Improved Speaker-Dependent Separation for CHiME-5 Challenge
This paper summarizes several follow-up contributions for improving our submitted NWPU speaker-dependent system for CHiME-5 challenge, which aims to solve the problem of multi-channel, highly-overlapped conversational speech recognition in a dinner party scenario with reverberations and non-stationary noises. We adopt a speaker-aware training method by using i-vector as the target speaker information for multi-talker speech separation. With only one unified separation model for all speakers, we achieve a 10% absolute improvement in terms of word error rate (WER) over the previous baseline of 80.28% on the development set by leveraging our newly proposed data processing techniques and beamforming approach. With our improved back-end acoustic model, we further reduce WER to 60.15% which surpasses the result of our submitted CHiME-5 challenge system without applying any fusion techniques.
💡 Research Summary
The paper addresses the challenging CHiME‑5 scenario, where multi‑channel recordings of spontaneous dinner‑party conversations contain heavy speaker overlap, reverberation, and non‑stationary background noise. The authors propose a comprehensive front‑end and back‑end pipeline that dramatically reduces word error rate (WER) from the baseline 80.28 % to 60.15 % on the development set, a 20 % absolute improvement.
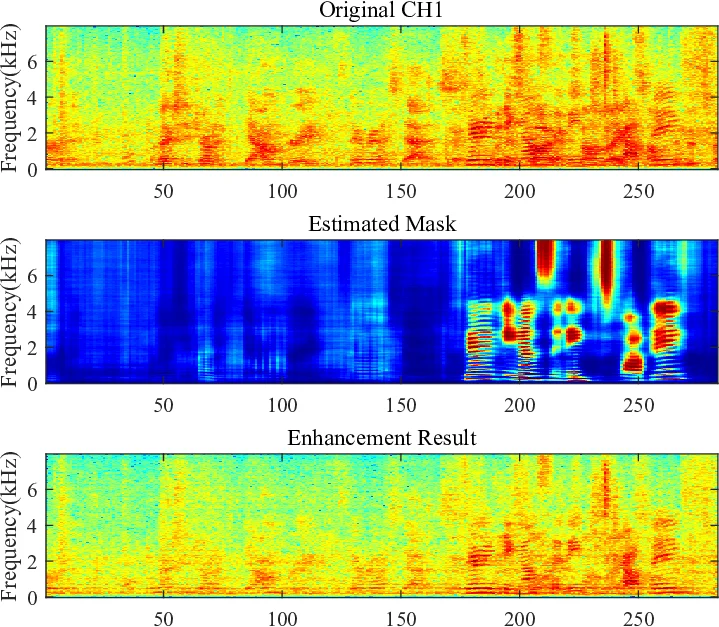
Data processing begins by extracting non‑overlapped speech segments for each speaker. These segments are first dereverberated using GWPE (Gaussian Weighted Prediction Error). An unsupervised two‑component complex Gaussian mixture model (CGMM) then estimates speech and noise masks, which feed an MVDR beamformer to suppress background interference. To further clean the signal, the single‑channel OMLSA (Optimally Modified Log Spectral Amplitude) denoiser is applied, yielding high‑quality “clean” references for mask training.
The core novelty is speaker‑aware training. For each utterance, an i‑vector is computed from the speaker’s non‑overlapped data and concatenated to the second TDNN layer and the subsequent BLSTM layer of a mask‑estimation network. The network predicts either an Ideal Ratio Mask (IRM) or a truncated Phase‑Sensitive Mask (PSM). Training data are simulated mixtures of the target speaker with one or two interfering speakers and background noise across a wide range of SNR/SDR conditions.
Two beamforming strategies are evaluated: the conventional MVDR and the Generalized Eigenvalue (GEV) beamformer. Because GEV directly maximizes expected SNR, it is more sensitive to mask accuracy. Experiments show that with the i‑vector‑conditioned model (named GWPE‑SA++), GEV reduces WER to 61.31 % compared with 63.12 % for MVDR, especially benefiting speakers recorded in the kitchen area.
On the back‑end, the authors replace the original 9‑layer TDNN acoustic model with a factored TDNN‑F and a CNN‑TDNN‑F architecture, trained with lattice‑free MMI (LF‑MMI) using Kaldi. Additional training data include reverberated utterances (generated with small‑room impulse responses) and the enhanced signals from the GWPE‑CGMM‑MVDR‑OMLSA pipeline. This acoustic model alone yields a 12 % absolute WER reduction (from 80.28 % to 68.43 %).
Combining the improved front‑end (i‑vector‑aware mask estimation + GEV beamforming) with the enhanced acoustic model results in a final WER of 60.15 % on the CHiME‑5 development set, surpassing the authors’ original submission and most other single‑system entries. The approach requires only one unified mask‑estimation network for all speakers, avoiding the computational overhead of training separate speaker‑dependent models or a two‑stage separation pipeline. It also complies with CHiME‑5’s restriction against external data, demonstrating a practical, scalable solution for real‑world multi‑speaker, reverberant ASR.
Comments & Academic Discussion
Loading comments...
Leave a Comment