Learning an Unknown Network State in Routing Games
We study learning dynamics induced by myopic travelers who repeatedly play a routing game on a transportation network with an unknown state. The state impacts cost functions of one or more edges of the network. In each stage, travelers choose their routes according to Wardrop equilibrium based on public belief of the state. This belief is broadcast by an information system that observes the edge loads and realized costs on the used edges, and performs a Bayesian update to the prior stage’s belief. We show that the sequence of public beliefs and edge load vectors generated by the repeated play converge almost surely. In any rest point, travelers have no incentive to deviate from the chosen routes and accurately learn the true costs on the used edges. However, the costs on edges that are not used may not be accurately learned. Thus, learning can be incomplete in that the edge load vectors at rest point and complete information equilibrium can be different. We present some conditions for complete learning and illustrate situations when such an outcome is not guaranteed.
💡 Research Summary
The paper investigates a dynamic learning process in transportation networks where the underlying state—representing infrastructure conditions such as bridge closures or damage—is initially unknown to travelers. The state influences the cost functions of one or more edges. In each discrete time period, a public information system broadcasts a belief (a probability distribution) over the possible states. Travelers, modeled as a continuum of non‑atomic users with fixed total demand, choose routes that minimize the expected travel cost under the current public belief. Because the cost functions are strictly increasing in edge load, the resulting Wardrop equilibrium for a given belief is unique, yielding a deterministic edge‑load vector for that period.
The information system observes only the edges that were actually used (i.e., those with positive load) and the realized travel costs on those edges, which are modeled as the deterministic cost plus Gaussian noise. Using these observations, the system updates the public belief via Bayes’ rule. Crucially, edges that receive no flow provide no cost observations, so their associated state information remains unrefined.
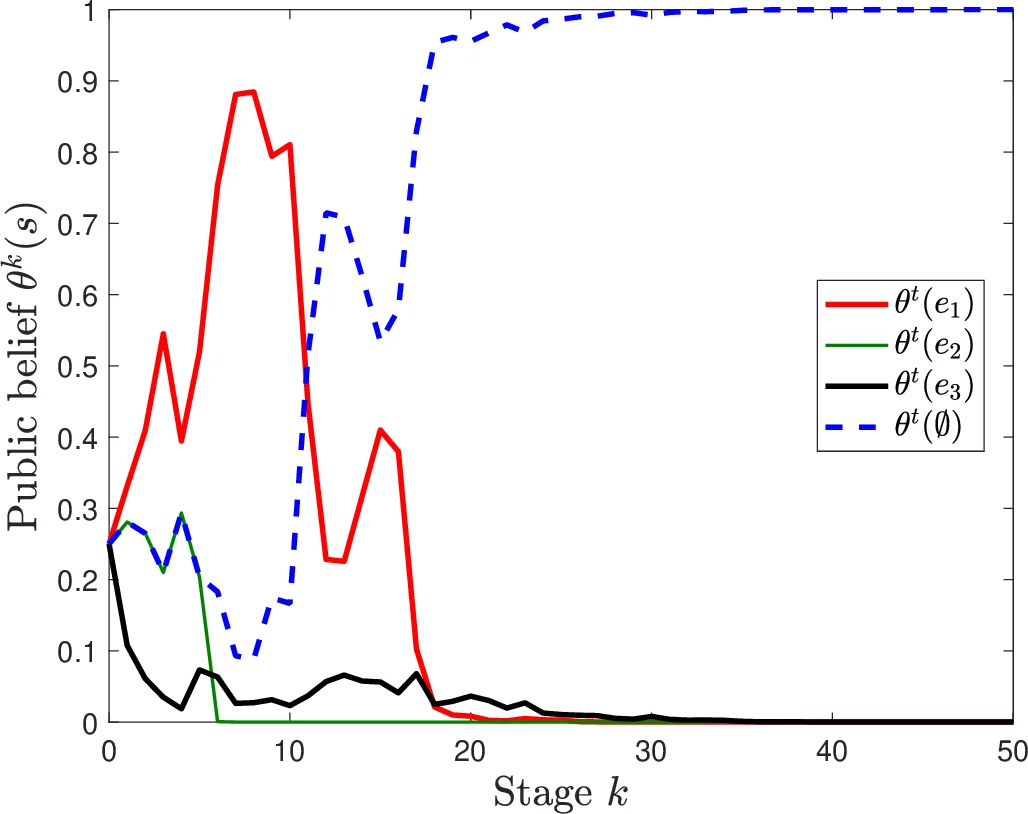
The authors prove a convergence theorem (Theorem 1): for any initial belief that assigns positive probability to every state, the sequence of belief–load pairs ((\theta_k, w_k^*)) converges almost surely to a rest point ((\bar\theta, \bar w)). At this rest point, the belief places zero probability on any state that would generate a distinguishable cost distribution given the observed loads; in other words, only states that are indistinguishable from the true state on the set of used edges survive. Simultaneously, (\bar w) is the Wardrop equilibrium corresponding to (\bar\theta), and travelers correctly learn the expected costs of all edges that are used at the rest point. Hence, no traveler has an incentive to deviate, and the observed costs provide no new information.
However, because unused edges are never observed, the learning can be incomplete: the edge‑load vector at the rest point may differ from the complete‑information Wardrop equilibrium (the equilibrium that would arise if the true state were known). The paper calls this “incomplete learning.” To explore when learning is complete, the authors present two propositions. Proposition 1 shows that in series‑parallel networks, the average travel cost at any rest point is at least as high as in the complete‑information equilibrium, establishing a performance bound despite possible incompleteness. Proposition 2 provides sufficient conditions under which travelers eventually use exactly the set of edges that would be used under complete information, leading to (\bar w = w_s^*) and (\bar\theta) collapsing onto the true state. These conditions involve sufficient distinguishability of cost functions across states, a full‑support initial belief, and network structures that force exploration of all potentially optimal routes.
Methodologically, the work blends routing games with Bayesian state estimation in a setting where observations are endogenous (they depend on the equilibrium flow). Classical Bayesian convergence results (e.g., Blackwell–Dubins) do not apply because the data generating process changes with the belief itself. The authors develop a novel stochastic analysis of the induced Markov process and prove almost‑sure convergence despite this feedback loop.
From a practical perspective, the findings suggest that real‑time traffic information systems can reliably learn the true costs of routes that are actually used, but may fail to learn about alternative routes that remain unused. Consequently, traffic managers should consider mechanisms to generate occasional exploratory traffic on under‑used links (e.g., random routing incentives or targeted sensor deployment) to avoid persistent inefficiencies caused by incomplete learning.
In summary, the paper makes three key contributions: (1) a formal model of repeated routing games with Bayesian state updates based on partial observations; (2) a rigorous proof of almost‑sure convergence to a rest point where used‑edge costs are learned accurately; and (3) identification of network‑topology and cost‑function conditions that guarantee complete learning, together with insights for designing information‑release policies that mitigate the risk of suboptimal equilibria.
Comments & Academic Discussion
Loading comments...
Leave a Comment