Apache Hive: From MapReduce to Enterprise-grade Big Data Warehousing
Apache Hive is an open-source relational database system for analytic big-data workloads. In this paper we describe the key innovations on the journey from batch tool to fully fledged enterprise data warehousing system. We present a hybrid architecture that combines traditional MPP techniques with more recent big data and cloud concepts to achieve the scale and performance required by today’s analytic applications. We explore the system by detailing enhancements along four main axis: Transactions, optimizer, runtime, and federation. We then provide experimental results to demonstrate the performance of the system for typical workloads and conclude with a look at the community roadmap.
💡 Research Summary
Apache Hive began as a SQL‑like front‑end for Hadoop MapReduce, primarily targeting ETL and batch reporting workloads. Over the past decade, the Hadoop ecosystem evolved with YARN, Spark, Flink, and other execution engines, creating demand for low‑latency, interactive analytics. Rather than building a new system from scratch, the Hive community chose to modernize the existing codebase, integrating mature data‑warehouse techniques while preserving its scalability on commodity hardware and cloud storage. The paper structures this evolution around four pillars: SQL and ACID support, query optimization, runtime improvements, and federation.
SQL and ACID support: Hive now implements a broad subset of ANSI‑SQL, including correlated subqueries, window functions, grouping sets, set operations, and integrity constraints. Table partitioning is expressed via the PARTITIONED BY clause, enabling partition pruning. ACID guarantees are provided through Snapshot Isolation. Each transaction receives a global TxnId; within a table, writes are identified by WriteId, FileId, and RowId. Inserts, updates, deletes, and merges are supported, with deletes represented as “tombstone” records in delta files. Data is stored in a base/delta layout: base directories hold stable snapshots, while delta directories capture incremental inserts or deletes. Periodic compaction (minor and major) merges delta files and reduces file‑system overhead without requiring table locks, ensuring that readers see a consistent snapshot while writers continue.
Query optimization: Hive delegates its optimizer to Apache Calcite, gaining a cost‑based planner, rule‑based rewrites, and support for materialized view rewriting. Hive adds query re‑optimization, result caching, and hints for fine‑grained control. The optimizer works on a logical plan generated from the parsed SQL AST, applies Calcite rules, and produces a physical plan that may be vectorized for columnar execution.
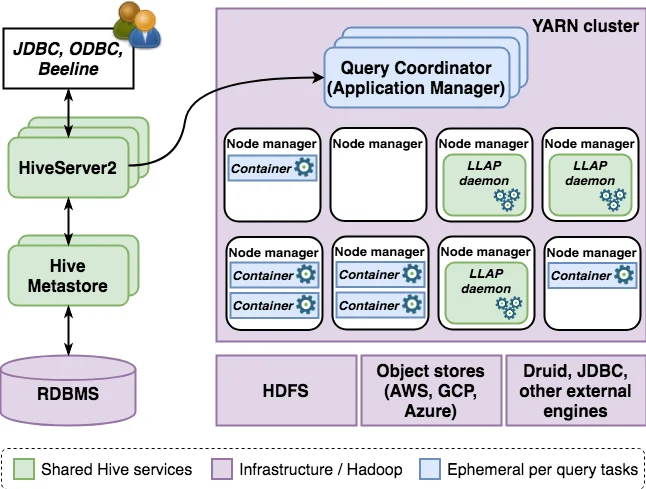
Runtime improvements: The original MapReduce engine, while reliable, suffered from high startup latency. Hive now defaults to Tez, a YARN‑compatible DAG engine that models jobs as vertices and edges, offering fine‑grained parallelism and better resource utilization. On top of Tez, Hive introduces LLAP (Long‑Lived and Process) – a pool of persistent executors that cache data in memory, avoid container launch overhead, and enable vectorized processing. Together, Tez and LLAP dramatically reduce query latency, making Hive suitable for interactive BI workloads.
Federation: By leveraging Calcite’s storage‑handler plug‑in architecture, Hive can push down predicates and aggregations to external systems such as Druid, HBase, and cloud object stores (S3, Azure Blob). This “single‑SQL‑layer” approach allows users to query heterogeneous data sources transparently while benefiting from Hive’s optimizer and ACID semantics where applicable.
Experimental evaluation: Using TPC‑DS, TPC‑HB, and mixed workloads, the authors demonstrate that Hive on Tez + LLAP outperforms the classic Hive‑MapReduce implementation by 5–10× in throughput and achieves sub‑second latency for many interactive queries. ACID transaction processing scales with concurrent users, and compaction overhead remains modest.
Impact and roadmap: The paper argues that Hive now competes with traditional MPP warehouses on functionality, performance, and scalability. Future work includes multi‑statement transactions, automated compaction scheduling, richer cost models, AI‑driven query tuning, Kubernetes‑native deployment, and tighter integration with streaming sources.
In conclusion, the authors present a comprehensive picture of how Hive transformed from a batch‑oriented MapReduce tool into a full‑featured, enterprise‑grade data warehousing platform, combining robust ACID guarantees, advanced optimization, low‑latency execution, and seamless federation across diverse data stores.
Comments & Academic Discussion
Loading comments...
Leave a Comment