An Efficient Approach to Achieve Compositionality using Optimized Multi-Version Object Based Transactional Systems
In the modern era of multi-core systems, the main aim is to utilize the cores properly. This utilization can be done by concurrent programming. But developing a flawless and well-organized concurrent program is difficult. Software Transactional Memory Systems (STMs) are a convenient programming interface which assist the programmer to access the shared memory concurrently without worrying about consistency issues such as priority-inversion, deadlock, livelock, etc. Another important feature that STMs facilitate is compositionality of concurrent programs with great ease. It composes different concurrent operations in a single atomic unit by encapsulating them in a transaction. Many STMs available in the literature execute read/write primitive operations on memory buffers. We represent them as Read-Write STMs or RWSTMs. Whereas, there exist some STMs (transactional boosting and its variants) which work on higher level operations such as insert, delete, lookup, etc. on a hash-table. We refer these STMs as Object Based STMs or OSTMs. The literature of databases and RWSTMs say that maintaining multiple versions ensures greater concurrency. This motivates us to maintain multiple version at higher level with object semantics and achieves greater concurrency. So, this paper pro-poses the notion of Optimized Multi-version Object Based STMs or OPT-MVOSTMs which encapsulates the idea of multiple versions in OSTMs to harness the greater concurrency efficiently.
💡 Research Summary
The paper addresses the challenge of achieving high concurrency and compositionality in multi‑core systems by extending object‑based Software Transactional Memory (OSTM) with multi‑version capabilities. Traditional STM approaches fall into two categories: read‑write STMs (RWSTMs) that operate on low‑level memory cells, and object‑based STMs that provide higher‑level operations such as insert, delete, and lookup on data structures like hash tables. RWSTMs benefit from multi‑versioning (MV) in databases, which reduces read‑write conflicts, but they lack the abstraction of object‑level operations. OSTMs, on the other hand, simplify programming by exposing high‑level methods and typically exhibit fewer aborts than RWSTMs, yet they maintain only a single version per object, causing aborts when a delete is followed by a lookup on the same key.
To combine the strengths of both worlds, the authors propose Optimized Multi‑Version Object‑Based STMs (OPT‑MVOSTM). The core idea is to keep multiple versions for each logical key (or object) so that a transaction performing a lookup can always read a consistent version, even if a concurrent transaction has already deleted the key. This eliminates the need to abort read‑only transactions that would otherwise be forced to abort in a single‑version OSTM.
Two concrete variants are implemented for hash‑table and linked‑list data structures:
-
OPT‑MVOSTM‑GC – an unbounded‑version system that periodically runs a garbage‑collection (GC) routine. The GC scans version lists and discards any version that is no longer reachable by any active transaction, thereby controlling memory consumption while preserving the benefits of unlimited versioning.
-
OPT‑KOSTM – a bounded‑version system that caps the number of versions per key at a configurable parameter K. When the (K + 1)‑th version is created, the oldest version is evicted. This approach reduces memory pressure and, as experiments show, often yields better performance than the GC variant because it avoids the overhead of scanning for garbage.
The authors formally prove that both variants satisfy opacity, the standard correctness criterion for STM systems. They extend the graph‑based opacity model to a two‑layer representation: layer‑0 captures low‑level read/write events, while layer‑1 captures high‑level object method invocations. By demonstrating that the conflict graph of any history generated by OPT‑MVOSTM is acyclic, they guarantee that every history can be linearized to a serial order that respects real‑time ordering, thus ensuring opacity.
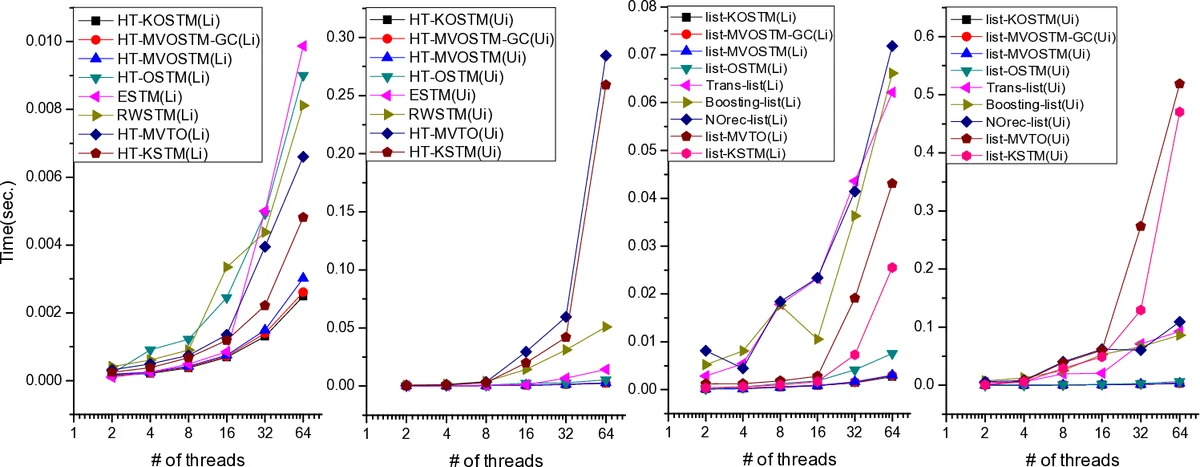
Performance evaluation is extensive. Three synthetic workloads (W1, W2, W3) with varying mixes of lookups, inserts, and deletes are executed on both hash‑table and list implementations. The results show that:
- OPT‑HT‑KOSTM outperforms state‑of‑the‑art hash‑table STMs (HT‑OSTM, ESTM, RWSTM, HT‑MVTO, HT‑KSTM) by factors ranging from 1.44× to 3.95× depending on the workload.
- OPT‑list‑KOSTM similarly beats list‑based STMs (list‑OSTM, Trans‑list, Boosting‑list, NOrec‑list, list‑MVTO, list‑KSTM) by factors up to 174× in the most write‑heavy scenario.
- Abort rates drop dramatically because read‑only transactions never abort when only lookups are involved.
- Memory usage is kept reasonable: the GC variant reduces memory consumption by ~16 % compared to the raw unbounded versioning, while the K‑bounded variant achieves ~24 % improvement.
The paper’s contributions are summarized as follows:
- Introduction of the OPT‑MVOSTM concept, a generic framework that can be applied to arbitrary data structures.
- Two practical memory‑management strategies (GC and K‑bounded) that make multi‑versioning feasible in production‑grade systems.
- Formal proof of opacity for the proposed designs.
- Comprehensive experimental validation showing superior throughput and lower abort rates compared to the best existing STM systems.
In conclusion, OPT‑MVOSTM successfully merges the abstraction benefits of object‑based STMs with the concurrency advantages of multi‑versioning. It delivers higher throughput, lower abort probability, and flexible memory management, making it a strong candidate for future concurrent programming frameworks on multi‑core architectures. Future work suggested includes extending the approach to more complex data structures (trees, graphs), adaptive tuning of the K parameter at runtime, and exploring distributed implementations.
Comments & Academic Discussion
Loading comments...
Leave a Comment