Automatic Detection and Compression for Passive Acoustic Monitoring of the African Forest Elephant
In this work, we consider applying machine learning to the analysis and compression of audio signals in the context of monitoring elephants in sub-Saharan Africa. Earth's biodiversity is increasingly under threat by sources of anthropogenic change (e…
Authors: Johan Bjorck, Brendan H. Rappazzo, Di Chen
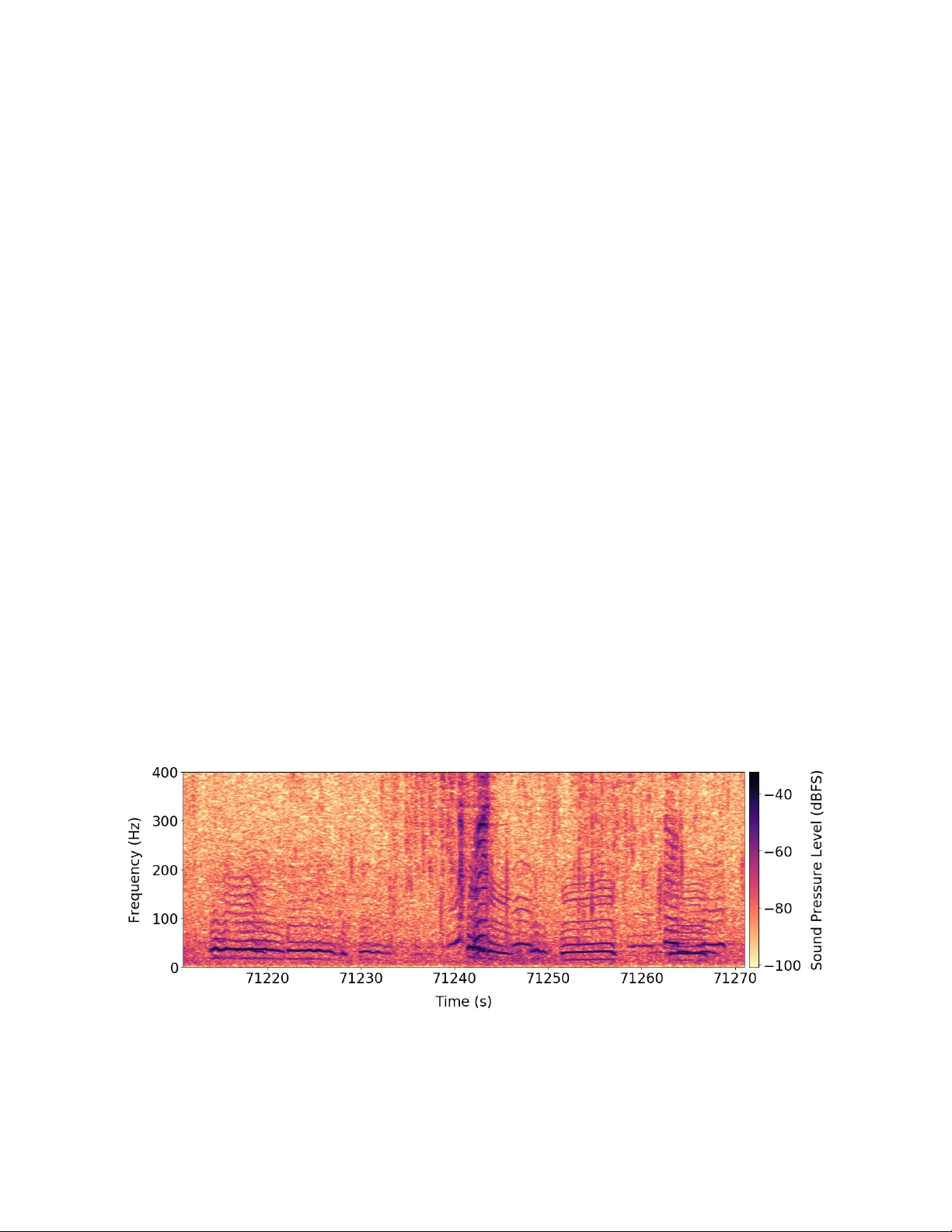
A utomatic Detection and Compr ession f or Passi v e Acoustic Monitoring of the African F or est Elephant Johan Bjor ck 1 Brendan H. Rappazzo 1 Di Chen 1 Richard Bernstein 1 Peter H. Wr ege 2 Carla P . Gomes 1 1 Dept. of Computer Science, Cornell Univ ersity , Ithaca, NY 2 Bioacoustics Research Program, Cornell Lab of Ornithology , Ithaca, NY Abstract In this work, we consider applying machine learning to the analysis and compression of audio signals in the conte xt of monitoring elephants in sub-Saharan Africa. Earths biodiv er - sity is increasingly under threat by sources of anthropogenic change (e.g. resource extraction, land use change, and cli- mate change) and surve ying animal populations is critical for de veloping conservation strategies. Howe v er , manually monitoring tropical forests or deep oceans is intractable. For species that communicate acoustically , researchers have ar- gued for placing audio recorders in the habitats as a cost- effecti v e and non-inv asi ve method, a strategy known as pas- siv e acoustic monitoring (P AM). In collaboration with con- servation efforts, we construct a large labeled dataset of pas- siv e acoustic recordings of the African Forest Elephant via crowdsourcing, compromising thousands of hours of record- ings in the wild. Using state-of-the-art techniques in artificial intelligence we impro ve upon previously proposed methods for passiv e acoustic monitoring for classification and seg- mentation. In real-time detection of elephant calls, network bandwidth quickly becomes a bottleneck and ef ficient ways to compress the data are needed. Most audio compression schemes are aimed at human listeners and are unsuitable for low-frequency elephant calls. T o remedy this, we pro- vide a novel end-to-end dif ferentiable method for compres- sion of audio signals that can be adapted to acoustic mon- itoring of any species and dramatically improves over niv e coding strategies. Introduction Poaching, illegal logging, and infrastructure expansions are some of many current threats to biodiversity , and large mam- mals are particularly susceptible. T o effecti v ely allocate con- servation resources and dev elop conservation strategies, en- dangered animal populations need to be accurately and eco- nomically surveyed, but for species that roam large or inac- cessible areas monitoring by humans becomes intractable. A promising approach for species communicating via acous- tic signals is passive acoustic monitoring (P AM), which in- volv es the use of autonomous recording devices scattered throughout habitats that record animal vocalizations. Com- pared to video monitoring, acoustic monitoring is not lim- ited by line of sight, is typically considerably cheaper and Copyright c 2019, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. Figure 1: The African forest elephant (Loxodonta cyclo- tis) is the smallest of the three extant elephant species, a keystone species in the rainforests of the Congo Basin, and is entirely relied upon by many trees to disperse their seeds (Campos-Arceiz and Blake 2011). Due to their highly- valued iv ory tusks, the elephant is a typical tar get for poach- ers in central Africa and the population has fallen by more than 60% in the last decade (Morelle 2016). Population monitoring is critical for the elephant’ s surviv al, and in this work, we consider combining passive acoustic monitoring and artificial intelligence tow ards this end. requires less bandwidth for transferring the data. Ho we ver , extracting useful data from these soundscapes is non-trivial and automatic approaches are necessary . In this work, we consider P AM in the context of monitor - ing the African forest elephant. T o enable real-time acoustic monitoring one needs to quickly and accurately detect ele- phants and potential threats to them – a classical challenge of classification and segmentation. Lev eraging recent adv ances in neural networks, we improve upon previous methods in automating P AM. In real-time threat-detection and popula- tion monitoring the bandwidth of the wireless networks be- comes a bottleneck, and one additionally has to use ef ficient data representations to only communicate the necessary in- formation. In man y lossy compression schemes, signal com- ponents inaudible to humans such as low frequencies are giv en low bit-rates, which in the context of low-frequenc y elephant calls is a poor strategy . Using a dif ferentiable proxy for non-differentiable bit truncation, we are able to cast this problem as an end-to-end differentiable setup, which can be trained via stochastic gradient descent (SGD) to get im- prov ed compression. W e focus on the African Forest Elephant both due to its bi- ological importance and the loud calls by which it communi- cates. This elephant is a keystone species in the rainforests of the Congo Basin, the second largest expanse of rainforest on earth and among the most speciose. Conserving viable popu- lations of forest elephants protects local biodi v ersity , b ut the expansi v eness of the rainforest and the dif ficulty of monitor - ing animals within it mak es manual monitoring problematic. Since elephants communicate over long distances via infra- sonic signals referred to as rumbles (Hedwig, DeBellis, and Wrege 2018) they are particularly suited to an acoustic ap- proach. These characteristic vocalizations provide informa- tion on occupancy , landscape use, population size, and the effects of anthropogenic disturbances (Wre ge et al. 2017). The contributions of our work are to 1) construct a large dataset of real-world elephant vocalizations from central Africa via passiv e acoustic monitoring, 2) surpass pre vi- ously proposed methods for automatic P AM in the context of elephant vocalizations via state-of-the-art artificial intel- ligence techniques, and 3) introduce a novel end-to-end dif- ferentiable technique for audio-compression, that can bal- ance the bit-rates between dif ferent frequency channels to the unique characteristics of the monitored species. The Dataset Data collection Established in 2000, the Elephant Listening Project (ELP) uses acoustic methods to study the ecology and behavior of forest elephants in order to improve e vidence-based decision making concerning their conserv ation. ELP has recorded sounds from over 150 different locations, amassing more than 700,000 hours of recordings. These varying en viron- ments provide the source material for generating training data for algorithm development. The dataset we consider in this work was collected between 2007 and 2012 from three sites in Gabon and one in the Central African Repub- lic, which will be referred to as Ceb1, Ceb4, Dzanga, and Jobo. A map showing these locations is given in Figure 7 of the Appendix. At all locations, a single recording device was placed in a tree 7-10 meters above the ground near for- est clearings (25 to 50ha) where elephants congregate for multiple purposes. The recording devices sample audio sig- nals at a rate of 2000 (12-bit resolution) or 4000Hz (16- bit) and can detect elephant calls up to approximately 0.8 km away . As is typical in bioacoustic applications the ani- mals are detected infrequently , and different locations hav e variable density , see T able 1. Additionally , multiple other sources of sound are recorded, both man-made and natural. For example, Ceb4 is close to a road and the recordings in- clude signals associated with logging and gunshots. Acoustic Characteristics of the Dataset The primary mode of communication among elephants is a low-frequency vocalization known as a rumble, typically lasting between 2 and 8 seconds. These sounds ha ve distinct frequency characteristics, with a lo w fundamental frequenc y (8 - 34Hz), often several higher harmonics, and slight fre- quency modulation. A typical recording is shown in Figure 2. At lar ge g atherings, multiple elephants often make simul- taneous or ov erlapping calls (see for example Figure 2 where two calls ov erlap). Other complications are the v ariability of the dataset, for example, some recording sites are close to logging concessions which are often visited by motorized vehicles which become recorded. Natural sources of noise include heavy wind, rainfall, insects chirping and thunder- storms, see Figure 3 for further examples. Labeling The labeling of rumbles to be used in the training and testing of detection algorithms was done by both experts and trained volunteers at the Elephant Listening Project. The v olunteers Figure 2: A spectrogram of se veral elephant rumble vocalizations within a 60-second segment of sound. The rich harmonic structure is typical of rumbles, howe ver , since higher frequency elements attenuate rapidly with distance, recording these higher frequency elements depends on source amplitude and distance. Thus, it is difficult to infer distance from harmonic structure alone. Figure 3: Examples of the diversity of acoustic signals en- countered in sound streams from Central African forest en- vironments. A) an elephant call combining both tonal and chaotic (broadband) sounds, often produced in agonistic sit- uations. B) an elephant rumble with few harmonics (source far from microphone and/or low amplitude). C) signals emit- ted by a dwarf crocodile (Osteolaemus tetraspis), including some harmonics similar to those of elephants. D) the buzzing of insects E) a motorized vehicle F) sound of splashing of water as elephants mov e through a stream. were recruited by a combination of work-study positions and information spread via word-of-mouth and were asked to identify individual elephant calls and their temporal extent in the recording. Positive labeling was based on a set of crite- ria de veloped by experts with more than ten years of e xperi- ence with forest elephant vocalizations and experience with potentially confusing en vironmental sounds. V olunteers fol- lowed a detailed training program that concluded with them labeling rumbles in two 24 hour long test sound files. The labels generated by the volunteers for the test files were compared to those of an expert. If the results were within 5% of each other , the volunteer was considered trained; if not, he/she repeated the process on other sound files un- til the 5% or less difference was achiev ed. The occasional further revie w of volunteer labeling efforts by the experts maintained reasonable consistency among all labelers (reli- ability > 98% ). Statistics about the dataset and the labeling can be seen in T able 1. T o facilitate online cro wdsourcing, we hav e created an online labeling application for labeling. The website contains a tutorial where participants can first learn about the characteristics and variations of elephant calls and other sounds that might occur in recordings. The tutorial is publicly available at www.udiscover.it/ applications/elp/tutorial.php . Once trained, participants can then label elephant calls in audio segments by using the application’ s annotation tool, see Figure 8 in the Appendix. By giving the same spectrum to multiple partici- pants one can gauge the accurac y of individual users and can encourage truthful responses. These issues will be addressed further in future work. Location Dates Collected Labelled hours Num. calls Apx. % Calls Ceb1 09/04 - 11/06 1870 52810 0.784 % Ceb4 08/06 - 11/03 1280 23038 0.500 % Jobo 09/05 - 11/06 1437 28609 0.553 % Dzan 11/04 - 12/02 312 63792 21.8 % T able 1: The statistics of the datasets by location. The Apx. percentage of calls refer to what portion of the audio recordings contained elephant calls. The dates are gi ven in YY/MM format. Classification and Segmentation The simplest and most straightforward problem for pas- siv e acoustic monitoring is that of detection. Giv en a short audio-clip we want to classify it as containing a signal pro- duced by the species of interest (in this case an elephant rumble) or not. This setting has been considered by many previous authors (Mac Aodha et al. 2018; Nichols 2016; Bittle and Duncan 2013), and is a crucial stepping stone to- ward using P AM for population surve ying and monitoring. A similar setting we consider is one of segmentation where we want to classify each discrete time step as belonging to an elephant call or not. Data Processing Giv en a specific location where a recording device is placed, say ”Ceb1” in T able 1, we extract all unique elephant rum- bles recorded. The calls will in some cases o verlap and if so we consider them as tw o or more unique calls. T o facilitate a homogeneous dataset, we extract signals of the fixed length 25.5 sec and remov e the handful of calls that are longer than this. W e then extract empty regions of the same length, that does not overlap with any elephant calls, uniformly at ran- dom, we e xtract as many empty re gions as there are elephant calls. The combined dataset of calls and empty frames is then split uniformly and randomly into a testing and training set, where additional augmentation might be performed on the training set. Given these fixed sized windows of audio recording, we transform them into the frequency domain via FFT . Using the signals down-sampled to 1000 Hz, we use a window size of 512 and hop-length of 384 we use FFT to transform the audio signal into the frequency domain. All frequency bands above 100Hz are removed, as the set of recorded elephant calls rarely ha ve significant signals abov e such frequency because of signal attenuation. This gives us a 64 time-steps by 47 frequenc y bands tensor , and we specif- ically choose time-steps to have the shape be a power of two which can be beneficial for training on GPUs. One has to be slightly careful when normalizing the dataset as the signals are very sparse, we have found that subtracting the mean of all frames containing no calls and then dividing the signal by the median call intensity works well. Neural Network Ar chitectures and T raining Audio-clips are approximately time-in v ariant, i.e., an ele- phant call will sound the same no matter if it starts after 1s or Location SVM RF AD A-grad DNN ((Mac Aodha et al. 2018)) Densenet + rnd crop Ceb1 77.22 76.73 77.01 91.11 93.40 Ceb4 70.21 69.82 71.50 90.15 93.68 Jobo 76.92 76.49 76.86 91.67 94.30 Dzan 72.21 69.79 70.86 75.86 77.51 A vg. 74.14 73.21 74.06 87.20 89.72 T able 2: The classification accuracy on the test-set for dif- ferent algorithms at different locations. 3s. This approximate symmetry suggests the use of con volu- tions ov er the time dimension would be successful, we hav e howe ver found it beneficial to additionally perform conv o- lutions over the frequency dimension. This corresponds to an approximate pitch-inv ariance, meaning that elephant calls from different elephants sound similar except for a uniform pitch change. Gi v en this two-w ay con volution, we adopt the state-of-the-art network architecture Densenet (Huang et al. 2017), which is a standard con v olutional network with skip connections between all layers. F or training this architecture we use best practices from neural network training (LeCun et al. 2012), we consider SGD with momentum and weight decay , iterativ ely lowering the learning rate as performance plateaus and using cross-entropy as the loss. W e further in- troduce data augmentation by adapting the technique of ran- domized cropping, which is typically used on image classifi- cation, to sound classification. The 64 time-steps are padded by 8 on both sides, and we feed a random 64 step long subsequence. Exact parameters are giv en in table 5 in the Appendix. For our segmentation setting we train a standard long short-term memory (LSTM) network (Hochreiter and Schmidhuber 1997), additionally , we use the same LSTM network with an initial one-dimensional con v olutional layer on the frequenc y dimension. This conv olution layers uses 25 filters and thus outputs a feature vector of length 25 for each time step, which is then fed into the LSTM network. For training this architecture we use the ADAM optimizer and cross-entropy as the loss. Results W e compare our approach to previously proposed methods in bioacoustic monitoring, both modern and classical. From the latter category , we consider the method of Dufour et al., where rich features based upon the MFCC coefficients are extracted and then fed into an SVM (Hearst et al. 1998). The MFCC coefficients are similar to the FFT , where the signal is decomposed into frequency parts, ho we ver , the filters and masks used are much more sophisticated. Given these coef- ficients for each time step, the features for the entire audio clip are the mean, v ariance and deri v ati v e of the coef ficients for each time step across the entire audio clip. Additionally , we consider feeding these features into a Random Forest classifier (Liaw , W iener , and others 2002) and an ADA Grad classifier , essentially emulating the approach of Ross and Allen although with slightly different features. The second type of baselines we consider are con volutional neural net- works, where we use the architecture (and training parame- 0 . 7 5 0 . 8 0 0 . 8 5 0 . 9 0 0 . 9 5 P r e c i s i o n 0 . 4 0 . 6 0 . 8 1 . 0 R e c a l l D N N O u r s R F A d a S V M Figure 4: W e here illustrated the precision-recall curve of the various classifiers we consider here. All algorithms based upon the MFCC features perform relativ ely poorly , whereas the classic neural networks and Densenet specifi- cally achiev e much higher scores. Location LSTM con v-LSTM Ceb1 70.50 95.24 Ceb4 70.43 90.54 Jobo 67.49 92.12 Dzan 70.54 88.95 A vg. 69.74 91.71 T able 3: The classification accuracy on the test-set for the segmentation task, gi v en for different algorithms at different locations. ters/schedule) of Mac Aodha et al. proposed for classifying the vocalizations of bats. The architecture is classical, mean- ing no skip-connections are used and dropout is not used (Sriv astava et al. 2014) for regularization, see Mac Aodha et al. for details. Results can be viewed in T able 2 where we see that our methods consistently outperform baselines across ev ery location. A more nuanced picture over the precision and recall is gi v en in Figure 4. F or the se gmentation setting, we compare our con volution-LSTM hybrid network’ s per- formance to that of only an LSTM network and show how the hybrid methods perform much better in terms of accu- racy , see T able 3. Compression Background The ultimate aim of passi ve acoustic monitoring is to pro- vide accurate real-time detections of elephant vocalizations and threats. It is infeasible to perform neural network com- putations on the recording devices, and hence the devices need to send their data over the wireless networks of sub- Saharan Africa. Unfortunately , wireless infrastructure is largely relativ ely poor or absent in this area of the world (Aker and Mbiti 2010), av ailable bandwidth is small and Figure 5: The main idea behind our end-to-end compression scheme is to introduce a continuous bit-rate vector λ and i.i.d. noise that serves as a proxy for the quantization error . By optimizing λ one can adjust the quantization lev el for different frequency bands, which can be optimized jointly with a neural-network classifier to find compression strategies that result in signals that are useful for classification. At deployment, the bit-rates of individual frequency channels are used for compression at the recording devices so that data transfer is minimized. data-transfer is expensi ve. T o make real-time passi ve acous- tic monitoring cost efficient, one has to transfer only the most relev ant information across the wireless network. A natural strategy for reducing the data-transfers across the wireless network is to compress the acoustic data. Most lossy compression codecs crucially rely on the specifics of the human auditory system to remove data that are irrele- vant to the experience of a human listener . For example, it is well kno wn that the sensiti vity of the human auditory system v aries with frequency (Painter and Spanias 2000), and hence many lossy compression algorithms remove lo w- frequency components or simply use a lo w bit-rate for them. In the context of elephant monitoring, this is a poor strate gy since the elephants communicate by low-frequency rumbles. It is clear that we need to dev elop compression strategies uniquely suited for the elephant calls and for the neural net- works that will analyze them. As neural networks are well known to be resistant to minor random perturbations (Mi- cike vicius et al. 2017) lossy compression is a promising av- enue. Additionally , as passiv e acoustic monitoring has ap- plications to many species, from small birds (Bardeli et al. 2010) to marine mammals (Bittle and Duncan 2013), data- driv en approaches such as ours av oids the laborious process of manually crafting audio codecs and can easily be adapted to ne w species. It does not require any hand-crafted features or any specific information regarding the structure of ani- mal vocalization (save for an approximate frequency range, information that is easily obtainable for most species), and one would only” need training data to adapt our framework to other species. End-to-end differentiable compr ession codecs As opposed to typical audio compression applications, the listener in our setup is not a human, additionally , the fre- Figure 6: W e here illustrate an example of quantization of a signal with elephant calls with e xtremely low bit-rate. Back- ground signal almost disappears with quantization while the elephant call loses much of its nuances. quency spectrum is vastly different. T o study this phe- nomenon in isolation and achiev e a simple setup we only consider compression in terms of the dif ferent frequency bands. Other aspects of lossy compression, for example, lossless compression on top of lossy strate gies, can be added to all methods we consider . W e assume that the one- dimensional X that describes the sound wa ves has been transformed via FFT as a pre-processing step into ˆ X , and consider the problem of assigning bit-rates to the different frequency bands. Simple operations such as FFT and bit- truncation can easily be implemented on the rudimentary hardware of the recording devices. W e propose a method that jointly optimizes for low bit-rates of the frequency chan- nels and high classification accuracy . Our algorithmic setup is illustrated in Figure 5. W e want to assign different bit-rates to different frequency-channels, which we achiev e by simply truncating the bit representation of elements of the channels, which lowers the precision. Our key insight is to exchange a non-differentiable bit-truncation by a differentiable proxy – we simply model truncation as additiv e Gaussian noise, a common model of quantization error (Gray and Neuhoff 1998). W e let the components of the vector λ denote the bit-rates of various frequency channels, and let β be a matrix with dimensions t × f with indepen- dent standard Gaussian entries, where there are t time-steps and f frequency bands. The truncation error is the propor- tional to by the matrix exp( − λ ) β , where the entries ( i, j ) are equal to exp( − λ j ) β ij . This ensures that the additive er - rors in the original elephant spectrogram ˆ X , which models bit-truncation, are independent but that each frequency band has its own error scale. The input to the neural networks is thus ˆ X + exp( − λ ) β , and we simultaneously optimize the network parameters ω for large classification accuracy and the total bit-rate which is simply expressed as P i λ i , balancing these two objectives with the hyper-parameter µ . The loss can be written as E β ∼ N ( ˆ X ,y ) ∼ D L y , DNN ω exp( − λ ) β + ˆ X + µ X i λ i (1) Here the dataset D contains tuples ( ˆ X , y ) of data ˆ X and labels y , L ( y , ˆ y ) denotes the loss function used to measure goodness of fit between ground-truth label y and estimated label ˆ y . The function DNN ω giv es the output of the trained neural network with netw ork parameters ω . W e again use the cross-entropy for the loss function. This function can be op- timized via SGD, where we exchange the expectation E [ · ] by sample av erages. Experiments W e compare different compression strategies by how well they transmit the important information as measured by how well a classifier can be trained to classify compressed ele- phant spectrograms given a fixed bit-rate. For all compres- sion strategies, we will use the Densenet model of earlier sections. The original Fourier signal has elements put into one of the 2 32 bins represented as 32 bit signed integers, low- ering the bit-rate simply corresponds to removing the least significant bits with the sign bit is removed last. This has the effect of quantizing the signal and removing small vari- ations in signal strength while keeping the large variations (see Figure 6). W e enforce that no less than 5 bits are used for each frequency band as the dynamic range of the au- dio signal has the effect of completely erasing the signal for smaller bit-rates. For assigning bit-rates via optimizing (1) we use the same Densenet architecture as for ev aluating the compression quality , and train it with the same parameters as in earlier sections and with µ = 10 − 7 . T o ensure specific total bit-rates we assign bit-rates to various frequency bands proportional to the values of the components of λ . W e com- pare our method against the method of assigning bit-rates proportional to the sensitivity of human hearing, using the well-known model of how human auditory sensitivity vary Method / Bit-rate Ceb1 Ceb4 Jobo Dzan Ours / 47 84.57 83.98 86.31 78.43 Human / 47 83.62 81.31 85.76 69.44 Ours / 141 92.81 92.21 93.19 77.96 Human / 141 86.61 91.90 90.32 73.51 Ours / 235 93.05 93.11 93.84 77.46 Human / 235 90.25 92.34 91.64 76.93 T able 4: The classification accuracy on the test-set for the giv en bit-rates at v arious locations. with frequency of (Painter and Spanias 2000). The propor- tional allocation excludes the 5 bits needed for the dynamic range of the signal. The results for v arious locations and bit- rates are giv en in T able 4, where we can clearly see that our proposed method achieves superior performance for the same bit-rates. For very small and very large bit-rates the dif- ference becomes smaller . Implementing our method leads to data compression of a factor roughly 116 compared to nively storing the 1000Hz signal in 32-bit floating point numbers while achieving little performance degradation. These sav- ings are significant for the often poor wireless networks of sub-Saharan Africa. Related W ork Bioacoustics The field of bioacoustics has for a long time been inter- ested in automatic approaches towards detecting and clas- sifying animal vocalizations with the ultimate goal to accu- rately survey population size and behavior (McDonald and Fox 1999). As sound wav es attenuate less in water , passive acoustic monitoring can cover vast underwater areas. Much effort has been in terms of large marine animals with charac- teristic vocalizations – predominately v arious whale species (Humpback, right (Thode et al. 2017), Baleen (Baumgartner and Mussoline 2011), Blue and Fin ( ˇ Sirovi ´ c, Hildebrand, and W iggins 2007)) and dolphins (Erbs, Elwen, and Grid- ley 2017). Acoustic signals are the primary mode of com- munication for many marine species and for lar ge gath- erings vocalizations typically overlap which together with long rev erberation times becomes challenging. T echniques used to ov ercome these issues include blind source separa- tion (Zhang and White 2017), pitch-tracking via dynamic programming (Baumgartner and Mussoline 2011) and ker - nel methods (Thode et al. 2017). On land, efforts towards bioacoustics have primarily fo- cused on various bird species, owing to the characteris- tic songs many of them use for mating and communica- tion. As bird species typically hav e unique songs, P AM makes it possible to accurately survey populations of en- dangered species, whereas using direct visual observ ations becomes problematic for species that are small and/or oc- cupy canopies (Bardeli et al. 2010). Popular strategies in- clude SVMs based upon MFCC (Dufour et al. 2014), seg- mentation via deep learning (K oops, V an Balen, and Wier - ing 2015) and dictionary learning (Salamon et al. 2017). Beyond birds, insects (Ganche v and Potamitis 2007), bats (Mac Aodha et al. 2018) and monkeys (T uresson et al. 2016) hav e all been considered. Elephants have been studied from a similar perspectiv e to ours by Pleiss, Wrege, and Gomes. For man y of these species, especially many birds, the vocal- izations occupy a relativ ely small frequency band making models less sensitive to noise and intra-population variabil- ity in vocalizations, hence making them unsuitable for ele- phant monitoring. Machine-learning f or A udio Machine learning for audio-signals has primarily focused on human speech due to applications such as virtual assis- tants, automatic transcription, and translation. F or a long time, mainstream research was primarily propelled by us- ing the EM-algorithms for training Hidden-Markov-Models (Hinton et al. 2012). Features for audio input could often be encoded via MFCC (Sahidullah and Saha 2012), and rich distributions could be represented via Gaussian-Mixture- Models (Juang, Levinson, and Sondhi 1986). While using neural networks for acoustic applications was concei ved more than 25 years ago (Bourlard and Morgan 2012), it was in only 2009 that deep learning approaches were shown to be competitiv e with more traditional “hand-crafted” ma- chine learning approaches (Mohamed, Dahl, and Hinton 2009). Deep learning has now gained mainstream traction and it has become the dominant paradigm. State-of-the-art speech recognition often relies on recurrent neural netw orks (Grav es and Jaitly 2014) (Sak, Senior , and Beaufays 2014), where con v olutional layers can automatically extract fea- tures (Sainath et al. 2015). Beyond speech recognition, deep learning for acoustic sensing in smartphones has been in ves- tigated (Lane, Georgie v , and Qendro 2015). Compression Compression for acoustic signals has been studied for a long time due to applications such as storing music on handheld devices and sending human conv ersations across networks, and many audio compression methods rely on essentially handcrafted features, for example, wav elets (Jagadeesh and Kumar 2014). Most methods for lossy compression of au- dio has the goal of ensuring signals are audible to humans, and hence most models are based upon the models of hu- man hearing, so-called psychoacoustic models. A salient feature of human hearing is that its sensitivity varies with frequency (Painter and Spanias 2000), a common strategy is to transform the audio-signal with the modified discrete cosine transform (MDCT) and address frequency bands in- dividually . Another phenomenon of human hearing is called simultaneous masking where signal A can make signal B (which is of a different frequency and intensity) inaudible (Jagadeesh and Kumar 2014). While traditional compression schemes ha ve typically re- lied on handcrafted features, the adv ent of deep learning has spurred interest in data-driv en approaches to compres- sion. Previous research has primarily focused on images and video, proposing various continuous and differentiable prox- ies for entropy and quantization, see for example (Ball ´ e, La- parra, and Simoncelli 2016) and (Agustsson et al. 2017). The only work on audio compression known to the authors is on human speech (Kankanahalli 2017) which has is dif- ferent in terms of frequency distribution, complexity , and dataset cleanliness; the proposed architecture relies on soft- max quantization. Future W ork and Conclusions Managers of protected areas designed for the forest ele- phants are interested in better conservation tools but need to see definiti v e proof of their efficac y . If useful information about elephant populations and human encroachments can reach managers within a reasonable timeframe, the poten- tial to expand acoustic monitoring across the Congo Basin becomes a reality . Collaboration with managers is thus in- strumental in developing a rapid work-flo w for the current acoustic monitoring project in northern Congo, which cov- ers 1500 square km of rainforest and generates sev en ter- abytes of sound data quarterly . W e hope that these proof-of- concept demonstrations of how various AI techniques can inspire future work on P AM, with the ultimate goal of real- world implementation. In this work, we have introduced a dataset of elephant calls recorded in the wild aimed at promoting interest and progress in automatic methods for passiv e acoustic mon- itoring and discussed our methods for labeling it. Using modern neural network architecture, state-of-the-art training regimes and data-augmentation techniques we hav e shown how to improv e upon previously proposed method for pas- siv e acoustic monitoring. Additionally , we have addressed how wireless network infrastructure is often lacking in sub- Saharan Africa data transfer quickly becomes a bottleneck for real-time systems. T o circumvent this issue, we hav e in- troduced a nov el scheme for jointly optimizing bit-rates and prediction accuracy , which beats a baseline based upon mod- els of human hearing. Acknowledgements W e would like to thanks the Elephant project, the Cornell Lab of Ornithology its volunteers and the Wildlife Conser- vation Society . This work is supported by NSF Expedition CCF-1522054 and ARO DURIP W911NF-17-1-0187. The work of PHW was supported by the U.S. Fish and Wildlife Service and the Robert G. and Jane V . Engel Foundation. A ppendix Parameter V alue init. learning rate 0.1 SGD momentum 0.9 batch size 64 initialization kaiming weight decay 0.0001 loss function cross-entropy T able 5: Hyper-parameters used for training. Figure 7: The sites from which the elephant recordings were collected, as seen via Google Earth. All areas were close to forest clearings, additionally , one is close to a river while CEB1 and CEB4 are within logging concessions. Note that this paper did not use sounds from all sites in this map. References Agustsson, E.; Mentzer , F .; Tschannen, M.; Cavigelli, L.; T imofte, R.; Benini, L.; and Gool, L. V . 2017. Soft-to-hard vector quan- tization for end-to-end learning compressible representations. In NIPS . Aker , J. C., and Mbiti, I. M. 2010. Mobile phones and economic dev elopment in africa. Journal of Economic P erspectives . Ball ´ e, J.; Laparra, V .; and Simoncelli, E. P . 2016. End-to-end opti- mized image compression. arXiv preprint . Bardeli, R.; W olff, D.; Kurth, F .; Koch, M.; T auchert, K.-H.; and Frommolt, K.-H. 2010. Detecting bird sounds in a comple x acous- tic en vironment and application to bioacoustic monitoring. P attern Recognition Letters . Baumgartner , M. F ., and Mussoline, S. E. 2011. A generalized baleen whale call detection and classification system. The Journal of the Acoustical Society of America . Bittle, M., and Duncan, A. 2013. A re vie w of current marine mam- mal detection and classification algorithms for use in automated passiv e acoustic monitoring. In Pr oceedings of Acoustics . Bourlard, H. A., and Morgan, N. 2012. Connectionist speech r ecognition: a hybrid appr oach . Springer Science & Business Me- dia. Campos-Arceiz, A., and Blake, S. 2011. Me gagardeners of the forest–the role of elephants in seed dispersal. Acta Oecologica . Dufour , O.; Artieres, T .; Glotin, H.; and Giraudet, P . 2014. Clus- terized mel filter cepstral coefficients and support vector machines for bird song identification. In Soundscape Semiotics-Localization and Cate gorization . Erbs, F .; Elwen, S. H.; and Gridley , T . 2017. Automatic classi- fication of whistles from coastal dolphins of the southern african subregion. The Journal of the Acoustical Society of America . Figure 8: W e here show the interface of online annotation tool, which enables crowdsourcing of labeling ef forts. Ganchev , T ., and Potamitis, I. 2007. Automatic acoustic identifi- cation of singing insects. Bioacoustics . Grav es, A., and Jaitly , N. 2014. T owards end-to-end speech recog- nition with recurrent neural networks. In International Confer ence on Machine Learning . Gray , R. M., and Neuhoff, D. L. 1998. Quantization. IEEE trans- actions on information theory . Hearst, M. A.; Dumais, S. T .; Osuna, E.; Platt, J.; and Scholkopf, B. 1998. Support vector machines. IEEE Intelligent Systems and their applications . Hedwig, D.; DeBellis, M.; and Wrege, P . H. 2018. Not so far: attenuation of low-frequenc y vocalizations in a rainforest environ- ment suggests limited acoustic mediation of social interaction in african forest elephants. Behavioral Ecology and Sociobiology . Hinton, G.; Deng, L.; Y u, D.; Dahl, G. E.; Mohamed, A.-r .; Jaitly , N.; Senior , A.; V anhoucke, V .; Nguyen, P .; Sainath, T . N.; et al. 2012. Deep neural networks for acoustic modeling in speech recog- nition: The shared vie ws of four research groups. IEEE Signal pro- cessing magazine . Hochreiter , S., and Schmidhuber , J. 1997. Long short-term mem- ory . 9:1735–80. Huang, G.; Liu, Z.; V an Der Maaten, L.; and W einberger , K. Q. 2017. Densely connected conv olutional networks. In CVPR . Jagadeesh, B., and Kumar , B. S. 2014. Psychoacoustic model-1 implementation for mpeg audio encoder using wa velet packet de- composition. In Emer ging Resear ch in Electr onics, Computer Sci- ence and T echnology . Juang, B.-H.; Levinson, S.; and Sondhi, M. 1986. Maximum like- lihood estimation for multiv ariate mixture observations of markov chains (corresp.). IEEE T ransactions on Information Theory . Kankanahalli, S. 2017. End-to-end optimized speech coding with deep neural networks. arXiv pr eprint arXiv:1710.09064 . K oops, H. V .; V an Balen, J.; and W iering, F . 2015. Automatic segmentation and deep learning of bird sounds. In International Confer ence of the Cr oss-Languag e Evaluation F orum for European Languages . Lane, N. D.; Georgie v , P .; and Qendro, L. 2015. Deepear: robust smartphone audio sensing in unconstrained acoustic en vironments using deep learning. In Pr oceedings of the 2015 A CM International Joint Confer ence on P ervasive and Ubiquitous Computing . LeCun, Y . A.; Bottou, L.; Orr , G. B.; and M ¨ uller , K.-R. 2012. Efficient backprop. In Neural networks: T ric ks of the trade . Liaw , A.; W iener , M.; et al. 2002. Classification and regression by randomforest. R news . Mac Aodha, O.; Gibb, R.; Barlow , K. E.; Browning, E.; Firman, M.; Freeman, R.; Harder, B.; Kinsey , L.; Mead, G. R.; Newson, S. E.; et al. 2018. Bat detectiv edeep learning tools for bat acoustic signal detection. PLoS computational biology . McDonald, M. A., and Fox, C. G. 1999. Passiv e acoustic methods applied to fin whale population density estimation. The J ournal of the Acoustical Society of America . Micike vicius, P .; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchae v , O.; V enkatesh, G.; et al. 2017. Mixed precision training. arXiv pr eprint arXiv:1710.03740 . Mohamed, A.-r .; Dahl, G.; and Hinton, G. 2009. Deep belief net- works for phone recognition. In Nips workshop on deep learning for speech r eco gnition and r elated applications . Morelle, R. 2016. Slow birth rate found in african forest elephants. Nichols, N. M. 2016. Marine mammal species detection and clas- sification . Ph.D. Dissertation. Painter , T ., and Spanias, A. 2000. Perceptual coding of digital audio. Pleiss, G.; Wrege, P . H.; and Gomes, C. 2016. Unpublished tech- nical report. Ross, J. C., and Allen, P . E. 2014. Random forest for improved analysis efficiency in passiv e acoustic monitoring. Ecological in- formatics . Sahidullah, M., and Saha, G. 2012. Design, analysis and experi- mental ev aluation of block based transformation in mfcc computa- tion for speaker recognition. Speech Communication . Sainath, T . N.; V in yals, O.; Senior , A.; and Sak, H. 2015. Con- volutional, long short-term memory , fully connected deep neural networks. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Confer ence on . Sak, H.; Senior , A.; and Beaufays, F . 2014. Long short-term mem- ory recurrent neural network architectures for large scale acous- tic modeling. In F ifteenth annual confer ence of the international speech communication association . Salamon, J.; Bello, J. P .; Farnsworth, A.; and Kelling, S. 2017. Fusing shallo w and deep learning for bioacoustic bird species clas- sification. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . ˇ Sirovi ´ c, A.; Hildebrand, J. A.; and Wiggins, S. M. 2007. Blue and fin whale call source lev els and propagation range in the southern ocean. The Journal of the Acoustical Society of America . Sriv asta v a, N.; Hinton, G.; Krizhevsk y , A.; Sutskev er , I.; and Salakhutdinov , R. 2014. Dropout: a simple way to prevent neu- ral networks from overfitting. The Journal of Machine Learning Resear ch . Thode, A.; Bonnel, J.; Thieury , M.; Fagan, A.; V erlinden, C.; Wright, D.; Berchok, C.; and Crance, J. 2017. Using nonlinear time w arping to estimate north pacific right whale calling depths in the bering sea. The Journal of the Acoustical Society of America . T uresson, H. K.; Ribeiro, S.; Pereira, D. R.; Papa, J. P .; and de Al- buquerque, V . H. C. 2016. Machine learning algorithms for auto- matic classification of marmoset vocalizations. Wrege, P . H.; Ro wland, E. D.; K een, S.; and Shiu, Y . 2017. Acous- tic monitoring for conservation in tropical forests: examples from forest elephants. Methods in Ecology and Evolution . Zhang, Z., and White, P . R. 2017. A blind source separation ap- proach for humpback whale song separation. The Journal of the Acoustical Society of America .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment