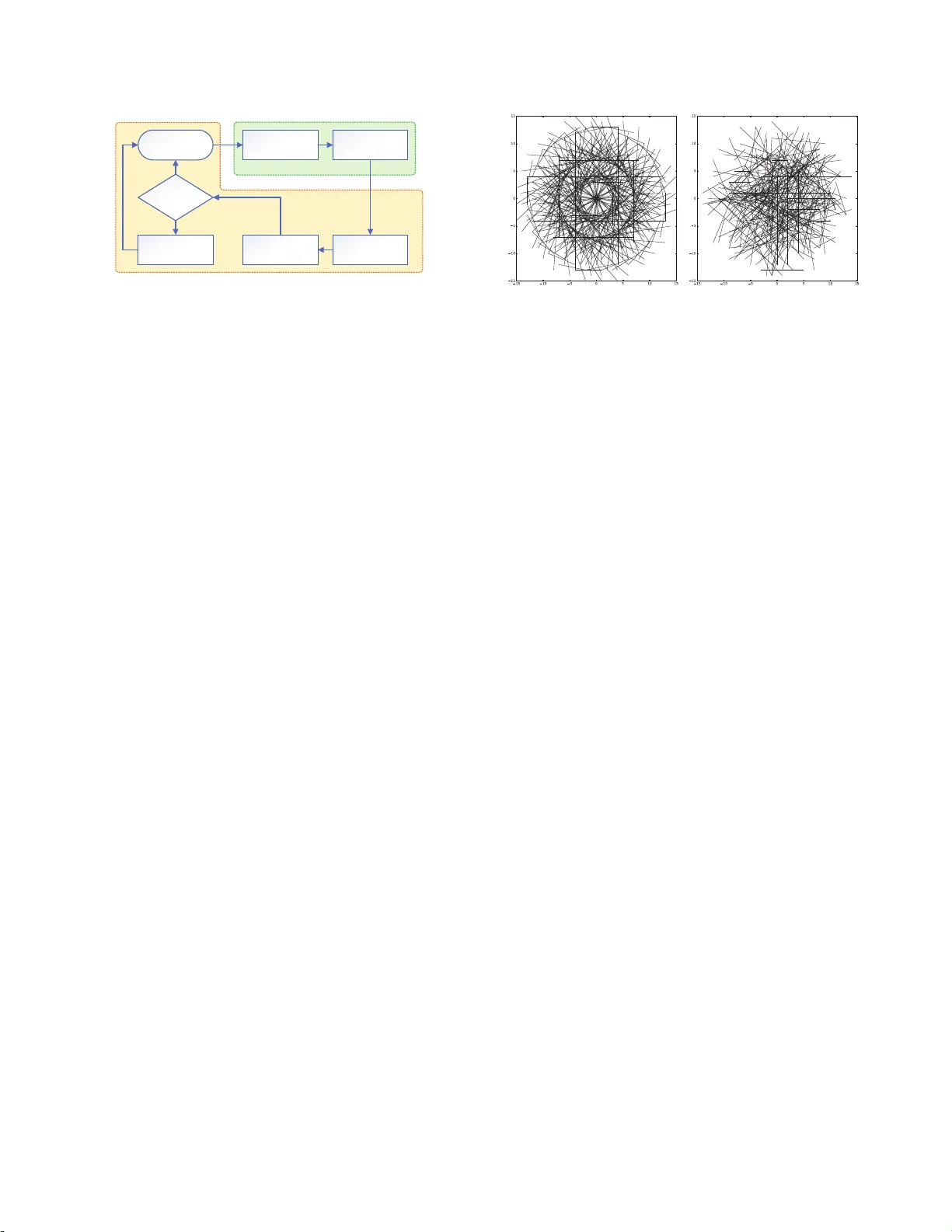
eSLAM: An Energy- Efficient Accelerator for R eal- Time ORB-SLAM on FPGA P lat f orm ∗ Runze Liu † ¶ , Jianlei Y ang † ¶ , Yiran Chen § , W eisheng Zhao ‡ ¶ † School of Computer Science and Engineering, Beihang University , B eijing, 100 191, China. ‡ School of Ele c tronic and I nformation Engineering, Beihang Univ ersity , Beijing, 1001 9 1, China. ¶ Beijing Advance d Innovation Center for Big Data and Brain Computing, Beihang University , Beijing, 100191 , China. § Department of Elec trical and C o mputer Engine ering, Duke Unive rsity , Durham, NC 27708, USA. jianlei@buaa.edu.cn weisheng.zhao@buaa.edu.cn ABSTRA CT Simultaneous Localization and Mapping (SLAM) is a critical t ask for autonomous navigation. Howeve r , due to the computational complexity of SLAM algorithms, it is very difficult t o achiev e real- time implementation on low-p owe r pl atforms. W e prop ose an energy- efficient architecture for real-time ORB (Oriented-F AST and Rot ated- BRIEF) b ase d visual SLAM system by accelerating t he most time- consuming stages of feature extraction and mat ching o n FPGA plat- form. Moreover , the or iginal ORB descriptor patt ern is reformed as a rotational symmetric manner which is much more hardware friendly . Optimizations including rescheduling and parallelizing are further ut ilized t o i mprov e the throughput and reduce the mem- ory foot p rint. Compared with Intel i7 and ARM Cortex- A9 CP Us on T UM dataset, our FPGA realization achie ves up t o 3 × and 31 × frame rate improvemen t, as well as up to 71 × and 25 × energy effi- ciency impro vemen t, res pe ct ively . KEYWORDS Visual SLAM, ORB, FPGA, Acceleration 1 IN TRODUCTION Simultaneous Lo calization and Mapping (SLAM) [3] is a critical technique for auto nomous navigation systems to build/up date a map of the surrounding environment and estimate their own l oca- tions in this map. SLAM is a fundamental problem for higher-leve l tasks such as path planning and navigation, and widely u sed in applications such as self-driving cars, robotics, virtu al reality and augmented reality . Recently , feature-based visual SLAM has received particular at- tention b ecause of its robustness t o large mot io ns and illu mina- tion changes compared w it h ot her visual SLAM approaches such ∗ This work w as supported in p art by the National N atural Science Foundation of China (61602022, 61501013, 61571023, 61521091 and 1157040329), State Key Labora tory of Software D e v elopment Environment (SKLSDE-2018ZX-07), National Key T echnolog y Program of China (2017ZX01032101), CCF-T encent IAGR20180101 a nd the Interna- tional Collaboration Project under Gr ant B16001. Permission to m ake digital or hard copies of a ll or par t of this work for personal or classroom u se is granted without fee provided that copies a re not made or distributed for pr ofit or commercial advantage a nd that copies bea r this notice and the full citation on the first page. Copyri ghts for components of this work owned by others than ACM must b e honored. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on ser vers or to redistribute to lists, requires prior specific perm ission and / or a fee. Request permiss ions fr om perm issions@acm.org. DA C ’19 , June 2–6, 2019, Las V egas, N V , USA © 2019 Association for Computing Mac hinery . A CM ISBN 978-1-4503-6725- 7/19/06. . . $15.00 https://doi.org/10.1145/3316781.3317820 as o ptical flow method o r direct metho d. Amo ng feature-based ap- proaches, ORB (Orien ted-F AST and Rotated -BRIE F) [ 8] is the most widely adopte d feature b ecause of its high efficiency and robust- ness. Howev er , the high computational intensity o f feature extrac- tion and matching makes it very challenging to ru n ORB-based vi- sual SLAM on low-power embedded platfor ms, su ch as drones and mobile robo ts, for real-time appl ications. Sev eral prior efforts have been made to accelerate visual SLAM on l ow-power platforms, but no fu lly integrated ORB-based visual SLAM is proposed on such platfo rms so far . Feature matching and ORB extraction is accelerated on FPGA for visual SLAM system, respectively in [2] and [4] . A SIFT -fe ature base d SLAM is imple- mented on FPGA [ 6] where o nly matrix comp utation is acceler- ated but the mo st time-consuming part, feature extraction, is not involv ed. A optical-flow b ase d visual inertial odometr y is imple- mented on ASIC [11], which is relatively less co mp utational inten- sive but may fail in scenarios with variational illuminations o r large motions/displacements, b ecause the basic assumptions of optical flow metho d are invalid in these scenarios [5]. In this paper , eSLAM is proposed as a heterogeneous architec- ture of ORB-based visual SLAM system. The most time-consuming procedures of feature extraction and matching are accelerated on FPGA while the remaini ng tasks including pose estimation, p ose optimization and map up dating are perfor med on the host ARM processor . The main contributions of this paper are listed as b elow: • A novel ORB-based visual SLAM accelerator is propose d for real-time appl icatio ns on energy-e fficient FPGA pl atforms. • A rotationally symmetric ORB descriptor pattern is utilize d to make our algorithm much more hardware-friendly . • Optimization including rescheduling and parallelizing are further exploited to improve the computat ion throughput. The remainder of this paper is organized as follows. Section 2 presents the ORB-based visual SLAM framew ork and the intro d uced rotationally symmetric descriptor . Se ction 3 illustrates the detailed architecture of eSLAM . Exp erimental results are evaluated fo r the proposed eSLAM in Se ction 4. Concluding remarks are given in Sec- tion 5. 2 ORB-BASED VISU AL SLAM SYSTEM 2.1 ORB-SLAM Framework The ORB-based visual SLAM system takes RGB-D (RGB and depth) images for mapping and lo calization. Its frame work, as shown in Input Image Feature Extraction Feature Matching Pose Estimation Key Frame ? Pose Optimization Map Updating False True FPGA Acceleration ARM Processor (Host) Figure 1: Visual SLAM algorithm framework. Figure 1, consists o f five main procedures: feature extraction, fea- ture matching, pose estimation, pose opt imizatio n and map updat- ing. In this work, feature extraction and feature matching are ac- celerated o n FPGA, and remaining tasks are p erformed on ARM processor . Feature Extraction: In this fu nction, ORB features are extracted from the input RGB images. ORB is a very efficient and robust co m- bination of F AST (Features from Accelerated Segment T est) key- point and BRIEF (Binary Robust Independent El ementar y Features) [1] descriptor . It calcul ates orientations of ev ery feature and rotates the descriptor pattern acco rdingly to make t he features rotationally in- variant. And t o obt ain scale invariance , a 4-layer pyramid is gener- ated from the original image. Aiming to implement ORB al gorithm on hardware efficiently , a hardware-fri endly , rotationally symmet- ric BRIEF descriptor pattern is prop osed in this work and illustrate d in Sect ion 2.2. Feature Mat ching: In feature matching, each feature detected in the current frame is matched with a 3D map point in t he global map according to the distance between their BRIEF descriptors. BRIEF descriptors are binar y str ings, their distances are d escribed by Ham- ming d istances. Pose Estimation: W e apply PnP (Perspective-n-Poin ts) metho d to the matche d feature pairs to estimate the translation and the rotation of the camera. RANSA C (Random Sample Consensus) is used to eliminate the mismatches. Pose Optimization: In t his fu nction, camera p o se estimated b y PnP is optimized by minimizing the reprojection error of the ob- served map p oints. Assuming that the pixel co ordinates of the fea- tures in t he current frame are ( c 1 , c 2 , . . ., c n ) , the po sitions of the matched map p oints are ( д 1 , д 2 , . . ., д n ) , the p ose of the camera is p , and h ( д i , p ) refers to the pixel co ordinate of д i when it is projecte d to the current frame. The reprojection error E can b e d efined as the following formul a: E = n Õ i = 1 k c i − h ( д i , p ) k 2 (1) Lev enberg-Marquardt method [7] is applie d iteratively to minimize E while adjusting the camera p ose p . Map Updat ing: Map upd ating is only executed in key frames. Key frames are a set of frames where the translation or rotat io n of the c amera is larger than a threshold. When a key frame is dete cted, the 3 D map p oints in the key frame are added to the global map, and the map p oints t hat have not be en matche d fo r a lo ng p eriod of time are d eleted from the global map to prev ent it from b ecoming too large. Figure 2: Pat tern of RS-BRIEF (left) and BRIEF ( r ight) . 2.2 Rotationally Symmetric BRIEF T o compute the BRIEF descriptor of a feature, 2 sets of locat ions in the neighborhoo d around the feature, L S ( S 1 , S 2 , . . ., S 256 ) and L D ( D 1 , D 2 , . . ., D 256 ) , are introduced. In ORB algorithm, to make the feature in- variant to rotation, L S and L D are rotat e d according to the feature ’s orientation and denoted as L S R ( S R 1 , S R 2 , . . ., S R 256 ) and L D R ( D R 1 , D R 2 , . . ., D R 256 ) . The descriptor T ( B 1 , B 2 , . . ., B 256 ) is a 25 6 bit s binary string. B i is 1 if I ( S R i ) > I ( D R i ) , else it is 0 , where I ( S R i ) and I ( D R i ) are the p ix el intensities on lo cat ion S R i and D R i . Originally , L S and L D are randomly selected in the neighbor- hoo d according to Gaussian distribut ion. A nd eve ry l ocation after rotation needs to b e calcu lated using the following formul a: x ′ = x · c os θ − y · s i nθ y ′ = y · c os θ + x · s i nθ (2) where ( x , y ) refers to the initial lo cation and ( x ′ , y ′ ) refers to t he lo- cation after rotat ion. Since 512 lo cations are required to be rotated in order to compu te the descriptor of each feature, t he rotat ion pro- cedure is quite comput e-intens ive . T o reduce the compu t ation cost of rotation procedure, a po pular approach is to pre-compute t he rotated BRIEF patterns [8] instead of computing them directly each time. In this approach, t he ori- entation of features is discretized into 30 different values, i.e., 12 degrees, 24 degrees, 36 degrees, etc. Then 30 BRIEF patterns after rotation are pre-compute d and built as a lo okup t able. The lookup table is utilized to obtain the descriptors when necessary so that the co mputation cost could be reduced significantly . One drawback of the above approach is the degradation in accu- racy . Because t he orientation of features is discretized, there will b e a deviation from t he true valu e which is up to 6 degrees (half of 1 2 degrees). Howev er , co nsidering that the test locations are select ed from a circular patch with a radius of 15 pixels, the maximum error of a test lo cation is ab out 1 pixel on the smo othened image. Hence, the influence on the accuracy is al mo st negligible. Although the pre-computing approach cou l d reduce the compu- tation cost significan tly in algor it hm level, it is still difficult t o im- plement them on hardware platforms directly . For FPGA hardware implementations, all the 30 BRIEF patterns are required to be pre- computed and stored as a lo okup table, which will introduce con- siderable amount of extra resources so that it st ill coul d not satisfy the req u ired energy efficiency . In order to make descriptor co mputing more hardware-friendly , we put for ward a special way to select the t est locations and pro- posed a 32-fold rotationally symmetric BRIEF pat t ern (RS-BRIEF). The proce d ure t o generate RS-BRIEF pattern is as follows. First of 2 all, it select s 2 sets of l ocations, L S 1 ( S 1 , S 2 , . . ., S 8 ) and L D 1 ( D 1 , D 2 , . . ., D 8 ) , in the neighborhoo d around t he feature according to Gaussian dis- tribution. Each of the 2 sets contains 8 l o cations. Then, it rotates L S 1 and L D 1 by increments o f eve ry 11.25 degrees, i.e., 11.25, 2 2.5, ..., 348.75, to gene rate L S 2 , L S 3 , .. ., L S 32 and L D 2 , L D 3 , . . ., L D 32 . The 2 sets, L ′ S ( L S 1 ∪ L S 2 ∪ . . . ∪ L S 32 ) and L ′ D ( L D 1 ∪ L D 2 ∪ . . . ∪ L D 32 ) , are the final test lo cations. The RS-BRIEF patt ern is visualized and compared with the original BRIEF p attern in Figure 2. In summar y , t he rotationally symmetric pattern (RS-BRIEF) is generated by rotating the two sets o f se eded lo cations, L S 1 and L D 1 . T o calcul ate descriptors with RS-BRIEF pattern, the operations of rotating test l o cations can be reduced to changing t he order of these locations or shifting the generated descriptor . And co nsequently it could be much mo re hardware friendly than original BRIEF descrip- tors by dramatically redu cing the computat ion without introducing extra memory footprint. 3 eSLAM ARCHI TECT URE ARM Processor BRIEF Matcher Instruction Data Image Resizing ORB Extractor SDRAM Figure 3: O vera ll architecture of eSLAM . The ove rall architecture of the prop osed ORB-based visual SLAM accelerator , eSLAM , is shown in Figure 3. It is partially accelerated on p rogrammable logic of FPGA and hosted b y an ARM processor . The ORB Ex tractor and t he BRIEF Matcher are implemented to ac- celerate feature extraction and matching, which acco unt for over 90% of the runtime on general computing p latforms. And the Im- age R esizing mo dule is adopte d to generate image pyrami ds layer by layer for the ORB Extractor. When the ORB Ext ractor is process- ing one layer , the Image Resizing mo dule applies nearest neighbor downsampling on the same layer to generate the next layer u ntil the w ho le image pyramid is processed. The ARM processor p er- forms p ose estimation, p ose optimization as well as map up dating. 3.1 ORB Extractor The ORB Extr actor aims to extract ORB features from images. It reads data from SDRAM via A XI bus, and compu tes the ORB fea- tures with a lo cal cache. After feature extraction is finished, it sends the result back t o SDRAM and the descripto r s of the features to t he BRIEF Matcher . The original workflow of ORB feature extraction could b e summarize d as follows: (1) Dete cting keypoints from the input image . Assuming t hat M key points are detected . (2) Filtering the keypoints. After filtering, only the N key points with the b est H ar r is scores are kept, where N < M . Image Cache FAST Detection Image Smoother NMS BRIEF Computing AXI Interface Heap Orientation Computing BRIEF Rotator Smoothened Image Cache Score Cache To BRIEF Matcher Figure 4: Architecture of the ORB Extract or. (3) Computing descriptors for the remained N key points. Obviously there are two major problems when impl ementing the o riginal workflow on hardware plat forms. Firstly , t he Detecting and Filtering pro cedures could be executed in parallel while the de- scriptors Compu ting p ro cedure has to be idled until the Filtering is finished. Furthermore, it requires amount of on-chip cache to store the intermediate data w hen Computing the descriptors. In order to improv e the compu tation throughput and reduce the memory con- sumption, the workflow of ORB feature extracting is res chedule d as a streaming manner as fol lows: (1) Dete cting keypoints from the input image. Assumin g t hat M key points are detected . (2) Computing descriptors for the dete cted M keypoints. (3) Filtering and reserving N features with t he best Harr is scores. After rescheduling, the descriptors Computing p ro cedure is ex- ecuted before Filtering procedu re so that t hey co u ld run simult a- neously and be pipelined for the streamin g keypoints. Compared with the original workflow , there are M − N extra keypoints calcu- lated which will introduce some overhe ads but the latency has b e en optimized significantly due to the eliminated idle states. M oreove r , the requ ired on-chip cache is also reduce d dramatically acco rding to t he streaming processing manner . The detaile d architecture of the ORB Ext ractor is shown in Fig- ure 4. It is co nnected to AXI Interface and includes a F AST Detec- tion modul e, a Image Smoother , an NMS (non-maximum su p pres- sion) mo dule, a BRIEF Computing module, an Orientation Comp ut- ing mo dule, a BRIEF Rotat or , a Heap and Caches (Image Cache, Score Cache and Smoo thened Image Cache). The details of these modul es are demonstrate d as follows: AXI Interface: The AXI Interface support s accessing SDRAM via AXI bus. The input image is read from SDRAM via AXI bus and stored in Image Cache while the compu tation results sto red in the Heap are written b ack to SDRAM. F AST Dete ction: T he F AST Detection modul e takes a 7 × 7 pix- els p at ch from the Image Cache as input. It dete cts F AST keypoint on t his pixels p at ch and co mp utes H arris co rner score for each key point. If a F AST keypoint is detecte d, the corresponding Har- ris score is written into Score Cache. 3 Image Smo other: This module appl ies Gaussian blur op erations on the 7 × 7 pixels patch of the original image for smoot hing. T hen the smo othened image is utilized for calculating descriptor s and orientations of features. NMS: The NMS mo dule applies non-maximum sup pression on the results of the F AST Detection modu le. It removes F AST key- points that are to o cl ose to each other , and o nly reserves the one with maximum Harr is score in any 3 × 3 pixels patch. Orientation Computing: T his modu le determines the or ienta- tion o f each feature. The orientation is defined as the vector from the center of the feature to the mass center of the circular patch. The p osition ( u , v ) o f the mass center is defined as: u = Í ( x , y ) ∈ C ( I ( x , y ) · x ) Í ( x , y ) ∈ C I ( x , y ) v = Í ( x , y ) ∈ C ( I ( x , y ) · y ) Í ( x , y ) ∈ C I ( x , y ) (3) where C refe rs to the circular patch and I ( x , y ) refe rs to the intensity of the pixel located at ( x , y ) . The Orientation Computing modu le builds a lo okup tabl e to determine the orientation from v / u and the signs of u and v . Since the pattern of t he test lo cations is 32- fold rotationally symmetric, the feature orientations are discretized and represented by an integral label r anged from 0 to 3 1, where 0 repre sents 0 degree, 1 repre sents 11.25 degrees, 2 represen ts 22.5 degrees, etc. BRIEF C om puting: The BRIEF Computing module takes circu- lar patches of smo othened pixels to calculate descriptors for fea- tures. T he test locations it u ses to generate descriptors follow the rotationally symmetric pattern we prop o sed. BRIEF Rotator: The BRIEF Rot ator shifts t he descriptor accord- ing to the feature orientation, which provi des the same res ults as rotating the t est lo cat ions of RS-BRIEF. Assuming that the feature orientation is n , the BRIEF Ro tator moves the 8 × n b its from the beginning of the descriptor to the end. Heap: T he H eap is created to store and filter the descriptors, co- ordinates and Harris scores of features. T o filter out some of the superfluous features, a max-heap structure is utilized to guarantee that only the 1024 features with the best Harris scores are reserved. Once the feature extraction is finished and sto red in the heap, t he descriptors and coo rdinates are sent to SDRAM through AXI Inter- face, and the descriptors are also delivered to the BRIEF Matcher . >ŝŶĞ ϭ ^ƚĂƚĞϭ >ŝŶĞ Ϯ >ŝŶĞ ϯ ^ƚĂƚĞϮ ^ƚĂƚĞϯ ϯ ϰ ϱ /ŶƉƵƚKƌĚĞƌ >ŝŶĞ ϰ >ŝŶĞ ϯ >ŝŶĞ Ϯ >ŝŶĞ ϰ >ŝŶĞ ϱ >ŝŶĞ ϯ Figure 5: I/O mechanism of Ima ge Cache. Line A, B and C refers to the 3 cache lines of Image Cache. Each square rep- resents 8 columns of pixe ls. Cache: There are 3 caches in ORB Extr actor including the Im- age Cache storing pix els of the input image, t he Score Cache stor- ing t he Harr is scores of the keypoints, and the Smoo thened Image Cache st oring the smoothened image. These caches are designed by a manner of “ping-pong me chanism” so that the streaming data could be processed simultaneou sly . The Image Cache is taken as an example to explain the data I/O mechanism. The Image Cache consists of 3 cache lines, each of which stores 8 columns of image pixels. As shown in Figure 5, the 3 cache l ines receive input data by turns. T he data I/O o f t he cache lines is controlled by a finite-state machine (FSM). The FSM is initialized by pre-storing 16 columns of pixels in cache line A and B. For each FSM state, one cache line receive s input data while t he ot her two send the data for outp ut. 3.2 BRIEF Matcher ĞƐĐƌŝƉƚŽƌ ĂĐŚĞ ŝƐƚĂŶĐĞ ŽŵƉƵƚŝŶŐ y//ŶƚĞƌĨĂĐĞ ŽŵƉĂƌĂƚŽƌ ZĞƐƵůƚ ĂĐŚĞ &ƌŽŵKZdžƚƌĂĐƚŽƌ Figure 6: Architecture of the BRIEF Matcher . In the BREIF Matcher mo dule, the features extracted from the current frame is compared with t he map points of the global map. The features descriptors are obtained from the ORB E x tractor , and the descript o rs of global map are from SDRAM via AXI bus. The matching results are sent back to SDRAM at last. The architecture of the BRIEF Matcher is shown in Figure 6. It is connected to AXI interface and includes a Descriptor Cache, a Dis- tance Computing mo dule, a Comparator and a Result Cache. The matching proce dure starts following the ORB extraction. Assum- ing 2 sets of descriptors D A ( DS 1 , DS 2 , . . ., D S n ) and D B ( D D 1 , D D 2 , . . ., D D m ) have b een pre-stored in Descriptor Cache, where D A is the descripto rs ob t ained from current frame, and D B is the descrip- tors of the map p oints in t he global map. For each descriptor D S i in D A , the Distance Computing mo dule c al c u lates the Hamming dis- tances b etween D S i and each descriptor D D j in D B . With the cal- culated H amming distances H D ( H i 1 , H i 2 , . . ., H i m ) , the Comparator searches through H D and finds t he minimum value to determine the mat c hing result and st ores them into t he Result Cache. 3.3 Parallelizing Me chanism Since eSLAM is a heterogeneous system with the ARM pro cessor as the host controller and FPGA as the acceleration mo dules, the paral- lelizing me chanism is critical t o improve the comp utation t hrough- put. The utilized paral l elized pipeline is shown in Figure 7. For normal frames pro cessing, while the ARM pro cessor is p erform- ing p ose estimation and po se opt imization, the ORB E xtractor and BRIEF Matcher are fired up t o do feature extraction and feature matching for the next frame. Howev er , it is differen t to process key frames because map updat ing is executed on the ARM processor after p ose estimation and po se op t imization. The ORB E xtractor performs feature extraction on FPGA in paral lel with the ARM pro- cessor , but t he BRIEF Mat cher would not start to work until map updating is finished. 4 & &D & &D W WK E ƚŚ ĨƌĂŵĞ;ŶŽƌŵĂůĨƌĂŵĞͿ ;EнϭͿ ƚŚ ĨƌĂŵĞ W WK ZD &W' & &D & &D W WK E ƚŚ ĨƌĂŵĞ;ŬĞLJĨƌĂŵĞͿ ;EнϭͿ ƚŚ ĨƌĂŵĞ W WK ZD &W' Dh WŝƉĞůŝŶĞ Figure 7: Para llelize d pipe line of normal frame (uppe r) and key frame ( low er), where FE refers to feature extraction, FM refers t o feature matching, PE refers t o pose estima tion, PO refers to pose optimization and MU refers to map u pdating. With the parallelizing me chanism ab ov e, the seve ral stages co u ld be p erformed efficiently in pip eline. For normal frames, feature ex- traction and matching runs in parallel with p ose estimation and op- timization. And for key frames, feature extraction r u ns in parallel with pose estimation and op timization. These parallel processing manners cou ld improv e the computing throughout significantly . 4 EXPERIMENT AL RESULTS 4.1 Experimental Setup Hardware Implementat ion: The proposed eSLAM system is im- plemented on Xilinx Zynq X CZ7045 SoC [ 12], which integrates an ARM Cortex- A9 processor and FPGA res ources. The clock fre- quency of the ARM processor is 767 M H z , and the clock of acceler- ating mo dules is 100 M H z . The resource utilization o f the prop o sed system is shown in T able 1. Since only ab out 1/4 resources are ut i- lized on XCZ7045, it is possible to protot ype them o nto SoCs w it h less resources and lower price, such as XCZ7030/X CZ7020 . T able 1: The F P G A resources u tilization of eSLAM . LU T FF DSP BRAM Utilization 56954 (26.0%) 67809 (15.5%) 111 (12.3%) 78 (14.3%) Dataset: The propose d eSLAM is evaluated o n T UM dataset [10]. It contains RGB images along with depth information and is widely used in visual SLAM co mmunity . T he image resolution is 640 × 480. Five differen t sequences in t he dataset, f r 1 / xyz , f r 1 / d e s k , f r 1 / r o o m , f r 2 / x yz and f r 2 / r p y are used for evaluation. Each sequence con- tains a ground tr uth trajector y that is obtained by a high-accuracy motion-capture system. 4.2 Acc uracy Analysis The accuracy of the visual SLAM system is measured by trajec- tory error which means the differe nce b etween the ground tru th trajector y and the estimated trajecto ry . As shown in Figure 8, the average tr ajectory error is compared with the original ORB based 濃 濅 濇 濉 濋 濄濃 濄濅 ĨƌϭdžLJnj ĨƌϮdžLJnj ĨƌϭĚĞƐŬ ĨƌϭƌŽŽŵ ĨƌϮƌƉLJ ǀĞƌĂŐĞdƌĂũĞĐƚŽƌLJƌƌŽƌ;ĐŵͿ Z^ͲZ/& ŽƌŝŐŝŶĂůKZ ǀ ĞƌĂŐĞƌƌŽƌ ϰϯ Đ ŵ ϰϭ ϲ Đŵ Figure 8: A verage tra je ctory error of the SLAM implemen- tation with RS-BRIEF compared with the original ORB on T UM datase t. Figure 9: E stimate d traje ctory of the RS-BRIEF de scriptor and original ORB descriptor based SLAM im plementations, compared with the ground truth t rajectory on f r 1 / d e s k . SLAM implementation on t he five se quences from T UM dataset. For f r 1 / xyz , f r 1 / r oom , and f r 2 / xy z sequence, the implementa- tion with original ORB has a b ett er accuracy than with RS-BRIEF descriptor . Howev er , the implementation wit h RS-BRIEF d escriptor could have a better accuracy than with original ORB when evalu- ated on f r 1 / d e s k and f r 2 / r py sequence. Among the five seq uences, the total average error o f RS-BRIEF base d implementation is abo ut 4 . 3 cm , and the original ORB based implementation is about 4 . 16 cm , which indicates that the accuracy of R S-BRIEF descripto r is compa- rable to the original descriptor . Meanwhile , the traject ories estimate d by the RS-BRIEF based im- plementation and the original ORB base d implementation are also compared with the ground truth tr ajectory on f r 1 / d e s k sequence and visualize d in Figure 9. Aiming to displ ay the traject o ries clearly , only a piece o f them are select e d as shown in Figure 9. 4.3 Performance Evaluation The perfor mance of t he propose d eSLAM system is co mpared with the software implementations on the integrated ARM Cortex- A 9 processor of X CZ7045 SoC and an Intel i7-4700 mq processor [9] . 5 T able 2: Detaile d runt im e breakdown of eSLAM co mpared with software implementations on ARM processor and Intel i7 CP U. eSLAM ARM Intel i7 Feature E xtraction 9.1 ms 291.6 m s 32.5 m s Feature M atching 4.0 ms 246.2 ms 19.7 ms Pose Estimation 9.2 ms 0.9 ms Pose Optimization 8.7 ms 0.5 ms Map Updating 9.9 ms 1.2 ms The runtime comparison is shown in T able 2. Accelerated by ORB Extractor and BRIEF Matcher , the latency of feature extraction and matching pro cedure in eSLAM is reduced to 9 . 1 ms and 4 ms , respec- tively . Comp ared with Intel CP U and A R M, eSLAM could achiev e 3 . 6 × and 32 × speed up in feature extraction, 4 . 9 × and 61 . 6 × spee dup in feature matching. T able 3 compares the average runtime p er frame, t he frame rate, the energy consumed p er frame, the p ower consumption of eSLAM with the ARM pro cessor and the Intel CP U. For normal frames, eSLAM p erforms feature extraction (FE) and mat ching (FM) simulta- neously with pose estimation (PE) and optimization (PO ). The av- erage runtime is the sum of p ro cessing time of PE and PO , 17 . 9 ms . For ke y frames, FE is p erformed simultaneously with PE. eSLAM ’s average runtime time is 31 . 8 ms , which is the su m of processing time o f FM, PE, PO and MU. Comp ared with the ARM processor , eSLAM achieve s abo ut 17 . 8 × sp eedup w hen processing key frames and 31 × sp eedu p for normal frames. Compared with the Intel i7 processor , it could achieve 1 . 7 × to 3 × spe edups. In terms of energ y consumption, the proposed eSLAM also shows great advantage compared with the ARM and Intel CP U. Although the power consumpt io n of eSLAM is increased by ab out 23% co m- pared with the ARM p rocessor due to the additional FPGA accel- erating modul es, t he energ y consumed p er frame is still reduce d by 14 × to 25 × depending on the key frame rate. Compared w it h the Intel i7 processor , the energy consumption is reduced by 41 × to 7 1 × . 4.4 Discussions As shown in T able 3, t he key frame r ate of eSLAM is 31 . 45 f p s , and the normal frame rat e is 55 . 87 f ps , which is much less than 171 f p s which is achieved by Navion [11]. T his gap is mainly be cause of t he adopt ed different algorithms. Navion ado pts the optical-flow method while only keypoints are detect ed bu t descriptors calcula- tion and feature matching are not required. Howe ver , the adopted feature-based ap p roach in eSLAM is much more robust in many sce- narios where opt ical-flow metho ds may fail. Because the optical- flow metho ds are only available with two basic assumptions: con- stant illumination and small motions/displacements existed [5 ]. Compared w it h the ORB extractor implemented o n FPGA in [ 4], the ORB extractor in eSLAM has deployed hardware-friendly opt i- mization, such as RS-BRIEF and workflow rescheduling. Hence, the latency of feature extraction in eSLAM is approximately 3 9% less than the latency of [4], even if 48% more pixels are processed in eSLAM b ecause of the involved extra two l aye rs in the image pyra- mid. T able 3: F ra me ra te and ene rgy effi ciency comparison re- sults, where “N-frame” repr esents the normal frame, and “K- frame” represents the key frame. ARM Intel i7 eSLAM Runtime N-frame 55 5.7 ms 53.6 ms 17.9 ms K-frame 565.6 m s 54.8 ms 31.8 ms Frame Rate N-frame 1.8 f p s 18.66 f ps 55.87 f p s K-frame 1.77 f p s 18.25 f ps 31 .45 f p s Powe r 1.574 W 47 W 1.936 W Energy per Frame N-frame 8 75 m J 2519 m J 35 m J K-frame 890 m J 25 75 m J 62 m J 5 CONCLUSIONS In this paper , a heterogeneous ORB-based visual SLAM system, eSLAM , is p rop osed for energy-efficient and real-time applications and eval- uated on Zynq platforms. The ORB algorithm is first reformulated as a rotationally symmetric pattern for hardware-frien dly impl e- mentation. Meanwhile, the most time-consuming stages, i.e., fea- ture extraction and matching, are accelerate d on FPGA to reduce the latency significantly . The eSLAM is also designed as a pip elined manner to furt her improv e the throughput and reduce the mem- ory fo otprint. The evaluation results on T UM dat aset have shown eSLAM could achieve 1 . 7 × to 3 × spee dup in frame rate, and 41 × to 71 × improvemen t in energy efficiency when co mpared with the In- tel i7 CP U . Compared with the ARM processor , eSLAM could achieve 17 . 8 × to 31 × sp eedup in frame rate, and 14 × to 25 × improveme nt in energy efficiency . REFERENCES [1] Michael Calonder , Vincent Lepetit, Christoph Strecha, a nd Pascal Fua. 2010. BRIEF: binar y r obust i ndepend ent elementary features . In Proceedings of Euro- pean Conference on Computer V ision (ECCV) . 778–792. [2] J. C ong, B. Gr igorian, G. Reinman, a nd M. Vitanza. 2011. Accelerating vision and navigation applications on a cu stomizable platform. In Proc eedings of IEEE Inter- national Conference on Appl ication-specific Systems, Architectures and Processors (ASAP) . 25–32. [3] Hugh Durr ant- Whyte and Tim Ba i ley . 2006. Simultaneous localization and map- ping: part I. IEEE rob otics & automation m agazine 13, 2 (2006), 99–110. [4] W eikang Fang, Y anjun Zhang, Bo Yu, and Shaoshan Liu. 2017. FPGA-based ORB Feature Extraction for Real-Time Vis ual SLAM. In Proceedings of International Conference on Field Program mable T echnology ( FPT) . 275–278. [5] Davi d F leet and Yair W eiss. 2006. Optical flow estimation. In Handbook of math- ematical models in c omputer vision . Spr i nger , 237–257. [6] Mengyuan Gu, Kaiyuan Guo, W enqiang W a ng, Yu W a ng, and Huazhong Y a ng. 2015. An FPGA-based real-time si m ultaneous localization and ma pping sys- tem. In Proceedings of International Conference on Field Progr ammable Te chnology (FPT) . 200–203. [7] Jorge J. Moré. 1978. The Lev enb erg-Mar quardt algorithm: Implementation and theory . Lecture Notes in Mathematics 630 (1978), 105–116. [8] Ethan Rublee, Vincent Rab aud, Kurt Konol ige, and Gary R. Bradski. 2012. ORB: an efficient alternative to SIFT or SURF. In Proc eedings of International Conference on Computer Vision (ICCV) . 2564–2571. [9] Intel C hip’s Specifica tions. 2017. Intel Core i7- 4700M Q Processor , 22nm. (2017). https://ark.intel.com/content/www/us/en/ark/ products/75117/intel-core- i7-4700mq-processor-6m- cache-up-to-3-40-ghz.html. [10] Jürgen Sturm, Nikolas Engelhard, Felix Endres, W olfram Burgard, and Daniel Cremers. 2012. A benchmar k for the evaluation of RGB-D SLAM systems. In IEEE/RSJ International Conference on Intelligent Rob ots and Systems . 573–580. [11] Amr Suleiman, Zhengdong Zhang, Luca Ca rlone, Sertac Karaman, a nd Vivienne Sze. 2019. Na vion: A 2mW Fully Integrated Real-Time Visual-Inertial Odometry Accelerator for A utonomous N avigation of Nano Dr ones. IEEE Journal of Solid- State Circuits ( JSSC) (2019), 1–14. [12] Xilinx. 2018. Zynq-7000 SoC. (2018). https://www.xil inx.com/products/silicon- devices/soc/zynq-7000.html. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment