End-to-End Environmental Sound Classification using a 1D Convolutional Neural Network
In this paper, we present an end-to-end approach for environmental sound classification based on a 1D Convolution Neural Network (CNN) that learns a representation directly from the audio signal. Several convolutional layers are used to capture the signal’s fine time structure and learn diverse filters that are relevant to the classification task. The proposed approach can deal with audio signals of any length as it splits the signal into overlapped frames using a sliding window. Different architectures considering several input sizes are evaluated, including the initialization of the first convolutional layer with a Gammatone filterbank that models the human auditory filter response in the cochlea. The performance of the proposed end-to-end approach in classifying environmental sounds was assessed on the UrbanSound8k dataset and the experimental results have shown that it achieves 89% of mean accuracy. Therefore, the propose approach outperforms most of the state-of-the-art approaches that use handcrafted features or 2D representations as input. Furthermore, the proposed approach has a small number of parameters compared to other architectures found in the literature, which reduces the amount of data required for training.
💡 Research Summary
This paper presents a novel end-to-end approach for environmental sound classification (ESC) utilizing a one-dimensional Convolutional Neural Network (1D CNN) that learns feature representations directly from raw audio waveforms, bypassing the need for handcrafted features or intermediate time-frequency representations like spectrograms.
The core innovation lies in the model’s ability to process the raw 1D audio signal. The proposed architecture consists of four convolutional layers (interleaved with two max-pooling layers for down-sampling) followed by three fully-connected layers. This design is intentionally compact, containing significantly fewer parameters than typical 2D CNNs used for image-based audio analysis (e.g., VGG, AlexNet), which reduces computational cost and mitigates overfitting risks in data-scarce domains like ESC.
A major practical challenge addressed is handling variable-length audio inputs, as environmental recordings are not of uniform duration. The authors employ a sliding window technique that segments a longer audio clip into multiple, overlapping fixed-length frames. Each frame is fed independently into the network, and the final prediction for the entire clip is obtained by averaging the predictions across all its frames. This method also provides a form of data augmentation.
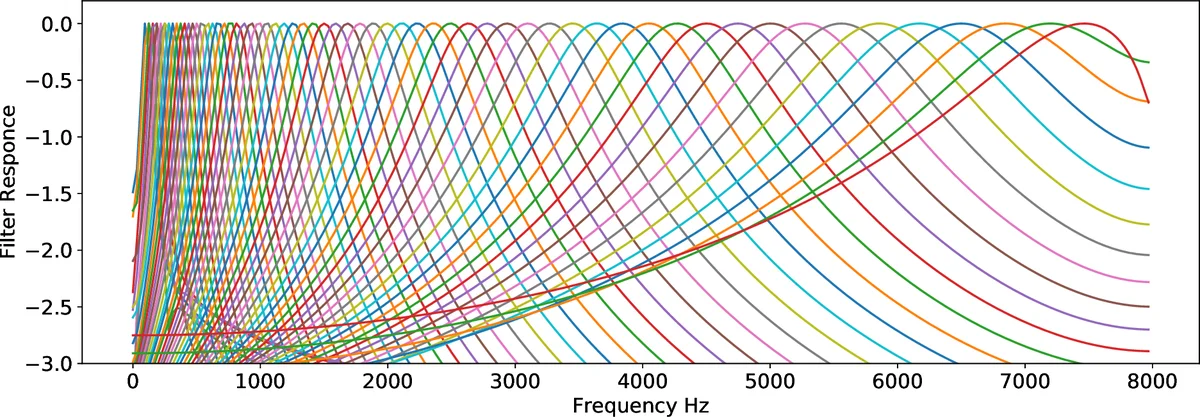
The research comprehensively evaluates the model on the UrbanSound8k dataset, a standard benchmark containing 8,732 sounds across 10 urban environment classes. Using a 10-fold cross-validation protocol, the proposed 1D CNN achieves a state-of-the-art mean accuracy of 89%. This performance surpasses contemporary leading methods that rely on 2D representations, such as SB-CNN (~79%) and a VGG-based approach (~72%). The paper also explores initializing the filters of the first convolutional layer with a Gammatone filterbank, which mimics the human cochlea’s frequency response. While this biologically-inspired initialization yields a slight performance improvement over random initialization, the analysis shows that the network can learn similarly effective band-pass filters directly from data.
Further analysis of the learned first-layer filters reveals they spontaneously develop characteristics akin to a diverse set of band-pass filters, covering various frequency ranges relevant for sound discrimination. This finding underscores the model’s capacity to discover meaningful audio features autonomously.
In conclusion, the paper demonstrates that a relatively simple and parameter-efficient 1D CNN operating on raw waveforms can outperform more complex, feature-dependent 2D models for environmental sound classification. The proposed end-to-end framework simplifies the processing pipeline, reduces data requirements, and offers a practical solution for handling real-world audio of variable length, making it a promising approach for resource-constrained and real-time applications such as smart city monitoring and IoT devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment