A Linear Time Algorithm for Seeds Computation
A seed in a word is a relaxed version of a period in which the occurrences of the repeating subword may overlap. We show a linear-time algorithm computing a linear-size representation of all the seeds of a word (the number of seeds might be quadratic…
Authors: Tomasz Kociumaka, Marcin Kubica, Jakub Radoszewski
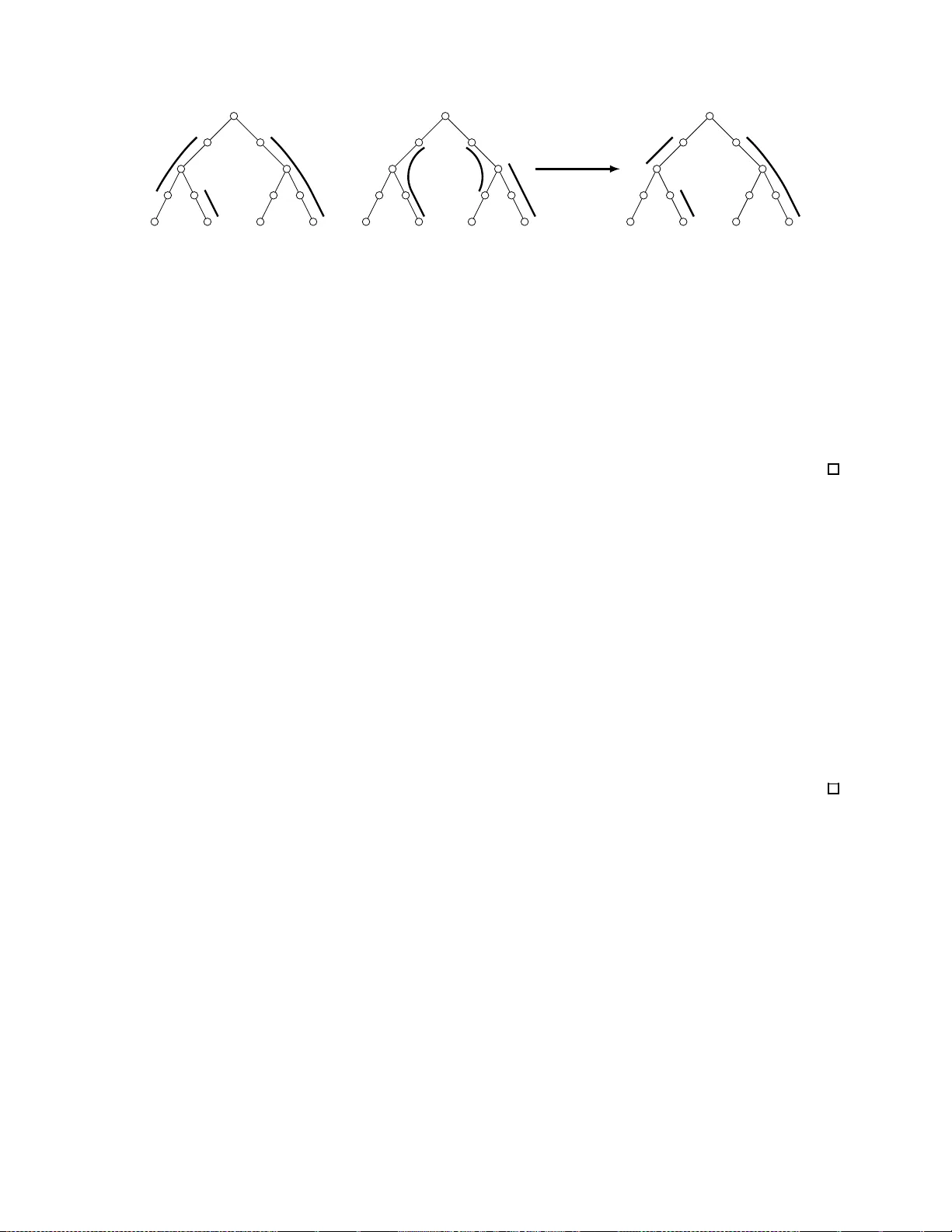
A Linear Time Algorithm for Seeds Computatio n T omasz Ko ciumak a 1,2 , Marcin Kubica 1 , Jakub Radoszewski 1 , W o jciec h Rytter 1 , and T omasz W ale ´ n 1 1 Institute of Informatics, U niversit y of W arsaw, P ola nd, [kociu maka, kubica,jrad,rytter,walen]@mimuw.edu.pl 2 Department of Computer Science, Bar-Ilan University , Ramat Ga n, Isr ael Abstract A seed in a word is a relaxed version of a p erio d in which the o ccurrences of the rep eating subw ord ma y o verl ap. W e sho w a linea r-time algorithm computing a linear-size representation of all th e seeds of a w ord (the num b er of seeds migh t b e qu ad ratic). I n p articular, one can easily derive the shortest seed and the num b er of seeds from our representation. Th us, w e solve an op en problem stated in the s urvey by Smyth (2000) and improv e up on a previous O ( n log n ) algorithm by Iliop oulos, Moore, and P ark (1996). Our app roac h is based on combinatorial relations b etw een seeds and subw ord complexity (u sed here for the first time in con text of seeds). In the previous pap ers, the compact representation of seeds consisted of tw o in d ep endent parts op erating on the suffix tree of the w ord an d the suffix t ree of the reverse of the w ord, resp ectively . Our second contribution is a simpler representation of all seeds whic h av oids dealing with t he reversed word. A preliminary versio n of this work, with a muc h more complex algo rithm constru ct ing the earlier representa tion of seeds, w as presented a t the 23rd Annual ACM-SIAM Symp osium of Discrete Algorithms (SODA 2012). 1 In tro duction The notion of p er io dicity in words is widely used in many fields, such as com binato rics on words, pattern matching, data compression, automata theory , formal languag e t heory , molecular biology etc. (see [35]). The concept of quasip erio dicity , introduced by Apostolico and Ehrenfeuch t in [5], is a genera lization of t he notion of p erio dicity: A quasip erio dic word is entirely cov ere d by o ccurrences of ano ther (shorter) word, called the quasip erio d or the c over . The o ccurr ences o f the quas iper io d may overlap, while in a p erio dic r ep etition the o ccurrences of the p erio d do not overlap. Hence, q uasip erio dicity enables detecting repetitive str ucture of words which canno t b e fo und using the cla ssic characteriza tions in terms of p erio ds. An extension of the notion of a cov er is the notion of a se e d : a cov er whic h is not necessarily aligned with the ends of the word b eing cov er ed, but is a llow ed to ov erflow on either s ide; s ee Fig. 1. More formally , a word v is a se e d of w if v is a sub word o f w and w is a subw or d o f so me word u cov ered by v . Seeds were first in tro duced a nd studied b y Iliop oulo s, Mo ore, and Park [26 ]. The original motiv ation for cov e rs a nd se eds comes fr om DNA sequence analysis (the sea rch for reg ularities and commo n fea tures in a a a a a a a a a a a a b b b b b b a a a a a a a a a a a a b b b b b b Figure 1: The word aba (ab ov e) is the shor test seed o f the word w = a abaaba baaba baabaa . Another seed of w is abaa b (b elow). Two of its “ov erhanging” o ccurrences co rresp ond to bo undary subw ords aab and a baa . In tota l, the word w has 35 distinct see ds, but do es no t hav e a non- trivial cov er. 1 DNA s equences). Due to natural applications in molecula r biolo gy (a hybridization approa ch to analysis o f a DNA se quence), b oth c ov ers a nd see ds hav e also b een extended in the s ense tha t a num b er of factors are considered instea d o f a single word [2 8]. This way , the notions o f k -covers [12, 25], λ -cov er s [24], and λ -seeds [22] w er e in tro duced. In applications such as molecular biology and computer-assisted music a nalysis, finding exact r epetitions is not a lw ays s ufficient ; the sa me problem o ccur s for quas iper io dic rep etitions. T his led to the introductio n of the notions of approximate co vers and seeds [2, 3, 4, 40, 10], partial covers and seeds [18, 3 2, 31], a nd a pproximate λ -covers [23]. Previous results . Iliop oulos, Mo ore, and Park [26 ] g av e a n O ( n log n )-time algorithm co mputing a linear representation of all the seeds of a given word. F or the next 15 y ears, no o ( n log n )-time algorithm was kno wn for this problem. Smyth formulated computing all the se eds of a word in linear time as an op en problem in his surv ey [41]. Berkman et a l. [7] gave a paralle l algo rithm co mputing all the seeds in O (log n ) time and O ( n 1+ ε ) space (for any po sitive ε ) using n pro c essors in the CRCW P RAM mo del. Much la ter, Christou et al. [1 1] prop osed an alterna tive seque n tial O ( n lo g n )-time algor ithm for computing the shortest s eed. In con tra st, a linear-time a lgorithm finding the sho rtest co ver of a word w as giv en b y Apos tolico et al. [6] and la ter on impr ov ed into an on-line algo rithm by Br eslauer [8]. Mo ore and Smyth [37, 38] prop osed a linear-time alg orithm computing a ll the covers of a w or d, wherea s Li and Smyth [34] afterw a rds developed an on-line algor ithm for the problem of representing a ll cov ers o f all prefixes of a word. Another line of resea rch is finding maximal quasip erio dic subw ords of a word. This notion r esembles maximal r ep etitions (runs) in a word [33], which is ano ther widely studied notio n of combinatorics on words. Two O ( n log n )-time a lgorithms for r ep orting all ma ximal qua sipe rio dic subw or ds of a word of length n have bee n proposed b y Broda l and Pedersen [9] and Iliop oulos a nd Mouchard [27]; these results improv ed upo n the initial O ( n log 2 n )-time a lgorithm by Ap ostolico and Ehrenfeuch t [5]. Our res ult. W e pr esent a linea r-time algor ithm computing the set Seeds ( w ) o f a ll seeds o f a given w ord w . As illustrated in Example 1.1, the num b er of seeds can be quadra tic in the length | w | (contrary to the n umber of covers, which is alw ays linear). Consequently , our algorithm returns a linear-size p ackage r epr esent ation of the set Seeds ( w ), which allows finding a shortest seed and the num b er of all seeds in a very s imple wa y . Example 1.1 . The following word of length 4 m + 3 co n tains Θ( m 2 ) different seeds : w = a m ba m ba m ba m . Those se eds are a i ba j with i + j ≥ m and 0 ≤ i, j ≤ m . Our pr o cedure assumes tha t the alpha bet Σ of the input word w consists of integers that ar e p oly nomial in ter ms of the leng th n of w . P ac k age Represen tation of Seeds. F or a word w , b y w [ i . . j ] we denote the s ub word w [ i ] · · · w [ j ]. W e int ro duce pac k a ges which are collections of consecutive prefixes of a sub word of w . More formally , for positive int egers i ≤ j 1 ≤ j 2 , we define a p ackage : pack ( i, j 1 , j 2 ) = { w [ i . . j ] : j 1 ≤ j ≤ j 2 } . If L is a set of tr iples of integers, then we denote: P ACK ( L ) = [ ( i,j 1 ,j 2 ) ∈L pack ( i, j 1 , j 2 ) . The output of our a lgorithm, calle d the p ackage r epr esentation of the set Seeds ( w ), co nsists of a set L of int eger triples such th at Seeds ( w ) = P ACK ( L ) and all the pac k ages in the representation are pairwise disjoint. (In other words, each see d b elong s to ex actly one pack age). fast-seeds 2019-03-15 02:02 2 a b a b a a b b a b a a b a a b a b a a b a a b b a a b a a b pack age o f seeds pack (1 , 8 , 10) a b a Figure 2: Pac k a ges from Example 1.2 illustrated as paths (in b old) in the uncompres sed suffix trie (that is, the trie of all the suffixes) of w = aba baabaa b . Example 1.2 . F or a word w = a babaab aab , a pack age r epresentation o f the set Seeds ( w ) is L = { (1 , 3 , 3) , (2 , 9 , 10) , (1 , 8 , 1 0) , (3 , 10 , 10) , (3 , 7 , 8) , (4 , 8 , 8) } . It co rresp onds to the following set P ACK ( L ) o f all see ds o f w : ababaa ba babaab aa ababaa baa abaab aba babaab aab ababa abaab abaaba ab abaaba baaba pack (1 , 3 , 3) pack (2 , 9 , 10) pack (1 , 8 , 10 ) pack (3 , 10 , 10 ) pack (3 , 7 , 8) pack (4 , 8 , 8) This c ollection of pack ages is also illustrated in Fig. 2 as a set of disjoint paths in the suffix trie of w . Previous Compact Represe n tation of Seeds . The original linear-size representation of see ds b y Il- iop oulos, Mo or e, and Park [26], als o employed in the pr eliminary version of our work [30], requires partition- ing the set Seeds ( w ) int o tw o disjoint s ubsets: Type- A seeds a re represe n ted a s paths in the suffix trie of w , while (the reversals o f ) type-B seeds admit a similar representation in the suffix trie of the reversed word w R . F or b oth t yp es, the num b er o f re po rted paths is s hown to b e linear using a simple argument: ea ch path can be uniquely extended to an edge of the cor resp onding suffix tree (repre sentin g s ub words of w whose o ccurrences s tart at the sa me p ositio ns). R emark 1.3 . E xample 1.2 illustr ated in F ig. 2 sho ws that this argument fails if we try to use it for repre sentin g all seeds (rather than just type-A seeds) o n the suffix tree of w : abaaba and abaa baab are both seeds of w = ababaa baab with the only occurr ences star ting at position 3, yet they cannot b e re po rted o n a single path b eca use aba abaa is not a seed of w . Structure of the P ap er. W e star t with a preliminar y Se ction 2, where w e r ecall several classic notions , relate pac k ages to suffix trees, and pro vide equiv ale n t formal definitions of seeds. Next, in Section 3, w e prove that seeds admit a pack age re presentation of linear size. Some of the underlying arguments ar e s tated in an algorithmic w ay so that they can be used in the subsequent Sectio n 4 as subroutines of a pr o cedure efficien tly computing s eeds of length Θ( n ). In Sectio n 5, w e provide the nov el relation b etw e en seeds and subw o rd fast-seeds 2019-03-15 02:02 3 complexity , which is the key com binatorial con tr ibution behind our main recurs ive algorithm describ ed in Section 6. The implemen tation of an auxiliary op eration on pac k age representations (applied to merge the results o f rec ursive calls) is de ferred to Section 7. Our T ec hniques. O ur linear -time solution relies o n several combinatorial and alg orithmic to ols. Compact repr e sentation of seeds: Despite its quadr atic size and the failure of the na ive a rgument (Re- mark 1.3), the set Seeds ( w ) alwa y s admits a pack age repr esentation of linear size (Section 3). While this fact is not essential for our alg orithm (see [30]), it makes our res ults muc h simpler a nd clea ner. Combinatorial prop erties of seeds : The co nnection b etw een se eds and subw ord complexity gives an efficien t reduction to a set of recurs ive calls o f total size decreased by a c onstant facto r (see Sections 5 and 6). Int erpretation o f pac k ages a s paths on the suffix trie: Pack a ges naturally corres po nd to paths in the (un- compacted) suffix trie, which ca n b e easily stored using the (compacted) suffix tr ee. W e use this int erpretation b oth to derive the com bina torial upp er b o und on the pac k a ge repr esentation size (Sec- tion 3) and in the algor ithmic construction of the pack a ge represent ation of long seeds (Section 4). The new linear-time offline algo rithm ans w ering W eighted Ancestor Queries (Section 7.1) lets us efficiently map pack ages on the suffix tree. Efficient ma nipula tion of pa ck a ge repres ent ations: P ack age representations pro vide a convenien t wa y of int erpreting the results of re cursive calls (seeds of ce rtain subw ords) as families o f sub words of the whole word w . This a llows for a simple linea r-time pro cedure agg regating the results of the recursive calls (Section 7). 2 Preliminaries W e co nsider wor ds ov er a poly nomially b ounded integer alphab et Σ. F or a word w , by | w | we denote its length and by w [ i ], for 1 ≤ i ≤ | w | , we denote its i th letter. By A lph ( w ) w e denote the set o f letters o ccurring in w . F o r 1 ≤ i ≤ j ≤ | w | , a word u = w [ i ] · · · w [ j ] is called a subwor d o f w . W e also say that w is a sup erst r ing of u . In this ca se, by w [ i . . j ] we deno te the o ccurr ence of u a t p osition i , called a fr agment of w . The s et of po sitions where u o ccurs in w is denoted by O c c ( u , w ) (or Oc c ( u ) if w is clear from the context). A fragment of w other tha n the whole word w is called a pr op er fragment of w . A fragmen t star ting at po sition 1 is called a pr efix of w and a fragment ending at p os ition | w | is c alled a su ffix o f w ; w e also say that the cor resp onding subw o rd is a prefix or suffix of w , resp ectively . A b or der of w is a subw o rd of w which o ccurs both as a prefix and as a suffix of w . An in tege r p , 1 ≤ p ≤ n , is a p erio d of a word w if w [ i ] = w [ i + p ] for 1 ≤ i ≤ | w | − p . It is w ell k nown that p is a p erio d of w if and only if w has a b order of leng th | w | − p ; s ee [13, 14]. Moreover, Fine and Wilf ’s Periodic it y L emma [17] asserts that if a word w has p er io ds p and q such that p + q − gcd( p, q ) ≤ | w | , then w a lso has a per io d gcd( p, q ). Throughtout the paper, b y w we denote the w or d which seeds are to b e computed and by n w e denote its leng th. 2.1 T ries, Suffix T rees, and P ac k age Represen t ations A trie is a roo ted tree whose node s corresp ond to prefixes of w or ds in a giv en (finit e) family W . If ν is a no de, then the cor resp onding prefix v is called the value of the no de. The no de with v a lue v is called the lo cus of v . The parent-c hild relation in the trie is defined so that the roo t is the locus of the empty word, while the parent µ of a no de ν is the lo cus of the v alue of ν with the last character remov ed. This character is the lab el of the edge from µ a nd ν . In general, if µ is an ances tor of ν , then the la bel of the path from µ to ν is the concatenation of edge lab els o n the path. A tr ie of ithe set W co n taining all the suffixes of a word b abaad is shown in Fig. 3. fast-seeds 2019-03-15 02:02 4 A no de is br anching if it ha s at least tw o children a nd t erminal if its v a lue b elongs to W . A c omp acte d trie is obtained from the underlying trie b y dissolving all nodes except for the ro o t, br anching no des, and terminal no des. In other words, w e compress paths of non-ter minal vertices with single children, and thu s the num b er of remaining no des b ecomes b ounded by 2 | W | . W e r efer to all preserved no des of the trie as explicit (since they are sto red explicitly) and to the diss olved ones as implicit . If ν is the locus of a word v in an uncompacted tr ie, then the lo cus of v in the corr esp onding co mpacted trie is de fined as ( µ, d ), wher e µ is the lo west explicit des cendant of ν , and d is th e distanc e (in the uncompa cted trie ) from ν to µ . Note that µ = ν and d = 0 if ν is explicit. E dges of a compa cted trie cor resp ond to paths in the underlying tr ie and thus their lab els a re non-e mpt y words, typically sto red as references to fra gments of the words in W . The suffix trie of w ord w is the trie of a ll suffixes of w (see Fig. 3), with the locus w [ i . . n ] lab elled b y the p os ition i . Consequently , there is a natural bijection b etw een subw ords of w and no des of the suffix trie; we often use it to identify subw ords o f w with their lo ci in the suffix trie. The su ffix t r e e of w [4 2] is the compacted suffix trie of w . F or a word o f length n , it takes O ( n ) space and can b e constructed in O ( n ) time either directly [15] or from the s uffix arr ay o f w ; see [36, 29, 14, 13]. W e say that tw o subw ords u and v of w are e qu ivalent if Oc c ( u, w ) = Oc c ( v , w ). The equiv alence classes of this relation cor resp ond to edg es of the suffix tree of w , as shown in the following observ ation a nd Fig. 3; see [13]. Observ ation 2. 1. Each e quivale nc e class is of the form E = pack ( i, j 1 , j 2 ) for some p ositions i ≤ j 1 ≤ j 2 and c orr esp onds to the set of al l no des on an e dge of the su ffix tre e of w (ex cluding the topmost ex plicit n ote). Henc e, ther e ar e at most 2 | w | e quivale nc e classes. a b a d a d b a a d d a d b a a d equiv alence cla ss pack (2 , 3 , 6) equiv alence cla ss pack (1 , 3 , 6) Figure 3: The suffix trie o f the word babaad . The equiv a lence cla sses corres po nd to compacted edges (excluding their topmost nodes ). Two o f them are marked in the figure: { ab , aba , ab aa , abaad } = pack (2 , 3 , 6) and { ba b , baba , babaa , babaad } = pack (1 , 3 , 6). In Section 7, we heavily use the c onnections b etw een s uffix trees and pack age representation to develop the following aux iliary pro cedur e: Com bine ( R 1 , . . . , R k ) : Given pack age representations of s ets R 1 , . . . , R k of subw ords of a word w , compute a smalles t pack age representation of T k i =1 R i . Note that the Com bine operation is muc h more complicated than a s imple in tersection of s ets of in terv als. The following lemma is proved in Section 7. Lemma 2.2. F o r a wor d w of length n and s et s R 1 , . . . , R k of subwor ds of w , given in p ackage r epr esent ations of total size N , Combine ( R 1 , . . . , R k ) c an b e implemente d in O ( n + N ) time. The size of the r esu lting p ackage r epr esentation i s at most N . fast-seeds 2019-03-15 02:02 5 2.2 Seeds: F ormal Definition and Equiv alent Characterizations W e say that a fra gment w [ i . . j ] c overs a p osition k (or that the p os ition k lies within w [ i . . j ]) if i ≤ k ≤ j . A word v is a c over of w ord w if the o ccurr ences o f v cover all po sitions in w . A word v is a se e d of word w if it is a sub word o f w and a cover of a sup erstr ing of w . This definition immedia tely implies the follo wing observ ation. Observ ation 2.3. L et v b e a se e d of wor d w . If v o c cu rs in a subwor d w ′ of w , then v is a se e d of w ′ . Denote by Seeds I ( w ) the se t of all seeds of w with lengths in in ter v al I . W e als o denote Seeds ( w ) = Seeds [1 ..n ] ( w ), Seeds ≤ k ( w ) = Seeds [1 ..k ] ( w ), Seeds ≥ k ( w ) = Seeds [ k..n ] ( w ), and Seeds k ( w ) = Seeds [ k..k ] ( w ). A left-overhanging occ urrence o f v in w is a prefix of w that matches a prop er suffix o f v . Symmetrically , a right-overh anging o ccur rence of v in w is a suffix of w that matc hes a prop er pr efix of v . The length of the occurre nce is the length of the corresp onding prefix/suffix of w . In this con text, us ual o ccur rences a re sometimes called ful l , while a gener alize d o ccurrence is a full or an ov erhanging one. A more oper ational definition o f seeds can b e formulated in terms of genera lized o ccurrences a s follows; see Fig. 1. F act 2. 4 ( Alternativ e definitio n of se e ds). A subwor d v of wor d w is a se e d of w if and only if e ach p osition in w i s c over e d by a ful l, left-overha nging, or r ight-overhanging o c curr enc e of v in w . Pr o of. Supp ose that v is a seed of w , i.e., a cov er of a sup erstring xwy of w . F or each p osition in w , the corres po nding p ositio n in xwy is covered by a full o ccurrence of v in xw y , which becomes a generalized o ccurrence of v when restricted to w . Hence, gener alized o ccur rences of v in w co ver a ll p ositions of w . F or the con verse implication, we cons truct a super string xwy of w which has v a s a cover. F o r this, w e extend w so that the longest left-ov erha nging o ccurr ence of v and the lo ngest rig ht -ov er hanging o ccur rence of v be come full o ccurre nces. Shorter overhanging o ccur rences may b e destr oy ed, but they do not cov er any extra p ositions in w compared to the longest ones. Consequently , the frag ment w in xwy is covered by full o ccurrences of v . What is more, the prefix x is cov ered by the o ccurr ence of v as a prefix of xwy and the suffix y is cov ered by the o ccurr ence of v a s a suffix o f xwy . Th us, v is a cov er o f xwy and a seed of w . W e denote by SUB k ( w ) the set all subwords of length k of word w . Fa ct 2 .4 lets us show that the fa mily SUB 2 ℓ − 1 ( w ) of subw ords o f length 2 ℓ − 1 of a word w uniquely determines the length- ℓ see ds of w . Lemma 2.5. L et v b e a n on-empty wor d such that 2 | v | − 1 ≤ n . The fol lowing c ondi tions ar e e quivalent: (1) v is a se e d of w ; (2) v is a se e d of every su bwor d of w of length 2 | v | − 1 . Pr o of. (1) ⇒ (2). Each s ∈ SUB 2 | v | − 1 ( w ) occurs as w [ i − | v | + 1 . . i + | v | − 1 ] for s ome po sition i , | v | ≤ i ≤ n − | v | + 1. The p osition i can o nly b e covered b y a full o ccurrence of v con tained within this fragment, so v is a subw o rd of each s ∈ SUB 2 | v | − 1 ( w ). Due to O bserv ation 2.3, v is a lso a seed o f every s ∈ SUB 2 | v | − 1 ( w ). (2) ⇒ (1). Positions i satisfying | v | ≤ i ≤ n − | v | + 1 are covered by full o ccurr ences of v due to the fact that v o c curs in each sub w ord of w of length 2 | v | − 1 , including w [ i − | v | + 1 . . i + | v | − 1]. If some po sition i < | v | or i > n − | v | + 1 in w is not cov ered by a full o ccurr ence o f v , then it can be cov ered by a left-ov erha nging o cc urrence of v in w [1 . . 2 | v | − 1] o r a righ t-ov er hanging o ccurr ence of v in w [ n − 2 | v | + 2 . . n ], resp ectively . These ov erha nging o c currences ar e also pr esent in w . Corollary 2.6. F or e ach wor d w and inte ger k , 1 ≤ k ≤ n +1 2 , we have Seeds ≤ k ( w ) = \ u ∈ SUB 2 k − 1 ( w ) Seeds ≤ k ( u ) . Pr o of. Co nsider a le ngth ℓ not exceeding k . Note that SUB 2 ℓ − 1 ( w ) = S s ∈ SUB 2 k − 1 ( w ) SUB 2 ℓ − 1 ( s ) , so Lemma 2.5 yields Seeds ℓ ( w ) = \ u ∈ SUB 2 ℓ − 1 ( w ) Seeds ℓ ( u ) = \ s ∈ SUB 2 k − 1 ( w ) \ u ∈ SUB 2 ℓ − 1 ( s ) Seeds ℓ ( u ) = \ s ∈ SUB 2 k − 1 ( w ) Seeds ℓ ( s ) . The eq uality holds for e ach length ℓ ≤ k , which concludes the pro o f. fast-seeds 2019-03-15 02:02 6 3 Represen tation Theorem Let v be a subw or d o f a word w . Let us introduce a deco mpo sition w = v − · ˆ v · v + such that ˆ v is the lo ngest subw or d o f w ha ving v as a b or der. In other words, ˆ v = w [min Oc c ( v ) . . max Oc c ( v ) + | v | − 1] , i.e., ˆ v can be seen as the shortes t fragment of w con taining all full o ccur rences of v in w ; see Fig. 4. w v v + ˆ v v − Figure 4 : Generalized o ccurr ences of a seed v of w and the decomp osition o f w in to v − , ˆ v , and v + . Definition 3. 1 (see Fig. 5) . We say that v is a quasiseed of w if it is a c over of ˆ v . If v is a se e d of v − v , then v is c al le d a left candida te of w , and in c ase v is a se e d of v v + , then v is c al le d a right candidate . By QSeeds ( w ), LCands ( w ), a nd RCands ( w ) w e denote the sets of quasiseeds, left ca ndidates, a nd right candidates o f w , resp ectively . Lemma 3.2. Seeds ( w ) = LCands ( w ) ∩ QSeeds ( w ) ∩ R Cands ( w ) . Pr o of. W e apply the characterization of Fact 2.4. O bserve that there a re natural bijections b etw een full o ccurrences of v in w and in ˆ v , b etw een left-ov erha nging occur rences of v in w and in v − v , and b etw een right-o verhanging o ccurr ences of v in w and in v v + . Next, note that an y positio n of w within ˆ v c ov ered an o verhanging o ccur rence of v mu st b e located within the leading o r trailing | v | characters of ˆ v , so it is a lso cov er ed b y a full o c currence of v since v is a b or der of ˆ v . Thu s, v is a qua siseed of w if and only if the po sitions of w within ˆ v ar e cov er ed by gener alized o ccurrence s of v . Moreov er, obser ve that v o ccur s in v − v only a s a suffix, so the p ositions within the leading v − of v − v and of w can b e cov ere d b y left-ov erhanging o ccurr ences only . Cons equently , v is a left candidate if a nd o nly if the p ositions within the leading v − of w are cov e red by gener alized o ccur rences o f v . Symmetrica lly , v is a r ight c andidate if and only if the positions within the trailing v + are covered by gener alized o ccur rences of v . Combining these three facts, we co nclude that v is a seed of w if and only if it is simultaneously a quasiseed, a left candidate, and a right ca ndidate. Next, we shall characterize the quasiseeds and candidates in a computationally feasible way and b ound the size s of their pack age repre sentations. 3.1 Quasiseeds F or a s et X = { x 1 , . . . , x k } of in tegers, x 1 < · · · < x k , let us de fine the v alue maxgap ( X ) as: maxgap ( X ) = ( 0 if k ≤ 1 , max { x i +1 − x i : 1 ≤ i < k } if k ≥ 2 . F or example, maxgap ( { 1 , 3 , 8 , 13 , 17 } ) = 5. The following easy observ a tion relates this function to covers; see, e.g., [7]. fast-seeds 2019-03-15 02:02 7 a a a a a a a a a a a a b b b b b b a a a a a a a a a a a a b b b b b b Figure 5: The w or d aba baa is a quas iseed o f w = aab aabab aababa abaa , where as the w o rd b aab is both a left and a right ca ndidate of w . Neither of them is a seed of w , though. Observ ation 3.3. A subwor d v of wor d w is a qu asise e d of w if and only if maxgap ( Oc c ( v , w )) ≤ | v | . Corollary 3.4. F or e ach e quivalenc e class E , the qu asise e ds c ontaine d in E form a single p ackage. In other wor ds, QSeeds ( w ) ∩ E has a p ackage r epr esentation of size 1. Pr o of. Co nsider the shortest subw o rd v ∈ E ∩ QSeeds ( w ) and let u ∈ E satisfy | u | ≥ | v | . Due to Obser - v ation 3.3, maxgap ( Oc c ( u )) = maxgap ( O c c ( v )) ≤ | v | ≤ | u | , so u is a lso a quasis eed. This completes the pro of. 3.2 Left Candida tes The b or der table B [0 . . n ] stores at B [ i ] the length of the long est prop er b order of w [1 . . i ] (we assume B [0 ] = − 1). The following fact was already s hown implicitly in [11]; we give its pr o of for completeness. Lemma 3.5. A subwor d v of wor d w is a left c andidate of w if and only if B [ | v − v | ] ≥ | v − | . Pr o of. Reca ll that p os itions within the prefix v − of v − v can only b e covered b y left-overhanging occur rences of v . Consequently , if v is a seed of v − v , then ther e is a prefix o f v − v of length at least | v − | equal to a suffix of v . In other words, there is a prop er b order of v − v of leng th at least | v − | . F or a pro of o f the converse implicatio n, suppose that v − v has a prop er b order of length at least | v − | . Since v has only one o ccur rence in v − v , the bo rder m ust b e a pr op er suffix of v . Cons equently , v ha s a left-ov erha nging o ccur rence in v − v of length at least | v − | . This fragment cov ers all p o sitions in v − ; the remaining po sitions in v − v are triv ially covered by the o ccurrence of v as a suffix o f v − v . A cla ssic pr op erty of the b order table is that 0 ≤ B [ i ] ≤ B [ i − 1] + 1 holds for 1 ≤ i ≤ n . Fine and Wilf ’s Periodicity Le mma [17] lets us further characterize po sitions where the right inequa lit y is strict. Lemma 3.6. If B [ i ] ≤ B [ i − 1] holds for a p osition i of t he wor d w , then B [ i ] + B [ i − 1] < i − 1 . Pr o of. W e as sume B [ i ] > 0; otherwis e, the claim holds triv ially: B [ i ] + B [ i − 1] = B [ i − 1] < i − 1. Since w [1 . . i ] do es not hav e a bor der of length B [ i − 1 ] + 1, we must hav e w [ B [ i − 1] + 1] 6 = w [ i ] = w [ B [ i ]], so B [ i − 1] + 1 − B [ i ] is no t a p erio d of w [1 . . i − 1] despite the fact that b oth i − B [ i ] and i − 1 − B [ i − 1 ] are per io ds o f this prefix. By the Periodicity Lemma, this yields ( i − B [ i ]) + ( i − 1 − B [ i − 1]) − 1 > i − 1 , so B [ i ] + B [ i − 1] < i − 1 holds as claimed. Let v be a subw ord of w and let v = v ′ a where a ∈ Σ. W e say that v is a critic al left c andidate if it is a left candidate, but v ′ is not a left candidate (in particula r, v ′ can b e the empt y word) or min Oc c ( v ′ ) < min Oc c ( v ). Let Active ( w ) = { j ∈ [1 . . n ] : B [ j − 1] < B [ j ] ≤ j − 1 2 } . The following lemma is the main technical c ontribution in the characterization of left candidates. fast-seeds 2019-03-15 02:02 8 Lemma 3.7. A fr agment w [ i . . j ] is (a) the le ftmost o c curr enc e of a left c andidate if and only if i − 1 ≤ B [ j ] ≤ j − i ; (b) the lef tmost o c curr enc e o f a critic al left c andidate if and only i f i = B [ j ] + 1 and j ∈ Active ( w ) . Pr o of. (a) If w [ i . . j ] is the leftmost o ccur rence o f a left ca ndidate v , then w [1 . . j ] = v − v and B [ j ] ≥ | v − | = i − 1 by Lemma 3 .5. Mor eov er , B [ j ] < | v | = j − i + 1, b ecause w [ i − j + B [ j ] . . B [ j ]] would o therwise be an ear lier o ccurrence of v . These tw o conditions yield i − 1 ≤ B [ j ] ≤ j − i . Conv ers ely , assume that i − 1 ≤ B [ j ] ≤ j − i. (1) Suppo se for a pro of by contradiction that v = w [ i . . j ] ha s an earlier o ccur rence at p osition i ′ , i.e., w [ i ′ . . i ′ + j − i ] = w [ i . . j ] for some po sition i ′ < i . Let w ′ = w [ i ′ . . j ]. The word v is a b order of w ′ , so w ′ has a p erio d i − i ′ , which we denote by p 1 . The shortest per io d o f the whole pr efix w [1 . . j ], hence a p erio d of w ′ , is j − B [ j ], whic h we denote by p 2 . By the fir st inequality of (1) , p 1 + p 2 = i − i ′ + j − B [ j ] ≤ j − i ′ + 1 = | w ′ | . Hence, p 1 and p 2 satisfy the assumption of the Periodicity Lemma a nd w ′ has p erio d gcd ( p 1 , p 2 ), which we denote b y p . Moreov e r, by the second inequality of (1), p 1 = i − i ′ < i ≤ j − B [ j ] = p 2 , so p < p 2 and p divides p 2 . Conseq uent ly , w [1 . . j ] has p erio d p , which contradicts the fact that p 2 is its shortest p er io d. Therefore, w [ i . . j ] indeed is the leftmost o ccurrence o f v a nd v − v = w [1 . . j ]. Due to B [ j ] ≥ i − 1 = | v − | , we conclude that v is a left ca ndidate by Lemma 3 .5. (b) First, ass ume that B [ j − 1] < B [ j ] ≤ j − 1 2 and i = B [ j ] + 1 . Note that i − 1 = B [ j ] = 2 B [ j ] − B [ j ] ≤ j − 1 − B [ j ] = j − i . By par t (a), w [ i . . j ] is therefore the leftmost o ccurr ence of a left candidate. O n the other hand, B [ j − 1 ] < B [ j ] = i − 1, so w [ i . . j − 1] is no t the leftmost o ccurr ence of a le ft c andidate. Th us, w [ i . . j ] is the leftmost o ccurrence of a critical left candidate. Next, assume that w [ i . . j ] is the leftmost o cc urrence of a critical left candidate. Part (a) yields i − 1 ≤ B [ j ] ≤ j − i (since w [ i . . j ] is the leftmost o ccur rence of a left candidate) and that B [ j − 1] < i − 1 or B [ j − 1] ≥ j − i (since w [ i . . j − 1] is not). In the latter case, w e have B [ j − 1 ] + B [ j ] ≥ j − i + i − 1 = j − 1, s o B [ j ] = B [ j − 1] + 1 holds b y Lemma 3.6. This yields a contradiction: j − i ≥ B [ j ] = B [ j − 1 ] + 1 ≥ j − i + 1 . Thu s, the only p ossibility is that B [ j − 1] < i − 1, i.e., B [ j − 1] ≤ i − 2. W e then have B [ j ] ≤ B [ j − 1] + 1 ≤ i − 1 ≤ B [ j ] , so B [ j − 1] < B [ j ] = i − 1. F urthermore, B [ j ] = 1 2 ( B [ j ] + B [ j ]) ≤ 1 2 ( j − i + i − 1) = j − 1 2 holds as claimed. F or a ta ble A [0 . . n + 1 ], assuming A [ n + 1 ] = −∞ , define the n e ar est smal lest value table N A such that for 0 ≤ i ≤ n we hav e : N A [ i ] = min { j > i : A [ j ] < A [ i ] } . fast-seeds 2019-03-15 02:02 9 Lemma 3 . 8. Packages pack ( B [ j ] + 1 , j, N B [ j ] − 1) for j ∈ Active ( w ) form a p ackage r epr esentation of t he family of lef t c andidates of w . This r epr esent ation (of size at most n ) c an b e c ompute d in O ( n ) time. Pr o of. Firs t, we sha ll prov e that for each j ∈ Active ( w ), the fragments w [ B [ j ] + 1 . . k ] for j ≤ k ≤ N B [ j ] − 1 are leftmost o ccurr ences o f left candidates . T o apply the characterizatio n of Le mma 3 .7(a), we need to show that B [ j ] ≤ B [ k ] ≤ k − B [ j ] − 1. The first inequality follows direc tly from the definition of the N B table, while for the seco nd one, we observe that B [ j ] + B [ k ] ≤ 2 B [ j ] + k − j ≤ j − 1 + k − j = k − 1 holds due to B [ j ] ≤ j − 1 2 and the clas sic prop erty of the b order table. Consequently , the pa ck a ges are disjoint and consis t of left candida tes only . It r emains to pr ov e that we do not leav e any left candidate b ehind. Suppose that w [ i . . k ] is the leftmost o ccurrence of a left candida te. Rep eatedly trimming the trailing character, we can r each a critical left candidate whose leftmos t o c currence is w [ i . . j ] (f or j ≤ k ). B y Lemma 3.7(b), w e ha ve that j ∈ Active ( w ) and i = B [ j ] + 1. Howev er, s ince w [ i . . k ′ ] is the leftm ost occur rence of a left candidate for all j ≤ k ′ ≤ k , Lemma 3.7(a) yields B [ k ′ ] ≥ i − 1 = B [ j ] for j ≤ k ′ ≤ k . Co nsequently , N B [ j ] > k . Th us, w [ i . . k ] ∈ pack ( B [ j ] + 1 , j, N B [ j ] − 1) indeed b elong s to one o f the pack ages we crea ted. The size of the pack age represe n tation is | Active ( w ) | ≤ n . As for the O ( n )-time construction algo rithm, we first build the b or der table B [3 9, 13, 14] a nd its neares t sma llest v alue table N B (using a Ca rtesian tree construction alg orithm [19]). Then, for each p os ition j , we test in constant time whether j ∈ Active ( w ) and, if so , we r etrieve the co rresp onding pack age. 3.3 Righ t Candidates F or word w , let us define a r everse b or der arr ay B R [1 . . n ] such that B R [ i ] is the length o f the long est pro per bo rder o f w [ i . . n ]. Lemma 3.9. A subwor d v of a wor d w is a right c andidate of w if and only if B R [ n − | v v + | + 1] ≥ | v + | . Pr o of. F ollows from Lemma 3.5 b y the symmetry b etw een B and B R as w ell as left and righ t candidates. Even though Lemma 3 .9 for r ight candidates and Lemma 3.5 for left ca ndidates ar e symmetr ic, the former allows us to represe n t r ight ca ndidates on each edge of the suffix tree of w as a single pack age. Thu s a r epresentation for rig h t candidates is muc h s impler to b e computed than the r epresentation for left candidates. Lemma 3.10. The int erse ction of RCands ( w ) with a single e quivalenc e class forms at most one p ackage. Mor e over, a p ackage r epr esentation (of size at most 2 n ) of t he set RCan d s ( w ) c an b e c ompute d in O ( n ) time. Pr o of. Let us co nsider a n equiv alence class E of subw ords o f w , with P = Oc c ( v ) for v ∈ E , and denote ℓ ( E ) = n − max P + 1 − B R [max P ] . W e will s how that v ∈ E is a right candidate if and only if | v | ≥ ℓ ( E ). By Lemma 3 .9, v is a r ight candidate if and only if B R [ n − | v v + | + 1] ≥ | v + | . How ever, | v v + | = n − max P + 1 and | v + | = n − max P + 1 − | v | , so the tw o conditions are equiv alent. Let us s how how to co mpute RCands ( w ) ∩ E for ea ch equiv alence class E = pack ( i, j 1 , j 2 ). W e construct the arr ay B R [39, 13, 14] and the suffix tre e o f w . Mor eov er, for each e quiv alence clas s E , we deter mine the common v alue max( Oc c ( v )) for v ∈ E . This lets us compute ℓ ( E ). W e ha ve prov ed that the right candidates in E are precisely words in E of length ℓ ( E ) or more . If ℓ ( E ) > | w [ i . . j 2 ] | , ther e are no r ight candidates in E . Otherwis e, we output a pack age pack ( i, max( j 1 , i + ℓ ( E ) − 1) , j 2 ) . fast-seeds 2019-03-15 02:02 10 3.4 Represen tation Theorem for Seeds Theorem 3.11. F or a wor d w of length n , the set Seeds ( w ) has a p ackage r epr esentation of size at most 3 n . Pr o of. By Lemma 3.2, we hav e Se e d s ( w ) = LCa n ds ( w ) ∩ QSeeds ( w ) ∩ R Cands ( w ). First, w e shall prov e the pack age r epresentation of QSeeds ( w ) ∩ RCand s ( w ) consists of at most 2 n pack ages. Indeed, for each equiv alence class E , b oth QSeed s ( w ) ∩ E and RCands ( w ) ∩ E form at most one pack a ge. The intersection of tw o pa ck a ges fo rms at mos t one pack age, so QSeeds ( w ) ∩ RCand s ( w ) has a pack age representation with at most one pack age p er equiv alence cla ss, i.e., of to tal size at mo st 2 n . By Lemma 3.8, LCan d s ( w ) has a pa ck a ge representation of size at most n . Finally , Lemma 2.2 implies that Seeds ( w ) ha s a pack a ge repres en tation of size at most 3 n . 4 Computing Long Seeds In this section, we provide a linear-time alg orithm c omputing see ds of length Θ( n ). F ormally , we cons ider the following op er ation for ℓ = Ω( n ). LONG-SEEDS ( ℓ, w ) : Computes a pa ck a ge representation of Seeds ≥ ℓ ( w ). Let us denote b y QSeeds ≥ ℓ ( w ) the set of all quasiseeds of w with lengths at least ℓ . O ur implementation is based on Theorem 3.11, and it uses the suffix tree of w to determine QSeeds ≥ ℓ ( w ). Let us partition the p ositions of w into a family F of O ( n/ℓ ) dis join t blo cks of length at most ℓ each. F or a set of p os itions X , we define its refined version: refine ( X ) = [ Y ∈F : Y ∩ X 6 = ∅ { min( Y ∩ X ) , max( Y ∩ X ) } ; see Fig. 6. Note that | refine ( X ) | ≤ 2 |F | = O ( n/ℓ ) = O (1). 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Figure 6 : F or n = 30 and ℓ = 6, refine ( { 2 , 5 , 6 , 10 , 13 , 14 , 15 , 18 , 26 , 27 , 28 , 29 } ) = { 2 , 6 , 10 , 1 3 , 18 , 26 , 29 } . Lemma 4.1. A subwor d v of length at le ast ℓ is a quasise e d if and only if m a xgap ( refine ( Oc c ( v ))) ≤ | v | . Pr o of. Clea rly , refin e ( O c c ( v )) ⊆ Oc c ( v ), so maxgap ( refine ( Oc c ( v ))) ≥ maxga p ( Oc c ( v )). Due to O bserv a- tion 3.3, it rema ins to prov e that maxg ap ( refine ( Oc c ( v ))) > | v | yields maxgap ( Oc c ( v )) > | v | . Let i < i ′ be consecutive elements of refine ( Oc c ( v )) s uc h that i ′ − i > | v | . Since | v | ≥ ℓ , p os itions i and i ′ belo ng to different blo c ks of F . Moreov er , thes e p ositions ar e consecutive elements of refine ( O c c ( v )), so i must b e the largest in its blo ck, i ′ m ust b e the sma llest in its blo ck, and all blo cks in b etw een ca nnot contain an y element of O c c ( v ). Co nsequently , i < i ′ are consecutive elements of O c c ( v ), i.e., maxga p ( Oc c ( v )) > | v | . W e trav ers e the suffix tree of w bottom- up, computing refin e ( Oc c ( v )) in cons tant time for each subw o rd v whose lo cus is an e xplicit no de. F act 4.2. The s et s refine ( Oc c ( v )) fo r all explicit n o des v of the suffix tr e e c an b e c ompute d in O ( n ) time. Pr o of. W e compute r efine ( Oc c ( v )) for each e xplicit node v and store it as a s orted list. F or this, we start with an empty set and consider all explicit c hildr en u of v . F or each child, w e merge the curre n t list with refine ( Oc c ( u )), removing elements w hic h are not extremes in their blo cks. This tak es O ( |F | ) = O (1) time for ea c h edge of the suffix tr ee, which gives O ( n ) time in total. fast-seeds 2019-03-15 02:02 11 Lemma 4.3 ( LONG-SEEDS Imple men tation). F or a thr eshold ℓ = Θ( n ) and a wor d w of length n , LONG-SEEDS ( ℓ, w ) c an b e imp lemente d in O ( n ) time. Pr o of. Firs t, we c ompute a pack age representation of the family QSeeds ≥ ℓ ( w ) of long quasiseeds . Consider an equiv alence class E = p a ck ( i, j 1 , j 2 ). Let P b e the co mmon o ccur rence s et O c c ( v ) for v ∈ E . The longest subw ord in each pack age is repre sented b y an e xplicit no de, so the pro cedure of Fact 4.2 co mputes refi n e ( P ). Let us define ℓ ′ := max( ℓ, maxgap ( refine ( P ))). By Lemma 4.1, a subw or d v ∈ E is a long quasisee d if and only if | v | ≥ ℓ ′ . If j 2 − i + 1 < ℓ ′ , ther e are no such qua siseeds. Otherwise, w e rep or t a pa ck a ge E ∩ QSeeds ≥ ℓ ( w ) = pack ( i, max( j 1 , i + ℓ ′ − 1) , j 2 ) . Finally , we a pply Lemma 3.2 and compute Seeds ≥ ℓ ( w ) = QSeeds ≥ ℓ ( w ) ∩ LCands ( w ) ∩ RCands ( w ) using Lemma 2.2 to implemen t the in tersectio n. Linear-size pac k ag e re presentations of left candida tes and rig h t candidates a re co nstructed using Lemmas 3.8 and 3 .10, r esp ectively . The total running time is O ( n ). W e also use the fo llowing o pe ration that can be computed using LONG-SEE DS. INT-SEEDS ( I , w ) : Computes a pack age representation of Seeds I ( w ). Our implementation of INT-SEEDS( I , w ) uses a r eduction to Lemmas 2.2 and 4 .3, and its running time is linear provided that I is b alanc e d , i.e., if the ra tio of its endpo int s in b ounded by a co nstant. Lemma 4.4 ( INT-SEE DS Implementa tion). F or an interval I = [ ℓ . . r ] and a wor d w of length n , INT-SEEDS ( I , w ) c an b e implemente d in O ( n ) time if r = O ( ℓ ) . Pr o of. W e construct a family R of fr agments of length 4 r cov ering w with overlaps of size 2( r − 1) (the last fragment might b e sho rter). Note that the to tal leng th of these frag ment s is a t most 2 n . F urther more, observe tha t SUB 2 r − 1 ( w ) = S s ∈ R SUB 2 r − 1 ( s ), so Coro llary 2.6 yields Seeds ≤ r ( w ) = \ u ∈ SUB 2 r − 1 ( w ) Seeds ≤ r ( u ) = \ s ∈ R \ u ∈ SUB 2 r − 1 ( s ) Seeds ≤ r ( u ) = \ s ∈ R Seeds ≤ r ( s ) . In particular, Seeds I ( w ) = T s ∈ R Seeds I ( s ). F or eac h s ∈ R , we apply Lemma 4.3 to determine a pack age representation of Seeds ≥ ℓ ( s ), and w e filter out se eds of length greater than r . This takes O ( | s | ) time for each s ∈ R , whic h is O ( n ) in total. Finally , we combine the pa ck a ge repre sentations in O ( n ) time using Lemma 2.2. 5 Relation b et w een Seeds, Compression and Subw ord Complexit y The subwor d c omplexity o f a word w is a fun ction which gives the num b er of subw o rds of a g iven length k , i.e., | SUB k ( w ) | . Since | SUB k ( w ) | is not mo notone in gener al, w e define a non- decreasing sequence ( β k ) n k =1 with β k ( w ) = | SUB k ( w ) | + k − 1; see Fig. 7. k 1 2 3 4 5 6 7 8 w [ k ] a b a b a a b b | SUB k ( w ) | 2 4 5 5 4 3 2 1 β k ( w ) 2 5 7 8 8 8 8 8 Figure 7 : Subw o rd complexity o f w and β k ( w ) for w = a babaab b . A co nnection b etw e en the s ub word c omplexity and the existence of seeds of certain lengths is crucial in the pap er . More precisely , ea ch seed provides a n upp er bo und o n the v alues β k ( w ). fast-seeds 2019-03-15 02:02 12 a b a b a b a c a c a c a c a c c b a a c b b c b c a b a d 1 5 10 15 20 25 30 Figure 8: COMPR 2 ( w ) = { w [1 . . 3] , w [7 . . 9] , w [16 . . 20] , w [22 . . 24] , w [29 . . 30] } = { aba , aca , ccbaa , bbc , ad } . W e ha ve SUB 2 ( aba ) ∪ SUB 2 ( aca ) ∪ SUB 2 ( ccbaa ) ∪ SUB 2 ( bbc ) ∪ SUB 2 ( ad ) = { ab , ba } ∪ { ac , ca } ∪ { cc , cb , b a , aa } ∪ { bb , bc } ∪ { ad } = SUB 2 ( w ) . Lemma 5.1 ( Gap Lemma). If β k ( w ) > 2 3 n , then w has no se e d v whose length satisfies 2 k − 2 ≤ | v | ≤ 1 6 n . Pr o of. W e shall prov e that if v is a see d of w , then β k ( w ) ≤ | v | + ( k − 1) n | v | . Note that we may a ssume | v | ≥ k ; otherwise, the righ t-ha nd side is at least n . Consider length- k fra gments starting a t p o sitions i , . . . , i + ℓ , where ℓ < | v | . W e claim that at most k − 1 of these fragments are not cov er ed by single o ccur rences of v . Let w [ i ′ . . i ′ + k − 1], for i ≤ i ′ ≤ i + ℓ , be the first such frag men t that is not c ov ered by any single o ccurrence of v . If i ′ do es not exist or i ′ + k − 1 > i + ℓ , we are do ne. Other wise, the o ccurre nce of v covering p os ition i ′ + k − 1 must s tart at some p osition j , i ′ < j < i ′ + k . Conse quent ly , the length- k fragments star ting at p ositio ns i ′′ , j ≤ i ′′ ≤ j + | v | − k , ar e all cov ered by this o cc urrence o f v . W e a re left with at most k − 1 remaining length- k fr agments (starting at p ositio ns i ′′ such that i ′ ≤ i ′′ < j or j + | v | − k < i ′′ ≤ i + ℓ ). Thu s, at most ( k − 1) n −| v | +1 | v | length- k fragments o f w a re no t covered by sing le o ccur rences of v . As a result, | SUB k ( w ) \ SUB k ( v ) | ≤ ( k − 1) n −| v | +1 | v | , a nd we o btain the claimed the upp er b ound on β k ( w ): β k ( w ) = k − 1 + | SUB k ( w ) | = k − 1 + | SUB k ( v ) | + | SUB k ( w ) \ SUB k ( v ) | ≤ | v | + ( k − 1) l n −| v | +1 | v | m ≤ | v | + ( k − 1) n | v | . If 2 k − 2 ≤ | v | ≤ 1 6 n , then we conclude that β k ( w ) ≤ | v | + ( k − 1) n | v | ≤ 1 6 n + 1 2 n = 2 3 n, which contradicts our assumption. Lemma 5 .1 yie lds a g ap in the feasible lengths of seeds of w . Seeds of length 1 6 n or mo re ca n b e determined using the LO NG-SEEDS pro cedure, so we may focus on computing r elatively short seeds. Due to the characterization of Lemma 2.5, we may ignor e some reg ions of w as long as we do not miss any subw ord o f cer tain length. T o formaliz e this in tuition, we define the following o pe ration COMPR k ( w ), which results in a set o f subw or ds S of w suc h that SUB k ( w ) = S s ∈ S SUB k ( s ). Let us take the s et of fragments which are le ftmost o ccurr ences o f subw ords in SUB k ( w ). An y t wo ov erla pping or consecutive fra gments are joined together, and the subw ords indicated b y the resulting set of fragments give the family COMPR k ( w ); see Fig. 8 for an exa mple. Recall tha t o ur mo tiv ation is to reduce computing short seeds in w to the analo gous op eration in ea ch s ∈ COMPR k ( w ). This is illustra ted by the following r esult. Lemma 5.2 ( Reduction Lemma). Consider a wor d w of length n . F or every int e ger k , 1 ≤ k ≤ n +1 2 , we have Seeds ≤ k ( w ) = \ s ∈ COMPR 2 k − 1 ( w ) Seeds ≤ k ( s ) . Pr o of. Note that SUB 2 k − 1 ( w ) = S s ∈ COMPR 2 k − 1 ( w ) SUB 2 k − 1 ( s ) . Hence, Coro llary 2.6 y ields Seeds ≤ k ( w ) = \ u ∈ SUB 2 k − 1 ( w ) Seeds ≤ k ( u ) = \ s ∈ COMPR 2 k − 1 ( w ) \ u ∈ SUB 2 k − 1 ( s ) Seeds ≤ k ( u ) = \ s ∈ COMPR 2 k − 1 ( w ) Seeds ≤ k ( s ) . This c oncludes the pro of. fast-seeds 2019-03-15 02:02 13 The v alues β k ( w ) can b e used to b ound the total leng th o f words s ∈ COMPR k ( w ), denoted k COM PR k ( w ) k . Lemma 5.3 ( Compression Lem ma). F or e ach wor d w and inte ger k , 1 ≤ k ≤ n +1 2 , we have k COMPR k ( w ) k ≤ β 2 k − 1 ( w ) . Pr o of. Let P be the set of p ositions cov ered by the leftmost o ccurrences of subw o rds from COMPR k ( w ). By construction, k COMPR k ( w ) k = | P | and i ∈ P if and only if i is included in the leftmost o ccurrence of some subw o rd s ∈ SUB k ( w ). If k ≤ i ≤ n − k + 1, then i is the midpoint of a length-(2 k − 1 ) fragment w [ i − k + 1 . . i + k − 1], which covers all length- k fragments of w containing p osition i including the leftmost o ccurrence o f s ∈ SUB k ( w ). Th us, w [ i − k + 1 . . i + k − 1 ] is als o the leftmost o ccur rence of the co rresp onding subw ord of length 2 k − 1 . This yields an injectiv e ma pping from the set o f p ositions i ∈ P ∩ [ k . . n − k + 1] to the family SUB 2 k − 1 ( w ). The remaining p ositions ( i < k and i > n − k + 1) acco un t for the extr a ter m 2 k − 2 = β 2 k − 1 ( w ) − | SUB 2 k − 1 ( w ) | in the upper b ound. F ro m the la st tw o lemmas we obtain the following co rollary tha t conv eys the intuition b ehind the main structural theorem in the following s ection. Corollary 5.4. L et 1 ≤ k ≤ n +3 4 and S = COMPR 2 k − 1 ( w ) . Then Seeds ≤ k ( w ) = \ s ∈ S Seeds ≤ k ( s ) and k S k ≤ β 4 k − 3 ( w ) . 6 Main Algorithm The main algorithm is a r ecursive pro cedure based on a structural theorem whic h combines the r esults of the pr evious section. k + 1 8 k − 1 ⌈ n 6 ⌉ 1 n forbidden area I balanced int erv al long seeds short seeds seed length Figure 9: Illus tration o f T heorem 6 .1(A) in ca se that 8 k ≤ ⌈ n 6 ⌉ . There is no see d o f leng th in the forbidden area. The computation o f a ll s eeds is split into recursive computatio n o f s hort seeds (of length at most k ) in subw ords s ∈ S , o f seeds with lengths in a bala nced interv al I , and of long seeds. Theorem 6.1 ( Decompos ition Theorem). Consider a wor d w of length n . If n ≤ 6 o r | A lph ( w ) | > 2 3 n , then Seeds ( w ) = Seeds ≥ 1 6 n ( w ) . Otherwise, we c an c ompute in line ar time a b alanc e d i nterval I and a family S of su bwor ds of w such that (A) Seeds ( w ) = Seeds ≥ 1 6 n ( w ) ∪ Seeds I ( w ) ∪ \ s ∈ S Seeds ≤ k ( s ) and (B) k S k ≤ 2 3 n. Pr o of. W e take k = max ℓ : 1 ≤ ℓ < ⌈ n 6 ⌉ a nd β 4 ℓ − 3 ( w ) ≤ 2 3 n , S = COMPR 2 k − 1 ( w ) , I = [ k + 1 . . min(8 k, ⌈ n 6 ⌉ ) − 1] . As fo r the first par t o f the statement, note that Seeds ( w ) = Seeds ≥ 1 6 n ( w ) ho lds trivia lly if n ≤ 6. On the other hand, if | Alph ( w ) | = β 1 ( w ) > 2 3 n , then the equality follo ws directly from the Gap Lemma (Lemma 5.1). Hence we can assume further that n > 6 and β 1 ( w ) ≤ 2 3 n . fast-seeds 2019-03-15 02:02 14 Correctness of (B). No w w e can guara n tee that k is well-defined and that it s atisfies β 4 k − 3 ( w ) ≤ 2 3 n . Then Co mpression Lemma (Lemma 5 .3) implies that S satisfies the condition (B) . Correctness of (A). T o prove condition (A) , we o bserve that the Reduction Lemma (Lemma 5 .2) y ields Seeds ≤ k ( w ) = T s ∈ S Seeds ≤ k ( s ). Thus, it is enough to prov e that Seeds ≥ k +1 ( w ) = Seed s ≥ 1 6 n ( w ) ∪ Seeds I ( w ), i.e., that there is no seed v with 8 k ≤ | v | < ⌈ n 6 ⌉ . This claim ho lds trivially for k = ⌈ n 6 ⌉ − 1 . O therwise, β 4 k +1 > 2 3 n , and the claim follows directly from the Gap Lemma (Lemma 5.1). Computing k and S . Let us start with the following claim. Claim. The se qu enc e | SUB m ( w ) | (c onse quently, also the se quenc e β m ( w ) ) c an b e c ompute d in line ar time. Pr o of. E ach equiv alence class E = pack ( i, j 1 , j 2 ) con tributes a single subw ord in SUB m ( w ) for each m ∈ [ j 1 − i + 1 . . j 2 − i + 1]. W e o btain at most 2 n such interv als; | SUB m ( w ) | is then the num b er of interv als that contain the elemen t m . This quan tit y can be computed in O ( n ) time using an auxiliary ar ray A of size n (initially se t to zer o es). F or an in terv al [ a . . b ], A [ a ] is incre men ted a nd A [ b + 1] is decremented. Then | SUB m ( w ) | = A [1] + · · · + A [ m ]. T o retr ieve S = COMPR 2 k − 1 ( w ), we iterate again ov er the e quiv alence class es E = pack ( i, j 1 , j 2 ). If 2 k − 1 ∈ [ j 1 − i + 1 . . j 2 − i + 1], we ma rk the p osition min P , w here P = Oc c ( v ) for v ∈ E . Nex t, we scan the text marking the first 2 k − 2 p ositions in ea ch gap be t w een subseq uen t alrea dy marked pos itions and the first 2 k − 2 p ositions a fter the final a lready marked p osition. After these tw o phas es, we build a w ord s ∈ S out o f each maximal r egion of marked p ositio ns. The algor ithm c omputing seeds relies on Theorem 6 .1, with the LONG-SEEDS pro cedure applied to compute Seeds ≥ 1 6 n ( n ), and recursive calls made to determine Seed s ( s ) for each s ∈ S . Finally , a pack age representation of Seeds I ( w ) is computed using INT-SEEDS. Algorithm 1: Recursive pro cedure SE EDS( w ) Input: A word w of length n . Output: An O ( n )-s ize pa ck a ge represe n tation of Seeds ( w ). if n ≤ 6 or | Alph ( w ) | > 2 3 n then return LO NG-SEEDS( ⌈ n 6 ⌉ , w ) Let I , S be as in the pro of of the Decomp os ition Theore m foreac h v ∈ S do R v := SEEDS( v ) R := Co mb ine( { R v : v ∈ S } ) Remov e from R seeds o f length at leas t min I return R ∪ LONG-SEE DS( ⌈ n 6 ⌉ , w ) ∪ INT-SEEDS( I , w ) (The three pack age repre sentations contain distinct seeds) Theorem 6.2 ( Main Result). An O ( n ) -size p ackage r epr esentation of the set See ds ( w ) of al l se e ds of a given length- n wor d w c an b e found in O ( n ) time. In p articular, a shortest se e d and the total n u mb er of se e ds c an b e c ompute d within the s ame time c omplexity. Pr o of. Co rrectness of the algor ithm SEE DS follows immediately from Theorem 6.1. T o b ound the running time, let us deno te by T ( n ) the ma ximum n umber of o per ations p erformed by the SEEDS function executed fast-seeds 2019-03-15 02:02 15 for a word of length n . Due to Theorem 6 .1 and Lemmas 2.2, 4.3 and 4.4, T ( n ) = O ( n ) + X i T ( n i ) , where X n i ≤ 2 3 n. This r ecurrence yields T ( n ) = O ( n ). 7 Implemen tation of the Op eration Com bine W e descr ibe he re the missing par t of the algorithm, which is based on some rather tec hnical computations on weigh ted trees. First, our algo rithm r equires a n efficient solution to the so- called weigh ted ancestor queries problem. Thus, in Section 7.1 we pres en t a n optimal offline pro cedure ans w ering weighted ancestor queries in a n arbitra ry weigh ted tree with p olynomially bo unded weights. 7.1 Offline W eigh ted Ancest or Queries In the weighted ancestor pr oblem, intro duced by F arach and Muthukrishnan [1 6] (see also [2 1]), we consider a r o oted tr ee T with an integer weight function weight defined on the no des. The weigh t of the ro ot m ust be zero and the weigh t of any o ther no de must be s trictly larger than the w eig ht of its parent . A classic example is any c ompacted trie with the weight of a node defined as the length of its v alue. The weighed ancestor q ueries, given a no de ν and a n integer v alue ℓ ≤ weight ( ν ), ask for the highest ancestor µ of ν s uch that weight ( µ ) ≥ ℓ , i.e., such an ancestor µ that weight ( µ ) ≥ ℓ a nd weight ( µ ) is smallest po ssible. W e denote the no de µ a s anc estor ( ν, ℓ ). W eighted a ncestor queries in the online setting ca n be a nswered in O (log lo g n ) time after O ( n )-time prepro cessing [1]. In the s pecia l cas e of the w eighted tree b eing a suffix tr ee of a word, they can b e answered in O (1) time with a da ta structure of O ( n ) space [21]. Nevertheless, no efficien t construction of this data structure is known. Below we show tha t if all the queries a re given offline and the weigh ts are p olynomia lly bo unded, then q queries can be ans wered in O ( n + q ) time. Let us first recall the classic union-find data structure. It main ta ins a partition S of [1 . . n ]. Ea ch set S ∈ S ha s an identifier id( S ) ∈ S . Initially , S is a par tition into singletons and id( { i } ) = i for 1 ≤ i ≤ n . The union-find data structur e supp orts fi nd ( i ) quer ies which, given an in tege r i ∈ [1 . . n ], return the ident ifier id( S ) of the set S ∈ S c ontaining i . Moreov er, a union ( i 1 , i 2 ) op era tion, g iven in teger s i 1 , i 2 ∈ [1 . . n ], replaces the sets S 1 , S 2 ∈ S such that i 1 ∈ S 1 and i 2 ∈ S 2 with their union S 1 ∪ S 2 . Note that union ( i 1 , i 2 ) is void if S 1 = S 2 , i.e., if find ( i 1 ) = find ( i 2 ). W e will only e ncounter line ar union-find instances , in which sets S ∈ S are f ormed b y consecutive integers and id( S ) = min( S ). In other w or ds, union ( i 1 , i 2 ) is allo wed for i 1 < i 2 only if find ( i 1 ) = find ( find ( i 2 ) − 1). F or such ins tances, the union-find op erations ca n b e implemen ted in a mortized O (1) time. Lemma 7.1 (Gab ow and T arjan [20]) . A se qu enc e of m line ar un ion-fi nd op er ations on a p artition of [1 . . n ] c an b e implemente d in O ( n + m ) t ime. W e are now ready to descr ib e an efficient offline pro ce dure answering w eighted anc estor queries . Lemma 7.2. Given a c ol le ction Q of weighte d anc estor queries on a weighte d tr e e T on n no des with inte ger weights up t o ( n + | Q | ) O (1) , al l the queries fr om Q c an b e answer e d in O ( n + | Q | ) t ime. Pr o of. W e pro cess the tree and the queries acco rding to non-incre asing weigh ts. W e main tain a union- find data s tructure w hic h stores a partition of the set V ( T ) of nodes of T . After the no des with weigh t ℓ ha ve bee n pro cessed, each par tition cla ss is e ither a singleton o f a no de µ s uch tha t weight ( µ ) < ℓ , or consists of the no des o f a subtree r o oted at a node µ such that weight ( µ ) ≥ ℓ . In either case, µ is the ide n tifier of the set. Note that, in order to up date the pa rtition for the next smaller v alue of ℓ , for each no de µ with weight ℓ it suffices to union the sing leton { µ } with the no de s ets of s ubtrees ro o ted at the children of µ . Moreov er, fast-seeds 2019-03-15 02:02 16 observe that after pro cessing no des a t level ℓ , for each no de ν , its anc estors µ with weight ( µ ) < ℓ form singletons, while ancesto rs µ with weight ( µ ) ≥ ℓ belong to the same class as ν . Hence, the identifier o f this class is the highest ancestor of µ with weight ( µ ) ≥ ℓ , i.e., an cestor ( ν, ℓ ) = f ind ( ν ). Co nsequently , the weigh ted a ncestor queries can b e answered using Algo rithm 2. Algorithm 2: Offline weigh ted ancestors for a weighted tree T and a set of quer ies Q W T = { weight ( µ ) : µ ∈ V ( T ) } ; W Q = { ℓ : ( ν , ℓ ) ∈ Q } ; foreac h ℓ ∈ W T ∪ W Q in the de cr e asing or der do foreac h µ ∈ V ( T ) : w e i ght ( µ ) = ℓ do foreac h ν : child of µ in the left-t o-right or der do union ( µ, ν ); foreac h ν : ( ν, ℓ ) ∈ Q do Repo rt anc estor ( ν, ℓ ) := find ( ν ); Next, we shall prov e tha t Algorithm 2 can be implemen ted in O ( n + | Q | ) time. Since no de weights and query weigh ts are in tegers b ounded by ( n + | Q | ) O (1) , they can be sorted using r adix sort in O ( n + | Q | ) time. F or union-find op eratio ns, we need to identify no des with integers [1 . . n ]. W e use the pr e-order identifiers as they guarantee that ea ch partition class (which can b e either a s ingleton or the no de s et o f a subtree ro oted at a given no de) consists of consecutive integers. With n − 1 u nion op era tions a nd | Q | find opera tions, Lemma 7.1 guara nt ees O ( n + | Q | ) ov era ll running time of the union- find data s tructure. W e apply o ffline weigh ted ancestor que ries to the suffix tree to obtain the following algor ithmic to o l. Corollary 7. 3. Given a c ol le ction of subwor ds s 1 , . . . , s k of a wor d w of length n , e ach r epr esente d by an o c curr enc e in w , in O ( n + k ) total t ime we c an c ompute the lo cus of e ach subwor d s i in the suffix tr e e of w . Mor e over, these lo ci c an b e made explicit in O ( n + k ) ex tr a time. Pr o of. Let T b e the suffix tree of w . Assume that s i = w [ a . . b ] and consider the following no des: the no de µ represent ing w [ a . . n ] (the terminal node of T annotated with a ) a nd ν = an cestor ( µ, b − a + 1). If w e denote b y d the depth of ν , then the lo cus of s i is ( ν , d − ( b − a + 1)). By Lemma 7.2, the lo ci of s i can be computed in O ( n + k ) time. In o rder to make the corresp onding implicit nodes ex plicit, w e need to gro up them according to the nearest explicit des cendant and sort them by distances fro m that no de. This can b e implemented in O ( n + k ) time via ra dix sor t. Then we simply c reate the explicit no des in the obtained or der. 7.2 In t ersection of F amilies of Pa ths in a T ree Let us in tro duce one more abstract ope ration on a ro oted tr ee T . A p ath family is a family of pairwise disjoint paths in T , each leading down wards. A path family is ca lled minimal if there is no o ther path family cov er ing the same set o f no des in T and co nsisting of a smaller num b er o f paths. Let P 1 , . . . , P m be path fa milies in T . Then b y P A THS T ( P 1 , . . . , P m ) we denote a minimal pa th family representing the no des cov er ed by all the families P 1 , . . . , P m ; see Fig. 1 0. Lemma 7. 4. The family P A THS T ( P 1 , . . . , P m ) c an b e c ompute d in line ar t ime with r esp e ct to the size of the tr e e T , the numb er m , and t otal numb er of p aths in al l famili es P i . Pr o of. F or each no de µ in T , w e would like to c ompute a v a lue, denoted S [ µ ], that is equa l to the num ber of paths in all families P i that contain node µ . O bserve that a no de µ is cov ered by a ll the families P i if a nd only if S [ µ ] = m . F or each no de ν in T , w e will store a counter C [ ν ] s o that, for a no de µ , S [ µ ] is equal to the sum of v alues C [ ν ] acro ss the no des ν in the s ubtree of µ . The co unt ers C are initially s et to zer o es. F or ea ch path fast-seeds 2019-03-15 02:02 17 P A THS Figure 10 : The P A THS T ( P 1 , P 2 ) operation: three c opies of the same r o oted tree T , the first tw o show P 1 and P 2 , a nd the third o ne shows P A THS T ( P 1 , P 2 ). leading from µ down to ν in P i , we increment the co un ter C a t ν a nd decr ement the coun ter at the pa rent of µ (unless µ is the ro ot). Next, for eac h node µ , w e co mpute S [ µ ] as the sum of v alues C [ ν ] a cross the no des ν in the subtree o f µ . This is done in a b o ttom-up fas hion using the S [ · ] v alues of the children of µ . This wa y , we compute all the no des repres en ted by P A THS T ( P 1 , . . . , P m ). Finally , in order to find the minimal path family cov er ing a ll these no des, we repeat the following proces s tra versing the tree in a bo ttom-up o rder: If the v alue S [ µ ] is m , we create a single-no de pa th { µ } . If also S [ ν ] = m for a child ν of µ , we merg e the paths containing these tw o no des . (W e c ho os e the child arbitrar ily if S [ ν ] = m fo r several children.) 7.3 Pro of of Lemma 2.2 W e are now ready to provide a n efficient implement ation of the Combine o per ation. Lemma 2.2. F o r a wor d w of length n and s et s R 1 , . . . , R k of subwor ds of w , given in p ackage r epr esent ations of total size N , Combine ( R 1 , . . . , R k ) c an b e implemente d in O ( n + N ) time. The size of the r esu lting p ackage r epr esentation i s at most N . Pr o of. W e reduce the pr oblem to computing P A THS T ( P 1 , . . . , P m ) for some path families P 1 , . . . , P m . W e fir st apply Corollar y 7 .3 for subwords w [ i . . j 1 ] and w [ i . . j 2 ] acr oss all pack ages pack ( i, j 1 , j 2 ) in R 1 , . . . , R m , extending the set of explicit no des of the s uffix tree T of w by the obtained lo ci. F or ea ch pack age, we create a path connecting the co rresp onding tw o lo ci. The pack ages in a pack age repres en tation are disjoint, so for ea ch R i this pro cess res ults in a path family . W e apply Le mma 7 .4 to compute a minimal path family P = P A THS T ( P 1 , . . . , P m ). Finally , for each path in P , we create a pack age in T . W e assume that e ach no de stores the lab el ℓ of any terminal no de in its subtree. If a path in P connects tw o no des at depths d 1 ≤ d 2 , a nd the second o ne stores the lab el ℓ , then we create a pack age pack ( ℓ, ℓ + d 1 − 1 , ℓ + d 2 − 1). Ac knowledgemen ts The authors thank Patryk Cza jk a for sugg esting a simplificatio n o f the algor ithm in Section 3.2 (Lemma 3.7). Jakub Radosze wski was s uppo rted by the “Algor ithms for text pr o cessing with er rors and uncer taint ies” pro ject carried out within the HOMING progr am o f the F oundation for P olish Science co-financed by the Europ ean Union under the Eur op ean Regio nal Developmen t F und. References [1] Amiho o d Amir, Ga d M. La ndau, Moshe Lewenstein, a nd Dina Sokol. Dynamic text and s tatic pattern matching. ACM T r ans. Algorithms , 3(2):1 9, 2007. do i:10.1 145/12 40233.1240242 . [2] Amiho o d Amir, Avivit Levy , Moshe Lewenstein, Ronit Lubin, and Benny Porat. Ca n we recov er the cov er ? In Juha K ¨ ar kk¨ ainen, Jakub Rado szewski, and W o jciech Rytter , editors, 28th Annual fast-seeds 2019-03-15 02:02 18 Symp osium on Combinatorial Pattern Matching, CPM 2017 , volume 78 of LIPIcs , pages 25 :1–25:1 5. Schloss Da gstuhl - Leibniz-Zentrum fuer Informatik, 2 017. doi: 10.42 30/LIPIc s.CPM.2017.25 . [3] Amiho o d Amir, Avivit Levy , Ronit Lubin, and Ely Pora t. Approximate cover of string s. In Juha K¨ ar kk¨ a inen, J akub Radosze wski, and W o jciech Ry tter, editor s, 28th Annual Symp osium o n Combina- torial Pattern Matching, CPM 2017 , volume 7 8 o f LIPIcs , pages 26 :1–26:1 4. Sc hloss Dagstuhl - Leibniz- Zentrum fuer Informatik, 2017 . do i:10. 4230/L IPIcs.CPM.2017.26 . [4] Amiho o d Amir, Avivit Levy , a nd Ely P orat. Qua si-p erio dicity under mismatch e rrors . In Gonzalo Nav a rro, David Sa nkoff, and Binha i Z h u, edito rs, Annual Symp osium on Combinatorial Pattern Match- ing, CPM 2018 , volume 105 of LIPIcs , pages 4 :1–4:1 5. Schloss Dagstuhl - Leibniz-Zent rum fuer Infor- matik, 20 18. doi:1 0.4230 /LIPIcs.CPM.2018.4 . [5] Alb erto Apo stolico and Andrzej Ehrenfeuch t. Efficient detection of quasip erio dicities in strings . The o- r etic al Comp uter Scie nc e , 119(2):24 7–265 , 1993 . doi:10.1 016/03 04- 397 5(93)90159- Q . [6] Alb erto Apo stolico, Martin F arach, a nd Cos tas S. I liop oulos. Optimal sup erprimitivity testing for strings. Information Pr o c essing L et ters , 39 (1):17–20 , 199 1. doi:10 .1016/ 0020- 0190(91)90056- N . [7] Omer Berkman, Costas S. Iliop o ulos, a nd Kunso o Park. The subtre e max gap problem with application to paralle l string cov er ing. Information and Computation , 123(1):12 7–13 7, 1995. doi:10 .1006 /inco.1995.1162 . [8] Dany Breslauer . An on-line string sup er primitivity test. Information Pr o c essing L etters , 44(6):3 45–34 7, 1992. doi:1 0.1016 /0020 - 0190(92)90111- 8 . [9] Gerth Stølting Bro dal and Christian N. S. Pedersen. Finding maximal qua sip erio dicities in strings. In Raffaele Gia ncarlo and David Sankoff, editors, Combinatoria l Pattern Matching, CPM 2000 , volume 18 48 of L e ctur e N otes in Computer S cienc e , pages 397–4 11. Springer , 2 000. doi:10 .1007 /3- 540- 45 123- 4_33 . [10] Manolis Chr isto doulakis, Co stas S. Iliop oulos, K unso o Park, a nd Jeo ng Se op Sim. Approximate seeds of strings . Journal of A ut omata, L anguages and Co mbinatorics , 10(5/ 6):609–6 26, 20 05. [11] Michalis Christou, Ma xime Cro chemore, Costas S. Iliop oulos, Marcin Kubica, Solon P . Pissis, J akub Radoszewski, W o jciec h Rytter, Bartosz Szreder , a nd T omasz W a le ´ n. Efficient seed computation r evisited. The or etic al Computer Scienc e , 483 :171– 181, 20 13. doi:1 0.1016 /j.tcs.2011.12.078 . [12] Richard Cole, Co stas S. Iliop oulos, Mana l Mo hamed, William F. Smyth, a nd Lu Y ang. The complexity of th e minim um k-cov er problem. Journal of Automata, L anguages and Combinatorics , 10 (5/6):641 –653, 2005. [13] Maxime Cro chemore, Christophe Hancar t, and Thierry Lecro q. Al gorithms on strings . Cambridge Univ ersity Pr ess, 2007 . doi:10. 1017/c bo9780511546853 . [14] Maxime C ro chemore and W o jciech Rytter. Jewels of Stringolo gy . W o rld Scientific, 200 3. doi:10 .1142 /4838 . [15] Mar tin F ara ch-Colton, P ao lo F erra gina, and S. Muthukrishnan. O n the so rting-complexity o f suffix tree construction. J ou rn al of the A CM , 47(6):98 7–101 1, 2000 . doi:10. 1145/3 55541.355547 . [16] Mar tin F arach-Colton and S. Muthukrishnan. Perfect hashing for str ings: F or malization a nd al- gorithms. In Danie l S. Hirschberg and Euge ne W. Myers, editors, Combinatori al Patt ern Match- ing, CPM 1996 , volume 1075 of L e ctur e Notes in Computer Scienc e , pages 130– 140. Spr inger, 1996 . doi:10 .1007 /3- 540- 61 258- 0_11 . fast-seeds 2019-03-15 02:02 19 [17] Nathan J. Fine and Herbert S. Wilf. Uniquenes s theorems for p erio dic functions. Pr o c e e dings of the Americ an Mathematic al So ciety , 1 6(1):109– 114, 1 965. doi: 10.230 7/203 4009 . [18] T om´ as Flouri, Costas S. Iliop oulos, T omasz K o ciumak a, Solon P . Piss is, Simon J. Puglisi, William F. Sm yth, and W o jciech T yczy ´ nski. Enha nced string co vering. The or etic al Computer S cienc e , 506:10 2–114 , 2013. doi:1 0.1016 /j.tc s.2013.08.013 . [19] Haro ld N. Gabow, Jon Louis Ben tley , and Rob er t Endre T arjan. Scaling and related techniques for geom- etry problems. In Richard A. DeMillo, editor , 16th Annual ACM Symp osium on The ory of Computing, STOC 1984 , pages 135–1 43. ACM, 1984 . doi:10. 1145/8 00057.808675 . [20] Haro ld N. Gab ow and Rob erd E. T arjan. A linear-time algor ithm for a sp ecia l case o f disjoint set union. Journal of Computer and S ystem Scienc es , 30 (2):209– 221, 19 85. doi: 10.101 6/002 2- 0000(85)90014- 5 . [21] Paw e l Gawryc howski, Mo she Lewenstein, and Patric k K . Nicholson. W eighted ance stors in suffix trees. In Andrea s S. Sc h ulz and Dorothea W agner, editors, Algorithms, ESA 2014 , volume 873 7 of L e ctur e Notes in Computer Scienc e , pa ges 455 –466. Spr inger, 2 014. doi: 10.10 07/978 - 3- 662- 44777- 2 _38 . [22] Qing Guo, Hui Zha ng, and Costas S. Iliop oulos. Computing the λ -seeds of a string . In Siu- Wing Cheng and Ch ung Keung Poon, editor s, Algorithmic Asp e cts in Information and Management, AAIM 2006 , volume 4 041 o f L e ctur e N otes in Computer Scienc e , pages 303– 313. Spring er, 20 06. doi:10 .1007 /11775096_28 . [23] Qing Guo, Hui Zhang, and Costas S. Iliop oulos. Computing the minimum approximate λ -cov er of a string. In F abio Crestani, Paolo F err agina, and Mark Sanderson, editors, String Pr o c essing and Information R etrieval, 13th International Confer enc e, SPIRE 2006 , volume 4209 o f L e ct u r e Notes in Computer Scienc e , pages 49–6 0. Spring er, 20 06. doi:10. 1007/1 1880561\_5 . [24] Qing Guo, Hui Zhang , and Co stas S. Iliop oulos. Co mputing the λ -cov er s of a string. In formation Scienc es , 1 77(19):3 957–3 967, 2007 . doi:10. 1016/j .ins.2007.02.020 . [25] Costa s S. I liop oulos, Manal Moha med, and William F. Sm yth. New c omplexity re sults for the k -cov er s problem. Information Scienc es , 181 (12):2571 –257 5, 2011. doi:10. 1016/ j.ins.2011.02.009 . [26] Costa s S. Iliop oulos , Dennis W. G. Moore, and Kunso o P ar k. Cov e ring a string. Algorithmi c a , 16(3):288 – 297, 19 96. doi:1 0.1007 /BF01955677 . [27] Costa s S. Iliop oulos and Laurent Mouchard. Quasip er io dicit y: F r om detection to normal forms . Jour n al of Automata, L anguages and Combinatori cs , 4(3):2 13–22 8, 19 99. [28] Costa s S. Iliop oulos and William F. Sm yth. An on- line algorithm o f computing a minimum set of k-cov ers of a string. In Austr alasian Workshop on Combinatorial Algori thms, A WOCA 1998 , pages 97–10 6, 19 98. [29] Juha K ¨ ar kk¨ aine n, Peter Sanders, and Stefan Burkhar dt. Linear w ork suffix a rray construction. Journal of the A CM , 53(6):91 8–936 , 2006. do i:10.1 145/12 17856.1217858 . [30] T omasz Kociumak a, Marcin Kubica, Jakub Radosz ewski, W o jciech Rytter, a nd T omasz W ale ´ n. A linear time algorithm for seeds computation. In Y uv al Raba ni, editor, 23r d Annual A CM-SIAM S ymp osium on Discr ete A lgorithms, SODA 2012 , pages 1095 –1112 . SIAM, 20 12. doi:1 0.113 7/1.97 81611973099 . [31] T omasz Ko ciumak a, Solo n P . Pissis , Jakub Rado szewski, W o jciech Rytter, and T omasz W ale´ n. Effi- cient a lgorithms for sho rtest pa rtial seeds in words. The or etic al Computer Scienc e , 710:139–1 47, 201 8. doi:10 .1016 /j.tcs.2016.11.035 . [32] T omasz Ko ciumak a, So lon P . Pissis, Jak ub Radoszewski, W o jciec h Rytter, and T o masz W ale ´ n. F a st algor ithm for pa rtial cov er s in words. A lgorithmic a , 73 (1):217–2 33, 2015. doi:10 .1007 /s00453- 014- 99 15- 3 . fast-seeds 2019-03-15 02:02 20 [33] Roman M. Ko lpako v and Gregory Kucherov. Finding ma ximal rep etitions in a word in linear time. In 40th Annual Symp osium on F oundatio ns of Computer Scienc e, FOCS 1999 , pag es 596–6 04. IEEE Computer So ciety , 1 999. doi :10.11 09/SFF CS.1999.814634 . [34] Yin Li and William F. Smyth. Computing the cov er array in linear time. Algorithmic a , 32(1):95–106 , 2002. doi:1 0.1007 /s004 53- 001- 0062- 2 . [35] M. Lo thaire. Applie d Combinatoric s on Wor ds . Cambridge Univ er sity P ress, 200 5. doi:10 .1017 /cbo9781107341005 . [36] Udi Manber and Eugene W. Myers. Suffix a rrays: A new metho d for on-line string searches. SIAM Journal on Computing , 2 2(5):935– 948, 1 993. doi: 10.113 7/022205 8 . [37] Dennis W. G. Mo o re and William F. Smyth. An optimal a lgorithm to compute all the c ov ers of a str ing. Information Pr o c essing L et ters , 50(5 ):239–2 46, 1 994. doi: 10.10 16/002 0- 0190(94)00045- X . [38] Dennis W. G. Mo o re and William F. Sm y th. A co rrection to ” An optimal algorithm to compute all the cov ers of a str ing”. Information Pr o c essing L ett ers , 54(2):101– 103, 1 995. doi:10 .1016 /0020- 0190(94)00235- Q . [39] James H. Mor ris, Jr. a nd V a ughan R. P ratt. A linea r pattern-matching algorithm. T echnical Repor t 40, Department of Computer Science, University o f Ca lifornia, Berkeley , 1970 . [40] Jeo ng Seop Sim, Kunso o P ar k, Sung-Ryul Kim, and Jee-Soo Lee. Finding approximate cov- ers o f s trings. Journal of Kor e a Information Scienc e So ciety , 29(1):16–2 1, 20 02. URL: http:/ /www. koreascience.or.kr/article/ArticleFullRecord.jsp?cn=JBGHG6_2002_v29n1_16 . [41] William F. Smyth. Repe titiv e p erhaps, but certainly not b o ring. The or etic al Comp uter Scienc e , 249(2):34 3–35 5, 2000 . do i:10.1 016/S0 304- 3975(00)00067- 0 . [42] Peter W einer. Linea r pattern ma tc hing algo rithms. In 14th Annual Symp osium on Switching and Automata The ory, S W A T 1973 , pages 1–11, W ashing ton, DC, USA, 1973 . IEE E Co mputer Society . doi:10 .1109 /SWAT.1973.13 . fast-seeds 2019-03-15 02:02 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment