DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis
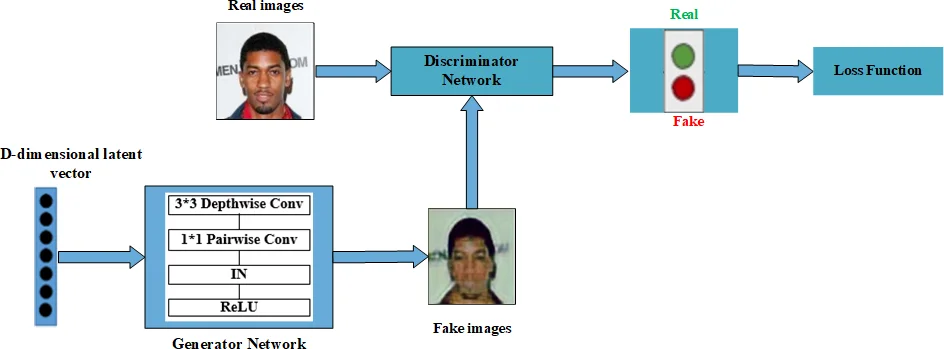
Recent work has shown significant progress in the direction of synthetic data generation using Generative Adversarial Networks (GANs). GANs have been applied in many fields of computer vision including text-to-image conversion, domain transfer, super-resolution, and image-to-video applications. In computer vision, traditional GANs are based on deep convolutional neural networks. However, deep convolutional neural networks can require extensive computational resources because they are based on multiple operations performed by convolutional layers, which can consist of millions of trainable parameters. Training a GAN model can be difficult and it takes a significant amount of time to reach an equilibrium point. In this paper, we investigate the use of depthwise separable convolutions to reduce training time while maintaining data generation performance. Our results show that a DepthwiseGAN architecture can generate realistic images in shorter training periods when compared to a StarGan architecture, but that model capacity still plays a significant role in generative modelling. In addition, we show that depthwise separable convolutions perform best when only applied to the generator. For quality evaluation of generated images, we use the Fr'echet Inception Distance (FID), which compares the similarity between the generated image distribution and that of the training dataset.
💡 Research Summary
The paper “DepthwiseGANs: Fast Training Generative Adversarial Networks for Realistic Image Synthesis” investigates whether replacing standard convolutional layers with depthwise separable convolutions can reduce the computational burden of GAN training while preserving image quality. The authors start from the well‑known StarGAN architecture, which performs multi‑domain image‑to‑image translation using a single generator‑discriminator pair. They design three variants: (1) DepthwiseDG, where both generator and discriminator use depthwise separable convolutions; (2) DepthwiseG, where only the generator is modified; and (3) DeeperDepthwiseG, which adds more depthwise separable layers to the generator to compensate for reduced capacity.
Depthwise separable convolutions factor a conventional K×K convolution into a depthwise spatial convolution applied independently to each input channel followed by a 1×1 pointwise convolution that mixes channel information. This factorisation reduces the number of multiply‑add operations by roughly 1/K² and cuts the number of trainable parameters dramatically. The authors quantify this reduction: the original StarGAN generator holds about 8.5 M parameters, whereas DepthwiseG’s generator contains only 1.5 M parameters, a reduction of over 80 %.
Training is performed on three facial image datasets—CelebA (≈200 k images, resized to 128×128), the Radboud Face Database (RaFD), and the Stirling 3D Face database—each providing multiple domains such as gender, hair colour, or facial expression. All experiments follow the StarGAN training protocol: an adversarial loss, a domain classification loss, and a reconstruction loss, with hyper‑parameters λ_cls = 1 and λ_rec = 10. The Adam optimizer runs on a single NVIDIA Tesla K20c GPU.
Performance is measured using the Fréchet Inception Distance (FID), which approximates the distance between the multivariate Gaussian statistics of real and generated images in the feature space of a pre‑trained Inception‑v3 network. The authors sample 140 images every 20 000 epochs to compute FID.
Results show that applying depthwise separable convolutions only to the generator (DepthwiseG) yields a model that converges faster in terms of FID and reaches a comparable final score to the baseline after roughly 175 epochs. Training time drops from about three days for StarGAN to one day and twelve hours for DepthwiseG. However, the reduced capacity leads to slightly blurrier textures in early epochs. By deepening the generator (DeeperDepthwiseG) to 11 depthwise separable layers, the parameter count rises to 5.6 M, and the model achieves FID values indistinguishable from StarGAN while still requiring only two days of training—still faster than the baseline.
Conversely, the DepthwiseDG variant, which also replaces the discriminator’s convolutions, performs poorly: generated images appear cartoon‑like, and FID scores are substantially higher. The authors attribute this degradation to the discriminator’s loss of expressive power, which hampers its ability to provide useful gradients for the generator.
Qualitative visual comparisons on CelebA demonstrate that DepthwiseG and DeeperDepthwiseG can faithfully transfer attributes such as hair colour, gender, and age, producing results that are visually indistinguishable from those of StarGAN. The deeper model (DeeperDepthwiseG) especially excels on the RaFD and Stirling datasets, where lighting conditions vary, maintaining fine details and realistic shading.
In summary, the study confirms that depthwise separable convolutions are an effective tool for building lightweight GANs when applied exclusively to the generator. They dramatically cut parameter count and training time without sacrificing final image quality, provided that the generator’s depth (or overall capacity) is sufficient to offset the loss of representational power per layer. The discriminator, however, should retain standard convolutions to preserve its discriminative strength. These findings open the door to deploying multi‑domain image translation GANs on resource‑constrained platforms such as mobile devices or edge‑computing units, where training speed and model size are critical constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment