Improved visible to IR image transformation using synthetic data augmentation with cycle-consistent adversarial networks
Infrared (IR) images are essential to improve the visibility of dark or camouflaged objects. Object recognition and segmentation based on a neural network using IR images provide more accuracy and insight than color visible images. But the bottleneck…
Authors: Kyongsik Yun, Kevin Yu, Joseph Osborne
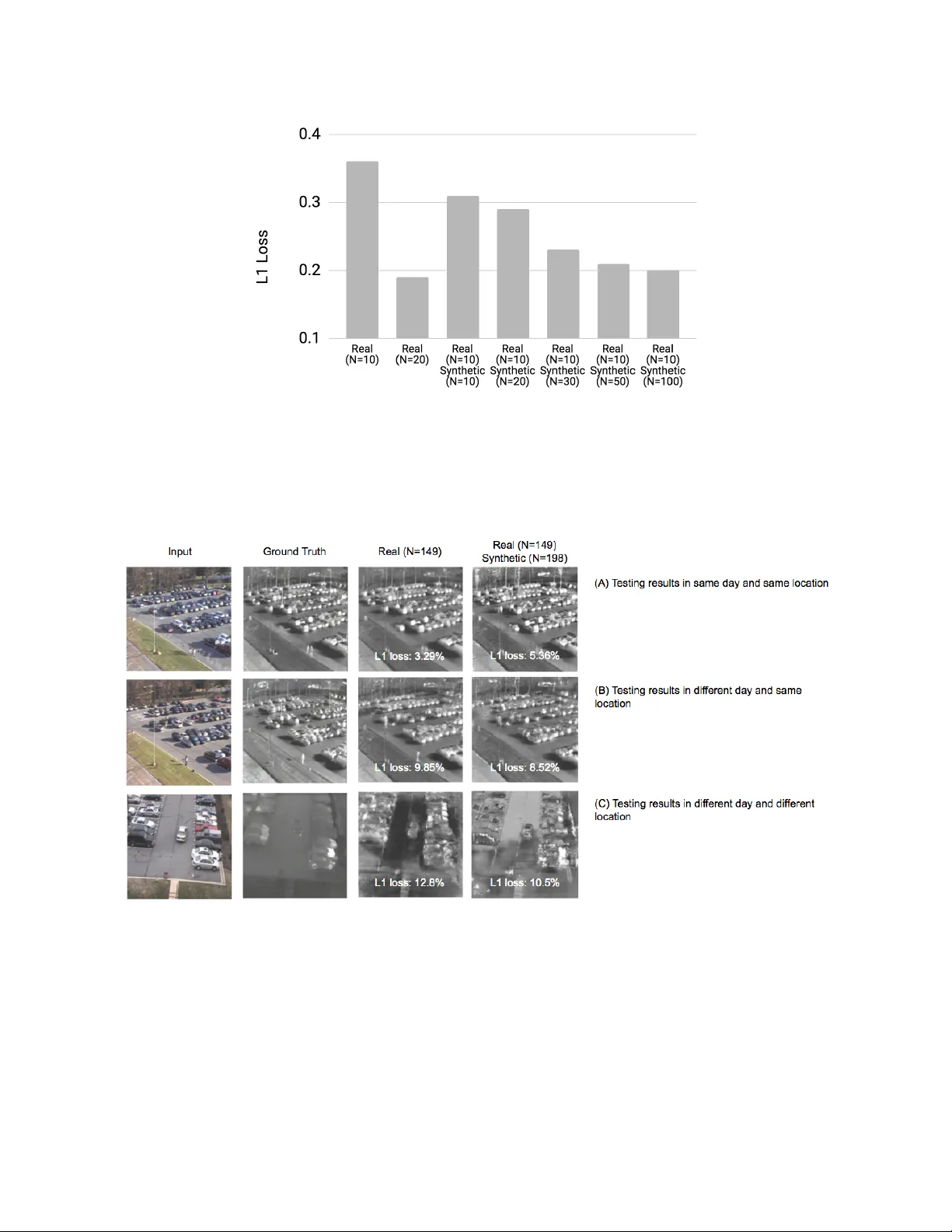
*kyun@j pl.nasa .gov; phone 1 818 354- 1468; fax 1 818 393-67 52 ; jpl.nas a.gov Improved vi sible to IR image transf ormation usin g synthetic dat a aug men t ati on wi th cy cle - cons istent ad ve rs ar ial n etw ork s Kyongsik Yun* , Kevin Yu, Joseph Osborne, Sarah E ldin , Luan Nguyen, Alexander Huyen, T ho mas Lu Jet Propulsion Laboratory, Californi a Institute of Tec hnology 4800 Oak Grove D rive, Pasadena, CA 91109 ABS TRACT Infrared (IR) images ar e ess ential to im prove the v isibility of da rk or c amouflag ed obj ects. O bje ct r ecognition and segmentat ion based on a neural n etwork using I R imag es pr ovide mor e accuracy and insight t h an color visible i m ages . But the bottleneck is the amoun t of relevan t IR imag es for train ing. It is difficult t o collect real -world IR images for sp ecial purpos es, including spac e e xplora tion, m ilitary and fire-figh ting a pp lications . T o solve this problem, we created color visible and I R images using a Unity-based 3D ga me e ditor. Th ese syn thetica ll y gen erated color visible and IR images wer e used to t rain cycle co nsistent advers arial n etworks (Cycl eGAN) t o convert vis ible imag es to IR imag es. CycleGAN has the advantage that it does not require precise ly match ing vis ible a nd IR pairs for transform ation t rainin g. In this study, we dis covered t h at additiona l synt hetic da ta can he lp improve CycleGAN perform ance. N eural n etwork training usin g real data (N = 20) perform ed more accur ate trans formations than training using real (N = 10) and synthet ic (N = 10) data combin ations. The result indica tes th at the synthe tic da t a canno t e x ceed the qu ality of the real d ata. N eural network training using real (N = 10) and synt hetic (N = 100) data combin ations showed almost the same perform ance as training using real data (N = 20). At least 10 times m ore s ynthetic data than real data is r equired to ac h ieve the same performanc e. I n summ ary, CycleGAN i s used w it h syn thetic data to improve the IR image conversi on performan ce of visible imag es. Keywords: image transform ation, data augmen tation, deep learning , machine learning, com puter vi si on 1. INTRO DUC TIO N Infrared (IR) im ages are essen tial for improvin g the visib il ity of objects. For exam ple, using a n i nfr ared camer a in the dark can improv e the sight of a firefigh ter and reduc e t h e r is k of slipp ing, t ravel , and falling 1, 2 . In our previous study, as part of the As sistant for Und erstand ing Data through R ea son ing, Extr action, and sYnthesis (AU DREY) pro ject supported by the Depar tment of Homela nd Security (DHS ) 3,4 , w e provided a n enh anced v ision using de ep learning- based image t r ansforma ti o n from v isible to IR images 5–7 . W e found that o bject recognit ion a nd segment ation based on the neura l n etwork us ing IR imag es were more accurat e and insightfu l than color v isible imag es. However, t he bottlene ck is t he amount of r elevant I R image s needed for training. Collecting real IR i mag es for special purposes , including space exploration , m ili ta ry , and fire-fighting appl ications, is a chall enge 5,6 . Simple data augmentation techniqu es (fli pping, tr anslating, and rotating) helped improve the classific at ion accur acy of the convolution al n eural n etwork w hen there w as a l ack of rele vant da ta in t h e r emote s ensing s ce n e classi fication 8 . O ther previous studies show ed that data au gmentation hel p ed generate the most accura te results i n classifying urban ar eas using polarimetric synth etic aperture radar data 9 . Dat a aug mentation also addresses t h e overfi tting p roblem in machine learning 10 . Previous studies showe d that sim ple d ata augmentatio n c an be b eneficial by modify ing t h e re al data (su ch a s flipping, t r anslating, and rot ating the image) whi le maintain ing object categories for obj ect r ecognitio n 11 . However , the real data itself is fundam entally limited . If th e re al dat a does not va r y sufficiently, it m ea ns t h at data augmentation ma y not be helpfu l. Th en we n ee d to consider sophist icated data augmen ta tion such a s synthe tic data gener ation. The r ecent maturation of 3D game engines and comput er physi cs e n gines enab les realistic synth etic im ages to b e g enerated . H ere we simul ated t he background and target using a 3D gam e engine . In this pap er, we c omp ared the pe rf ormance of simp le data augmen tation and sy nthetic data generat ion in the prob lem of visible to I R image t ransform ation. 2. SYNT HETI C DATA GENE RATION We cr ea ted color visible and IR images us ing t he 3D gam e editor ARMA3 (Boh emia Interactiv e, Am sterdam, The Netherlands). ARMA3 i s an open, realism-based , military tactical video game t hat d elivers rea listic synth etic image generation . A RMA3 is based on Real Vi rtuality 4 3D e ng ine. ARMA3 uses NVIDIA PhysX , a n ope n source real- tim e physics engine m iddlewar e SDK , t o enabl e real-w orld simulations of vehicles, land, sea and air. We deve loped a scr ipt to wo rk with ARMA3 , whi ch spawns random peopl e and vehicles at r an dom l oc ations in a specif ied l ocat ion and imports images from multip le an gles in a given 3D environ ment. We can a lso sp ecify the motion and behavior of the object. For e xample, a p erson can w alk down a st reet or di r ect a truck to run on a spe cified rout e. Through this process , we c r eated hundreds of high-qual it y imag es in a matter of hours. In real ity, it c an take days or w eeks to ta k e i m age s in the real world. The relative cost of this synthetic data gener ation pr ocess is n egligible c ompar ed to the po tential cost of collecting s imilar dat a in real life . We further processed the syn thetic imag e using a sele ctive Gauss ian blur filter with a blur radius of 5 pixels and a max imum delta o f 50. The maximum d elta is the maximum differen ce b etween t h e pi x el valu e a nd the surround ing pixel value (v al ue be twee n 0 -255). Those pixe ls with va lues highe r than this m ax de lt a va l ue are not blurred (Figur e 1 ). For pairs of real-vis ible ima ges and IR imag es, we used an open-sour ce visi ble an d infrar ed ca mouf lage video database provided by the Sign al Multim edia and Telecom municatio ns Labora tory a t the Federal University of Rio d e Jan ei r o 12 ( htt p://www02.sm t.ufrj.b r/~fusion/ ). Figure 1 . Representati ve camo uflage datase t images of (A ) real vis ible-ligh t, (B) rea l I R , (C) syn thetic v isible-ligh t, (D) synthe tic IR imag es. We also used another da ta s et th at include parking lot surv eillan ce images that contain t h e visib le - light /I R p air s provid ed by the Arm y Research Laboratory . T h e synth etic dataset mimics the si tuation at various spatial perspe ctives, different times of the day, and background (F igure 2). In these various situations, cre ating an actual imag e can be cos tl y and time- consuming . With a 3D game engin e, however , it takes no more than 20 seconds to cre at e a high-qual it y synthe tic image. Wi th s ynth etic data, w e can pinpoi nt the e xact location of each object (su ch as a person, car, etc.) b ased on 3D model information, and place them in any position. We can also shuffle t h e background and th e target t o c reate an infinite combination of synthetic data. For target recogni tion and s egmentation purposes, objects are al r eady fu lly annotated in the 3D mod el and do not requ ire manual lab el i ng. In particul ar, ma nual labeling for segm entation requ ires a great dea l of time and resourc es when us ing real imag es. Manual la b eling by humans m ay i nterfere w ith suc cessful training of neural ne tw orks by creating inconsist ent ground truth data sets between the labe ls. T h e sy nthetic data solv es all of these problems. Figure 2 . Repr esent ati ve parkin g- lo t s ynthe tic da ta se t i mage s of ( A) direct ov erhead view , ( B) a ngled overhead view , (C) close distance view, (D ) long distance view, (E ) rural backgro und v iew, (F) night t ime view . 3. ADVERSARI A L NETWORKS We used gene rative adv ersarial netwo rks to train a ssoc iations betwe en various camouflage and parking- lot images of visible-ligh t and IR counterpar ts. Gen erative advers arial ne tworks learn the l oss of cla ss ifying wh ether t h e output i mag e is rea l, wh il e at t he same time the networks learn the g enerative model to mi nimize this loss 13 . To train the generative adversarial networ ks, t h e ob jective i s to solve the min-m ax game, f inding the m inimum over θ g , or the parameters of our generator n et wo rk G a nd maximum over θ d , or th e p arameter s of our discr iminator network D. (1) The first t erm i n the obje ctive function (1) is the likelihoo d, or expecta tion, of the real data being r eal from t he d ata distribution P data . The log D(y ) is the discrim inator output f or real d at a y. If y is rea l, D(y) is 1 and log D(y) is 0, wh ich becomes the maximum . T h e se cond term is th e expe ctation of z dr awn from P(z) , meaning the random data inpu t for our generator ne tw ork (Figure 1). D(G(z) ) is the output of our discriminator for generated fake dat a G(z) . If G(z) is c lose t o real, D(G(z)) is close to 1, a n d the log ( 1- D(G( z))) becomes v ery sm all (minim ized). (2 ) (3) We used t h e r andom i nput variable z as inp ut t o the generat or network . An i m age can be used as input to t h e g enerator network instead of z . In the o bjectiv e funct ion (2), x , th e real input imag e w as a conditio nal term for our generator. We then added a conditional t erm x t o our discr iminator netwo rk, as in func ti o n (3). The conditional advers arial network s lear n ed the loss func tion 14, 15 and the m apping from the input i mag e to th e o utput imag e. While the origin al generative adv ersarial networks ge ne r at e the re a l -looking imag e from the random noise input z, t h e condition al generat ive adversar ia l ne t wor k s ( CGAN) c an find th e a ssoc iation of the two images (i.e., visible- light and IR). CGAN then converts or r econstructs the real input im age into anoth er imag e. CGAN’s o ne c h allenge is t r aining data in th at they requir e spatially and tempora ll y mat ching image pairs for training . T h e t wo imag e spa ces ha ve to be closely interrelated . This can b e time consuming or even impossible to translat e, depend ing on the two imag e types . I n our ca se , the visible light a n d t he infrared cameras were n ot exactly syn chroniz ed in time and spa ce. This is where c ycl e consistent a dversarial networks (CycleGAN) is favorabl e. With CycleGAN, we can use the deep neural network m odel to transform b et w een two discrete , unpaired images. T hey need not be preci s ely synchroni zed spatial ly nor temporal ly. In order to determ ine how we l l th e entire translation syst em performs , CycleGA N introdu ce d tw o generators (a g enerator t h at c o nverts visible- light to IR imag es, and anoth er gen erator to conver t back from IR to visible-light imag es ). Thi s appro ach allows Cy cleGAN to be simultaneous ly trained in a bidirect ional transform ation to balance t h e variabi lity and consisten cy betw een training images, resul ting in a b etter transl ation betwe en unpair ed images 16 . Our goal is t o translate the captured i m age in the visible spe ctrum to the same image captured by t he IR wavelength , while at the same time m ai n taining t h e structur al similarity of t he input and output ima ges. We used the U- Net ar chitecture 17 for a progress ively dow nsam pled and upsampl ed en coder-decod er network-b ased ge nerator for efficiency. We th en app lied ski p layers on the network . Th at i s, each dow nsampling layer is sen t to an d coupl ed to a correspondi ng upsamp ling layer . Finally , t h e upsam pling layer can directly learn impor tant structu ral features in the downsampli ng layer . For CycleGA N, we used ResNet-based generators to generat e high-quali ty images 16 . In terms of training, all weights were random ly initiali zed using a Gaussian distribu tion with mean 0 and standard devia tion 0.02. The we ight of the discrimi nator was updated via stoch astic gradient d escent. Then, the we ights of the g enerators we re updat ed accord ing to the differ ence between the gener ated im age and t h e input ground truth . The discrimina tor and generator r an alternately until conv ergence or a pre-spe cified number of epochs passed (epoch = 10,000). 4. TRAIN ING AND TESTING Figure 3 . Trans for m ing real visible-li ght images t o I R i ma ges. (A ) Re al vi sibl e -ligh t imag e , ( B ) transforme d IR images trained by 10 r eal images , (C) transfo rmed IR im age train ed by 10 real and 100 syntheti c i mag es. By adding 100 synthet ic images for neur al network training , the t ransforma tion perfo rmance i mp roved compa red to only 10 r eal i m age s used for training . Synthe tic data helps improve neural network performa nce. We found t hat a dd itional synthe tic data helps improve image transf ormation pe rf ormance (Figure 3). Neura l n etwork training usin g real data (N = 20) perform ed more accur ate trans formations than training using real (N = 10) and synthet ic (N = 10) dat a combinations. Neural network training using real (N = 10) and synth etic (N = 100) data combin ations showed almost the s ame performan ce as training us ing re al dat a (N = 20). We use d gen erator L1 loss, wh ich is the difference between ge n erator ou tput and ground truth, as a perform ance me asure (Figure 4). Figure 4 . N eural ne twork p erform ance o f vari ous data se ts. Add itiona l syn thetic d ata he lped to i mpr ove cycle c on sisten t advers arial network ( Cyc leGAN ) performan ce. D eep neural netw ork training usi ng real data (N = 20 ) was twic e as accu rate as t rain ing us ing real (N = 10) and synthet ic (N = 10) dat a combin ations. T he re s ult i nd icates that the synthet ic data cannot exceed the quali ty of the rea l data. The neur al networ k training us ing real (N = 10) and synthet ic (N = 100 ) data show ed almost t h e same performan ce as training using real (N = 20) data. This m eans t hat mo re than 10 times as mu ch syn thetic data as the re al data is required to achi eve the same per forman ce. Figure 5. T ransfo rmation results of vis ible-ligh t and IR im ages. (A ) Te sting res ults in sam e day and same loca tion, (B) testing re sults in d ifferent day and sam e loca ti o n, (C) T esting res ults in d ifferent day and d ifferent lo cation u sing real da tas et (N=149 ) and, us ing comb inat ion of re al (N=1 49) and synthet ic (N= 198) data set. A t otal of 149 real vi si bl e - lig h t and IR imag e pairs i n the p arki n g data set were used for training. With limited training data, image transform ation was performed rel atively well (L 1 l oss: 3 .29%) in a test environm ent that was consistent wi th the training enviro nment ( sa m e ti m e of a day a nd sam e camera perspe ctive). How ever, the system fail ed t o generaliz e and yield ed poor r esults in other environm ent s (L1 loss: 12. 8%) (Figur e 5). C ombining the real data w ith the synthetic dataset (N = 198) impro ved the test results for the di ff erent da y (F igure 5B), and for t he differ ent day and locat ions (Figure 5C), compar ed t o the re al ima ge data set. Inc luding synthe tic da ta in the same location on the same day da t a set increased L 1 loss (Figur e 5A) . This is because the origina l real d ata is overfitt ed for a p articular situa tion ( the s ame location with the same d ay). B ecause sy nthetic data sets include more diverse e nvironm ents in te rms of tim e and space in images, t rainin g wi th synth etic data achiev ed h igher per formance in a mor e g enerali ze d environment t h an training with only r eal data. Figure 6. Tr ansform ation perfo rmance o f vi sible- li g ht a nd IR images in various cond itions. In diffe rent day and diffe rent location condi tions, the L 1 l oss decre ased a s we added more synthet ic ima ges. In the same day condition, the L1 l o ss increased as we added m ore syn thetic images that were irreleva nt to the purpos e of training . 5. DISCUSSION We showed that visib le-light imag es could b e transform ed to IR imag es using Cyc leGAN , and conversi on results w ith limited da ta sets could be enhanc ed by adding synthetic data generat ion based on the 3D ga m e engine . We also found that the amoun t of syn thetic data depends on the quality o f the d ata, but we n eed at least 10 times mor e synthe tic data than real d ata to achi eve the sam e performanc e. Also, i f t h e s ynthetic data is not relevant to the purpose of the traini ng, the test resul ts may b e degraded. This study used very sma ll data se ts, and the g enerated syn thetic da ta was not very large. La r ger synthe tic da t a generation is requir ed f or the future re s e arc h . In a p revious 3D pose estima tion study, the authors syn thesized 2 million images for training t o improv e perform ance 18 . Ano the r previous study used data augment ation with manual fea tures (input fr om ex perts) to obtain a hi gher accuracy than t h e clin ical diagnostics in dete cting mammograph ic lesions using a total of 45 ,000 i mag es 19 . In the medical field, espec ially large data sets have been used, ach ie v ing unpre cedented accuracy , wh ich is much higher than the clini cal diagnost ics 20, 21 . We only ge ne r at e d s yntheti c data using a 3D gam e e n gine, and did not perform simp le data augment ation techniques, suc h as flipping, ro tating, and zooming in/out. The com bination of synthetic da ta generation and data augmentation may prov ide more v ariability in the dat a set, en abling high er accuracy . Another idea is to change th e image style and create a synth etic imag e us ing g enera tive a dv ersarial networks . A previous stud y showed the improvemen t of classifica tion accuracy by using style transf er with traditional data augmenta tion 22 . Due to l ack of d ata, generalizat ion was not often done. D ata augmentation is k nown to lead to network regular ization a nd improv ed test accuracy 23 . In our study, we trained the network from the beginning . The t r ansformation of visible and IR imag es is a new area that ma y not be a ble to ben efit from transfe r learnin g (reus ing pre -trained m odels for new prob le ms ). Howe ver, many previ ous studi es found that deep neural networks c o uld learn transf erable f eatures whi ch generali ze well to nov el tasks 24 . For exampl e, the firs t three con volutiona l layers of a pre-train ed network can be de li v ered as a who le to ne w problems . The next thre e layers can b e transferr ed and fine- tuned for adaptation . We will be nefit from the next v ersion of IR image transforma tion from visible ligh t through tra nsf er learn ing, large scale synthe tic data gen eration as we ll as data augmen tation. ACKNOWLEDGMENT The research was carried out at the Jet Propulsion Laborator y, California Ins ti t ute o f Technology , under a contract with the Nation al Aeron autics a n d Sp ace Admin istration. T h e r esearch was funded by th e U.S. Department of Home land Security Science and Technology Directorate Next G eneration First Responders Apex Program (DHS S&T NGFR) under NAS A prime con tract NAS 7-03001, T ask Plan Num ber 82-106095 . REFE RENCES [1] Smith, D. L., [Firefight er fatalities and injuries : the ro le of heat stress and PPE] , F irefighter Life Safe ty R esearch Center, Ill inois Fire Se rvice Institu te, Univ ersity of Illinois (2008). [2] Karter, M. J. and Molis , J. L., [US Firefight er Injuries-2012 . Nationa l Fire Prot ection Assoc iation, Fire Analysis and Resear ch Division, Quincy, MA] (2012) . [3] Sanquist, T. F . and Br isbois, B. R. , “Attention and Situat ional Awar eness in Firs t Respond er Operat ions” (2016). [4] Baggett, R. K. and Fos ter, C. S., “ The Future of Homel and Security Tec hnology ,” Homeland Security Technologi es for the 21st Century 257 (2017) . [5] Yun, K. , Bus tos, J. and Lu, T., “Pre dicting Rap id Fire Growt h (Flashove r) Using Condi tiona l G enerative Adversaria l N etworks ,” Electroni c Im aging 20 18 (9), 1–4 (2018). [6] Yun, K. , Lu, T. and C how, E., “Oc cluded obj ect reconstru ction for first respon ders with augmented reality glasses using cond itional gen erative adversar ial ne tworks,” Pat tern Recogni tion and Tr acking XX IX 10649 , 10 6490T, Internation al Society f or Optics and Photoni cs (2018). [7] Yun, K. , Huy en, A. and Lu, T., “D eep Neura l N etworks for Pattern Recognition ,” arXiv prepr int arXiv:1809 .09645 (2018) . [8] Yu, X., Wu, X., Luo, C. and Ren, P., “Deep learning in re mo te sensin g scene cl assification : a data augm entation enhanced convolution al neural netwo rk framewor k,” GIS cience & Remote Sens ing 54 (5) , 741–758 ( 2017). [9] De, S., Bruz zone, L., Bh attacharya , A ., Bovolo , F. and Ch audhuri, S ., “ A novel t ec h nique base d on dee p learning and a synth etic target da tabase for classific ation of urban areas in PolSAR dat a,” I EEE Journ al of Selec ted Topics in Applied Earth Obser vations an d Remot e Se nsing 11 (1 ), 154–170 (2018). [10] Zhang, C ., Bengio, S., Hardt, M. , Recht, B. and Vinya ls, O., “Unders tanding deep learning requires reth inking generalizat ion,” arXiv preprint arXiv:1611.03 530 (2016) . [11] Eitel, A. , Spr ingenberg, J. T., Sp inello, L ., Riedmiller, M. an d Burgard, W ., “ Mu ltimoda l deep le arning for robus t RGB -D ob ject recognit ion,” 2015 IEEE/RS J Internationa l Confer ence on Int elligent Robo ts and Systems (IROS ), 681–687, IE EE (2015). [12] Ellmauth aler, A., Pag liari, C. L ., da Silva, E. A . B., Gois, J. N. and Neves, S. R., “A visible -light and infrared video dat aba s e for perform ance ev aluation of v ideo/im age fusion me thods,” Mul tidim Syst Sign Process 30 (1), 119–143 (201 9). [13] Goodfellow , I., Poug et -A badie , J., Mirza, M., Xu , B., W arde-Farley, D. , Ozair, S ., Courville, A. and Beng io, Y., “Generativ e adversar ial nets,” Adv ances in n eural inform ation pro ce ss ing syst ems, 2672–2 680 (2014) . [14] Isola, P ., Z h u, J.-Y., Zhou, T. and Efros, A. A ., “Imag e- to -image t r anslation with conditio nal adv ersarial networks,” arXiv preprin t (2017) . [15] Mirza, M. and Osinder o, S., “Con ditional generative ad versa ria l nets,” arX iv preprint arXiv:1411 .1784 (2014) . [16] Zhu, J.-Y. , P ark, T., Iso la, P. and Efros, A. A. , “Unpaired image- to -im age translat ion using cycl e-consistent adversarial networks ,” Proceedings of the IE EE Internat ional Conf erence on Compu ter Vis ion, 2223–223 2 (2017) . [17] Ronneberg er, O., Fisch er, P. and Brox, T ., “ U- net: Convo lutional networks for biomedi cal image segm entation, ” Internation al Confer ence on Medi cal imag e computing and computer- assisted int ervention , 23 4–241, Spring er (2015). [18] Rogez, G. and Schm id, C., “MoCa p-guided Data Augmen tation for 3D Pose Est imation i n t h e Wild,” [Advances in Neural Inform ation Pro cessing Sys tems 29] , D . D. L ee, M . Sugiyam a, U. V. Luxburg , I. Guyon , and R . G arnett, Eds., Curra n Associa te s , Inc., 3108 –3116 (201 6). [19] Kooi, T. , Litjens, G. , V an Ginn eken, B., Gube rn-Mérid a, A., Sánchez , C. I., Mann , R., den He eten, A. and Karsse meije r , N., “Large scal e deep le arning for com puter ai ded dete ction of mamm ographi c lesions,” M edical image anal ysis 35 , 303–312 (2017). [20] Oh, J., Yun , K., Hwan g, J.-H. and Chae, J.-H. , “classifi cation of suic ide attempts through a Machine le arning algorithm Ba s ed on Mu ltiple sys te m ic Psychi atric scales ,” Frontiers in psych iatry 8 , 192 (201 7). [21] Litjens, G ., Kooi, T., Bejnordi, B. E., Setio, A. A. A ., Ciompi, F., Gh afoorian, M., V an Der Laak, J. A. , V an Ginneken , B . and Sánch ez, C. I., “ A survey on d eep le arni n g in m edical imag e analysis ,” Medical ima ge analys is 42 , 60–88 (20 17). [22] Perez, L . and Wang, J., “The Eff ectiveness of D ata Augm entation in Im age Classif ication us ing Deep L earning,” arXiv:1712 .04621 [cs] (2017). [23] Keskar , N . S ., Mudiger e, D., Noc edal, J., Sm elyanskiy, M. and Tang , P . T. P., “On Large-B atch Train ing for Deep Learning: Generaliza ti on Gap and Sharp Minim a,” arXiv: 1609.048 36 [cs, mat h] (2016) . [24] Long, M ., Cao, Y ., Wang, J. and Jordan, M. I., “Learn ing trans ferable features with dee p adaptatio n networks ,” arXiv pr epri n t arXiv:15 02.02791 (2015).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment