Improving Adversarial Robustness by Encouraging Discriminative Features
Deep neural networks (DNNs) have achieved state-of-the-art results in various pattern recognition tasks. However, they perform poorly on out-of-distribution adversarial examples i.e. inputs that are specifically crafted by an adversary to cause DNNs to misbehave, questioning the security and reliability of applications. In this paper, we encourage DNN classifiers to learn more discriminative features by imposing a center loss in addition to the regular softmax cross-entropy loss. Intuitively, the center loss encourages DNNs to simultaneously learns a center for the deep features of each class, and minimize the distances between the intra-class deep features and their corresponding class centers. We hypothesize that minimizing distances between intra-class features and maximizing the distances between inter-class features at the same time would improve a classifier’s robustness to adversarial examples. Our results on state-of-the-art architectures on MNIST, CIFAR-10, and CIFAR-100 confirmed that intuition and highlight the importance of discriminative features.
💡 Research Summary
The paper investigates why deep neural networks (DNNs) are vulnerable to adversarial examples (AX) and proposes a simple yet effective regularization technique to improve robustness. The authors argue that the conventional softmax cross‑entropy loss only encourages separation between class decision boundaries but does not explicitly control the distribution of deep features within each class. Consequently, intra‑class features can be widely scattered, making it easy for a small perturbation to push a sample across a decision boundary.
To address this, the authors incorporate the “center loss” originally introduced for face recognition. Center loss maintains a learnable prototype (center) for each class and adds a penalty term that forces the deep feature vector of every training sample to stay close to its class center. The overall loss becomes a weighted sum of the softmax cross‑entropy and the center loss:
L = – Σ_i log ( e^{W_{y_i}^T f(x_i)} / Σ_j e^{W_j^T f(x_i)} ) + λ Σ_i || f(x_i) – c_{y_i} ||_2^2
where f(x_i) is the penultimate‑layer feature, c_{y_i} is the current center for the true class, and λ balances the two objectives. In all experiments λ is set to 1, and centers are updated with an exponential moving average to keep training stable.
The authors conduct a thorough empirical study across three benchmark datasets (MNIST, CIFAR‑10, CIFAR‑100) and four modern architectures (MLP, VGG‑19, ResNet‑18, DenseNet‑40). They compare four model families:
- DS – trained with softmax loss only.
- DSC – trained with softmax + center loss.
- AT‑DS – adversarially trained (FGSM) with softmax only.
- AT‑DSC – adversarially trained with both losses.
For each model they evaluate robustness against a suite of white‑box attacks (FGSM, PGD, Carlini‑Wagner) and black‑box attacks (single‑pixel, evolutionary methods). The key findings are:
- On MNIST, DSC improves FGSM robustness from ~70% to ~79% accuracy, while maintaining comparable clean‑test accuracy. PGD and CW attacks, being stronger, show smaller gaps but DSC still outperforms DS.
- On CIFAR‑10, DSC consistently yields higher adversarial accuracy across all attacks. For example, ResNet‑18 under PGD improves from 68.64% (DS) to 74.29% (DSC), a relative gain of about 8%. Similar trends appear for VGG‑19 and DenseNet‑40.
- On CIFAR‑100, gains are more modest and sometimes negative for very deep models (e.g., DenseNet‑40) where the clean‑test accuracy of DSC drops, leading to reduced adversarial performance. This highlights a trade‑off: overly aggressive center regularization can hurt overall discriminability.
- Combining center loss with adversarial training (AT‑DSC) yields the best of both worlds. Compared to AT‑DS, AT‑DSC gains an extra 2–5% adversarial accuracy on most configurations, confirming that the discriminative feature regularizer complements the robustness provided by adversarial examples.
- Statistical significance is verified via two‑sample t‑tests over five random seeds per architecture; p‑values are below 0.05 in the majority of comparisons, indicating that the improvements are not due to random chance.
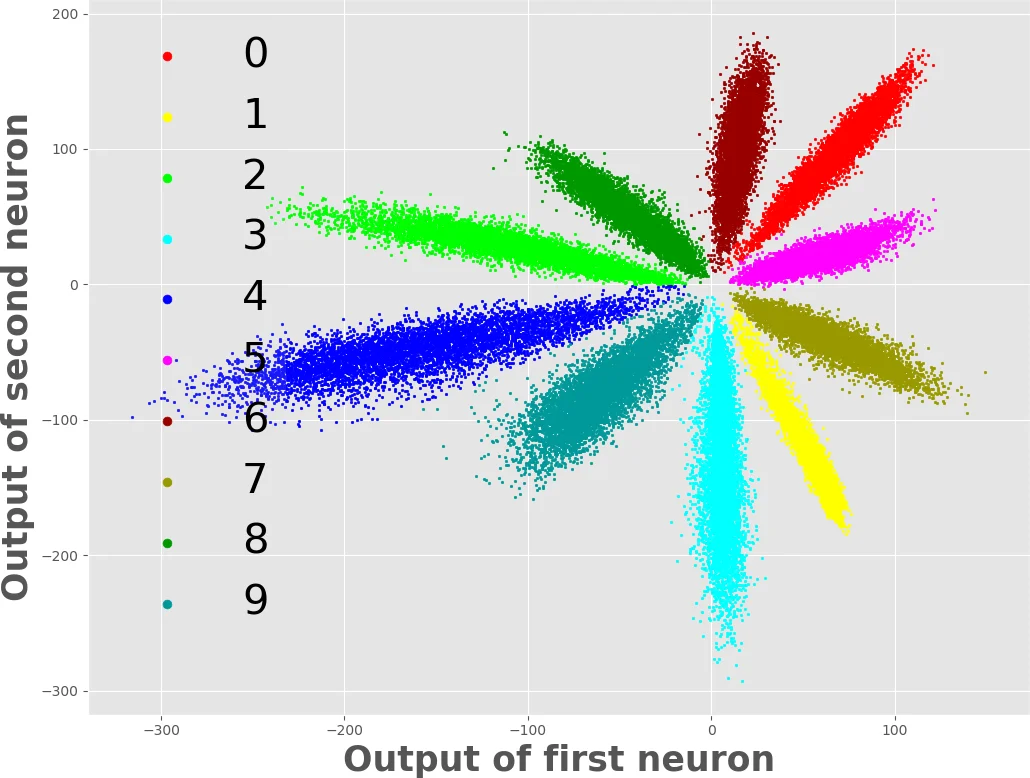
The authors interpret these results through the lens of feature geometry. Center loss reduces intra‑class variance, producing tight, spherical clusters in the feature space. Softmax loss continues to push different class clusters apart, thereby enlarging the margin. When an adversary perturbs an input, the required perturbation magnitude to cross from one cluster to another grows with the intra‑class compactness, making attacks harder to succeed. The visualizations (Figures 1 and 2) illustrate that DSC models have clearly separated clusters with lower spread, whereas DS models exhibit scattered intra‑class points that overlap under perturbation.
The paper also discusses limitations. The fixed λ=1 may not be optimal for all datasets; a too‑large center penalty can shrink inter‑class distances and degrade clean accuracy. Moreover, black‑box robustness depends heavily on the underlying architecture and dataset difficulty; for CIFAR‑100 the benefit of center loss diminishes. The authors suggest future work on adaptive λ scheduling, multi‑center (sub‑cluster) representations, and combining center loss with other regularizers such as Jacobian regularization.
In conclusion, the study demonstrates that encouraging discriminative, low‑variance feature representations via center loss is a lightweight and effective strategy to bolster adversarial robustness across a range of standard vision benchmarks. The approach can be easily integrated into existing training pipelines and complements more computationally intensive defenses like adversarial training.
Comments & Academic Discussion
Loading comments...
Leave a Comment