Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
Single-channel, speaker-independent speech separation methods have recently seen great progress. However, the accuracy, latency, and computational cost of such methods remain insufficient. The majority of the previous methods have formulated the sepa…
Authors: Yi Luo, Nima Mesgarani
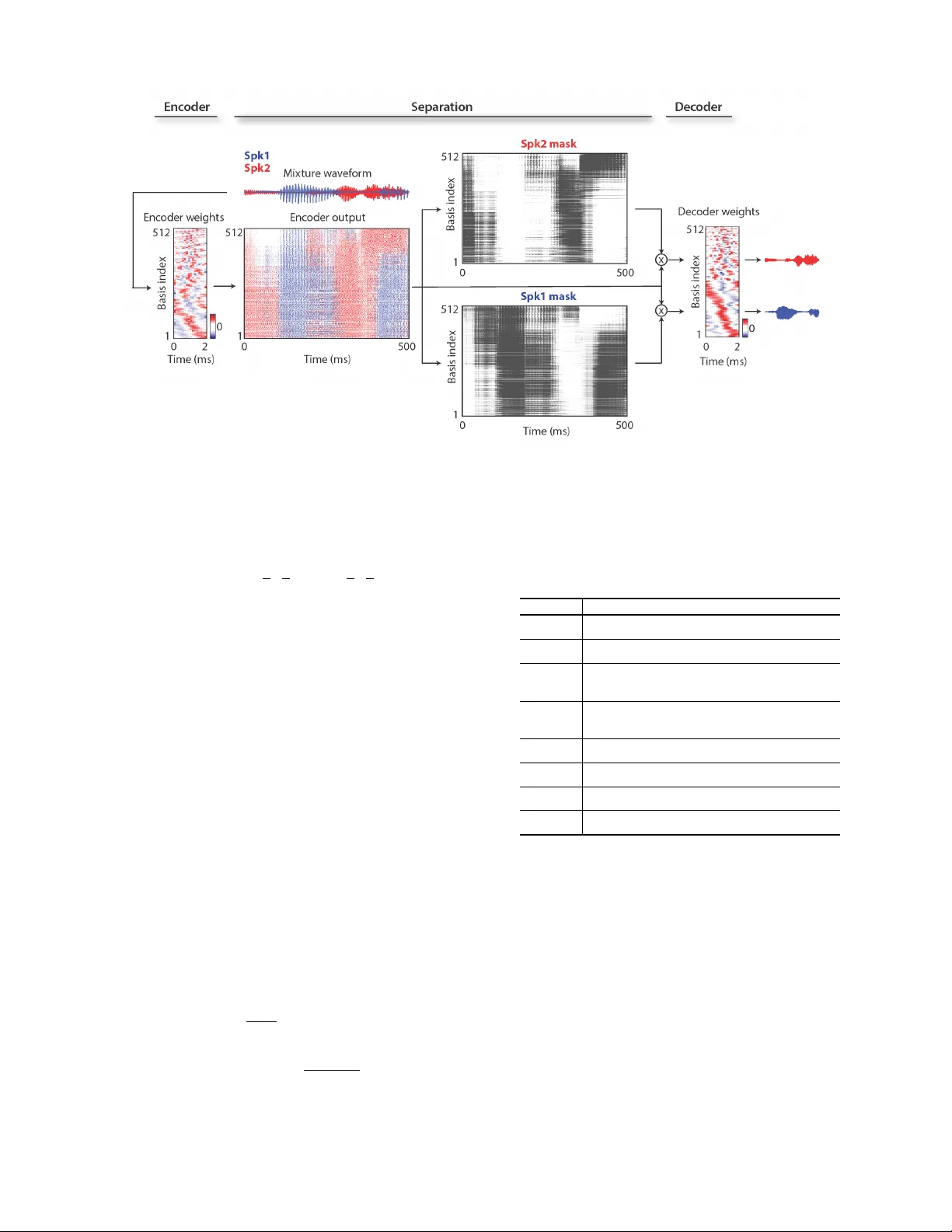
1 Con v-T asNet: Surpassing Ideal T ime-Frequency Magnitude Masking for Speech Separation Y i Luo, Nima Mesgarani Abstract —Single-channel, speaker -independent speech sepa- ration methods ha ve recently seen great progress. Howev er , the accuracy , latency , and computational cost of such methods remain insufficient. The majority of the previous methods have formulated the separation problem through the time-frequency repr esentation of the mixed signal, which has several drawbacks, including the decoupling of the phase and magnitude of the signal, the suboptimality of time-frequency r epresentation f or speech separation, and the long latency in calculating the spectrograms. T o address these shortcomings, we propose a fully-con volutional time-domain audio separation network (Con v-T asNet), a deep learning framework for end-to-end time-domain speech separa- tion. Con v-T asNet uses a linear encoder to generate a r epresenta- tion of the speech wa vef orm optimized for separating individual speakers. Speaker separation is achiev ed by applying a set of weighting functions (masks) to the encoder output. The modified encoder repr esentations are then in verted back to the wavef orms using a linear decoder . The masks are f ound using a temporal con volutional network (TCN) consisting of stacked 1-D dilated con volutional blocks, which allows the network to model the long-term dependencies of the speech signal while maintaining a small model size. The proposed Conv-T asNet system signifi- cantly outperforms previous time-frequency masking methods in separating two- and three-speaker mixtures. Additionally , Conv- T asNet surpasses sev eral ideal time-frequency magnitude masks in two-speaker speech separation as ev aluated by both objective distortion measures and subjective quality assessment by human listeners. Finally , Con v-T asNet has a significantly smaller model size and a shorter minimum latency , making it a suitable solution for both offline and r eal-time speech separation applications. This study therefor e represents a major step toward the realization of speech separation systems for real-world speech processing technologies. Index T erms —Source separation, single-channel, time-domain, deep learning, real-time I . I N T RO D U C T I O N Robust speech processing in real-world acoustic en viron- ments often requires automatic speech separation. Because of the importance of this research topic for speech processing technologies, numerous methods have been proposed for solv- ing this problem. Howe ver , the accurac y of speech separation, particularly for new speakers, remains inadequate. Most previous speech separation approaches hav e been formulated in the time-frequency (T -F , or spectrogram) rep- resentation of the mixture signal, which is estimated from the wa veform using the short-time Fourier transform (STFT) [1]. Speech separation methods in the T -F domain aim to approx- imate the clean spectrogram of the individual sources from the mixture spectrogram. This process can be performed by directly approximating the spectrogram representation of each source from the mixture using nonlinear regression techniques, where the clean source spectrograms are used as the training target [2]–[4]. Alternativ ely , a weighting function (mask) can be estimated for each source to multiply each T -F bin in the mixture spectrogram to recov er the individual sources. In recent years, deep learning has greatly adv anced the perfor- mance of time-frequency masking methods by increasing the accuracy of the mask estimation [5]–[12]. In both the direct method and the mask estimation method, the wa veform of each source is calculated using the in verse short-time Fourier transform (iSTFT) of the estimated magnitude spectrogram of each source together with either the original or the modified phase of the mixture sound. While time-frequency masking remains the most commonly used method for speech separation, this method has sev eral shortcomings. First, STFT is a generic signal transformation that is not necessarily optimal for speech separation. Second, accurate reconstruction of the phase of the clean sources is a nontri vial problem, and the erroneous estimation of the phase introduces an upper bound on the accuracy of the reconstructed audio. This issue is evident by the imperfect reconstruction accuracy of the sources ev en when the ideal clean magnitude spectrograms are applied to the mixture. Although methods for phase reconstruction can be applied to alleviate this issue [11], [13], [14], the performance of the method remains suboptimal. Third, successful separation from the time-frequency representation requires a high-resolution frequency decomposition of the mixture signal, which requires a long temporal window for the calculation of STFT . This requirement increases the minimum latency of the system, which limits its applicability in real-time, low-latenc y appli- cations such as in telecommunication and hearable devices. For e xample, the window length of STFT in most speech separation systems is at least 32 ms [5], [7], [8] and is e ven greater in music separation applications, which require an e ven higher resolution spectrogram (higher than 90 ms) [15], [16]. Because these issues arise from formulating the separation problem in the time-frequency domain, a logical approach is to a void decoupling the magnitude and the phase of the sound by directly formulating the separation in the time domain. Previous studies have explored the feasibility of time-domain speech separation through methods such as independent com- ponent analysis (ICA) [17] and time-domain non-negativ e matrix factorization (NMF) [18]. Howe ver , the performance of these systems has not been comparable with the performance of time-frequency approaches, particularly in terms of their ability to scale and generalize to large data. On the other hand, a few recent studies have explored deep learning for time-domain audio separation [19]–[21]. The shared idea in all 2 these systems is to replace the STFT step for feature extraction with a data-driven representation that is jointly optimized with an end-to-end training paradigm. These representations and their inv erse transforms can be explicitly designed to replace STFT and iSTFT . Alternatively , feature e xtraction together with separation can be implicitly incorporated into the network architecture, for example by using an end-to-end conv olutional neural network (CNN) [22], [23]. These methods are different in how they extract features from the wa veform and in terms of the design of the separation module. In [19], a con volutional encoder moti vated by discrete cosine transform (DCT) is used as the front-end. The separation is then performed by passing the encoder features to a multilayer perceptron (MLP). The reconstruction of the wa veforms is achieved by in verting the encoder operation. In [20], the separation is incorporated into a U-Net 1-D CNN architecture [24] without explicitly transforming the input into a spectrogram-like representation. Howe ver , the performance of these methods on a large speech corpus such as the benchmark introduced in [25] has not been tested. Another such method is the time-domain audio separation network (T asNet) [21], [26]. In T asNet, the mixture wa veform is modeled with a con volutional encoder-decoder ar- chitecture, which consists of an encoder with a non-negati vity constraint on its output and a linear decoder for in verting the encoder output back to the sound wa veform. This frame work is similar to the ICA method when a non-ne gati ve mixing matrix is used [27] and to the semi-nonnegati ve matrix factorization method (semi-NMF) [28], where the basis signals are the parameters of the decoder . The separation step in T asNet is done by finding a weighting function for each source (similar to time-frequency masking) for the encoder output at each time step. It has been shown that T asNet has achieved better or comparable performance with various pre vious T -F domain systems, showing its effecti veness and potential. While T asNet outperformed previous time-frequenc y speech separation methods in both causal and non-causal implemen- tations, the use of a deep long short-term memory (LSTM) network as the separation module in the original T asNet signif- icantly limited its applicability . First, choosing smaller kernel size (i.e. length of the wav eform segments) in the encoder increases the length of the encoder output, which makes the training of the LSTMs unmanageable. Second, the large number of parameters in deep LSTM network significantly increases its computational cost and limits its applicability to low-resource, low-po wer platforms such as wearable hearing devices. The third problem which we will illustrate in this paper is caused by the long temporal dependencies of LSTM networks which often results in inconsistent separation accu- racy , for example, when changing the starting point of the mixture. T o alleviate the limitations of the previous T asNet, we propose the fully-conv olutional T asNet (Con v-T asNet) that uses only con volutional layers in all stages of processing. Motiv ated by the success of temporal con volutional network (TCN) models [29]–[31], Conv-T asNet uses stacked dilated 1- D con volutional blocks to replace the deep LSTM networks for the separation step. The use of conv olution allo ws parallel processing on consecutive frames or segments to greatly speed up the separation process and also significantly reduces the model size. T o further decrease the number of parameters and the computational cost, we substitute the original con volution operation with depthwise separable conv olution [32], [33]. W e show that with these modifications, Con v-T asNet signif- icantly increases the separation accuracy over the previous LSTM-T asNet in both causal and non-causal implementations. Moreov er , the separation accuracy of Conv-T asNet surpasses the performance of ideal time-frequency magnitude masks, including the ideal binary mask (IBM [34]), ideal ratio mask (IRM [35], [36]), and Winener filter -like mask (WFM [37]) in both signal-to-distortion ratio (SDR) and subjectiv e (mean opinion score, MOS) measures. The rest of the paper is organized as follows. W e introduce the proposed Conv-T asNet in section II, describe the experi- mental procedures in section III, and sho w the experimental results and analysis in section IV. I I . C O N V O LU T I O N A L T I M E - D O M A I N A U D I O S E PAR AT I O N N E T W O R K The fully-con volutional time-domain audio separation net- work (Con v-T asNet) consists of three processing stages, as shown in figure 1 (A): encoder, separation, and decoder . First, an encoder module is used to transform short segments of the mixture wav eform into their corresponding representations in an intermediate feature space. This representation is then used to estimate a multiplicativ e function (mask) for each source at each time step. The source wa veforms are then reconstructed by transforming the masked encoder features using a decoder module. W e describe the details of each stage in this section. A. T ime-domain speech separation The problem of single-channel speech separation can be formulated in terms of estimating C sources s 1 ( t ) , . . . , s c ( t ) ∈ R 1 × T , given the discrete wav eform of the mixture x ( t ) ∈ R 1 × T , where x ( t ) = C X i =1 s i ( t ) (1) In time-domain audio separation, we aim to directly estimate s i ( t ) , i = 1 , . . . , C , from x ( t ) . B. Convolutional encoder-decoder The input mixture sound can be divided into ov erlapping segments of length L , represented by x k ∈ R 1 × L , where k = 1 , . . . , ˆ T denotes the segment index and ˆ T denotes the total number of segments in the input. x k is transformed into a N - dimensional representation, w ∈ R 1 × N by a 1-D con volution operation, which is reformulated as a matrix multiplication (the index k is dropped from no w on): w = H ( xU ) (2) where U ∈ R N × L contains N vectors (encoder basis func- tions) with length L each, and H ( · ) is an optional nonlinear function. In [21], [26], H ( · ) was the rectified linear unit (ReLU) to ensure that the representation is non-negati ve. The decoder reconstructs the waveform from this representation 3 Fig. 1. (A): the block diagram of the T asNet system. An encoder maps a segment of the mixture waveform to a high-dimensional representation and a separation module calculates a multiplicativ e function (i.e., a mask) for each of the target sources. A decoder reconstructs the source wa veforms from the masked features. (B): A flowchart of the proposed system. A 1-D convolutional autoencoder models the wav eforms and a temporal con volutional network (TCN) separation module estimates the masks based on the encoder output. Different colors in the 1-D conv olutional blocks in TCN denote different dilation factors. (C): The design of 1-D conv olutional block. Each block consists of a 1 × 1 - conv operation followed by a depthwise conv olution ( D − conv ) operation, with nonlinear acti vation function and normalization added between each two con volution operations. T wo linear 1 × 1 − conv blocks serve as the residual path and the skip-connection path respectively . using a 1-D transposed con volution operation, which can be reformulated as another matrix multiplication: ˆ x = w V (3) where ˆ x ∈ R 1 × L is the reconstruction of x , and the rows in V ∈ R N × L are the decoder basis functions, each with length L . The overlapping reconstructed se gments are summed together to generate the final wav eforms. Although we reformulate the encoder/decoder operations as matrix multiplication, the term ”con volutional autoencoder” is used because in actual model implementation, conv olutional and transposed con volutional layers can more easily handle the overlap between segments and thus enable faster training and better con ver gence. 1 C. Estimating the separ ation masks The separation for each frame is performed by estimating C vectors (masks) m i ∈ R 1 × N , i = 1 , . . . , C where C is the number of speakers in the mixture that is multiplied by the encoder output w . The mask vectors m i hav e the constraint 1 W ith our Pytorch implementation, this is possibly due to the dif ferent auto- grad mechanisms in fully-connected layer and 1-D (transposed) con volutional layers. that m i ∈ [0 , 1] . The representation of each source, d i ∈ R 1 × N , is then calculated by applying the corresponding mask, m i , to the mixture representation w : d i = w m i (4) where denotes element-wise multiplication. The wav eform of each source ˆ s i , i = 1 , . . . , C is then reconstructed by the decoder: ˆ s i = d i V (5) The unit summation constraint in [21], [26], P C i =1 m i = 1 , was applied based on the assumption that the encoder -encoder architecture can perfectly reconstruct the input mixture. In section IV -A, we will examine the consequence of relaxing this unity summation constraint on separation accuracy . D. Convolutional separation module Motiv ated by the temporal conv olutional network (TCN) [29]–[31], we propose a fully-con volutional separation module that consists of stacked 1-D dilated con volutional blocks, as shown in figure 1 (B). TCN was proposed as a replacement for RNNs in various sequence modeling tasks. Each layer in a TCN consists of 1-D con volutional blocks with increasing 4 dilation factors. The dilation factors increase exponentially to ensure a sufficiently large temporal context window to take advantage of the long-range dependencies of the speech signal, as denoted with different colors in figure 1 (B). In Con v-T asNet, M con volutional blocks with dilation factors 1 , 2 , 4 , . . . , 2 M − 1 are repeated R times. The input to each block is zero padded accordingly to ensure the output length is the same as the input. The output of the TCN is passed to a conv olutional block with kernel size 1 ( 1 × 1 − conv block, also kno wn as pointwise con volution) for mask estimation. The 1 × 1 − conv block together with a nonlinear activ ation function estimates C mask vectors for the C target sources. Figure 1 (C) sho ws the design of each 1-D conv olutional block. The design of the 1-D con volutional blocks follo ws [38], where a residual path and a skip-connection path are applied: the residual path of a block serves as the input to the next block, and the skip-connection paths for all blocks are summed up and used as the output of the TCN. T o further decrease the number of parameters, depthwise separable con- volution ( S - conv ( · ) ) is used to replace standard con volution in each conv olutional block. Depthwise separable con volution (also referred to as separable con volution) has proven effecti ve in image processing tasks [32], [33] and neural machine translation tasks [39]. The depthwise separable con volution operator decouples the standard con volution operation into two consecutiv e operations, a depthwise con volution ( D - conv ( · ) ) followed by pointwise conv olution ( 1 × 1 − conv ( · ) ): D - conv ( Y , K ) = concat ( y j ~ k j ) , j = 1 , . . . , N (6) S - conv ( Y , K , L ) = D - conv ( Y , K ) ~ L (7) where Y ∈ R G × M is the input to S - conv ( · ) , K ∈ R G × P is the con volution kernel with size P , y j ∈ R 1 × M and k j ∈ R 1 × P are the rows of matrices Y and K , respectiv ely , L ∈ R G × H × 1 is the con volution kernel with size 1, and ~ denotes the con volution operation. In other words, the D - conv ( · ) operation con volv es each ro w of the input Y with the corresponding row of matrix K , and the 1 × 1 − conv block linearly transforms the feature space. In comparison with the standard conv olution with kernel size ˆ K ∈ R G × H × P , depthwise separable conv olution only contains G × P + G × H parameters, which decreases the model size by a factor of H × P H + P ≈ P when H P . A nonlinear acti v ation function and a normalization oper- ation are added after both the first 1 × 1 - conv and D - conv blocks respecti vely . The nonlinear activ ation function is the parametric rectified linear unit (PReLU) [40]: P ReLU ( x ) = ( x, if x ≥ 0 αx, otherwise (8) where α ∈ R is a trainable scalar controlling the negati ve slope of the rectifier . The choice of the normalization method in the network depends on the causality requirement. For noncausal configuration, we found empirically that global layer normalization (gLN) outperforms all other normalization methods. In gLN, the feature is normalized over both the channel and the time dimensions: g LN ( F ) = F − E [ F ] p V ar [ F ] + γ + β (9) E [ F ] = 1 N T X N T F (10) V ar [ F ] = 1 N T X N T ( F − E [ F ]) 2 (11) where F ∈ R N × T is the feature, γ , β ∈ R N × 1 are trainable parameters, and is a small constant for numerical stability . This is identical to the standard layer normalization applied in computer vision models where the channel and time dimension correspond to the width and height dimension in an image [41]. In causal configuration, gLN cannot be applied since it relies on the future values of the signal at any time step. Instead, we designed a cumulativ e layer normalization (cLN) operation to perform step-wise normalization in the causal system: cLN ( f k ) = f k − E [ f t ≤ k ] p V ar [ f t ≤ k ] + γ + β (12) E [ f t ≤ k ] = 1 N k X N k f t ≤ k (13) V ar [ f t ≤ k ] = 1 N k X N k ( f t ≤ k − E [ f t ≤ k ]) 2 (14) where f k ∈ R N × 1 is the k -th frame of the entire feature F , f t ≤ k ∈ R N × k corresponds to the feature of k frames [ f 1 , . . . , f k ] , and γ , β ∈ R N × 1 are trainable parameters applied to all frames. T o ensure that the separation module is in variant to the scaling of the input, the selected normalization method is applied to the encoder output w before it is passed to the separation module. At the beginning of the separation module, a linear 1 × 1 - conv block is added as a bottleneck layer . This block determines the number of channels in the input and residual path of the subsequent con volutional blocks. F or instance, if the linear bottleneck layer has B channels, then for a 1-D con volutional block with H channels and kernel size P , the size of the kernel in the first 1 × 1 - conv block and the first D - conv block should be O ∈ R B × H × 1 and K ∈ R H × P respectiv ely , and the size of the kernel in the residual paths should be L Rs ∈ R H × B × 1 . The number of output channels in the skip-connection path can be different than B , and we denote the size of kernels in that path as L S c ∈ R H × S c × 1 . I I I . E X P E R I M E N TA L P R O C E DU R E S A. Dataset W e e valuated our system on two-speak er and three-speaker speech separation problems using the WSJ0-2mix and WSJ0- 3mix datasets [25]. 30 hours of training and 10 hours of validation data are generated from speakers in si tr s from the datasets. The speech mixtures are generated by randomly selecting utterances from different speakers in the W all Street Journal dataset (WSJ0) and mixing them at random signal- to-noise ratios (SNR) between -5 dB and 5 dB. 5 hours of 5 Fig. 2. V isualization of the encoder and decoder basis functions, encoder representation, and source masks for a sample 2-speaker mixture. The speakers are shown in red and blue. The encoder representation is colored according to the po wer of each speaker at each basis function and point in time. The basis functions are sorted according to their Euclidean similarity and show diversity in frequency and phase tuning. ev aluation set is generated in the same way using utterances from 16 unseen speakers in si dt 05 and si et 05. The scripts for creating the dataset can be found at [42]. All the wa veforms are resampled at 8 kHz. B. Experiment configurations The networks are trained for 100 epochs on 4-second long segments. The initial learning rate is set to 1 e − 3 . The learning rate is halv ed if the accurac y of v alidation set is not improved in 3 consecutiv e epochs. Adam [43] is used as the optimizer . A 50% stride size is used in the con volutional autoencoder (i.e. 50% ov erlap between consecuti ve frames). Gradient clipping with maximum L 2 -norm of 5 is applied during training. The hyperparameters of the network are sho wn in table I. A Pytorch implementation of the Con v-T asNet model can be found at 2 . C. T raining objective The objective of training the end-to-end system is max- imizing the scale-in variant source-to-noise ratio (SI-SNR), which has commonly been used as the ev aluation metric for source separation replacing the standard source-to-distortion ratio (SDR) [5], [9], [44]. SI-SNR is defined as: s targ et := h ˆ s , s i s k s k 2 e noise := ˆ s − s targ et SI-SNR := 10 log 10 k s targ et k 2 k e noise k 2 (15) where ˆ s ∈ R 1 × T and s ∈ R 1 × T are the estimated and original clean sources, respectively , and k s k 2 = h s , s i denotes the 2 https://github .com/naplab/Con v-T asNet T ABLE I H Y PE R PAR A M E TE R S O F TH E N E TW O R K . Symbol Description N Number of filters in autoencoder L Length of the filters (in samples) B Number of channels in bottleneck and the residual paths’ 1 × 1 - conv blocks S c Number of channels in skip-connection paths’ 1 × 1 - conv blocks H Number of channels in con volutional blocks P Kernel size in conv olutional blocks X Number of conv olutional blocks in each repeat R Number of repeats signal power . Scale in variance is ensured by normalizing ˆ s and s to zero-mean prior to the calculation. Utterance-lev el permutation in variant training (uPIT) is applied during training to address the source permutation problem [7]. D. Evaluation metrics W e report the scale-in variant signal-to-noise ratio improve- ment (SI-SNRi) and signal-to-distortion ratio improvement (SDRi) [44] as objectiv e measures of separation accuracy . SI- SNR is defined in equation 15. The reported improvements in tables III to V indicate the additiv e v alues ov er the original mixture. In addition to the distortion metrics, we also ev aluated the quality of the separated mixtures using both the perceptual ev aluation of subjectiv e quality (PESQ, [45]) and the mean opinion score (MOS) [46] by asking 40 normal hearing sub- 6 jects to rate the quality of the separated mixtures. All human testing procedures were approved by the local institutional revie w board (IRB) at Columbia Univ ersity in the City of New Y ork. E. Comparison with ideal time-fr equency masks Follo wing the common configurations in [5], [7], [9], the ideal time-frequency masks were calculated using STFT with a 32 ms window size and 8 ms hop size with a Hanning window . The ideal masks include the ideal binary mask (IBM), ideal ratio mask (IRM), and W iener filter -like mask (WFM), which are defined for source i as: I B M i ( f , t ) = ( 1 , |S i ( f , t ) | > |S j 6 = i ( f , t ) | 0 , otherwise (16) I RM i ( f , t ) = |S i ( f , t ) | P C j =1 |S j ( f , t ) | (17) W F M i ( f , t ) = |S i ( f , t ) | 2 P C j =1 |S j ( f , t ) | 2 (18) where S i ( f , t ) ∈ C F × T are the complex-v alued spectro- grams of clean sources i = 1 , . . . , C . I V . R E S U LTS Figure 2 visualizes all the internal variables of Conv- T asNet for one example mixture sound with two ov erlapping speakers (denoted by red and blue). The encoder and decoder basis functions are sorted by the similarity of the Euclidean distance of the basis functions found using the unweighted pair group method with arithmetic mean (UPGMA) method [47]. The basis functions show a div ersity of frequency and phase tuning. The representation of the encoder is colored according to the power of each speaker at the corresponding basis output at each time point, demonstrating the sparsity of the encoder representation. As can be seen in figure 2, the estimated masks for the two speakers highly resemble their encoder representations, which allo ws for the suppression of the encoder outputs that correspond to the interfering speaker and the extraction of the target speaker in each mask. The separated waveforms for the two speakers are estimated by the linear decoder, whose basis functions are shown in figure 2. The separated wav eforms are sho wn on the right. A. Non-negativity of the encoder output The non-negati vity of the encoder output was enforced in [21], [26] using a rectified-linear nonlinearity (ReLU) function. This constraint was based on the assumption that the masking operation on the encoder output is only meaningful when the mixture and speaker wav eforms can be represented with a non-neg ativ e combination of the basis functions, since an unbounded encoder representation may result in unbounded masks. Howe ver , by removing the nonlinear function H , another assumption can be made: with an unbounded but highly overcomplete representation of the mixture, a set of non-negati ve masks can still be found to reconstruct the clean sources. In this case, the overcompleteness of the representa- tion is crucial. If there exist only a unique weight feature for the mixture as well as for the sources, the non-negati vity of the mask cannot be guaranteed. Also note that in both assump- tions, we put no constraint on the relationship between the encoder and decoder basis functions U and V , meaning that they are not forced to reconstruct the mixture signal perfectly . One way to explicitly ensure the autoencoder property is by choosing V to be the pseudo-in verse of U (i.e. least square reconstruction). The choice of encoder/decoder design af fects the mask estimation: in the case of an autoencoder , the unit summation constraint must be satisfied; otherwise, the unit summation constraint is not strictly required. T o illustrate this point, we compared fi ve different encoder -decoder configura- tions: 1) Linear encoder with its pseudo-in verse (Pin v) as decoder , i.e. w = x ( V T V ) − 1 V T and ˆ x = w V , with Softmax function for mask estimation. 2) Linear encoder and decoder where w = xU and ˆ x = wV , with Softmax or Sigmoid function for mask estimation. 3) Encoder with ReLU activ ation and linear decoder where w = ReLU ( xU ) and ˆ x = w V , with Softmax or Sigmoid function for mask estimation. Separation accuracy of different configurations in table III shows that pseudo-in verse autoencoder leads to the worst performance, indicating that an explicit autoencoder config- uration does not necessarily impro ve the separation score in this frame work. The performance of all other configurations is comparable. Because linear encoder and decoder with Sigmoid function achiev es a slightly better accuracy over other methods, we used this configuration in all the following experiments. B. Optimizing the network parameter s W e ev aluate the performance of Conv-T asNet on two speaker separation tasks as a function of dif ferent network parameters. T able II shows the performance of the systems with different parameters, from which we can conclude the following statements: (i) Encoder/decoder: Increasing the number of basis signals in the encoder/decoder increases the overcompleteness of the basis signals and improves the performance. (ii) Hyperparameters in the 1-D con volutional blocks: A possible configuration consists of a small bottleneck size B and a large number of channels in the con- volutional blocks H . This matches the observ ation in [48], where the ratio between the conv olutional block and the bottleneck H /B was found to be best around 5. Increasing the number of channels in the skip-connection block improves the performance while greatly increases the model size. Therefore, we selected a small skip- connection block as a trade-off between performance and model size. (iii) Number of 1-D conv olutional blocks: When the receptive field is the same, deeper networks lead to better perfor- mance, possibly due to the increased model capacity . 7 T ABLE II T H E E FF EC T O F D I FF ER E N T C O N FIG U R A T I O NS I N C O NV - T A S N ET . N L B H S c P X R Normali- zation Causal Receptiv e field (s) Model size SI-SNRi (dB) SDRi (dB) 128 40 128 256 128 3 7 2 gLN × 1.28 1.5M 13.0 13.3 256 40 128 256 128 3 7 2 gLN × 1.28 1.5M 13.1 13.4 512 40 128 256 128 3 7 2 gLN × 1.28 1.7M 13.3 13.6 512 40 128 256 256 3 7 2 gLN × 1.28 2.4M 13.0 13.3 512 40 128 512 128 3 7 2 gLN × 1.28 3.1M 13.3 13.6 512 40 128 512 512 3 7 2 gLN × 1.28 6.2M 13.5 13.8 512 40 256 256 256 3 7 2 gLN × 1.28 3.2M 13.0 13.3 512 40 256 512 256 3 7 2 gLN × 1.28 6.0M 13.4 13.7 512 40 256 512 512 3 7 2 gLN × 1.28 8.1M 13.2 13.5 512 40 128 512 128 3 6 4 gLN × 1.27 5.1M 14.1 14.4 512 40 128 512 128 3 4 6 gLN × 0.46 5.1M 13.9 14.2 512 40 128 512 128 3 8 3 gLN × 3.83 5.1M 14.5 14.8 512 32 128 512 128 3 8 3 gLN × 3.06 5.1M 14.7 15.0 512 16 128 512 128 3 8 3 gLN × 1.53 5.1M 15.3 15.6 512 16 128 512 128 3 8 3 cLN X 1.53 5.1M 10.6 11.0 T ABLE III S E P A R A T I ON S C O RE F O R D I FF E RE N T S Y S TE M C O N FIG U R A T I O NS . Encoder Mask Model size SI-SNRi (dB) SDRi (dB) Pin v Softmax 1.5M 12.1 12.4 Linear Softmax 12.9 13.2 Sigmoid 13.1 13.4 ReLU Softmax 13.0 13.3 Sigmoid 12.9 13.2 (iv) Size of receptiv e field: Increasing the size of receptiv e field leads to better performance, which shows the im- portance of modeling the temporal dependencies in the speech signal. (v) Length of each segment: Shorter segment length consis- tently improv es performance. Note that the best system uses a filter length of only 2 ms ( L f s = 16 8000 = 0 . 002 s ), which makes it very difficult to train a deep LSTM network with the same L due to the large number of time steps in the encoder output. (vi) Causality: Using a causal configuration leads to a signif- icant drop in the performance. This drop could be due to the causal con volution and/or the layer normalization operations. C. Comparison of Con v-T asNet with pre vious methods W e compared the separation accuracy of Con v-T asNet with previous methods using SDRi and SI-SNRi. T able IV com- pares the performance of Conv-T asNet with other state-of-the- art methods on the same WSJ0-2mix dataset. For all systems, we list the best results that have been reported in the literature. The numbers of parameters in different methods are based on our implementations, except for [12] which is provided by the authors. The missing values in the table are either because the numbers were not reported in the study or because the results were calculated with a different STFT configuration. The pre vious T asNet in [26] is denoted by the (B)LSTM- T asNet. While the BLSTM-T asNet already outperformed IRM and IBM, the non-causal Con v-T asNet significantly surpasses the performance of all three ideal T -F masks in SI-SNRi and SDRi metrics with a significantly smaller model size comparing with all previous methods. T able V compares the performance of Conv-T asNet with those of other systems on a three-speaker speech separation task in volving the WSJ0-3mix dataset. The non-causal Conv- T asNet system significantly ou tperforms all previous STFT - based systems in SDRi. While there is no prior result on a causal algorithm for three-speaker separation, the causal Con v- T asNet significantly outperforms even the other tw o non-causal STFT -based systems [5], [7]. Examples of separated audio for two and three speaker mixtures from both causal and non- causal implementations of Conv-T asNet are av ailable online [49]. T ABLE IV C O MPA R IS O N W I T H OT H E R M E T HO D S O N W S J 0- 2 M I X DAT A S E T . Method Model size Causal SI-SNRi (dB) SDRi (dB) DPCL++ [5] 13.6M × 10.8 – uPIT -BLSTM-ST [7] 92.7M × – 10.0 D ANet [8] 9.1M × 10.5 – AD ANet [9] 9.1M × 10.4 10.8 cuPIT -Grid-RD [50] 47.2M × – 10.2 CBLDNN-GA T [12] 39.5M × – 11.0 Chimera++ [10] 32.9M × 11.5 12.0 W A-MISI-5 [11] 32.9M × 12.6 13.1 BLSTM-T asNet [26] 23.6M × 13.2 13.6 Con v-T asNet-gLN 5.1M × 15.3 15.6 uPIT -LSTM [7] 46.3M X – 7.0 LSTM-T asNet [26] 32.0M X 10.8 11.2 Con v-T asNet-cLN 5.1M X 10.6 11.0 IRM – – 12.2 12.6 IBM – – 13.0 13.5 WFM – – 13.4 13.8 8 T ABLE V C O MPA R IS O N W I T H OT H E R S Y S TE M S O N W S J 0- 3 M I X DAT A S E T . Method Model size Causal SI-SNRi (dB) SDRi (dB) DPCL++ [5] 13.6M × 7.1 – uPIT -BLSTM-ST [7] 92.7M × – 7.7 D ANet [8] 9.1M × 8.6 8.9 AD ANet [9] 9.1M × 9.1 9.4 Con v-T asNet-gLN 5.1M × 12.7 13.1 Con v-T asNet-cLN 5.1M X 7.8 8.2 IRM – – 12.5 13.0 IBM – – 13.2 13.6 WFM – – 13.6 14.0 D. Subjective and objective quality evaluation of Con v-T asNet In addition to SDRi and SI-SNRi, we ev aluated the sub- jectiv e and objective quality of the separated speech and compared with three ideal time-frequenc y magnitude masks. T able VI shows the PESQ score for Con v-T asNet and IRM, IBM, and WFM, where IRM has the highest score for both WSJ0-2mix and WSJ0-3mix dataset. Howe ver , since PESQ aims to predict the subjecti ve quality of speech, human quality ev aluation can be considered as the ground truth. Therefore, we conducted a psychophysics experiment in which we asked 40 normal hearing subjects to listen and rate the quality of the separated speech sounds. Because of the practical limita- tions of human psychophysics experiments, we restricted the subjectiv e comparison of Con v-T asNet to the ideal ratio mask (IRM) which has the highest PESQ score among the three ideal masks (table VI). W e randomly chose 25 two-speaker mixture sounds from the two-speaker test set (WSJ0-2mix). W e av oided a possible selection bias by ensuring that the av erage PESQ scores for the IRM and Con v-T asNet separated sounds for the selected 25 samples were equal to the average PESQ scores ov er the entire test set (comparison of tables VI and VII). The length of each utterance was constrained to be within 0.5 standard deviation of the mean of the entire test set. The subjects were asked to rate the quality of the clean utterances, the IRM-separated utterances, and the Con v-T asNet separated utterances on the scale of 1 to 5 (1: bad, 2: poor , 3: fair , 4: good, 5: excellent). A clean utterance was first given as the reference for the highest possible score (i.e. 5). Then the clean, IRM, and Con v-T asNet samples were presented to the subjects in random order . The mean opinion score (MOS) of each of the 25 utterances was then a veraged over the 40 subjects. Figure 3 and table VII show the result of the human subjectiv e quality test, where the MOS for Conv-T asNet is significantly higher than the MOS for the IRM ( p < 1 e − 16 , t-test). In addition, the superior subjectiv e quality of Conv- T asNet over IRM is consistent across most of the 25 test utterances as sho wn in figure 3 (C). This observation sho ws that PESQ consistently underestimates MOS for Conv-T asNet separated utterances, which may be due to the dependence of PESQ on the magnitude spectrogram of speech [45] which could produce lower scores for time-domain approaches. T ABLE VI P E SQ S C O RE S F O R T H E I D E AL T-F M A S KS A N D C O N V - T AS N E T O N T H E E N TI R E W S J 0 -2 M I X A N D W S J 0- 3 M I X T E ST S E T S . Dataset PESQ IRM IBM WFM Con v-T asNet WSJ0-2mix 3.74 3.33 3.70 3.24 WSJ0-3mix 3.52 2.91 3.45 2.61 T ABLE VII M E AN O P I NI O N S C O R E ( M OS , N = 4 0) A N D P E S Q F O R T H E 2 5 S E L EC T E D U T TE R A N CE S F RO M T H E W S J 0- 2 M I X T E ST S E T . Method MOS PESQ Con v-T asNet-gLN 4.03 3.22 IRM 3.51 3.74 Clean 4.23 4.5 E. Processing speed comparison T able VIII compares the processing speed of LSTM-T asNet and causal Conv-T asNet. The speed is ev aluated as the av erage processing time for the systems to separate each frame in the mixtures, which we refer to as time per frame (TPF). TPF determines whether a system can be implemented in real time, which requires a TPF that is smaller than the frame length. For the CPU configuration, we tested the system with one processor on an Intel Core i7-5820K CPU. For the GPU configuration, we preloaded both the systems and the data to a Nvidia T itan Xp GPU. LSTM-T asNet with CPU configuration has a TPF close to its frame length (5 ms), which is only marginally acceptable in applications where only a slower CPU is av ailable. Moreov er , the processing in LSTM-T asNet is done sequentially , which means that the processing of each time frame must wait for the completion of the previous time frame, further increasing the total processing time of the entire utterance. Since Con v-T asNet decouples the processing of consecutiv e frames, the processing of subsequent frames does not have to wait until the completion of the current frame and allows the possibility of parallel computing. This process leads to a TPF that is 5 times smaller than the frame length (2 ms) in our CPU configuration. Therefore, e ven with slower CPUs, Con v-T asNet can still perform real-time separation. T ABLE VIII P RO C ES S I N G T I ME F O R C AU S A L L S TM - T A S N E T A N D C O N V - T A S N E T . T H E S P EE D I S E V A L UATE D A S T H E A V E RA GE T I M E R E QU I R E D T O S E P A R A T E A F R AM E ( T I ME P E R F R A ME , T P F ). Method CPU/GPU TPF (ms) LSTM-T asNet 4.3/0.2 Con v-T asNet-cLN 0.4/0.02 F . Sensitivity of LSTM-T asNet to the mixtur e starting point Unlike language processing tasks where sentences have determined starting words, it is difficult to define a general starting sample or frame for speech separation and enhance- ment tasks. A robust audio processing system should therefore 9 Fig. 3. Subjective and objective quality evaluation of separated utterances in WSJ0-2mix. (A): The mean opinion scores (MOS, N = 40) for IRM, Con v-T asNet and the clean utterance. Conv-T asNet significantly outperforms IRM ( p < 1 e − 16 , t-test). (B): PESQ scores are higher for IRM compared to the Conv-T asNet ( p < 1 e − 16 , t-test). Error bars indicate standard error (STE) (C): MOS versus PESQ for indi vidual utterances. Each dot denotes one mixture utterance, separated using the IRM (blue) or Con v-T asNet (red). The subjective ratings of almost all utterances for Con v-T asNet are higher than their corresponding PESQ scores. be insensitiv e to the starting point of the mixture. Howe ver , we empirically found that the performance of the causal LSTM- T asNet is very sensitive to the exact starting point of the mixture, which means that shifting the input mixture by se veral samples may adversely affect the separation accuracy . W e systematically examined the rob ustness of LSTM-T asNet and causal Conv-T asNet to the starting point of the mixture by ev aluating the separation accuracy for each mixture in the WSJ0-2mix test set with dif ferent sample shifts of the input. A shift of s samples corresponds to starting the separation at sample s instead of the first sample. Figure 4 (A) shows the performance of both systems on the same example mixture with different v alues of input shift. W e observe that, unlike LSTM-T asNet, the causal Con v-T asNet performs consistently well for all shift v alues of the input mixture. W e further tested the overall robustness for the entire test set by calculating the standard de viation of SDRi in each mixture with shifted mixture inputs similar to figure 4 (A). The box plots of all the mixtures in the WSJ0-2mix test set in figure 4 (B) show that causal Conv-T asNet performs consistently better across the entire test set, which confirms the robustness of Con v- T asNet to v ariations in the starting point of the mixture. One explanation for this inconsistency may be due to the sequen- tial processing constraint in LSTM-T asNet which means that failures in previous frames can accumulate and affect the separation performance in all following frames, while the decoupled processing of consecuti ve frames in Conv-T asNet alleviates the effect of occasional error . G. Properties of the basis functions One of the motiv ations for replacing the STFT represen- tation of the mixture signal with the conv olutional encoder in T asNet was to construct a representation of the audio that is optimized for speech separation. T o shed light on the properties of the encoder and decoder representations, we examine the basis functions of the encoder and decoder (ro ws of the matrices U and V ). The basis functions are sho wn Fig. 4. (A): SDRi of an example mixture separated using LSTM-T asNet and causal Con v-T asNet as a function of the starting point in the mixture. The performance of Con v-T asNet is considerably more consistent and insensitive to the start point. (B): Standard de viation of SDRi across all the mixtures in the WSJ0-2mix test set with varying starting points. in figure 5 for the best noncausal Conv-T asNet, sorted in the same way as figure 2. The magnitudes of the FFTs for each filter are also shown in the same order . As seen in the figure, the majority of the filters are tuned to lo wer frequencies. In addition, it shows that filters with the same frequency tuning express various phase values for that frequenc y . This observation can be seen by the circular shift of the low- frequency basis functions. This result suggests an important role for low-frequenc y features of speech such as pitch as well as explicit encoding of the phase information to achiev e superior speech separation performance. V . D I S C U S S I O N In this paper, we introduced the fully-con volutional time- domain audio separation network (Con v-T asNet), a deep learning framework for time-domain speech separation. This framew ork addresses the shortcomings of speech separation in the STFT domain, including the decoupling of phase and magnitude, the suboptimal representation of the mixture audio for separation, and the high latency of calculating the STFT . 10 Fig. 5. V isualization of encoder and decoder basis functions and the magnitudes of their FFTs. The basis functions are sorted based on their pairwise Euclidean similarity . The improv ements are accomplished by replacing the STFT with a conv olutional encoder-decoder architecture. The sepa- ration in Con v-T asNet is done using a temporal conv olutional network (TCN) architecture together with a depthwise sepa- rable con volution operation to address the challenges of deep LSTM networks. Our ev aluations showed that Con v-T asNet significantly outperforms STFT speech separation systems ev en when the ideal time-frequency masks for the target speakers are used. In addition, Con v-T asNet has a smaller model size and a shorter minimum latency , which makes it suitable for low-resource, low latency applications. Unlike STFT which has a well-defined in verse transform that can perfectly reconstruct the input, best performance in the proposed model is achiev ed by an ov ercomplete linear con volutional encoder -decoder frame work without guarantee- ing the perfect reconstruction of the input. This observation motiv ates rethinking of autoencoder and overcompleteness in the source separation problem which may share similarities to the studies of ov ercomplete dictionary and sparse coding [51], [52]. Moreover , the analysis of the encoder/decoder basis functions in section IV -G re vealed two interesting properties. First, most of the filters are tuned to low acoustic frequencies (more than 60% tuned to frequencies below 1 kHz). This pattern of frequency representation, which we found using a data-driv en method, roughly resembles the well-kno wn mel- frequency scale [53] as well as the tonotopic organization of the frequencies in the mammalian auditory system [54], [55]. In addition, the ov erexpression of lower frequencies may indicate the importance of accurate pitch tracking in speech separation, similar to what has been reported in human multitalker perception studies [56]. In addition, we found that filters with the same frequency tuning explicitly express various phase information. In contrast, this information is implicit in the STFT operations, where the real and imaginary parts only represent symmetric (cosine) and asymmetric (sine) phases, respectiv ely . This explicit encoding of signal phase values may be the key reason for the superior performance of T asNet over the STFT -based separation methods. The combination of high accuracy , short latency , and small model size makes Con v-T asNet a suitable choice for both offline and real-time, low-latency speech processing applica- tions such as embedded systems and wearable hearing and telecommunication de vices. Con v-T asNet can also serve as a front-end module for tandem systems in other audio processing tasks, such as multitalker speech recognition [57]–[60] and speaker identification [61], [62]. On the other hand, several limitations of Con v-T asNet must be addressed before it can be actualized, including the long-term tracking of speakers and generalization to noisy and reverberant en vironments. Because Con v-T asNet uses a fixed temporal context length, the long- term tracking of an individual speaker may fail, particularly when there is a long pause in the mixture audio. In addition, the generalization of Con v-T asNet to noisy and reverberant conditions must be further tested [26], as time-domain ap- proaches are more prone to temporal distortions which are par- ticularly sev ere in rev erberant acoustic en vironments. In such conditions, extending the Con v-T asNet framework to incor- porate multiple input audio channels may prov e adv antageous when more than one microphone is a vailable. Previous studies hav e shown the benefit of extending speech separation to multichannel inputs [63]–[65], particularly in adv erse acoustic conditions and when the number of interfering speakers is large (e.g., more than 3). In summary , Con v-T asNet represents a significant step tow ard the realization of speech separation algorithms and opens many future research directions that would further improv e its accuracy , speed, and computational cost, which could ev entually make automatic speech separation a common and necessary feature of ev ery speech processing technology designed for real-world applications. V I . A C K N O W L E D G M E N T S This work was funded by a grant from the National Institute of Health, NIDCD, DC014279; a National Science Foundation CAREER A ward; and the Pew Charitable T rusts. 11 R E F E R E N C E S [1] D. W ang and J. Chen, “Supervised speech separation based on deep learning: An overvie w , ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , 2018. [2] X. Lu, Y . Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder . ” in Interspeec h , 2013, pp. 436–440. [3] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “ An experimental study on speech enhancement based on deep neural networks, ” IEEE Signal pr ocessing letters , vol. 21, no. 1, pp. 65–68, 2014. [4] ——, “ A regression approach to speech enhancement based on deep neural networks, ” IEEE/ACM T ransactions on Audio, Speech and Lan- guage Processing (TASLP) , vol. 23, no. 1, pp. 7–19, 2015. [5] Y . Isik, J. Le Roux, Z. Chen, S. W atanabe, and J. R. Hershey , “Single- channel multi-speaker separation using deep clustering, ” Interspeech 2016 , pp. 545–549, 2016. [6] D. Y u, M. K olbæk, Z.-H. T an, and J. Jensen, “Permutation in variant training of deep models for speaker-independent multi-talker speech separation, ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 241–245. [7] M. Kolbæk, D. Y u, Z.-H. T an, and J. Jensen, “Multitalker speech separation with utterance-level permutation in variant training of deep recurrent neural networks, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 25, no. 10, pp. 1901–1913, 2017. [8] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 246–250. [9] Y . Luo, Z. Chen, and N. Mesgarani, “Speaker-independent speech separation with deep attractor network, ” IEEE/ACM Tr ansactions on Audio, Speech, and Language Pr ocessing , vol. 26, no. 4, pp. 787–796, 2018. [Online]. A vailable: http://dx.doi.org/10.1109/T ASLP . 2018.2795749 [10] Z.-Q. W ang, J. Le Roux, and J. R. Hershey , “ Alternative objecti ve functions for deep clustering, ” in Pr oc. IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018. [11] Z.-Q. W ang, J. L. Roux, D. W ang, and J. R. Hershe y , “End-to-end speech separation with unfolded iterati ve phase reconstruction, ” arXiv preprint arXiv:1804.10204 , 2018. [12] C. Li, L. Zhu, S. Xu, P . Gao, and B. Xu, “CBLDNN-based speaker- independent speech separation via generati ve adversarial training, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2018 IEEE Inter- national Conference on . IEEE, 2018. [13] D. Griffin and J. Lim, “Signal estimation from modified short-time fourier transform, ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 32, no. 2, pp. 236–243, 1984. [14] J. Le Roux, N. Ono, and S. Sagayama, “Explicit consistency constraints for stft spectrograms and their application to phase reconstruction. ” in SAP A@ INTERSPEECH , 2008, pp. 23–28. [15] Y . Luo, Z. Chen, J. R. Hershey , J. Le Roux, and N. Mesgarani, “Deep clustering and con ventional networks for music separation: Stronger together , ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 61–65. [16] A. Jansson, E. Humphrey , N. Montecchio, R. Bittner, A. Kumar, and T . W eyde, “Singing voice separation with deep u-net con volutional networks, ” in 18th International Society for Music Information Retrieval Confer ence , 2017, pp. 23–27. [17] S. Choi, A. Cichocki, H.-M. Park, and S.-Y . Lee, “Blind source separa- tion and independent component analysis: A re view , ” Neural Information Pr ocessing-Letters and Reviews , vol. 6, no. 1, pp. 1–57, 2005. [18] K. Y oshii, R. T omioka, D. Mochihashi, and M. Goto, “Beyond nmf: T ime-domain audio source separation without phase reconstruction. ” in ISMIR , 2013, pp. 369–374. [19] S. V enkataramani, J. Casebeer , and P . Smaragdis, “End-to-end source separation with adaptive front-ends, ” arXiv pr eprint arXiv:1705.02514 , 2017. [20] D. Stoller, S. Ewert, and S. Dixon, “W ave-u-net: A multi-scale neu- ral network for end-to-end audio source separation, ” arXiv preprint arXiv:1806.03185 , 2018. [21] Y . Luo and N. Mesgarani, “T asnet: time-domain audio separation network for real-time, single-channel speech separation, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2018 IEEE International Confer ence on . IEEE, 2018. [22] S.-W . Fu, T .-W . W ang, Y . Tsao, X. Lu, and H. Ka wai, “End-to-end w ave- form utterance enhancement for direct e valuation metrics optimization by fully conv olutional neural networks, ” IEEE/ACM Tr ansactions on Audio, Speech and Language Processing (T ASLP) , v ol. 26, no. 9, pp. 1570–1584, 2018. [23] S. Pascual, A. Bonafonte, and J. Serr ` a, “Segan: Speech enhancement generativ e adversarial network, ” Pr oc. Interspeech 2017 , pp. 3642–3646, 2017. [24] O. Ronneberger , P . Fischer, and T . Brox, “U-net: Conv olutional networks for biomedical image segmentation, ” in International Conference on Medical imag e computing and computer-assisted intervention . Springer, 2015, pp. 234–241. [25] J. R. Hershey , Z. Chen, J. Le Roux, and S. W atanabe, “Deep clustering: Discriminativ e embeddings for segmentation and separation, ” in Acous- tics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 31–35. [26] Y . Luo and N. Mesgarani, “Real-time single-channel dereverberation and separation with time-domain audio separation network, ” Proc. Interspeech 2018 , pp. 342–346, 2018. [27] F .-Y . W ang, C.-Y . Chi, T .-H. Chan, and Y . W ang, “Nonnegativ e least- correlated component analysis for separation of dependent sources by volume maximization, ” IEEE transactions on pattern analysis and machine intelligence , v ol. 32, no. 5, pp. 875–888, 2010. [28] C. H. Ding, T . Li, and M. I. Jordan, “Conve x and semi-nonnegati ve ma- trix factorizations, ” IEEE transactions on pattern analysis and machine intelligence , vol. 32, no. 1, pp. 45–55, 2010. [29] C. Lea, R. V idal, A. Reiter, and G. D. Hager, “T emporal con volutional networks: A unified approach to action segmentation, ” in Eur opean Confer ence on Computer V ision . Springer , 2016, pp. 47–54. [30] C. Lea, M. D. Flynn, R. V idal, A. Reiter , and G. D. Hager, “T empo- ral conv olutional networks for action segmentation and detection, ” in pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2017, pp. 156–165. [31] S. Bai, J. Z. Kolter , and V . Koltun, “ An empirical ev aluation of generic con volutional and recurrent networks for sequence modeling, ” arXiv pr eprint arXiv:1803.01271 , 2018. [32] F . Chollet, “Xception: Deep learning with depthwise separable conv o- lutions, ” arXiv pr eprint , 2016. [33] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W . W ang, T . W eyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient con vo- lutional neural networks for mobile vision applications, ” arXiv preprint arXiv:1704.04861 , 2017. [34] D. W ang, “On ideal binary mask as the computational goal of audi- tory scene analysis, ” in Speech separation by humans and machines . Springer , 2005, pp. 181–197. [35] Y . Li and D. W ang, “On the optimality of ideal binary time–frequency masks, ” Speech Communication , v ol. 51, no. 3, pp. 230–239, 2009. [36] Y . W ang, A. Narayanan, and D. W ang, “On training targets for super - vised speech separation, ” IEEE/ACM T ransactions on Audio, Speech and Language Processing (TASLP) , vol. 22, no. 12, pp. 1849–1858, 2014. [37] H. Erdogan, J. R. Hershey , S. W atanabe, and J. Le Roux, “Phase- sensitiv e and recognition-boosted speech separation using deep recurrent neural networks, ” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 708–712. [38] A. V an Den Oord, S. Dieleman, H. Zen, K. Simon yan, O. V inyals, A. Graves, N. Kalchbrenner, A. Senior , and K. Kavukcuoglu, “W avenet: A generative model for raw audio, ” CoRR abs/1609.03499 , 2016. [39] L. Kaiser, A. N. Gomez, and F . Chollet, “Depthwise separable conv olu- tions for neural machine translation, ” arXiv preprint , 2017. [40] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, ” in Pr oceedings of the IEEE international confer ence on computer vision , 2015, pp. 1026–1034. [41] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization, ” arXiv pr eprint arXiv:1607.06450 , 2016. [42] “Script to generate the multi-speaker dataset using wsj0, ” http://www . merl.com/demos/deep- clustering . [43] D. Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint arXiv:1412.6980 , 2014. [44] E. V incent, R. Gribon val, and C. F ´ evotte, “Performance measurement in blind audio source separation, ” IEEE transactions on audio, speech, and language pr ocessing , vol. 14, no. 4, pp. 1462–1469, 2006. [45] A. W . Rix, J. G. Beerends, M. P . Hollier, and A. P . Hekstra, “Perceptual ev aluation of speech quality (pesq)-a ne w method for speech quality assessment of telephone networks and codecs, ” in Acoustics, Speech, and Signal Pr ocessing, 2001. Pr oceedings.(ICASSP’01). 2001 IEEE International Conference on , v ol. 2. IEEE, 2001, pp. 749–752. [46] ITU-T Rec. P .10, “V ocabulary for performance and quality of service, ” 2006. 12 [47] R. R. Sokal, “ A statistical method for e valuating systematic relationship, ” University of Kansas science bulletin , vol. 28, pp. 1409–1438, 1958. [48] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov , and L.-C. Chen, “Mobilenetv2: Inv erted residuals and linear bottlenecks, ” in Proceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2018, pp. 4510–4520. [49] “ Audio samples for Con v-TasNet, ” http://naplab .ee.columbia.edu/ tasnet.html . [50] C. Xu, X. Xiao, and H. Li, “Single channel speech separation with constrained utterance level permutation inv ariant training using grid lstm, ” in Acoustics, Speech and Signal Processing (ICASSP), 2018 IEEE International Conference on . IEEE, 2018. [51] T .-W . Lee, M. S. Lewicki, M. Girolami, and T . J. Sejnowski, “Blind source separation of more sources than mixtures using ov ercomplete representations, ” IEEE signal pr ocessing letters , vol. 6, no. 4, pp. 87– 90, 1999. [52] M. Zibulevsky and B. A. Pearlmutter , “Blind source separation by sparse decomposition in a signal dictionary , ” Neural computation , v ol. 13, no. 4, pp. 863–882, 2001. [53] S. Imai, “Cepstral analysis synthesis on the mel frequency scale, ” in Acoustics, Speech, and Signal Pr ocessing, IEEE International Confer- ence on ICASSP’83. , vol. 8. IEEE, 1983, pp. 93–96. [54] G. L. Romani, S. J. Will iamson, and L. Kaufman, “T onotopic org ani- zation of the human auditory cortex, ” Science , vol. 216, no. 4552, pp. 1339–1340, 1982. [55] C. Pantev , M. Hoke, B. Lutkenhoner , and K. Lehnertz, “T onotopic orga- nization of the auditory cortex: pitch v ersus frequency representation, ” Science , vol. 246, no. 4929, pp. 486–488, 1989. [56] C. J. Darwin, D. S. Brungart, and B. D. Simpson, “Effects of fundamen- tal frequency and v ocal-tract length changes on attention to one of two simultaneous talkers, ” The Journal of the Acoustical Society of America , vol. 114, no. 5, pp. 2913–2922, 2003. [57] J. R. Hershey , S. J. Rennie, P . A. Olsen, and T . T . Kristjansson, “Super- human multi-talker speech recognition: A graphical modeling approach, ” Computer Speech & Language , vol. 24, no. 1, pp. 45–66, 2010. [58] C. W eng, D. Y u, M. L. Seltzer, and J. Droppo, “Deep neural networks for single-channel multi-talker speech recognition, ” IEEE/A CM T rans- actions on Audio, Speech and Language Pr ocessing (TASLP) , v ol. 23, no. 10, pp. 1670–1679, 2015. [59] Y . Qian, X. Chang, and D. Y u, “Single-channel multi-talker speech recognition with permutation in variant training, ” arXiv pr eprint arXiv:1707.06527 , 2017. [60] K. Ochi, N. Ono, S. Miyabe, and S. Makino, “Multi-talker speech recognition based on blind source separation with ad hoc microphone array using smartphones and cloud storage. ” in INTERSPEECH , 2016, pp. 3369–3373. [61] Y . Lei, N. Scheffer , L. Ferrer , and M. McLaren, “ A nov el scheme for speaker recognition using a phonetically-aware deep neural network, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Conference on . IEEE, 2014, pp. 1695–1699. [62] M. McLaren, Y . Lei, and L. Ferrer , “ Advances in deep neural network approaches to speaker recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 4814–4818. [63] S. Gannot, E. V incent, S. Markovich-Golan, A. Ozerov , S. Gannot, E. V incent, S. Markovich-Golan, and A. Ozerov , “ A consolidated perspectiv e on multimicrophone speech enhancement and source sep- aration, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr ocessing (T ASLP) , v ol. 25, no. 4, pp. 692–730, 2017. [64] Z. Chen, J. Li, X. Xiao, T . Y oshioka, H. W ang, Z. W ang, and Y . Gong, “Cracking the cocktail party problem by multi-beam deep attractor net- work, ” in Automatic Speech Recognition and Understanding W orkshop (ASR U), 2017 IEEE . IEEE, 2017, pp. 437–444. [65] Z.-Q. W ang, J. Le Roux, and J. R. Hershey , “Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker- independent speech separation, ” in Acoustics, Speech and Signal Pr o- cessing (ICASSP), 2018 IEEE International Conference on . IEEE, 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment