Speaker-Invariant Training via Adversarial Learning
We propose a novel adversarial multi-task learning scheme, aiming at actively curtailing the inter-talker feature variability while maximizing its senone discriminability so as to enhance the performance of a deep neural network (DNN) based ASR syste…
Authors: Zhong Meng, Jinyu Li, Zhuo Chen
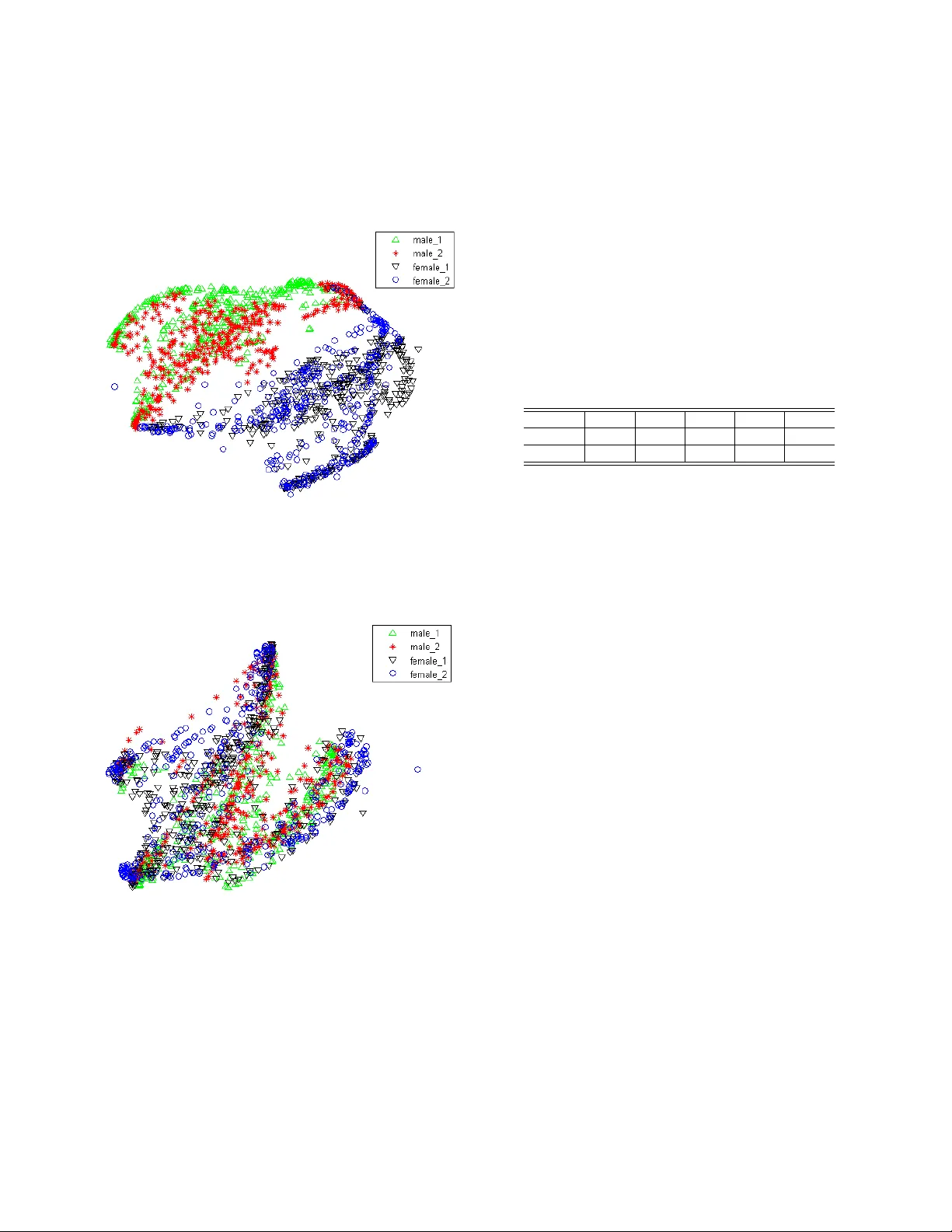
SPEAKER-INV ARIANT TRAINING VIA AD VERSARIAL LEARNING Zhong Meng 1 , 2 ∗ , Jinyu Li 1 , Zhuo Chen 1 , Y ong Zhao 1 , V adim Mazalo v 1 , Y ifan Gong 1 , Biing-Hwang (F r ed) J uang 2 1 Microsoft AI and Research, Redmond, W A, USA 2 Georgia Institute of T echnology , Atlanta, GA, USA ABSTRA CT W e propose a nov el adv ersarial multi-task learning scheme, aim- ing at activ ely curtailing the inter-talker feature v ariability while maximizing its senone discriminability so as to enhance the perfor- mance of a deep neural network (DNN) based ASR system. W e call the scheme speaker -in variant training (SIT). In SIT , a DNN acoustic model and a speak er classifier network are jointly optimized to min- imize the senone (tied triphone state) classification loss, and simul- taneously mini-maximize the speaker classification loss. A speaker- in variant and senone-discriminativ e deep feature is learned through this adv ersarial multi-task learning. W ith SIT , a canonical DNN acoustic model with significantly reduced variance in its output prob- abilities is learned with no e xplicit speaker-independent (SI) trans- formations or speaker-specific representations used in training or testing. Ev aluated on the CHiME-3 dataset, the SIT achie ves 4.99% relativ e word error rate (WER) improvement over the conv entional SI acoustic model. With additional unsupervised speaker adaptation, the speaker-adapted (SA) SIT model achieves 4.86% relati ve WER gain ov er the SA SI acoustic model. Index T erms — speaker-in variant training, adversarial learning, speech recognition, deep neural networks 1. INTR ODUCTION The deep neural network (DNN) based acoustic models hav e been widely used in automatic speech recognition (ASR) and hav e achiev ed extraordinary performance improvement [1, 2]. How- ev er, the performance of a speaker-independent (SI) acoustic model trained with speech data from a large number of speakers is still affected by the spectral variations in each speech unit caused by the inter-speaker variability . Therefore, speaker adaptation meth- ods are widely used to boost the recognition system performance [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]. Recently , adversarial learning has captured great attention of deep learning community given its remarkable success in estimat- ing generati ve models [14]. In speech, it has been applied to noise- robust [15, 16, 17, 18, 19] and conv ersational ASR [20] using gradi- ent rev ersal layer [21] or domain separation network [22]. Inspired by this, we propose speaker-in variant training (SIT) via adversarial learning to reduce the effect of speaker variability in acoustic mod- eling. In SIT , a DNN acoustic model and a DNN speaker classifier are jointly trained to simultaneously optimize the primary task of minimizing the senone classification loss and the secondary task of mini-maximizing the speaker classification loss. Through this adv er- sarial multi-task learning procedure, a feature extractor is learned as ∗ Zhong Meng performed the work while he was a research intern at Mi- crosoft AI and Research, Redmond, W A, USA. the bottom layers of the DNN acoustic model that maps the input speech frames from different speakers into speaker-in variant and senone-discriminativ e deep hidden features, so that further senone classification is based on representations with the speaker factor al- ready normalized out. The DNN acoustic model with SIT can be directly used to generate word transcription for unseen test speakers through one-pass online decoding. On top of the SIT DNN, further adaptation can be performed to adjust the model tow ards the test speakers, achie ving even higher ASR accurac y . W e ev aluate SIT with ASR experiments on CHiME-3 dataset, the SIT DNN acoustic model achieves 4.99% relative WER improv e- ment ov er the baseline SI DNN. Further , SIT achieves 4.86% relati ve WER gain over the SI DNN when the same unsupervised speaker adaptation process is performed on both models. With t-distributed stochastic neighbor embedding (t-SNE) [23] visualization, we sho w that, after SIT , the deep feature distrib utions of different speakers are well aligned with each other , which demonstrates the strong capabil- ity of SIT in reducing speaker -variability . 2. RELA TED WORK Speaker -adaptive training (SA T) is proposed to generate canonical acoustic models coupled with speak er adaptation. For Gaussian mix- ture model (GMM)-hidden Markov model (HMM) acoustic model, SA T applies unconstrained [24] or constrained [25] model-space lin- ear transformations that separately model the speaker-specific char- acteristics and are jointly estimated with the GMM-HMM parame- ters to maximize the likelihood of the training data. Cluster-adapti ve training (CA T) [26] is then proposed to use a linear interpolation of all the cluster means as the mean of the particular speaker instead of a single cluster as representativ e of a particular speaker . Howev er, SA T of GMM-HMM needs to hav e two sets of models, the SI model and canonical model. During testing, the SI model is used to gener- ate the first pass decoding transcription, and the canonical model is combined with speaker-specific transformation to adapt to the new speaker . For DNN-HMM acoustic model, CA T [12] and multi-basis adaptiv e neural networks [7] are proposed to represent the weight and/or the bias of the speaker-dependent (SD) affine transformation in each hidden layer of a DNN acoustic model as a linear combina- tion of SI bases, where the combination weights are low-dimensional SD speaker representations. The canonical SI bases with reduced variances are jointly optimized with the SD speaker representations during the SA T to minimize the cross-entropy loss. During unsuper- vised adaptation, the test speaker representations are re-estimated using alignments from the first-pass decoding of the test data with SI DNN as the supervisions and are used in the second-pass decod- ing to generate the transcription. Factorized hidden layer [13] is similar to [12, 7], but includes SI DNN weights as part of the linear combination. In [5], SD speaker codes are transformed by a set of SI matrices and then directly added to the biases of the hidden-layer affine transformations. The speaker codes and SI transformations are jointly estimated during SA T . F or these methods, two passes of decoding are required to generate the final transcription in unsuper- vised adaption setup, which increases the computational comple xity of the system. In [6, 3], an SI adaptation network is learned to derive speaker- normalized features from i-vectors to train the canonical DNN acoustic model. The i-vectors for the test speakers are then esti- mated and used for decoding after going through the SI adaptation network. In [20], a reconstruction network is trained to predict the input i-vector giv en the speech feature and its corresponding i-vector are at the input of the acoustic model. The mean-squared error loss of the i-vector reconstruction and the cross-entropy loss of the DNN acoustic model are jointly optimized through adversar- ial multi-task learning. Although these methods generate the final transcription with one-pass of decoding, they need to go through the entire test utterances in order to estimate the i-vectors, making it impossible to perform online decoding. Moreover , the accuracy of i-v ectors estimation are limited by the duration of the test utter- ances. The estimation of i-vector for each utterance also increases the computational complexity of the system. SIT directly minimizes the speaker variations by optimizing an adversarial multi-task objecti ve other than the most basic cross en- tropy object as in SA T . It forgoes the need of estimating any addi- tional SI bases or speaker representations during training or testing. The direct use of SIT DNN acoustic model in testing enables the generation of word transcription for unseen test speakers through one-pass online decoding. Moreover , it effecti vely suppresses the inter-speak er v ariability via a lightweight system with much reduced training parameters and computational complexity . T o achieve ad- ditional gain, unsupervised speaker adaptation can also be further conducted on the SIT model with one extra pass of decoding. 3. SPEAKER-INV ARIANT TRAINING T o perform SIT , we need a sequence of speech frames X = { x 1 , . . . , x N } , a sequence of senone labels Y = { y 1 , . . . , y N } aligned with X and a sequence of speaker labels S = { s 1 , . . . , s N } aligned with X . The goal of SIT is to reduce the variances of hid- den and output units distributions of the DNN acoustic model that are caused by the inherent inter-speaker variability in the speech signal. T o achiev e speaker -robustness, we learn a speaker -invariant and senone-discriminative deep hidden feature in the DNN acous- tic model through adversarial multi-task learning and make senone posterior predictions based on the learned deep feature. In order to do so, we vie w the first few layers of the acoustic model as a feature extractor network M f with parameters θ f that maps X from differ- ent speakers to deep hidden features F = { f 1 , . . . , f N } (see Fig. 1) and the upper layers of the acoustic model as a senone classifier M y with parameters θ y that maps the intermediate features F to the senone posteriors p y ( q | f i ; θ y ) , q ∈ Q as follows: M y ( f i ) = M y ( M f ( x i )) = p y ( q | x i ; θ f , θ y ) (1) where Q is the set of all senones modeled by the acoustic model. W e further introduce a speaker classifier network M s which maps the deep features F to the speaker posteriors p s ( a | f i ; θ s ) , a ∈ A as follo ws: M s ( M f ( x i )) = p s ( a | x i ; θ s , θ f ) (2) Fig. 1 . The framew ork of speaker -in variant training via adversarial learning for unsupervised adaptation of the acoustic models where a is one speaker in the set of all speakers A . T o make the deep features F speaker-in variant, the distrib utions of the features from different speakers should be as close to each other as possible. Therefore, the M f and M s are jointly trained with an adversarial objectiv e, in which θ f is adjusted to maximize the frame-level speaker classification loss L speaker ( θ f , θ s ) while θ s is adjusted to minimize L speaker ( θ f , θ s ) belo w: L speaker ( θ f , θ s ) = − N X i =1 log p s ( s i | x i ; θ f , θ s ) = − N X i =1 X a ∈A 1 [ a = s i ] log M s ( M f ( x i )) (3) where s i denote the speaker label for the input frame x i . This minimax competition will first increase the discriminativ- ity of M s and the speaker-in variance of the features generated by M f , and will ev entually conv erge to the point where M f generates extremely confusing features that M s is unable to distinguish. At the same time, we want to make the deep features senone- discriminativ e by minimizing the cross-entropy loss between the predicted senone posteriors and the senone labels as follows: L senone ( θ f , θ y ) = − N X i =1 log p y ( y i | x i ; θ f , θ y ) = − N X i =1 X q ∈Q 1 [ q = y i ] log M y ( M f ( x i )) (4) In SIT , the acoustic model network and the condition classifier network are trained to jointly optimize the primary task of senone classification and the secondary task of speaker classification with an adversarial objective function. Therefore, the total loss is con- structed as L total ( θ f , θ y , θ s ) = L senone ( θ f , θ y ) − λ L speaker ( θ s , θ f ) (5) where λ controls the trade-of f between the senone loss and the speaker classification loss in Eq.(4) and Eq.(3) respecti vely . W e need to find the optimal parameters ˆ θ y , ˆ θ f and ˆ θ s such that ( ˆ θ f , ˆ θ y ) = arg min θ y ,θ f L total ( θ f , θ y , ˆ θ s ) (6) ˆ θ s = arg max θ s L total ( ˆ θ f , ˆ θ y , θ s ) (7) The parameters are updated as follows via back propagation with stochastic gradient descent (SGD): θ f ← θ f − µ ∂ L senone ∂ θ f − λ ∂ L speaker ∂ θ f (8) θ s ← θ s − µ ∂ L speaker ∂ θ s (9) θ y ← θ y − µ ∂ L senone ∂ θ y (10) where µ is the learning rate. Note that the negativ e coef ficient − λ in Eq. (8) induces reversed gradient that maximizes L speaker ( θ f , θ s ) in Eq. (3) and makes the deep feature speaker-in variant. For easy implementation, gradient rev ersal layer is introduced in [21], which acts as an identity trans- form in the forward propagation and multiplies the gradient by − λ during the backward propagation. The optimized network consisting of M f and M y is used as the SIT acoustic model for ASR on test data. 4. EXPERIMENTS In this work, we perform SIT on a DNN-hidden Markov model (HMM) acoustic model for ASR on CHiME-3 dataset. 4.1. CHiME-3 Dataset The CHiME-3 dataset is released with the 3rd CHiME speech Sepa- ration and Recognition Challenge [27], which incorporates the W all Street Journal corpus sentences spoken in challenging noisy en vi- ronments, recorded using a 6-channel tablet based microphone array . CHiME-3 dataset consists of both real and simulated data. The real speech data was recorded in fiv e real noisy environments (on buses (BUS), in caf ´ es (CAF), in pedestrian areas (PED), at street junctions (STR) and in booth (BTH)). T o generate the simulated data, the clean speech is first conv olved with the estimated impulse response of the en vironment and then mixed with the background noise separately recorded in that environment [28]. The noisy training data consists of 1999 real noisy utterances from 4 speakers, and 7138 simulated noisy utterances from 83 speakers in the WSJ0 SI-84 training set recorded in 4 noisy environments. There are 3280 utterances in the dev elopment set including 410 real and 410 simulated utterances for each of the 4 en vironments. There are 2640 utterances in the test set including 330 real and 330 simulated utterances for each of the 4 en vironments. The speakers in training set, dev elopment set and the test set are mutually different (i.e., 12 dif ferent speakers in the CHiME-3 dataset). The training, dev elopment and test data sets are all recorded in 6 different channels. In the experiments, we use 9137 noisy training utterances in the CHiME-3 dataset as the training data. The real and simulated de vel- opment data in CHiME-3 are used as the test data. Both the training and test data are far -field speech from the 5th microphone channel. The WSJ 5K word 3-gram language model (LM) is used for decod- ing. 4.2. Baseline System In the baseline system, we first train an SI DNN-HMM acoustic model using 9137 noisy training utterances with cross-entrop y crite- rion. The 29-dimensional log Mel filterbank features together with 1st and 2nd order delta features (totally 87-dimensional) for both the clean and noisy utterances are extracted by following the process in [29]. Each frame is spliced together with 5 left and 5 right context frames to form a 957-dimensional feature. The spliced features are fed as the input of the feed-forward DNN after global mean and vari- ance normalization. The DNN has 7 hidden layers with 2048 hidden units for each layer . The output layer of the DNN has 3012 out- put units corresponding to 3012 senone labels. Senone-level forced alignment of the clean data is generated using a Gaussian mixture model-HMM system. As sho wn in T able 1, the WERs for the SI DNN are 17.84% and 17.72% respecti vely on real and simulated test data respectiv ely . Note that our experimental setup does not achie ve the state-of-the-art performance on CHiME-3 dataset (e.g., we did not perform beamforming, sequence training or use recurrent neural network language model for decoding.) since our goal is to simply verify the ef fectiveness of SIT in reducing inter -speaker v ariability . 4.3. Speaker -In variant T raining f or Robust Speech Recognition W e further perform SIT on the baseline noisy DNN acoustic model with 9137 noisy training utterances in CHiME-3. The feature ex- tractor M f is initialized with the first N h layers of the DNN and the senone classifier is initialized with the rest (7 − N h ) hidden layers plus the output layer . N h indicates the position of the deep hidden feature in the acoustic model. The speaker classifier M s is a feedfor - ward DNN with 2 hidden layers and 512 hidden units for each layer . The output layer of M s has 87 units predicting the posteriors of 87 speakers in the training set. M f , M y and M s are jointly trained with an adversarial multi-task objectiv e as described in Section 3. N h and λ are fixed at 2 and 3 . 0 in our experiments. The SIT DNN acoustic model achieves 16.95% and 16.54% WER on the real and simulated test data respecti vely , which are 4.99% and 6.66% relativ e improv ements over the SI DNN baseline. System Data BUS CAF PED STR A vg. SI Real 24.77 16.12 13.39 17.27 17.84 Simu 18.07 21.44 14.68 16.70 17.72 SIT Real 22.91 15.63 12.77 16.66 16.95 Simu 16.64 20.23 13.53 15.96 16.54 T able 1 . The ASR WER (%) performance of SI and SIT DNN acoustic models on real and simulated development set of CHiME-3. 4.4. V isualization of Deep Featur es W e randomly select two male speakers and two female speakers from the noisy training set and extract speech frames aligned with the phoneme “ah” for each of the four speakers. In Figs. 2 and 3, we visualize the deep features F generated by the SI and SIT DNN acoustic models when the “ah” frames of the four speakers are giv en as the input using t-SNE. In Fig. 2, the deep feature distrib utions in the SI model for the male (in red and green) and female speak- ers (in back and blue) are far away from each other and ev en the distributions for the speakers of the same gender are separated from each other . While after SIT , the deep feature distributions for all the male and female speak ers are well aligned with each other as shown in Fig. 3. The significant increase in the overlap among distribu- tions of dif ferent speakers justifies that the SIT remarkably enhances the speaker -in variance of the deep features F . The adversarial op- timization of the speaker classification loss does not just serve as a regularization term to achie ve better generalization on the test data. Fig. 2 . t-SNE visualization of the deep features F generated by the SI DNN acoustic model when speech frames aligned with phoneme “ah” from two male and two female speakers in CHiME-3 training set are fed as the input. Fig. 3 . t-SNE visualization of the deep features F generated by the SIT DNN acoustic model when the same speech frames as in Fig. 2 are fed as the input. 4.5. Unsupervised Speaker Adaptation SIT aims at suppressing the effect of inter-speaker variability on DNN acoustic model so that the acoustic model is more compact and has stronger discriminativ e po wer . When adapted to the same test speakers, the SIT DNN is expected to achiev e higher ASR perfor- mance than the baseline SI DNN due to the smaller overlaps among the distributions of dif ferent speech units. In our experiment, we adapt the SI and SIT DNNs to each of the 4 speakers in the test set in an unsupervised fashion. The con- strained re-training (CR T) [30] method is used for adaptation, where we re-estimate the DNN parameters of only a subset of layers while holding the remaining parameters fixed during cross-entropy train- ing. The adaptation target (1-best alignment) is obtained through the first-pass decoding of the test data, and the second-pass decoding is performed using the SA SI and SI DNNs. The WER results for unsupervised speaker adaptation is shown in T able 2, in which only the bottom 2 layers of the SI and SIT DNNs are adapted during CR T . The speaker -adapted (SA) SIT DNN achiev es 15.46% WER which is 4.86% relatively higher than the SA SI DNN. The CR T adaptation provides 8.91% and 8.79% relative WER gains ov er the unadapted SI and SIT models respecti vely . The lower WER after speaker adaptation indicates that SIT has effec- tiv ely reduced the high variance and overlap in an SI acoustic model caused by the inter-speak er variability . System BUS CAF PED STR A vg. SA SI 22.76 15.56 11.52 15.37 16.25 SA SIT 21.42 14.79 11.11 14.70 15.46 T able 2 . The ASR WER (%) performance of SA SI and SA SIT DNN acoustic models after CR T unsupervised speaker adaptation on real dev elopment set of CHiME-3. 5. CONCLUSIONS AND FUTURE WORKS In this work, SIT is proposed to suppress the effect of inter-speak er variability on the SI DNN acoustic model. In SIT , a DNN acous- tic model and a speaker classifier network are jointly optimized to minimize the senone classification loss, and simultaneously mini- maximize the speaker classification loss. Through this adversarial multi-task learning procedure, a feature e xtractor network is learned to map the input frames from different speakers to deep hidden fea- tures that are both speaker -invariant and senone-discriminati ve. Evaluated on CHiME-3 dataset, the SIT DNN acoustic model achiev es 4.99% relati ve WER improvement ov er the baseline SI DNN. W ith the unsupervised adaptation tow ards the test speakers using CR T , the SA SIT DNN achiev es additional 8.79% relative WER gain, which is 4.86% relati vely improved over the SA SI DNN. W ith t-SNE visualization, we show that, after SIT , the deep feature distributions of different speakers are well aligned with each other , which verifies the strong capability of SIT in reducing speaker -variability . SIT forgoes the need of estimating any additional SI bases or speaker representations which are necessary in other con ventional approaches such as SA T . The SIT trained DNN acoustic model can be directly used to generate the transcription for unseen test speakers through one-pass online decoding. It enables a lightweight speaker - in variant ASR system with reduced number of parameters for both training and testing. Additional gains are achiev able by performing further unsupervised speaker adaptation on top of the SIT model. In the future, we will ev aluate the performance of the i-vector based speaker-adversarial multi-task learning [20] on CHiME-3 dataset and compare it with the proposed SIT . W e will perform SIT on long short-term memory-recurrent neural networks acoustic models [31, 32] and compare the improvement with feedforward DNNs. Moreover , we will perform SIT on thousands of hours of data to verify its scalability to lar ge dataset. 6. REFERENCES [1] G. Hinton, L. Deng, D. Y u, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Pr ocessing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [2] Dong Y u and Jinyu Li, “Recent progresses in deep learning based acoustic models, ” IEEE/CAA Journal of Automatica Sinica , vol. 4, no. 3, pp. 396–409, 2017. [3] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic models using i-vectors, ” in 2013 IEEE W orkshop on Automatic Speech Recognition and Understanding , Dec 2013, pp. 55–59. [4] J. Xue, J. Li, D. Y u, M. Seltzer , and Y . Gong, “Singular value decomposition based low-footprint speaker adaptation and per - sonalization for deep neural network, ” in ICASSP , 2014, pp. 6359–6363. [5] S. Xue, O. Abdel-Hamid, H. Jiang, L. Dai, and Q. Liu, “Fast adaptation of deep neural netw ork based on discriminant codes for speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 22, no. 12, pp. 1713– 1725, Dec 2014. [6] Y . Miao, H. Zhang, and F . Metze, “Speaker adaptiv e train- ing of deep neural network acoustic models using i-vectors, ” IEEE/A CM T ransactions on Audio, Speec h, and Language Pr ocessing , vol. 23, no. 11, pp. 1938–1949, Nov 2015. [7] C. Wu and M. J. F . Gales, “Multi-basis adaptiv e neural network for rapid adaptation in speech recognition, ” in Pr oc. ICASSP , April 2015, pp. 4315–4319. [8] Y . Zhao, J. Li, and Y . Gong, “Low-rank plus diagonal adap- tation for deep neural networks, ” in Proc.ICASSP , 2016, pp. 5005–5009. [9] Z. Huang, S. Siniscalchi, I. Chen, et al., “Maximum a posteri- ori adaptation of network parameters in deep models, ” in Pr oc. Interspeech , 2015. [10] Z. Huang, J. Li, S. Siniscalchi, et al., “Rapid adaptation for deep neural networks through multi-task learning, ” in Inter- speech , 2015. [11] P . Swietojanski, J. Li, and S. Renals, “Learning hidden unit contributions for unsupervised acoustic model adapta- tion, ” IEEE/ACM T ransactions on Audio, Speech, and Lan- guage Processing , v ol. 24, no. 8, pp. 1450–1463, Aug 2016. [12] T . T an, Y . Qian, and K. Y u, “Cluster adapti ve training for deep neural network based acoustic model, ” IEEE/ACM T ransac- tions on A udio, Speech, and Language Pr ocessing , vol. 24, no. 3, pp. 459–468, March 2016. [13] L. Samarakoon and K. C. Sim, “Factorized hidden layer adaptation for deep neural network based acoustic modeling, ” IEEE/A CM T ransactions on Audio, Speec h, and Language Pr ocessing , vol. 24, no. 12, pp. 2241–2250, Dec 2016. [14] Ian Goodfello w , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair , Aaron Courville, and Y oshua Bengio, “Generative adv ersarial nets, ” in NIPS , pp. 2672–2680. 2014. [15] Y usuke Shinohara, “ Adversarial multi-task learning of deep neural networks for robust speech recognition., ” in INTER- SPEECH , 2016, pp. 2369–2372. [16] Dmitriy Serdyuk, Kartik Audhkhasi, Phil ´ emon Brakel, Bhu- vana Ramabhadran, Samuel Thomas, and Y oshua Bengio, “In- variant representations for noisy speech recognition, ” in NIPS W orkshop , 2016. [17] Sining Sun, Binbin Zhang, Lei Xie, and Y anning Zhang, “ An unsupervised deep domain adaptation approach for rob ust speech recognition, ” Neur ocomputing , 2017. [18] Z. Meng, Z. Chen, V . Mazalov , J. Li, and Y . Gong, “Unsuper- vised adaptation with domain separation networks for robust speech recognition, ” in Pr oceeding of ASR U , Dec 2017. [19] Zhong Meng, Jinyu Li, Y ifan Gong, and Biing-Hwang (Fred) Juang, “ Adversarial teacher-student learning for unsupervised domain adaptation, ” in Pr oc.ICASSP . IEEE, 2018. [20] George Saon, Gakuto Kurata, T om Sercu, et al., “English con- versational telephone speech recognition by humans and ma- chines, ” Pr oc. Interspeech , 2017. [21] Y aroslav Ganin and V ictor Lempitsky , “Unsupervised domain adaptation by backpropagation, ” in Proc. ICML , Lille, France, 2015, vol. 37, pp. 1180–1189, PMLR. [22] K onstantinos Bousmalis, George Trigeor gis, Nathan Silber - man, Dilip Krishnan, and Dumitru Erhan, “Domain separa- tion networks, ” in Proc. NIPS , D. D. Lee, M. Sugiyama, U. V . Luxbur g, I. Guyon, and R. Garnett, Eds., pp. 343–351. Curran Associates, Inc., 2016. [23] Laurens v an der Maaten and Geoffrey Hinton, “V isualizing data using t-sne, ” Journal of Machine Learning Resear ch , vol. 9, no. Nov , pp. 2579–2605, 2008. [24] T asos Anastasakos, John McDonough, Richard Schwartz, and John Makhoul, “ A compact model for speaker-adaptiv e train- ing, ” in ICSLP . IEEE, 1996. [25] M.J.F . Gales, “Maximum likelihood linear transformations for hmm-based speech recognition, ” Computer Speech & Lan- guage , v ol. 12, no. 2, pp. 75 – 98, 1998. [26] M. J. F . Gales, “Cluster adapti ve training of hidden markov models, ” IEEE T ransactions on Speech and A udio Pr ocessing , vol. 8, no. 4, pp. 417–428, Jul 2000. [27] J. Barker , R. Marxer , E. V incent, and S. W atanabe, “The third chime speech separation and recognition challenge: Dataset, task and baselines, ” in Pr oc.ASR U , Dec 2015, pp. 504–511. [28] T . Hori, Z. Chen, H. Erdogan, et al., “The merl/sri system for the 3rd chime challenge using beamforming, robust feature extraction, and advanced speech recognition, ” in Proc.ASR U , Dec 2015, pp. 475–481. [29] J. Li, D. Y u, J.-T . Huang, and Y . Gong, “Improving wide- band speech recognition using mixed-bandwidth training data in CD-DNN-HMM, ” in Pr oc. SLT . IEEE, 2012, pp. 131–136. [30] Hakan Erdogan, T omoki Hayashi, John R Hershey , T akaaki Hori, Chiori Hori, W ei-Ning Hsu, Suyoun Kim, Jonathan Le Roux, Zhong Meng, and Shinji W atanabe, “Multi-channel speech recognition: Lstms all the way through, ” in CHiME-4 workshop , 2016, pp. 1–4. [31] F . Beaufays H. Sak, A. Senior , “Long short-term memory re- current neural network architectures for large scale acoustic modeling, ” in Interspeech , 2014. [32] Z. Meng, S. W atanabe, J. R. Hershey , and H. Erdogan, “Deep long short-term memory adaptive beamforming networks for multichannel robust speech recognition, ” in ICASSP , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment