Adaptive Resource Management for a Virtualized Computing Platform within Edge Computing
In virtualized computing platforms, energy consumption is related to the computing-plus-communication processes. However, most of the proposed energy consumption models and energy saving solutions found in literature consider only the active Virtual …
Authors: Thembelihle Dlamini, Angel Fern, ez Gamb{i}n
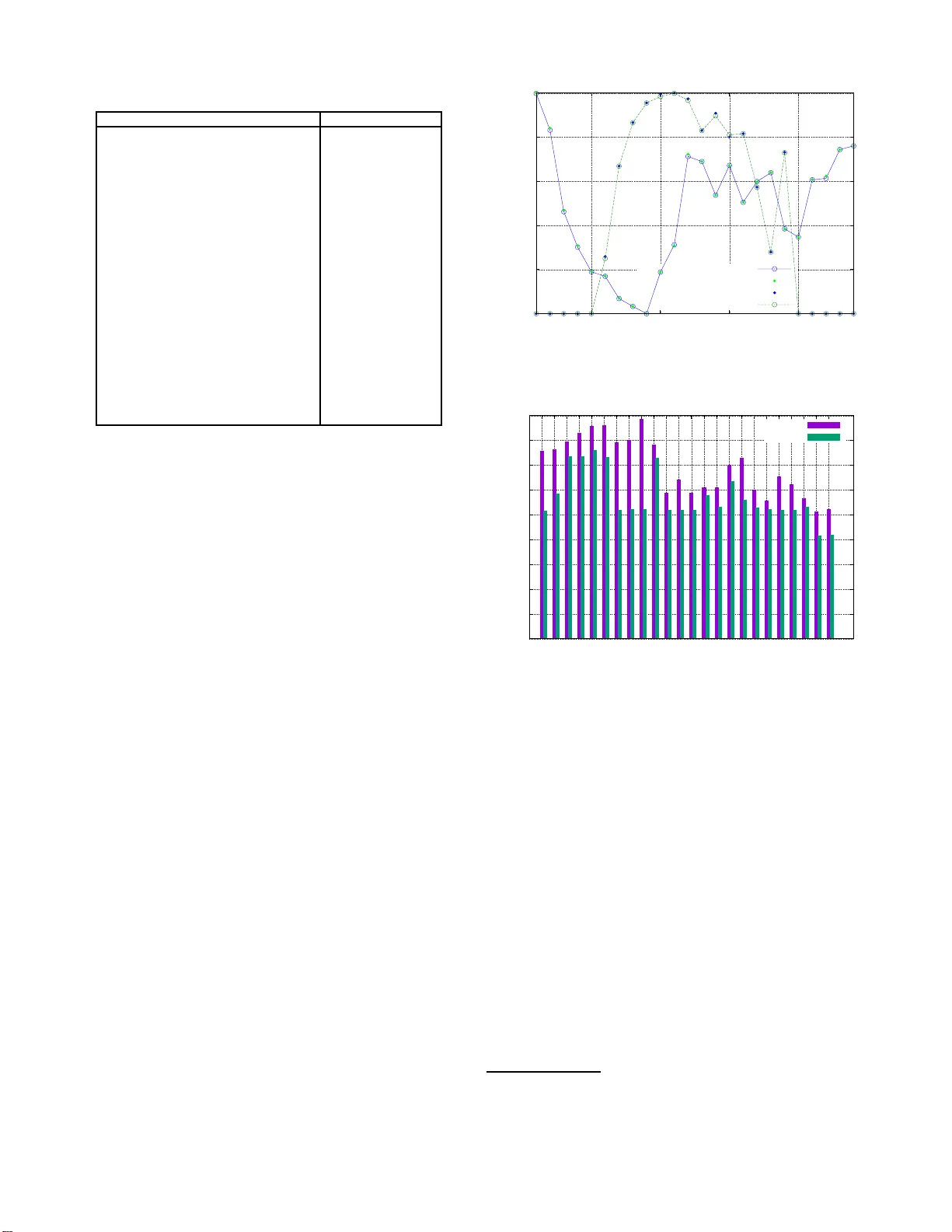
Adapti v e Resource Management for a V irtualiz ed Computing Platform within Edge Compu ting Thembelihle Dlamini ∗ † , ´ Angel Fern ´ andez Gamb ´ ın ∗ ∗ Departmen t of Info rmation Engineer ing, University of Padov a, Padova, Italy † Athonet, Bolzano V icentino, V icenza, Italy { dlamini, afgambin } @dei.unipd.it Abstract —In virtualized computing platf orms, ener gy con- sumption is related to the computing-plus-co mmunication pro- cesses. Ho wever , most of the proposed energy consumpt ion mod- els and energy saving solutions f ound in lit erature consider only the activ e V irtual Machines (VMs), th us th e over all operational energy expenditure is usually related to solely the computation process. T o address this shortcoming, in th is paper we consider a computing-plus-communication en er gy model, wi thin the Multi- access Edge Computing (MEC) paradigm, and then put fo rward a combination of a traffic engineering- and MEC Location Service-based online server management algorithm with Ener gy Harvesting (EH) capabilities, called A utomated Resource Con- troller for Energy-awar e Serv er (ARCES) , f or autoscaling and reconfiguring th e computing-p lus-communication resour ces. The main goal is to minimize the overa ll energy consumption, under hard per -task delay constraints (i.e., Qu ali t y of Service (QoS)). ARCES join tly performs (i) a short-term ser ver demand and harv ested solar energy fo recasting, (ii) VM soft-scaling, workload and processing rate allocation and lastly , (iii) switch ing on/off of transmission drivers (i.e., fast tunable lasers) coupled with the location-aware traffic schedulin g . Our nu merica l results rev eal that ARCE S achieves on a verage energy savings of 69 %, and an energy consumption ranging from 31 %- 45 %and from 21 %- 25 % at different values of per -VM re configuration cost, with respect to the case where no energy manag ement is applied. Index T erms —Multi -acce ss ed ge computing, energy harvest- ing, soft-scaling, adaptive contro l. I . I N T RO D U C T I O N The data gr o wth gener a ted by p e rv asi ve mobile d e vices and the Internet of Things, couple with the dem a n d for ultr a-lo w latency , requires high computation r esources which are not av a ilab le at the end- user d e v ice. Undou btedly , offloading to a powerful compu tational resou rce-enriched server located closer to mob ile users is an ideal so lution. Th us, Mu lti-access Edge Computing (MEC [1 ]) has recently emerged to en- able low-latency and location-aware d ata processing at the network edge , i.e., in c lo se prox imity to mob ile devices, sensors, actuators and connected things. Despite th e potential presented by M E C, th e computing resources (i.e., VMs) plus commun ication w ith in the MEC server (nod e) raises concern s related to energy consum ption, in the effort to build greener networks an d reduce carbon emissions into the atmo sphere. Nonetheless, with th e integration of EH into the ed ge (or computin g) system [2], r esulting into an EH- p o wered MEC (EH-MEC) system, the carbon footp r int a n d the depend ence on the power gr id can be m inimized. The en ergy drained in the co mputing p latform due to the computin g-plus-commu nication pro c e ss es is associated with (i) the running VMs [3][4] and (ii) the comm unication within the server’ s virtual network [5] ( see Fig. 3 .5 in this reference) . It is observed in th e literature that most of the existing Energy Saving (E S ) studies h a ve inv olved autoscalin g [6] [7 ][8][9][10] (scaling u p/down the nu mber of c o mputing nod e s/s ervers or VMs), VM migration [11] ( movement of a VM fro m one host to anoth er) and soft re so urce scaling [1 2] (shor tening the access time to ph y sical resou rces), all hereby referr ed to as VM soft-sca ling , i.e. , the r e duction of comp uting resources per time instance. Hence, the p r oposed energy mode ls (see [1 3] for a summary of the p roposed models) and the overall op erational expenditure of the comp uting no de is usually r elated to the computatio n process (i.e., the runn ing VMs), overlooking the commun ication processes within the server . Regarding energy consum ption related to commu nication within a c o mputing node, it is shown in [14][15] that having the lea st numb er of data tr a nsmission driv ers ( fast tunable lasers) can yield significant amoun t of ESs. It is worth ob- serving that bo th works, [ 14 ][15], are n ot along the direction of ME C, but they pro pose th e tuning of the transmission drivers as o ne of the ES strategies with in the Mobile Network (MN) infr a structure. Th u s, ESs within the MEC server can be join tly achieved by launch ing a n op timal number of VMs for compu tin g, and transmission drivers cou pled with th e location-aware traffic routing for real-time data transfer . A. Motivation The virtualized MEC n ode is equipp ed with h igher com- putational a n d storage resources co m pared to the en d-users devices, in or der to h andle the c omputation work load being generated at th e network edge. Howev er , while MEC tries to meet th e co mputational d emand and the gu arantee o f low-latency , th e issue o f energy consum p tion is still a chal- lenge within th e virtu alized co mputing no d e [3][4]. T o addr ess this challen ge: (i) it is expe c ted that the Network Func tio n V irtualization (NFV) framew ork c an exploit the benefits of virtualization tech nologies to significantly reduce the energy consump tion in MN infrastru cture; (ii) the curre nt trends in battery and so lar modu le costs show an expected redu c tio n. This two points motivate the integration o f MEC and EH systems tow ards green computing [2][16]. 978-1-7281-2 294-6/19/$ 31.00 c 2019 IEEE B. Related work For several yea r s, great e ffort h as b een dev oted to study energy savings in co mputing environmen ts with the aim of minimizing the energy con sumption. Procedur e s for the d y- namic on/off switch ing of servers have been p r oposed as a way of minimiz in g energy co nsumption in computing p latforms. In [6], computing resources a r e provisioned d epending on the expected server workloads via a rein f orcement learn ing-based resource managemen t algorithm, which learn s the optimal po l- icy f or d ynamic workload of floading and servers au toscaling. Our pr e v ious works in [7 ] and [17], fo cus on th e provision o f computin g r e so urces ( VMs) based on a Limited Loo k ahead Control (LLC) policy and the n etwork impact (the use o f traffic load as a perform ance metric [1 8]), after f o recasting the future workloa d s a nd harvested energy . A sing le Base Station (BS) optimiza tio n case is considered for an off-grid site in [7], and a mu ltiple BS optimization case, each BS site p owered by h y brid e nergy sources, is studied in [17] whe r e the edge managem ent proced ures are enab led by an ed ge controller . This work differs fr om our previous works as the MEC server is placed in prox im ity to a BS cluster, an d not on e co -located for each BS . Moreover, here we focus on the integration of commun ication-related energy consum ption b y co nsidering the tuning of the transmission d ri vers, which is a novel conce p t within the ME C p aradigm. In [11], Central Proce ssing Unit (CPU) utilization thresholds are used to ide ntify over-utilized servers. VMs are migrated to servers that will accep t them without in c urring in high energy co sts. Subsequ ently , th e idle servers are tu rned-off . Energy m anagement is also of interest in da ta c e nters using virtua liza tion technolo gies. Along the same lines of VM soft- scalin g, in [8] a tra ffic eng ineering-based adap ti ve approa c h is presented with the aim o f minimizing energy consump tion induced by compu ting, commu nication and re- configur ation costs of virtualized clouds. An iterati ve m ethod is used to obtain ESs with in a server that tran smits wirelessly to clients. Th en, in [ 9] the compu ting-plus-comm unication is also con sid e red towards a goal of saving energy thr ough an adap ti ve transmission rate for a Fog node. An auto mated server provision ing alg orithm that aims to meet workload demand wh ile minimizing en ergy con sumption in data centers is presented in [10]. Here, energy-aware server pr ovisioning is perfo r med by taking into accou nt trade- of fs between cost, perfor mance, and reliab ility . Lastly , a soft r esour ce scaling mechanism is proposed in [12] where th e schedu ler shortens the maxim um resou rce usage time f or e a ch VM, i.e., the time slice allocated for u sing the under lying physical r esources, in order to compen sate f o r the low en ergy sa vings achieved with Dynamic V oltage and Freq uency Scaling (D VFS). C. Objective an d Contributions The main contributions of th is work are as follows: • we co n sider the aforementione d scenario, where MEC and EH are combin e d into a single system located close to a BS clu ster, tow ards energy self-sustainability in MNs. MEC SERVER INPUT BUFFER OUTPUT BUFFER T o BSs Input traffic Admitted traffic ACR W orkloads Computation result SOLAR SW GRID EM EB N I C N I C N I C Virtual Switch VM 2 VM 1 Virtualization layer Figure 1: V irtualized computing system powered by hybrid energy sources: on-grid power and green energy . The elec- tromechan ical switch (SW) selects the appr opriate so u rce of energy . The EH-MEC sy stem is equipp ed with solar pane ls for EH and an Energy Buffer (EB) for energy storage. • W e co n sider a co mputing-plus-c o mmunication ene rgy model within th e MEC par adigm, formu lating a con- strained o p timization prob lem. Du e to the non -linear be- havior of the rate-vs-power relatio n ship, the optimization problem is non-c on vex . T o solve it, we con vexify the function by using Geometric Prog ramming (GP [19]) and then em ploying th e CVXOPT to olbox 1 and ap proxima- tions. • W e f orecast the short-term f u ture server workload and harvested en ergy , by using a Long Short-T erm Memory (LSTM) neural network [20], to enable foresighted o pti- mization. • L astly , we dev elop an online co ntroller-based algorith m called Automated Resource Controller for Energy-aware Server (ARCES) for the MEC server managem e nt based on LLC theory [21] an d energy manag ement proced ures. The m ain goal is to minimize the overall e n ergy con- sumption, u nder har d per-task de la y c onstraints (i.e., QoS), through the joint consideration of VM soft-scaling and the tunin g of tran smission d ri vers cou pled with the location-aware traf fic rou ting. T o the best of our knowl- edge, this is a novel con c ept within the MEC parad igm. ARCES considers future server workloads, onsite green stored en ergy , and target BS (based on th e Location Service (LS) [22]), and then enable ES procedu res. The pro posed op timization strategy is able to red uce the energy consumptio n un der th e guidance of the online re so urce controller and the energy management procedures. The rest o f the pap er is o rganized as follows. The system model is p resented in Section II. In Section III, w e detail the optim ization p roblem and the p r oposed L LC-based online algorithm . Simulation results are d iscussed in Section I V. Lastly , we conclud e our work in Section V. 1 M. Andersen and J. Dahl. CVXOPT : Python Softw are for Con vex Pro- gramming, 2019. [Online]. A v ailabl e: https://cvxop t.org/ I I . S Y S T E M M O D E L As a major deploymen t of MEC [1] , the co n sidered network scenario is illustrated in Fig. 1. It consists of a cache-enabled, TCP/IP o f fload-enab led ( partial compu ta tio n at the ne twork adapter), virtu alized MEC server hosting M VMs a n d it is assumed to be de p loyed at an aggr e gation po int [1][ 2], i.e., a point in proximity to a gro up of BSs intercon n ected to the MEC server f o r compu tation offloading. The MEC nod e is assumed to be equipp ed with higher comp utational and storage resources c o mpared to the end-user device. The server clients are assumed to be mo bile users moving in gro ups and they are rep resented by the Reference Point Group Mo bility Mo del (RPGM [23]) . Their cur r ent loc ations are known throug h the LS App lica tio n Programma b le Interface (API) [22], in the MEC platfor m, which is a service that suppo rts UE’ s location retriev al mech anism, and the n passing the info rmation to th e authorized a pplications with in the server . The comp uting site is empowered with EH capabilities throu gh a solar p anel a n d an EB that enables en ergy stor age. Energy supp ly from the power grid is also av ailable f o r backup. The En ergy Man ager (EM) is an entity respon sible fo r selecting the appropriate energy source and fo r mon itoring the energy le vel of the EB. The virtualized Access Contr o l Router (A CR) of Fig. 1 acts as an access gateway , r e sponsible for ro uting, an d it is lo cally h osted as an application. Moreover, we con sider a discrete-time model, wh ereby time is discretized as t = 1 , 2 , . . . , and each time slot t has a fixed duration τ . A. Server W orkloa d an d Energy Consu mption For m any MN services, the workload deman d exhibits a di- urnal behavior , thus it suffices to f orecast the short- term server workload (u sing h istorical datasets [2 ][10]) and then enable dynamic re so urce m anagement within the ser ver . In this work, anonymized real server work load traces obtained from [24] are used to emu late server workload s due to the difficulties in obtaining relev an t open source datasets containing computing requests. A trace file co nsist of the file size, session du ration, total nu mber of packets and av erage transmission rate, over one day . In our numerical r esults, we use the to tal number of packets, denoted b y L in ( t ) ([b its]), to represent the buf fered (or admitted ) com putation workload at the input buffer at time slot t ( see r ed curve in Fig. 2). In addition , we assume that the upper-boun ded input/outp ut (I/O) queu e’ s of Fig. 1 are loss-free and th e y im plement the First-In First-Out (FI FO) service d iscipline, thus L in ( t ) = L out ( t ) , where L out ( t ) is the amount of the aggr e gate com p utation result stored at the output buf fer . The total ene r gy co nsumption ([ J ]) for the virtualized c o m- puting platform is form ulated as follows, inspired by [7 ][8] and the virtualizatio n knowledge fr om [5]: θ MEC ( t ) = θ COMP ( t ) + θ COMM ( t ) , (1) where θ COMP ( t ) is the en ergy drain ed due to computation and θ COMM ( t ) due to intra-co mmunications processes in the MEC server at time slot t . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 1:00 5:00 10:00 15:00 20:00 Normalized values Time [h] Server Solar Figure 2: Example traces for server workload s from [24] and harvested solar e n ergy from [25]. Computing energy: θ COMP ( t ) = θ CPU ( t ) + θ SC ( t ) + θ TOE ( t ) , where θ CPU ( t ) is the en ergy drained due to th e runnin g VMs, w .r .t CPU utilization, and θ SC ( t ) is the energy drained due to VM switching the pro c essi ng ra tes f m ( t ) ∈ [0 , f max ] . f max [(bit/s)] is the m aximum pro cessing r ate fo r VM m . θ TOE ( t ) is the en ergy ind uced by th e TCP/IP offload on the network in terface card (NIC, e.g ., TCP/IP ch e cksum offload). In practice, the VM s ar e instantiated on top of the CPU c o res and e a ch VM processes the currently allotted task by man aging its own local virtualize d comp u ting resou rces, thus we model th e proce ssing rates to be between f 0 = 0 (represen ts ze r o spe e d of the VM, e.g., deep sleep o r shut- down) and f max . Here, we assume that real-time processing of computatio n workloads is pe r formed in par allel over the VMs interconn ected b y a power-limited and rate-adap ti ve switch e d V irtual Local Area Network (VLAN). Considering that θ CPU ( t ) is related to the number of VMs runnin g in time slot t , named M ( t ) ≤ M , and on the CPU frequen c y that is allotted to each VM, θ CPU ( t ) is obtained using th e linear relation ship between the CPU u tilizatio n contributed b y VM m , and the energy drained is, inspired by [7]: θ CPU ( t ) = P M ( t ) m =1 θ idle ,m ( t ) + θ dyn ,m ( t ) , (2) where θ idle ,m ( t ) represen ts the static en ergy drained by VM m in the idle state, and the quantity θ dyn ,m ( t ) = α m ( t )( θ max ,m ( t ) − θ idle ,m ( t )) represents the dynamic energy compon ent o f VM m , where α m ( t ) = ( f m ( t ) /f max ) 2 [21] is a lo a d depend ent factor and θ max ,m ( t ) is the maximu m energy that VM m can drain. Next, we remark that the VM switch ing cost θ SC ( t ) de- pends on th e freq u ency reconfig uration, i. e., the transition from f 1 ( t ) (current processing r ate for VM m ) to f 2 ( t ) (the next p r ocessing rate) , as a n examp le. In short, the energy cost depend s on the absolute processing rate gap, | f 2 ( t ) − f 1 ( t ) | . Thus, θ SC ( t ) is defined as [8]: θ SC ( t ) = P M ( t ) m =1 κ e ( f 2 ( t ) − f 1 ( t )) 2 , (3) where κ e is the the p er -VM reconfigur a tio n cost caused by a unit-size frequ ency switchin g . T yp ically , κ e is limited to a fe w hundr eds of mJ per (MHz) 2 . At this regard, we put f o rward th e following: at the begin- ning of time slot t , the online resou rce con troller adaptiv ely allocates the av ailable virtual resour ces and thus deter m ines the VMs demand ed, M ( t ) , the workload allotted to VM m , denoted b y λ m ( t ) , an d f m ( t ) for VM m that will yield the desired or expected p rocessing time , χ m ( t ) = λ m ( t ) /f m ( t ) . Note that L in ( t ) = P M ( t ) m =1 λ m ( t ) . Moreover , in practical app li- cation scena rios, th e maximu m per-VM comp utation lo ad to b e computed is gen erally limited up to an assigned value, named λ max . Lastly , the VM provisioning an d worklo ad allocation is discussed in Section III-B2, and f m ( t ) ∆ = λ m ( t ) / ∆ . Along the same lines of compu tation, advancemen t in TCP/IP Offload Eng ine (TOE) techn ology e nables partial computatio n in th e server’ s NIC [26], i.e., some TCP/IP processing (e . g., checksu m computation ) is offloaded to a specialized ha r dware o n the network adap ter , relieving the host CPU fro m the overhead of processing TCP/IP . Thus, θ TOE ( t ) is obtained by using the fact that it is data volume dependent and then d etermined using the workload volume received. Du e to the lack of an existing TOE energy m o del, we rely on the perfor mance measure for the Broad c om (Fibr e) 10 Gb ps NIC [26], which is considered here as an example of a TCP/IP offload-capable device. Then, θ TOE ( t ) is obtained as: θ TOE ( t ) = ζ ( t ) θ TOE idle ( t ) + θ TOE max ( t ) , (4) where θ TOE idle ( t ) > 0 is the ene r gy drained by the TOE when powered, with all links co nnected without any data transfer . This motiv ates the id ea of tun in g even the NIC so that th e energy dra in ed is always zero when ther e is no data tr ansfer . For th is, we have ζ ( t ) = (0 , 1 ) as th e NIC switching status indicator ( 1 for acti ve state and 0 for idle state). θ TOE max ( t ) = L in ( t ) η is the maximum energy draine d by the TOE. η is a fixed v alue measured in [Gbit/ J ]. Communication energy: θ COMM ( t ) = θ VLAN ( t ) + θ WC OM ( t ) , where θ VLAN ( t ) is the en ergy draine d due to th e commun ication links (to-and-fro m each VM), and θ WC OM ( t ) is the energy d rained due to the numb er of transmission (optical) drivers used for the data transfe r to target BS(s). The co mmunication energy with in the VL AN is obtaine d by using the Shannon- Ha rtle y expon ential analysis. Here , we assume tha t each VM m co mmunicates with the resource controller thr ough a d edicated reliable link , that o perates at the transmission rate of r m ( t ) [(bit/s)]. Thus, the en e r gy needed for sustaining the two-way m th link is de fined as, inspired by [16]: θ VLAN ( t ) = 2 P M ( t ) m =1 P m ( r m ( t ))( λ m ( t ) /r m ( t )) , (5) where P m ( r m ( t )) = Γ m (2 r m ( t ) /W m − 1) is the p o wer draine d by the m th commun ication link and Γ m = W m × N ( m ) 0 g m . N ( m ) 0 (W / Hz) is the noise spectral power density , W m is the bandwidth , and g m is the (non- negati ve ) g ain of the m th link. In practical application scenarios, the maximum p er -slot co m- munication rate w ith in the intra-VLAN is g enerally limited up to an assigned value r max . Th us, the following hard constraint must hold: P M ( t ) m =1 r m ( t ) ≤ r max . Before proceed ing, we consider the two-way per-task ex- ecution delay ([ s]). W e hav e the m = { 1 , . . . , M ( t ) } link connectio n delays, each d enoted b y Ω m ( t ) = λ m ( t ) /r m ( t ) , and χ m ( t ) ≤ ∆ , where ∆ is the maximum per-slot an d per-VM p r ocessing time ([s]). At this regard, we note that ∆ is also the server’ s response time, i. e., the maximum time allowed for pr ocessing th e total computation load and it is fixed in a dv ance regardless o f the task size allocated to VM m . Since parallel real-time p rocessing is assumed in this work, the overall co mmunication eq uates to 2 Ω m ( t ) + ∆ . Theref ore, the hard per-task delay con straint on the co mputation time is: max { 2 Ω m ( t ) } + ∆ ≤ τ max , where τ max is the maximum tolerable delay , which is fixed in advance. Finally , θ WC OM ( t ) depe nds o n th e number of laser (optical) drivers, named Y ( t ) ≤ Y ( Y is the total nu mber of them), that are required for transferrin g ℓ y ( t ) ∈ L out ( t ) in time slot t ( ℓ y ( t ) is the downlink traffic v olume ([bits] o f the driv er at slot t ). L out ( t ) is accumulated over a fixed per iod o f time to form a batch at the o utput buf fer . At this regard, we n ote th at a large nu mber of drivers yield large transmission speed while at the same time resultin g into hig h en e r gy c o nsumption [ 1 5]. Therefo re, th e energy consump tion can be minimize d by launching an optimal nu m ber of d r i vers fo r the data transfer . Moreover , for e very mobile client who offloaded th eir task in to the MEC server associa te d with the rad io no des, i.e. BSs, its location and the comp utation result is k no wn thro ugh the UE subscription pr ocedure (i.e., through th e LS), thus enab ling the location-aware traffic routing and obtaining Y ( t ) . The energy dra in ed d uring the data tran smissi on pr ocess consists of the following: a constant ene rgy f or utilizing each fast tunable d r i ver d enoted b y O opt ,y ( t ) ([ J /s]), the target transmission rate r 0 [bits/s] and L out ( t ) . Thu s, the energy is, inspired by [14][27]: θ WC OM ( t ) = P Y ( t ) y =1 O opt ,y ( t ) l y ( t ) r 0 , (6) where the p arameter Y ( t ) is obtained using the total numb e r of target BS s as Y ( t ) = 1 α · ( ω ( t )+1 ω ( t ) ) 2 (see [1 4 ]), where ω ( t ) = q Υ σN BS ( t ) . α ∈ (0 , 1] is a controllable factor tha t determines the delay co n straint o f optical networks, σ ([ ms ]) is th e reconfig uration co st for tuning the transceivers, N BS ( t ) is an integer v alue representing the total number of target BSs at time slot t , and Υ is the number of time slots at wh ich the computed workload is accum ulated at the output buf fer . α, σ , and Υ are fixed values. L out ( t ) is equ ally distributed over the Y ( t ) drivers. B. Energy P atterns and Storage The energy buffer of Fig. 1 is characterized b y its ma x imum energy storage capacity B max , an d power charging /d ischarging and leak ing losses are not assumed. At each time slot t , the EM provides the energy level report to the MEC server, thro ugh the pull mo de proced ure (e.g., File Transfer Protoco l [28]), thus the EB level B ( t ) is kn o wn, enab ling the p rovision of the required co mputation and com munication resources, i. e., the VMs and laser drivers. In this work, the amo unt of harvested energy H ( t ) in time slot t is obtaine d fr om o pen-source so lar traces within a solar panel farm located in Armen ia [25] ( see gree n curve in Fig. 2), where the dataset time scale match es ou r time slot duration ( 1 min ). T h e dataset is the r esult of daily en vironm ental records fo r a place assumed to be f ree fro m surro unding obstruction s (e.g. , building s, sha d es). In ou r numerical r esults, H ( t ) is o btained by picking o ne d ay da ta from the dataset an d then scaling the solar energy to fit the EB capacity B max of 490 kJ . Thus, th e av ailable EB level B ( t + 1) at the beginning of time slot t + 1 is calculated as follows: B ( t + 1) = B ( t ) + H ( t ) − θ MEC ( t ) + E ( t ) , (7) where B ( t ) is the energy level in the battery at the beginning of time slot t , θ MEC ( t ) is the en ergy consumption o f the computin g platfor m over time slot t , see Eq. (1), and E ( t ) ≥ 0 is the amoun t of energy purchased from the power grid . W e remark that B ( t ) is updated at th e beginn ing of time slot t whereas H ( t ) and θ MEC ( t ) are only known at the en d o f it. For decision makin g b y the resour ce contro ller, the received EB lev el reports are compar ed with the fo llo wing thresholds: B low and B up , respectively termed the lower an d the up per energy threshold with 0 < B low < B up < B max . B up corre- sponds to the desired energy buffer level and B low is the lowest EB le vel that the MEC server should e ver reach . The suitable energy source at each time slot t is selected ba sed on the for ecast expec ta tio ns, i.e., the expected harvested energy ˆ H ( t ) . If ˆ H ( t ) is enoug h to reac h B up , no ene r gy purch ase is need ed. Oth e rwise, th e remaining amoun t u p to B up , i.e., E ( t ) = B up − B ( t ) is boug ht from the electrical grid. Our optimization f r ame work in Section III - A makes sure that B ( t ) never falls below B low and guaran tees that B up is reached at ev ery time slot. I I I . P R O B L E M F O R M U L A T I O N In this section, we form u late an op timization pr oblem to obtain r educed energy consumption thro u gh short-term server workload and harvested solar energy forec asting alo ng with server manageme nt pro cedures. The optimization pro blem is defined in Section III -A, and the o nline server man agement proced u res are presented in Section III-B. A. Optimization Pr oblem On per time slot basis, the o nline controller ad ap- ti vely schedules the commu nication and co m puting resou rces, at the same time receiving the en ergy lev el report fro m the EM. The g o al is to min imize the overall resulting commun ication-plus-comp uting energy , i.e., the energy co n- sumption r elated to the MEC server’ s VMs and tr ansmission drivers. T o achieve th is, fo r t = 1 , . . . , T , where T is the optimization horizo n , we define the optimization problem as: P1 : min E P T t =1 θ MEC ( t ) (8) subject to: C1 : d ≤ M ( t ) ≤ M , C2 : B low ≤ B ( t ) ≤ B max , C3 : 0 ≤ f m ( t ) ≤ f max , C4 : 0 ≤ λ m ( t ) ≤ λ max , C5 : χ m ( t ) ≤ ∆ , C6 : P M ( t ) m =1 r m ( t ) ≤ r max , C7 : max { 2 Ω m ( t ) } + ∆ ≤ τ max , where E ∆ = { M ( t ) , { α m ( t ) } , { P m ( t ) } , { λ m ( t ) } , ζ ( t ) , Y ( t ) } is th e set of obje c ti ve variables to be configu red at slot t in the ME C server, for the c omputing-plu s-communication processes. Regarding th e co n straints, C1 forces the requ ired number of VMs, M ( t ) , to be always greater than or equal to a minimum number d ≥ 1 : the target of this is to b e always able to hand le mission critical c o mmunications. C2 makes sur e that th e EB level is always ab ove or equa l to a preset threshold B low , to gu arantee energy self-sustainability over time. C3 and C4, bound the maximum processing rate and work loads of each run ning VM m . Constraint C5 represents a har d-limit on th e c o rresponding per-slot an d per-VM pro cessing time. Furthermo re, C6 b o unds the aggregate communica tio n rate sustainable by the V L AN to r max and C7 fo rces the server to process the offloaded task s within the set value τ max . From P1, we n ote that θ MEC ( t ) consists of a non-co n vex compon ent, i.e., Eq. (5), while th e others are conv ex and non-d ecreasing . Then, Eq. (5) can be conve xified into a conv ex function using GP theor y [1 9], b y introducin g alter n ati ve vari- ables and approxima tio ns. In this, we intr oduce fixed param- eters ( i.e., µ m , ν m ) and approx imations. Dr opping the ind ex t for con venience, we let r m = 2 λ m / ( τ max − ∆) . W e o b tain P m ( r m ) in terms of λ m , by re arranging the Shanno n-Hartley expression and substituting th e value of r m , as: ˆ P m ( r m ) = ((2 λ m / ( τ max − ∆)) − ν m W m ) ln 2 µ m W m + ln ( N ( m ) 0 ) − ln g m . From the Shannon -Hartley expression, we simply ob served the presence of the log-sum-exp function as it has been proven to be co n vex in [29] and recall that P m ( r m ) = exp( ˆ P m ( r m )) . T o solve P1, we le verage the use of LL C [2 1], GP [19], and heuristics, ob taining the feasible system control inputs ψ ( t ) = ( M ( t ) , { α m ( t ) } , { P m ( t ) } , { λ m ( t ) } , ζ ( t ) , Y ( t )) , th at yield th e best system behavior within T . B. Resource Contr oller Design and Server Management In this subsection , a server workload and energy ha rvesting forecasting m e th od, and an on line resource m anagement algo- rithm are p r oposed to solve the previously stated prob lem P1. In subsection III-B1, we discuss the L STM n eural n etw ork used to p redict the short-term future server workload s an d harvested energy , then in subsection III- B 2, w e solve P1 by using LLC prin ciples, GP theo ry , an d h euristics, an d lastly , in subsection III-B3 we put forward the ARCES algorithm. 1) Server workloa d and ener gy pr ediction: in ord er to estimate the system worklo ad over the prediction ho rizon T , we perfor m tim e series pred iction, i.e., we ob tain T = 3 estimates of ˆ L( t + 1) and ˆ H ( t + 1 ) , by using an LSTM network developed in Python using T ensorFlow d e e p learning librar ies (Keras, Seq uential, D e n se, L STM), with a hidden layer of 4 LSTM neu r ons, and an o utput laye r that makes a single value prediction . Th e dataset is split as 67% for training and 33% for testing. As for the perfor mance measure of the mode l, we use the Root Mean Squ are Error (RMSE). In this work, pred iction steps similar to [7] ar e ado pted (see T able I in this refer ence), and Fig. 3 shows the pred ic tio n results that will be discussed in Section IV -B. 2) Edge system d ynamics: we denote the system state vector at time t by u ( t ) = ( M ( t ) , Y ( t ) , B ( t )) , which con- tains the numb er of active VMs, M ( t ) , tran smissi on drivers, Y ( t ) , and the EB level, B ( t ) . The inpu t vector ψ ( t ) = ( M ( t ) , { α m ( t ) } , { P m ( t ) } , { λ m ( t ) } , ζ ( t ) , Y ( t )) d ri ves the MEC server behavior (handles the join t VM soft-scaling and the tu ning of transmission dr ivers) at time t . Note that { P ∗ m ( t ) } is o b tained with CVXOPT , and { λ ∗ m ( t ) } is o b tained by following remark 1 . The system b e ha vior is describ ed by th e discrete-time state-space equation, adoptin g the LLC princip le s [21][30]: u ( t + 1) = φ ( u ( t ) , ψ ( t )) , (9) where φ ( · ) is a behavioral model that cap tures the relatio nship between ( u ( t ) , ψ ( t )) , an d the next state u ( t + 1) . Note that this relationship accou nts for the amou nt of energy dr ained θ MEC ( t ) , that harvested H ( t ) and that purch ased fro m the electrical g rid E ( t ) , which together lead to the next buffer lev el B ( t + 1) th rough Eq . (7). The online resour ce manage- ment algorithm, ARCES, find s the best control action vector that yields the desired energy sa vings within the co mputing en vironm ent. Specifically , for each tim e slot t , p roblem (8) is solved, obtaining control actions fo r the pred iction h o rizon T . The control action that is applied a t time t is ψ ∗ ( t ) , which is the first one in the retrie ved co ntrol sequen ce. This control a m ounts to setting the numb er of in stantiated VM s, M ∗ ( t ) ( along with their obtained { α ∗ m ( t ) } , { P ∗ m ( t ) } , { λ ∗ m ( t ) } values), NIC status to either active or not, ζ ∗ ( t ) ∈ (0 , 1) , and the optimal transmission dr i vers, Y ∗ ( t ) . The entire process is repeated e very time slot t when the co ntroller can adjust the behavior g i ven the new state in f ormation. Since the a c tual values for the system input c a n not be measured until the next tim e instan t when the contr o ller a d justs the system behavior , the cor r esponding system state for t + 1 can only be estimated as: ˆ u ( t + 1) = φ ( u ( t ) , ψ ( t )) . (10) For these estimatio ns we use th e fo recast values of lo ad ˆ L in ( t ) and harvested energy ˆ H ( t ) , from the LSTM fo recasting module. Algorithm 1 : ARCES Pseudocode Input: u ( t ) (curren t state) Output: ψ ∗ ( t ) (control input vector) 01: Parameter initialization S ( t ) = { u ( t ) } 02: for ( n with in the pred iction ho r izon of dep th T ) do - ˆ L in ( t + n ) := forecast the workload - ˆ H( t + n ) := f orecast th e energy - S ( t + n ) = ∅ 03: for (eac h u ( t ) in S ( t + n ) ) do - genera te all reachable states ˆ u ( t + n ) - S ( t + n ) = S ( t + n ) ∪ { ˆ u ( t + n ) } 04: for (eac h ˆ u ( t + n ) in S ( t + n ) ) do - calculate the correspo n ding θ MEC ( ˆ u ( t + n )) end for end f or end for 05: - obtain a sequence of reachab le states yielding minimum energy cost 06: ψ ∗ ( t ) := co ntrol leadin g from u ( t ) to ˆ u min 07: Return ψ ∗ ( t ) Remark 1 (VM pro visioning a nd loa d distribution): a r emark on the provisioned VMs at slot t , M ( t ) , is in order . The nu mber of active VMs depen ds on the forecasted server workload, ˆ L in ( t + 1) , an d each VM c a n compute an amoun t of up to λ max (considerin g that virtualizatio n technolog ies specify the minim um and maximum a mount of r esources that can be a llo cated per VM [31]). The n, the projected nu mber of VMs that sha ll be ac tive in slot t to serve the fo recasted server workloads is hereby obtained as: M ( t ) = ( ˆ L in ( t + 1) /λ max ) , wher e · returns the nearest upper integer . W e h e uristically split the workloa d amo n g VMs by allocating a workload λ m ( t ) = λ max to th e first M ( t ) − 1 VMs, m = 1 , . . . , M ( t ) − 1 , and th e rem a in ing worklo ad λ m ( t ) = ˆ L in ( t + 1 ) − ( M ( t ) − 1) λ max to the last one. T his load distribution is motivated by the shares featu re [ 31] th at is inheren t in virtualization tech n ologies. This enables the resource sch e duler to ef ficiently d istrib ute resou rces amongst contend in g VMs, thus gua r anteeing the comp letion of th e computatio n process within the expected time. 3) The ARCES algo rithm: in or d er to obtain the b est control action that will adjust the computing system be- havior at time t , with negligible co m putational overhead, the controller explor es the prediction h orizon of compris- ing discrete states an d come s up with th e feasibility ac- tion set that yields th e m in imum energy cost, i.e., ψ ( t ) = ( M ( t ) , { α m ( t ) } , { P m ( t ) } , { λ m ( t ) } , ζ ( t ) , Y ( t )) . The algorithm p seudocode is o utlined in Algorithm 1 and it f ollo ws the tech nique from [21]. Starting fro m th e initial state , the controller constructs, in a breadth-first fashion, a tree comp r ising all possible future states up to the prediction depth T . The algorithm proceeds as f ollo ws: A search set S consisting of the cu rrent system state is initialized (line 0 1), T able I. System Parameters. Parame ter V alue Max. number of VMs, M 10 Min. number of VMs, d 1 Time slot duratio n, τ 1 min Idle state ene rgy for VM m , θ idle ,m ( t ) 10 J Max. energy for VM m , θ max ,m ( t ) 60 J per-VM reconfigu ration cost, κ e 0 . 005 J / (MHz) 2 TOE in idle state, θ TOE idle ( t ) 13 . 1J Max. allo wed processing time, ∆ 0 . 8 s Processing rate set, { f m ( t ) } { 0 , 50 , 70 , 90 , 105 } Bandwidt h, W m 1 MHz Max. number of dri vers, Y 6 Max. tolerable dela y , τ max 2 s Noise spectral density , N ( m ) 0 - 174 dBm/ Hz Max. VM m load, γ max 5 Mbit Dri ver energy , O opt ,y ( t ) 1 J / s T arget transmission rate, r 0 1 Mbps Controll able factor of delay , α 0 . 96 Reconfigur ation overh ead, σ 20 ms Energy storage capaci ty , β max 490 kJ Lowe r energy threshold, β low 30 % of β max Upper energy threshold, β up 70 % of β max and it is accumulated as the a lgorithm tr a verse through the tree (line 03), accounting for predictions, accumulated w orklo ads at the outp ut b uffer , past outp uts and co ntrols. The set of states reach ed at e very pr ediction d epth t + n is referred to as S ( t + n ) (line 02). Given u ( t ) , we first estimate the worklo a d ˆ L in ( t + n ) and harvested en ergy ˆ H ( t + n ) (line 02 ) , and generate the next set of reachab le con trol ac tio ns by ap plying the inpu t workload and en ergy ha rvested (line 03 ). The e nergy cost function cor responding to e a ch generated state ˆ u ( t + n ) is then c omputed ( line 04) . Once the prediction horizon is explored, a sequence of reachab le states yielding min imum energy consump tion is obtained (line 05). The contr ol action ψ ∗ ( t ) corr esponding to ˆ u ( t + n ) (the first state in this sequ ence) is provided as in put to the system wh ile the rest are discard ed (line 06) . The p rocess is r epeated at the b e ginnin g of each time slot t . I V . P E R F O R M A N C E E V A L U A T I O N This section present some selected n umerical r esults o f the ARCES algorithm for real server workloads. T h e para m eters that were used for the simulation s are listed in T able I. A. Simula tion Setup As on e of the MEC deployment scenario s, we assume that the MEC server is placed at an aggregation point where BSs in p roximity c a n offload their co mputation workload following the rand om real- valued arri val p r ocess. Ou r time slot duration τ is set to 1 min and th e time horizo n is set to T = 3 time slots. Th e sim u lations ar e carried ou t b y exploitin g th e Python progr amming language. B. Numerical Results In Fig. 3, we show real and pred icted values for th e server workloads (Ser ver) an d h a rvested en e r gy ( Solar) over time. W e track the one-step predictive mean value at ea c h step of the on- line forecasting ro utine. The obtained a verage pr ediction error 0 0.2 0.4 0.6 0.8 1 1:00 5:00 10:00 15:00 20:00 Normalized values Time [h] Server (p r edict) Server (re a l) Solar (real) Solar (predict) Figure 3: Forecast m ean value for L ( t ) and H ( t ) . 0 10 20 30 40 50 60 70 80 90 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 5 16 17 18 1 9 20 21 22 2 3 24 Mean energy savings [%] Time [h] ARCES IRS Figure 4: Mean energy sa v ings with in the M E C server . (RMSE) for the server workloads and har ves ted energy pro- cesses, both n ormalized in [0,1 ] f or T ∈ { 1 , 2 , 3 } , are L in ( t ) = { 0 . 017 , 0 . 019 , 0 . 02 1 } and H ( t ) = { 0 . 038 , 0 . 0 39 , 0 . 03 9 } . Note that the predictio n s for L in ( t ) ar e mo re accurate than tho se of H ( t ) (co nfirmed by comp aring the average RMSE), due to dif ferences in the u sed dataset granular ity . Howe ver , the measured accuracy is deemed good enough fo r the propo sed optimization . Our online server man agement algorithm (ARCES) is bench marked with an other on e, name d Itera ti ve-b a sed Resource Sch eduler (IRS), which is inspired b y the iterativ e approa c h fro m [8]. In IRS, the o ptimum computin g-plus-commu nication par ameters ar e obtained in an iterative manner: at the en d of each cycle, conv ergence condition s are used to d e termine if the foun d so lu tion is acceptable or the optimizatio n process should continue. The observed condition s are as follows: (i) to ensure th a t the total load L in ( t ) has been fully allocated with accuracy P M ( t ) m =1 λ m ( t ) − L in ( t ) L in ( t ) ≤ ǫ , with ǫ = 0 . 01 ; ( ii) to verify if the selected workin g fre q uency f m ( t ) is ab le to cope with the input load L in ( t ) , guarantee ing that the computation 10 20 30 40 50 60 1 2 3 4 5 6 7 8 9 10 A verage per-task consumed energy [J] VMs, M ( t ) ARCES ( κ e = 0 . 00 5 ) IRS ( κ e = 0 . 00 5 ) ARCES ( κ e = 0 . 00 1 ) IRS ( κ e = 0 . 00 1 ) Figure 5: A verage per-task consumed energy v s VMs. processing time is within the server’ s resp o nse time limit ∆ , i.e., L in ( t ) ≤ f m ( t )∆ . Th e average e n ergy sa vings obtained by ARCES are shown in Fig. 4 . The average results for ARCES ( κ e = 0 . 0 05 , Γ m = 0 . 5 mW , η = 1 . 4 Gbit/ J ) show en e r gy savings of 6 9 %, while IRS a chie ves 56 % o n average, in both cases with respe c t to the ca se where no energy ma n agement procedu res are app lied; i.e., the MEC server provisions the compu ting resources for maximum expected com putation worklo ad (maxim um value of θ MEC ( t ) , with M = 10 , ∀ t ). As expected, the hig hest energy savings p eak is ob served at 9 h as the ag gregate computatio n requests/workload was at its lo west with an expected incr ease in th e com putation workload and harvested solar energy in the n ear future. The effectiv eness of the joint VM so f t-scaling and tuning of transmission d ri vers, coupled with fo r esighted o ptimization is obser ved in the obtained numerical results. In Fig. 5, we show the effects of the per-VM reco nfiguration cost o n θ MEC ( t ) a t κ e = { 0 . 001 , 0 . 005 } ( Γ m = 0 . 5 mW , η = 1 . 4 Gb it/ J ), taking into account the per formance o f ARCES when com pared with IRS for M ( t ) = 1 , . . . , M . It can be observed th a t θ MEC ( t ) increases with large κ e only for sm all values of M ( t ) , and as M ( t ) increa ses the energy con sumption decreases for large κ e . Moreover , ARCES leads to an energy consump tion red u ction with respect I RS from 25 % to 7 % (case of κ e = 0 . 0 05 ) and f rom 7 % to 5 % (case of κ e = 0 . 0 01 ). When ARCES is com pared with th e case w h ere no energy managem ent is ap plied (maximu m value of θ MEC ( t ) , with M = 10 , ∀ t ), th e ob tained energy reduction range s from 45 % to 31 % (case of κ e = 0 . 0 05 ) and from 25 % to 21 % (case of κ e = 0 . 0 01 ). Th e se nu merical re su lts c onfirm that jointly autoscaling the available com puting-plus-co mmunication re- sources within the comp uting platform provides remar kable energy sa v in gs. The se results conf orms to our expectations from [16]. V . C O N C L U S I O N S In th is paper, we have envisioned a h ybrid-powered MEC server placed in proxim ity to a BS cluster fo r ha ndling the offloaded compu tation workload. Moreover , the use of green energy promo tes e n ergy self-sustainab ility within the ne t- work. W e h ave con sidered a c o mputing-plu s-communication energy model, within the MEC paradigm, and then have pu t forward a combina tio n of a traffic engineerin g- and M EC Location Service-based online server m anagement algorith m with EH capab ilities, called Au tomated Resou rce Controller for Energy- aware Server (ARCES), for autoscalin g and re- configur ing the com puting-plus-co mmunication resource s. The main goal is to minimize the overall en e r gy consu m ption, under hard per-task delay constrain ts (i.e., QoS). ARCES jointly perfo rms (i) a short-term server dem and and harvested solar energy forecasting, (ii) VM soft-scaling, workload an d processing r ate allo cation and lastly , (iii) switching on/off of transmission drivers (i.e . , fast tunab le la ser s) cou pled with the location-aware traf fic scheduling . Num erical re su lts, obtained with real- w orld en ergy and server work load tr a c es, d emon- strate that the pro posed algo r ithm (ARCES) achieves energy sa vings of 69 %, o n av erage, with an energy c o nsumption ranging from 31 %- 45 % at high per-VM reconfiguratio n cost and fr om 21 %- 25 % at low per-VM reco nfiguration cost, with respect to the case where no energy man a gement techn iques are applied. A C K N O W L E D G E M E N T S This work has r e cei ved fund ing from the Eu r opean Union ’ s Horizon 2 020 research and innovation program me unde r the Marie Sklodowska-Curie gran t agreemen t No . 6758 91 (SCA VENGE). R E F E R E N C E S [1] S. Kekki, W . Featherstone, Y . Fang, P . Kuure, A. Li, A. Ranjan, D. Purkayastha, F . Jiangping, D. Frydman, G. V erin, K. W en, K. Kim, R. Arora, A. Odgers, L. M. Contreras, and S. Scarpina, “M EC in 5G Networks, ” ETSI, Sophia-Antipolis, France, T ech. Rep., Jun 2018. [2] D. Thembelihle, M. Rossi, and D. Munaretto, “Softwarization of Mobile Network Functions towards Agile and Energy Efficient 5G Architectures: A Survey ,” W ireless Communications and Mobile Computing , 2017. [3] R. M orabit o, “Power Consumption of V irtualization T echnologies: An Empirical In vestigation, ” in IEE E International Conference on Utility and Cloud Computing (UCC) , Limassol, Cyprus, Dec 2015. [4] Y . Jin, Y . W e n, and Q. Chen, “Energy e f ficiency and server virtualization in data centers: An empirical investigation, ” in IEEE Conference on Computer Communications W orkshops , Orlando, USA, Mar 2012. [5] M. Portnoy , V ir tuali zation essentials . John Wile y & Sons, 2012. [6] J. Xu and S. Ren, “Online Learning for Offloading and Autoscaling in Renewable- Powered Mobile Edge Computing, ” in IEEE GLOBE COM , W ashington, USA, Dec 2016. [7] T . Dlamini, ´ A. F . Gamb´ ın, D. Munaretto, and M. Ros si, “Online Resource Management in Ene rgy Harvesting BS Sites through Prediction and Soft-Scaling of Computing Re s ources, ” in IEEE PIMRC , Bologna, Italy, Sep 2018. [8] M. Shojafar , N. Cordeschi, D. Amendola, and E. Baccarelli, “Energy-saving adaptiv e computing and traffi c engineering for real-time-service data centers, ” in IEEE International Conference on Communication W orkshop (ICCW) , London, UK, Jun 2015. [9] M. Shojafar , N. Cordesc hi, and E. Baccarelli, “Energy-efficient Adaptive Resource Management for Real-time V ehicular Cloud Services, ” IEEE T ransactions on Cloud Computing , 2016. [10] B. Guenter , N. Ja in, and C. Williams, “Managing cost, performance, and reliability tradeoffs for energy-aware server provisioning, ” in Proceedings IEEE INFOCOM , Shanghai, China, Apr. 2011. [11] A. Beloglazov , J. Abawajy , and R. Buyya, “E ner gy-aw are Resource Allocation Heuristics for Efficient Management of Data Centers for Cloud Computing, ” F utur e Generation Computer Systems , vol. 28, no. 5, pp. 755–768, 2012. [12] R. Nathuji and K. Schwan, “V irtualPower: coordinated power management in virtualized e nterprise systems, ” in Proceedings of ACM SIGOPS symposium on Operating systems principles , W a shington, USA, Oc t 2007. [13] C. Gu, H. Huang, and X. Jia, “Power Metering for V irtual Machine in Cloud Computing-Challenges and Opportunities, ” IEEE Acces s , vol. 2, pp. 1106–1116, 2014. [14] S. Fu, H. W en, J. Wu, and B. W u, “Cross-Networks Ene rgy Efficiency Tradeof f: From Wired Networks to Wireless Networks, ” IEEE A ccess , vol . 5, pp. 15–26, 2017. [15] B. W u, S. Fu, X. Jiang, and H. W en, “ Joint Scheduling and Routing for QoS Guaranteed Pack et Transmission in Ene rgy Efficient Reconfigurable WDM Mesh Networks, ” IEEE Journal on Selected Areas in Communications , vol. 32, no. 8, pp. 1533–1541, 2014. [16] N. Cordeshi, M. Shojafar, and E. Bac carelli, “Energy-saving self-configuring network da ta centers, ” Computer Networks , vol. 57, no. 17, pp. 3479–3491, 2013. [17] T . Dlamini, ´ A. F . Gamb ´ ın, D. Munaretto, a nd M. Rossi, “Online Supervisory Control a nd Resource Management for Energy Harvesting BS Sites Empowered with Computation Capabilities,” Wir eles s Communications and Mobile Computing , 2019. [18] E. Oh, K. Son, a nd B . Krishnamachari, “Dynamic Base Station Switching- On/Off Strategies for Green Cellular Networks, ” IEEE Tr ansactions on Wir ele ss Communications , vol. 12, no. 5, pp. 2126–2136, 2013. [19] W .-C. Ho, L. -P . Tung, T .-S. Chang, and K.-T . Feng, “Enhanced component carrier selection and power allocation in L TE-advanced downlink s ystems, ” in 2013 IEEE WCNC , Shanghai, China, Apr 2013. [20] I. Goodfellow , Y . Bengio, and A. Courville, Deep Learning . MIT Press, 2016. [21] J. P . Ha yes, “Self-Optimization in Computer Systems via On-Line Control: Appli- cation to Power Management, ” in Proceedings of the First International Confer ence on Autonomic Computing , May 2004. [22] “Mobile Edge Computing (MEC): Location API, ” ETSI, Sophia-Antipolis, France, T ec h. Rep., Jul 2017. [23] B. Fan and H. Ahmed, “A surve y of mobility models,” W ireless Adhoc Networks , vol. 206, pp. 147–176, 2011. [24] “150 Megabit Ethernet anonymized packet traces.” [Online]. A vailable: http://mawi.wide.ad.jp/mawi/ ditl/ditl2009/ [25] “Solar Radiation Measurement Data. ” [Online]. A vailable: https://energydata.info/dataset/armenia- solar - radiation- measurement- data- 2017 [26] S. Ripduman, R. Andrew , A. W . Moore, and M. Kieran, “Characterizing 10 Gbps network interface ene r gy consumption, ” in IEEE 35th Conference on Local Computer Networks (LCN) , C olor ado, USA, Oct 2010. [27] Chen, Lixing and Zhou, Sheng and Xu, Jie, “Computation peer of floading for energy-constrained mobile edge computing in small-cell networks, ” IEEE/ACM T ransactions on Networking , vol. 26, no. 4, pp. 1619–1632, 2018. [28] “3GPP TS 32. 2. 297, Charging Data Rececord (CDR ) file format a nd transfer, ” ETSI, Sophia-Antipolis, France, T ech. Re p. , Aug 2016. [29] S. Boyd and L. V andenberghe, Convex Optimization . Cambridge Univ ersity Press, 2004. [30] S. Abdelwahed, N. Kandasa my , and S. Nee ma, “Online control for self- management in computing s ystems, ” in IE EE Real-T ime and E mbedded T e c hnology and Applications Sympos ium (RT AS) , Ontario, Canada, May 2004. [31] M. Ca rdosa, M. R. Korupolu, and A. Singh, “Shares and utilities based power consolidation in virtualized server environments, ” in IFIP/IEEE International Symposium on Integrated Networ k Manag ement , New Y ork, USA, June 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment