Learning discriminative features in sequence training without requiring framewise labelled data
In this work, we try to answer two questions: Can deeply learned features with discriminative power benefit an ASR system's robustness to acoustic variability? And how to learn them without requiring framewise labelled sequence training data? As exis…
Authors: Jun Wang, Dan Su, Jie Chen
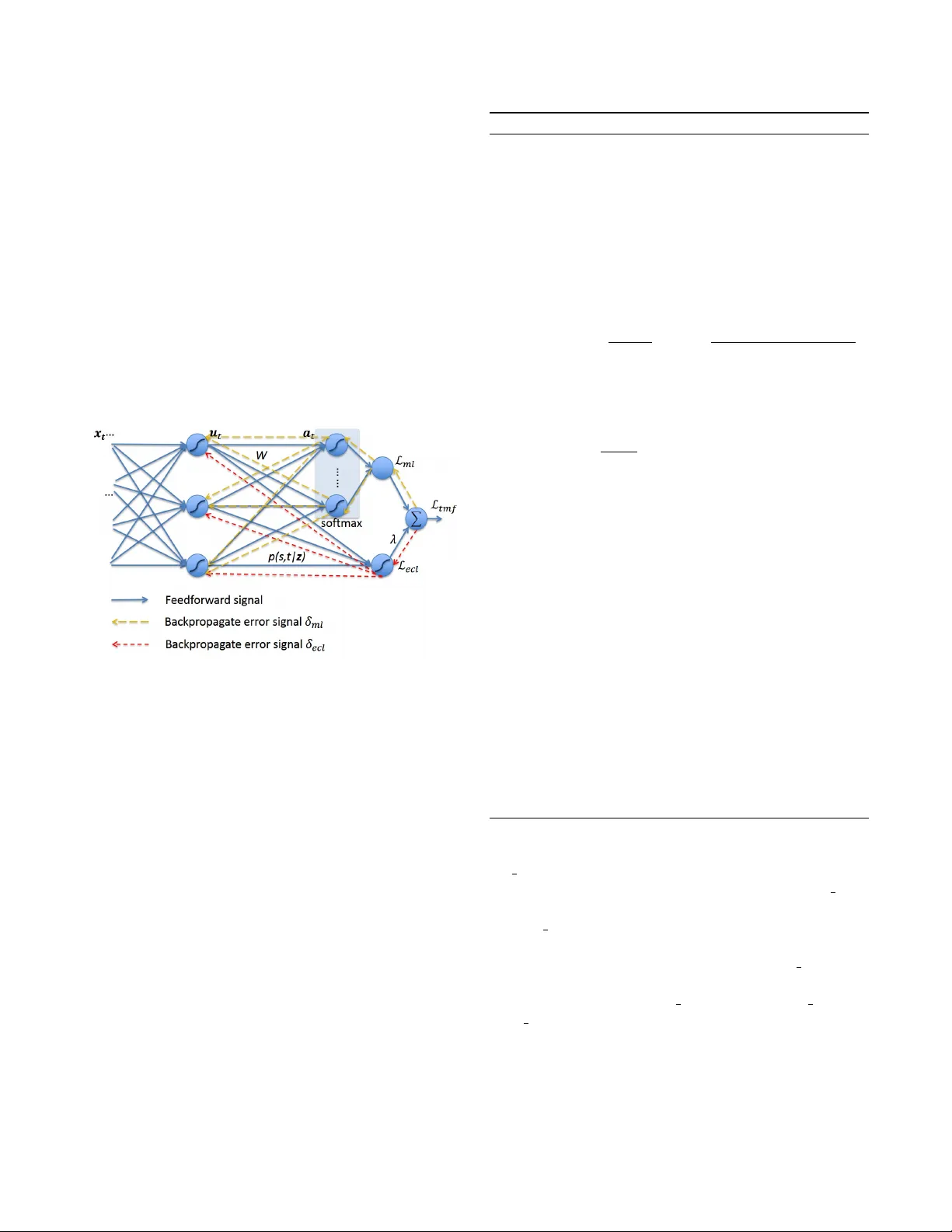
LEARNING DISCRIMINA TIVE FEA TURES IN SEQUENCE TRAINING WITHOUT REQUIRING FRAMEWISE LABELLED D A T A J un W ang 1 , Dan Su 1 , Jie Chen 1 , Shulin F eng 3 , Dongpeng Ma 1 , Na Li 1 , Dong Y u 2 1 T encent AI Lab, Shenzhen, China 2 T encent AI Lab, Belle vue W A, USA 3 K ey Laboratory on Machine Perception, Peking Univ ersity , Beijing, China { joinerwang, dansu, leojiechen, shulinfeng, dongpengma, nenali, dyu } @tencent.com ABSTRA CT In this work, we try to answer two questions: Can deeply learned features with discriminative po wer benefit an ASR system’ s robustness to acoustic v ariability? And ho w to learn them without requiring frame wise labelled sequence training data? As existing methods usually require knowing where the labels occur in the input sequence, they ha ve so far been limited to many real-world sequence learning tasks. W e pro- pose a novel method which simultaneously models both the sequence discriminativ e training and the feature discrimina- tiv e learning within a single network architecture, so that it can learn discriminativ e deep features in sequence training that ob viates the need for presegmented training data. Our e x- periment in a realistic industrial ASR task shows that, without requiring any specific fine-tuning or additional complexity , our proposed models have consistently outperformed state- of-the-art models and significantly reduced W ord Error Rate (WER) under all test conditions, and especially with high- est improv ements under unseen noise conditions, by relative 12 . 94% , 8 . 66% and 5 . 80% , showing our proposed models can generalize better to acoustic variability . Index T erms — ASR, discriminati ve feature learning, acoustic variability , sequence discriminative training. 1. INTR ODUCTION Mismatch between training and testing conditions is a ubiq- uitous problem in modern neural network-based systems. It is particularly common in perceptual sequence learning tasks (e.g. speech recognition, handwriting recognition, motion recognition) where unsegmented noisy input streams are an- notated with strings of discrete labels. For example, acoustic variability for modern Automatic Speech Recognition (ASR) systems arises from speaker , accent, background noise, re- verberation, channel, and recording conditions, etc. Ensuring robustness to variability is a challenge, as it is impractical to see all types of acoustic conditions during training. Sev eral model and feature based adaptation methods has been proposed, such as Noise Adaptiv e T raining [1, 2, 3] and 3 Shulin did this work while he was an intern at T encent V ector T aylor Series [4] for handling en vironment variability , and Maximum Likelihood Linear Regression (MLLR) [5] and iV ectors [6] for handling speaker variability . Discriminativ e feature learning is another important orientation. For exam- ple, manifold regularized deep neural networks [7] has been proposed for speech-in-noise recognition tasks. While mani- fold learning approaches are known to require relativ ely high complexity , recently , alternati ve methods for learning dis- criminativ e features hav e been originally suggested for Face Recognition (FR) tasks. Among them, Contrastive Loss [8, 9] and T riplet Loss [10] respectively construct loss functions for image pairs and triplets to supervise the embedding learn- ing; Center Loss [11] encourages intra-class compactness by penalizing the distances between the features of samples and their centers; Alternati ve approaches such as SphereFace [12] and CosFace [13] replace the simple Euclidean distance metric with more suitable metric space for FR tasks. V ari- ants of these methods have also been successfully adopted in Speaker Recognition (SR) tasks [14, 15]. For FR and SR tasks, their goal of learning discrimina- tiv e features is to identify ne w unseen classes without label prediction[11, 16]. In contrast, our goal for ASR tasks is to enhance robustness to ne w unseen acoustic conditions during testing. In Section 2.1, we first in vestigate the deeply learned features with a joint supervision of frame-level Cross En- tropy (CE) Loss and Center Loss in our ASR system. Despite the success of discriminativ e feature learning approaches for FR and SR problems, so far , it has not been possible to apply these approaches to sequence-discriminativ e train- ing models. The problem is that these loss functions are defined separately for each point in the training sequence; ev en worse, any other loss functions adopted for the joint supervision must also be defined separately for each point, thus sequence-discriminativ e training mechanisms, such as Connectionist T emporal Classification (CTC)[17], MMI[18], MBR[19] and LFMMI[20]), are ruled out. T o address this problem, in Section 2.2, we propose a novel, general mech- anism by encouraging the sequence-discriminative training model to simultaneously learn feature representations with discriminativ e power , so that the model can exploit the full potential of sequence modelling mechanisms. Section 3 com- pares our proposed mechanisms to baseline methods, and the paper concludes with Section 4. 2. PR OPOSED METHOD During testing, an ASR system may encounter ne w recording conditions, microphone types, speakers, accents and back- ground noises. Even if the test scenarios are seen during training, there can be significant variability in their statistics. Can deeply learned representations with more discriminati ve power benefit the system’ s robustness to acoustic variability? In Section 2.1, we firstly consider fusion of two criterias for framewise training, and then in Section 2.2 we discuss two losses for joint supervision for sequence training without re- quiring framewise labels and in vestigate their potential ef fects on feature learning. 2.1. Framewise Multi-loss Fusion W e assume an acoustic model whose output nodes represent K classes, e.g., context dependent (CD) phonemes, CD sub- phonemes, or labels of the associated HMM states, among others. Center Loss (CL) can be formulated as follows: L cl = X t || u t − c k t || 2 2 (1) where the deeply learned feature u t ∈ R D is the second last layer’ s output at time t ; given frame wise training data and annotation pairs ( x t , k t ) : t = 1 , ..., T , the input x t belongs to the k t -th class, and the c k t ∈ R D denotes the k t -th class center of the deep features. Center Loss learns a center of deep features for each class and penalizes the distance between the deep features and their corresponding class centers; it can significantly enhance the discriminativ e power of deep features [11, 16]. Howe ver , without separability , the deep features and centers could de- grade to zero at which point the Center Loss is very small. Therefore we use a Cross Entropy (CE) Loss function to en- sure the separability of the deep features: L ce = − X t log y k t t (2) where y k t t is the k t -th output after the softmax operation on the output of the last layer: y k t t = e a k t t P K j =1 e a j t (3) a t = W u t + B (4) where a t ∈ R K is the output of the last layer and a j t indicates the j -th element, and W ∈ R K × D , B ∈ R K are the weight and bias matrix of the last layer . The Framewise Multi-Loss Fusion (FMF) of the above two losses with a balancing scalar λ can then be formulated as follows: L f mf = L ce + λ L cl (5) The joint supervision by FMF benefits both the inter-class separability and the intra-class compactness of deep features, and will be proved in our experiment to be effecti ve for ro- bustness to acoustic v ariability . 2.2. T emporal Multi-loss Fusion This section presents a nov el method called T emporal Multi- loss Fusion (TMF) for learning discriminativ e deep features that removes the need for framewise labelled training se- quences. It models both the sequence discriminati ve training and the feature discriminativ e learning within a single net- work architecture. The basic idea is to interpret the network outputs as a probability distribution over all possible label sequences, conditioned on a giv en sequence. Giv en this dis- tribution, a fusion loss function can be deriv ed that directly maximizes the probabilities of the correct labelings while penalizing the distance between the deep features and the corresponding centers. W ithout loss of generality , we illustrate sequence discrim- inativ e training with CTC [17] method. The goal of Maxi- mum Likelihood (ML) training in CTC is to simultaneously maximize the log probabilities of all the correct classifications in the training set. This means minimizing the following loss function: L ml = − X ( x , z ) ∈ S ln ( p ( z | x )) (6) where ( x , z ) ∈ S are the training data pairs. Since the framewise annotated training data ( x t , k t ) : t = 1 , ..., T is no longer available, we define a conditional Expected Center Loss (ECL) as follows: L ecl = X s X t p ( s, t | z ) || u t − c z 0 s || 2 2 (7) where L ecl means a conditional expected loss by the deep representation u t deviating from c z 0 s which is the center cor - responding to symbol z 0 s . Following the con vention of CTC, for labelling sequence z of length r , we denote by z 1: s and z r − s : r its first and last s symbols respectively , define a set of positions where label j occurs as l ab ( z , j ) = { s : z 0 s = j } , where a modified label sequence z 0 is defined with blanks added to the beginning and the end of z , and inserted between ev ery pair of consecutive labels. Given the labelling z , the probability of all the paths corresponding to z that go through a gi ven symbol s in z 0 at time t can be calculated as the prod- uct of the forward and backward v ariables at the symbol s and time t : p ( s, t | z ) = α t ( s ) β t ( s ) (8) where the detailed calculation for the forward v ariables α t ( s ) and backward v ariables β t ( s ) can be referred to [17]. Finally , we formulate the TMF objective function as be- low: L tmf = L ml + λ L ecl (9) where a scalar λ is used for balancing ECL and CTC loss. ECL encourages the intra-class compactness while CTC Loss encourages the separability of features. Consequently , their joint supervision minimizes the intra-class variations while keeping the features of dif ferent classes separable. As the objectiv e function is differentiable, the network can then be trained with standard back-propagation through time. W e provide the learning details about TMF in Algo- rithm 1, and accordingly illustrate its feedforward process and backpropagate error signal flo w in Figure 1. Fig. 1 . Illustration of the feedforward process and the back- propagate error signal flow under fusion supervision: The feedforward signal is denoted with blue solid lines; the back- propagate error signals generated by CTC and ECL are de- noted with yellow and red dash lines, respecti vely . 3. EXPERIMENTS AND AN AL YSIS 3.1. Data A noisy far -field training corpus was simulated based on a clean corpus of 2 million clean speech utterances which were 1845 . 78 hours in total, by adding reverberation and mixing with various environmental noises. The room simulator was based on IMA GE method [21] and generated 15 K room im- pulse responses (RIRs). The noisy speech corpus covered re- verberation time (R T60) ranging from 0 to 600 ms, and cov- ered different noise types at uniformly distributed SNRs rang- ing from 15 to 30 dB. Both the clean and the noisy corpus were split into training set of 1840 hours and v alidation set of 5 . 78 hours which contains 6 K utterances. T o construct test set, we used a separated clean speech dataset of real-world conv ersation recordings, denoted as Algorithm 1 T emporal Multi-loss Fusion learning algorithm Input : T raining pairs of sequences ( x , z ) ∈ S ; initialized parameters θ in con volutional and LSTM layers, parameters W and { c j | j = 1 , 2 , ..., K } in full connection and loss layers, respectiv ely; balancing factor λ , and learning rate µ and γ . Output : The parameters θ and W . 1: while not con verge do 2: Compute the TMF joint loss by Equation 9 3: Compute the backpropagation error signal through the softmax layer: δ ml ( k ) = ∂ L tmf ∂ a k t = y k t − P s ∈ lab ( z ,k ) α t ( s ) β t ( s ) P | z 0 | s =1 α t ( s ) β t ( s ) (10) 4: Compute the backpropagation error signal by ECL: δ ecl = ∂ L ecl ∂ u t = X s α t ( s ) β t ( s )( u t − c z 0 s ) (11) 5: Compute the fusion of backpropagation error signals through the second last layer: δ = W > δ ml + λδ ecl (12) 6: Compute weight adjustments ∆ W and ∆ θ with the chain rule using the backpropagation error signals δ ml and δ , respecti vely . 7: Update the parameters: c z 0 s = c z 0 s − µ X t α t ( s ) β t ( s )( c z 0 s − u t ) (13) W = W − γ ∆ W (14) θ = θ − γ ∆ θ (15) 8: end while test clean . It had 1 K utterances and 1 . 43 hours length in total. W e simulated a noisy test set by mixing test clean with the same noise types as training set and denoted it as noise seen . Furthermore, to ev aluate the robustness of our proposed method under unseen acoustic conditions, we simulated another noisy test set by mixing test clean with a different set of noise types not seen during training and denoted this test set as noise unseen . Both noise seen and noise unseen were simulated with R T60 ranging from 0 to 600 ms, with uniformly distributed SNRs from 15 to 30 dB. FBank features of 40 -dimension were computed with 25 ms window length, 10 ms hop size, and formed a 120 - dimension vector along with their first and second order difference. After normalization, the vector of the current frame was concatenated with those of the preceding 5 frames and the subsequent 5 frames, resulting in an input vector of dimension 40 ∗ 3 ∗ (5 + 1 + 5) = 1320 . 3.2. Experiment Setup While increasing the neural network depth, as discussed in [3], the internal deep representations became increasingly discriminativ e and insensitiv e to many sources of variability in speech signals, although DNNs could not extrapolate to test samples substantially different from the training exam- ples which were not sufficiently representativ e. Hence it was important for us to set a solid bar as baseline systems. W e adopted state-of-the-art models which hav e been well-tuned for our industrial applications as our baselines: For frame- wise training, CE indicated the model trained with CE loss function as our baseline model; correspondingly , FMF in- dicated the proposed model with framewise multi-loss joint supervision. For sequence training, CTC indicated the model trained with CTC criteria as our baseline model, and TMF indicated the proposed model with temporal multi-loss joint supervision; furthermore, we w anted to look into the potential benefit by the proposed TMF model to other state-of-the-art ASR system: The model denoted as CTC+MMI was initial- ized with the CTC model and then trained with sequence discriminativ e training [22, 23] with MMI criteria [18]; the model denoted as TMF+MMI was initialized with the TMF model and then trained with MMI. All the above models shared the same basal network ar- chitecture and hyperparameter configuration, so that they had approximately equal computation complexity , as the com- plexity added by joint supervision could be negligible. The architecture contained two 2 -dimensional CNN layers, each with a kernel size of (3 , 3) , a stride of (1 , 1) , and followed with a maxpool layer with a kernel size of (2 , 2) and a stride of (2 , 2) , and then five LSTM layers, each with hidden size of 1024 and with peephole, and then one full-connection FC layer plus a softmax layer . Batch normalization was applied after each CNN and LSTM layer to accelerate conv ergence and improve generalization. W e used CD phonemes as our output units, which were about 12 K classes in our Chinese ASR system. During training, the balancing factor λ was set to experi- ential values of 1 e − 3 and 1 e − 4 for clean and noisy condi- tions, respecti vely . The class centers were updated only when α t ( s ) β t ( s ) ≥ 0 . 01 , with the batch momentum µ of 1 e − 3 , and the ”blank” class was excluded. Adam optimizer was adopted. The learning rate had an initial value of 1 e − 4 and would be halved if the average v alidation likelihood after ev- ery 5 K batches hadn’ t raised for 3 successi ve times. The train- ing would be early stopped if the likelihood hadn’t raised for 8 successi ve times. 3.3. Result and Analysis T able 1 compares experiment result in terms of test WERs by differnt models: CE versus FMF for frame wise training, CTC versus TMF , and CTC+MMI versus TMF+MMI for sequence training. The better performances are marked with bold num- bers; their corresponding relati ve impro vements are gi ven in parentheses, and the highest relative improvements among test clean , noise seen and noise unseen test conditions are marked with underlines. It shows that the proposed models consistently outper- form their corresponding baseline models under all test con- ditions. Meanwhile, it is worth noting that all of the highest relativ e improv ements are achiev ed under the unseen noise condition. This result proves that the joint supervision by our proposed methods effecti vely benefit the system’ s robustness, and can generalize the sequence discriminative training better to noise variability by enhancing the inter-class separability and the intra-class compactness of deep feature. W e obtained the abov e improv ements without fine-tuning hyperparameters for the proposed models. As mentioned in Section 3.2, the network structure and hyperparameters have been fine-tuned to optimize the baseline models, and then di- rectly inherited by the proposed models. Hence another merit of the proposed models is that they don’t necessarily require additional complexity or hyperparameter tuning in addition to a giv en baseline model. T able 1 . WERs (%) of CE v .s. FMF , CTC v .s. TMF , and CTC+MMI v .s. TMF+MMI ; the better scores were marked with bold numbers, follo wed with their relati ve improve- ment in parentheses; the highest relative improv ement scores among various noise conditions were underlined. test clean noise seen noise unseen CE 5 . 66 8 . 82 10 . 05 FMF 5.19 ( 8 . 30 ) 8.15 ( 7 . 60 ) 8.75 ( 12 . 94 ) CTC 4 . 67 8 . 19 8 . 08 TMF 4.33 ( 7 . 28 ) 7.59 ( 7 . 33 ) 7.38 ( 8 . 66 ) CTC+MMI 4 . 45 7 . 34 7 . 58 TMF+MMI 4.29 ( 3 . 59 ) 7.12 ( 3 . 00 ) 7.14 ( 5 . 8 ) 4. CONCLUSIONS W e have introduced a novel method which obviates the need for framewise labelled training data and allows the network to directly learn deep discriminative feature representations while performing sequence discriminativ e training. W e have demonstrated that the deeply learned features with discrim- inativ e po wer could benefit the ASR system’ s robustness to noise variability . W ithout requiring any specific fine-tuning or additional complexity , the proposed models have outper- formed state-of-the-art models for an industrial ASR system, and the relativ e improvements are especially remarkable un- der unseen conditions. Future research includes extending the proposed method to v arious sequence discriminativ e train- ing mechanisms, and ev aluating their effecti veness to v arious sources of acoustic variability . 5. REFERENCES [1] O. Kalinli, M.L. Seltzer, J. Droppo, and A. Acero, “Noise adapti ve training for robust automatic speech recognition, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , pp. 1889–1901, 2010. [2] M.L. Seltzer , D. Y u, and Y . W ang, “ An in vestigation of deep neural networks for noise robust speech recog- nition, ” in Pr oceedings of International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2013. [3] D. Y u, M.L. Seltzer , J. Li, J.T . Huang, and F . Seide, “Feature learning in deep neural networks - studies on speech recognition tasks, ” in Pr oceedings of Interna- tional Conference on Learning Representation . IEEE, 2013. [4] C.K. Un and N.S. et al. Kim, “Speech recognition in noisy en vironments using first-order vector taylor se- ries, ” Speech Communication , vol. 24(1), pp. 39–49, 1998. [5] Y . W ang and M.J. Gales, “Speaker and noise factoriza- tion for robust speech recognition, ” IEEE T ransactions on Audio, Speech and Languag e Pr ocessing , vol. 20(7), pp. 2149–2158, 2012. [6] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic mod- els using i-vectors, ” in Pr oceedings of IEEE Auto- matic Speech Recognition and Understanding W ork- shop . IEEE, 2013, pp. 55–59. [7] V . S. T omar and R. Rose, “Manifold regularized deep neural networks, ” in Pr oceedings of Confer ence of the International Speech Communication Association . IEEE, 2014. [8] R. Hadsell, S. Chopra, and Y . LeCun, “Dimension- ality reduction by learning an in variant mapping, ” in Pr oceedings of Computer vision and pattern reco gni- tion (CVPR) . IEEE computer society conference, 2006, vol. 2, pp. 1735–1742. [9] Y . Sun, Y . Chen, X. W ang, and X. T ang, “Deep learning face representation by joint identification-verification, ” in Advances in Neural Information Processing Systems , 2014, pp. 1988–1996. [10] F . Schro, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering, ” in Pr oceedings of CVPR , 2015, pp. 815–823. [11] Y .D. W en, K.P . Zhang, Z.F . Li, and Y . Qiao, “ A discrimi- nativ e feature learning approach for deep f ace learning, ” in Pr oceedings of Eur opean Confer ence on Computer V ision , 2016. [12] W . Liu, Y . W en, Z. Y u, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition, ” in Pr oceedings of CVPR . IEEE, 2017, pp. 212–220. [13] H. W ang, Y .T . W ang, Z. Zhou, X. Ji, D.H. Gong, J.C. Zhou, Z.F . Li, and W . Liu, “Cosface: Large margin co- sine loss for deep face recognition, ” in Pr oceedings of Confer ence on Computer V ision and P attern Recogni- tion (CVPR) . IEEE, 2018. [14] S. Y adav and A. Rai, “Learning discriminative features for speaker identification and verification, ” in Proceed- ings of Conference of the International Speech Commu- nication Association . IEEE, 2018. [15] N. Li, D.Y . T uo, D. Su, Z.F . Li, and D. Y u, “Deep dis- criminativ e embeddings for duration robust speaker v er- ification, ” in INTERSPEECH . IEEE, 2018. [16] H. Liu, W . Shi, W .P . Huang, and Q. Guan, “ A discrimi- nativ ely learned feature embedding based on multi-loss fusion for person search, ” in Pr oceedings of ICASSP . IEEE, 2018. [17] A. Graves, A. Fernandez, F . Gomez, and J. Schmidhu- ber , “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural net- works, ” in Pr oceedings of the 23rd International Con- fer ence on Machine Learning . IEEE, 2006. [18] D. Po vey , D. Kanevsk y , B. Kingsbury , B. Ramabhadran, G. Saon, and K. V isweswariah, “Boosted mmi for model and feature-space discriminati ve training, ” in Pr oceed- ings of ICASSP . IEEE, 2008. [19] B. Kingsb ury , “Lattice-based optimization of sequence classification criteria for neural network acoustic mod- eling, ” in Pr oceedings of ICASSP . IEEE, 2009. [20] D. Pove y , V . Peddinti, D. Galvez, P . Ghahrmani, V . Manohar , X.Y . Na, Y .M. W ang, and S. Khudanpur, “Purely sequence-trained neural networks for asr based on lattice-free mmi, ” in INTERSPEECH . IEEE, 2016. [21] J.B. Allen and D.A. Berkley , “Image method for ef- ficiently simulation room-small acoustic, ” J ournal of the Acoustical Society of America , v ol. 65, pp. 943–950, 1979. [22] K. V esely , A. Ghoshal, L. Burget, and D Pove y , “Sequence-discriminativ e training of deep neural net- works, ” in INTERSPEECH , 2013. [23] H. Sak, O. V inyals, G. Heigold, A. Senior , E. McDer- mott, R. Monga, and M Mao, “Sequence discriminativ e distributed training of long short-term memory recurrent neural networks, ” in INTERSPEECH , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment