Learning Individual Styles of Conversational Gesture
Human speech is often accompanied by hand and arm gestures. Given audio speech input, we generate plausible gestures to go along with the sound. Specifically, we perform cross-modal translation from "in-the-wild'' monologue speech of a single speaker…
Authors: Shiry Ginosar, Amir Bar, Gefen Kohavi
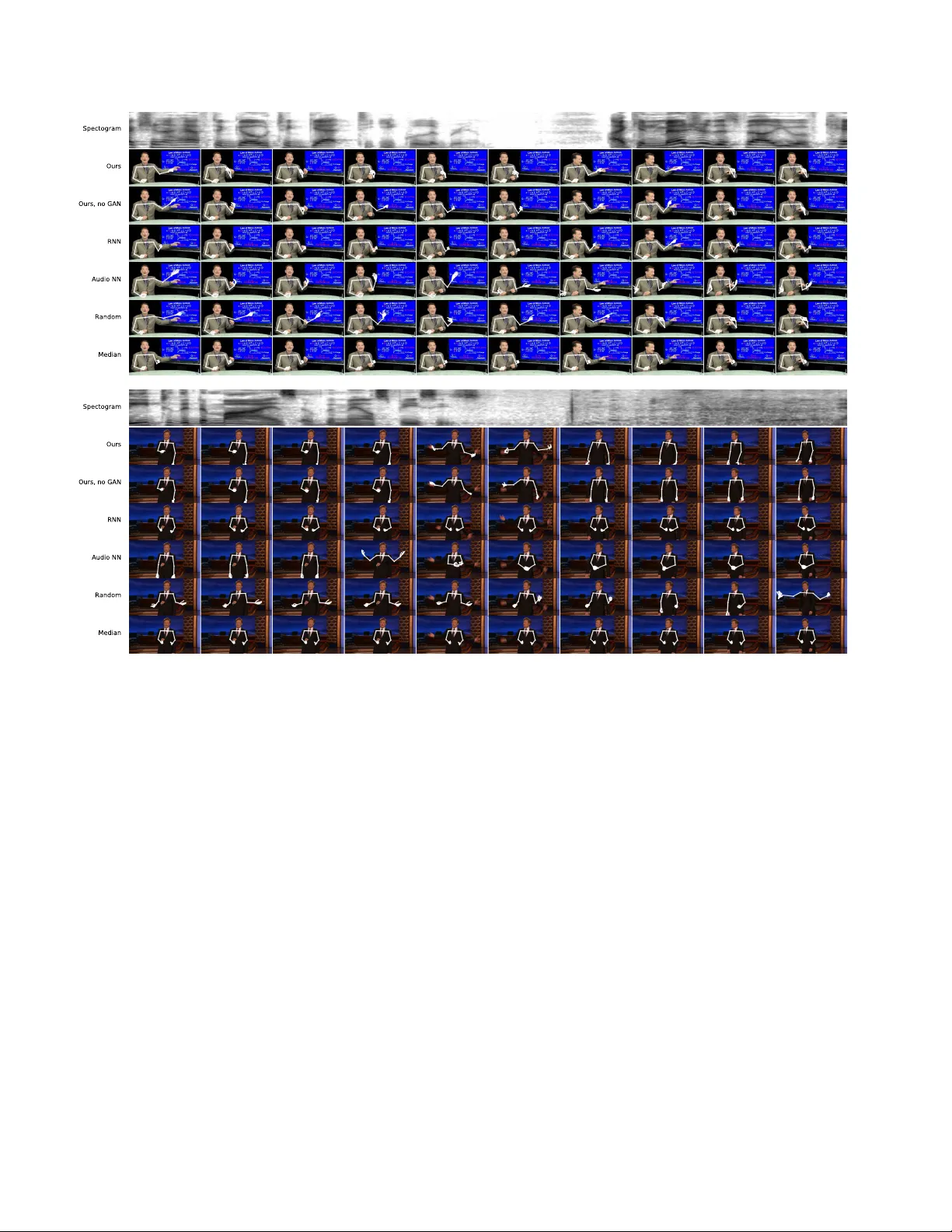
Learning Indi vidual Styles of Con v ersational Gestur e Shiry Ginosar ∗ UC Berkele y Amir Bar ∗ Zebra Medical V ision Gefen K oha vi UC Berkele y Caroline Chan MIT Andre w Owens UC Berkele y Jitendra Malik UC Berkele y Figure 1: Speech-to-gesture translation example . In this paper , we study the connection between conv ersational gesture and speech. Here, we sho w the result of our model that predicts gesture from audio. From the bottom upward: the input audio, arm and hand pose predicted by our model, and video frames synthesized from pose predictions using [ 10 ]. (See http://people.eecs.berkeley. edu/ ˜ shiry/speech2gesture for video results.) Abstract Human speech is often accompanied by hand and arm gestur es. Given audio speech input, we gener ate plausi- ble gestur es to go along with the sound. Specifically , we perform cr oss-modal translation fr om “in-the-wild” mono- logue speec h of a single speaker to their hand and arm mo- tion. W e train on unlabeled videos for which we only have noisy pseudo gr ound truth fr om an automatic pose detec- tion system. Our pr oposed model significantly outperforms baseline methods in a quantitative comparison. T o support r esear ch towar d obtaining a computational understanding of the relationship between gestur e and speech, we r elease a lar ge video dataset of person-specific g estur es. 1. Introduction When we talk, we con vey ideas via two parallel channels of communication—speech and gesture. These con versa- tional, or co-speech, gestures are the hand and arm motions ∗ Indicates equal contribution. we spontaneously emit when we speak [ 34 ]. They comple- ment speech and add non-verbal information that help our listeners comprehend what we say [ 6 ]. Kendon [ 23 ] places con versational gestures at one end of a continuum, with sign language, a true language, at the other end. In between the two e xtremes are pantomime and emblems like “Italianite”, with an agreed-upon v ocabulary and culture-specific mean- ings. A gesture can be subdivided into phases describing its progression from the speaker’ s rest position, through the gesture preparation, strok e, hold and retraction back to rest. Is the information con ve yed in speech and gesture corre- lated? This is a topic of ongoing debate. The hand-in-hand hypothesis claims that gesture is redundant to speech when speakers refer to subjects and objects in scenes [ 43 ]. In contrast, according to the tr ade-off hypothesis , speech and gesture are complementary since people use gesture when speaking w ould require more ef fort and vice versa [ 15 ]. W e approach the question from a data-driv en learning perspec- tiv e and ask to what extent can we predict gesture motion from the raw audio signal of speech. W e present a method for temporal cross-modal transla- tion . Gi ven an input audio clip of a spoken statement (Fig- 1 Almaram Angelica Kubinec Kagan Covach Stewart Ellen Meyers Oliver Conan Figure 2: Speaker -specific gesture dataset . W e sho w a representative video frame for each speaker in our dataset. Below each one is a heatmap depicting the frequenc y that their arms and hands appear in dif ferent spatial locations (using the skeletal representation of gestures shown in Figure 1 ). This visualization rev eals the speak er’ s resting pose, and ho w they tend to mo ve—for e xample, Angelica tends to k eep her hands folded, whereas K ubinec frequently points to wards the screen with his left hand. Note that some speakers, like Kagan , Conan and Ellen , alternate between sitting and standing and thus the distribution of their arm positions is bimodal. ure 1 bottom), we generate a corresponding motion of the speaker’ s arms and hands which matches the style of the speaker , despite the fact that we have never seen or heard this person say this utterance in training (Figure 1 middle). W e then use an existing video synthesis method to visualize what the speaker might hav e looked like when saying these words (Figure 1 top). T o generate motion from speech, we must learn a map- ping between audio and pose. While this can be formu- lated as translation, in practice there are two inherent chal- lenges to using the natural pairing of audio-visual data in this setting. First, gesture and speech are asynchr onous , as gesture can appear before, after or during the correspond- ing utterance [ 4 ]. Second, this is a multimodal prediction task as speakers may perform different gestures while say- ing the same thing on different occasions. Moreov er , ac- quiring human annotations for large amounts of video is in- feasible. W e therefore need to get a training signal from pseudo gr ound truth of 2 D human pose detections on unla- beled video. Nev ertheless, we are able to translate speech to gesture in an end-to-end fashion from the raw audio to a sequence of poses. T o ov ercome the asynchronicity issue we use a large temporal context (both past and future) for prediction. T emporal context also allo ws for smooth gesture prediction despite the noisy automatically-annotated pseudo ground truth. Due to multimodality , we do not expect our predicted motion to be the same as the ground truth. Howe ver , as this is the only training signal we have, we still use automatic pose detections for learning through regression. T o av oid regressing to the mean of all modes, we apply an adversar- ial discriminator [ 19 ] to our predicted motion. This ensures that we produce motion that is “real” with respect to the current speaker . Gesture is idiosyncratic [ 34 ], as different speakers tend to use different styles of motion (see Figure 2 ). It is there- fore important to learn a personalized gesture model for each speaker . T o address this, we present a lar ge, 144 -hour person-specific video dataset of 10 speakers that we make publicly av ailable 1 . W e deliberately pick a set of speakers for which we can find hours of clean single-speaker footage. Our speakers come from a di verse set of backgrounds: tele- vision show hosts, uni versity lecturers and telev angelists. They span at least three religions and discuss a large range of topics from commentary on current affairs through the philosophy of death, chemistry and the history of rock mu- sic, to readings in the Bible and the Qur’an. 1 http://people.eecs.berkeley.edu/ ˜ shiry/ speech2gesture 2. Related W ork Con versational Gestures McNeill [ 34 ] divides gestures into several classes [ 34 ]: emblematics hav e specific con ven- tional meanings ( e.g . “thumbs up!”); iconics conv ey physi- cal shapes or direction of mov ements; metaphorics describe abstract content using concrete motion; deictics are point- ing gestures, and beats are repetiti ve, fast hand motions that provide a temporal framing to speech. Many psychologists have studied questions related to co- speech gestures [ 34 , 23 ] (See [ 46 ] for a revie w). This vast body of research has mostly relied on studying a small num- ber of individual subjects using recorded choreographed story retelling in lab settings. Analysis in these studies was a manual process. Our goal, instead, is to study conv ersa- tional gestures in the wild using a data-driv en approach. Conditioning gesture prediction on speech is arguably an ambiguous task, since gesture and speech may not be syn- chronous. While McNeill [ 34 ] suggests that gesture and speech originate from a common source and thus should co- occur in time according to well-defined rules, Kendon [ 23 ] suggests that gesture starts before the corresponding utter- ance. Others even argue that the temporal relationships be- tween speech and gesture are not yet clear and that gesture can appear before, after or during an utterance [ 4 ]. Sign language and emblematic gesture recognition There has been a great deal of computer vision work geared tow ards recognizing sign language gestures from video. This includes methods that use video transcripts as a weak source of supervision [ 3 ], as well as recent methods based on CNNs [ 37 , 26 ] and RNNs [ 13 ]. There has also been work that recognizes emblematic hand and face gestures [ 17 , 14 ], head gestures [ 35 ], and co-speech gestures [ 38 ]. By con- trast, our goal is to predict co-speech gestures from audio. Con versational agents Researchers hav e proposed a number of methods for generating plausible gestures, par- ticularly for applications with con versational agents [ 8 ]. In early work, Cassell et al . [ 7 ] proposed a system that guided arm/hand motions based on manually defined rules. Sub- sequent rule-based systems [ 27 ] proposed new ways of ex- pressing gestures via annotations. More closely related to our approach are methods that learn gestures from speech and text, without requiring an author to hand-specify rules. Notably , [ 9 ] synthesized ges- tures using natural language processing of spoken text, and Neff [ 36 ] proposed a system for making person-specific gestures. Levine et al . [ 30 ] learned to map acoustic prosody features to motion using a HMM. Later work [ 29 ] e xtended this approach to use reinforcement learning and speech recognition, combined acoustic analysis with te xt [ 33 ], cre- ated hybrid rule-based systems [ 40 ], and used restricted Boltzmann machines for inference [ 11 ]. Since the goal of these methods is to generate motions for virtual agents, they use lab-recorded audio, text, and motion capture. This al- lows them to use simplifying assumptions that present chal- lenges for in-the-wild video analysis like ours: e .g ., [ 30 ] requires precise 3D pose and assumes that motions occur on syllable boundaries, and [ 11 ] assumes that gestures are initiated by an upward motion of the wrist. In contrast with these methods, our approach does not explicitly use any text or language information during training—it learns gestures from raw audio-visual correspondences—nor does it use hand-defined gesture categories: arm/hand pose are predicted directly from audio. V isualizing predicted gestures One of the most common ways of visualizing gestures is to use them to animate a 3D av atar [ 45 , 29 , 20 ]. Since our work studies personalized gestures for in-the-wild videos, where 3D data is not av ail- able, we use a data-driv en synthesis approach inspired by Bregler et al . [ 2 ]. T o do this, we employ the pose-to-video method of Chan et al . [ 10 ], which uses a conditional gen- erativ e adversarial network (GAN) to synthesize videos of human bodies from pose. Sound and vision A ytar et al . [ 1 ] use the synchronization of visual and audio signals in natural phenomena to learn sound representations from unlabeled in-the-wild videos. T o do this, they transfer knowledge from trained discrim- inativ e models in the visual domain, to the audio domain. Synchronization of audio and visual features can also be used for synthesis. Langlois et al . [ 28 ] try to optimize for synchronous e vents by generating rigid-body animations of objects falling or tumbling that temporally match an input sound wa ve of the desired sequence of contact events with the ground plane. More recently , Shlizerman et al . [ 42 ] animated the hands of a 3D av atar according to input mu- sic. Howe ver , their focus w as on music performance, rather than gestures, and consequently the space of possible mo- tions was limited ( e .g ., the zig-zag motion of a violin bo w). Moreov er , while music is uniquely defined by the motion that generates it (and is synchronous with it), gestures are neither unique to, nor synchronous with speech utterances. Sev eral works ha ve focused on the specific task of synthesizing videos of faces speaking, giv en audio input. Chung et al . [ 12 ] generate an image of a talking face from a still image of the speaker and an input speech segment by learning a joint embedding of the face and audio. Simi- larly , [ 44 ] synthesizes videos of Obama saying nov el words by using a recurrent neural network to map speech audio to mouth shapes and then embedding the synthesized lips in ground truth facial video. While both methods enable the creation of fake content by generating faces saying words taken from a different person, we focus on single-person models that are optimized for animating same-speaker ut- terances. Most importantly , generating gesture, rather than lip motion, from speech is more in v olved as gestures are asynchronous with speech, multimodal and person-specific. 3. A Speaker -Specific Gesture Dataset W e introduce a large 144 -hour video dataset specifically tailored to studying speech and gesture of indi vidual speak- ers in a data-driven fashion. As sho wn in Figure 2 , our dataset contains in-the-wild videos of 10 gesturing speak- ers that were originally recorded for television sho ws or univ ersity lectures. W e collect sev eral hours of video per speaker , so that we can individually model each one. W e chose speakers that cov er a wide range of topics and ges- turing styles. Our dataset contains: 5 talk show hosts, 3 lecturers and 2 telev angelists. Details about data collection and processing as well as an analysis of the indi vidual styles of gestures can be found in the supplementary material. Gesture representation and annotation W e represent the speakers’ pose over time using a temporal stack of 2D skeletal keypoints, which we obtain using OpenPose [ 5 ]. From the complete set of keypoints detected by OpenPose, we use the 49 points corresponding to the neck, shoulders, elbows, wrists and hands to represent gestures. T ogether with the video footage, we provide the skeletal keypoints for each frame of the data at a 15 fps. Note, howe ver , that these are not ground truth annotations, but a proxy for the ground truth from a state-of-the-art pose detection system. Quality of dataset annotations All ground truth, whether from human observ ers or otherwise, has associated error . The pseudo ground truth we collect using automatic pose detection may have much larger error than human an- notations, but it enables us to train on much larger amounts of data. Still, we must estimate whether the accuracy of the pseudo ground truth is good enough to support our quantita- tiv e conclusions. W e compare the automatic pose detections to labels obtained from human observers on a subset of our training data and find that the pseudo ground truth is close to human labels and that the error in the pseudo ground truth is small enough for our task. The full experiment is detailed in our supplementary material. 4. Method Giv en raw audio of speech, our goal is to generate the speaker’ s corresponding arm and hand gesture motion. W e approach this task in two stages—first, since the only sig- nal we have for training are corresponding audio and pose detection sequences, we learn a mapping from speech to gesture using L 1 regression to temporal stacks of 2 D key- points. Second, to av oid regressing to the mean of all pos- sible modes of gesture, we employ an adversarial discrim- inator that ensures that the motion we produce is plausible with respect to the typical motion of the speaker . T i m e Au d io F r e q u e n c y G G ( t 1 ), . . . , G ( t T ) Real or Fake Motion Sequence? D L 1 regression loss Figure 3: Speech to gesture translation model. A conv olutional audio encoder downsamples the 2 D spectrogram and transforms it to a 1 D signal. The translation model, G , then predicts a corre- sponding temporal stack of 2 D poses. L 1 regression to the ground truth poses provides a training signal, while an adversarial dis- criminator , D , ensures that the predicted motion is both temporally coherent and in the style of the speaker . 4.1. Speech-to-Gesture T ranslation Any realistic gesture motion must be temporally coher- ent and smooth. W e accomplish smoothness by learning an audio encoding which is a representation of the whole ut- terance, taking into account the full temporal extent of the input speech, s , and predicting the whole temporal sequence of corresponding poses, p , at once (rather than recurrently). Our fully con volutional netw ork consists of an audio en- coder followed by a 1 D UNet [ 39 , 22 ] translation architec- ture, as shown in Figure 3 . The audio encoder takes a 2 D log-mel spectrogram as input, and downsamples it through a series of conv olutions, resulting in a 1 D signal with the same sampling rate as our video ( 15 Hz). The UNet transla- tion architecture then learns to map this signal to a temporal stack of pose vectors (see Section 3 for details of our gesture representation) via an L 1 regression loss: L L 1 ( G ) = E s , p [ || p − G ( s ) || 1 ] . (1) W e use a UNet architecture for translation since its bot- tleneck provides the network with past and future tempo- ral context, while the skip connections allow for high fre- quency temporal information to flow through, enabling pre- diction of fast motion. 4.2. Predicting Plausible Motion While L 1 regression to keypoints is the only way we can extract a training signal from our data, it suffers from the kno wn issue of regression to the mean which produces ov erly smooth motion. This can be seen in our supplemen- tary video results. T o combat the issue and ensure that we produce realistic motion, we add an adversarial discrimi- nator [ 22 , 10 ] D , conditioned on the difference of the pre- dicted sequence of poses. i.e. the input to the discriminator is the vector m = [ p 2 − p 1 , . . . , p T − p T − 1 ] where p i are 2 D pose ke ypoints and T is the temporal extent of the input au- dio and predicted pose sequence. The discriminator D tries to maximize the follo wing objective while the generator G (translation architecture, Section 4.1 ) tries to minimize it: L GAN ( G, D ) = E m [log D ( m )] + E s [log(1 − G ( s ))] , (2) where s is the input audio speech se gment and m is the mo- tion deriv ativ e of the predicted stack of poses. Thus, the generator learns to produce real-seeming speaker motion while the discriminator learns to classify whether a gi ven motion sequence is real. Our full objectiv e is therefore: min G max D L GAN ( G, D ) + λ L L 1 ( G ) . (3) 4.3. Implementation Details W e obtain translation in v ariance by subtracting (per frame) the neck ke ypoint location from all other ke ypoints in our pseudo ground truth gesture representation (section 3 ). W e then normalize each keypoint ( e.g . left wrist) across all frames by subtracting the per-speaker mean and divid- ing by the standard deviation. During training, we take as input spectrograms corresponding to about 4 seconds of au- dio and predict 64 pose vectors, which correspond to about 4 seconds at a 15 Hz frame-rate. At test time we can run our network on arbitrary audio durations. W e optimize us- ing Adam [ 24 ] with a batch size of 32 and a learning rate of 10 − 4 . W e train for 300K/90K iterations with and without an adversarial loss, respecti vely , and select the best performing model on the validation set. 5. Experiments W e show that our method produces motion that quanti- tativ ely outperforms se veral baselines, as well as a pre vious method that we adapt to the problem. 5.1. Setup W e describe our experimental setup including our base- lines for comparison and ev aluation metric. 5.1.1 Baselines W e compare our method to several other models. Always predict the median pose Speakers spend most of their time in rest position [ 23 ], so predicting the speaker’ s median pose can be a high-quality baseline. For a visualiza- tion of each speaker’ s rest position, see Figure 2 . Predict a randomly chosen gesture In this baseline, we randomly select a different gesture sequence (which does not correspond to the input utterance) from the training set of the same speaker , and use this as our prediction. While we would not expect this method to perform well quantita- tiv ely , there is reason to think it would generate qualitativ ely appealing motion: these are real speaker gestures—the only way to tell they are fake is to ev aluate how well they corre- sponds to the audio. Nearest neighbors Instead of selecting a completely ran- dom gesture sequence from the same speaker , we can use audio as a similarity cue. For an input audio track, we find its nearest neighbor for the speaker using pretrained audio features, and transfer its corresponding motion. T o repre- sent the audio, we use the state-of-the-art VGGish feature embedding [ 21 ] pretrained on AudioSet [ 18 ], and use co- sine distance on normalized features. RNN-based model [ 42 ] W e further compare our motion prediction to an RNN architecture proposed by Shlizerman et al . Similar to us, Shlizerman et al . predict arm and hand motion from audio in a 2 D skeletal ke ypoint space. Ho w- ev er , while our model is a con volutional neural network with log-mel spectrogram input, theirs uses a 1 -layer LSTM model that takes MFCC features (a lo w-dimensional, hand- crafted audio feature representation) as input. W e e valuated both feature types and found that for [ 42 ], MFCC features outperform the log-mel spectrogram features on all speak- ers. W e therefore use their original MFCC features in our experiments. F or consistency with our own model, instead of measuring L 2 distance on PCA features, as they do, we add an extra hidden layer and use L 1 distance. Ours, no GAN Finally , as an ablation, we compare our full model to the prediction of the translation architecture alone, without the adversarial discriminator . 5.1.2 Evaluation Metrics Our main quantitative ev aluation metric is the L 1 regres- sion loss of the dif ferent models in comparison. W e ad- ditionally report results according to the percent of correct keypoints (PCK) [ 47 ], a widely accepted metric for pose de- tection. Here, a predicted keypoint is defined as correct if it falls within α max( h, w ) pixels of the ground truth key- point, where h and w are the height and width of the person bounding box, respectiv ely . W e note that PCK was designed for localizing object parts, whereas we use it here for a cross-modal prediction task (predicting pose from audio). First, unlike L 1 , PCK is not linear and correctness scores fall to zero outside a hard threshold. Since our goal is not to predict the ground truth motion but rather to use it as a training signal, L 1 is more suited to measuring how we perform on av erage. Second, PCK is sensitive to large gesture motion as the correctness radius depends on the width of the span of the speaker’ s arms. While [ 47 ] suggest α = 0 . 1 for data with full people and α = 0 . 2 for data where only half the person is visi- ble, we take an av erage over α = 0 . 1 , 0 . 2 and show the full results in the supplementary . 5.2. Quantitative Ev aluation W e compare the results of our method to the baselines using our quantitati ve metrics. T o assess whether our re- sults are perceptually convincing, we conduct a user study . Finally , we ask whether the gestures we predict are person- specific and whether the input speech is indeed a better pre- dictor of motion than the initial pose of the gesture. 5.2.1 Numerical Comparison W e compare to all baselines on 2 , 048 randomly chosen test set interv als per speaker and display the results in T able 1 . W e see that on most speakers, our model outperforms all others, where our no-GAN condition is slightly better than the GAN one. This is expected, as the adversarial dis- criminator pushes the generator to snap to a single mode of the data, which is often further a way from the actual ground truth than the mean predicted by optimizing L 1 loss alone. Our model outperforms the RNN-based model on most speakers. Qualitatively , we find that this baseline pre- dicts relatively small motions on our data, which may be due to the fact that it has relativ ely low capacity compared to our UNet model. 5.2.2 Human Study T o gain insight into how synthesized gestures perceptually compare to real motion, we conducted a small-scale real vs. fake perceptual study on Amazon Mechanical T urk. W e used two speakers who are always shot from the same camera vie wpoint: Oliv er , whose gestures are relatively dy- namic and Meyers, who is relativ ely stationary . W e visu- alized gesture motion using videos of skeletal wire frames. T o provide participants with additional context, we included the ground truth mouth and facial ke ypoints of the speaker in the videos. W e show examples of skeletal wire frame videos in our video supplementary material. Participants watched a series of video pairs. In each pair, one video was produced from a real pose sequence; the other was generated by an algorithm—our model or a base- line. Participants were then asked to identify the video con- taining the motion that corresponds to the speech sound (we did not verify that they in fact listened to the speech while answering the question). V ideos of 4 seconds or 12 seconds each of resolution 400 × 226 (downsampled from 910 × 512 in order to fit two videos side-by-side on different screen sizes) were shown, and after each pair , participants were giv en unlimited time to respond. W e sampled 100 input audio intervals at random and predicted from them a 2 D - keypoint motion sequence using each method. Each task consisted of 20 pairs of videos and was performed by 300 different participants. Each participant was given a short training set of 10 video pairs before the start of the task, and was gi ven feedback indicating whether they had cor- rectly identified the ground-truth motion. W e compared all the gesture-prediction models (Sec- tion 5.1.1 ) and assessed the quality of each method using Figure 4: Our trained models are person-specific. For e very speaker audio input (row) we apply all other indi vidually trained speaker models (columns). Color saturation corresponds to L 1 loss values on a held out test set (lo wer is better). For each row , the entry on the diagonal is lightest as models work best using the input speech of the person they were trained on. the rate at which its output fooled the participants. Inter- estingly , we found that for the dynamic speaker all meth- ods that generate realistic motion fooled humans at similar rates. As sho wn in T able 2 , our results for this speaker were comparable to real motion sequences, whether selected by an audio-based nearest neighbor approach or randomly . For the stationary speaker who spends most of the time in rest position, real motion was more often selected as there is no prediction error associated with it. While the nearest neighbor and random motion models are significantly less accurate quantitati vely (T able 1 ), they are perceptually con- vincing because their components are realistic. 5.2.3 The Predicted Gestures ar e Person-Specific For ev ery speaker’ s speech input (Figure 4 rows), we pre- dict gestures using all other speakers’ trained models (Fig- ure 4 columns). W e find that on average, predicting using our model trained on a dif ferent speaker performs better nu- merically than predicting random motion, but significantly worse than alw ays predicting the median pose of the input speaker (and far worse than the predictions from the model trained on the input speaker). The diagonal structure of the confusion matrix in Figure 4 ex emplifies this. 5.2.4 Speech is a Good Predictor f or Gesture Seeing the success of our translation model, we ask how much does the audio signal help when the initial pose of the gestur e sequence is known . In other words, ho w much can sound tell us beyond what can be predicted from motion dy- namics. T o study this, we augment our model by providing it the pose of the speaker directly preceding their speech, which we incorporate into the bottleneck of the UNet (Fig- ure 3 ). W e consider the following conditions: Predict me- dian pose , as in the baselines abo ve. Predict the input initial Model Meyers Oli ver Conan Stewart Ellen Kagan Kubinec Covach Angelica Almaram A vg. L1 A vg. PCK Median 0 . 66 0 . 69 0 . 79 0 . 63 0 . 75 0 . 80 0 . 80 0 . 70 0 . 74 0 . 76 0 . 73 38 . 11 Random 0 . 93 1 . 00 1 . 10 0 . 94 1 . 07 1 . 11 1 . 12 1 . 00 1 . 04 1 . 08 1 . 04 26 . 55 NN [ 21 ] 0 . 88 0 . 96 1 . 05 0 . 93 1 . 02 1 . 11 1 . 10 0 . 99 1 . 01 1 . 06 1 . 01 27 . 92 RNN [ 42 ] 0 . 61 0 . 66 0 . 76 0 . 62 0 . 71 0 . 74 0 . 73 0 . 72 0 . 72 0 . 75 0 . 70 39 . 69 Ours, no GAN 0 . 57 0 . 60 0 . 63 0 . 61 0 . 71 0 . 72 0 . 68 0 . 69 0 . 75 0 . 76 0 . 67 44 . 62 Ours, GAN 0 . 77 0 . 63 0 . 64 0 . 68 0 . 81 0 . 74 0 . 70 0 . 72 0 . 78 0 . 83 0 . 73 41 . 95 T able 1: Quantitati ve results for the speech to gesture translation task using L 1 loss (lower is better) on the test set. The rightmost column is the av erage PCK value (higher is better) o ver all speakers and α = 0 . 1 , 0 . 2 (See full results in supplementary). Oliv er Meyers Model 4 seconds 12 seconds 4 seconds 12 seconds Median 12 . 1 ± 2 . 8 6 . 7 ± 2 . 0 34 . 0 ± 4 . 2 25 . 8 ± 3 . 9 Random 34 . 2 ± 4 . 0 29 . 1 ± 3 . 7 40 . 9 ± 4 . 6 34 . 3 ± 4 . 4 NN [ 21 ] 36 . 9 ± 3 . 9 26 . 4 ± 3 . 8 43 . 5 ± 4 . 5 33 . 3 ± 4 . 4 RNN [ 42 ] 18 . 2 ± 3 . 2 10 . 0 ± 2 . 5 37 . 5 ± 4 . 6 19 . 4 ± 3 . 6 Ours, no GAN 25 . 0 ± 3 . 8 19 . 8 ± 3 . 4 36 . 1 ± 4 . 3 33 . 1 ± 4 . 2 Ours, GAN 35 . 4 ± 4 . 0 27 . 8 ± 3 . 9 33 . 2 ± 4 . 4 22 . 0 ± 4 . 0 T able 2: Human study results for the speech to gesture translation task on 4 and 12 -second video clips of two speakers—one dy- namic (Oli ver) and one relati vely stationary (Me yers). As a metric for comparison, we use the percentage of times participants were fooled by the generated motions and picked them as real over the ground truth motion in a two-alternati ve forced choice. W e found that humans were not sensitive to the alignment of speech and gesture. For the dynamic speak er , gestures with realistic motion— whether randomly selected from another video of the same speaker or generated by our GAN-based model—fooled humans at equal rates (no statistically significant difference between the bolded numbers). Since the stationary speaker is usually at rest position, real unaligned motion sequences look more realistic as the y do not suffer from prediction noise lik e the generated ones. pose , a model that simply repeats the input initial ground- truth pose as its prediction. Speech input , our model. Initial pose input , a variation of our model in which the audio in- put is ablated and the network predicts the future pose from only an initial ground-truth pose input, and Speech & initial pose input , where we condition the prediction on both the speech and the initial pose. T able 3 displays the results of the comparison for our model trained without the adversarial discriminator (no GAN). When comparing the Initial pose input and Speech & initial pose input conditions, we find that the addition of speech significantly impro ves accuracy when we a verage the loss across all speakers ( p < 10 − 3 using a two sided t-test). Interestingly , we find that most of the gains come from a small number of speakers ( e.g . Oli ver) who make large motions during speech. Model A vg. L 1 A vg. PCK Pred. Predict the median pose 0 . 73 38 . 11 Predict the input initial pose 0 . 53 60 . 50 Input Speech input 0 . 67 44 . 62 Initial pose input 0 . 49 61 . 24 Speech & initial pose input 0 . 47 62 . 39 T able 3: How much information does sound provide once we know the initial pose of the speaker? W e see that the initial pose of the gesture sequence is a good predictor for the rest of the 4-second motion sequence (second to last row), but that adding audio improves the prediction (last row). W e use both average L 1 loss (lower is better) and average PCK ov er all speakers and α = 0 . 1 , 0 . 2 (higher is better) as metrics of comparison. W e com- pare two baselines and three conditions of inputs. 5.3. Qualitative Results W e qualitatively compare our speech to gesture transla- tion results to the baselines and the ground truth gesture sequences in Figure 5 . Please refer to our supplementary video results which better con ve y temporal information. 6. Conclusion Humans communicate through both sight and sound, yet the connection between these modalities remains un- clear [ 23 ]. In this paper , we proposed the task of predict- ing person-specific gestures from “in-the-wild” speech as a computational means of studying the connections between these communication channels. W e created a large person- specific video dataset and used it to train a model for pre- dicting gestures from speech. Our model outperforms other methods in an experimental e v aluation. Despite its strong performance on these tasks, our model has limitations that can be addressed by incorporating in- sights from other work. For instance, using audio as in- put has its benefits compared to using textual transcriptions as audio is a rich representation that contains information about prosody , intonation, rhythm, tone and more. How- ev er , audio does not directly encode high-le vel language se- Figure 5: Speech to gestur e translation qualitative r esults. W e show the input audio spectrogram and the predicted poses o verlaid on the ground-truth video for Dr . Kubinec (lecturer) and Conan O’Brien (sho w host). See our supplementary material for more r esults. mantics that may allow us to predict certain types of gesture ( e.g . metaphorics), nor does it separate the speaker’ s speech from other sounds ( e.g . audience laughter). Additionally , we treat pose estimations as though the y were ground truth, which introduces significant amount of noise—particularly on the speakers’ fingers. W e see our work as a step to ward a computational anal- ysis of conv ersational gesture, and opening three possible directions for further research. The first is in using gestures as a representation for video analysis: co-speech hand and arm motion make a natural tar get for video prediction tasks. The second is using in-the-wild gestures as a way of train- ing con versational agents: we presented one way of visual- izing gesture predictions, based on GANs [ 10 ], b ut, follo w- ing classic work [ 8 ], these predictions could also be used to driv e the motions of virtual agents. Finally , our method is one of only a handful of initial attempts to predict mo- tion from audio. This cross-modal translation task is fertile ground for further research. Acknowledgements: This work was supported, in part, by the A WS Cloud Credits for Research and the DARP A MediFor pro- grams, and the UC Berkeley Center for Long-T erm Cybersecu- rity . Special thanks to Alyosha Efros, the bestest advisor , and to T inghui Zhou for his dreams of late-night talk show stardom. References [1] Y . A ytar , C. V ondrick, and A. T orralba. Soundnet: Learning sound representations from unlabeled video. In Advances in Neural Information Pr ocessing Systems , 2016. 3 [2] C. Bregler , M. Cov ell, and M. Slaney . V ideo re write: Driv- ing visual speech with audio. In Computer Graphics and Interactive T echniques , SIGGRAPH, pages 353–360. A CM, 1997. 3 [3] P . Buehler , A. Zisserman, and M. Everingham. Learning sign language by watching tv (using weakly aligned subti- tles). In Computer V ision and P attern Recognition (CVPR) , pages 2961–2968. IEEE, 2009. 3 [4] B. Butterworth and U. Hadar . Gesture, speech, and compu- tational stages: A reply to McNeill. Psychological Revie w , 96:168–74, Feb . 1989. 2 , 3 [5] Z. Cao, T . Simon, S.-E. W ei, and Y . Sheikh. Realtime multi- person 2d pose estimation using part affinity fields. In Com- puter V ision and P attern Recognition (CVPR) . IEEE, 2017. 4 [6] J. Cassell, D. McNeill, and K.-E. McCullough. Speech- gesture mismatches: Evidence for one underlying represen- tation of linguistic and nonlinguistic information. Pra gmat- ics and Cognition , 7(1):1–34, 1999. 1 [7] J. Cassell, C. Pelachaud, N. Badler , M. Steedman, B. Achorn, T . Becket, B. Douville, S. Prev ost, and M. Stone. Animated con versation: Rule-based generation of facial ex- pression, gesture & spoken intonation for multiple con versa- tional agents. In Computer Graphics and Interactive T ech- niques , SIGGRAPH, pages 413–420. A CM, 1994. 3 [8] J. Cassell, J. Sulliv an, E. Churchill, and S. Prevost. Embod- ied con versational ag ents . MIT press, 2000. 3 , 8 [9] J. Cassell, H. H. V ilhj ´ almsson, and T . Bickmore. Beat: the behavior expression animation toolkit. In Life-Like Charac- ters , pages 163–185. Springer , 2004. 3 [10] C. Chan, S. Ginosar, T . Zhou, and A. A. Efros. Everybody Dance Now. ArXiv e-prints , Aug. 2018. 1 , 3 , 4 , 8 [11] C.-C. Chiu and S. Marsella. How to train your av atar: A data driven approach to gesture generation. In Interna- tional W orkshop on Intelligent V irtual Agents , pages 127– 140. Springer , 2011. 3 [12] J. S. Chung, A. Jamaludin, and A. Zisserman. Y ou said that? In British Machine V ision Conference , 2017. 3 [13] N. Cihan Camgoz, S. Hadfield, O. Koller , H. Ney , and R. Bo wden. Neural sign language translation. In Computer V ision and P attern Recognition (CVPR) . IEEE, June 2018. 3 [14] T . J. Darrell, I. A. Essa, and A. P . Pentland. T ask-specific gesture analysis in real-time using interpolated views. IEEE T ransactions on P attern Analysis and Machine Intelligence , 18(12):1236–1242, Dec. 1996. 3 [15] J. P . de Ruiter, A. Bangerter, and P . Dings. The interplay between gesture and speech in the production of referring expressions: In vestig ating the tradeof f hypothesis. T opics in Cognitive Science , 4(2):232–248, Mar . 2012. 1 [16] D. F . Fouhey , W .-c. Kuo, A. A. Efros, and J. Malik. From lifestyle vlogs to ev eryday interactions. arXiv preprint arXiv:1712.02310 , 2017. 10 [17] W . T . Freeman and M. Roth. Orientation histograms for hand gesture recognition. In W orkshop on Automatic F ace and Gestur e Recognition . IEEE, June 1995. 3 [18] J. F . Gemmeke, D. P . Ellis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. Plakal, and M. Ritter . Au- dio set: An ontology and human-labeled dataset for audio ev ents. In International Confer ence on Acoustics, Speech and Signal Pr ocessing , pages 776–780, Mar . 2017. 5 [19] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farley , S. Ozair, A. Courville, and Y . Bengio. Gen- erativ e adversarial nets. In Advances in Neural Information Pr ocessing Systems , pages 2672–2680, 2014. 2 [20] A. Hartholt, D. T raum, S. C. Marsella, A. Shapiro, G. Stra- tou, A. Leuski, L.-P . Morency , and J. Gratch. All T ogether Now: Introducing the V irtual Human T oolkit. In 13th In- ternational Confer ence on Intelligent V irtual Agents , Edin- bur gh, UK, Aug. 2013. 3 [21] S. Hershey , S. Chaudhuri, D. P . W . Ellis, J. F . Gemmeke, A. Jansen, C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney , R. W eiss, and K. W ilson. CNN ar- chitectures for large-scale audio classification. In Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocess- ing . 2017. 5 , 7 [22] P . Isola, J.-Y . Zhu, T . Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In Com- puter V ision and P attern Recognition (CVPR) , 2017. 4 [23] A. Kendon. Gestur e: V isible Action as Utterance . Cam- bridge Univ ersity Press, 2004. 1 , 3 , 5 , 7 , 10 , 11 [24] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. CoRR , abs/1412.6980, 2014. 5 [25] M. Kipp, M. Neff, K. H. Kipp, and I. Albrecht. T o wards natural gesture synthesis: Evaluating gesture units in a data- driv en approach to gesture synthesis. In C. Pelachaud, J.-C. Martin, E. Andr ´ e, G. Chollet, K. Karpouzis, and D. Pel ´ e, editors, Intelligent V irtual Agents , pages 15–28, Berlin, Hei- delberg, 2007. Springer Berlin Heidelber g. 10 [26] O. Koller , H. Ney , and R. Bo wden. Deep hand: How to train a cnn on 1 million hand images when your data is contin- uous and weakly labelled. In Computer V ision and P attern Recognition (CVPR) , pages 3793–3802. IEEE, 2016. 3 [27] S. K opp, B. Krenn, S. Marsella, A. N. Marshall, C. Pelachaud, H. Pirker , K. R. Th ´ orisson, and H. V ilhj ´ almsson. T owards a common framework for multimodal generation: The behavior markup language. In International workshop on intelligent virtual agents , pages 205–217. Springer , 2006. 3 [28] T . R. Langlois and D. L. James. Inv erse-foley animation: Synchronizing rigid-body motions to sound. ACM T ransac- tions on Graphics , 33(4):41:1–41:11, July 2014. 3 [29] S. Levine, P . Kr ¨ ahenb ¨ uhl, S. Thrun, and V . K oltun. Gesture controllers. In A CM T ransactions on Graphics , volume 29, page 124. A CM, 2010. 3 [30] S. Levine, C. Theobalt, and V . K oltun. Real-time prosody- driv en synthesis of body language. In ACM T ransactions on Graphics , v olume 28, page 172. A CM, 2009. 3 [31] T .-Y . Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ra- manan, P . Dollr , and C. L. Zitnick. Microsoft coco: Common objects in context. In Eur opean Confer ence on Computer V i- sion (ECCV) , Zrich, 2014. Oral. 10 [32] R. C. B. Madeo, S. M. Peres, and C. A. de Moraes Lima. Gesture phase segmentation using support vector machines. Expert Systems with Applications , 56:100 – 115, 2016. 11 [33] S. Marsella, Y . Xu, M. Lhommet, A. Feng, S. Scherer , and A. Shapiro. V irtual character performance from speech. In Symposium on Computer Animation , SCA, pages 25–35. A CM, 2013. 3 [34] D. McNeill. Hand and Mind: What Gestur es Reveal about Thought . Univ ersity of Chicago Press, Chicago, 1992. 1 , 2 , 3 , 10 [35] L.-P . Morency , A. Quattoni, and T . Darrell. Latent-dynamic discriminativ e models for continuous gesture recognition. In Computer V ision and P attern Recognition (CVPR) , pages 1– 8. IEEE, 2007. 3 [36] M. Neff, M. Kipp, I. Albrecht, and H.-P . Seidel. Gesture modeling and animation based on a probabilistic re-creation of speak er style. ACM T ransactions on Graphics , 27(1):5:1– 5:24, Mar . 2008. 3 [37] T . Pfister , K. Simonyan, J. Charles, and A. Zisserman. Deep con volutional neural networks for efficient pose estimation in gesture videos. In Asian Conference on Computer V ision , pages 538–552. Springer , 2014. 3 [38] F . Quek, D. McNeill, R. Bryll, S. Duncan, X.-F . Ma, C. Kir- bas, K. E. McCullough, and R. Ansari. Multimodal hu- man discourse: gesture and speech. ACM T ransactions on Computer -Human Interaction (TOCHI) , 9(3):171–193, 2002. 3 [39] O. Ronneberger , P .Fischer , and T . Brox. U-net: Conv olu- tional networks for biomedical image segmentation. In Med- ical Image Computing and Computer-Assisted Intervention (MICCAI) , v olume 9351 of LNCS , pages 234–241. Springer , 2015. 4 [40] N. Sadoughi and C. Busso. Retrieving target gestures to- ward speech driv en animation with meaningful beha viors. In Pr oceedings of the 2015 ACM on International Confer ence on Multimodal Interaction , ICMI ’15, pages 115–122. ACM, 2015. 3 [41] H. Sakoe and S. Chiba. Dynamic programming algorithm optimization for spoken word recognition. IEEE T ransac- tions on Acoustics, Speech, and Signal Pr ocessing , 26(1):43– 49, Feb . 1978. 11 [42] E. Shlizerman, L. Dery , H. Schoen, and I. Kemelmacher - Shlizerman. Audio to body dynamics. In Computer V ision and P attern Recognition (CVPR) . IEEE, 2018. 3 , 5 , 7 [43] W . C. So, S. Kita, and S. Goldin-Meadow . Using the hands to identify who does what to whom: Gesture and speech go hand-in-hand. Cognitive Science , 33(1):115–125, Feb . 2009. 1 [44] S. Suwajanakorn, S. M. Seitz, and I. Kemelmacher - Shlizerman. Synthesizing obama: Learning lip sync from audio. ACM T ransactions on Graphics , 36(4):95:1–95:13, July 2017. 3 [45] M. Thiebaux, S. Marsella, A. N. Marshall, and M. Kall- mann. Smartbody: Behavior realization for embodied con- versational agents. In International Joint Confer ence on Au- tonomous Agents and Multiagent Systems , volume 1, pages 151–158. International Foundation for Autonomous Agents and Multiagent Systems, 2008. 3 [46] P . W agner, Z. Malisz, and S. Kopp. Gesture and speech in interaction: An overvie w . Speech Communication , 57:209 – 232, 2014. 3 [47] Y . Y ang and D. Ramanan. Articulated human detection with flexible mixtures of parts. IEEE T ransactions on P attern Analysis and Machine Intellig ence , 35(12):2878–2890, Dec. 2013. 5 Figure 6: A segmented gesture unit. 7. A ppendix 7.1. Dataset Data collection and processing W e collected internet videos by querying Y ouT ube for each speaker , and de- duplicated the data using the approach of [ 16 ]. W e then used out-of-the-box face recognition and pose detection systems to split each videos into intervals in which only the subject appears in frame and all detected keypoints are vis- ible. Our dataset consists of 60 , 000 such intervals with an av erage length of 8 . 7 seconds and a standard deviation of 11 . 3 seconds. In total, there are 144 hours of video. W e split the data into 80% train, 10% validation, and 10% test sets, such that each source video only appears in one set. Quality of dataset annotations W e estimate whether the accuracy of the pseudo ground truth is good enough to sup- port our quantitative conclusions via the following experi- ment. W e took a 200 -frame subset of the pseudo ground truth used for training and had it labeled by 3 human ob- servers with neck and arm ke ypoints. W e quantified the consensus between annotators via, σ i , a standard devia- tion per keypoint-type i , as is typical in COCO [ 31 ] ev al- uation. W e also computed || op i − µ i || , the distance between the OpenPose detection and the mean of the annotations, and || prediction − µ i || the distance between our audio- to-motion prediction and the annotation mean. W e found that the pseudo gr ound truth is close to human labels , since 0 . 14 = E [ || op i − µ i || ] ≈ E [ σ i ] = 0 . 06 ; And that the er- r or in the pseudo gr ound truth is small enough for our task , since 0 . 25 = || pr ediction − µ i || >> σ i = 0 . 06 . Note that this is a lower bound on the prediction error since it is computed on training data samples. 7.2. Learning Indi vidual Gesture Dictionaries Gesture unit segmentation W e use an unsupervised method for building a dictionary of an individual’ s ges- tures. W e segment motion sequences into gesture units, propose an appropriate descriptor and similarity metric and then cluster the gestures of an individual. A gesture unit is a sequence of gestures that starts from a rest position and returns to a rest position only after the last gesture [ 23 ]. While [ 34 ] observed that most of their subjects usually perform one gesture at a time, a study of an 18 -minute video dataset of TV speakers reported that their gestures were often strung together in a sequence [ 25 ]. W e treat each gesture unit – from rest position to rest position – as an atomic segment. Cluster 3 Cluster 4 Cluster 9 Figure 7: Individual styles of gestur e . Examples from Jon Stew- art’ s gesture dictionary . W e use an unsupervised approach to the temporal seg- mentation of gesture units based on prediction error (by contrast, [ 32 ] use a supervised approach). Gi ven a motion sequence of k eypoints (Section 3 ) from time t 0 to t T , we try to predict the t T +1 pose. A low prediction error may signal that the speaker is at rest, or that they are in the middle of a gesture that the model has frequently seen during training. Since speakers spend most of the time in rest position [ 23 ], a high prediction error may indicate that a new gesture has begun. W e segment gesture units at points of high predic- tion error (without defining a rest position per person). An example of a segmented gesture unit is displayed in Fig- ure 6 . W e train a segmentation model per subject and do not expect it to generalize across speakers. Dictionary learning W e use the first 5 principal compo- nents of the keypoints computed ov er all static frames as a gesture unit descriptor . This reduces the dimensionality while capturing 93% of the variance. W e use dynamic time warping [ 41 ] as our distance metric to account for temporal variations in the execution of similar gestures. Since this is not a Euclidean norm, we must compute the distance be- tween each pair of datapoints. W e precompute a distance matrix for a randomly chosen sample of 1 , 000 training ges- ture units and use it to hierarchically cluster the datapoints. Individual styles of gesture These clusters represent an unsupervised definition of the typical gestures that an in- dividual performs. For each dictionary element cluster we define the central point as the point that is closest on aver - age to all datapoints in the cluster . W e sort the gesture units in each cluster by their distance to the central point and pick the most central ones for display . W e visualize some exam- ples of the dictionary of gestures we learn for Jon Stewart in Figure 7 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment