Adversarial Teacher-Student Learning for Unsupervised Domain Adaptation
The teacher-student (T/S) learning has been shown effective in unsupervised domain adaptation [1]. It is a form of transfer learning, not in terms of the transfer of recognition decisions, but the knowledge of posteriori probabilities in the source d…
Authors: Zhong Meng, Jinyu Li, Yifan Gong
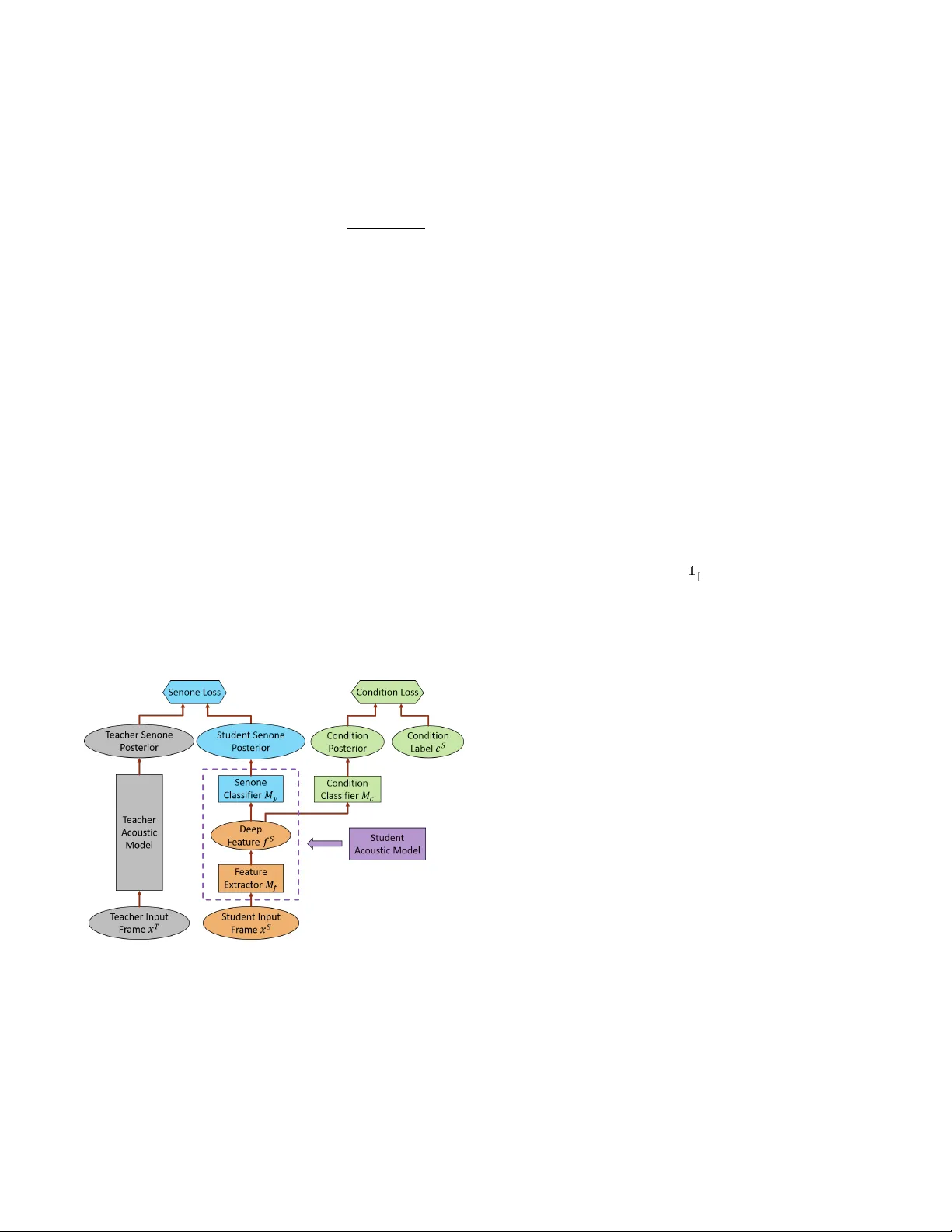
AD VERSARIAL TEA CHER-STUDENT LEARNING FOR UNSUPER VISED DOMAIN AD APT A TION Zhong Meng 1 , 2 ∗ , Jinyu Li 1 , Y ifan Gong 1 , Biing-Hwang (F r ed) Juang 2 1 Microsoft AI and Research, Redmond, W A, USA 2 Georgia Institute of T echnology , Atlanta, GA, USA ABSTRA CT The teacher -student (T/S) learning has been shown ef fective in unsupervised domain adaptation [1]. It is a form of transfer learning, not in terms of the transfer of recognition decisions, but the kno wl- edge of posteriori probabilities in the source domain as ev aluated by the teacher model. It learns to handle the speaker and en viron- ment variability inherent in and restricted to the speech signal in the target domain without proactiv ely addressing the rob ustness to other likely conditions. Performance degradation may thus ensue. In this work, we advance T/S learning by proposing adversarial T/S learning to explicitly achie ve condition-rob ust unsupervised domain adaptation. In this method, a student acoustic model and a condition classifier are jointly optimized to minimize the Kullback-Leibler di- ver gence between the output distributions of the teacher and student models, and simultaneously , to min-maximize the condition classi- fication loss. A condition-in variant deep feature is learned in the adapted student model through this procedure. W e further propose multi-factorial adversarial T/S learning which suppresses condition variabilities caused by multiple factors simultaneously . Evaluated with the noisy CHiME-3 test set, the proposed methods achie ve rel- ativ e word error rate improvements of 44.60% and 5.38%, respec- tiv ely , over a clean source model and a strong T/S learning baseline model. Index T erms — teacher-student learning, adversarial training, domain adaptation, parallel unlabeled data 1. INTR ODUCTION W ith the advance of deep learning, the performance of automatic speech recognition (ASR) has been greatly improved [2, 3, 4, 5, 6]. Howe ver , the ASR still suf fers from large performance degrada- tion when a well-trained acoustic model is presented in a new domain [7, 8]. Many domain adaptation techniques were proposed to address this issue, such as regularization-based [9, 10, 11, 12], transformation-based [13, 14, 15], singular value decomposition- based [16, 17, 18] and subspace-based [19, 20, 21, 22] approaches. Although these methods ef fectively mitigate the mismatch between source and target domains, the y reply on the transcription or the first-pass decoding hypotheses of the adaptation data. T o address these limitations, teacher-student (T/S) learning [23] is used to achieve unsupervised adaptation [1] with no exposure to any transcription or decoded hypotheses of the adaptation data. In T/S learning, the posteriors generated by the teacher model are used in lieu of the hard labels deriv ed from the transcriptions to train the target-domain student model. Although T/S learning achieves large ∗ Zhong Meng performed the work while he was a research intern at Mi- crosoft AI and Research, Redmond, W A, USA. word error rate (WER) reduction in domain adaptation, it is similar to the traditional training criterion such as cross entropy (CE) which implicitly handles the v ariations in each speech unit (e.g. senone) caused by the speaker and en vironment variability in addition to pho- netic variations. Recently , adversarial training has become a hot topic in deep learning with its great success in estimating generative models [24]. It has also been applied to noise-rob ust [25, 26, 27, 28] and speak er- in variant [29] ASR using gradient re versal layer [30] or domain sep- aration network [31]. A deep intermediate feature is learned to be both discriminati ve for the main task of senone classification and in- variant with respect to the shifts among different conditions. Here, one condition refers to one particular speaker or one acoustic en- vironment. For unsupervised adaptation, both the T/S learning and adversarial training forgo the need for any labels or decoded results of the adaptation data. T/S learning is more suitable for the situa- tion where parallel data is available since the paired data allows the student model to be better-guided by the kno wledge from the source model, while adversarial training is more po werful when such data is not av ailable. T o benefit from both methods, in this work, we adv ance T/S learning with adver sarial T/S training for condition-robust unsu- pervised domain adaptation, where a student acoustic model and a domain classifier are jointly trained to minimize the Kullback- Leibler (KL) diver gence between the output distributions of the teacher and student models as well as to min-maximize the con- dition classification loss through adversarial multi-task learning. A senone-discriminativ e and condition-in variant deep feature is learned in the adapted student model through this procedure. Based on this, we further propose the multi-factorial adversarial (MF A) T/S learning where the condition variabilities caused by multiple factors are minimized simultaneously . Evaluated with the noisy CHiME-3 test set, the proposed method achiev es 44.60% and 5.38% relativ e WER improvements over the clean model and a strong T/S adapted baseline acoustic model, respectiv ely . 2. TEA CHER-STUDENT LEARNING By using T/S learning for unsupervised adaption, we want to learn a student acoustic model that can accurately predict the senone pos- teriors of the target-domain data from a well-trained source-domain teacher acoustic model. T o achieve this, we only need tw o sequences of unlabeled parallel data, i.e., an input sequence of source-domain speech frames to the teacher model X T = { x T 1 , . . . , x T N } and an input sequence of tar get-domain speech frames to the student model X S = { x S 1 , . . . , x S N } . X T and X S are parallel to each other, i.e, each pair of x S i and x T i , ∀ i ∈ { 1 , . . . , N } are frame-by-frame syn- chronized. T/S learning aims at minimizing the Kullback-Leibler (KL) di- ver gence between the output distributions of the teacher model and the student model by taking the unlabeled parrallel data X T and X S as the input to the models. The KL diver gence between the teacher and student output distributions p T ( q | x T i ; θ T ) and p S ( q | x S i ; θ S ) is KL ( p T || p S ) = X i X q ∈Q p T ( q | x T i ; θ T ) log p T ( q | x T i ; θ T ) p S ( q | x S i ; θ S ) (1) where q is one of the senones in the senone set Q , i is the frame in- dex, θ T and θ S are the parameters of the teacher and student models respectiv ely . T o learn a student netw ork that approximates the given teacher network, we minimize the KL div ergence with respect to only the parameters of the student network while keeping the param- eters of the teacher model fixed, which is equi valent to minimizing the loss function below: L ( θ S ) = − X i X q ∈Q p T ( q | x T i ; θ T ) log p S ( q | x S i ; θ S ) (2) The target domain data used to adapt the student model is usu- ally recorded under multiple conditions, i.e., the adaptation data of- ten comes from a large number of different talkers speaking under various types of environments (e.g., home, bus, restaurant and etc). T/S learning can only implicitly handle the inherent speaker and en- vironment variability in the speech signal and its robustness can be improv ed if it can explicitly handle the condition in variance. 3. AD VERSARIAL TEA CHER-STUDENT LEARNING In this section, we propose the adversarial T/S learning (see Fig. 1) to effecti vely suppress the condition (i.e., speaker and environment) variations in the speech signal and achie ve robust unsupervised adap- tation with multi-conditional adaptation data. Fig. 1 . The framework of adversarial T/S learning for unsupervised adaptation of the acoustic models Similar to the T/S learning, we first clone the student acoustic model from the teacher and use unlabeled parallel data as the input to adapt the student model. T o achiev e condition-robustness, we learn a condition-invariant and senone-discriminative deep feature in the adapted student model through the senone posteriors gener- ated by the teacher model and the condition label for each frame. In order to do so, we vie w the first few layers of the acoustic model as a feature extractor with parameters θ f that maps input speech frames X S of dif ferent conditions to deep intermediate features F S = { f S 1 , . . . , f S N } and the upper layers of the student network as a senone classifier M y with parameters θ y that maps the interme- diate features F S to the senone posteriors p S ( q | f S i ; θ y ) , q ∈ Q as follows: M y ( f S i ) = M y ( M f ( x S i )) = p S ( q | x S i ; θ f , θ y ) (3) where we hav e θ S = { θ f , θ y } as the student model. W e further introduce a condition classifier network M c with θ c which maps the deep features F S to the condition posteriors p c ( a | x S i ; θ c , θ f ) , a ∈ A as follo ws: M c ( M f ( x S i )) = p c ( a | x S i ; θ c , θ f ) (4) where a is one condition in the set of all conditions A . T o make the deep features F S condition-in variant, the distribu- tions of the features from different conditions should be as close to each other as possile. Therefore, the M f and M c are jointly trained with an adversarial objectiv e, in which θ f is adjusted to maximize the condition classification loss L condition ( θ f , θ c ) while θ c is adjusted to minimize the L condition ( θ f , θ c ) belo w: L condition ( θ f , θ c ) = − N X i log p c ( c S i | x S i ; θ f , θ c ) = − N X i X a ∈A 1 [ a = c S i ] log M c ( M f ( x S i )) (5) where c S i denote the condition label for the input frame x S i of the student model. This minimax competition will first increase the discriminativ- ity of M c and the condition-inv ariance of the features generated by M f and will ev entually con verge to the point where M f generates extremely confusing features that M c is unable to distinguish. At the same time, we use T/S learning to let the behavior of the student model in the target domain approach the behavior of the teacher model in the source domain by minimizing the KL div er- gence of the output distributions between the student and teacher acoustic models. Equivalently , we minimize the loss function in Eq. (2) as re-formulated below: L TS ( θ f , θ y ) = − X i X q ∈Q p T ( q | x T i ; θ f , θ y ) M y ( M f ( x S i )) (6) In adversarial T/S learning, the student netw ork and the condition classifier network are trained to jointly optimize the primary task of T/S learning using soft targets from the teacher model and the sec- ondary task of condition classification with an adversarial objective function. Therefore, the total loss is constructed as L total ( θ f , θ y , θ c ) = L TS ( θ f , θ y ) − λ L condition ( θ f , θ c ) (7) where λ controls the trade-off between the T/S loss and the condition classification loss in Eq.(6) and Eq.(5) respectiv ely . W e need to find the optimal parameters ˆ θ y , ˆ θ f and ˆ θ c such that ( ˆ θ f , ˆ θ y ) = min θ y ,θ f L total ( θ f , θ y , ˆ θ c ) (8) ˆ θ c = max θ c L total ( ˆ θ f , ˆ θ y , θ c ) (9) The parameters are updated as follows via back propagation through time with stochastic gradient descent (SGD): θ f ← θ f − µ ∂ L TS ∂ θ f − λ ∂ L condition ∂ θ f (10) θ c ← θ c − µ ∂ L condition ∂ θ c (11) θ y ← θ y − µ ∂ L TS ∂ θ y (12) where µ is the learning rate. Note that the negati ve coef ficient − λ in Eq. (10) induces re- versed gradient that maximizes L condition ( θ f , θ c ) in Eq. (5) and makes the deep feature condition-inv ariant. For easy implemen- tation, gradient reversal layer is introduced in [30], which acts as an identity transform in the forward propagation and multiplies the gradient by − λ during the backward propagation. The optimized student network consisting of M f and M y is used as the adapted acoustic model for ASR in the target-domain. 4. MUL TI-F A CTORIAL ADVERSARIAL TEA CHER-STUDENT LEARNING Speaker and environment are two different factors that contribute to the inherent v ariability of the speech signal. In Section 3, adver- sarial T/S learning is proposed to reduce the variations induced by the single condition. For a more comprehensiv e and thorough so- lution to the condition variability problem, we further propose the multi-factorial adversarial (MF A) T/S learning, in which multiple factors causing the condition variability are suppressed simultane- ously through adversarial multi-task learning. In MF A T/S framew ork, we keep the senone classifier M y and feature e xtractor M f the same as in adversarial T/S, b ut introduce R condition classifiers M r c , r = 1 , . . . , R . M r c maps the deep feature to the condition posteriors of f actor r . T o make the deep features F S condition-in variant to each factor , we jointly train M f and M r c , r = 1 , . . . , R with an adversarial objective, in which θ f is adjusted to maximize the total condition classification loss of all factors while θ r c is adjusted to minimize the total condition classification loss of all factors. At the same time, we minimize the KL diver gence between the output distributions of the teacher and student models. The total loss function for MF A T/S learning is formulated as L total ( θ f , θ y , θ 1 c , . . . , θ R c ) = L TS ( θ f , θ y ) − λ R X r =1 L r condition ( θ r c , θ f ) (13) where L TS is defined in Eq. (6) and L r condition for each r are formu- lated in the same way as in Eq. (5). All the parameters are optimized in the same way as in Eq. (8) to Eq. (12). Note that better per- formance may be obtained when the condition losses hav e different combination weights. Howe ver , we just equally add them together in Eq. (13) to avoid tuning. 5. EXPERIMENTS T o compare directly with the results in [1], we use exactly the same experiment setup as in [1]. W e perform unsupervised adaptation of a clean long short-term memory (LSTM)- recurrent neural networks (RNN) [32, 33, 34] acoustic model trained with 375 hours of Mi- crosoft Cortana voice assistant data to the noisy CHiME-3 dataset [35] using T/S and adversarial T/S learning. The CHiME-3 dataset incorporates W all Street Journal (WSJ) corpus sentences spoken in challenging noisy en vironments, recorded using a 6-channel tablet. The real far -field noisy speech from the 5th microphone channel in CHiME-3 dev elopment data set is used for testing. A standard WSJ 5K word 3-gram language model (LM) is used for decoding. The clean acoustic model is an LSTM-RNN trained with cross- entropy criterion. W e extract 80-dimensional input log Mel filter- bank feature as the input to the acoustic model. The LSTM has 4 hidden layers with 1024 units in each layer . A 512-dimensional pro- jection layer is inserted on top each hidden layer to reduce the num- ber of parameters. The output layer has 5976 output units predicting senone posteriors. A WER of 23.16% is achieved when e valuating the clean model on the test data. The clean acoustic model is used as the teacher model in the following e xperiments. 5.1. T/S Learning for Unsupervised Adaptation W e first use parallel data consisting of 9137 pairs of clean and noisy utterances in the CHiME-3 training set (named as “clean-noisy”) as the adaptation data for T/S learning. In order to let the student model be in variant to environments, the training data for student model should include both clean and noisy data. Therefore, W e extend the original T/S learning work in [1] by also including 9137 pairs of the clean and clean utterances in CHiME-3 (named as “clean-clean”) for adaptation. By perform T/S learning with both the “clean-noisy” and “clean-clean” parallel data, the learned student model should per - form well on both the clean and noisy data because it will approach the beha vior of teacher model on clean data no matter it is presented with clean or noisy data. The unadapted Cortana model has 6.96% WER on the clean test set. After T/S learning with both the “clean-noisy” and “clean-clean” parallel data, the student model has 6.99% WER on the clean test. As the focus of this study is to improve T/S adaptation on noisy test data, we will only report results with the CHiME-3 real noisy channel 5 test set. The WER results on the noisy channel 5 test set of T/S learn- ing are sho wn in T able 1. The T/S learning achieves 13.88% and 13.56% average WERs when adapted to “clean-noisy” and “clean- noisy & clean-clean” respectively , which are 40.05% and 41.45% relativ e improv ements ov er the unadapted clean model. Note that our experimental setup does not achie ve the state-of-the-art perfor- mance on CHiME-3 dataset (e.g., we did not perform beamforming, sequence training or use RNN LM for decoding.) since our goal is to simply verify the effecti veness of adversarial T/S learning in achieving condition-rob ust unsupervised adaptation. 5.2. Adversarial T/S Learning for En vironment-Rob ust Unsu- pervised Adaptation W e adapt the clean acoustic model with the “clean-noisy & clean- clean” parallel data using adversarial T/S learning so that the result- ing student model is en vironment in variant. The feature e xtractor M f is initialized with the first N h hidden layers of the clean stu- dent LSTM and the senone classifier M y is initialized with the last (4 − N h ) hidden layers plus the output layer of the clean LSTM. N h indicates the position of the deep feature in the student LSTM. The condition classifier DNN M c has 2 hidden layers with 512 units in each hidden layer . T o achie ve en vironment-robust unsupervised adaptation, the condition classifier DNN M c is designed to predict the posteriors of different en vironments at the output layer . As the adaptation data comes from both the clean and noisy environments, we first use System Adaptation Data B US CAF PED STR A vg. Unadapted - 27.93 24.93 18.53 21.38 23.16 T/S clean-noisy 16.00 15.24 11.27 13.07 13.88 clean-noisy , clean-clean 15.96 14.32 11.00 13.04 13.56 T able 1 . The WER (%) performance of unadapted, T/S learning adapted LSTM acoustic models for robust ASR on the real noisy channel 5 test set of CHiME-3. System Conditions BUS CAF PED STR A vg. Adversarial T/S 2 en vironments 15.24 13.95 10.71 12.76 13.15 6 en vironments 15.58 13.23 10.65 13.10 13.12 87 speakers 14.97 13.63 10.84 12.24 12.90 87 speakers, 6 en vironments 15.38 13.08 10.47 12.45 12.83 T able 2 . The WER (%) performance of adversarial T/S learning adapted LSTM acoustic models for robust ASR on the real noisy channel 5 test set of CHiME-3. The adaptation data consists of “clean-noisy” and “clean-clean”. an M c with 2 output units to predict these two en vironments. As shown in T able 2, the adversarial T/S learning with 2-environment condition classifier achiev es 13.15% WER, which are 43.22% and 3.02% relativ ely improved over the unadapted and T/S learning adapted models respectively . The N h and λ are fixed at 4 and 5 . 0 respectiv ely in all our experiments. Howe ver , the noisy data in CHiME-3 is recorded under 5 dif- ferent noisy en vironments, i.e, on b uses (B US), in cafes (CAF), in pedestrian areas (PED), at street junctions (STR) and in booth (BTH). T o mitigate the speech variations among these environ- ments, we further use an M c with 6 output units to predict the posteriors of the 5 noisy and 1 clean environments. The WER with 6-en vironment condition classier is 13.12% which achieves 43.35% and 3.24% relative improvement over the unadapted and T/S learn- ing adapted baseline models respectiv ely . The increasing amount of noisy environments to be normalized through adversarial T/S learning lead to very limited WER improvement which indicates that the differences among v arious kinds of noises are not significant enough in CHiME-3 as compared to the distinctions between clean and noisy data. 5.3. Adversarial T/S Learning for Speaker -Robust Unsuper- vised Adaptation T o achiev e speaker -robust unsupervised adaptation, M c is designed to predict the posteriors of dif ferent speaker identities at the output layer . The 7138 simulated and 1999 real noisy utterances in CHiME- 3 training set are dictated by 83 and 4 different speakers respec- tiv ely and the 9137 clean utterances are read by the same speakers. In speaker-robust adversarial T/S adaptation, an M c with 87 output units are used to predict the posteriors of the 87 speakers. From T a- ble 2, the adversarial T/S learning with 87-speaker condition classi- fier achie ves 12.90% WER, which is 44.30% and 4.87% relative im- prov ement over the unadapted and T/S adapted baseline models re- spectiv ely . Larger WER improv ement is achieved by speaker-rob ust unsupervised adaptation than the en vironment-robust methods. This is because T/S learning itself is able to reduce the en vironment vari- ability through directly teaching the noisy student model with the senone posteriors from the clean data, which limits the space of im- prov ement that environment-rob ust adversarial T/S learning can ob- tain. 5.4. Multi-factorial Adversarial T/S Learning for Unsupervised Adaptation Speaker and en vironment robustness can be achieved simultaneously in unsupervised adaptation through MF A T/S learning, in which we need two condition classifiers: M 1 c predicts the posteriors of 87 speakers and M 2 c predicts the posteriors of 1 clean and 5 noisy en vi- ronments in the adaptation data. From T able 2, the MF A T/S learn- ing achie ves 12.83% WER, which is 44.60% and 5.38% relati ve im- prov ement over unadapted and T/S baseline models. The MF A T/S achiev es lo wer WER than all the unifactorial adversarial T/S systems because it addresses the variations caused by all kinds of f actors. 6. CONCLUSIONS In this work, adversarial T/S learning is proposed to adapt a clean acoustic model to highly mismatched multi-conditional noisy data in a purely unsupervised f ashion. T o suppress the condition v ariabil- ity in speech signal and achieve robust adaptation, a student acoustic model and a condition classifier are jointly optimized to minimize the KL diver gence between the output distributions of the teacher and student models while simultaneously mini-maximize condition classification loss. W e further propose the MF A T/S learning where multiple condition classifiers are introduced to reduce the condition variabilities caused by different factors. The proposed methods re- quires only the unlabeled parallel data for domain adaptation. For environment adaptation on CHiME-3 real noisy channel 5 dataset, T/S learning gets 41.45% relative WER reduction from the clean-trained acoustic model. Adversarial T/S learning with en vi- ronment and speaker classifiers achiev es 3.24% and 4.87% relative WER improvements over the strong T/S learning model, respec- tiv ely . MF A T/S achie ves 5.38% relative WER improvement over the same baseline. On top of T/S learning, reducing speaker vari- ability proves to be more ef fective than reducing en vironment vari- ability T/S learning on CHiME-3 dataset because T/S learning al- ready addresses most en vironment mismatch issues. Simultaneously decreasing the condition v ariability in multiple factors can further slightly improv e the ASR performance. The adversarial T/S learning was verified its effecti veness with a relati vely small CHiME-3 task. W e recently developed a far-field speaker system using thousands of hours data with T/S learning [36]. W e are no w currently applying the proposed adv ersarial T/S learning to further improv e our far-field speaker system. 7. REFERENCES [1] J. Li, M. L Seltzer , X. W ang, et al., “Large-scale domain adap- tation via teacher-student learning, ” in Pr oc. INTERSPEECH , 2017. [2] T . Sainath, B. Kingsbury , B. Ramabhadran, et al., “Making deep belief networks effecti ve for large v ocabulary continuous speech recognition, ” in Pr oc. ASR U , 2011, pp. 30–35. [3] N. Jaitly , P . Nguyen, A. Senior , and V . V anhouck e, “ Appli- cation of pretrained deep neural networks to large vocabulary speech recognition, ” in Pr oc. INTERSPEECH , 2012. [4] G. Hinton, L. Deng, D. Y u, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Pr ocessing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [5] Li Deng, Jin yu Li, Jui-T ing Huang, et al., “Recent advances in deep learning for speech research at Microsoft, ” in ICASSP . IEEE, 2013, pp. 8604–8608. [6] Dong Y u and Jinyu Li, “Recent progresses in deep learning based acoustic models, ” IEEE/CAA Journal of Automatica Sinica , vol. 4, no. 3, pp. 396–409, 2017. [7] J. Li, L. Deng, Y . Gong, and R. Haeb-Umbach, “ An overvie w of noise-rob ust automatic speech recognition, ” IEEE/A CM T ransactions on Audio, Speech and Language Pr ocessing , vol. 22, no. 4, pp. 745–777, April 2014. [8] J. Li, L. Deng, R. Haeb-Umbach, and Y . Gong, Robust Auto- matic Speech Recognition: A Bridge to Practical Applications , Academic Press, 2015. [9] D. Y u, K. Y ao, H. Su, G. Li, and F . Seide, “Kl-diver gence regularized deep neural network adaptation for impro ved large vocab ulary speech recognition, ” in Pr oc. ICASSP , May 2013, pp. 7893–7897. [10] Z. Huang, S. Siniscalchi, I. Chen, et al., “Maximum a posteri- ori adaptation of network parameters in deep models, ” in Pr oc. Interspeech , 2015. [11] H. Liao, “Speaker adaptation of context dependent deep neural networks, ” in Pr oc. ICASSP , May 2013, pp. 7947–7951. [12] Z. Huang, J. Li, S. Siniscalchi, et al., “Rapid adaptation for deep neural networks through multi-task learning, ” in Inter- speech , 2015. [13] F . Seide, G. Li, X. Chen, and D. Y u, “Feature engineering in context-dependent deep neural networks for con versational speech transcription, ” in Pr oc. ASR U , Dec 2011, pp. 24–29. [14] P . Swietojanski, J. Li, and S. Renals, “Learning hidden unit contributions for unsupervised acoustic model adapta- tion, ” IEEE/ACM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 24, no. 8, pp. 1450–1463, Aug 2016. [15] Y . Zhao, J. Li, J. Xue, and Y . Gong, “In vestigating online low-footprint speaker adaptation using generalized linear re- gression and click-through data, ” in ICASSP , 2015, pp. 4310– 4314. [16] Jian Xue, Jinyu Li, and Y ifan Gong, “Restructuring of deep neural network acoustic models with singular value decompo- sition., ” in Interspeech , 2013, pp. 2365–2369. [17] J. Xue, J. Li, D. Y u, M. Seltzer, and Y . Gong, “Singular v alue decomposition based lo w-footprint speaker adaptation and per- sonalization for deep neural network, ” in Proc. ICASSP , May 2014, pp. 6359–6363. [18] Y . Zhao, J. Li, and Y . Gong, “Low-rank plus diagonal adapta- tion for deep neural networks, ” in Pr oc. ICASSP , March 2016, pp. 5005–5009. [19] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic models using i-vectors, ” in Pr oc. ASR U , Dec 2013, pp. 55–59. [20] S. Xue, O. Abdel-Hamid, H. Jiang, L. Dai, and Q. Liu, “Fast adaptation of deep neural netw ork based on discriminant codes for speech recognition, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 22, no. 12, pp. 1713– 1725, Dec 2014. [21] L. Samarakoon and K. C. Sim, “Factorized hidden layer adaptation for deep neural network based acoustic modeling, ” IEEE/A CM T ransactions on Audio, Speec h, and Languag e Pr ocessing , vol. 24, no. 12, pp. 2241–2250, Dec 2016. [22] Y . Zhao, J. Li, K. Kumar , and Y . Gong, “Extended lo w-rank plus diagonal adaptation for deep and recurrent neural net- works, ” in ICASSP , 2017, pp. 5040–5044. [23] J. Li, R. Zhao, J.-T . Huang, and Y . Gong, “Learning small- size DNN with output-distribution-based criteria., ” in Pr oc. INTERSPEECH , 2014, pp. 1910–1914. [24] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair, Aaron Courville, and Y oshua Bengio, “Generativ e adversarial nets, ” in Advances in Neural Information Pr ocessing Systems , pp. 2672–2680. 2014. [25] Y usuke Shinohara, “ Adversarial multi-task learning of deep neural networks for robust speech recognition., ” in INTER- SPEECH , 2016, pp. 2369–2372. [26] D. Serdyuk, K. Audhkhasi, P . Brakel, B. Ramabhadran, et al., “In variant representations for noisy speech recognition, ” in NIPS W orkshop , 2016. [27] Sining Sun, Binbin Zhang, Lei Xie, et al., “ An unsupervised deep domain adaptation approach for robust speech recogni- tion, ” Neur ocomputing , 2017. [28] Z. Meng, Z. Chen, V . Mazalov , J. Li, and Y . Gong, “Unsuper- vised adaptation with domain separation networks for robust speech recognition, ” in Pr oceeding of ASR U , 2017. [29] Z. Meng, J. Li, Z. Chen, et al., “Speaker-in variant training via adversarial learning, ” in Pr oc. ICASSP , 2018. [30] Y arosla v Ganin and V ictor Lempitsky , “Unsupervised domain adaptation by backpropagation, ” in ICML , 2015. [31] K onstantinos Bousmalis, George T rigeorgis, Nathan Silber- man, Dilip Krishnan, and Dumitru Erhan, “Domain separation networks, ” in NIPS . Curran Associates, Inc., 2016. [32] H. Sak, A. Senior , and F . Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in Interspeech , 2014. [33] Z. Meng, S. W atanabe, J. R. Hershey , and H. Erdogan, “Deep long short-term memory adaptive beamforming networks for multichannel robust speech recognition, ” in ICASSP , 2017. [34] H. Erdogan, T . Hayashi, J. R. Hershey , et al., “Multi-channel speech recognition: Lstms all the way through, ” in CHiME-4 workshop , 2016, pp. 1–4. [35] J. Barker , R. Marxer , E. V incent, and S. W atanabe, “The third CHiME speech separation and recognition challenge: Dataset, task and baselines, ” in Pr oc. ASR U , 2015, pp. 504–511. [36] J. Li, R. Zhao, Z. Chen, et al., “Developing far-field speaker system via teacher-student learning, ” in Pr oc. ICASSP , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment