aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model
As an alternative to question answering methods based on feature engineering, deep learning approaches such as convolutional neural networks (CNNs) and Long Short-Term Memory Models (LSTMs) have recently been proposed for semantic matching of questions and answers. To achieve good results, however, these models have been combined with additional features such as word overlap or BM25 scores. Without this combination, these models perform significantly worse than methods based on linguistic feature engineering. In this paper, we propose an attention based neural matching model for ranking short answer text. We adopt value-shared weighting scheme instead of position-shared weighting scheme for combining different matching signals and incorporate question term importance learning using question attention network. Using the popular benchmark TREC QA data, we show that the relatively simple aNMM model can significantly outperform other neural network models that have been used for the question answering task, and is competitive with models that are combined with additional features. When aNMM is combined with additional features, it outperforms all baselines.
💡 Research Summary
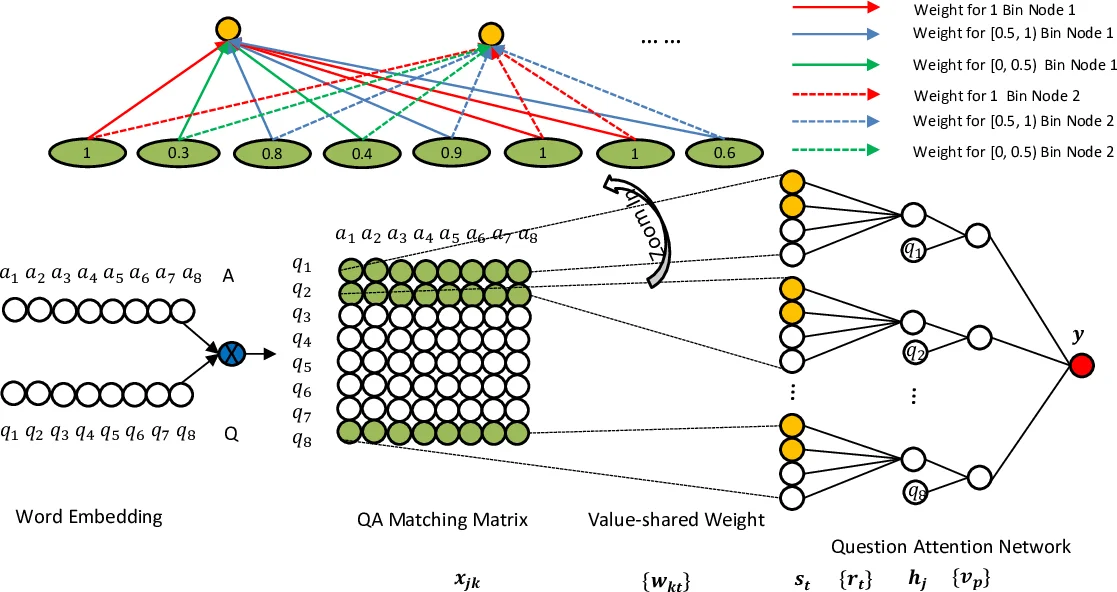
The paper introduces a novel neural architecture called aNMM (attention‑based Neural Matching Model) for ranking short answer texts in question answering (QA) tasks. The authors identify two critical shortcomings of existing deep learning approaches—convolutional neural networks (CNNs) and Long Short‑Term Memory networks (LSTMs). First, CNNs employ position‑shared weights designed for image data, assuming spatial regularities that do not hold for textual semantic matching where important similarity signals can appear at any position. Second, most models treat all question terms equally or rely on sequential order, neglecting the fact that certain question words (the “focus”) are far more informative for determining answer relevance.
To address these issues, aNMM incorporates (1) a value‑shared weighting scheme and (2) a question‑attention network. For each question‑answer pair, a QA matching matrix is built by computing cosine similarity between pre‑trained word embeddings of every question term and every answer term. The matrix entries lie in the interval
Comments & Academic Discussion
Loading comments...
Leave a Comment