GraphCage: Cache Aware Graph Processing on GPUs
Efficient Graph processing is challenging because of the irregularity of graph algorithms. Using GPUs to accelerate irregular graph algorithms is even more difficult to be efficient, since GPU’s highly structured SIMT architecture is not a natural fit for irregular applications. With lots of previous efforts spent on subtly mapping graph algorithms onto the GPU, the performance of graph processing on GPUs is still highly memory-latency bound, leading to low utilization of compute resources. Random memory accesses generated by the sparse graph data structure are the major causes of this significant memory access latency. Simply applying the conventional cache blocking technique proposed for matrix computation have limited benefit due to the significant overhead on the GPU. We propose GraphCage, a cache centric optimization framework for highly efficient graph processing on GPUs. We first present a throughput-oriented cache blocking scheme (TOCAB) in both push and pull directions. Comparing with conventional cache blocking which suffers repeated accesses when processing large graphs on GPUs, TOCAB is specifically optimized for the GPU architecture to reduce this overhead and improve memory access efficiency. To integrate our scheme into state-of-the-art implementations without significant overhead, we coordinate TOCAB with load balancing strategies by considering the sparsity of subgraphs. To enable cache blocking for traversal-based algorithms, we consider the benefit and overhead in different iterations with different working set sizes, and apply TOCAB for topology-driven kernels in pull direction. Evaluation shows that GraphCage can improve performance by 2 ~ 4x compared to hand optimized implementations and state-of-the-art frameworks (e.g. CuSha and Gunrock), with less memory consumption than CuSha.
💡 Research Summary
GraphCage addresses the long‑standing performance bottleneck of memory‑latency bound graph processing on GPUs by introducing a cache‑centric optimization framework that explicitly leverages the GPU’s last‑level cache (LLC). The authors first observe that existing GPU graph frameworks such as Gunrock and CuSha focus heavily on work‑efficiency, load‑balancing, and synchronization, yet they leave data locality largely untouched. CuSha’s shard‑based approach uses shared memory to achieve cache locality, but its reliance on a COO‑like representation inflates memory consumption and the small shared‑memory size forces the creation of many sub‑graphs, incurring substantial merging overhead.
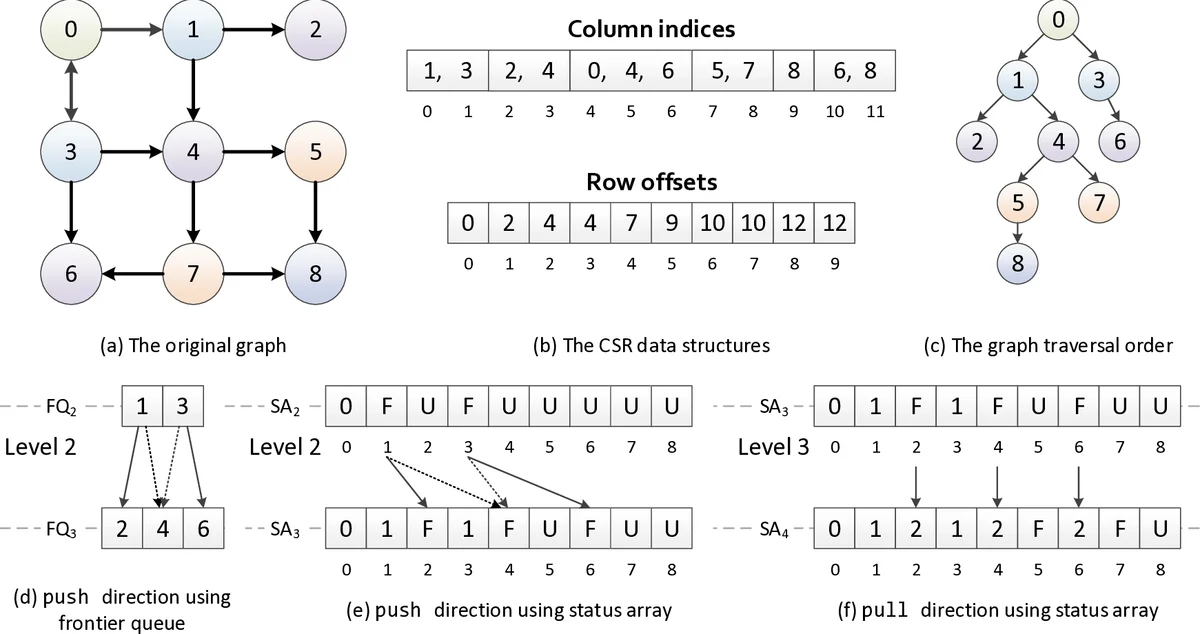
To overcome these limitations, GraphCage proposes the Throughput‑Oriented Cache Blocking (TOCAB) scheme. TOCAB statically partitions the input graph into blocks sized to fit the LLC, replacing sparse global‑sum accesses with dense accesses to partial sums stored in per‑block buffers. This transformation reduces random DRAM accesses and improves memory‑access throughput. Crucially, TOCAB is designed for both push and pull execution directions. In the pull direction, which is naturally atomic‑free, TOCAB enables topology‑driven kernels to benefit from cache locality without incurring synchronization costs. In the push direction, the scheme still reduces the number of irregular accesses by aggregating contributions locally before a final global update.
The framework also integrates TOCAB with sophisticated load‑balancing strategies that consider sub‑graph sparsity. By dynamically assigning work at the warp, block, or grid level (building on prior VWC, TWC, and Enterprise techniques), GraphCage mitigates the severe degree‑skew typical of scale‑free graphs. For traversal‑based algorithms (e.g., BFS, Betweenness Centrality), the authors analyze the evolving size of the active frontier and enable cache blocking only when the working set is large enough to amortize the blocking overhead, applying it primarily to topology‑driven kernels in the pull phase.
Implementation details reveal that GraphCage retains the CSR representation, thereby saving memory compared with CuSha’s COO‑like format. The authors integrate TOCAB into the Gunrock code base with minimal invasive changes, demonstrating that the approach can be adopted by existing frameworks without a complete redesign.
Experimental evaluation on a modern NVIDIA V100 GPU across a suite of real‑world graphs (road networks, social graphs, web graphs) and algorithms (PageRank, BFS, Single‑Source Shortest Path, Betweenness Centrality) shows substantial gains. GraphCage achieves 2–4× speedup over hand‑optimized baselines and state‑of‑the‑art frameworks, while consuming less memory than CuSha. Profiling indicates a marked increase in LLC hit rates and a corresponding reduction in DRAM traffic, confirming that the cache‑blocking strategy successfully improves temporal and spatial locality.
The paper acknowledges limitations: static block size selection can be sub‑optimal for highly irregular graphs, and the overhead of cache blocking may outweigh benefits during early BFS iterations when the active frontier is tiny. Moreover, the current work targets a single‑GPU environment; extending the approach to multi‑GPU systems and exploring adaptive block sizing are identified as future research directions.
In summary, GraphCage demonstrates that a carefully crafted cache‑blocking scheme, when combined with direction‑aware execution and load‑balancing, can unlock the latent performance potential of modern GPUs for irregular graph workloads, establishing a new design paradigm for GPU‑centric graph processing.
Comments & Academic Discussion
Loading comments...
Leave a Comment