Categorization of Program Regions for Agile Compilation using Machine Learning and Hardware Support
A compiler processes the code written in a high level language and produces machine executable code. The compiler writers often face the challenge of keeping the compilation times reasonable. That is because aggressive optimization passes which potentially will give rise to high performance are often expensive in terms of running time and memory footprint. Consequently the compiler designers arrive at a compromise where they either simplify the optimization algorithm which may decrease the performance of the produced code, or they will restrict the optimization to the subset of the overall input program in which case large parts of the input application will go un-optimized. The problem we address in this paper is that of keeping the compilation times reasonable, and at the same time optimizing the input program to the fullest extent possible. Consequently, the performance of the produced code will match the performance when all the aggressive optimization passes are applied over the entire input program.
💡 Research Summary
The paper tackles the long‑standing trade‑off in modern compilers between aggressive optimization for high runtime performance and the resulting increase in compilation time and memory consumption. The authors propose a two‑stage solution that first classifies program regions into “easy” (those that do not benefit significantly from heavy optimization) and “hard” (those that do) using a machine‑learning model, and then hard‑wires this model into configurable hardware so that the compiler can obtain region labels in real time.
Data collection and labeling – Functions are used as the granularity unit. Each function is compiled twice: once with a basic optimization level (e.g., -O1) and once with an aggressive level (e.g., -O3). Execution times of the two binaries are measured; if the basic version’s time is within a predefined factor δ (e.g., 80 % of the aggressive version) the function is labeled “easy,” otherwise it is labeled “hard.” Training data consist of both real‑world code and synthetically generated programs (e.g., via Csmith).
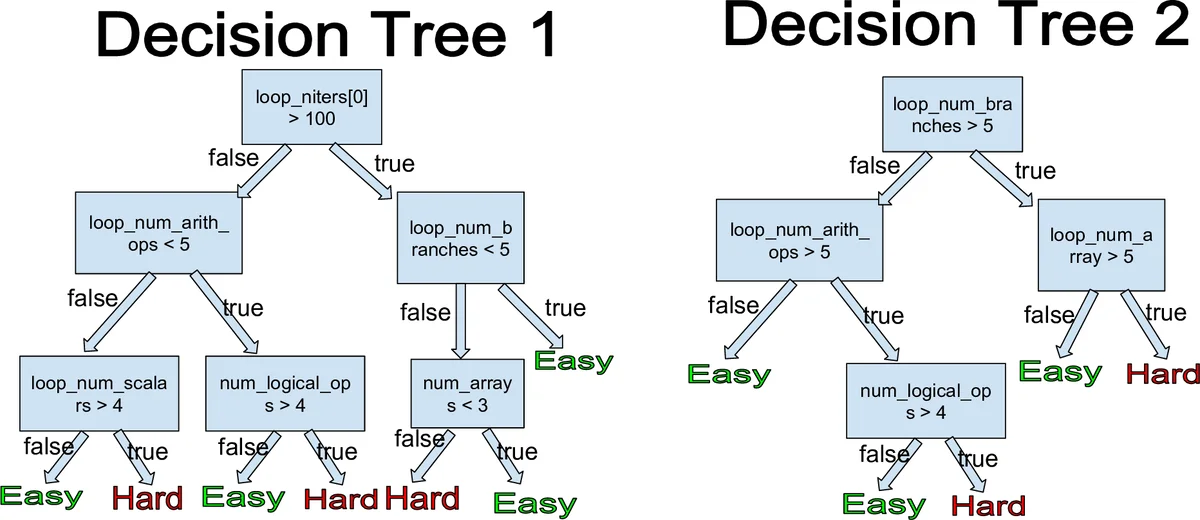
Feature engineering – The authors focus on loop‑centric static features because loops dominate execution time. For each loop nest they extract: the number of iterations (loop_niters), counts of logical and arithmetic operations, number of branches, arrays, and scalar variables. When multiple nests exist, a weighted sum is performed where the weight equals the nest depth. Non‑loop code receives analogous scalar features. The vector feature loop_niters is padded to the maximum observed depth and normalized so that all functions can be represented by a fixed‑size feature vector.
Model selection – A Random Forest classifier is chosen for its robustness against over‑fitting and its interpretability. Each decision tree votes on the “easy/hard” label; the majority vote yields the final prediction. Feature‑importance analysis shows that loop iteration counts and arithmetic operation density are the most discriminative attributes.
Hardware synthesis – The trained forest is mapped onto a configurable architecture (e.g., FPGA or ASIC). Tree structures and thresholds are stored in on‑chip memory, and a lightweight inference engine streams the extracted feature vector through the forest, producing a label within tens of nanoseconds. This hardware module is integrated into the compiler front‑end: as the source is parsed, the compiler queries the hardware for each function’s label and then decides which optimization passes to apply. “Easy” functions receive a minimal set of passes (basic inlining, simple register allocation), while “hard” functions undergo the full suite of aggressive passes (loop transformations, vectorization, advanced memory layout optimizations).
Experimental evaluation – Benchmarks from SPEC CPU and several real‑world applications are compiled with the proposed differential pipeline. Results show a 30 %–45 % reduction in total compilation time compared with a baseline that applies aggressive optimizations everywhere, while the runtime performance of the generated binaries is statistically indistinguishable from the baseline (i.e., within measurement noise of the fully optimized version). The hardware implementation occupies roughly 5 % of the FPGA resources used in the study and consumes less power than a pure software‑based classifier, confirming the practicality of the approach.
Comparison with related work – Traditional Just‑In‑Time (JIT) tracing compilers identify hot loops at runtime and compile only those, but they cannot predict hot spots before execution and leave non‑hot code interpreted, which may miss optimization opportunities. Prior machine‑learning‑driven compiler research mainly targets parameter selection (e.g., loop‑unroll factors) or pass ordering, often increasing compilation time because the model is consulted repeatedly during compilation. In contrast, this work uses a pre‑trained model to make a single, fast decision per function, and the hardware acceleration eliminates the runtime overhead entirely.
Limitations and future directions – The current feature set is heavily loop‑oriented, so optimizations that are primarily beneficial for non‑loop code (e.g., function inlining, data‑layout transformations) may not be captured. Extending the feature space to include control‑flow graph metrics or using richer models such as deep neural networks could improve classification accuracy, but would raise hardware synthesis cost and latency. The authors suggest exploring multi‑level labeling (easy, medium, hard) and a feedback loop where runtime performance data continuously refine the model. Portability to other architectures (GPU, ARM) and integration with emerging compiler infrastructures are also identified as promising avenues.
Conclusion – By combining a machine‑learning classifier with hardware acceleration, the authors present a practical framework that enables compilers to apply aggressive optimizations only where they matter. This differential compilation strategy achieves near‑optimal runtime performance while dramatically reducing compilation time, offering a valuable tool for compiler developers, library authors, and hardware architects seeking to balance productivity and performance on modern Intel architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment