Super-realtime facial landmark detection and shape fitting by deep regression of shape model parameters
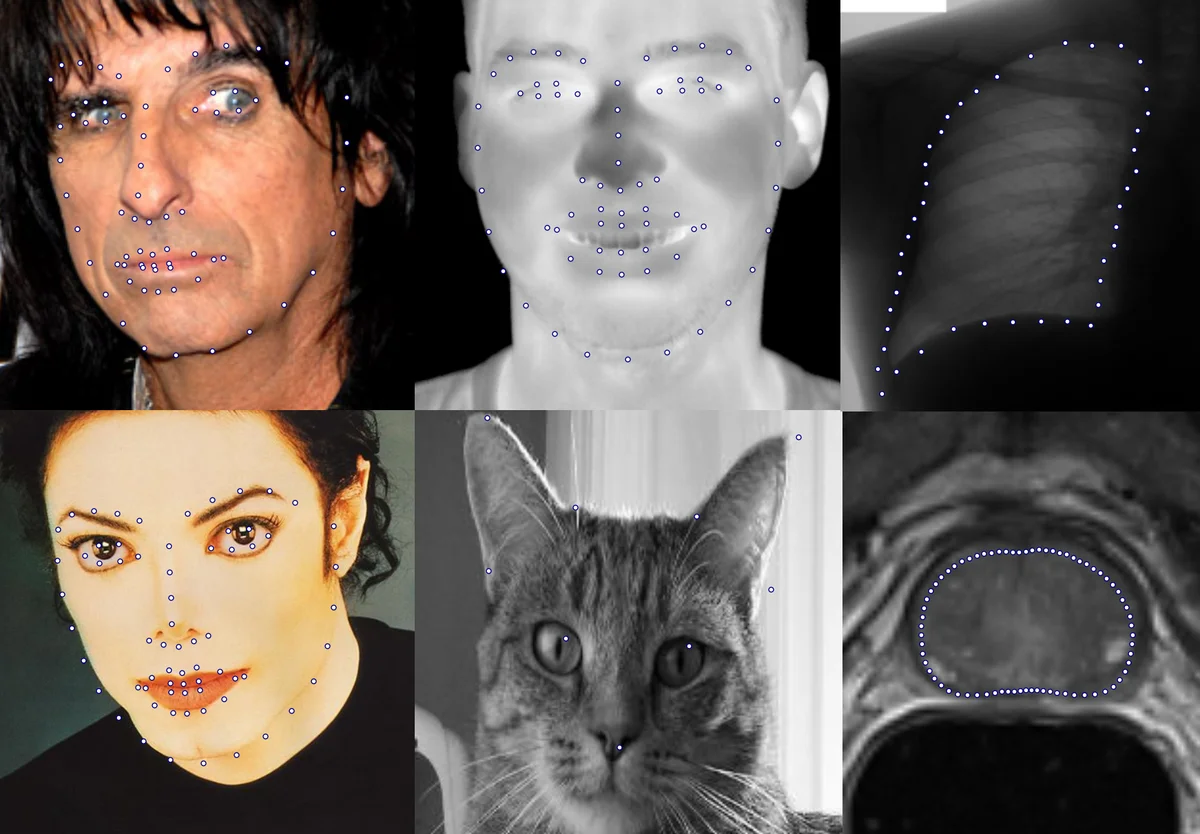
We present a method for highly efficient landmark detection that combines deep convolutional neural networks with well established model-based fitting algorithms. Motivated by established model-based fitting methods such as active shapes, we use a PCA of the landmark positions to allow generative modeling of facial landmarks. Instead of computing the model parameters using iterative optimization, the PCA is included in a deep neural network using a novel layer type. The network predicts model parameters in a single forward pass, thereby allowing facial landmark detection at several hundreds of frames per second. Our architecture allows direct end-to-end training of a model-based landmark detection method and shows that deep neural networks can be used to reliably predict model parameters directly without the need for an iterative optimization. The method is evaluated on different datasets for facial landmark detection and medical image segmentation. PyTorch code is freely available at https://github.com/justusschock/shapenet
💡 Research Summary
The paper introduces a novel approach for ultra‑fast facial and medical landmark detection by embedding a statistical shape model directly into a deep convolutional neural network (CNN). Traditional model‑based methods such as Active Shape Models (ASMs), Active Appearance Models (AAMs) and Constrained Local Models (CLMs) rely on iterative optimization of PCA parameters to fit a shape to an image, which is computationally expensive and unsuitable for real‑time applications. Recent deep‑learning based alignment networks achieve high accuracy but still struggle to reach the hundreds‑of‑frames‑per‑second regime while preserving the geometric plausibility enforced by a shape model.
The core contribution is a custom “PCA layer” that stores the mean shape and a set of eigen‑vectors (principal components) computed offline from the training landmarks. During forward propagation the network predicts a small set of scalar weights for these components together with four global transformation parameters (scale, rotation, x‑translation, y‑translation). The layer multiplies the eigen‑vectors by their predicted weights, adds the mean shape, and finally applies the global similarity transform to obtain the landmark coordinates in image space. Because the eigen‑vectors are fixed, back‑propagation only updates the regression head and the preceding feature extractor; the PCA layer itself is fully differentiable and incurs virtually no computational overhead regardless of the number of components used.
The feature extractor is deliberately lightweight: it consists solely of 2‑D convolutional blocks (C2DB) with 3×3 kernels, interleaved with down‑sampling and instance‑normalization layers (DN). No fully‑connected layers are employed, drastically reducing the parameter count and memory footprint. Spatially separated convolutions along the height and width axes further cut the number of learnable parameters. The entire network processes 224×224 RGB (or single‑channel) images and outputs the PCA weights and global transform in a single forward pass.
Training uses standard landmark datasets (HELEN, LFPW) to compute the PCA basis. Images are cropped around the face, resized, and optionally augmented with random rotations, scaling, and flips. The loss is a simple point‑to‑point distance (L1 or MSE) between predicted and ground‑truth landmarks, normalized by the inter‑ocular distance. Because the PCA layer is part of the computational graph, the loss propagates through the shape generation step, allowing end‑to‑end optimization of both the feature extractor and the regression head.
Extensive experiments evaluate the method on five heterogeneous datasets: (1) 300W (indoor and outdoor RGB faces), (2) a thermal‑IR face database, (3) a cat facial landmark set, (4) the JSRT chest X‑ray dataset (lung landmarks), and (5) the PROMISE12 prostate MRI slices. For each dataset the authors select an appropriate number of PCA components (typically 5–25) and train the same network architecture. Results show a consistent inference speed of approximately 410 frames per second on an RTX 2080 Ti using half‑precision (FP16), independent of the number of components. Normalized mean errors (NME) range from 2.3 % on the thermal set to 4.1 % on the cat dataset, comparable to or better than state‑of‑the‑art methods that require far more computation time.
A key observation is that increasing the number of PCA components beyond about 15 yields diminishing returns for facial data, confirming that a compact linear shape space is sufficient when combined with a powerful CNN regressor. Moreover, separating global similarity parameters from the PCA coefficients enables the model to handle large head poses and image‑level transformations without inflating the dimensionality of the shape space.
The discussion highlights the method’s generality: the PCA layer can be reused for any problem where data can be represented by a linear subspace (e.g., organ contours, hand poses). Limitations include the reliance on a linear PCA basis, which may struggle with highly non‑linear deformations, and the current 2‑D formulation that does not directly capture depth variations in 3‑D data. Future work could explore non‑linear manifold learning, 3‑D extensions, and integration with temporal models for video streams.
In conclusion, the authors deliver a practical, open‑source (PyTorch) solution that merges the interpretability and geometric constraints of statistical shape models with the speed and robustness of deep learning. The approach achieves super‑real‑time landmark detection across diverse imaging modalities while maintaining competitive accuracy, opening the door for real‑time downstream applications such as augmented reality, driver monitoring, and intra‑operative medical navigation.
Comments & Academic Discussion
Loading comments...
Leave a Comment