Speaker-Independent Speech-Driven Visual Speech Synthesis using Domain-Adapted Acoustic Models
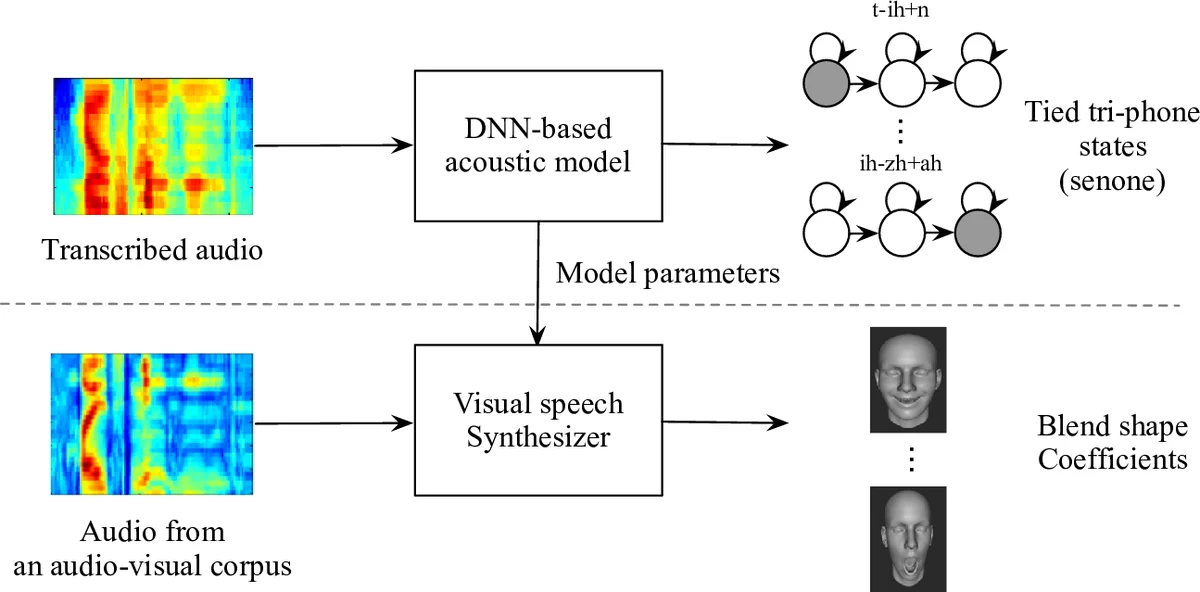
Speech-driven visual speech synthesis involves mapping features extracted from acoustic speech to the corresponding lip animation controls for a face model. This mapping can take many forms, but a powerful approach is to use deep neural networks (DNNs). However, a limitation is the lack of synchronized audio, video, and depth data required to reliably train the DNNs, especially for speaker-independent models. In this paper, we investigate adapting an automatic speech recognition (ASR) acoustic model (AM) for the visual speech synthesis problem. We train the AM on ten thousand hours of audio-only data. The AM is then adapted to the visual speech synthesis domain using ninety hours of synchronized audio-visual speech. Using a subjective assessment test, we compared the performance of the AM-initialized DNN to one with a random initialization. The results show that viewers significantly prefer animations generated from the AM-initialized DNN than the ones generated using the randomly initialized model. We conclude that visual speech synthesis can significantly benefit from the powerful representation of speech in the ASR acoustic models.
💡 Research Summary
This paper addresses the challenge of building a speaker‑independent speech‑driven visual speech synthesis system without requiring large amounts of synchronized audio‑video‑depth data. The authors propose to leverage a high‑capacity acoustic model (AM) originally trained for automatic speech recognition (ASR) on ten thousand hours of audio‑only speech. The AM is built using a standard Kaldi recipe: monophone and triphone GMM/HMM models are first trained, followed by LDA and speaker‑adaptive fMLLR transforms. The final acoustic features are 40‑dimensional log‑mel filter‑bank (LMFB) vectors extracted with a 21‑frame context window. A deep neural network with five 1024‑unit fully‑connected layers, SELU activations, a 512‑dimensional bottleneck, and a softmax output over 8,419 senones is trained first with cross‑entropy and then fine‑tuned using the sequential minimum Bayes risk (sMBR) criterion.
To adapt this AM for visual speech synthesis, the softmax layer is removed and replaced by a 32‑dimensional linear regression layer that predicts blendshape coefficients (BSCs) controlling a 3‑D face rig. All preceding layers are frozen, thereby transferring the rich speech representation learned from massive audio data to the new task. The regression layer is trained on a much smaller, but fully synchronized, multimodal corpus of ninety hours, comprising 44.1 kHz audio, 60 fps RGB video, and 30 fps depth streams. The authors also describe an automatic pipeline for generating ground‑truth BSCs: a generic 51‑blendshape model is personalized per subject using example expressions, 2‑D facial landmarks are detected with a CNN, depth maps are aligned via ICP with point‑plane constraints, and the final blendshape weights are obtained by minimizing a combined depth‑to‑mesh, landmark, and L1 sparsity objective using a Gauss‑Seidel solver.
Because the acoustic model operates at 100 fps while the video is at 60 fps, the authors down‑sample senone labels and extract LMFB features with a 16.67 ms hop size, resulting in a longer temporal context (≈350 ms) for the 60 fps configuration. Experiments show that the 60 fps AM achieves higher frame accuracy (≈70 % vs. 66 % for 100 fps) under both CE and sMBR losses, confirming the benefit of the larger context window. Objective mean absolute error (MAE) between predicted and ground‑truth BSCs is virtually identical for the AM‑initialized network and a network trained from random initialization. However, a subjective listening‑viewing test with 30 participants and 30 random utterances reveals a clear preference for the AM‑initialized system: viewers consistently judged its lip motions to match the speech more naturally.
The study demonstrates that a massive, audio‑only ASR model provides a powerful prior for visual speech synthesis, enabling high‑quality, speaker‑independent lip animation with only modest amounts of multimodal data. Limitations include the inability to capture non‑speech facial dynamics (e.g., smiles) and the reliance on a relatively small synchronized dataset for fine‑tuning. Future work is suggested to explore multimodal pre‑training, generative adversarial or variational models for richer facial expression synthesis, and real‑time deployment scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment