Attention Based Fully Convolutional Network for Speech Emotion Recognition
Speech emotion recognition is a challenging task for three main reasons: 1) human emotion is abstract, which means it is hard to distinguish; 2) in general, human emotion can only be detected in some specific moments during a long utterance; 3) speec…
Authors: Yuanyuan Zhang, Jun Du, Zirui Wang
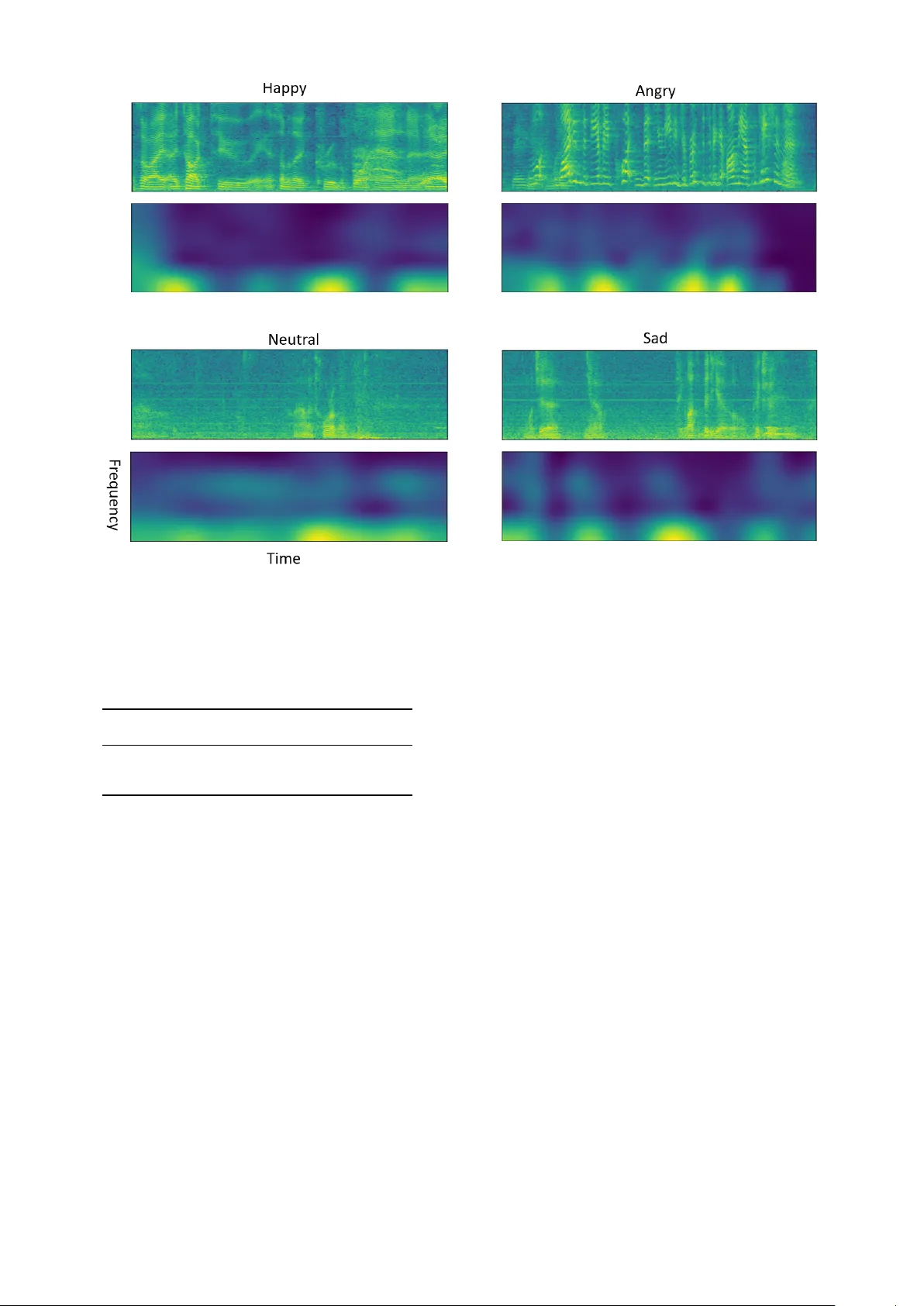
Attention Based Fully Con v olutional Network for Speech Emotion Recognition Y uanyuan Zhang, Jun Du, Zirui W ang, Jianshu Zhang, Y anhui T u National Engineering Laboratory for Speech and Language Information Processing, Univ ersity of Science and T echnology of China, Hefei, China { zyuan, cs211, xysszjs, tuyanhui } @mail.ustc.edu.cn, jundu@ustc.edu.cn Abstract —Speech emotion recognition is a challenging task for three main reasons: 1) human emotion is abstract, which means it is hard to distinguish; 2) in general, human emotion can only be detected in some specific moments during a long utterance; 3) speech data with emotional labeling is usually limited. In this paper , we pr esent a nov el attention based fully con volutional network for speech emotion recognition. W e employ fully con vo- lutional network as it is able to handle variable-length speech, free of the demand of segmentation to keep critical information not lost. The pr oposed attention mechanism can make our model be aware of which time-frequency region of speech spectrogram is more emotion-rele vant. Considering limited data, the transfer learning is also adapted to improv e the accuracy . Especially , it’ s interesting to observ e obvious impr ovement obtained with natural scene image based pre-trained model. V alidated on the publicly av ailable IEMOCAP corpus, the proposed model outperformed the state-of-the-art methods with a weighted accuracy of 70.4% and an unweighted accuracy of 63.9% respecti vely . I . I N T RO D U C T I O N Emotions play an important role in human communica- tions [1] and successfully detecting the emotion states is help- ful to improv e the efficiency of human-computer interaction. For instance, in call centers, tracking customers’ emotion states can be useful for quality measurement [2] and the calls from angry customers can therefore be assigned to experi- enced agents. Speech is one of the communication channels that emotions could have serious influence on. T echnically , emotions af fect both the voice characteristics and linguistic content. In this study , we focus on the change of voice characteristics to recognize the underlying emotions in speech. Fig. 1. The traditional speech emotion recognition system. Speech emotion recognition (SER) has been an activ e research field for decades [3], [4], [5], [6]. W e demonstrate the architecture of traditional approaches for SER in Figure 1. First, acoustic features which are believ ed to incorporate the information of human emotions are extracted from raw speech wa veform frame by frame. The features include pitch, voicing probability , energy , etc. Then various statistical functions (e.g. mean, max, linear regression coefficients, etc.) are applied to the frame-level features. And the outputs are concatenated as a feature vector to represent the whole utterance. Finally , the utterance feature vector is fed to the classifier . There are many classification models that have been used [3], [4], [5], [6], with support vector machine (SVM) being one of the most popular choices. Recently , deep learning methods hav e been introduced to this field. In [7], deep neural network (DNN) was used on the top of traditional utterance-le vel features and achie ved a significant impro vement on the accurac y compared with con ventional classifiers. [8] used DNN to learn the short-term acoustic features, followed by traditional statistical functions to construct utterance-le vel features and the extreme learning machine (ELM) was used as the classifier . In [9], the state-of- the-art result was reported by using both conv olutional and re- current layers to directly learn the mapping from speech spec- trogram to the corresponding emotion state. In [9], the speech spectrogram must be segmented into pieces or zero-padded to a fixed size to satisfy the requirement of con volutional neural network (CNN). Each sub-utterance was assigned the emotion label of the corresponding whole utterance. And during the testing procedure, the prediction of the whole utterance was ev aluated by averaging the posterior probabilities of all sub- utterances. Howe ver , it is not quite reasonable to assume that each sub-sentence within a whole sentence represents the overall emotion. In addition, the speech continuity could be destroyed by segmentation which made the system more difficult to catch the whole process of emotion changing from rise to fall. T o solve this problem, in this study , the fully con volutional neural network (FCN) is adopted to handle variable-length speech, free of the demand of segmentation to keep critical in- formation not lost. In addition, attention mechanism has shown its efficiency especially in encoder-decoder models [10], [11], [12], which is employed to guide the decoder to know which parts of the outputs of the encoder are more important. Specific to classification models, a self-attention mechanism has been proposed and it is designed to tell the classifier which parts of the input are more relev ant to the output classes. In [13], [14], the self-attention was used to extract sentence embedding for semantic analysis. In [15], the authors used the self- attention mechanism on SER, enabling the netw ork to focus on emotional salient of an utterance. The encoder they adopted is long short-term memory (LSTM). Considering many irrelev ant signals are mix ed with speech signals, we adopt attention mechanism with FCN to achieve 2D attention visualization on top of spectrograms rather than 1D attention visualization only on the time axis in [15]. Another problem is the that speech data with emotional labeling is usually hard to collect. T ransfer learning is a useful method to solve the current task with the help of the knowledge obtained from related problems [10], which can be operated as finetuning the parameters of network from a pre- trained model, It has been widely used when the training data is insufficient [16], [17], [18], [19], especially when the model is based on CNN. In this paper, we present an interesting observation, i.e., an ob vious improv ement on SER can be obtained with natural scene image based pre-trained model. It worth noting that speech signal is very different from image. The remainder of the paper is or ganized as follo ws. In Section 2, we first introduce the proposed architecture. In Section 3, we report and analyze experiment results. Finally we summarize our work and present conclusions in Section 4. I I . T H E P RO P O S E D A R C H I T E C T U R E Fig. 2. The overall architecture of an attention based fully con volutional neural network. In this paper , we propose a nov el attention based fully con volutional neural network. The input of the model is also the spectrogram. But inherently unlike [9], we do not need to segment spectrograms into pieces or pad them to a fixed shape. The FCN is able to handle spectrogram with v ariable sizes. The overall architecture is shown in Figure 2. The FCN encodes the spectrogram into a high-lev el representation while the attention mechanism impels the remaining sub-layers of the model to focus on specific time-frequency regions of the input spectrogram. All components of the system can be optimized jointly . Fig. 3. The AlexNet based FCN configurations. The con volutional layer parameters are denoted as “Conv(kernel size)-[stride size]-[number of chan- nels]”. The maxpooling layer parameters are denoted as “Maxpool-[kernel size]-[stride size]”. For brevity , the local response normalization layer and ReLU activ ation function is not shown. A. Fully convolutional network CNN has been widely used for deep learning, which does not require traditional handcrafted feature extraction and it has been proved that CNN based system can obtain a comparable or ev en better accuracy compared with the traditional systems on the SER task [15], [20], [21]. The basic components of CNN are conv olution, pooling and activ ation layers. The con volutional layer is determined by the number of input channels, the number of output feature maps, the kernel size and stride. Each kernel can be considered as a filter whose size is usually much smaller than the input. Hence, a kernel operates on a local re gion of input rather than the whole feature map. The locations that connect to higher layers are called receptiv e fields. On a giv en feature map, the kernel weights are shared to detect certain feature in different locations and to reduce the complexity of network. The pooling layers usually conduct an average or max pooling operation to remove noise and extract robust features. The acti vation layers are actually element-wise nonlinear functions [12]. The typical CNNs, including Ale xNet [22], Oxford VGGNet [23], and ResNet [24] take fixed-size input. Inspired by [18], we turn the AlexNet into a fully con volutional network by simply removing its fully connected layers. And then it is used as our encoder , which is shown in Figure 3. All the con volution layers are follo wed by a ReLU activ ation function, and the first two conv olution layers are equipped with a local response normalization layer . W e also directly adapt the VGGnet to classify emotion states, but it yields a lower accuracy than AlexNet due to the limited training data. Assuming that the output of FCN encoder is a 3-dimensional array of size F × T × C ,where the F and T correspond to the frequenc y and time domains of spectrogram and C is channel size. W e can consider the output as a variable-length grid of L elements, L = F × T . Each of the elements is a C-dimensional vector corresponding to a region of speech spectrogram, represented as a i . A = { a 1 , · · · , a L } , a i ∈ R C (1) B. Attention layer Intuitiv ely , not all time-frequenc y units contrib ute equally to the emotion state of the whole utterance, i.e., not all the element vectors of set A contribute equally to the emotion state. Hence, we introduce attention mechanism to extract the elements that are important to the emotion of the utterance and aggregate those element arrays to form an utterance emotion vector . W e use the follo wing formulas to realize this idea: e i = u T tanh( W a i + b ) (2) α i = exp( λe i ) P L k =1 exp( λe k ) (3) c = L X i =1 α i a i (4) That is, first we feed the annotation a i through a multi- layer-perceptron (MLP) layer with the tanh as the non-linear activ ation function to obtain a new representation of a i . Then we measure the importance weight, e i , of the a i by the inner product between this ne w vector and the learnable vector u . After that, the normalized importance weight α i is calculated through the softmax function. Finally , the utterance emotion vector c is computed as the weighted sum of set A with importance weights. λ is a scale factor which controls the uniformity of the importance weights of the annotation vectors. λ ranges between 0 and 1. If λ = 1 , the scaled-softmax becomes the commonly used softmax function. If λ = 0 , the importance weights will be a uniform distribution on the set A , which means all the time-frequency units have the same importance weights for the final utterance emotion vector . In this study , λ = 0 . 3 is used for the balance. I I I . E X P E R I M E N T S A. Database and featur e e xtraction W e validate our systems on the IEMOCAP database [25], one of the widely used databases on speech emotion recog- nition. The IEMOCAP corpus comprises fiv e sessions, each of which includes labeled emotional speech utterances from recordings of dialogs between two actors. There is no actor ov erlapping between these sessions. T o be comparable with [9], we utilize the database in the same way: • The IEMOCAP database contains scripted and impro- vised dialogs. W e only use improvised data. • W e use the speech utterances from four emotion cate- gories, i.e., happy , sad, angry and neutral. • W e implement a five-fold cross validation. In each fold, the data from four sessions is used for model training, and the data from the remaining session is splited: one actor for validation and the other one as the testing set. The experiments only apply the ra w spectrogram as the input, the spectrogram extraction process is consistent with T ABLE I T H E A C CU R AC Y C O M P A R I SO N OF A L E X N ET A ND VG G N ET - 1 6 W I T H R A ND O M I N I TI A L I ZAT IO N O R FIN E T U NI N G . System W eighted Accuracy Unweighted Accuracy AlexNet Random-init 66 . 5% 54 . 8% AlexNet Finetuning 67 . 9% 57 . 3% VGGNet-16 Random-init 65 . 3% 54 . 8% VGGNet-16 Finetuning 66 . 8% 56 . 7% [9]: First, a sequence of overlapping Hamming windows are applied to the speech wav eform, with window shift set to 10 msec, and window size set to 40 msec. Then, for each frame we calculate a discrete Fourier transform (DFT) of length 800. Finally the 200-dimensional low-frequenc y part of the spectrogram is used as the input. Please note that in [9], the Hamming window size of 20 msec is used, and the authors concluded that the size of 20 msec is better . In our study , we set the window size to 40 msec and achiev e a higher accuracy . B. Evaluation metric The IEMOCAP database is imbalanced with respect to the emotional classes. So we adopt both the weighted accuracy (W A) and the unweighted accuracy (U A) as the metric: • W eighted accuracy - the overall accuracy across all utter- ances of the testing set. • Unweighted accuracy - the a verage of accuracies across all the classes. C. Experiment results and analysis First, we directly adapt Ale xNet and VGGNet-16 to classify . The only difference is that there are 4 nodes in softmax layer . The utterances are split or padded to fixed-length sub- utterances by using the same method in [9]. During the testing procedure, the posterior probabilities are the average of the all sub-utterances respectiv ely . Considering the limited data, we compare the networks with random initialization and the pre- trained networks based on ImageNet dataset [26]. T able I summarizes the results of AlexNet and V GGNet- 16 with different initializations. It’ s interesting to observe the pre-trained neural networks (NNs) always outperform the NNs with random initialization. It’ s worth noting that the speech signal is very different from image. The only explanation is the pre-trained NNs have been empowered to detect some certain structures so that they can be more easily trained. By comparing the first ro w and third row (or comparing the second row and fourth row), we demonstrate that the AlexNet outperforms the VGGNet-16 on this task. W e think the lack of sufficient training speech data is one main reason. Based on these results, our FCN model directly uses AlexNet, excluding its full connected layers. And we initialize FCN by using the pre-trained parameters. The published state-of-the-art results using the IEMOCAP corpus are given in [9]. W e list their two best models, i.e., CNN+LSTM Model1 and CNN+LSTM Model2 in T able II. Model1 is a CNN-LSTM model while Model2 is trained based Fig. 4. The 2D-attention weights of FCN model for 4 examples in different emotion categories. T op: The spectrogram. Bottom: The 2D-attention weights figure of spectrogram. Each point of the figure corresponds to the point of spectrogram in the same location and the brighter color represents the larger weight. T ABLE II T H E A C CU R AC Y C O M P A R I SO N BE T W E EN FC N BA S ED A T T EN T I O N M O D E L A N D T H E O TH E R S Y S TE M S . System W eighted Accuracy Unweighted Accuracy Our FCN+Attention 70 . 4% 63 . 9% CNN+LSTM Model1 in [9] 68 . 8% 59 . 4% CNN+LSTM Model2 in [9] 67 . 3% 62 . 0% on Model1 in order to improve the unweighted accuracy . The attention based FCN model is trained just by one step. And compared with the best results in both Model1 and Model2, our attention based FCN model achieves 1 . 6% and 1 . 9% absolute improvements on W A and U A, respectively . T o explain why the improvement can be gained from our proposed approach, we plot the 2D-attention weights of FCN model for 4 test examples of different emotion categories in Figure 4. The Figure 4 illustrates that the attention weights of the non-speech frames are quite small which indicates that the voice activ ation detection is implicitly implemented and the information from non-speech frames are ignored by the attention mechanism automatically . Besides, the time- frequency units of spectrogram are assigned different weights based on the degrees they are rele vant to emotion states. That explains why the attention weights are also small on parts of the voice frames. And the attention weights always have small values in high frequency areas, which is consistent with the common sense that the information of speech is mainly contained in the low frequency area. Actually , the bright area extends from low frequency to high frequency with a decreas- ing brightness. This indicates our 2D-attention mechanism has detected the emotional segment successfully and assigned decreasing weights from lo w to high frequency bands. The 2D-attention mechanism is able to scan the spectrogram not only in the time domain but also in the frequency domain. I V . C O N C L U S I O N S W e demonstrated that the CNN architectures designed for visual recognition can be directly adapted for speech emo- tion recognition. Besides, it’ s interesting to see the transfer learning can build a solid bridge between natural image and speech signal. Finally , we proposed an attention based FCN model. Our model is able to handle utterances with variable lengths and the attention mechanism empowers the network to focus on emotionally salient regions of spectrogram. Our system achieves beyond the state-of-the-art accuracy on the benchmark dataset IEMOCAP . R E F E R E N C E S [1] R. Cowie, E. Douglas-Cowie, N. Tsapatsoulis, G. V otsis, S. Kollias, W . Fellenz, and J. G. T aylor , “Emotion recognition in human-computer interaction, ” IEEE Signal pr ocessing magazine , vol. 18, no. 1, pp. 32–80, 2001. [2] F . Burkhardt, J. Ajmera, R. Englert, J. Stegmann, and W . Burleson, “De- tecting anger in automated voice portal dialogs, ” in Ninth International Confer ence on Spoken Language Pr ocessing , 2006. [3] C. V inola and K. V imaladevi, “ A survey on human emotion recognition approaches, databases and applications, ” ELCVIA Electr onic Letters on Computer V ision and Image Analysis , vol. 14, no. 2, pp. 24–44, 2015. [4] M. El A yadi, M. S. Kamel, and F . Karray , “Survey on speech emotion recognition: Features, classification schemes, and databases, ” P attern Recognition , vol. 44, no. 3, pp. 572–587, 2011. [5] P . Chandrasekar, S. Chapaneri, and D. Jayaswal, “ Automatic speech emotion recognition: A survey , ” in Cir cuits, Systems, Communication and Information T echnology Applications (CSCIT A), 2014 International Confer ence on . IEEE, 2014, pp. 341–346. [6] S. G. K oolagudi and K. S. Rao, “Emotion recognition from speech: a revie w , ” International journal of speech technology , vol. 15, no. 2, pp. 99–117, 2012. [7] A. Stuhlsatz, C. Meyer , F . Eyben, T . Zielke, G. Meier , and B. Schuller , “Deep neural networks for acoustic emotion recognition: raising the benchmarks, ” in Acoustics, speech and signal processing (ICASSP), 2011 IEEE international conference on . IEEE, 2011, pp. 5688–5691. [8] K. Han, D. Y u, and I. T ashev , “Speech emotion recognition using deep neural network and extreme learning machine, ” in F ifteenth Annual Confer ence of the International Speech Communication Association , 2014. [9] A. Satt, S. Rozenberg, and R. Hoory , “Efficient emotion recognition from speech using deep learning on spectrograms, ” Proc. Interspeech 2017 , pp. 1089–1093, 2017. [10] D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate, ” arXiv pr eprint arXiv:1409.0473 , 2014. [11] M.-T . Luong, H. Pham, and C. D. Manning, “Effecti ve ap- proaches to attention-based neural machine translation, ” arXiv pr eprint arXiv:1508.04025 , 2015. [12] J. Zhang, J. Du, S. Zhang, D. Liu, Y . Hu, J. Hu, S. W ei, and L. Dai, “W atch, attend and parse: An end-to-end neural network based approach to handwritten mathematical expression recognition, ” P attern Recognition , vol. 71, pp. 196–206, 2017. [13] Z. Y ang, D. Y ang, C. Dyer , X. He, A. Smola, and E. Hovy , “Hierarchical attention networks for document classification, ” in Proceedings of the 2016 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T ec hnologies , 2016, pp. 1480–1489. [14] Z. Lin, M. Feng, C. N. d. Santos, M. Y u, B. Xiang, B. Zhou, and Y . Bengio, “ A structured self-attentiv e sentence embedding, ” arXiv pr eprint arXiv:1703.03130 , 2017. [15] S. Mirsamadi, E. Barsoum, and C. Zhang, “ Automatic speech emotion recognition using recurrent neural networks with local attention, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE Inter- national Conference on . IEEE, 2017, pp. 2227–2231. [16] R. Girshick, J. Donahue, T . Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation, ” in Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , 2014, pp. 580–587. [17] J. Donahue, Y . Jia, O. V inyals, J. Hoffman, N. Zhang, E. Tzeng, and T . Darrell, “Decaf: A deep convolutional activ ation feature for generic visual recognition, ” in International confer ence on machine learning , 2014, pp. 647–655. [18] J. Long, E. Shelhamer, and T . Darrell, “Fully con volutional networks for semantic segmentation, ” in Pr oceedings of the IEEE conference on computer vision and pattern reco gnition , 2015, pp. 3431–3440. [19] O. Koller , O. Zargaran, H. Ney , and R. Bowden, “Deep sign: hybrid cnn-hmm for continuous sign language recognition, ” in Pr oceedings of the British Machine V ision Conference 2016 , 2016. [20] G. Trigeorgis, F . Ringev al, R. Brueckner , E. Marchi, M. A. Nicolaou, B. Schuller , and S. Zafeiriou, “ Adieu features? end-to-end speech emotion recognition using a deep con volutional recurrent network, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Conference on . IEEE, 2016, pp. 5200–5204. [21] Z. Aldeneh and E. M. Provost, “Using regional saliency for speech emo- tion recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 2741–2745. [22] A. Krizhevsk y , I. Sutskever , and G. E. Hinton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural infor- mation pr ocessing systems , 2012, pp. 1097–1105. [23] K. Simon yan and A. Zisserman, “V ery deep con volutional networks for large-scale image recognition, ” arXiv preprint , 2014. [24] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern recognition , 2016, pp. 770–778. [25] C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower , S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database, ” Language r esources and evaluation , vol. 42, no. 4, p. 335, 2008. [26] O. Russako vsky , J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy , A. Khosla, M. Bernstein et al. , “Imagenet large scale visual recognition challenge, ” International Journal of Computer V ision , vol. 115, no. 3, pp. 211–252, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment