Audio-Based Activities of Daily Living (ADL) Recognition with Large-Scale Acoustic Embeddings from Online Videos
Over the years, activity sensing and recognition has been shown to play a key enabling role in a wide range of applications, from sustainability and human-computer interaction to health care. While many recognition tasks have traditionally employed i…
Authors: Dawei Liang, Edison Thomaz
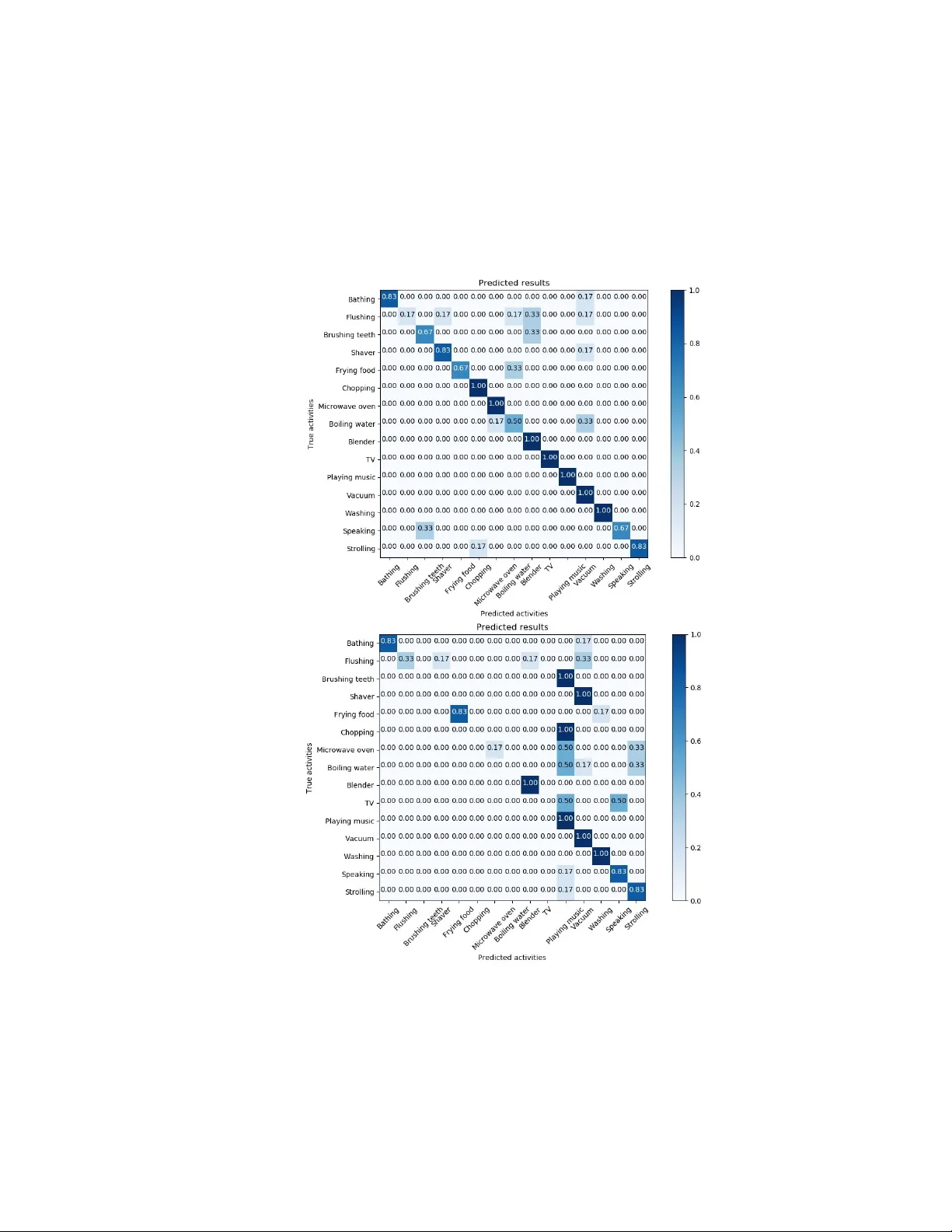
A udio-Based Activities of Daily Living ( ADL) Recognition with Large-Scale Acoustic Embeddings from Online Videos D A WEI LIANG, the University of T e xas at Austin, USA EDISON THOMAZ, the University of T e xas at Austin, USA Over the years, activity sensing and recognition has been shown to play a key enabling role in a wide range of applications, from sustainability and human-computer interaction to health care . While many recognition tasks have traditionally employed inertial sensors, acoustic-based methods oer the benet of capturing rich contextual information, which can be useful when discriminating complex activities. Given the emergence of deep learning techniques and le veraging new , large-scaled multi-media datasets, this paper revisits the opportunity of training audio-based classiers without the onerous and time-consuming task of annotating audio data. W e propose a framework for audio-based activity r ecognition that makes use of millions of embedding features from public online video sound clips. Based on the combination of oversampling and deep learning approaches, our framework does not require further feature processing or outliers ltering as in prior work. W e evaluated our approach in the context of Activities of Daily Living ( ADL) by recognizing 15 everyday activities with 14 participants in their own homes, achieving 64.2% and 83.6% averaged within-subject accuracy in terms of top-1 and top-3 classication r espectively . Individual class performance was also e xamined in the paper to further study the co-occurrence characteristics of the activities and the robustness of the framework. CCS Concepts: • Human-centered computing → Empirical studies in ubiquitous and mobile computing ; Additional K ey W ords and Phrases: Activity r ecognition, de ep learning, multi-class classication, audio processing 1 INTRODUCTION Sensing and recognizing human daily activities has b een demonstrated to b e useful in many areas, from sustainability to health care. For example, older adults in their own homes could benet from proactive assistance and monitoring in as a way to "live-in-place " and not be forced to move to an assiste d-living or nursing facility . While on-body inertial sensors such as accelerometers and gyroscopes are popular in many human activity recognition applications, prior work suggests that they are not eective at recognizing complex and multidimensional activities on their own [ 1 – 3 ]. A udio, on the other hand, oers much promise in this respect; many daily activities generate characteristic sounds that can be captured with any o-the-shelf device with a microphone . Hence, researchers have propose d several dierent types of audio event recognition frameworks over the years, from applications on wearable and mobile devices [ 4 , 5 ] to home-based sensor systems [6, 7]. With the development of deep neural networks in recent years, se veral eorts have been made by resear chers to model large-scaled acoustic ev ents. These include the usage of deep learning for sound classication on existing datasets [ 8 ] and the recognition of acoustic categories in the wild [ 9 ]. Howev er , most such frameworks suer from the laborious collection of ground truth training data. Some researchers have explor ed the use of crowd-sourced data to alleviate the problem, such as Nguy en et al. and Rossi et al. Despite encouraging results, these methods have proven dicult to scale as they partially rely on human input or interaction. Large-scale, open-source audio colle ctions no w oer a rich source of audio data reecting a large number of everyday activities. In this work, we present a novel scheme to recognize activities of daily living in the home. Instead of directly collecting ground truth data and labels from users as in most prior resear ch, we explored the feasibility of using millions Authors’ addr esses: Dawei Liang, the University of T exas at A ustin, USA, dawei.liang@utexas.edu; Edison Thomaz, the University of T exas at A ustin, USA, ethomaz@utexas.edu. 1 of audio embeddings from general-sourced Y ouT ube videos as the only training set. Due to the considerable size and highly unbalanced characteristics of the on-line data, our method combines both oversampling and deep learning approaches. The contributions of this work can be summarized as: • A novel framework for activity recognition with ambient audio that relies exclusively on a large-scale audio dataset. It aims to empower traditional audio-based activity recognition by applying over 2 million audio embedding features from nearly 52,000 public Y outube vide os. T ypically , the proposed framework do es not require feature augmentation and semi-supervised learning processes as in relevant research. • An evaluation of the framework with 14 subjects in their homes and 15 activities of daily living. The proposed method was able to yield promising performance for activities and was robust to environmental variability . 2 RELA TED WORK 2.1 Inertial Sensing Activity recognition based on sensor data is not new . It has be en widely use d for several domains including self monitoring [ 10 ], assistance in smart home [ 11 ] or diagnosis of some activity-related disease [ 12 ]. Traditional appr oaches of activity recognition rely on inertial sensors such as accelerometers and gyroscopes. They can be implemented exibly on smart phones [ 2 , 3 ], smart watches [ 10 , 13 ] or wearable sensor boards [ 1 ]. For example, K wapisz et al. [ 2 ] managed to recognize walking, jogging, upstairs, downstairs, sitting and standing by just using a smart phone in subjects’ po ckets. Thomaz et al.[ 10 ] proposed the usage of 3-axis accelerometers embe dded in an o-the-shelf smart watch for detection of eating moment. Similarly , Ravi et al. [ 1 ] showed the feasibility of attaching a sensor board on human body for simple movement classication. Most of such work focuse d on recognition of very simple activities involving limited types of sensors. The limitation of the activity class availability can b e improved by combining more sensing mo dalities. Howev er , implementation of complex sensor arrays always brings challenges in insuciency of training sets and constraints of energy or computing r esource. The subject and location sensitivity of traditional inertial sensing can make it even harder for generalization of activity models [14]. 2.2 A udio Sensing Out of such reasons, researchers have proposed to empower activity recognition by video and audio approaches. Microphones have the benets of simplicity and e xibility for implementation. Eronen et al. [ 15 ] proposed the pilot study to recognize common contexts based on sounds by using statistical learning methods. Y atani and Truong [ 16 ] explored the recognition of 12 activities r elated to throat movement such as eating, drinking, speaking and coughing by acoustic data collected from human throat area. This was completed by a simple wearable headset consisting of a tiny microphone, a pie ce of stethoscope and a Bluetooth module. Another study sho wed that human eating activity can also be eectively inferred by using wrist-mounted acoustic sensing [ 4 ]. This implies the practicality of simple audio-based activity recognition by o-the-shelf products such as smart watches. With the development of smart phones in recent years, phone-base d acoustic sensing also shows great capability on activity recognition tasks. The A mbientSense application [ 5 ] is an example . It is an Android app that can process ambient sound data in real time either on user front end or on an on-line server . It was tested on mainstream smart phones (Samsung Galaxy SII and Google Nexus One) and yielde d satisfactor y results on classication of 23 context of daily life. Lu et al. [ 17 ] developed the SoundSense to dete ct multiple speech, music and ambient sound categories base d on mobile platforms. Acoustic sensing can also be used for indoor scenarios, especially when video-based metho ds may bring privacy concerns. Laput et al.[ 6 ] 2 described the concept of general-purpose sensing, where multiple sensor units including a microphone were embedde d on a single home-oriented sensor tag. Chen et al. [ 7 ] provided an audio solution for detection of 6 common activities in bathroom based on MFCC features. Their work typically aims at elder care since direct behavioral obser vations can b e quite embarrassing to be shared with clinicians. More recently , acoustic sensing and recognition have been signicantly improved based on the usage of de ep learning techniques. Salamon and Bello [ 8 ] proposed an architecture combining feature augmentation and a CNN to evaluate on-line audio data. Lane et al. [ 9 ] developed the DeepEar to classify multiple categories for dierent sensing tasks based on a well-tuned fully connected network. 2.3 A udio-Based Activity Recognition with Online Data Most of the prior work requires a manual collection of ground truth audio data from individual users. This can b e quite laborious especially if we are targeting at multiple classes of activities. Also, it is actually unrealistic to ask the users to train the model on their own before using it. Hence, Hwang and Lee [ 18 ] introduced a crowd-sourcing framework for the problem. They dev elope d a mobile platform to collect audio data from multiple users. The platform could then generate a global K -nearest neighbors (KNN) classier based on Gaussian histogram of MFCC features to recognize basic audio scenes. Howev er , this still requires collection of user data and the performance of the system highly depends on the size and quality of the training set. General-purp osed acoustic database, on the other hand, can potentially ser ve as ideal data source to the e xisting systems. Over the past years, the Freesound database (https://freesound.org/) has been one of the most commonly used database for audio research. Started in 2005 and currently maintaine d by the Freesound team, it is a crowd-sourced dataset consisting of over 120’000 annotated audio recordings. Besides, Salamon et al. [ 19 ] released the UrbanSound database containing 18.5 hours of urban sound clips selected from the Freesound. Säger et al. [ 20 ] improved the Fr eesound recordings by adding adjective-noun and verb-noun pairs to the audio tags and constructed a new A udioPairBank dataset. Rossi et al. [ 21 ] rst attempted context recognition based on MFCC features extracted from the on-line Fr eesound database by using a Gaussian Mixture Model (GMM). Howev er , due to the limited size of the training set (4678 audio samples for 23 target context), the top-1 classication accuracy based on dedicated sound recordings was just 38%. The performance was improved to 57% by manually ltering over one thir d of the samples as outliers. Beyond that, Nguyen et al. [ 22 , 23 ] leveraged semi-supervised learning methods to combine the on-line Freesound data with users’ own recordings. After manually ltering outliers for quality , they trained a semi-supervise d GMM on MFCC features extracted fr om 163 Freesound audio clips for 9 context classes. The model was then applied to unlabeled user-centric data recorded by smart phones with a headset microphone. The performance was evaluated based on the second half of the user data with an average accuracy of 54% for 7 users. T o further improv e the performance, Nguyen et al. [ 23 ] also presented two active learning mechanisms, where a supervised GMM was rst trained on the same Freesound data or well-labeled user data and then interactively queried users for labeling the unlabeled user-centric data. Clearly , from the prior work we can see that the e xisting crowd-sourced datasets do not generalize suciently the audio recorded across users, and previous research still needs to rely on user data and manual ltering of outliers for better performance. In April 2017, Google’s Sound Understanding team released the A udio Set database [ 24 ] 1 containing ontology and embedding features of over 2 million audio clips drawn from general Y ouT ube videos. The clips are categorize d by 527 audio labels and many of the class lab els can be potentially bridge d to the common real world scenarios. Actually , the idea of domain adaptation from the web has been developed in several activity recognition research. Hu et al. [ 25 ] 1 https://research.google.com/audioset/ 3 proposed to use web search text as a bridge for similarity measures between sensor readings. Fast et al. [ 26 ] developed the A ugur , a system leveraging contexts from on-line ctions to pr edict human activities in the real world. In terms of audio-based classication, A ytar et al. [ 27 ] describe d the SoundNet framework for knowledge transfer between large-scaled videos and target sounds based on a de ep CNN. T o the b est of our knowledge, however , very few attempts have been made to adapt such tremendous scale of on-line audio samples for real-world activity recognition, and this can be even challenging when leveraging the Y ouT ub e sound features due to the ambiguous source of the raw videos from movies, cartoons to cr owd-sourced data. The most r elevant up-to-date achievement was pr oposed by Laput et al. [ 28 ], where the r esearchers developed a mixed process of audio augmentation for a deep network and combined the online sound eect libraries with the A udio Set data for audio context classication. Their work shows promising results when applying the augmentation process with the online sound eect data. Ho wever , the performance of the framework dropped signicantly if purely using the video sounds (i.e. the A udio Set [ 24 ] data) without augmentation. Moreover , their work mainly focused on the classication of environmental contexts, and the statistics in terms of individual activity classes still largely remained unexplored. In our research, we aime d to study the feasibility and performance reported from the perspective of individual activity recognition by leveraging only the online video sound clips for training. Our in-lab and multi-subject studies sho wed that the proposed framework was able to yield promising performance even without any feature augmentation or semi-supervised learning techniques. 3 IMPLEMENT A TION 3.1 A udio Set In 2017, Google ’s Sound Understanding team released a large-scale acoustic dataset, named Audio Set [ 24 ], endeavoring to bridge the gap in data availability between image and audio research. The A udio Set contains information of over 2 million audio soundtracks drawn fr om general Y ouT ube videos. The dataset is structured as a hierarchical ontology consisting of 527 class labels and the size is still growing no w . All audio clips are equally chunked as 10 seconds long and labeled by human experts. The dataset does not provide original waveforms of the audio clips. Instead, the samples are presented in the form of both source indexes an d bottlene ck embedding features. The audio index contains information of the audio ID , URL, class lab els, and start and end time of the sample within the corresponding source video. The embedding features are generated from the embedding layer of a VGG-like deep neural network (DNN) architecture trained on the Y ouT ube-100M dataset [ 29 ]. The generation frequency is roughly 1Hz (96 10ms audio frames, i.e. 0.96 se conds of audio per emb edding vector). In other words, one emb edding vector can describ e one se cond of audio clip, and therefore there are 10 embedding vectors for each audio clip within the dataset. Before released, the embedding vectors have also been post-processed by principle component analysis (PCA) and whitening as w ell as quantization to 8 bits per embedding element. Only the rst 128 PCA coecients are kept and released. The original vectors are all stored within T ensorF low [ 30 ] Record les. Given the signicant size of the emb eddings and the lack of convenience for data pr ocessing, Kong et al. [ 31 ] provided a converted Python Numpy v ersion of the raw embeddings which are adopted in our research. Their converted dataset has been released publicly online 2 . 2 https://github.com/qiuqiangkong/ICASSP2018_audioset 4 T able 1. T arget activities and association with Audio Set labels Category Activity Class Associated A udio Set Labels Bathing/Showering Bathtub (lling or washing) W ashing hands and face Sink (lling or washing); W ater tap, faucet Bathroom Flushing toilet T oilet ush Brushing teeth T oothbrush Shavering Electric shaver , electric razor Chopping food Chopping (food) Frying foo d Frying (foo d) Kitchen Boiling water Boiling Squeezing juice Blender Using microwave o ven Microwave o ven W atching T V T elevision Living/Bed room Listening to music Piano Floor cleaning V acuum cleaner Chatting Conversation; Narration, monologue Outdoor Strolling W alk, footsteps; Wind noise (microphone) 3.2 Label Association Before implementation, we need to consider the range of target activities and how we can associate the class labels in the A udio Set with them. Our research leverages existing audio samples and labels from on line as the training set, and we aim at target activities that frequently appear in the home. Sp ecically , the range of our target classes has been limited to target activities that are suitable for audio-based recognition. Here ‘suitable ’ means that the sound of the activity should be featured and easily captured in practice. Hence , we excluded pet categories for our study because such sound is normally sparse in natural home scenarios. Classes such as ’silence’ was also not chosen because the corresponding attributes can be ambiguous from sleeping, standing, to maybe just absence of the person in the room. Body movement with very weak sound features is not suitable for audio-based recognition as well. Further mor e, it is not always possible to nd an exact matching b etween the Audio Set labels and the actual activities. In such cases, we adopted an indirect matching process. That is, we rst determined the most relevant objects and environmental contexts regarding to the target activities. W e then chose A udio Set classes of such objects and contexts as representation of the activities. For example, we used class ’water tap ’ and ’sink’ as representation of ’washing hands and faces’ as all three classes involve usage of water and the features are quite similar . This is actually a very subje ctive process as there is no quantized measurement to determine the similarity b etween such relevant classes and the actual target classes. For the class ’listening to music’ , we focuse d on studying only piano-related musics as examples. It is noted that the dataset provides a quality rating of audio labels based on manual assessment. Most of the labels have been assessed by experts based on a random check of 10 audio segments within the label. The samples of each label are actually divided into three subsets ( evaluation , balance d training , and unbalanced training ) for training and evaluation purposes. The evaluation and balanced training sets are of much smaller size than the rest unbalance d training set, and due to the considerable size of samples and factors such as misinterpretation or confusibility , many class labels of the unbalanced training sets are actually of poor rating results. In our frame work, we did not consider the sample ratings and we incorporate all three evaluation, balanced training and unbalance d data for our training set. 5 W e therefore determined 15 common home-related activities for the framework. They are associated with 18 Audio Set labels. T able 1 shows the association between our target activities and the Audio Set class lab els, and all audio embeddings of the listed Audio Set classes are used as the only training data in our proposed scheme. 3.3 Oversampling A typical characteristic of the Audio Set data is the unbalanced distribution in terms of the class size. In our implemen- tation, we also remo ved samples with label co-occurrence among the target classes to ensure mutual e xclusiveness, and table 2 shows the numb er of embedding vectors per class in our raw training set without any sampling process. The numbers here include embeddings from all three subsets (evaluation set, balanced training set and unbalanced training set). The actual size for some classes is slightly smaller than the y appear on the released Audio Set since we adopted the converted Python Numpy version of features as mentioned. As we can see, classes ’chatting’ and ’listening to music’ have the most embe ddings (174,220 and 115,200 respectively). Class ’brushing teeth’ is of the least, only 1230, which accounts for 0.7% of the largest class. In other words, the two majority classes account for over half of the whole training set. The unbalanced distribution of the class size leads to highly unbalanced training in our study . As we will see in the dedicated test se ction, the distribution of training class can heavily aect the recognition p erformance, and we implemented two oversampling pr ocesses for the problem. The unbalanced distribution of labels can mainly be aected by two facts. Firstly , the distribution actually reects the diversity and frequency of the class labels within the source Y ouTube videos. For example, elements of chatting or musics can be captured in a large amount of video topics, from advertisement, news to cartoons. Brushing teeth, on the contrary , appears much less and typically just in some movie scenes or daily life recordings. Chatting can also involve several modalities according to the speaker’s gender , age and the context of the spee ch, while brushing activities seem to be much more similar among each. Secondly , we are using only samples without label co-occurrence among the target classes. The size of the remaining disjoint data can also aect the actual distribution in our training set. T able 2. Number of embedding vectors p er activity class Activity Categor y # of Embedding V ectors Chatting 174,220 Listening to music 115,200 Strolling in courtyard 81,450 W atching T V 22,250 Flushing toilet 22,190 Floor cleaning 19,710 W ashing hands and face 17,080 Frying foo d 15,820 Bathing/Showering 14,270 Squeezing juice 12,600 Shavering 8,570 Using microwave o ven 8,180 Boiling water 4,440 Chopping food 2,060 Brushing teeth 1,230 T otal 519,270 6 The eects of unbalanced training on classication have be en discussed in several work [ 32 – 34 ]. Without prior knowledge of the unbalanced priors, a classier can always tend to predict the majority classes, and there should be higher cost for misclassifying the minority classes [ 32 ]. In our scheme, w e implemented random oversampling with replacement and synthetic minority oversampling te chnique (SMOTE) [ 33 ] to handle the problem. The process of random oversampling can be divided into two steps. The rst is to calculate the sampling size for each minority class, i.e. to calculate the dierence of size between the target class and the majority class. Then each minority class will be re-sampled with replacement until the sampling size is lled. This is actually replication of existing data without introducing any extra information into the dataset. The SMOTE, on the contrar y , works by adding new elements for the minority classes. It le verages the K -nearest-neighbors (KNN) approach to rst generate ne w data points around the existing data points. Then one of the neighbors is randomly selected as the synthetic new elements and will be introduced to the minority class. In our implementation, the oversampling process was developed based on the Python imbalanced-learn package [ 33 , 35 ]. All parameters were set as default in the imbalanced-learn package version 0.3.3 except that the random state was kept as 0. By the o versampling processes, we actually obtain 2,613,300 emb edding vectors in total for the 15 classes. The size are the same for both random oversampling and the SMOTE. 3.4 Architecture Deep learning has b een proven to be powerful for large-scale classication. Due to the considerable size of audio samples involved in our study , and also to keep the same feature format as released in the A udio Set, we adopted neural networks for both embedding feature extraction and classication in our propose d framework. Fig.1 shows the architecture. Overall, there are two networks in our me chanism, a pre-trained feature e xtraction network and a classication network. In details, we adopted the pre-trained VGGish model [ 29 ] as the extraction network and all parameters of the network were xed during our training process. The classication network consists of 1-dimensional Fig. 1. Architecture of our proposed scheme. W e applied the V GGish model [ 29 ] as the featur e extraction network. The feature netw ork was pre-trained on the Y ouTube-100M dataset and all parameters were fixed in our training process. The generated embeddings are then segmented and passed to the classification network. Our classification network consists of plain 1-dimensional convolutional layers and dense layers, and the model was trained and fine-tuned on the oversampled A udio Set [24] embeddings. 7 Fig. 2. Architecture of the classification network. The classification network is constructed as 3 1-dimensional convolutional lay ers and 2 fully connect (dense) layers. The network takes as input segmented embedding vectors and outputs probability distribution of the activity labels. convolutional layers and dense layers. The parameters and weights of the classication netw ork were trained and ne tuned on the A udio Set data. Besides, we added an embedding segmentation process between the two networks to improve r ecognition p erformance. In the initial A udio Set, the frame-level features of the audio clips were generated by a VGG-like acoustic model pre-trained on the Y ouT ube-100M dataset. T o enable researchers to extract the same format of featur es, Hershey et al. [ 29 ] provided a T ensorFlow version of the mo del called VGGish . It has been trained on the same Y ouTube-100M dataset and can produce the same format of 128-dimensional embeddings for every second of audio sample. The V GGish model takes as input non-overlapping frames of log mel spectrogram of raw audio waveforms. The source codes and weights of the pre-trained VGGish model are released on the public Audio Set model GitHub repositor y 3 . The source codes also include pre-processing steps for e xtracting the log mel spectrogram features to feed the model and post-processing steps for PCA transform and element-wise quantization which have also been adopte d on the released Audio Set data. In our implementation, the audio pre-processing step takes as input audio waveforms with 16 bit resolution, so we manually convert other formats of audio samples (such as raw recordings from smart phones) to the wav e format using a free on-line converter 4 before passing the raw audio for processing. The parameters of the VGGish network kept constant during the whole training and validation process. The network could then output a vector of 128 syntactic embeddings for every second of the input audio. Our classication netw ork consists of 3 plain convolutional layers and 2 dense (fully conne cted) layers. The structure is shown in Fig.2. The conv olutional layers are all 1-dimensional tensor with linear activation and same paddings to ensure the same featur e size. The number of channels are 19, 20 and 30 respectively for the 3 layers. The kernel size was all set as 5 with a stride of 1. W e applied 500 neurons for the rst dense layer . The second dense layer is the output layer , thus there are 15 neurons and the output activation was set as softmax. A atten layer was used to connect the convolutional layers and the dense layers. W e chose categorical cross entropy as the loss. In terms of the optimizer , we applied stochastic gradient descent with Nesterov momentum. The learning rate was set as 0.001 with 1e-6 decay and 0.9 momentum. The network takes as input (128 * 1) segmented and normalized embeddings from the segmentation step of our architecture and outputs predicted probability distribution of the labels. Under the top-1 classication scenario, the label with the highest probability will be selected as the nal prediction. Our classication network was built and 3 https://github.com/tensorow/models/tree/master/resear ch/audioset 4 https://audio.online- convert.com/convert- to- wav 8 compiled on Python Keras API [ 36 ] with T ensorow [ 30 ] backend. The weights were trained and ne tuned on the A udio Set embe ddings. In addition to the neural networks and audio processing steps, we also applied embedding segmentation to determine the unit length of an audio segment for recognition. This is natural because the length of a single embedding vector (1 second) can be too short to some activities and may not be able to capture enough information for recognition. Also, increasing the segment length can help to alle viate the eects of outliers and noise within the real world r ecordings. Hence, we introduce d a segmentation process on embeddings b etween the two networks. For convenience, in the following sections we will describe the length of a unit segment by number of embedding vectors (1 second each). In our architecture, the segmentation is completed by grouping the embedding vectors using a x-size d window with no overlaps. The vectors will then be averaged within each group to yield a new embedding vector . In other words, each unit audio segment is describe d by an averaged embedding vector . Activity labels will then b e assigned to the averaged vectors and those vectors actually serve as the instances for classication. The emb eddings are standardized using min-max scaling before tting to the classication network. The source code of our ov erall architecture has been made publicly available online 5 . Both the oversampling and training processes were developed on the T exas Advanced Computing Center (T ACC) Mav erick ser ver . Spe cically , we applied the N VIDIA K40 GP U on the ser ver to accelerate the training process. The training embeddings were split as 90% for training and 10% for validation using the Pyhton Scikit-learn package [ 37 ]. The T ensorFlow version provided was T ensorFlow-GP U 1.0.0 [ 30 ]. Befor e training, we set all random seeds as 0 to ensure the same training status. Besides, a batch of 100 embedding vectors were input each time. The classication network was trained until the validation performance no longer improved (in our study , 15 to 20 epochs dep ending on the re-sampling set in use). 4 FEASIBILITY ST UD Y 4.1 Pilot T est T able 3. Recognition performance leveraging dierent architectures of implementation. Architecture Accuracy F-Scor e Baseline(RF) + raw embeddings 34.4% 24.5% Baseline(RF) + random oversampling 36.7% 27.2% Baseline(RF) + SMOTE 45.6% 37.1% CNN + raw embeddings 52.2% 44.8% CNN + random oversampling 81.1% 80.0% CNN + SMOTE 73.3% 71.1% W e evaluated the feasibility of our framework based on a pilot lab study . There are two purposes to do so. Firstly , we would like to check if our proposed metho dology can actually work based on real-world ambient recordings. Although the architecture had b een well trained on the A udio Set data, the characteristics of the Y ouTube video sounds and real-world ambient sounds could possibly b e dierent. Secondly , we would need a real-world test to determine the best combination strategy for the sampling process and the classier . In this dedicated study , we collected sounds of the target activities in the wild by placing an o-the-shelf smart phone (Huawei P9) nearby for recording. In the pilot study , the context of the activities was well-controlled with low variability . Specically , we tried best to exclude irr elevant 5 https://github.com/dawei- liang/Audio AR_Research_Codes 9 environmental noise such as sounds of toilet fans or air conditioners during the collection. Also, when a target activity was performed there were no extra on-going activities. When the study began, the smart phone was place d in a natural fashion near where the activity was going to b e performed. The collection was manually starte d when the sound of the activity could b e clearly captured. Sound recording for each activity lasted for 60 seconds, and it would b e stopped Fig. 3. Recognition results of the pilot study using random oversampling + CNN (top) and raw embeddings input + CNN (down). It is obvious that the performance with the oversampling process far exceeds the performance with only raw embeddings input. 10 when the proposed time ended. This same process had been repeated for each individual activity until the collection for all 15 activities was completed. W e chose a segmentation size of 10 embe dding vectors (9.6 seconds) for the dedicated study . The recognition performance was evaluated based on 3 dierent sampling processes (raw embeddings input/no oversampling, random oversampling, and the SMOTE). T o make it clearer how the classication netw ork performs, w e also tuned and trained a random forest classier on the same training sets as a baseline. The random forest was built using the Python Scikit-learn package [ 37 ]. W e used the overall accuracy and overall F-score as the performance metrics. In binary classication, the F-score is calculated as 2 * (precision * recall) / (precision + recall) and it incorporates information for both precision and recall performance. In our study , the overall F-score across multiple classes can be calculated by nding the weighted average of F-scores of the individual labels. T able 3 shows the recognition performance based on dierent architectures. For convenience, the random forest is abbreviated as RF in the table. From the results we can see that the random forest without any sampling process yields the worst accuracy and F-score (34.4% and 24.5%). This is comparable to the dedicated study by Rossi et al. [ 21 ], where the authors trained a GMM on 4678 raw samples from the crowd-scoured Freesound dataset and obtained 38% o verall accuracy for 23 context categories. Clearly , introduction of the classication network signicantly improves the recognition performance, especially if combining with the oversampling processes. The combination of random oversampling and our classication network yields the best performance (81.1% ov erall accuracy and 80.0% overall F-score). Generally , classiers with oversampling outperform those without one. Fig.3 shows in details the performance of individual classes with and without oversampling, and the entries have been normalized for each class. As w e can see, classication network input with raw embeddings overts to some of the majority classes such as ’playing music’ and ’strolling’ . Network input with the random oversampled embe ddings, on the contrar y , yields equally promising results to most classes. The worst class for the top-1 architecture was ’ushing toilet’ with only 17% class accuracy . This is probably because the segmentation length was too long to the ushing activity and too much irrelevant information was captured within the segments. Fig. 4. F-score performance with dierent segmentation size. The performance was worst when no segmentation process was applied. With increment of the segments size, the F-scor e significantly increased and remained stable around 80%. The random guess levels were around 7%. 11 T o determine how the segmentation process can ae ct the classication performance, we compared the overall F-score under dierent size of embedding segmentation. The comparison is shown in Fig.4. As reference, we also plotted the random guess lev els (around 7%). Fr om the gure, we can se e that the performance was the w orst when no segmentation process was introduce d (i.e. 1 embedding vector each segment), with an F-score of only 65%. By applying a bigger segment size, the F-score value signicantly incr eased to over 80%. In addition, we can see that the unit segmentation length of 5 embe dding vectors has already enabled the instances to capture enough information for the classication. Further enlarging the size of segmentation no longer improve the o verall recognition performance. 4.2 More Discussions towards Domain Shis From the perspective of transfer learning, our framework is actually a domain adaptation process where we try to nd a mapping b etween the source Y outub e soundtracks and the real-world recordings. Generally speaking, audio features from such on-line videos can be ver y dierent from those of the real-world collections for activity recognition. Interestingly , our classication network only yielded 53% validation and training accuracy on the random oversampled A udio Set embeddings. But the p erformance of our top-1 scheme reached to over 80% on the ambient recordings. Besides, we have noticed that the validation performance on the A udio Set data could have been further improved by adopting deeper layers. However , increasing the depth of the model would no longer help to improve the performance on real-world data (it might even harm the performance). A p ossible reason is that ambient sounds from the real world (especially in home settings) can generally be of less complexity and be more ’linear separable’ than those on the Y ouT ube videos. In other words, a model t too much on the A udio Set data can probably becomes over-tting to the sound recordings from our home settings. 5 IN- THE-WILD TESTS 5.1 T est Design By the pilot test, we veried the feasibility of the proposed framework and determined the appropriate combination of the oversampling and segmentation strategies with the proposed networks. T o generalize the study in more natural settings, we then implemented in-the-wild scripte d tests based on 14 human subjects in their actual home environment. In the pr evious feasibility study , we made se veral assumptions for the test envir onment. Firstly , there was little irrelevant environmental noise such as noise of common home appliances during the collection process. The audio samples were recorded by a smart phone nearby with almost no articial or ambient disturbance during the processes. Secondly , the start and end points of the collection were also carefully selecte d to ensure high quality recordings. Thirdly , there were almost no overlaps and co-occurrence among the activities. In other words, individual collections wer e ensured to be strictly mutual exclusive. How ever , in real-world settings such assumptions can always be broken. For example, human artifacts such as sounds from roommates and ambient noise from air conditioners or refrigerators are almost inevitable in our home. Also , people tend to perform activities in a more continuous way and it is quite reluctant if the framework always requires a pause. Hence, we are interested to see how the proposed architecture performs under such more natural circumstances. The real-world tests wer e performe d based on a scripted scenario. A key advantage of the scripted tests is that the procedure of following the script can simulate the continuous process of human activities just as in natural home settings. All target activities wer e listed in advance in the form of instructions such as "First head to the bathroom, wash your hands and face" or " After juice prepared, please warm some fo od using the microwave oven" . Each human subject 12 then simply followed the instructions on a paper and freely perform the activities. W e adopted the same o-the-shelf device (Huawei P9) in the collection. The smart phone was carried on the subjects’ arms with a wristband so that the they could perform the activities without paying attention to the collection process. During the whole colle ction, an expert (one of the authors of the paper) followed the subjects while they were performing the activities but would keep a distance (e.g. waiting outside the room while the subject was performing room cleaning) to allow sucient freedom for the subjects. The key roles of the expert w ere to answer questions by the subjects during the test and to label the time stamps of the target activities by using a timer starte d simultaneously with the r ecording phone. T o avoid subjective bias, the tested volunteers had not been told the full purpose of the experiment until the whole colle ction was completed. All participants of the study were required to signed an IRB protocol form before the tests. T o incorporate variability factors in the tests, the expert would occasionally introduce a small amount of fr ee chatting during some of the activities such as watching T V , frying or strolling. T o simulate the concurr ence of activities, the subjects were allowed to perform some activities simultaneously such as short washing during the fr ying work. In addition, all 14 tests were performed in volunteers’ own home and they were allowed to leave some household appliances such as the air conditioners or r efrigerator compressor working as normal. T o further follow their normal modality , they were encouraged to use their o wn devices or tools (e.g. their own vacuum cleaner , kitchen and toilet appliances) for the collection. In our script, most activities were r equired to be just performe d once and the length was determined freely by the participants. W e prepared some bacon, cucumbers or carrots in advance for activities ’frying food’ , ’chopping food’ and ’squeezing juice’ . Given the diversity of tele vision programs, the participants were asked to watch for 5 dierent channels with around 30 seconds each for the class ’watching T V’ . For class ’ enjoying music’ , the subjects wer e specied to play their own piano or listen to rele vant types of musics such as piano solo or symphonies chosen by themselves. Besides, class ’shavering’ was waived for female subjects. 5.2 Results and Discussions In total we were able to obtain 32105 se conds (535 minutes) of audio data from 14 subjects (7 males and 7 females). Based on the labeled time stamps, we manually segmented the target activity data from the raw recordings. Overall, we identied that roughly 12078 seconds (201 minutes) of the clips w ere target-related, accounting for 37.6% of the total. The resulting sparsity is comparable to audio-based activity recognition in practice as not all home-r elated activities can generate specic sound features and audio-based frameworks are not suitable for them. W e then applie d the best architecture of the proposed framework (classication network with random oversampling) to evaluate the results. The unit segmentation length was set as 10 embedding vectors (9.6 seconds). The test results were rst examined base d on each individual participant. Fig.5 shows the overall classication performance within single subjects. Because of the high inequality of segment length among the activities, we adopted the overall weighted av erage as the performance metric. In other words, for a given subject, the contribution of each tested instance to the overall accuracy is inversely proportional to the amount of tested data within that corresponding activity class. By weighting the instances, each activity class within the subject can then contribute equally to the overall performance. In our studies, the averaged top-1 classication accuracy was 64.16% for all tested subjects. In addition to the top-1 classication, we also e valuated the overall performance using a top-3 classication scenario given the co-o ccurrence of activities and the variability during the tests. In the top-3 classication, predicted labels with the top 3 highest probability are considered as the nal predictions, and a true positive can be counted if any of the 3 labels match the ground truth. It incorp orates the variants of predictions due to possible similarity of sound features or 13 Fig. 5. Classification performance within subjects. The averaged top-1 and top-3 accuracies are 64.16% and 83.59% respectively for all subjects. concurrence of the actual activities. From the gure w e can see that the top-3 performance was much b etter than the top-1 scenario, with an averaged accuracy of 83.59% for all 14 subjects. T o evaluate the performance of individual activity classes, we also summarized the class accuracies across all tested subjects. W e calculated the average values for both the top-1 and top-3 classication, and Fig.6 and Fig.7 present the statistics for both settings. Instead of directly applying confusion matrices, we adopted a similar weighted approach for the analysis. That is, tested instances from each subject were assigned with weight that was inv ersely pr oportional to the amount of data within them. This enables samples from dierent subjects and dierent tested environment with varying data size to contribute equally to the overall performance of the target classes. In addition, the gures also indicate the Fig. 6. T op-1 classification p erformance for individual activity classes across the subjects ( A:Bathing/Showering; B:Flushing; C:Brushing T eeth; D:Doing Shaver; E:Fr ying; F:Chopping; G:Microwave Oven; H:Boiling; I:Squeezing Juice; J:W atching T V; K:P laying Music; L:Floor Cleaning; M:W ashing; N:Chaing; O:Strolling) 14 Fig. 7. T op-3 classification p erformance for individual activity classes across the subjects ( A:Bathing/Showering; B:Flushing; C:Brushing T eeth; D:Doing Shaver; E:Fr ying; F:Chopping; G:Microwave Oven; H:Boiling; I:Squeezing Juice; J:W atching T V; K:P laying Music; L:Floor Cleaning; M:W ashing; N:Chaing; O:Strolling) deviations of the class accuracies away fr om the mean. A smaller deviation represents a mor e stable performance of the predictions and further implies a stronger robustness of the framew ork towards variants in the actual tests. A s indicated from the gures, ’shav ering’ , ’chopping food’ and ’using microwav e oven’ showed the best performance with almost 100% averaged class accuracy and almost zero deviation. Class ’oor cleaning’ was also of satisfactor y results due to its clear and unique sound featur es. On the contrary , howev er , most of the ushing activities were misclassied by the framework. It is probably because the process of pumping was too short given the segmentation length and the sounds of water ushing can largely overlap with those of the washing or frying activities. Also in the gures, some activities such as ’frying fo od’ , ’boiling water’ , ’squeezing juice’ and ’brushing teeth’ are of high deviations from their average . It is reasonable because the mo dalities of cooking and b oiling can vary in practice depending on the choice of the kettles and cooking tools or the variant cooking styles among the participants. The performance of kitchen activities was also aected by usage of hoo ds by some of the participants. The brushing activity could mainly be aected by the noise of toilet fans. Especially , we noticed that our framework faile d to recognize almost all brushing activities with electric toothbrush possibly due to the lack of relevant training samples in the Audio Set. If comparing the results in both gures, we can also see that the performance of most activities increased signicantly from the top-1 scenarios to the top-3 scenarios, reaching to nearly 100% mean accuracy with much smaller deviations. This implies the existence of activity co-occurrence and overlaps of acoustic features among distinct activities such as simultaneous chatting with outdoor strolling or a music show on TV , which are also commonly seen in the natural home settings. Because of the dierence in terms of evaluation metrics and test conditions, it was challenging to directly compare the performance across the related work. As reference, Rossi et al. [ 21 ] combined a semi-super vised or manual ltering of outliers with the Gaussian Mixture Mo del (GMM) to classify 23 acoustic contexts. They extracted the MFCC features from the Freesound dataset with the sequence length of 30 seconds for training. The b est top-1 classication and top-3 classication performance were 57% and 80% respectively only if with manual ltering of the outliers. Hershey et al. [ 29 ] trained two fully connected networks with and without the embedding extraction pr ocess to classify the Audio Set [ 24 ] categories. They adopted the mean A verage Precision (mAP) as the performance metric and obtained the best 15 mAP of 0.31 only if taking the embe ddings as input. Kong et al. [ 31 ] completed a similar test using an attention mo del from a probability persp ective, achieving mAP of 0.327 and AUC of 0.965. The state of the art by Laput at al. [ 28 ] reported the classication performance from several perspectives. Their best model achieved 80.4% overall accuracy for 30 context classes r ecorded in the wild, but the framework relied on a mixed pr ocess of audio augmentation and combination of sound eect libraries for training. If purely using the online video sounds (i.e. the Audio Set [ 24 ] data), their framew ork yielded an ov erall accuracy of 69.5% when check-pointe d on the test set and 41.7% when tested directly on the real-world sounds. Correspondingly , our framework was not developed base d on any feature augmentation and semi-supervise d learning processes. The overall classication accuracy of our model was 81.1% for 15 activity classes in the lab study . Our top-1 and top-3 performance was 64.2% and 83.6% respectively based on multi-subject tests of 14 participants in their actual home environment. 6 CONCLUSION The collection of ground truth user data can be time-consuming and lab orious in multi-class audio learning. This paper presented a novel frame work leveraging large-scaled on-line Y ouT ube video soundtracks as the only training set to empower audio-based activity recognition. Specically , our proposed framework aims to recognize 15 common home-related activities. Due to the tremendous size of the dataset and the highly unbalance d distribution of the training classes, our framework combined both oversampling and deep learning architectures without further needs of feature augmentation and semi-super vised learning processes. T o evaluate its performance, we designed both in-lab pilot tests and in-the-wild scripted tests with multiple subje cts in their home. Results showed that our proposed framework was able to achie ve promising performance and robustness to the environmental variability in dier ent test scenarios. Other design considerations including the association of activity labels and ee cts of embedding segmentation were also discussed in the paper . REFERENCES [1] Nishkam Ravi, Nikhil Dandekar , Preetham Mysore, and Michael L Littman. Activity recognition from accelerometer data. In Aaai , volume 5, pages 1541–1546, 2005. [2] Jennifer R K wapisz, Gary M W eiss, and Samuel A Moore. Activity recognition using cell phone acceler ometers. ACM SigKDD Explorations Newsletter , 12(2):74–82, 2011. [3] Alvina Anjum and Muhammad Usman Ilyas. Activity recognition using smartphone sensors. In Consumer Communications and Networking Conference (CCNC), 2013 IEEE , pages 914–919. IEEE, 2013. [4] Edison Thomaz, Cheng Zhang, Irfan Essa, and Gregory D Abowd. Inferring meal eating activities in real world settings from ambient sounds: A feasibility study . In Proceedings of the 20th International Conference on Intelligent User Interfaces , pages 427–431. ACM, 2015. [5] Mirco Rossi, Sebastian Feese, Oliver Amft, Nils Braune, Sandro Martis, and Gerhard Tröster . Ambientsense: A real-time ambient sound recognition system for smartphones. In Pervasive Computing and Communications W orkshops (PERCOM W orkshops), 2013 IEEE International Conference on , pages 230–235. IEEE, 2013. [6] Gierad Laput, Y ang Zhang, and Chris Harrison. Synthetic sensors: T owards general-purpose sensing. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems , pages 3986–3999. ACM, 2017. [7] Jianfeng Chen, Alvin Har vey Kam, Jianmin Zhang, Ning Liu, and Louis Shue. Bathroom activity monitoring based on sound. In International Conference on Pervasive Computing , pages 47–61. Springer , 2005. [8] Justin Salamon and Juan Pablo Bello. De ep convolutional neural networks and data augmentation for environmental sound classication. IEEE Signal Processing Letters , 24(3):279–283, 2017. [9] Nicholas D Lane, Petko Georgiev , and Lorena Qendro. Deepear: robust smartphone audio sensing in unconstrained acoustic environments using deep learning. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing , pages 283–294. A CM, 2015. [10] Edison Thomaz, Irfan Essa, and Gregory D Abowd. A practical approach for recognizing eating moments with wrist-mounted inertial sensing. In Proceedings of the 2015 ACM International Joint Conference on Per vasive and Ubiquitous Computing , pages 1029–1040. ACM, 2015. [11] Liming Chen, Chris D Nugent, and Hui W ang. A knowledge-driven appr oach to activity recognition in smart homes. IEEE Transactions on Knowledge and Data Engineering , 24(6):961–974, 2012. 16 [12] Agnes Grünerbl, Amir Muaremi, V enet Osmani, Gernot Bahle, Stefan Oehler , Gerhard Tröster , Oscar Mayora, Christian Haring, and Paul Lukowicz. Smartphone-based recognition of states and state changes in bipolar disorder patients. IEEE Journal of Biomedical and Health Informatics , 19(1):140– 148, 2015. [13] Muhammad Shoaib, Stephan Bosch, Hans Scholten, Paul JM Havinga, and Ozlem Durmaz Incel. T owards detection of bad habits by fusing smartphone and smartwatch sensors. In Pervasive Computing and Communication W orkshops (PerCom W orkshops), 2015 IEEE International Conference on , pages 591–596. IEEE, 2015. [14] Hanghang T ong Xing Su and Ping Ji. Activity recognition with smartphone sensors. Tsinghua Science and T echnology , 19(3):235–249, 2014. [15] Antti J Eronen, V esa T Peltonen, Juha T Tuomi, Anssi P Klapuri, Seppo Fagerlund, Timo Sorsa, Gaëtan Lorho, and Jyri Huopaniemi. Audio-based context recognition. IEEE Transactions on Audio, Spe ech, and Language Processing , 14(1):321–329, 2006. [16] Koji Y atani and Khai N Truong. Bodyscope: a wearable acoustic sensor for activity recognition. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing , pages 341–350. ACM, 2012. [17] Hong Lu, W ei Pan, Nicholas D Lane, T anzeem Choudhury, and Andrew T Campbell. Soundsense: scalable sound sensing for people-centric applications on mobile phones. In Proceedings of the 7th international conference on Mobile systems, applications, and services , pages 165–178. ACM, 2009. [18] K yuwoong Hwang and Soo- Y oung Lee. Environmental audio scene and activity recognition through mobile-based crowdsourcing. IEEE Transactions on Consumer Electronics , 58(2), 2012. [19] Justin Salamon, Christopher Jacoby , and Juan Pablo Bello. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia , pages 1041–1044. ACM, 2014. [20] Sebastian Säger , Benjamin Elizalde, Damian Borth, Christian Schulze, Bhiksha Raj, and Ian Lane. Audiopairbank: towards a large-scale tag-pair-based audio content analysis. EURASIP Journal on Audio , Spee ch, and Music Processing , 2018(1):12, 2018. [21] Mirco Rossi, Gerhard Troster , and Oliver Amft. Recognizing daily life context using web-collected audio data. In W earable Computers (ISWC), 2012 16th International Symposium on , pages 25–28. IEEE, 2012. [22] Long- V an Nguyen-Dinh, Mirco Rossi, Ulf Blanke , and Gerhard Tröster . Combining crowd-generated media and personal data: semi-supervised learning for context recognition. In Procee dings of the 1st ACM international workshop on Personal data meets distributed multime dia , pages 35–38. ACM, 2013. [23] Long- V an Nguyen-Dinh, Ulf Blanke, and Gerhard T röster . T owards scalable activity recognition: Adapting zero-eort crow dsourced acoustic models. In Proceedings of the 12th International Conference on Mobile and Ubiquitous Multimedia , page 18. ACM, 2013. [24] Jort F Gemmeke, Daniel PW Ellis, Dylan Free dman, Aren Jansen, W ade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter . Audio set: An ontology and human-labeled dataset for audio events. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on , pages 776–780. IEEE, 2017. [25] Derek Hao Hu, Vincent W enchen Zheng, and Qiang Yang. Cross-domain activity recognition via transfer learning. Pervasive and Mobile Computing , 7(3):344–358, 2011. [26] Ethan Fast, William McGrath, Pranav Rajpurkar, and Michael S Bernstein. Augur: Mining human behaviors from ction to power interactive systems. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems , pages 237–247. ACM, 2016. [27] Y usuf A ytar , Carl V ondrick, and Antonio Torralba. Soundnet: Learning sound representations from unlabele d video. In Advances in Neural Information Processing Systems , pages 892–900, 2016. [28] Gierad Laput, Karan Ahuja, Mayank Goel, and Chris Harrison. Ubicoustics: Plug-and-play acoustic activity recognition. In The 31st Annual ACM Symposium on User Interface Software and T echnology , pages 213–224. ACM, 2018. [29] Shawn Hershey , Sourish Chaudhuri, Daniel PW Ellis, Jort F Gemmeke, Aren Jansen, R Channing Moore, Manoj Plakal, Devin Platt, Rif A Saurous, Bryan Seybold, et al. Cnn architectures for large-scale audio classication. In A coustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on , pages 131–135. IEEE, 2017. [30] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citr o, Greg S. Corrado, Andy Davis, Jerey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow , Andrew Harp, Georey Irving, Michael Isard, Y angqing Jia, Rafal Jozefowicz, Lukasz Kaiser , Manjunath Kudlur , Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray , Chris Olah, Mike Schuster , Jonathon Shlens, Benoit Steiner , Ilya Sutskever , Kunal Talwar , Paul Tucker , Vincent V anhoucke, Vijay V asudevan, Fernanda Viégas, Oriol Vinyals, Pete W arden, Martin W attenberg, Martin Wicke, Y uan Yu, and Xiaoqiang Zheng. T ensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorow .org. [31] Qiuqiang Kong, Y ong Xu, W enwu W ang, and Mark D Plumbley . Audio set classication with attention model: A probabilistic perspective. arXiv preprint arXiv:1711.00927 , 2017. [32] Alexander Liu, Joydeep Ghosh, and Cheryl E Martin. Generative oversampling for mining imbalanced datasets. In DMIN , pages 66–72, 2007. [33] Nitesh V Chawla, Kevin W Bowyer , Lawrence O Hall, and W Philip Kegelmeyer . Smote: synthetic minority over-sampling technique. Journal of articial intelligence research , 16:321–357, 2002. [34] Hui Han, W en-Y uan Wang, and Bing-Huan Mao. Borderline-smote: a new over-sampling method in imbalance d data sets learning. In International Conference on Intelligent Computing , pages 878–887. Springer , 2005. [35] Guillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research , 18(17):1–5, 2017. 17 [36] François Chollet et al. Keras. https://keras.io, 2015. [37] F. Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer , R. W eiss, V . Dubourg, J. V anderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay . Scikit-learn: Machine learning in Python. Journal of Machine Learning Research , 12:2825–2830, 2011. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment