Unsupervised Adaptation with Domain Separation Networks for Robust Speech Recognition
Unsupervised domain adaptation of speech signal aims at adapting a well-trained source-domain acoustic model to the unlabeled data from target domain. This can be achieved by adversarial training of deep neural network (DNN) acoustic models to learn …
Authors: Zhong Meng, Zhuo Chen, Vadim Mazalov
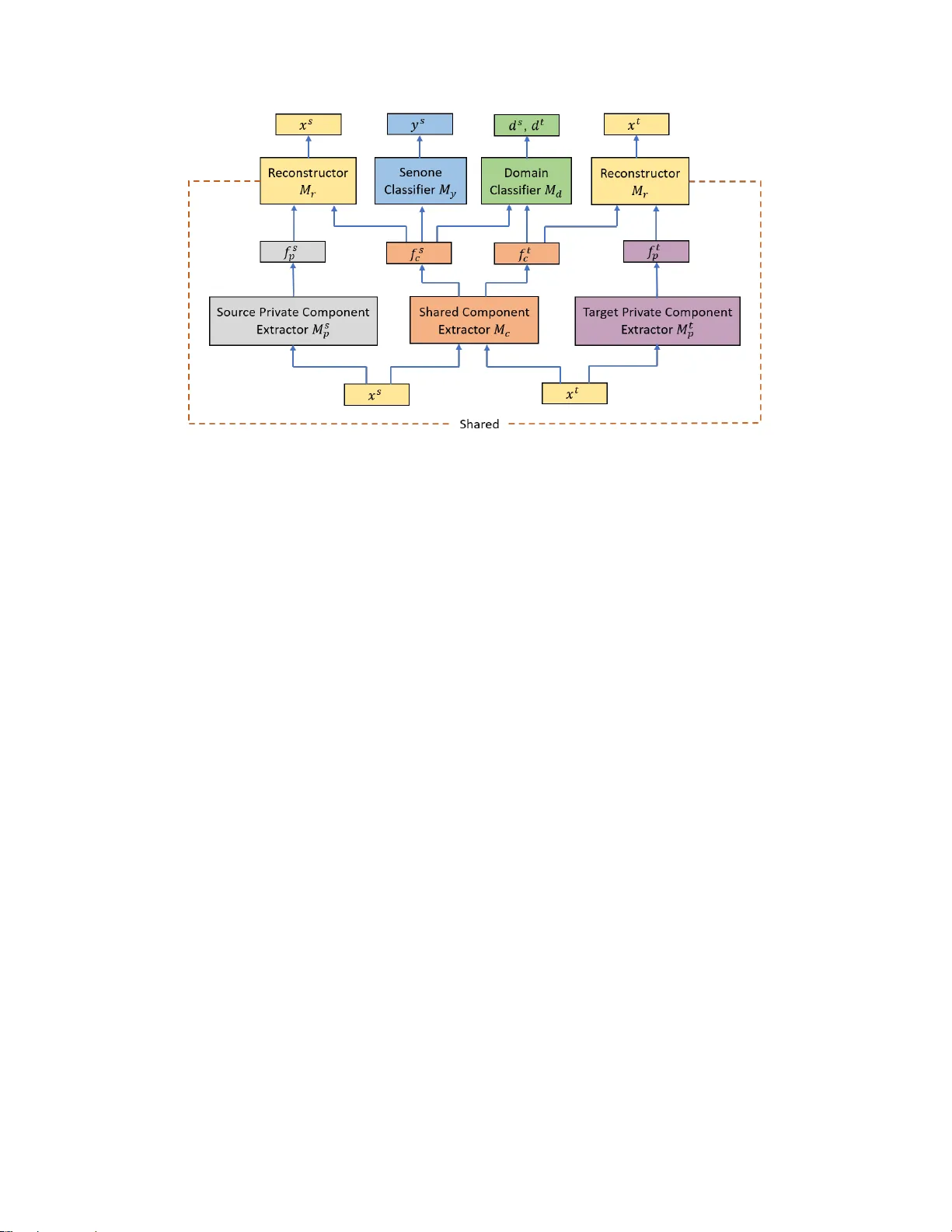
UNSUPER VISED AD APT A TION WITH DOMAIN SEP ARA TION NETWORKS FOR R OBUST SPEECH RECOGNITION Zhong Meng 1 , 2 ∗ , Zhuo Chen 1 , V adim Mazalov 1 , Jinyu Li 1 , Y ifan Gong 1 1 Microsoft AI and Research, Redmond, W A 2 Georgia Institute of T echnology , Atlanta, GA ABSTRA CT Unsupervised domain adaptation of speech signal aims at adapting a well-trained source-domain acoustic model to the unlabeled data from target domain. This can be achiev ed by adversarial training of deep neural network (DNN) acoustic models to learn an intermediate deep representation that is both senone-discriminati ve and domain-inv ariant. Specifi- cally , the DNN is trained to jointly optimize the primary task of senone classification and the secondary task of domain classification with adversarial objecti ve functions. In this work, instead of only focusing on learning a domain-in variant feature (i.e. the shared component between domains), we also characterize the difference between the source and target domain distrib utions by e xplicitly modeling the pri vate com- ponent of each domain through a priv ate component e xtractor DNN. The priv ate component is trained to be orthogonal with the shared component and thus implicitly increases the degree of domain-in variance of the shared component. A reconstructor DNN is used to reconstruct the original speech feature from the priv ate and shared components as a regu- larization. This domain separation framework is applied to the unsupervised en vironment adaptation task and achie ved 11.08% relative WER reduction from the gradient re versal layer training, a representative adversarial training method, for automatic speech recognition on CHiME-3 dataset. Index T erms — robust speech recognition, deep neural networks, domain adaptation, adversarial training, multi-task training 1. INTR ODUCTION In recent years, adv ances in deep learning have led to re- markable performance boost in automatic speech recognition (ASR) [1, 2, 3, 4, 5, 6]. Howe ver , ASR systems still suffer from lar ge performance degradation when acoustic mismatch exists between the training and test conditions [7, 8]. Many factors contribute to the mismatch, such as v ariation in en- vironment noises, channels and speaker characteristics. Do- main adaptation is an ef fectiv e way to address this limitation, ∗ Zhong Meng performed the work while he was a research intern at Mi- crosoft AI and Research, Redmond, W A. in which the acoustic model parameters or input features are adjusted to compensate for the mismatch. One dif ficulty with domain adaptation is that av ailable data from the target domain is usually limited, in which case the acoustic model can be easily overfitted. T o address this issue, regularization-based approaches are proposed in [9, 10, 11, 12] to regularize the neuron output distrib utions or the model parameters. In [13, 14], transformation-based approaches are introduced to reduce the number of learn- able parameters. In [15, 16, 17], the trainable parameters are further reduced by singular value decomposition of weight matrices of a neural network. Although these methods utilize the limited data from the target domain, they still require labelling for the adaptation data and can only be used in supervised adaptation. Unsupervised domain adaptation is necessary when hu- man labelling of the tar get domain data is una vailable. It has become an important topic with the rapid increase of the amount of untranscribed speech data for which the human an- notation is expensiv e. Pawel et al. proposed to learn the con- tribution of hidden units by additional amplitude parameters [18] and dif ferential pooling [19]. Recently , W ang et al. pro- posed to adjust the linear transformation learned by batch nor- malized acoustic model in [20]. Although these methods lead to increased performance in the ASR task when no labels are av ailable for the adaptation data, they still rely on the senone (tri-phone state) alignments against the unlabeled adaptation data through first pass decoding. The first pass decoding re- sult is unreliable when the mismatch between the training and test conditions is significant. It is also time-consuming and can be hardly applied to huge amount of adaptation data. There are ev en situations when decoding adaptation data is not allo wed because of the priv acy agreement signed with the speakers. These methods depending on the first pass decoding of the unlabeled adaptation data is sometimes called “semi- supervised” adaptation in literature. The goal of our study is to achiev e purely unsupervised domain adaptation without any exposure to the labels or the decoding results of the adaptation data in the target domain. In [21] we show that the source-domain model can be ef- fectiv ely adapted without any transcription by using teacher- student (T/S) learning [22], in which the posterior probabil- ities generated by the source-domain model can be used in lieu of labels to train the target-domain model. Ho we ver , T/S learning relies on the availability of parallel unlabeled data which can be usually simulated. Howe ver , if parallel data is not av ailable, we cannot use T/S learning for model adaptation. In this study , we are exploring the solution to do- main adaptation without parallel data and without transcrip- tion. Recently , adversarial training has become a very hot topic in deep learning because of its great success in estimat- ing generativ e models [23]. It was first applied to the area of unsupervised domain adaptation by Ganin et al. in [24] in a form of multi-task learning. In their work, the unsu- pervised adaptation is achieved by learning deep intermedi- ate representations that are both discriminativ e for the main task (image classification) on the source domain and in v ari- ant with respect to mismatch between source and target do- mains. The domain in variance is achiev ed by the adversarial training of the domain classification objecti ve functions. This can be easily implemented by augmenting any feed-forward models with a fe w standard layers and a gradient r eversal layer (GRL) . This GRL approach has been applied to acoustic models for unsupervised adaptation in [25] and for increasing noise robustness in [26, 27]. Improved ASR performance is achiev ed in both scenarios. Howe ver , the GRL method focuses only on learning a domain-in v ariant representation, ignoring the unique charac- teristics of each domain, which could also be informati ve. In- spired by this, Bousmailis et al. [28] proposed the domain separation networks (DSNs) to separate the deep representa- tion of each training sample into two parts: one priv ate com- ponent that is unique to its domain and one shared component that is inv ariant to the domain shift. In this work, we pro- pose to apply DSN for unsupervised domain adaptation on a DNN-hidden Markov model (HMM) acoustic model, aim- ing to increase the noise robustness in speech recognition. In the proposed frame work, the shared component is learned to be both senone-discriminativ e and domain-in v ariant through adversarial multi-task training of a shared component extrac- tor and a domain classifier . The pri v ate component is trained to be orthogonal with the shared component to implicitly in- crease the de gree of domain-inv ariance of the shared compo- nent. A reconstructor DNN is used to reconstruct the original speech feature from the priv ate and shared components, serv- ing for regularization. The proposed method achiev es 11 . 08% relativ e WER improvement ov er the GRL training approach for robust ASR on the CHiME-3 dataset. 2. DOMAIN SEP ARA TION NETWORKS In the pur ely unsupervised domain adaptation task, we only have access to a sequence of speech frames X s = { x s 1 , . . . , x s N s } from the source domain distribution, a se- quence of senone labels Y s = { y s 1 , . . . , y s N s } aligned with source data X s and a sequence of speech frames X t = { x t 1 , . . . , x t N t } from a target domain distribution. Senone labels or other types of transcription are not a vailable for the target speech sequence X t . When applying domain separation networks (DSNs) to the unsupervised adaptation task, our goal is to learn the shared (or common) component extractor DNN M c that maps an input speech frame x s from source domain or x t from tar get domain to a domain-in variant shared component f s c or f t c respectiv ely . At the same time, learn a senone clas- sifier DNN M y that maps the shared component f s c from the source domain to the correct senone label y s . T o achie ve this, we first perform adversarial training of the domain classifier DNN M d that maps the shared component f s c or f t c to its domain label d s or d t , while simultaneously minimizing the senone classificaton loss of M y giv en shared component f s c from the source domain to ensure the senone- dicriminativeness of f s c . For the source or the tar get domain, we extract the source or the target priv ate component f s p or f t p that is unique to the source or the target domain through a source or a target priv ate component extractor M s p or M t p . The shared and priv ate com- ponents of the same domain are trained to be orthogonal to each other to further enhance the degree of domain-in v ariance of the shared components. The extracted shared and priv ate components of each speech frame are concatenated and fed as the input of a reconstructor M r to reconstruct the input speech frame x s or x t . The architecture of DSN is shown in Fig. 1, in which all the sub-networks are jointly optimized using SGD. The opti- mized shared component extractor M c and senone classifier M y form the adapted acoustic model for subsequent robust speech recognition. 2.1. Deep Neural Networks Acoustic Model The shared component extractor M c and senone predictor of the DSN are initialized from an DNN-HMM acoustic model. The DNN-HMM acoustic model is trained with la- beled speech data ( X s , Y s ) from the source domain. The senone-lev el alignment Y s is generated by a well-trained GMM-HMM system. Each output unit of the DNN acoustic model corresponds to one of the senones in the set Q . The output unit for senone q ∈ Q is the posterior probability p ( q | x s n ) obtained by a soft- max function. 2.2. Shared Component Extraction with Adversarial T raining The well-trained acoustic model DNN in Section 2.1 can be decomposed into two parts: a share component extractor M c with parameters θ c and a senone classifier M y with param- eters θ y . An input speech frame from source domain x s is first mapped by the M c to a K-dimensional shared component Fig. 1 . The architecture of domain separation networks. f s c ∈ R K . f s c is then mapped to the senone label posteriors by a senone classifier M y with parameters θ y as follows. M y ( f s c ) = M y ( M c ( x s i )) = p ( ˆ y s n = q | x s i ; θ c , θ y ) (1) where ˆ y s i denotes the predicted senone label for source frame x s i and q ∈ Q . The domain classifier DNN M d with parameters θ d takes the shared component from source domain f s c or target do- main f t c as the input to predict the two-dimensional domain label posteriors as follo ws (the 1st and 2nd output units stand for the source and target domains respecti vely). M d ( M c ( x s i )) = p ( ˆ d s i = a | x s i ; θ c , θ d ) , a ∈ { 1 , 2 } (2) M d ( M c ( x t j )) = p ( ˆ d t j = a | x t j ; θ c , θ d ) , a ∈ { 1 , 2 } (3) where ˆ d s i and ˆ d t j denote the predicted domain labels for the source frame x s i and the target frame x t j respectiv ely . In order to adapt the source domain acoustic model (i.e., M c and M y ) to the unlabeled data from target domain, we want to make the distribution of the source domain shared component P ( f s c ) = P ( M c ( x s )) as close to that of the target domain P ( f t c ) = P ( M c ( x t )) as possible. In other w ords, we want to make the shared component domain-inv ariant. This can be realized by adv ersarial training, in which we adjust the parameters θ c of shared component extractor to maximize the loss of the domain classifier L c domain ( θ c ) belo w while ad- justing the parameters θ d to minimize the loss of the domain classifier L d domain ( θ d ) below . L d domain ( θ d ) = − N s X i log p ( ˆ d s i = 1 | x s i ; θ d ) − N t X j log p ( ˆ d t j = 2 | x t j ; θ d ) (4) L c domain ( θ c ) = − N s X i log p ( ˆ d s i = 1 | x s i ; θ c ) − N t X j log p ( ˆ d t j = 2 | x t j ; θ c ) (5) This minimax competition will first increase the capability of both the shared component extractor and the domain classi- fier and will e ventually con ver ge to the point where the shared component extractor generates e xtremely confusing represen- tations that domain classifier is unable to distinguish (i.e., domain-in v ariant). Simultaneously , we minimize the loss of the senone clas- sifier below to ensure the domain-inv ariant shared component f s c is also discriminativ e to senones. L senone ( θ c , θ y ) = − N s X i log p ( y s i | x s i ; θ y , θ c ) (6) Since the adversarial training of the domain classifier M d and shared component e xtractor M c has made the distrib ution of the target domain shared-component f t c as close to that of f s c as possible, the f t c is also senone-discriminativ e and will lead to minimized senone classification error giv en optimized M y . Because of the domain-in variant property , good adap- tation performance can be achieved when the target domain data goes through the network. 2.3. Private Components Extraction T o further increase the degree of domain-in variance of the shared components, we explicitly model the priv ate compo- nent that is unique to each domain by a pri v ate component extractor DNN M p parameterized by θ p . M s p and M t p map the source frame x s and the target frame x t to hidden rep- resentations f s p = M s p ( x s ) and f t p = M t p ( x t ) which are the priv ate components of the source and target domains respec- tiv ely . The priv ate component for each domain is trained to be orthogonal to the shared component by minimizing the dif- ference loss below . L diff ( θ c , θ s p , θ t p ) = N s X i M c ( x s i ) M s p ( x s i ) > 2 F + N t X j M c ( x t j ) M t p ( x t j ) > 2 F (7) where || · || 2 F is the squared Frobenius norm. All the v ectors are assumed to be column-wise. As a regularization term, the predicted shared and priv ate components are then concatenated and fed into a reconstruc- tor DNN M r with parameters θ r to recov er the input speech frames x s and x t from both source and target domains re- spectiv ely . The reconstructor is trained to minimize the mean square error based reconstruction loss as follows: L recon ( θ c , θ s p , θ t p , θ r ) = N s X i || ˆ x s i − x s i || 2 2 + N t X j || ˆ x t j − x t j || 2 2 (8) ˆ x s i = M r ([ M c ( x s i ) , M s p ( x s i )]) (9) ˆ x t j = M r ([ M c ( x t j ) , M t p ( x t j )]) (10) where [ · , · ] denotes concatenation of two vectors. The total loss of DSN is formulated as follows and is jointly optimized with respect to the parameters. L total ( θ y , θ c , θ d , θ s p , θ t p , θ r ) = L senone ( θ c , θ y ) + L d domain ( θ d ) − α L c domain ( θ c ) + β L diff ( θ c , θ s p , θ t p ) + γ L recon ( θ c , θ s p , θ t p , θ r ) (11) min θ y ,θ c ,θ d ,θ s p ,θ t p ,θ r L total ( θ y , θ c , θ d , θ s p , θ t p , θ r ) (12) All the parameters of DSN are jointly optimized through backprogation with stochastic gradient descent (SGD) as follows: θ c ← θ c − µ ∂ L senone ∂ θ c − α ∂ L c domain ∂ θ c + β ∂ L diff ∂ θ c + γ ∂ L recon ∂ θ c (13) θ d ← θ d − µ ∂ L d domain ∂ θ d , θ y ← θ y − µ ∂ L senone ∂ θ y (14) θ s p ← θ s p − µ β ∂ L diff ∂ θ s p + γ ∂ L recon ∂ θ s p (15) θ t p ← θ t p − µ β ∂ L diff ∂ θ t p + γ ∂ L recon ∂ θ t p (16) θ r ← θ r − µ ∂ L recon ∂ θ r (17) Note that the negati ve coefficient − α in Eq. (13) induces rev ersed gradient that maximizes the domain classification loss in Eq. (5) and makes the shared components domain- in v ariant. W ithout the rev ersal gradient, SGD would make representations dif ferent across domains in order to minimize Eq. (4). For easy implementation, GRL is introduced in [24], which acts as an identity transform in the forward pass and multiplies the gradient by − α during the backward pass. The optimized shared component extractor M c and senone classifier M y form the adapted acoustic model for robust speech recognition. 3. EXPERIMENTS In this work, we perform the pure unsupervised en viron- ment adaptation of the DNN-HMM acoustic model with domain separation networks for robust speech recognition on CHiME-3 dataset. 3.1. CHiME-3 Dataset The CHiME-3 dataset is released with the 3rd CHiME speech Separation and Recognition Challenge [29], which incorpo- rates the W all Street Journal corpus sentences spoken in challenging noisy en vironments, recorded using a 6-channel tablet based microphone array . CHiME-3 dataset consists of both real and simulated data. The real speech data was recorded in four real noisy en vironments (on buses (BUS), in caf ´ es (CAF), in pedestrian areas (PED), and at street junc- tions (STR)). T o generate the simulated data, the clean speech is first con voluted with the estimated impulse response of the en vironment and then mixed with the background noise sep- arately recorded in that en vironment [30]. The noisy training data consists of 1600 real noisy utterances from 4 speakers, and 7138 simulated noisy utterances from 83 speakers in the WSJ0 SI-84 training set recorded in 4 noisy en vironments. There are 3280 utterances in the dev elopment set including 410 real and 410 simulated utterances for each of the 4 envi- ronments. There are 2640 utterances in the test set including 330 real and 330 simulated utterances for each of the 4 envi- ronments. The speakers in training set, dev elopment set and the test set are mutually different (i.e., 12 different speakers in the CHiME-3 dataset). The training, de velopment and test data sets are all recorded in 6 different channels. 8738 clean utterances corresponding to the 8738 noisy training utterances in the CHiME-3 dataset are selected from the WSJ0 SI-85 training set to form the clean training data in our experiments. WSJ 5K word 3-gram language model is used for decoding. 3.2. Baseline System In the baseline system, we first train a DNN-HMM acoustic model with clean speech and then adapt the clean acoustic model to noisy data using GRL unsupervised adaptation in [24]. Hence, the source domain is with clean speech while the target domain is with noisy speech. The 29-dimensional log Mel filterbank features together with 1st and 2nd order delta features (totally 87-dimensional) for both the clean and noisy utterances are e xtracted by following the process in [31]. Each frame is spliced to- gether with 5 left and 5 right context frames to form a 957- dimensional feature. The spliced features are fed as the input of the feed-forward DNN after global mean and variance normalization. The DNN has 7 hidden layers with 2048 hidden units for each layer . The output layer of the DNN has 3012 output units corresponding to 3012 senone labels. Senone-lev el forced alignment of the clean data is generated using a GMM-HMM system. The DNN is first trained with 8738 clean training utterances in CHiME-3 and the align- ment to minimize the cross entrop y loss and then tested with simulation and real dev elopment data of CHiME-3. The DNN well-trained with clean data is then adapted to the 8738 noisy utterances from Channel 5 using GRL method. No senone alignment of the noisy adaptation data is used for the unsupervised adaptation. The feature extractor is initial- ized with the first 4 hidden layers of the clean DNN and the senone classifier is initialized with the last 3 hidden layers plus the output layers of the clean DNN. The domain classi- fier is a feedforward DNN with two hidden layers and each hidden layer has 512 hidden units. The output layer of the domain classifier has 2 output units representing source and target domains. The 2048 hidden units of the 4 th hidden layer of the DNN acoustic model is fed as the input to the domain classifier . A GRL is inserted in between the deep representa- tion and the domain classifier for easy implementation. The GRL adapted system is tested on real and simulation noisy dev elopment data in CHiME-3 dataset. 3.3. Domain Separation Networks for Unsupervised Adaptation W e adapt the clean DNN acoustic model trained in Section 3.2 to the 8738 noisy utterances using DSN. No senone align- ment of the noisy adaptation data is used for the unsupervised adaptation. The DSN is implemented with CNTK 2.0 T oolkit [32]. The shared component extractor M c is initialized with the first N h hidden layers of the clean DNN and the senone classifier M y is initialized with the last (7 − N h ) hidden layers plus the output layer of the clean DNN. N h indicates the position of shared component in the DNN acoustic model and ranges from 3 to 7 in our experiments. The domain classifier M d of the DSN has e xactly the same architecture as that of the GRL. The priv ate component extractors M s p and M t p for the clean and noisy domains are both feedforward DNNs with 3 hidden layers and each hidden layer has 512 hidden units. The output layers of both M s p and M t p hav e 2048 output units. The reconstructor M r is a feedforward DNN with 3 hidden layers and each hidden layer has 512 hidden units. The out- put layer of the M r has 957 output units with no non-linear activ ation functions to reconstruct the spliced input features. The acti v ation functions for the hidden units of M c is sig- moid. The activ ation functions for hidden units of M s p , M t p , M d and M r are rectified linear units (ReLU). The activ ation functions for the output units of M c and M d are softmax. The activ ation functions for the output units of M s p , M t p are sigmoid. All the sub-networks except for M y and M c are randomly initialized. The learning rate is fixed at 5 × 10 − 5 throughout the experiments. The adapted DSN is tested on real and simulation dev elopment data in CHiME-3 Dataset. System Data BUS CAF PED STR A vg. Clean Real 36.25 31.78 22.76 27.18 29.44 Simu 26.89 37.74 24.38 26.76 28.94 GRL Real 35.93 28.24 19.58 25.16 27.16 Simu 26.14 34.68 22.01 25.83 27.16 DSN Real 32.62 23.48 17.29 23.46 24.15 Simu 23.38 30.39 19.51 22.01 23.82 T able 1 . The WER (%) performance of unadapted acoustic model, GRL and DSN adapted DNN acoustic models for ro- bust ASR on real and simulated dev elopment set of CHiME-3. 3.4. Result Analysis T able 1 sho ws the WER performance of clean, GRL adapted and DSN adapted DNN acoustic models for ASR. The clean DNN achie ves 29.44% and 28.25% WERs on the real and simulated development data respectiv ely . The GRL adapted acoustic model achie ves 27.16% and 27.16% WERs on the real and simulated dev elopment data. The best WER performance for DSN adapted acoustic model are 24.15% and 23.82% on real and simulated development data, which achiev e 11.08% and 12.30% relative improv ement over the GRL baseline system and achiev e 17.97 % and 17.69% rel- ativ e improv ement over the unadapted acoustic model. The N h Rev ersal Gradient Coef ficient α 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 A vg. 3 27.2 26.24 25.76 26.51 26.12 26.92 26.65 26.91 27.41 26.64 4 26.56 26.08 25.75 25.99 25.88 26.76 27.0 27.13 27.74 26.54 5 26.53 25.9 26.07 25.88 25.72 26.17 27.36 26.67 27.37 26.41 6 25.77 25.17 25.06 24.94 24.6 25.19 25.53 25.42 25.93 25.29 7 25.99 25.5 24.73 24.43 25.08 24.53 25.07 24.15 24.29 24.86 T able 2 . The ASR WERs (%) for the DSN adapted acoustic models with respect to N h rev ersal gradient coefficient α on the real dev elopment set of CHiME-3. best WERs are achiev ed when N h = 7 and α = 8 . 0 . By com- paring the GRL and DSN performance at N h = 4 , we observe that the introduction of pri vate components and reconstructor lead to 5.1% relativ e improv ements in WER. W e inv estigate the impact of shared component position N h and the rev ersal gradient coefficient α on the WER per- formance as in T able 2. W e observe that the WER decreases with the gro wth of N h , which is reasonable as the higher hid- den representation of a well-trained DNN acoustic model is inherently more senone-discriminative and domain-in v ariant than the lower layers and can serve as a better initialization for the DSN unsupervised adaptation. 4. CONCLUSIONS In this work, we in vestigate the domain adaptation of the DNN acoustic model by using domain separation networks. Different from the con ventional supervised, semi-supervised and T/S adaptation approaches, DSN is capable of adapting the acoustic model to the adaptation data without any expo- sure to its transcription, decoded lattices or unlabeled parallel data from the source domain. The shared component be- tween source and target domains extracted by DSN through adversarial multi-task training is both domain-inv ariant and senone-discriminativ e. The extraction of priv ate component that is unique to each domain significantly improves the degree of domain-in variance and the ASR performance. When e valuated on the CHiME-3 dataset for en vironment adaption task, the DSN achie ves 11.08% and 17.97% relati ve WER improv ement ov er the GRL baseline system and the un- adapted acoustic model. The WER decreases when higher hidden representations of the DNN acoustic model are used as the initial shared component. The WER first decreases and then increases with the gro wth of the re versal gradient coef fi- cient. In the future, we will adapt long short-term memory- recurrent neural networks acoustic models [33, 34, 35] using DSN and compare the improv ement with the feedforward DNN. Moreover , we will perform DSN-based unsupervised adaptation with thousands of hours of data to v erify its scala- bility to large dataset. 5. REFERENCES [1] Frank Seide, Gang Li, and Dong Y u, “Con versational speech transcription using context-dependent deep neu- ral networks, ” in Pr oc. INTERSPEECH , 2011. [2] T ara N Sainath, Brian Kingsbury , Bhuvana Ramabhad- ran, Petr Fousek, Petr Novak, and Abdel-rahman Mo- hamed, “Making deep belief networks effecti ve for large vocab ulary continuous speech recognition, ” in A uto- matic Speech Recognition and Understanding (ASRU) . IEEE, 2011, pp. 30–35. [3] Navdeep Jaitly , Patrick Nguyen, Andrew Senior , and V incent V anhoucke, “ Application of pretrained deep neural networks to large vocab ulary speech recogni- tion, ” in Pr oc. INTERSPEECH , 2012. [4] Geoffre y Hinton, Li Deng, Dong Y u, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andre w Se- nior , V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al., “Deep neural networks for acoustic mod- eling in speech recognition: The shared views of four research groups, ” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [5] Li Deng, Jin yu Li, Jui-T ing Huang, Kaisheng Y ao, Dong Y u, Frank Seide, Michael Seltzer , Geoff Zweig, Xi- aodong He, Jason W illiams, et al., “Recent advances in deep learning for speech research at microsoft, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 8604–8608. [6] Dong Y u and Jinyu Li, “Recent progresses in deep learn- ing based acoustic models, ” IEEE/CAA J ournal of Au- tomatica Sinica , vol. 4, no. 3, pp. 396–409, 2017. [7] J. Li, L. Deng, Y . Gong, and R. Haeb-Umbach, “ An ov erview of noise-robust automatic speech recognition, ” IEEE/A CM T ransactions on Audio, Speech and Lan- guage Processing , v ol. 22, no. 4, pp. 745–777, April 2014. [8] J. Li, L. Deng, R. Haeb-Umbach, and Y . Gong, Robust Automatic Speech Recognition: A Bridge to Practical Applications , Academic Press, 2015. [9] D. Y u, K. Y ao, H. Su, G. Li, and F . Seide, “Kl- div er gence regularized deep neural network adapta- tion for improv ed large v ocab ulary speech recognition, ” in 2013 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , May 2013, pp. 7893– 7897. [10] Zhen Huang, Sabato Marco Siniscalchi, I-Fan Chen, Jinyu Li, Jiadong W u, and Chin-Hui Lee, “Maximum a posteriori adaptation of network parameters in deep models, ” in Interspeech , 2015. [11] H. Liao, “Speaker adaptation of conte xt dependent deep neural networks, ” in 2013 IEEE International Confer- ence on Acoustics, Speech and Signal Processing , May 2013, pp. 7947–7951. [12] Zhen Huang, Jinyu Li, Sabato Marco Siniscalchi, I-Fan Chen, Ji W u, and Chin-Hui Lee, “Rapid adaptation for deep neural networks through multi-task learning., ” in Interspeech , 2015, pp. 3625–3629. [13] Roberto Gemello, Franco Mana, Stefano Scanzio, Pietro Laface, and Renato De Mori, “Linear hidden trans- formations for adaptation of hybrid ann/hmm models, ” Speech Communication , vol. 49, no. 10, pp. 827 – 835, 2007, Intrinsic Speech V ariations. [14] F . Seide, G. Li, X. Chen, and D. Y u, “Feature engineer- ing in context-dependent deep neural networks for con- versational speech transcription, ” in 2011 IEEE W ork- shop on A utomatic Speech Recognition Understanding , Dec 2011, pp. 24–29. [15] Jian Xue, Jinyu Li, and Y ifan Gong, “Restructuring of deep neural network acoustic models with singular value decomposition., ” in Interspeech , 2013, pp. 2365–2369. [16] J. Xue, J. Li, D. Y u, M. Seltzer , and Y . Gong, “Singular value decomposition based lo w-footprint speaker adap- tation and personalization for deep neural network, ” in 2014 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , May 2014, pp. 6359–6363. [17] Y . Zhao, J. Li, and Y . Gong, “Low-rank plus diagonal adaptation for deep neural netw orks, ” in 2016 IEEE In- ternational Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , March 2016, pp. 5005–5009. [18] P . Swietojanski, J. Li, and S. Renals, “Learning hid- den unit contributions for unsupervised acoustic model adaptation, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 24, no. 8, pp. 1450– 1463, Aug 2016. [19] P . Swietojanski and S. Renals, “Dif ferentiable pooling for unsupervised speaker adaptation, ” in 2015 IEEE In- ternational Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , April 2015, pp. 4305–4309. [20] Z. Q. W ang and D. W ang, “Unsupervised speak er adap- tation of batch normalized acoustic models for robust asr , ” in 2017 IEEE International Confer ence on Acous- tics, Speech and Signal Pr ocessing (ICASSP) , March 2017, pp. 4890–4894. [21] Jinyu Li, Michael L Seltzer , Xi W ang, Rui Zhao, and Y i- fan Gong, “Large-scale domain adaptation via teacher- student learning, ” in INTERSPEECH , 2017. [22] Jinyu Li, Rui Zhao, Jui-T ing Huang, and Y ifan Gong, “Learning small-size DNN with output-distribution- based criteria., ” in INTERSPEECH , 2014, pp. 1910– 1914. [23] Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farle y , Sherjil Ozair, Aaron Courville, and Y oshua Bengio, “Generativ e adversar- ial nets, ” in Advances in Neural Information Pr ocess- ing Systems 27 , Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W einberger , Eds., pp. 2672– 2680. Curran Associates, Inc., 2014. [24] Y aroslav Ganin and V ictor Lempitsky , “Unsupervised domain adaptation by backpropagation, ” in Pr oceed- ings of the 32nd International Confer ence on Machine Learning , Francis Bach and David Blei, Eds., Lille, France, 07–09 Jul 2015, vol. 37 of Pr oceedings of Ma- chine Learning Researc h , pp. 1180–1189, PMLR. [25] Sining Sun, Binbin Zhang, Lei Xie, and Y anning Zhang, “ An unsupervised deep domain adaptation approach for robust speech recognition, ” Neur ocomputing , vol. 257, pp. 79 – 87, 2017, Machine Learning and Signal Pro- cessing for Big Multimedia Analysis. [26] Y usuke Shinohara, “ Adversarial multi-task learning of deep neural networks for robust speech recognition., ” in INTERSPEECH , 2016, pp. 2369–2372. [27] Dmitriy Serdyuk, Kartik Audhkhasi, Phil ´ emon Brakel, Bhuvana Ramabhadran, Samuel Thomas, and Y oshua Bengio, “In variant representations for noisy speech recognition, ” in NIPS 2016 End-to-end Learning for Speech and Audio Pr ocessing W orkshop , 2016. [28] K onstantinos Bousmalis, George T rigeorgis, Nathan Silberman, Dilip Krishnan, and Dumitru Erhan, “Do- main separation networks, ” in Advances in Neural Infor- mation Processing Systems 29 , D. D. Lee, M. Sugiyama, U. V . Luxb urg, I. Guyon, and R. Garnett, Eds., pp. 343– 351. Curran Associates, Inc., 2016. [29] J. Barker , R. Marxer , E. V incent, and S. W atanabe, “The third chime speech separation and recognition chal- lenge: Dataset, task and baselines, ” in 2015 IEEE W orkshop on Automatic Speech Recognition and Under- standing (ASR U) , Dec 2015, pp. 504–511. [30] T . Hori, Z. Chen, H. Erdogan, J. R. Hershey , J. Le Roux, V . Mitra, and S. W atanabe, “The merl/sri system for the 3rd chime challenge using beamforming, robust feature extraction, and advanced speech recognition, ” in 2015 IEEE W orkshop on Automatic Speech Recognition and Understanding (ASR U) , Dec 2015, pp. 475–481. [31] Jinyu Li, Dong Y u, Jui-Ting Huang, and Y ifan Gong, “Improving wideband speech recognition using mix ed- bandwidth training data in cd-dnn-hmm, ” in Spo- ken Languag e T echnology W orkshop (SLT), 2012 IEEE . IEEE, 2012, pp. 131–136. [32] Dong Y u, Adam Eversole, Mike Seltzer , Kaisheng Y ao, Zhiheng Huang, Brian Guenter , Oleksii Kuchaiev , Y u Zhang, Frank Seide, Huaming W ang, et al., “ An introduction to computational networks and the compu- tational network toolkit, ” Micr osoft T echnical Report MSR-TR-2014–112 , 2014. [33] H. Sak, A. Senior, and F . Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in Interspeech , 2014. [34] Z. Meng, S. W atanabe, J. R. Hershey , and H. Erdogan, “Deep long short-term memory adaptive beamforming networks for multichannel robust speech recognition, ” in ICASSP , 2017. [35] H. Erdogan, T . Hayashi, J. R. Hershey , et al., “Multi- channel speech recognition: Lstms all the way through, ” in CHiME-4 workshop , 2016, pp. 1–4.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment